Python 爬虫selenium
1.selenium自动化
selenium可以操作浏览器,在浏览器页面上实现:点击、输入、滑动 等操作。
不同于selenium自动化,逆向本质是:
- 分析请求,例如:请求方法、请求参数、加密方式等。
- 用代码模拟请求去实现同等功能。
逆向 vs 自动化Selenium
- Selenium,【优】简单不需要逆向,只需要控制浏览器去执行预设的操作即可;【缺点】性能差,不利于批量实现
- 逆向, 【优】算法逆向出来后,性能好且利于批量实现; 【缺点】语法难搞的js加密算法,不容易逆向
2.必备操作
2.1 模块 & 驱动
-
安装模块
pip install selenium -
下载驱动
Selenium想要控制谷歌、火狐、IE、Edage等浏览器,必须要使用对应的驱动才行。【Selenium】->【驱动】->【浏览器】【Selenium】->【火狐驱动】->【火狐浏览器】【Selenium】->【谷歌驱动】->【谷歌浏览器】谷歌驱动的下载:114及之前版本: http://chromedriver.storage.googleapis.com/index.html117/118/119版本: https://googlechromelabs.github.io/chrome-for-testing/浏览器版本的获取:在谷歌浏览器上访问 chrome://version/ 例如:119.0.6045.200 (正式版本) (64 位) (cohort: Stable) -
快速使用
import time from selenium import webdriver from selenium.webdriver.chrome.service import Serviceservice = Service("driver/chromedriver.exe") driver = webdriver.Chrome(service=service)driver.get('https://passport.bilibili.com/login')time.sleep(5) driver.close()
2.2 寻找标签
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Byservice = Service("driver/chromedriver.exe")
driver = webdriver.Chrome(service=service)driver.get('打开网址')# find_element find_elements
tag = driver.find_element(By.ID, "user")
tag = driver.find_element(By.CLASS_NAME, "c1")
tag = driver.find_element(By.TAG_NAME, "div")
tag = driver.find_element(By.XPATH, "/html/body/div[1]/div/div[2]/div[3]/div[3]/div/div/div/div[1]/span[2]")
tag = driver.find_element(By.XPATH, '//*[@id="geetest-wrap"]//input[@name="tel"]')tag_list = driver.find_elements(By.XPATH, "/html/body/div/div[2]/div/div[2]/div/div[2]/div[2]/div/div/div/div/div[2]/a")
for tag in tag_list:print(tag)time.sleep(5)
driver.close()
示例:5xclass.cn
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Byservice = Service("driver/chromedriver.exe")
driver = webdriver.Chrome(service=service)driver.get('https://www.5xclass.cn/')# 根据ID寻找
tag = driver.find_element(By.ID, "bs-example-navbar-collapse-1")
print(tag.text)
print(10 * "-")# 根据类名寻找
tags = driver.find_elements(By.CLASS_NAME, "panel-heading")
for tag in tags:print(tag.text)
print(10 * "-")# 根据标签名称寻找
tags = driver.find_elements(By.TAG_NAME, "li")
for tag in tags:print(tag.text)
print(10 * "-")# 根据XPATH寻找
tag = driver.find_element(By.XPATH, "/html/body/div/div[2]/div/div[2]/div/div[2]/div[1]")
print(tag.text)
print(10 * "-")# 根据XPATH寻找
tag = driver.find_element(By.XPATH, '//*[@id="bs-example-navbar-collapse-1"]/ul[1]/li[1]/a')
print(tag.text)
print(10 * "-")# 根据XPATH寻找多个
tags = driver.find_elements(By.XPATH, '/html/body/div/div[2]/div/div[2]/div/div[2]/div[2]/div/div/div/div/div[2]/a')
for tag in tags:print(tag.text)
print(10 * "-")# 根据父子关系嵌套寻找
parent = driver.find_element(By.XPATH, '/html/body/div/div[2]/div/div[2]/div/div[2]/div[2]/div/div/div/div')
tags = parent.find_elements(By.XPATH, "div[@class='course']/a")
for tag in tags:print(tag.text)time.sleep(5)
driver.close()
2.3 执行操作
常见的执行操作:点击、输入
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Byservice = Service("driver/chromedriver.exe")
driver = webdriver.Chrome(service=service)driver.get('https://passport.bilibili.com/login')# 1.点击短信登录
time.sleep(3)
sms_btn = driver.find_element(By.XPATH,'//*[@id="app"]/div[2]/div[2]/div[3]/div[1]/div[3]'
)
sms_btn.click() # 点击# 2.输入账号
phone_txt = driver.find_element(By.XPATH,'//*[@id="app"]/div[2]/div[2]/div[3]/div[2]/div[1]/div[1]/input'
)
phone_txt.send_keys("18630087660") # 输入time.sleep(55)
driver.close()
2.4 执行JavaScript
如果【选择标签】【执行操作】这种操作起来比较繁琐,也可以直接在页面上去执行js代码实现功能。
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Byservice = Service("driver/chromedriver.exe")
driver = webdriver.Chrome(service=service)driver.get('https://passport.bilibili.com/login')# ############# 1.点击短信登录 #############
time.sleep(3)
sms_btn = driver.find_element(By.XPATH,'//*[@id="app"]/div[2]/div[2]/div[3]/div[1]/div[3]'
)
sms_btn.click()# ############# 2.输入账号 #############
phone_txt = driver.find_element(By.XPATH,'//*[@id="app"]/div[2]/div[2]/div[3]/div[2]/div[1]/div[1]/input'
)
phone_txt.send_keys("18630087660")# ############# 3.选择国家 #############
time.sleep(2)
driver.execute_script('document.querySelector(".area-code-select").children[18].click()')# ############# 4.读取cookie #############
data_string = driver.execute_script('return document.cookie;') # return document.title;
print(data_string)# ############# 5.读取cookie #############
cookie_list = driver.get_cookies()
print(cookie_list)time.sleep(2550)
driver.close()
2.5 等待
如果页面加载比较慢,需要等待某个元素加载成功后,再执行某些操作。
示例1:基于lambda表达式
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.wait import WebDriverWaitservice = Service("driver/chromedriver.exe")
driver = webdriver.Chrome(service=service)driver.get('https://passport.bilibili.com/login')# ############# 方式1:点击短信登录 #############
time.sleep(3)
sms_btn = driver.find_element(By.XPATH,'//*[@id="app"]/div[2]/div[2]/div[3]/div[1]/div[3]'
)
sms_btn.click()# ############# 方式2:点击短信登录(推荐) #############
sms_btn = WebDriverWait(driver, 30, 0.5).until(lambda dv: dv.find_element(By.XPATH,'//*[@id="app"]/div[2]/div[2]/div[3]/div[1]/div[3]'
))
sms_btn.click()
示例2:自定义函数
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.wait import WebDriverWaitservice = Service("driver/chromedriver.exe")
driver = webdriver.Chrome(service=service)driver.get('https://passport.bilibili.com/login')def func(dv):print("无返回值,则间隔0.5s执行一次此函数;如有返回值,则复制给sms_btn变量")# <div xxx="123" id="uuu"></div># <img src="..."/>tag = dv.find_element(By.XPATH,'//*[@id="app"]/div[2]/div[2]/div[3]/div[1]/div[3]')img_src = tag.get_attribute("xxx")if img_src:return tagreturnsms_btn = WebDriverWait(driver, 30, 0.5).until(func)
sms_btn.click()time.sleep(250)
driver.close()
2.4 执行JavaScript
如果【选择标签】【执行操作】这种操作起来比较繁琐,也可以直接在页面上去执行js代码实现功能。
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Byservice = Service("driver/chromedriver.exe")
driver = webdriver.Chrome(service=service)driver.get('https://passport.bilibili.com/login')# ############# 1.点击短信登录 #############
time.sleep(3)
sms_btn = driver.find_element(By.XPATH,'//*[@id="app"]/div[2]/div[2]/div[3]/div[1]/div[3]'
)
sms_btn.click()# ############# 2.输入账号 #############
phone_txt = driver.find_element(By.XPATH,'//*[@id="app"]/div[2]/div[2]/div[3]/div[2]/div[1]/div[1]/input'
)
phone_txt.send_keys("18630087660")# ############# 3.选择国家 #############
time.sleep(2)
driver.execute_script('document.querySelector(".area-code-select").children[18].click()')# ############# 4.读取cookie #############
data_string = driver.execute_script('return document.cookie;') # return document.title;
print(data_string)# ############# 5.读取cookie #############
cookie_list = driver.get_cookies()
print(cookie_list)time.sleep(2550)
driver.close()
2.5 等待
如果页面加载比较慢,需要等待某个元素加载成功后,再执行某些操作。
示例1:基于lambda表达式
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.wait import WebDriverWaitservice = Service("driver/chromedriver.exe")
driver = webdriver.Chrome(service=service)driver.get('https://passport.bilibili.com/login')# ############# 方式1:点击短信登录 #############
time.sleep(3)
sms_btn = driver.find_element(By.XPATH,'//*[@id="app"]/div[2]/div[2]/div[3]/div[1]/div[3]'
)
sms_btn.click()# ############# 方式2:点击短信登录(推荐) #############
sms_btn = WebDriverWait(driver, 30, 0.5).until(lambda dv: dv.find_element(By.XPATH,'//*[@id="app"]/div[2]/div[2]/div[3]/div[1]/div[3]'
))
sms_btn.click()
示例2:自定义函数
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.wait import WebDriverWaitservice = Service("driver/chromedriver.exe")
driver = webdriver.Chrome(service=service)driver.get('https://passport.bilibili.com/login')def func(dv):print("无返回值,则间隔0.5s执行一次此函数;如有返回值,则复制给sms_btn变量")# <div xxx="123" id="uuu"></div># <img src="..."/>tag = dv.find_element(By.XPATH,'//*[@id="app"]/div[2]/div[2]/div[3]/div[1]/div[3]')img_src = tag.get_attribute("xxx")if img_src:return tagreturnsms_btn = WebDriverWait(driver, 30, 0.5).until(func)
sms_btn.click()time.sleep(250)
driver.close()
示例3:全局配置
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Byservice = Service("driver/chromedriver.exe")
driver = webdriver.Chrome(service=service)# 后续找元素时,没找到时则等待10去寻找(一旦找到则继续)
driver.implicitly_wait(30)driver.get('https://passport.bilibili.com/login')sms_btn = driver.find_element(By.XPATH,# '//*[@id="app"]/div[2]/div[2]/div[3]/div[1]/div[3]''//*[@id="xxxxxxxxxapp"]/div[2]/div[2]/div[3]/div[1]/div[3]'
)
sms_btn.click()
print("找到了")
time.sleep(250)
driver.close()
2.6 获取值
当找到某个标签之后,想要获取标签内部值。
示例1:文本和属性
例如:<a id='x1' class="info mine" href="5xclass.cn">武沛齐</a>
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
service = Service("driver/chromedriver.exe")
driver = webdriver.Chrome(service=service)
driver.implicitly_wait(10)driver.get('https://www.5xclass.cn')tag = driver.find_element(By.XPATH,'/html/body/div/div[2]/div/div[2]/div/div[2]/div[2]/div/div/div/div/div[2]/a[1]'
)
print(tag.text)
print(tag.get_attribute("target"))
print(tag.get_attribute("data-toggle"))driver.close()
示例2:获取值
例如:<input type='text' value="?" placeholder="?" />
例如:<select ><option value='1'>北京</option> </option value='2'>上海</option> </select> ,获取select标签的value属性
import timefrom selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Byservice = Service("driver/chromedriver.exe")
driver = webdriver.Chrome(service=service)
driver.implicitly_wait(10)driver.get('https://www.bilibili.com/')time.sleep(10)tag = driver.find_element(By.XPATH,'//*[@id="nav-searchform"]/div[1]/input'
)
print(tag)
print(tag.text)
print(tag.get_attribute("placeholder"))
print(tag.get_attribute("value"))time.sleep(1000)
driver.close()
示例3:选择相关
<input type="radio" name="findcar" value="1" checked="">新车
<input type="radio" name="findcar" value="2">二手机
import timefrom selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import Byservice = Service("driver/chromedriver.exe")
driver = webdriver.Chrome(service=service)
driver.implicitly_wait(10)driver.get('https://www.autohome.com.cn/beijing/')# ############### 1.单独找到每一个 ###############
tag = driver.find_element(By.XPATH,'/html/body/div[1]/div[11]/div[2]/div[1]/div[1]/label[1]/span/input'
)
print(tag.get_property("checked")) # Truetag = driver.find_element(By.XPATH,'/html/body/div[1]/div[11]/div[2]/div[1]/div[1]/label[2]/span/input'
)
print(tag.get_property("checked")) # False# ############### 2.循环找到每一个 ###############
parent = driver.find_element(By.XPATH,'/html/body/div[1]/div[11]/div[2]/div[1]/div[1]'
)tag_list = parent.find_elements(By.XPATH,'label/span/input'
)
for tag in tag_list:print( tag.get_property("checked"), tag.get_attribute("value") )driver.close()
2.7 源码+bs4
打开页面后,如果基于selenium不太容易定位和寻找,也可以结合bs4来进行寻找。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoupservice = Service("driver/chromedriver.exe")
driver = webdriver.Chrome(service=service)
driver.implicitly_wait(10)driver.get('https://car.yiche.com/')html_string = driver.page_sourcesoup = BeautifulSoup(html_string, features="html.parser")
tag_list = soup.find_all(name="div", attrs={"class": "item-brand"})
for tag in tag_list:child = tag.find(name='div', attrs={"class": "brand-name"})print(child.text)driver.close()
2.8 携带Cookie
driver.add_cookie({'name': 'foo', 'value': 'bar'})
import timefrom selenium import webdriver
from selenium.webdriver.chrome.service import Serviceservice = Service("driver/chromedriver.exe")
driver = webdriver.Chrome(service=service)# 注意:一定要先访问,不然Cookie无法生效
driver.get('https://dig.chouti.com/about')# 加cookie
driver.add_cookie({'name': 'token','value': 'eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJqaWQiOiJjZHVfNDU3OTI2NDUxNTUiLCJleHBpcmUiOiIxNzA0MzI5NDY5OTMyIn0.8n_tWcEHXsBSXWIY9rBoGWwaLPF8iWIruryhKTe5_ks'
})# 再访问
driver.get('https://dig.chouti.com/')time.sleep(2000)
driver.close()
2.9 IP检测和代理
如果网站进行了IP访问限制,例如:每个IP每天只能操作5次。此时可以选择购买IP,然后在请求时添加代理IP即可,具体步骤:
- 购买IP
- 登录购买IP渠道的后台,配置自己IP白名单
- 代码携带代理
import time
import requests
from selenium import webdriver
from selenium.webdriver.chrome.service import Service# 换成自己生成的代理
res = requests.get(url="https://dps.kdlapi.com/api/getdps/?secret_id=o60wwtxvs5ukaqqz18ai&num=1&signature=i6s9shfjfiogat5ijecbyfwwc5grwrzj&pt=1&format=json&sep=1")
proxy_string = res.json()['data']['proxy_list'][0]
print(f"获取代理:{proxy_string}") # "182.106.136.218:40192"service = Service("driver/chromedriver.exe")opt = webdriver.ChromeOptions()
# opt.add_argument(f'--proxy-server=222.89.70.40:40001') # 代理
opt.add_argument(f'--proxy-server={proxy_string}') # 代理
driver = webdriver.Chrome(service=service, options=opt)driver.get('https://myip.ipip.net/')time.sleep(2000)
driver.close()
2.10 特征检测
有些网站为了防止selenium,会检测特征,并禁止访问。
如果想要正常使用selenium访问,那就需要隐藏浏览器相关的特征。
import time
import requests
from selenium import webdriver
from selenium.webdriver.chrome.service import Serviceservice = Service("driver/chromedriver.exe")opt = webdriver.ChromeOptions()opt.add_argument('--disable-infobars')
opt.add_experimental_option("excludeSwitches", ["enable-automation"])
opt.add_experimental_option('useAutomationExtension', False)driver = webdriver.Chrome(service=service, options=opt)# Selenium在打开任何页面之前,先运行这个Js文件。
with open('driver/hide.js') as f:driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": f.read()})driver.get('https://www.5xclass.cn')time.sleep(2000)
driver.close()
2.11 无头和其他
如果不想显示展示在浏览器上的操作,只想偷偷的在后台运行。
opt.add_argument('--headless')
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Serviceservice = Service("driver/chromedriver.exe")
opt = webdriver.ChromeOptions()
opt.add_argument('--headless')
driver = webdriver.Chrome(service=service, options=opt)driver.get('https://www.5xclass.cn')
tag = driver.find_element(By.XPATH,'/html/body/div/div[2]/div/div[2]/div/div[2]/div[2]/div/div/div/div/div[2]/a[1]'
)
print(tag.text)
print(tag.get_attribute("target"))
print(tag.get_attribute("data-toggle"))driver.close()
其他配置:
opt.add_argument('--disable-infobars') # 禁止策略化
opt.add_argument('--no-sandbox') # 解决DevToolsActivePort文件不存在的报错
opt.add_argument('window-size=1920x3000') # 指定浏览器分辨率
opt.add_argument('--disable-gpu') # 谷歌文档提到需要加上这个属性来规避bug
opt.add_argument('--incognito') # 隐身模式(无痕模式)
opt.add_argument('--disable-javascript') # 禁用javascript
opt.add_argument('--start-maximized') # 最大化运行(全屏窗口),不设置,取元素会报错
opt.add_argument('--hide-scrollbars') # 隐藏滚动条, 应对一些特殊页面
opt.add_argument('lang=en_US') # 设置语言
opt.add_argument('blink-settings=imagesEnabled=false') # 不加载图片, 提升速度
opt.add_argument('User-Agent=Mozilla/5.0 (Linux; U; Androi....') # 设置User-Agent
opt.binary_location = r"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" # 手动指定使用的浏览器位置
2.12 截屏
找到某个标签后,可以通过截图的形式保存图片。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Serviceservice = Service("driver/chromedriver.exe")
driver = webdriver.Chrome(service=service)driver.get('https://www.5xclass.cn')
tag = driver.find_element(By.XPATH,'/html/body/div/div[2]/div/div[2]/div/div[2]'
)# 截图&保存
tag.screenshot("demo.png")# 截图&图片内容
body = tag.screenshot_as_png
print(body)# 截图&Base64编码格式图片内容
b64_body = tag.screenshot_as_base64
print(b64_body)driver.close()
3.案例:x东搜索
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service# 换成自己生成的代理
res = requests.get(url="https://dps.kdlapi.com/api/getdps/?secret_id=o60wwtxvs5ukaqqz18ai&num=1&signature=i6s9shfjfiogat5ijecbyfwwc5grwrzj&pt=1&format=json&sep=1")
proxy_string = res.json()['data']['proxy_list'][0]
print(f"获取代理:{proxy_string}")service = Service("driver/chromedriver.exe")
opt = webdriver.ChromeOptions()opt.add_argument(f'--proxy-server={proxy_string}') # 代理
opt.add_argument('blink-settings=imagesEnabled=false') # 不加载图片opt.add_argument('--disable-infobars')
opt.add_experimental_option("excludeSwitches", ["enable-automation"])
opt.add_experimental_option('useAutomationExtension', False)driver = webdriver.Chrome(service=service, options=opt)driver.implicitly_wait(10)with open('driver/hide.js') as f:driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": f.read()})# 1.打开京东
driver.get('https://www.jd.com/')# 2.搜索框+输入
tag = driver.find_element(By.XPATH,'//*[@id="key"]'
)
tag.send_keys("iphone手机")# 3.点击搜索
tag = driver.find_element(By.XPATH,'//*[@id="search"]/div/div[2]/button'
)
tag.click()# 4.查询列表
tag_list = driver.find_elements(By.XPATH,'//*[@id="J_goodsList"]/ul/li'
)
for tag in tag_list:# title = tag.find_element(By.XPATH, 'div/div[@class="p-name p-name-type-2"]//em').texttitle = tag.find_element(By.XPATH, 'div/div[@class="p-name p-name-type-2"]/a/em').textprint(title)driver.close()
4.案例:x麦网
import timeimport requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service# 换成自己生成的代理
res = requests.get(url="https://dps.kdlapi.com/api/getdps/?secret_id=o60wwtxvs5ukaqqz18ai&num=1&signature=i6s9shfjfiogat5ijecbyfwwc5grwrzj&pt=1&format=json&sep=1")
proxy_string = res.json()['data']['proxy_list'][0]
print(f"获取代理:{proxy_string}")service = Service("driver/chromedriver.exe")
opt = webdriver.ChromeOptions()
opt.add_argument(f'--proxy-server={proxy_string}') # 代理
opt.add_argument('blink-settings=imagesEnabled=false')
opt.add_argument('--disable-infobars')
opt.add_experimental_option("excludeSwitches", ["enable-automation"])
opt.add_experimental_option('useAutomationExtension', False)
driver = webdriver.Chrome(service=service, options=opt)
driver.implicitly_wait(10)
with open('driver/hide.js') as f:driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": f.read()})# 1.打开大麦网
driver.get('https://www.damai.cn/')# 2.搜索框+输入
tag = driver.find_element(By.XPATH,'//input[@class="input-search"]'
)
tag.send_keys("周杰伦")# 3.点击搜索
tag = driver.find_element(By.XPATH,'//div[@class="btn-search"]'
)
tag.click()# 4.查询列表
tag_list = driver.find_elements(By.XPATH,'//div[@class="search__itemlist"]//div[@class="items"]'
)
for tag in tag_list:title = tag.find_element(By.XPATH, 'div[@class="items__txt"]/div[1]/a').textprint(title)time.sleep(2000)
driver.close()如果不加代理,访问频繁时会提示验证码
相关文章:

Python 爬虫selenium
1.selenium自动化 selenium可以操作浏览器,在浏览器页面上实现:点击、输入、滑动 等操作。 不同于selenium自动化,逆向本质是: 分析请求,例如:请求方法、请求参数、加密方式等。用代码模拟请求去实现同等…...

为啥vue3设计不直接用toRefs,而是reactive+toRefs
Vue 3 设计中将 reactive 和 toRefs 结合使用而非直接使用 toRefs,主要基于以下设计考量: 1. 响应式粒度的不同需求 reactive 适用于对象整体响应式 reactive 会为整个对象创建响应式代理,自动追踪对象内部所有属性的变化。这种设计适用于需要…...

深入解析 vLLM:高性能 LLM 服务框架的架构之美(二)调度管理
深入解析 vLLM:高性能 LLM 服务框架的架构之美(一)原理与解析 深入解析 vLLM:高性能 LLM 服务框架的架构之美(二)调度管理 1. vLLM 调度器结构与主要组件 在 vLLM 中,调度器的结构设计围绕任务…...

VMware安装教程
一、安装VMware软件 1. 安装前准备 系统要求: 操作系统:Windows 10/11 或 Linux(如Ubuntu、CentOS)。硬件要求: CPU:支持虚拟化技术(Intel VT-x 或 AMD-V),需在BIOS中启…...

iOS事件传递和响应
背景 对于身处中小公司且业务不怎么复杂的程序员来说,很多技术不常用,你可能看过很多遍也都大致了解,但是实际让你讲,不一定讲的清楚。你可能说,我以独当一面,应对自如了,但是技术的知识甚多&a…...

TensorFlow 实现任意风格的快速风格转换
一、什么是风格迁移? 风格迁移(Style Transfer)是一种利用深度学习技术,将一幅图像的内容与另一幅图像的艺术风格相结合,生成新图像的技术。其核心思想是将图像的“内容”和“风格”分离,再重新组合&#…...

火绒终端安全管理系统V2.0【系统防御功能】
火绒企业版V2.0系统防御功能包含系统加固、应用加固、软件安装拦截、摄像头保护和浏览器保护。火绒终端安全管理软件V2.0守护企业用户终端安全。 系统防御 1. 系统加固 系统加固功能根据火绒提供的安全加固策略,当程序对特定系统资源操作时提醒用户可能存在的安…...

全志A133 android10 适配SLM770A 4G模块
一,模块基本信息 1.官方介绍 SLM770A是美格智能最新推出的一款LTE Cat.4无线通讯模组,最大支持下行速率150Mbps及上行速率50Mbps。同时向下兼容现有的3G和2G网络,以确保即使在偏远地区也可以进行网络通信。 SLM770A模组支持分集接收和MIMO技…...

第3章 3.2 配置系统 .NET Core配置系统
3.2.1 配置系统的基本使用 .NET Core中的配置系统支持非常丰富的配置源,包括文件(JSON、XML、INI等)、注册表、环境变量、命令行、Azure Key Vault等,配置系统还支持自定义配置源。 用配置系统开发包Microsoft.Extensions.Confi…...

装修流程图: 装修前准备 → 设计阶段 → 施工阶段 → 安装阶段 → 收尾阶段 → 入住
文章目录 引言I 毛坯房装修的全流程**1. 装修前准备****1.1 确定装修预算****1.2 选择装修方式****1.3 选择装修公司****1.4 办理装修手续****2. 设计阶段****2.1 量房****2.2 设计方案****2.3 确认方案****3. 施工阶段****3.1 主体拆改****3.2 水电改造****3.3 防水工程****3.…...

Python----数据结构(单链表:节点,是否为空,长度,遍历,添加,删除,查找)
一、链表 链表是一种线性数据结构,由一系列按特定顺序排列的节点组成,这些节点通过指针相互连接。每个节点包含两部分:元素和指向下一个节点的指针。其中,最简单的形式是单向链表,每个节点含有一个信息域和一个指针域&…...

NLP-RNN-LSTM浅析
双向 LSTM(Bi - LSTM) 结构原理:从图片中可以看到,双向 LSTM 由两个方向相反的 LSTM 组成,一个是正向 LSTM(forward),一个是反向 LSTM(backward)。正向 LSTM …...
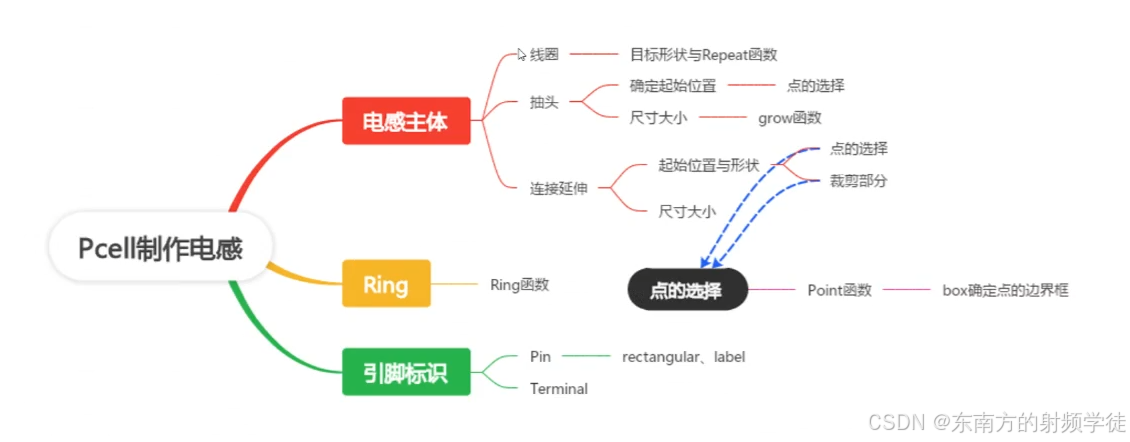
【Cadence射频仿真学习笔记】Pcell Designer设计电感学习笔记
Cadence的Pcell designer官方入门教程 一、下载Pcell Designer 首先,前往Cadence网站下载Pcell Designer软件 (具体安装过程就不记录了,大家自己去看视频吧) 二、创建新的P-cell 然后打开Virtuoso,点击Tools->…...

臻识相机,华夏相机,芊熠车牌识别相机加密解密
臻识,华夏,芊熠这三种车牌识别相机解密我都试过了,可以正常解密成功,其它品牌我暂时没有测试。超级简单,免费的,白嫖无敌! 流程: ①:先导出配置文件,例如我以…...

一个前端,如何同时联调多个后端
文章目录 场景解决方案思路实现步骤创建项目目标前端配置安装cross-env配置vue.config.js配置package.json 测试 场景 一个前端,需要同时和N个后端联调 一个需求里有若干个模块,分别给不同的后端开发,前端需要和N个后端联调 本地开启一个端…...

向量的点乘的几何意义
源自AI 向量的点乘(Dot Product)在几何和图形学中有重要的意义。它不仅是数学运算,还可以用来描述向量之间的关系。以下是点乘的几何意义及其应用: 1. 点乘的定义 对于两个向量 a 和 b,它们的点乘定义为:…...

如何组织和管理JavaScript文件:最佳实践与策略
在现代Web开发中,JavaScript已经成为不可或缺的一部分。随着项目规模的扩大,JavaScript代码的复杂性也随之增加。如何有效地组织和管理这些文件,不仅影响开发效率,还直接关系到项目的可维护性和可扩展性。本文将深入探讨如何组织和…...

mysql实时同步到es
测试了多个方案同步,最终选择oceanu产品,底层基于Flink cdc 1、实时性能够保证,binlog量很大时也不产生延迟 2、配置SQL即可完成,操作上简单 下面示例mysql的100张分表实时同步到es,优化备注等文本字段的like查询 创…...

DeepSeek动画视频全攻略:从架构到本地部署
DeepSeek 本身并不直接生成动画视频,而是通过与一系列先进的 AI 工具和传统软件协作,完成动画视频的制作任务。这一独特的架构模式,使得 DeepSeek 在动画视频创作领域发挥着不可或缺的辅助作用。其核心流程主要包括脚本生成、画面设计、视频合成与后期处理这几个关键环节。 …...

第3章 3.3日志 .NET Core日志 NLog使用教程
3.3.1 .NET Core日志基本使用 书中介绍了把日志输出到控制台的使用方式: 安装 Microsoft.Extensions.Logging 和 Microsoft.Extensions.Logging.Console 日志记录代码: using Microsoft.Extensions.DependencyInjection; using Microsoft.Extensions.…...

极致轻松:5分钟掌握开源手绘白板的完整创作体验
极致轻松:5分钟掌握开源手绘白板的完整创作体验 【免费下载链接】excalidraw Virtual whiteboard for sketching hand-drawn like diagrams 项目地址: https://gitcode.com/GitHub_Trending/ex/excalidraw 你是否曾为寻找一个既美观又实用的绘图工具而烦恼&a…...

SEER‘S EYE预言家之眼创意工坊:用户自定义规则与场景的模组开发教程
SEERS EYE预言家之眼创意工坊:用户自定义规则与场景的模组开发教程 你是不是觉得,现在那些AI狼人杀或者社交推理游戏,来来去去就那么几个板子,玩久了有点腻?或者你脑子里有个特别酷的剧本杀设定,但找不到合…...

游戏加速新体验:OpenSpeedy带你打破帧率束缚
游戏加速新体验:OpenSpeedy带你打破帧率束缚 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否曾为游戏中的卡顿而烦恼?或是希望在单机游戏中体验…...

2025届学术党必备的降重复率方案解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 当下学术环境之中,AI论文网站身为辅助研究的工具,主要具备文献检索、…...

告别手动复制!OpenDataLab MinerU智能文档理解快速提取PDF文字
告别手动复制!OpenDataLab MinerU智能文档理解快速提取PDF文字 1. 为什么需要智能文档理解? 在日常办公和学术研究中,PDF文档是最常见的文件格式之一。然而,从PDF中提取文字和结构化数据一直是个令人头疼的问题。传统方法通常面…...

RWKV7-1.5B-World的Java后端集成指南:SpringBoot API服务开发
RWKV7-1.5B-World的Java后端集成指南:SpringBoot API服务开发 1. 前言:为什么选择RWKV7-1.5B-World RWKV7-1.5B-World作为新一代开源大语言模型,以其高效的推理性能和适中的模型尺寸,成为企业级应用的热门选择。对于Java开发者而…...

告别混乱!用MD04/MD07/ZMD06看懂SAP物料可用性,采购与生产计划不再抓瞎
SAP物料可用性实战指南:从MD04到ZMD06的高效决策路径 每天清晨,当供应链计划员、采购专员和生产调度员打开SAP系统时,面对MD04事务码中密密麻麻的物料需求数据,最迫切需要解答的三个问题是:哪些物料会短缺?…...

Fedora启动盘制作终极指南:Media Writer三步搞定系统安装
Fedora启动盘制作终极指南:Media Writer三步搞定系统安装 【免费下载链接】MediaWriter Fedora Media Writer - Write Fedora Images to Portable Media 项目地址: https://gitcode.com/gh_mirrors/me/MediaWriter Fedora Media Writer是一款跨平台的Fedora启…...

C++26反射不是“玩具”!金融高频交易系统中毫秒级Schema热更新实现全链路源码分析
更多请点击: https://intelliparadigm.com 第一章:C26反射不是“玩具”!金融高频交易系统中毫秒级Schema热更新实现全链路源码分析 C26 核心反射(Core Reflection)提案(P2996R3)已进入草案冻结…...

打破语言壁垒:XUnity.AutoTranslator让全球游戏无障碍畅玩
打破语言壁垒:XUnity.AutoTranslator让全球游戏无障碍畅玩 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 你是否曾因语言障碍而错过精彩的游戏剧情?XUnity.AutoTranslator作为一款…...