《机器学习实战》专栏 No12:项目实战—端到端的机器学习项目Kaggle糖尿病预测
《机器学习实战》专栏 第12集:项目实战——端到端的机器学习项目Kaggle糖尿病预测
本集为专栏最后一集,本专栏的特点是短平快,聚焦重点,不长篇大论纠缠于理论,而是在介绍基础理论框架基础上,快速切入实战项目和代码,所有代码都经过实践检验,是读者入门和熟悉上手的上佳知识材料
在本集中,我们将通过 Kaggle 平台的经典糖尿病预测(Pima Indians Diabetes Dataset)数据集,系统回顾完整的机器学习流程。本文将涵盖以下内容:
- 项目背景与目标
- 数据收集与加载
- 数据清洗与探索性数据分析 (EDA)
- 特征工程与数据预处理
- 模型选择与训练
- 模型评估与优化
- 模型部署与监控
- 总结与展望
本文将提供完整代码,并附有详细注释和图表,帮助你掌握从零开始构建一个端到端的机器学习项目的全过程。所有代码在基于python 3.9.5 版本上运行通过。
一、项目背景与目标
背景
糖尿病是一种常见的慢性疾病,早期预测可以帮助医生采取预防措施。Pima Indians Diabetes 数据集是一个经典案例,用于预测患者是否患有糖尿病。该数据集包含多个医学指标(如血糖水平、BMI 等)以及目标变量(是否患有糖尿病)。
目标
我们的目标是构建一个分类模型,根据患者的医学指标预测其是否患有糖尿病。具体任务包括:
- 数据清洗与探索
- 特征工程与模型训练
- 模型评估与优化
- 部署模型并监控性能
二、数据收集与加载
首先,我们需要从 Kaggle 下载数据集并加载到 Python 环境中。
import pandas as pd# 加载数据集
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv"
column_names = ['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome'
]
data = pd.read_csv(url, names=column_names)# 查看数据集前几行
print(data.head())
输出:
Pregnancies Glucose BloodPressure SkinThickness Insulin BMI \
0 6 148 72 35 0 33.6
1 1 85 66 29 0 26.6
2 8 183 64 0 0 23.3
3 1 89 66 23 94 28.1
4 0 137 40 35 168 43.1 DiabetesPedigreeFunction Age Outcome
0 0.627 50 1
1 0.351 31 0
2 0.672 32 1
3 0.167 21 0
4 2.288 33 1
# 查看数据集的统计信息
print(data.describe())
输出:
Pregnancies Glucose BloodPressure SkinThickness Insulin \
count 768.000000 768.000000 768.000000 768.000000 768.000000
mean 3.845052 120.894531 69.105469 20.536458 79.799479
std 3.369578 31.972618 19.355807 15.952218 115.244002
min 0.000000 0.000000 0.000000 0.000000 0.000000
25% 1.000000 99.000000 62.000000 0.000000 0.000000
50% 3.000000 117.000000 72.000000 23.000000 30.500000
75% 6.000000 140.250000 80.000000 32.000000 127.250000
max 17.000000 199.000000 122.000000 99.000000 846.000000 BMI DiabetesPedigreeFunction Age Outcome
count 768.000000 768.000000 768.000000 768.000000
mean 31.992578 0.471876 33.240885 0.348958
std 7.884160 0.331329 11.760232 0.476951
min 0.000000 0.078000 21.000000 0.000000
25% 27.300000 0.243750 24.000000 0.000000
50% 32.000000 0.372500 29.000000 0.000000
75% 36.600000 0.626250 41.000000 1.000000
max 67.100000 2.420000 81.000000 1.000000
三、数据清洗与探索性数据分析 (EDA)
数据清洗
检查数据集中是否存在缺失值或异常值。
# 检查缺失值
print(data.isnull().sum())
输出(该数据集比较完整,没有缺失值):
Pregnancies 0
Glucose 0
BloodPressure 0
SkinThickness 0
Insulin 0
BMI 0
DiabetesPedigreeFunction 0
Age 0
Outcome 0
dtype: int64
# 检查异常值(例如,Glucose、BMI 等不应为 0)
abnormal_columns = ['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI']
for col in abnormal_columns:print(f"{col} 中的异常值数量: {len(data[data[col] == 0])}")
输出:
Glucose 中的异常值数量: 5
BloodPressure 中的异常值数量: 35
SkinThickness 中的异常值数量: 227
Insulin 中的异常值数量: 374
BMI 中的异常值数量: 11
数据分布可视化
使用 Matplotlib 和 Seaborn 可视化数据分布。
import matplotlib.pyplot as plt
import seaborn as sns# 目标变量分布
sns.countplot(x='Outcome', data=data)
plt.title("Outcome Distribution")
plt.show()

# 数值特征分布
data.hist(figsize=(12, 10))
plt.tight_layout()
plt.show()

图表说明:
- 上图,目标变量
Outcome的分布显示正负样本比例不均衡。 - 下图,各数值特征的分布呈现不同的偏态。
四、特征工程与数据预处理
处理异常值
用中位数填充异常值(如 Glucose、BMI 等为 0 的情况)。
for col in abnormal_columns:median_value = data[col].median()data[col] = data[col].replace(0, median_value)
标准化数值特征
对数值特征进行标准化处理。
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()
scaled_features = scaler.fit_transform(data.drop('Outcome', axis=1))
X = pd.DataFrame(scaled_features, columns=data.columns[:-1])
y = data['Outcome']
划分训练集与测试集
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
五、模型选择与训练
我们尝试多种分类算法,包括逻辑回归、随机森林和支持向量机。
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report# 定义模型
models = {"Logistic Regression 逻辑回顾模型": LogisticRegression(),"Random Forest 随机森林模型": RandomForestClassifier(random_state=42),"Support Vector Machine 支持向量机模型": SVC(probability=True)
}# 训练与评估
for name, model in models.items():model.fit(X_train, y_train)y_pred = model.predict(X_test)print(f"Model: {name}")print(f"Accuracy: {accuracy_score(y_test, y_pred):.4f}")print(classification_report(y_test, y_pred))
输出:
Model: Logistic Regression 逻辑回顾模型
Accuracy: 0.7078precision recall f1-score support0 0.75 0.82 0.78 1001 0.60 0.50 0.55 54accuracy 0.71 154macro avg 0.68 0.66 0.67 154
weighted avg 0.70 0.71 0.70 154Model: Random Forest 随机森林模型
Accuracy: 0.7597precision recall f1-score support0 0.79 0.85 0.82 1001 0.68 0.59 0.63 54accuracy 0.76 154macro avg 0.74 0.72 0.73 154
weighted avg 0.75 0.76 0.76 154Model: Support Vector Machine 支持向量机模型
Accuracy: 0.7273precision recall f1-score support0 0.76 0.84 0.80 1001 0.64 0.52 0.57 54accuracy 0.73 154macro avg 0.70 0.68 0.69 154
weighted avg 0.72 0.73 0.72 154
**可以发现三种模型的各项指标包括准确率差不多,随机森林模型稍微好一点点。
六、模型评估与优化
超参数调优
使用网格搜索优化随机森林模型。
from sklearn.model_selection import GridSearchCVparam_grid = {'n_estimators': [50, 100, 200],'max_depth': [None, 10, 20],'min_samples_split': [2, 5, 10]
}grid_search = GridSearchCV(RandomForestClassifier(random_state=42), param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)print("Best Parameters:", grid_search.best_params_)
print("Best Accuracy:", grid_search.best_score_)
输出:
Best Parameters: {'max_depth': 10, 'min_samples_split': 2, 'n_estimators': 100}
Best Accuracy: 0.7752632280421164
七、模型部署与监控
保存模型
使用 joblib 保存训练好的模型。
import joblibbest_model = grid_search.best_estimator_
joblib.dump(best_model, "diabetes_model.pkl")
输出:
['diabetes_model.pkl']
加载模型并预测
loaded_model = joblib.load("diabetes_model.pkl")
new_data = [[6, 148, 72, 35, 0, 33.6, 0.627, 50]] # 示例输入
prediction = loaded_model.predict(new_data)
print("Prediction:", prediction)
输出:
Prediction: [1]
可见模型非常准确的预测出了结果。
监控模型性能
定期重新训练模型,并使用 A/B 测试验证新模型的效果。
八、总结与展望
通过本项目,我们完成了一个端到端的机器学习流程,包括数据清洗、特征工程、模型训练与优化、部署与监控。以下是几点建议:
- 关注数据质量:数据清洗是成功的关键。
- 尝试多种模型:不要局限于单一算法。
- 持续监控模型:生产环境中模型性能可能随时间变化。
希望这篇文章对你有所帮助!如果你有任何问题或想法,欢迎在评论区留言讨论。

下个专栏预告 12集机器学习实战到此就结束了,下个专栏我们将聚焦于深度学习进阶,帮助读者从深度学习的基础知识逐步进阶到前沿技术,涵盖理论、实战和行业应用。每集聚焦一个核心知识点,并结合实际项目进行实践,确保内容既深入又实用。同时,我们将探讨与当下最流行的大模型(如 GPT、BERT、Diffusion Models 等)相关的技术和知识点。
《深度学习进阶》系列博文大纲
第1集:深度学习基础回顾与框架选择
- 知识点:
- 深度学习的基本概念:神经网络、激活函数、损失函数、优化器。
- 常见深度学习框架对比:TensorFlow vs PyTorch。
- GPU 加速与分布式训练简介。
- 实战项目:
- 使用 TensorFlow 和 PyTorch 构建简单的全连接神经网络,解决 MNIST 手写数字分类问题。
- 图示:
- 神经网络结构图、MNIST 数据集样例。
- 前沿关联:
- 引入大模型的背景:为什么需要更深、更复杂的网络?
第2集:卷积神经网络(CNN)与图像分类
- 知识点:
- 卷积层、池化层、批归一化的作用与原理。
- 经典 CNN 架构:LeNet、AlexNet、VGG、ResNet。
- 实战项目:
- 使用 ResNet 实现 CIFAR-10 图像分类任务。
- 图示:
- CNN 结构图、特征图可视化。
- 前沿关联:
- 大模型中的视觉架构(如 Vision Transformer, ViT)。
第3集:循环神经网络(RNN)与序列建模
- 知识点:
- RNN 的基本原理与局限性。
- LSTM 和 GRU 的改进。
- 序列建模的应用场景:语言建模、时间序列预测。
- 实战项目:
- 使用 LSTM 预测股票价格趋势。
- 图示:
- RNN 展开图、LSTM 单元结构。
- 前沿关联:
- Transformer 在序列建模中的崛起。
第4集:Transformer 架构与自然语言处理(NLP)
- 知识点:
- 自注意力机制(Self-Attention)与多头注意力。
- Transformer 的编码器-解码器结构。
- BERT、GPT 等预训练模型的原理与应用。
- 实战项目:
- 使用 Hugging Face Transformers 库微调 BERT 模型,完成情感分析任务。
- 图示:
- Transformer 架构图、注意力权重热力图。
- 前沿关联:
- 探讨 GPT-4 和 PaLM 等超大规模语言模型的能力与挑战。
第5集:生成对抗网络(GAN)与图像生成
- 知识点:
- GAN 的基本原理:生成器与判别器的对抗过程。
- 改进版 GAN:DCGAN、CycleGAN、StyleGAN。
- 实战项目:
- 使用 DCGAN 生成手写数字图像。
- 图示:
- GAN 训练流程图、生成图像样本。
- 前沿关联:
- Diffusion Models 的兴起及其在图像生成中的优势。
第6集:扩散模型(Diffusion Models)与高质量图像生成
- 知识点:
- 扩散模型的核心思想:去噪过程与逆向生成。
- DDPM(Denoising Diffusion Probabilistic Models)与改进版本。
- 实战项目:
- 使用预训练的 Stable Diffusion 模型生成艺术图像。
- 图示:
- 扩散模型的训练与推理流程图、生成结果对比。
- 前沿关联:
- 探讨 MidJourney 和 DALL·E 的背后技术。
第7集:强化学习(RL)与决策系统
- 知识点:
- 强化学习的基本概念:状态、动作、奖励。
- Q-Learning 与深度 Q 网络(DQN)。
- 近端策略优化(PPO)与 Actor-Critic 方法。
- 实战项目:
- 使用 DQN 玩 Atari 游戏(如 Breakout)。
- 图示:
- 强化学习框架图、游戏画面截图。
- 前沿关联:
- AlphaGo 和 ChatGPT 中的强化学习应用。
第8集:多模态学习与跨领域融合
- 知识点:
- 多模态数据的特点与挑战。
- 跨模态模型:CLIP、DALL·E、Flamingo。
- 实战项目:
- 使用 CLIP 模型实现文本到图像的检索。
- 图示:
- 多模态模型架构图、检索结果展示。
- 前沿关联:
- 探讨多模态大模型(如 GPT-4 Vision)的应用潜力。
第9集:自监督学习与无监督学习
- 知识点:
- 自监督学习的核心思想:通过构造伪标签进行预训练。
- SimCLR、BYOL、MAE 等代表性方法。
- 实战项目:
- 使用 SimCLR 对 CIFAR-10 数据集进行无监督特征提取。
- 图示:
- 自监督学习框架图、特征空间可视化。
- 前沿关联:
- 自监督学习在大模型预训练中的广泛应用。
第10集:联邦学习与隐私保护
- 知识点:
- 联邦学习的基本原理:分布式训练与隐私保护。
- 差分隐私与同态加密。
- 实战项目:
- 使用 TensorFlow Federated 实现简单的联邦学习实验。
- 图示:
- 联邦学习架构图、训练过程示意图。
- 前沿关联:
- 探讨大模型在隐私保护方面的挑战与解决方案。
第11集:模型压缩与加速
- 知识点:
- 模型压缩技术:剪枝、量化、知识蒸馏。
- TensorRT 和 ONNX 在模型部署中的应用。
- 实战项目:
- 使用知识蒸馏将 BERT 模型压缩为 DistilBERT。
- 图示:
- 模型压缩流程图、性能对比图表。
- 前沿关联:
- 探讨大模型的高效推理技术(如稀疏化、动态计算)。
第12集:大模型的未来与行业应用
- 知识点:
- 大模型的发展趋势:规模增长、多模态融合、通用人工智能(AGI)。
- 大模型在医疗、金融、教育等领域的应用案例。
- 实战项目:
- 使用开源大模型(如 LLaMA 或 Bloom)构建一个问答系统。
- 图示:
- 大模型发展历程图、行业应用场景图。
- 前沿关联:
- 探讨 AGI 的可能性与伦理挑战。
相关文章:
《机器学习实战》专栏 No12:项目实战—端到端的机器学习项目Kaggle糖尿病预测
《机器学习实战》专栏 第12集:项目实战——端到端的机器学习项目Kaggle糖尿病预测 本集为专栏最后一集,本专栏的特点是短平快,聚焦重点,不长篇大论纠缠于理论,而是在介绍基础理论框架基础上,快速切入实战项…...

【vue项目中如何实现一段文字跑马灯效果】
在Vue项目中实现一段文字跑马灯效果,可以通过多种方式实现,以下是几种常见的方法: 方法一:使用CSS动画和Vue数据绑定 这种方法通过CSS动画实现文字的滚动效果,并结合Vue的数据绑定动态更新文本内容。 步骤ÿ…...
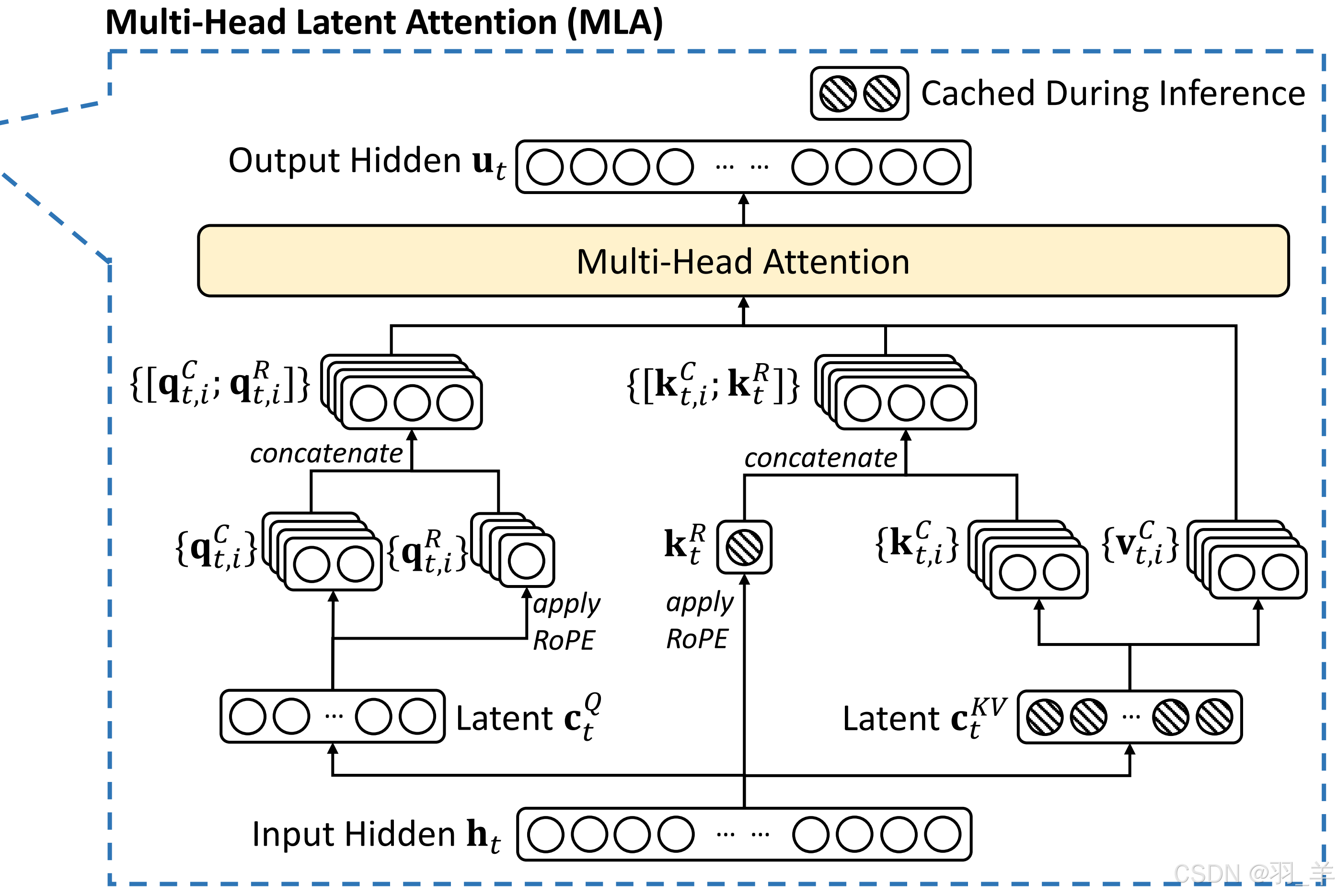
DeepSeek 细节之 MLA (Multi-head Latent Attention)
DeepSeek 系统模型的基本架构仍然基于Transformer框架,为了实现高效推理和经济高效的训练,DeepSeek 还采用了MLA(多头潜在注意力)。 MHA(多头注意力)通过多个注意力头并行工作捕捉序列特征,但面临高计算成本…...

Python爬虫具体是如何解析商品信息的?
在使用Python爬虫解析亚马逊商品信息时,通常会结合requests库和BeautifulSoup库来实现。requests用于发送HTTP请求并获取网页内容,而BeautifulSoup则用于解析HTML页面并提取所需数据。以下是具体的解析过程,以按关键字搜索亚马逊商品为例。 …...

lerobot调试记录
这里写自定义目录标题 libtiff.so undefined symbol libtiff.so undefined symbol anaconda3/envs/lerobot3/lib/python3.10/site-packages/../.././libtiff.so.6: undefined symbol: jpeg12_write_raw_data, version LIBJPEG_8.01.安装库 conda install -c conda-forge jpeg …...

【Word转PDF】在线Doc/Docx转换为PDF格式 免费在线转换 功能强大好用
在日常办公和学习中,将Word文档转换为PDF格式的需求非常普遍。无论是制作简历、撰写报告还是分享文件,都需要确保文档格式在不同设备上保持一致。而小白工具的“Word转PDF”功能正是为此需求量身打造的一款高效解决方案。 【Word转PDF】在线Doc/Docx转换…...

Jenkins 配置 Credentials 凭证
Jenkins 配置 Credentials 凭证 一、创建凭证 Dashboard -> Manage Jenkins -> Manage Credentials 在 Domain 列随便点击一个 (global) 二、添加 凭证 点击左侧 Add Credentials 四、填写凭证 Kind:凭证类型 Username with password: 配置 用…...

Datawhale Ollama教程笔记5
Dify 接入 Ollama 部署的本地模型 Dify 支持接入 Ollama 部署的大型语言模型推理和 embedding 能力。 快速接入 下载 Ollama 访问 Ollama 安装与配置,查看 Ollama 本地部署教程。 运行 Ollama 并与 Llama 聊天 ollama run llama3.1Copy to clipboardErrorCopied …...

小爱音箱连接电脑外放之后,浏览器网页视频暂停播放后,音箱整体没声音问题解决
背景 22年买的小爱音箱增强版play,小爱音箱连接电脑外放之后,浏览器网页视频暂停播放后,音箱整体没声音(一边打着游戏,一边听歌,一边放视频,视频一暂停,什么声音都没了,…...

go设置镜像代理
前言 在 Go 开发中,如果直接从官方源(https://proxy.golang.org)下载依赖包速度较慢,可以通过设置 镜像代理 来加速依赖包的下载。以下是增加 Go 镜像代理的详细方法: 一、设置 Go 镜像代理 1. 使用环境变量设置代理…...

Python爬虫系列教程之第十二篇:爬虫异常处理与日志记录
大家好,欢迎继续关注本系列爬虫教程!在实际的爬虫项目中,网络请求可能会因为各种原因失败,如连接超时、目标服务器拒绝访问、解析错误等。此外,大规模爬虫任务运行过程中,各种异常情况层出不穷,…...

将Google文档导入WordPress:简单实用的几种方法
Google文档是内容创作者非常实用的写作工具。它支持在线编辑、多人协作,并能够自动保存内容。但当我们想把Google文档中的内容导入WordPress网站时,可能会遇到一些小麻烦,比如格式错乱、图片丢失等问题。本文将为大家介绍几种简单实用的方法&…...

大白话实战Gateway
网关功能 网关在分布式系统中起了什么作用?参考下图: 前端想要访问业务访问,就需要知道各个访问的地址,而业务集群服务有很多,前端需要记录非常多的服务器地址,这种情况下,我们需要对整个业务集群做一个整体屏蔽,这个时候就引入Gateway网关,它就是所有服务的请求入…...

深入学习解析:183页可编辑PPT华为市场营销MPR+LTC流程规划方案
华为终端正面临销售模式转型的关键时刻,旨在通过构建MPRLTC项目,以规避对运营商定制的过度依赖,并探索新的增长路径。项目核心在于建设一套全新的销售流程与IT系统,支撑双品牌及自有品牌的战略发展。 项目总体方案聚焦于四大关键议…...

【微中子代理踩坑-前端node-sass安装失败】
微中子代理踩坑-前端node-sass安装失败-windows 1.npm版本2.python2.73.安装Visual Studio 1.npm版本 当前使用node版本13.12.0 2.python2.7 安装python2.7.9并配置环境变量 3.安装Visual Studio 安装Visual Studio 我是直接勾选了3个windows的sdk,然后就好了 最后 npm in…...

使用open-webui+deepseek构建本地AI知识库
序 本文主要研究一下如何使用OpenWebUIdeepseek构建本地AI知识库 步骤 拉取open-webui镜像 docker pull ghcr.io/open-webui/open-webui:maindocker启动 docker run -d -p 3000:8080 \ -e OLLAMA_BASE_URLhttp://host.docker.internal:11434 \ ghcr.io/open-webui/open-we…...

CSS盒模
CSS盒模型就像一个快递包裹,网页上的每个元素都可以看成是这样一个包裹,它主要由以下几个部分组成: 内容(content):就像包裹里真正装的东西,比如文字、图片等。在CSS里,可用width&a…...

【开源向量数据库】Milvus简介
Milvus 是一个开源、高性能、可扩展的向量数据库,专门用于存储和检索高维向量数据。它支持近似最近邻搜索(ANN),适用于图像检索、自然语言处理(NLP)、推荐系统、异常检测等 AI 应用场景。 官网:…...

机器学习笔记——常用损失函数
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本笔记介绍机器学习中常见的损失函数和代价函数,各函数的使用场景。 热门专栏 机器学习 机器学习笔记合集 深度学习 深度学习笔记合集 文章目录 热门…...

Nginx--日志(介绍、配置、日志轮转)
前言:本博客仅作记录学习使用,部分图片出自网络,如有侵犯您的权益,请联系删除 一、Nginx日志介绍 nginx 有一个非常灵活的日志记录模式,每个级别的配置可以有各自独立的访问日志, 所需日志模块 ngx_http_log_module 的…...

解决Blender到Unity FBX转换的终极指南:告别模型旋转错乱
解决Blender到Unity FBX转换的终极指南:告别模型旋转错乱 【免费下载链接】blender-to-unity-fbx-exporter FBX exporter addon for Blender compatible with Unitys coordinate and scaling system. 项目地址: https://gitcode.com/gh_mirrors/bl/blender-to-uni…...

novelWriter:专为小说创作而生的开源写作神器
novelWriter:专为小说创作而生的开源写作神器 【免费下载链接】novelWriter novelWriter is an open source plain text editor designed for writing novels. 项目地址: https://gitcode.com/gh_mirrors/no/novelWriter 如果你正在寻找一款专注于小说创作的…...

Ubuntu 22.04 系统上完整安装 ROS 2 Humble
第一步:确保系统支持 UTF-8 编码sudo apt update && sudo apt install locales sudo locale-gen en_US en_US.UTF-8 sudo update-locale LC_ALLen_US.UTF-8 LANGen_US.UTF-8 export LANGen_US.UTF-8第二步:添加 ROS 2 软件源# 安装 curl sudo ap…...

Nginx反向代理SSE请求,为什么你的实时推送总断线?这3个配置项是关键
Nginx反向代理SSE请求:根治断线问题的3个关键配置实战 当你在金融交易系统或物联网监控平台中部署SSE实时推送时,是否经常遇到这样的场景:仪表盘数据突然停止更新,客户端不断重连,而Nginx错误日志里满是upstream timed…...

5分钟掌握Path of Building:流放之路最强离线Build规划终极指南
5分钟掌握Path of Building:流放之路最强离线Build规划终极指南 【免费下载链接】PathOfBuilding Offline build planner for Path of Exile. 项目地址: https://gitcode.com/GitHub_Trending/pa/PathOfBuilding 还在为《流放之路》复杂的Build规划而烦恼吗&…...
时,除了提供散热要求还需提供什么资料?)
设计制作芯片测试座(老化座)时,除了提供散热要求还需提供什么资料?
芯片测试是确保产品质量与可靠性的最后一道关键防线。而作为连接芯片与测试设备的桥梁,测试座(Socket)的性能直接决定了测试的准确性、效率与成本。许多工程师在定制或选购测试座时,往往只关注散热要求,却忽略了其他同…...

黑芝麻智能C1200汽车SoC:跨域计算与异构架构解析
1. 黑芝麻智能Wudang C1200系列汽车SoC概述在Linux 6.19内核更新日志中,我注意到两款引人注目的汽车级SoC:瑞萨电子的R-Car X5H(16/32核Cortex-A720AE)和黑芝麻智能的Wudang C1200系列(8/10核Cortex-A78AE)…...

MATLAB翼型分析终极指南:用XFOILinterface快速完成气动性能计算
MATLAB翼型分析终极指南:用XFOILinterface快速完成气动性能计算 【免费下载链接】XFOILinterface 项目地址: https://gitcode.com/gh_mirrors/xf/XFOILinterface 在航空航天工程和流体力学研究中,翼型气动性能分析是一个基础而关键的任务。传统上…...
)
别再用FR4不行了!实测12G-SDI在普通PCB板材上的完整布线指南(附阻抗计算与AntiPad避坑)
别再用FR4不行了!实测12G-SDI在普通PCB板材上的完整布线指南(附阻抗计算与AntiPad避坑) 在高速数字视频传输领域,12G-SDI作为4K/60fps内容的主流接口标准,其PCB设计一直被视为需要特殊高频板材的"贵族技术"。…...

CXPatcher:3分钟快速解锁CrossOver游戏性能的终极指南
CXPatcher:3分钟快速解锁CrossOver游戏性能的终极指南 【免费下载链接】CXPatcher A patcher to upgrade Crossover dependencies and improve compatibility 项目地址: https://gitcode.com/gh_mirrors/cx/CXPatcher 想要在Mac上流畅运行Windows游戏却遇到性…...