用deepseek学大模型05逻辑回归
deepseek.com:逻辑回归的目标函数,损失函数,梯度下降 标量和矩阵形式的数学推导,pytorch真实能跑的代码案例以及模型,数据,预测结果的可视化展示, 模型应用场景和优缺点,及如何改进解决及改进方法数据推导。
逻辑回归全面解析
一、数学推导
模型定义:
逻辑回归模型为概率预测模型,输出 P ( y = 1 ∣ x ) = σ ( w ⊤ x + b ) P(y=1 \mid \mathbf{x}) = \sigma(\mathbf{w}^\top \mathbf{x} + b) P(y=1∣x)=σ(w⊤x+b),其中 σ ( z ) = 1 1 + e − z \sigma(z) = \frac{1}{1+e^{-z}} σ(z)=1+e−z1。
1. 目标函数与损失函数
-
损失函数(交叉熵):
单个样本的损失:
L ( y , y ^ ) = − y log ( y ^ ) − ( 1 − y ) log ( 1 − y ^ ) \mathcal{L}(y, \hat{y}) = -y \log(\hat{y}) - (1-y) \log(1-\hat{y}) L(y,y^)=−ylog(y^)−(1−y)log(1−y^)
其中 y ^ = σ ( w ⊤ x + b ) \hat{y} = \sigma(\mathbf{w}^\top \mathbf{x} + b) y^=σ(w⊤x+b)。所有样本的平均损失(标量形式):
J ( w , b ) = − 1 N ∑ i = 1 N [ y i log ( y ^ i ) + ( 1 − y i ) log ( 1 − y ^ i ) ] J(\mathbf{w}, b) = -\frac{1}{N} \sum_{i=1}^N \left[ y_i \log(\hat{y}_i) + (1-y_i) \log(1-\hat{y}_i) \right] J(w,b)=−N1i=1∑N[yilog(y^i)+(1−yi)log(1−y^i)]矩阵形式( X \mathbf{X} X为设计矩阵, y \mathbf{y} y为标签向量):
J ( w , b ) = − 1 N [ y ⊤ log ( σ ( X w + b ) ) + ( 1 − y ) ⊤ log ( 1 − σ ( X w + b ) ) ] J(\mathbf{w}, b) = -\frac{1}{N} \left[ \mathbf{y}^\top \log(\sigma(\mathbf{X}\mathbf{w} + b)) + (1-\mathbf{y})^\top \log(1-\sigma(\mathbf{X}\mathbf{w} + b)) \right] J(w,b)=−N1[y⊤log(σ(Xw+b))+(1−y)⊤log(1−σ(Xw+b))]
2. 梯度下降推导
-
标量形式梯度:
对 w j w_j wj求偏导:
∂ L ∂ w j = ( y ^ − y ) x j \frac{\partial \mathcal{L}}{\partial w_j} = (\hat{y} - y) x_j ∂wj∂L=(y^−y)xj
对 b b b求偏导:
∂ L ∂ b = y ^ − y \frac{\partial \mathcal{L}}{\partial b} = \hat{y} - y ∂b∂L=y^−y -
矩阵形式梯度:
梯度矩阵为:
∇ w J = 1 N X ⊤ ( σ ( X w + b ) − y ) \nabla_{\mathbf{w}} J = \frac{1}{N} \mathbf{X}^\top (\sigma(\mathbf{X}\mathbf{w} + b) - \mathbf{y}) ∇wJ=N1X⊤(σ(Xw+b)−y)
∂ J ∂ b = 1 N ∑ i = 1 N ( y ^ i − y i ) \frac{\partial J}{\partial b} = \frac{1}{N} \sum_{i=1}^N (\hat{y}_i - y_i) ∂b∂J=N1i=1∑N(y^i−yi)
损失函数的设计是机器学习模型的核心环节,它决定了模型如何衡量预测值与真实值的差异,并指导参数优化方向。逻辑回归的损失函数(交叉熵)设计并非偶然,而是基于概率建模、数学优化和信息论的深刻原理。以下从多个角度详细解释其设计逻辑:
一、损失函数的设计逻辑
1. 概率建模的视角
逻辑回归的目标是预测样本属于某一类的概率(二分类)。
-
假设数据服从伯努利分布:
对单个样本,标签 y ∈ { 0 , 1 } y \in \{0,1\} y∈{0,1},模型预测的概率为:
{ P ( y = 1 ∣ x ) = y ^ = σ ( w ⊤ x + b ) , P ( y = 0 ∣ x ) = 1 − y ^ . \begin{cases} P(y=1 \mid \mathbf{x}) = \hat{y} = \sigma(\mathbf{w}^\top \mathbf{x} + b), \\ P(y=0 \mid \mathbf{x}) = 1 - \hat{y}. \end{cases} {P(y=1∣x)=y^=σ(w⊤x+b),P(y=0∣x)=1−y^.
样本的联合似然函数为:
L ( w , b ) = ∏ i = 1 N y ^ i y i ( 1 − y ^ i ) 1 − y i . L(\mathbf{w}, b) = \prod_{i=1}^N \hat{y}_i^{y_i} (1 - \hat{y}_i)^{1 - y_i}. L(w,b)=i=1∏Ny^iyi(1−y^i)1−yi. -
最大化对数似然:
为了便于优化,对似然函数取负对数(将乘法转为加法,凸函数性质不变):
− log L ( w , b ) = − ∑ i = 1 N [ y i log y ^ i + ( 1 − y i ) log ( 1 − y ^ i ) ] . -\log L(\mathbf{w}, b) = -\sum_{i=1}^N \left[ y_i \log \hat{y}_i + (1 - y_i) \log (1 - \hat{y}_i) \right]. −logL(w,b)=−i=1∑N[yilogy^i+(1−yi)log(1−y^i)].
最小化该式等价于最大化似然函数,此即 交叉熵损失。
2. 信息论视角
交叉熵(Cross-Entropy)衡量两个概率分布 P P P(真实分布)和 Q Q Q(预测分布)的差异:
H ( P , Q ) = − E P [ log Q ] . H(P, Q) = -\mathbb{E}_{P}[\log Q]. H(P,Q)=−EP[logQ].
对于二分类问题:
- 真实分布 P P P:标签 y y y是确定的(0或1),可视为一个 Dirac delta分布。
- 预测分布 Q Q Q:模型输出的概率 y ^ \hat{y} y^。
交叉熵的表达式与负对数似然一致,因此最小化交叉熵等价于让预测分布逼近真实分布。
3. 优化视角:梯度性质
-
交叉熵 vs 均方误差(MSE):
若使用 MSE 损失 L = 1 2 ( y − y ^ ) 2 \mathcal{L} = \frac{1}{2}(y - \hat{y})^2 L=21(y−y^)2,其梯度为:
∂ L ∂ w j = ( y − y ^ ) ⋅ y ^ ( 1 − y ^ ) ⋅ x j . \frac{\partial \mathcal{L}}{\partial w_j} = (y - \hat{y}) \cdot \hat{y} (1 - \hat{y}) \cdot x_j. ∂wj∂L=(y−y^)⋅y^(1−y^)⋅xj.
当 y ^ \hat{y} y^接近 0 或 1 时(预测置信度高),梯度中的 y ^ ( 1 − y ^ ) \hat{y}(1 - \hat{y}) y^(1−y^)趋近于 0,导致 梯度消失,参数更新缓慢。交叉熵的梯度为:
∂ L ∂ w j = ( y ^ − y ) x j . \frac{\partial \mathcal{L}}{\partial w_j} = (\hat{y} - y) x_j. ∂wj∂L=(y^−y)xj.
梯度直接正比于误差 ( y ^ − y ) (\hat{y} - y) (y^−y),无论预测值大小,梯度始终有效,优化更高效。
4. 数学性质
- 凸性:交叉熵损失函数在逻辑回归中是凸函数(Hessian矩阵半正定),保证梯度下降能找到全局最优解。
- 概率校准性:交叉熵强制模型输出具有概率意义(需配合 sigmoid 函数),而 MSE 无此特性。
二、为什么不是其他损失函数?
1. 均方误差(MSE)的缺陷
- 梯度消失问题(如上述)。
- 对概率的惩罚不对称:
当 y = 1 y=1 y=1时,预测 y ^ = 0.9 \hat{y}=0.9 y^=0.9的 MSE 损失为 0.01 0.01 0.01,而交叉熵损失为 − log ( 0.9 ) ≈ 0.105 -\log(0.9) \approx 0.105 −log(0.9)≈0.105。
交叉熵对错误预测(如 y ^ = 0.1 \hat{y}=0.1 y^=0.1时 y = 1 y=1 y=1)的惩罚更严厉( − log ( 0.1 ) ≈ 2.3 -\log(0.1) \approx 2.3 −log(0.1)≈2.3),符合分类任务需求。
2. 其他替代损失函数
- Hinge Loss(SVM使用):
适用于间隔最大化,但对概率建模不直接,且优化目标不同。 - Focal Loss:
改进交叉熵,解决类别不平衡问题,但需额外调整超参数。
三、交叉熵的数学推导
1. 从伯努利分布到交叉熵
假设样本独立,标签 y ∼ Bernoulli ( y ^ ) y \sim \text{Bernoulli}(\hat{y}) y∼Bernoulli(y^),其概率质量函数为:
P ( y ∣ y ^ ) = y ^ y ( 1 − y ^ ) 1 − y . P(y \mid \hat{y}) = \hat{y}^y (1 - \hat{y})^{1 - y}. P(y∣y^)=y^y(1−y^)1−y.
对数似然函数为:
log P ( y ∣ y ^ ) = y log y ^ + ( 1 − y ) log ( 1 − y ^ ) . \log P(y \mid \hat{y}) = y \log \hat{y} + (1 - y) \log (1 - \hat{y}). logP(y∣y^)=ylogy^+(1−y)log(1−y^).
最大化对数似然等价于最小化其负数,即交叉熵损失。
2. 梯度推导(矩阵形式)
设设计矩阵 X ∈ R N × D \mathbf{X} \in \mathbb{R}^{N \times D} X∈RN×D,权重 w ∈ R D \mathbf{w} \in \mathbb{R}^D w∈RD,偏置 b ∈ R b \in \mathbb{R} b∈R,预测值 y ^ = σ ( X w + b ) \hat{\mathbf{y}} = \sigma(\mathbf{X}\mathbf{w} + b) y^=σ(Xw+b)。
交叉熵损失:
J ( w , b ) = − 1 N [ y ⊤ log y ^ + ( 1 − y ) ⊤ log ( 1 − y ^ ) ] . J(\mathbf{w}, b) = -\frac{1}{N} \left[ \mathbf{y}^\top \log \hat{\mathbf{y}} + (1 - \mathbf{y})^\top \log (1 - \hat{\mathbf{y}}) \right]. J(w,b)=−N1[y⊤logy^+(1−y)⊤log(1−y^)].
梯度计算:
∂ J ∂ w = 1 N X ⊤ ( y ^ − y ) , \frac{\partial J}{\partial \mathbf{w}} = \frac{1}{N} \mathbf{X}^\top (\hat{\mathbf{y}} - \mathbf{y}), ∂w∂J=N1X⊤(y^−y),
∂ J ∂ b = 1 N ∑ i = 1 N ( y ^ i − y i ) . \frac{\partial J}{\partial b} = \frac{1}{N} \sum_{i=1}^N (\hat{y}_i - y_i). ∂b∂J=N1i=1∑N(y^i−yi).
四、实际应用中的设计原则
- 任务需求匹配:分类任务需概率输出,回归任务用 MSE。
- 优化效率:梯度应稳定且易于计算。
- 概率解释性:损失函数需与概率模型一致(如交叉熵配 sigmoid)。
- 鲁棒性:对异常值的敏感程度(交叉熵比 MSE 更敏感,需数据清洗)。
五、总结
逻辑回归的交叉熵损失函数是通过以下步骤设计的:
- 概率假设:假设数据服从伯努利分布。
- 最大似然估计:将参数估计问题转化为优化问题。
- 数学简化:取负对数似然,得到交叉熵形式。
- 优化验证:选择梯度性质更优的损失函数。
这种设计使得逻辑回归在二分类任务中高效、稳定,且输出具有概率意义,成为基础且强大的模型。
二、PyTorch 代码案例
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification# 生成数据
X, y = make_classification(n_samples=1000, n_features=2, n_redundant=0, n_clusters_per_class=1)
X = torch.tensor(X, dtype=torch.float32)
y = torch.tensor(y, dtype=torch.float32).view(-1, 1)# 定义模型
class LogisticRegression(nn.Module):def __init__(self, input_dim):super().__init__()self.linear = nn.Linear(input_dim, 1)def forward(self, x):return torch.sigmoid(self.linear(x))model = LogisticRegression(2)
criterion = nn.BCELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)# 训练
losses = []
for epoch in range(100):y_pred = model(X)loss = criterion(y_pred, y)loss.backward()optimizer.step()optimizer.zero_grad()losses.append(loss.item())# 可视化损失曲线
plt.plot(losses)
plt.title("Training Loss")
plt.show()# 决策边界可视化
w = model.linear.weight.detach().numpy()[0]
b = model.linear.bias.detach().numpy()x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100), np.linspace(y_min, y_max, 100))
Z = model(torch.tensor(np.c_[xx.ravel(), yy.ravel()], dtype=torch.float32)).detach().numpy()
Z = Z.reshape(xx.shape)plt.contourf(xx, yy, Z, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y.squeeze(), edgecolors='k')
plt.title("Decision Boundary")
plt.show()
三、可视化展示
- 数据分布:二维散点图展示类别分离情况。
- 损失曲线:训练过程中损失值下降曲线。
- 决策边界:等高线图显示模型预测分界线。
四、应用场景与优缺点
-
应用场景:
信用评分、垃圾邮件检测、疾病预测(线性可分问题)。 -
优点:
- 计算高效,适合大规模数据。
- 输出概率解释性强。
-
缺点:
- 无法直接处理非线性关系。
- 对多重共线性敏感。
五、改进方法与数学推导
-
正则化:
- L2正则化:目标函数变为
J reg = J ( w , b ) + λ 2 ∥ w ∥ 2 J_{\text{reg}} = J(\mathbf{w}, b) + \frac{\lambda}{2} \|\mathbf{w}\|^2 Jreg=J(w,b)+2λ∥w∥2
梯度更新:
w ← w − η ( ∇ w J + λ w ) \mathbf{w} \leftarrow \mathbf{w} - \eta \left( \nabla_{\mathbf{w}} J + \lambda \mathbf{w} \right) w←w−η(∇wJ+λw)
- L2正则化:目标函数变为
-
特征工程:
添加多项式特征 x 1 2 , x 2 2 , x 1 x 2 x_1^2, x_2^2, x_1x_2 x12,x22,x1x2等,将数据映射到高维空间。 -
核方法:
通过核技巧隐式映射到高维空间(需结合其他模型如SVM)。
六、总结
逻辑回归通过概率建模解决二分类问题,代码简洁高效,但需注意其线性假设的限制。通过正则化、特征工程等手段可显著提升模型性能。
相关文章:

用deepseek学大模型05逻辑回归
deepseek.com:逻辑回归的目标函数,损失函数,梯度下降 标量和矩阵形式的数学推导,pytorch真实能跑的代码案例以及模型,数据,预测结果的可视化展示, 模型应用场景和优缺点,及如何改进解决及改进方法数据推导。…...

图解循环神经网络(RNN)
目录 1.循环神经网络介绍 2.网络结构 3.结构分类 4.模型工作原理 5.模型工作示例 6.总结 1.循环神经网络介绍 RNN(Recurrent Neural Network,循环神经网络)是一种专门用于处理序列数据的神经网络结构。与传统的神经网络不同,…...

vue文件没有name属性怎么被调用
如果你在 index.vue 文件中定义了一个组件,但没有在组件定义中使用 name 属性,你仍然可以通过几种方式来引用和使用这个组件。 1. 使用局部注册 在父组件中直接导入并注册 index.vue 中的组件(index.vue没有name属性)࿰…...

YOLOv11-ultralytics-8.3.67部分代码阅读笔记-build.py
build.py ultralytics\data\build.py 目录 build.py 1.所需的库和模块 2.class InfiniteDataLoader(dataloader.DataLoader): 3.class _RepeatSampler: 4.def seed_worker(worker_id): 5.def build_yolo_dataset(cfg, img_path, batch, data, mode"train"…...

alt+tab切换导致linux桌面卡死的急救方案
环境 debian12 gnome43.9 解决办法 观察状态栏,其实系统是没有完全死机的,而且gnome也可能没有完全死机。 1. alt f4 关闭桌面上的程序,因为这个方案是我刚刚看到的,所以不确定能不能用,比起重启系统,…...
linux和简单命令)
Spark(2)linux和简单命令
(一)Linux的文件系统 文件系统:操作系统中负责管理和存储文件信息的软件结构称为文件管理系统。 文件系统的结构通常叫做目录树结构,从斜杆/根目录开始; Linux号称万物皆文件,意味着针对Linux的操作,大多…...

如何在Windows下使用Ollama本地部署DeepSeek R1
参考链接: 通过Ollama本地部署DeepSeek R1以及简单使用的教程(超详细) 【DeepSeek应用】DeepSeek R1 本地部署(OllamaDockerOpenWebUI) 如何将 Chatbox 连接到远程 Ollama 服务:逐步指南 首先需要安装oll…...

【Content-Type详解、Postman中binary格式、json格式数据转原始二进制流等】
Content-Type详解、Postman中binary格式、json格式数据转原始二进制流等 背景:postman中如何使用binary格式上传文件 Content-TypeContent-Type的格式由三部分组成:以下是一些常见的Content-Type示例: Postman中 binary格式定义:用…...

spring boot知识点3
1.spring boot能否使用xml配置 可以,但是很繁琐,现在都建议走JavaConfig 2.spring boot的核心配置文件 application.properties application.yml 3.bootstrap.properties和application.properties的区别 b:用于远程配置 a:…...

Dart 3.5语法 28-29
028问号可选类型可空类型保存null空String的isEmpty和NotEmpty ?问号可选类型可空类型保存null叹号强制解包??双冒号运算符String的isEmpty和isNotEmpty ? 问号可选类型,可空类型 可选类型可以保存null,就是空的意思 String.isEmpty 是判断是否是空白字符串,他并不是null…...

利用AFE+MCU构建电池管理系统(BMS)
前言 实际BMS项目中,可能会综合考虑成本、可拓展、通信交互等,用AFE(模拟前端)MCU(微控制器)实现BMS(电池管理系统)。 希望看到这篇博客的朋友能指出错误或提供改进建议。 有纰漏…...

【教学类-89-06】20250220新年篇05——元宵节灯笼
背景需求: 每年元宵、国庆都回带孩子做灯笼。用python对"对折灯笼“的纸模进行不同图案的填充(区分物权) 【教学类-39】A4红纸-国旗灯笼纸模(庆祝中华人民共和国成立74周年)_a4 打印 灯笼-CSDN博客文章浏览阅读1…...

C++ Primer 类的静态成员
欢迎阅读我的 【CPrimer】专栏 专栏简介:本专栏主要面向C初学者,解释C的一些基本概念和基础语言特性,涉及C标准库的用法,面向对象特性,泛型特性高级用法。通过使用标准库中定义的抽象设施,使你更加适应高级…...

【UCB CS 61B SP24】Lecture 4 - Lists 2: SLLists学习笔记
本文内容为重写上一节课中的单链表,将其重构成更易于用户使用的链表,实现多种操作链表的方法。 1. 重构单链表SLList 在上一节课中编写的 IntList 类是裸露递归的形式,在 Java 中一般不会这么定义,因为这样用户可能需要非常了解…...

【科研绘图系列】R语言绘制小提琴图、散点图和韦恩图(violin scatter plot Venn)
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍加载R包数据下载画图1画图2画图3画图4画图5画图6画图7参考介绍 【科研绘图系列】R语言绘制小提琴图、散点图和韦恩图(violin & scatter plot & Venn) 加载R包 library…...

Linux中POSIX应用场景
Linux 提供了丰富的 POSIX(Portable Operating System Interface)标准接口,这些接口可以帮助开发者编写可移植、高效的应用程序。POSIX 标准定义了一系列系统调用和库函数,涵盖了文件操作、进程管理、线程管理、信号处理、同步机制…...
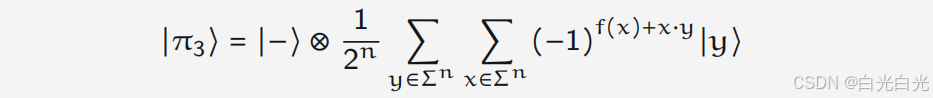
量子算法导论
重学了量子算法,不知道是温故而知新,还是之前的教材没有讲过这个概念。 如果把(图灵机)计算机比作一个查询机器,输入x通过f(x)作用得出结果,而查询的过程就是计算的过程。 中文解释…...

nasm - BasicWindow_64
文章目录 nasm - BasicWindow_64概述笔记my_build.batnasm_main.asmEND nasm - BasicWindow_64 概述 学习网上找到的demo. x64和x86的汇编源码还差挺多的。 x64的汇编代码不好写,细节整不对,程序就不运行。 如果要查为啥不运行,也要看和正向…...

SpringBoot:SSL证书部署+SpringBoot实现HTTPS安全访问
一、前言 SSL协议介于TCP/IP协议栈的第四层(传输层)和第七层(应用层)之间,为基于TCP的应用层协议(如HTTP)提供安全连接。它通过在客户端和服务器之间建立一个加密的通道,确保数据在传…...

selenium爬取苏宁易购平台某产品的评论
目录 selenium的介绍 1、 selenium是什么? 2、selenium的工作原理 3、如何使用selenium? webdriver浏览器驱动设置 关键步骤 代码 运行结果 注意事项 selenium的介绍 1、 selenium是什么? 用于Web应用程序测试的工具。可以驱动浏览…...
)
MCP 2026国产化配置实战:从零搭建符合等保2.0三级+信创名录要求的高可用集群(含OpenEuler 24.03 LTS完整脚本)
更多请点击: https://intelliparadigm.com 第一章:MCP 2026国产化部署概述与合规基线解析 MCP(Mission-Critical Platform)2026 是面向关键信息基础设施的国产化高可靠平台,其部署需严格遵循《信创产品适配目录&#…...

Gemma-4-26B-A4B-it-GGUF惊艳效果:输入Kubernetes Events列表截图→识别频繁事件→关联Pod日志线索
Gemma-4-26B-A4B-it-GGUF惊艳效果:输入Kubernetes Events列表截图→识别频繁事件→关联Pod日志线索 1. 模型能力概览 Gemma-4-26B-A4B-it-GGUF是Google Gemma 4系列中的高性能MoE(混合专家)模型,具备256K tokens的超长上下文处理…...

自洽性与Agent的结合
让智能体学会“自我验证”,提升决策可靠性。随着大语言模型(LLM)从单纯的“对话接口”演进为“行动中枢”,AI Agent(智能体)正逐步突破“被动响应”的局限,向“自主决策、主动执行”的高阶形态演…...
)
从零搭建AI开发环境:手把手教你用Anaconda管理多个PyTorch+CUDA版本(Ubuntu 20.04/22.04实测)
从零搭建AI开发环境:手把手教你用Anaconda管理多个PyTorchCUDA版本(Ubuntu 20.04/22.04实测) 在深度学习项目开发中,不同项目往往需要不同版本的PyTorch和CUDA环境。比如一个项目可能基于PyTorch 1.8和CUDA 10.2开发,…...

大模型这把锤子,能砸破多少芯片工程师的护城河
"大力出奇迹"——这是大模型最让人惊讶的地方。你以为某些任务需要专业积累,需要特定知识,需要领域经验,结果大模型上来就能给出一个像模像样的答案。这种"一力降十会"的感觉,出现的频率将会越来越高。现在很…...

Chrome 0-Day危机:WebGPU时代的首个致命漏洞与全球安全防线崩塌
引言:CVE-2026-5281深度解析与GPU计算时代的浏览器安全重构 2026年4月2日,美国网络安全和基础设施安全局(CISA)发布红色紧急警告,要求所有联邦机构在24小时内完成Google Chrome浏览器的紧急更新。这一不同寻常的指令源…...

非线性光学与虚拟布拉格光栅技术解析
1. 非线性光学基础与虚拟布拉格光栅技术概述非线性光学研究光场与物质相互作用中那些不能用线性关系描述的物理现象。当光强足够高时,介质极化强度P与电场强度E的关系会显现出非线性特征,这种非线性来源于介质中电子在强光场作用下的非简谐运动。二阶非线…...

高效QMC音频解密方案:qmc-decoder完整技术指南与跨平台实践
高效QMC音频解密方案:qmc-decoder完整技术指南与跨平台实践 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 在数字音乐管理领域,QQ音乐QMC加密格式长…...
)
MCP 2026跨服务器编排落地手册(2024Q4唯一兼容RFC-9321的工业级方案)
更多请点击: https://intelliparadigm.com 第一章:MCP 2026跨服务器编排的核心演进与RFC-9321对齐原理 MCP 2026(Multi-Cluster Protocol 2026)标志着分布式系统控制平面从单集群协调迈向全域协同的关键跃迁。其核心演进聚焦于状…...

2026年硕士论文开题报告降AI攻略:研究计划和方法论部分完整处理
2026年硕士论文开题报告降AI攻略:研究计划和方法论部分完整处理 截止日期只剩两天,AI率76%。 翻了论坛、问了学长、试了工具,最后用嘎嘎降AI(www.aigcleaner.com)一次过——4.8元,从76%降到了7%。把这段经…...