【Redis 原理】网络模型
文章目录
- 用户空间 && 内核空间
- 阻塞IO
- 非阻塞IO
- 信号驱动IO
- 异步IO
- IO多路复用
- select
- poll
- epoll
- Web服务流程
- Redis 网络模型
- Redis单线程网络模型的整个流程
- Redis多线程网络模型的整个流程
用户空间 && 内核空间
为了避免用户应用导致冲突甚至内核崩溃,用户应用与内核是分离的
- 进程的寻址空间会划分为两部分:内核空间、用户空间
- 用户空间只能执行受限的命令(Ring3),而且不能直接调用系统资源,必须通过内核提供的接口来访问
- 内核空间可以执行特权命令(Ring0),调用一切系统资源

阻塞IO
顾名思义,阻塞IO就是两个阶段都必须阻塞等待:
阶段一:
- 用户进程尝试读取数据(比如网卡数据)
- 此时数据尚未到达,内核需要等待数据
- 此时用户进程也处于阻塞状态
阶段二:
- 数据到达并拷贝到内核缓冲区,代表已就绪
- 将内核数据拷贝到用户缓冲区
- 拷贝过程中,用户进程依然阻塞等待
- 拷贝完成,用户进程解除阻塞,处理数据

非阻塞IO
顾名思义,非阻塞IO的recvfrom操作会立即返回结果而不是阻塞用户进程
阶段一:
- 用户进程尝试读取数据(比如网卡数据)
- 此时数据尚未到达,内核需要等待数据
- 返回异常给用户进程
- 用户进程拿到error后,再次尝试读取
- 循环往复,直到数据就绪
阶段二:
- 将内核数据拷贝到用户缓冲区
- 拷贝过程中,用户进程依然阻塞等待
- 拷贝完成,用户进程解除阻塞,处理数据

可以看到,非阻塞IO模型中,用户进程在第一个阶段是非阻塞,第二个阶段是阻塞状态。虽然是非阻塞,但性能并没有得到提高。而且忙等机制会导致CPU空转,CPU使用率暴增
信号驱动IO
信号驱动IO是与内核建立SIGIO的信号关联并设置回调,当内核有FD就绪时,会发出SIGIO信号通知用户,期间用户应用可以执行其它业务,无需阻塞等待。
阶段一:
- 用户进程调用sigaction,注册信号处理函数
- 内核返回成功,开始监听FD
- 用户进程不阻塞等待,可以执行其它业务
- 当内核数据就绪后,回调用户进程的SIGIO处理函数
阶段二:
- 收到SIGIO回调信号
- 调用recvfrom,读取
- 内核将数据拷贝到用户空间
- 用户进程处理数据

当有大量IO操作时,信号较多,SIGIO处理函数不能及时处理可能导致信号队列溢出,而且内核空间与用户空间的频繁信号交互性能也较低。
异步IO
异步IO的整个过程都是非阻塞的,用户进程调用完异步API后就可以去做其它事情,内核等待数据就绪并拷贝到用户空间后才会递交信号,通知用户进程.
阶段一:
- 用户进程调用aio_read,创建信号回调函数
- 内核等待数据就绪
- 用户进程无需阻塞,可以做任何事情
阶段二:
- 内核数据就绪
- 内核数据拷贝到用户缓冲区
- 拷贝完成,内核递交信号触发aio_read中的回调函数
- 用户进程处理数据

判断同步还是异步的依据:

IO多路复用
无论是阻塞IO还是非阻塞IO,用户应用在第一阶段都需要调用recvfrom来获取数据,差别在于无数据时的处理方案:
- 如果调用recvfrom时,恰好没有数据,阻塞IO会使CPU阻塞,非阻塞IO使CPU空转,都不能充分发挥CPU的作用。
- 如果调用recvfrom时,恰好有数据,则用户进程可以直接进入第二阶段,读取并处理数据
而在单线程情况下,只能依次处理IO事件,如果正在处理的IO事件恰好未就绪(数据不可读或不可写),线程就会被阻塞,所有IO事件都必须等待,性能自然会很差。
文件描述符(File Descriptor):简称FD,是一个从0 开始的无符号整数,用来关联Linux中的一个文件。在Linux中,一切皆文件,例如常规文件、视频、硬件设备等,当然也包括网络套接字(Socket)。
IO多路复用:是利用单个线程来同时监听多个FD,并在某个FD可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源
select
select是Linux最早是由的I/O多路复用技术,其数据结构定义如下:
// 定义类型别名 __fd_mask,本质是 long int
typedef long int __fd_mask;
//fd_set 记录要监听的fd集合,及其对应状态
typedef struct {// fds_bits是long类型数组,长度为 1024/32 = 32// 共1024个bit位,每个bit位代表一个fd,0代表未就绪,1代表就绪__fd_mask fds_bits[__FD_SETSIZE / __NFDBITS];// ...
} fd_set;// select函数,用于监听fd_set,也就是多个fd的集合
int select(int nfds, // 要监视的fd_set的最大fd + 1fd_set *readfds, // 要监听读事件的fd集合fd_set *writefds,// 要监听写事件的fd集合fd_set *exceptfds, // // 要监听异常事件的fd集合// 超时时间,null-用不超时;0-不阻塞等待;大于0-固定等待时间struct timeval *timeout
);
这里对参数作以下说明:
nfds:要监听的文件描述符的最大值 + 1,目的:告诉内核服务组要遍历的最大范围readfds、writefds、exceptfds:分别表示需要监听的事件集合。需要监听fd的哪一个操作就将对应的文件描述都写入到相应的集合timeout:设置select的等待时间
①NULL:表示select没有timeout,select将一直被阻塞,直到某个文件描述符上发生了事件
②0:仅检测描述符集合的状态,然后立即返回,并不等待外部事件的发生
③特定的时间值:如果在指定时间内没有事件发生,select将超时返回fd_set:形式上来讲这个结构是一个整数数组,但是实际上是按照位图的思想来使用的。使用位图中对应的比特位来表示要监视的文件描述符
阶段一:
- 用户进程调用select,指定要监听的FD集合
- 内核监听FD对应的多个socket
- 任意一个或多个socket数据就绪则返回readable
- 此过程中用户进程阻塞
阶段二:
- 用户进程找到就绪的socket
- 依次调用recvfrom读取数据
- 内核将数据拷贝到用户空间
- 用户进程处理数据

下面通过一个例子来说明:
假设我们现在需要监听的fd为1,2,5,并且内核中监听到了fd=1的文件描述符上有事件发生,那么我们会得到如下的结果:

紧接着,内核需要将更新后的位图信息copy到用户空间中的位图中,这样用户空间通过遍历位图就可以得到就绪的文件描述符,进而做相关业务处理。
而后,需要继续监听刚开始的1,2,5号文件描述符的时候就需要我们手动设置位图内容后才能正常监听。
select模式存在的问题:
- 需要将整个fd_set从用户空间拷贝到内核空间,select结束还要再次拷贝回用户空间
- select无法得知具体是哪个fd就绪,需要遍历整个fd_set
- fd_set监听的fd数量有限
- 每次调用select,都需要手动设置fd集合,从接口使用角度来讲非常不便
poll
poll模式对select模式做了简单改进,但性能提升不明显,部分关键代码如下:
// pollfd 中的事件类型
#define POLLIN //可读事件
#define POLLOUT //可写事件
#define POLLERR //错误事件
#define POLLNVAL //fd未打开// pollfd结构
struct pollfd {int fd; /* 要监听的fd */short int events; /* 要监听的事件类型:读、写、异常 */short int revents;/* 实际发生的事件类型 */
};
// poll函数
int poll(struct pollfd *fds, // pollfd数组,可以自定义大小nfds_t nfds, // 数组元素个数int timeout // 超时时间
);
IO流程:
- 创建pollfd数组,向其中添加关注的fd信息,数组大小自定义
- 调用poll函数,将pollfd数组拷贝到内核空间,转链表存储,无上限
- 内核遍历fd,判断是否就绪
- 数据就绪或超时后,拷贝pollfd数组到用户空间,返回就绪fd数量n
- 用户进程判断n是否大于0
- 大于0则遍历pollfd数组,找到就绪的fd
与select的对比:
- select模式中的fd_set大小固定为
sizeof(fd_set),而pollfd在内核中采用链表,理论上无上限 - 监听FD越多,每次遍历消耗时间也越久,性能反而会下降
epoll
epoll模式是对select和poll的改进,它提供了三个函数:
struct eventpoll {//...struct rb_root rbr; // 一颗红黑树,记录要监听的FDstruct list_head rdlist;// 一个链表,记录就绪的FD//...
};
// 1.创建一个epoll实例,内部是event poll,返回对应的句柄epfd
int epoll_create(int size);// 2.将一个FD添加到epoll的红黑树中,并设置ep_poll_callback
// callback触发时,就把对应的FD加入到rdlist这个就绪列表中
int epoll_ctl(int epfd, // epoll实例的句柄int op, // 要执行的操作,包括:ADD、MOD、DELint fd, // 要监听的FDstruct epoll_event *event // 要监听的事件类型:读、写、异常等
);// 3.检查rdlist列表是否为空,不为空则返回就绪的FD的数量
int epoll_wait(int epfd, // epoll实例的句柄struct epoll_event *events, // 空event数组,用于接收就绪的FDint maxevents, // events数组的最大长度int timeout // 超时时间,-1用不超时;0不阻塞;大于0为阻塞时间
);

我们可以看到。epoll中是将select的功能进行了拆分,拆分为epoll_ctl 和 epoll_wait。
其中epoll_ctl是将一个FD添加到epoll的红黑树中,并设置ep_poll_callback
在callback触发时,就把对应的FD加入到rdlist 这个 绪列表中。
epoll_wait主要是检查rdlist列表是否为空,不为空则返回就绪的FD的数量
总结:
select模式存在的问题:
- 能监听的FD最大不超过
sizeof(fd_set) - 每次select都需要把所有要监听的FD都拷贝到内核空间
- 每次都要遍历所有FD来判断就绪状态
- 每次调用select,都需要手动设置fd集合,从接口使用角度来讲非常不便
poll模式的问题:
- 和select函数一样,poll返回后,需要轮询pollfd来获取就绪的文件描述符
- 每次调用poll都需要把大量的pollfd结构从用户态拷贝到内核中
- 同时连接的大量客户端在一时刻可能只有很少的处于就绪状态,因此随着监视的文件描述符数量的增长,其效率也会线性下降
epoll模式中如何解决这些问题的
- 基于epoll实例中的红黑树保存要监听的FD,理论上无上限,而且增删改查效率都非常高
- 每个FD只需要执行一次epoll_ctl添加到红黑树,以后每次epol_wait无需传递任何参数,无需重复拷贝FD到内核空间
- 利用ep_poll_callback机制来监听FD状态,无需遍历所有FD,因此性能不会随监听的FD数量增多而下降
事件通知机制
当FD有数据可读时,我们调用epoll_wait(或者select、poll)可以得到通知。但是事件通知的模式有两种:
LevelTriggered:简称LT,也叫做水平触发。只要某个FD中有数据可读,每次调用epoll_wait都会得到通知。EdgeTriggered:简称ET,也叫做边沿触发。只有在某个FD有状态变化时,调用epoll_wait才会被通知。
举个栗子:
- 假设一个客户端socket对应的FD已经注册到了epoll实例中
- 客户端socket发送了2kb的数据
- 服务端调用epoll_wait,得到通知说FD就绪
- 服务端从FD读取了1kb数据
- 回到步骤3(再次调用epoll_wait,形成循环)
结果:
如果我们采用LT模式,因为FD中仍有1kb数据,则第⑤步依然会返回结果,并且得到通知
如果我们采用ET模式,因为第③步已经消费了FD可读事件,第⑤步FD状态没有变化,因此epoll_wait不会返回,数据无法读取,客户端响应超时。
LT是epoll的默认行为,使用ET能够减少epoll触发的次数,但是代价就是要求程序员一次响应就绪过程中就把所有的数据都处理完
相当于一个文件描述符就绪后,不会反复被提示就绪,看起来就是比LT更高效一些,但是在LT情况下如果也能做到每次就绪文件描述符都立刻处理,不让这个就绪信息被重复提示的话,其实性能也是一样的。另一方面。ET的代码复杂度相比之下更高。
Web服务流程
基于epoll模式的web服务的基本流程如图:

epoll_create创建实例
①创建红黑树,用于记录要监听的fd
②创建链表,用于记录就绪的fd- 创建
serverSocket,得到对应的fd - 调用
epoll_ctl监听步骤2中获取到的fd
①将fd注册到步骤1中的红黑树中
②注册相应的回调函数,在fd就绪时通过该函数处理 - 调用
epoll_wait,等待fd就绪 - 判断就绪事件类型,根据类型作出相应的处理
Redis 网络模型
问题引入:
Q1:Redis到底是单线程还是多线程?
- 如果仅仅聊Redis的核心业务部分(命令处理),答案是单线程
- 如果是聊整个Redis,那么答案就是多线程
- 在Redis版本迭代过程中,在两个重要的时间节点上引入了多线程的支持:
①Redis v4.0:引入多线程异步处理一些耗时较旧的任务,例如异步删除命令unlink
②Redis v6.0:在核心网络模型中引入 多线程,进一步提高对于多核CPU的利用率
因此,对于Redis的核心网络模型,在Redis 6.0之前确实都是单线程。是利用epoll(Linux系统)这样的IO多路复用技术在事件循环中不断处理客户端情况
Q2:为什么Redis要选择单线程?
- 抛开持久化不谈,Redis是纯内存操作,执行速度非常快,它的性能瓶颈是网络延迟而不是执行速度,因此多线程并不会带来巨大的性能提升。
- 多线程会导致过多的上下文切换,带来不必要的开销
- 引入多线程会面临线程安全问题,必然要引入线程锁这样的安全手段,实现复杂度增高,而且性能也会大打折扣
Redis单线程网络模型的整个流程

根据上面的模型结合web服务流程,我们对其进行详细展开:
-
server Socket初始化阶段

上图源码中包含了server socket的创建,IO多路复用模型的epoll的初始化,客户端连接server的处理函数注册,客户端读、写事件 处理函数的注册 -
客户端读事件触发流程
①client_server 发出读请求
②aeApiPoll监听到该就绪事件
③触发命令请求处理器readQueryFromClient
④将请求写入输入缓冲区c->queryBuf
⑤解析queryBuf数据为redis 命令
⑥选择并执行命令,将结果视情况写入到buf或者reply。(c->buf可以写的下就写,否则写到c->reply,这是一个链表,理论无上限)
⑦将客户端添加到server.clients_pending_write队列。等待被命令回复处理器sendReplyToClient处理返回
Redis多线程网络模型的整个流程
Redis 6.0版本中引入了多线程,目的是为了提高IO读写效率。
因此在解析客户端命令、写响应结果时采用了多线程。
核心的命令执行、IO多路复用模块依然是由主线程执行。

相关文章:
【Redis 原理】网络模型
文章目录 用户空间 && 内核空间阻塞IO非阻塞IO信号驱动IO异步IOIO多路复用selectpollepoll Web服务流程Redis 网络模型Redis单线程网络模型的整个流程Redis多线程网络模型的整个流程 用户空间 && 内核空间 为了避免用户应用导致冲突甚至内核崩溃,用…...

cpp中的继承
一、继承概念 在cpp中,封装、继承、多态是面向对象的三大特性。这里的继承就是允许已经存在的类(也就是基类)的基础上创建新类(派生类或者子类),从而实现代码的复用。 如上图所示,Person是基类&…...

DeepSeek全栈接入指南:从零到生产环境的深度实践
第一章:DeepSeek技术体系全景解析 1.1 认知DeepSeek技术生态 DeepSeek作为新一代人工智能技术平台,构建了覆盖算法开发、模型训练、服务部署的全链路技术栈。其核心能力体现在: 1.1.1 多模态智能引擎 自然语言处理:支持文本生成(NLG)、语义理解(NLU)、情感分析等计算…...

CSS 真的会阻塞文档解析吗?
在网页开发领域,一个常见的疑问是 CSS 是否会阻塞文档解析。理解这一问题对于优化网页性能、提升用户体验至关重要。要深入解答这个问题,需要从浏览器渲染网页的原理说起。 浏览器渲染网页的基本流程 浏览器在接收到 HTML 文档后,会依次进行…...
大模型的UI自动化:Cline 使用Playwright MCP Server完成测试
大模型的UI自动化:Cline 使用Playwright MCP Server完成测试 MCP MCP(Model Context Protocol),是一个开发的协议,标准化了应用程序如何为大模型提供上下文。MCP提供了一个标准的为LLM提供数据、工具的方式,使用MCP会更容易的构建Agent或者是基于LLM的复杂工作流。 最近…...
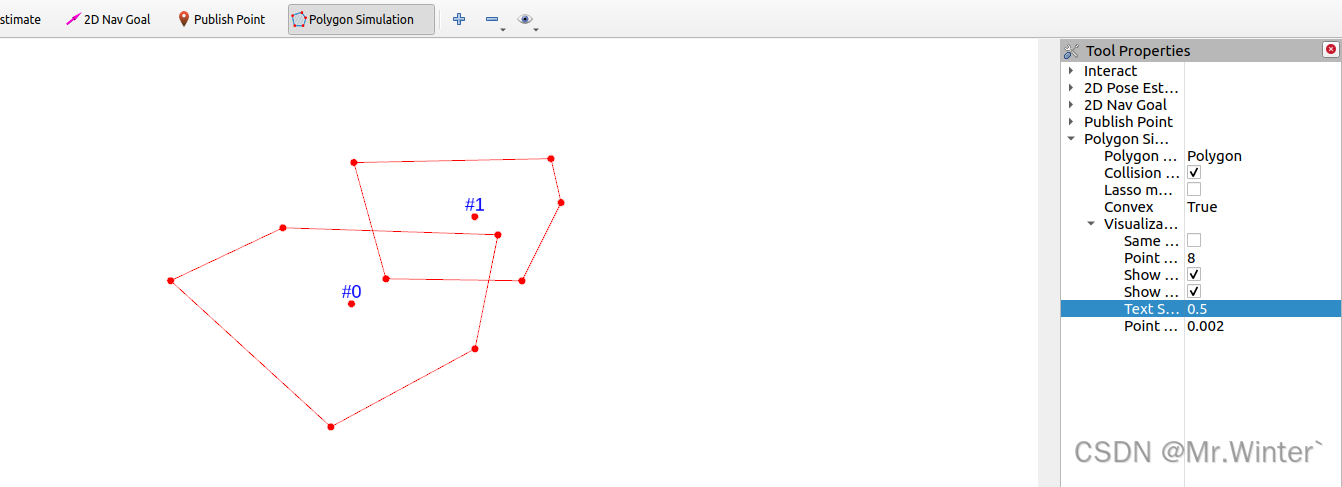
碰撞检测 | 图解凸多边形分离轴定理(附ROS C++可视化)
目录 0 专栏介绍1 凸多边形碰撞检测2 多边形判凸算法3 分离轴定理(SAT)4 算法仿真与可视化4.1 核心算法4.2 仿真实验 0 专栏介绍 🔥课设、毕设、创新竞赛必备!🔥本专栏涉及更高阶的运动规划算法轨迹优化实战,包括:曲线…...

Python 基本数据类型
目录 1. 字符串(String) 2. 列表(List) 3. 字典(Dictionary) 4. 集合(Set) 5. 数字(Number) 6. 布尔值(Boolean) 1. 字符串&…...

突破“第一崇拜“:五维心理重构之路
一、视频介绍 在这个崇尚"第一"的时代,我们如何找到自己的独特价值?本视频将带您踏上五维心理重构之旅,从诗意人生的角度探讨如何突破"圣人之下皆蝼蚁"的局限。我们将穿越人生的不同阶段,从青春的意气风发到…...

KubeKey一键安装部署k8s集群和KubeSphere详细教程
目录 一、KubeKey简介 二、k8s集群KubeSphere安装 集群规划 硬件要求 Kubernetes支持版本 操作系统要求 SSH免密登录 配置集群时钟 所有节点安装依赖 安装docker DNS要求 存储要求 下载 KubeKey 验证KubeKey 配置集群文件 安装集群 验证命令 登录页面 一、Ku…...

UE5网络通信架构解析
文章目录 前言一、客户端-服务器架构(C/S Model)二、对等网络架构(P2P,非原生支持)三、混合架构(自定义扩展)四、UE5网络核心机制 前言 UE5的网络通信主要基于客户端-服务器(C/S&am…...

实验3 知识表示与推理
实验3 知识表示与推理 一、实验目的 (1)掌握知识和知识表示的基本概念,理解其在AI中的深刻含义与意义; (2)熟悉AI中常用的知识表示方法的优缺点及其应用场景; (3)掌握产…...

基于Springboot银行信用卡额度管理系统【附源码】
基于Springboot银行信用卡额度管理系统 效果如下: 系统登陆页面 用户个人中心页面 新增信用卡申请页面 评估审核页面 管理员主页面 评估审核页面 操作日志管理页面 消费页面 研究背景 随着金融行业的快速发展和信息技术的不断进步,信用卡作为一种便捷…...

达梦数据库学习笔记@1
目录 达梦数据库学习笔记一、表空间管理(一)默认表空间(二)相关数据字典(三)表空间操作(四)临时表空间管理 二、重做日志管理(一)系统视图(二&…...

图像处理篇---图像处理中常见参数
文章目录 前言一、分贝(dB)的原理1.公式 二、峰值信噪比(PSNR, Peak Signal-to-Noise Ratio)1.用途2.公式3.示例 三、信噪比(SNR, Signal-to-Noise Ratio)1.用途2.公式3.示例 四、动态范围(Dyna…...

AI Agent实战:打造京东广告主的超级助手 | 京东零售技术实践
前言 自2022年末ChatGPT的问世,大语言模型(LLM)技术引发全球关注。在大模型技术落地的最佳实践中,智能体(Agent)架构显现出巨大潜力,成为业界的普遍共识,各大公司也纷纷启动Agent技…...

50周学习go语言:第1周 环境搭建
以下是为零基础学习者准备的详细第1周教程,包含环境搭建、工具配置和首个Go程序的完整操作指南: 一、Go语言环境安装(Windows/macOS/Linux通用) 1. 下载安装包 官网地址:https://go.dev/dl//根据系统选择对应版本&am…...

4. MySQL 逻辑架构说明
4. MySQL 逻辑架构说明 文章目录 4. MySQL 逻辑架构说明1. 逻辑架构剖析1.1 服务器处理客户端请求1.2 Connectors(连接器)1.3 第1层:连接层1.4 第2层:服务层1.5 第3层:引擎层1.6 存储层 2. SQL执行流程2.1 MySQL 中的 SQL 执行流程 2.2 MySQL…...

《AI与NLP:开启元宇宙社交互动新纪元》
在科技飞速发展的当下,元宇宙正从概念逐步走向现实,成为人们关注的焦点。而在元宇宙诸多令人瞩目的特性中,社交互动体验是其核心魅力之一。人工智能(AI)与自然语言处理(NLP)技术的迅猛发展&…...

面对STM32的庞大体系,如何避免迷失在细节中?
我第一次接触STM32时,我以为抱着开发板就是拥抱未来,实际上一开机就喜提四大耳光,看到卖家演示的MP3播放、TFT彩屏、网口通信好炫酷,忍不住买回来掌握这些神技,到最后发现最实用的还是开发板的关机键和复位键。 看视频…...

ragflow-RAPTOR到底是什么?请通俗的解释!
RAPTOR有两种不同的含义,具体取决于上下文: RAPTOR作为一种信息检索技术 RAPTOR是一种基于树状结构的信息检索系统,全称为“Recursive Abstractive Processing for Tree-Organized Retrieval”(递归抽象处理树组织检索)…...

Avue动态配置进阶:利用findObject精准操控表单option
1. Avue动态表单配置的核心痛点 在后台管理系统开发中,表单动态配置是个高频需求。就拿用户管理模块来说,不同租户看到的角色、部门、岗位选项应该是不同的。传统做法往往需要手动遍历整个表单配置对象,代码冗长且容易出错。我接手过的一个项…...

Ubuntu/Linux下Protobuf多版本管理与切换指南:告别‘port_def.inc’和版本冲突噩梦
Ubuntu/Linux下Protobuf多版本管理与切换实战指南 在C项目开发中,Protobuf作为高效的序列化工具被广泛使用。但当你的机器上同时运行着多个不同年代的项目时,Protobuf版本管理就成了一场噩梦。最常见的就是port_def.inc缺失或版本不兼容错误,…...

AGI不是替代研究员,而是重定义“用户真相”——SITS2026演讲中被删减的8分钟深度推演
第一章:AGI不是替代研究员,而是重定义“用户真相”——SITS2026演讲中被删减的8分钟深度推演 2026奇点智能技术大会(https://ml-summit.org) 被压缩的范式跃迁 在SITS2026主会场后台,一段8分钟未公开的推演视频揭示了关键转折:A…...

Spring源码速成笔记,普通Java程序员进阶必备!
大多数Java程序员Spring框架还没有一个清楚的认知。拿Spring来说,现在面试面试官一般会直接问:谈一下你对Spring的理解?不会像以前的面试一样直接给你具象出某一个具体的点,而是给你抛出一个很大的范围,然后根据你回答…...
)
超星学习通/中科大实验室安全考试自动答题脚本保姆级教程(Python版,含Cookie获取)
超星学习通实验室安全考试自动化解决方案实战指南 实验室安全考试是高校学生必须面对的常规考核之一,但反复刷题的过程往往耗时费力。作为一名长期研究教育自动化工具的技术爱好者,我发现通过Python脚本与浏览器开发者工具的结合,可以高效解决…...

[进阶配置] 从零到一:Windows 10 上 WSL2 的完整配置与优化指南
1. WSL2环境准备与基础安装 第一次接触WSL2的朋友可能会觉得有点懵,其实它就是Windows系统里内置的一个Linux运行环境。相比传统虚拟机,WSL2性能更好、资源占用更低,特别适合开发者使用。我自己从WSL1用到WSL2,实测开发效率提升了…...

汇编语言从零到一:手把手构建你的第一个可执行程序
1. 环境搭建:从零开始配置汇编开发环境 第一次接触汇编语言的朋友可能会被各种陌生的工具和概念吓到,但其实搭建开发环境比你想象中简单得多。我刚开始学汇编时也走了不少弯路,今天就把最实用的配置方法分享给你。 必备工具三件套:…...

从零到精飞:APM多旋翼核心参数调校实战指南
1. APM飞控入门:从组装到基础参数设置 第一次接触APM飞控的新手常会被密密麻麻的参数表吓到。我刚开始调试植保无人机时,光是理解PID三个字母就花了整整一周。其实只要掌握核心逻辑,调参就像给汽车做四轮定位——有标准流程可循。 多旋翼飞控…...
)
房屋租赁管理|基于springboot + vue房屋租赁管理系统(源码+数据库+文档)
房屋租赁管理系统 目录 基于springboot vue房屋租赁管理系统 一、前言 二、系统功能演示 三、技术选型 四、其他项目参考 五、代码参考 六、测试参考 七、最新计算机毕设选题推荐 八、源码获取: 基于springboot vue房屋租赁管理系统 一、前言 博主介绍&am…...

【AGI审计可信度生死线】:从GAAP到IFRS,6类会计估计场景中AGI决策偏差率超阈值的3个隐藏信号
第一章:AGI在财务分析与审计中的范式革命 2026奇点智能技术大会(https://ml-summit.org) 传统财务分析与审计长期受限于规则引擎的刚性、样本抽样的偏差以及人工复核的认知负荷。AGI的崛起正打破这一边界——它不再仅执行预设逻辑,而是具备跨模态理解财…...