机器学习3-聚类
1 聚类解决的问题
- 知识发现,发现事物之间的潜在关系
- 异常值检测
- 特征提取 数据压缩的例子
- 新闻自动分组、用户分群、图像分割、像素压缩等等




2 与监督学习比较
监督学习是需要给定X、Y,X为特征,Y为标签,选择模型,学习(目标函数最优化问题),生成模型,这个模型本质上是一组参数,
无监督机器学习的数据只有X,没有标签,只根据X的相似度来做一些事情,相似度的计算一般通过距离来度量。相似度高的聚类在一起,进而可以对数据降维
3 聚类算法
主流的聚类算法可以分为两类:划分聚类(Partitioning Clustering)和层次聚类(Hierarchical Clustering)。他们主要的区别是
- 划分聚类是一系列扁平的结构,它们之间没有任何显式的结构来表名彼此的关联性。常见算法有K-means、K-medoids、Gaussian Mixture Model(高斯混合模型)、Spectral Clustering(谱聚类)、Centroid-based Clustering等
- 层次聚类是具有层次结构的簇集合,因此能够输出比划分聚类输出的无结构簇集合提供更丰富的信息。层次聚类可以认为是嵌套的划分聚类,常见算法有Single-linkage、Complete-linkage、Connectivity-based Clustering等

4 相似度
X中的每一条数据都可以理解为多维空间中的一个点
相似度用点和点之间的距离衡量
-
欧氏距离
O p = ( x 1 − x 2 ) 2 + ( y 1 − y 2 ) 2 ) O_p=\sqrt {(x_1-x_2)^2+(y_1-y_2)^2)} Op=(x1−x2)2+(y1−y2)2)
∣ x ∣ = x 2 + y 2 |x|=\sqrt{x^2+y^2} ∣x∣=x2+y2
-
明可夫斯基距离
d ( X , Y ) = ( x 1 − y 1 ) p + ( x 2 − y 2 ) p + ( x 3 − y 3 ) p + . . . + ( x p − y p ) p p d(X,Y)=\sqrt[p]{(x_1-y_1)^p+(x_2-y_2)^p+(x_3-y_3)^p+...+(x_p-y_p)^p} d(X,Y)=p(x1−y1)p+(x2−y2)p+(x3−y3)p+...+(xp−yp)p
- p=1时,曼哈顿距离
- p=2时,欧氏距离
- p=无穷,切比雪夫距离,哪个纬度值最大就是哪个差值作为距离
-
余弦距离
c o s θ = a ⋅ b ∣ ∣ a ∣ ∣ ∣ ∣ b ∣ ∣ cos\theta=\frac{a \cdot b} {||a||||b||} cosθ=∣∣a∣∣∣∣b∣∣a⋅b
c o s θ = x 1 x 2 + y 1 y 2 x 1 2 + y 1 2 × x 2 2 + y 2 2 cos\theta=\frac{x_1x_2+y_1y_2}{\sqrt{x_1^2+y_1^2}\times \sqrt{x_2^2+y_2^2}} cosθ=x12+y12×x22+y22x1x2+y1y2
拓展:如何通过向量夹角理解不同“维度”? 三角函数 sinx, cosx 的泰勒展开推导及两个巧妙应用_三角函数泰勒展开-CSDN博客


从图中很容易看出a/b/c之间的关系,将a2+b2-c^2作为一个判定因子Δ,则Δ是a,b,c三个变量的函数。对于同样一个角,如果三角形边长过长,则Δ会变动很大,如果过小,则Δ会变动很小,也就是说没有归一化。为了消除边长的影响,需要除以2ab,保证Δ的范围在-1到+1之间
为什么要用Δ除以2ab ?
- 根据三角形的公理:两边之和大于第三边,两边之差小于第三边,得出a+b>c>a-b
- 那么c2的取值范围为(a+b)2>c2>(a-b)2,展开就是a2+b2+2ab>c2>a2+b^2- 2ab
- 于是判定因子Δ=a2+b2-c^2的范围在-2ab到2ab之间
- 这样就把Δ规范到了-1到1之间
cosθ=(a2+b2-c^2)/2ab
余弦距离在文本分类中使用很广,余弦距离通过评价文章相似度
- 将文章分词
- 将文章转变为词向量(TFIDF,逆文档频率,如果将文章分词通过one-hot编码,会产生稀疏的问题,而TFIDF很好的解决了这个问题)
- 转换为词向量后,将文章映射到高维空间变为一个向量
- 文章之间的向量的余弦距离代表文章之间的相似度
4.1 文本相似度
TF-IDF
TF:在给定文档中某个词出现的概率,即:在谋篇文章中 某次出现的次数/谋篇文章的总次数。
DF:语料库中包含某词的总文章数
IDF:I 是inverse的意思,代表某词在语料库中的重要程度,为了减少经常用的词对于相似度的贡献,比如“的”,“是”这一类的词
TF-IDF: TF*IDF


4.2 数据相似度
-
Jaccard相似系数
主要用于计算符号度量或布尔值度量的个体间的相似度,个体的特征属性由符号度量或者布尔值表示无法衡量差异具体值的大小,只能获得“是否相同”这个结果,所以Jaccard系数只判断个体间共同具有的特征是否一致的问题
用于网页去重、文本相似度分析
-
Pearson相关系数
线性相关系数,对数据分布要求较高
理解pearson相关系数,首先要理解协方差(Covariance),协方差是反映两个随机变量相关程度的指标,如果一个变量跟随另一个变量同时变大或者变小,那么这两个变量的协方差就是正值,反之相反,公式:

pearson公式:


范围:-1 到 1
缺点:
1)与样本数量有关,如果n过小,很有可能出现接近1,n过大可能小于1;且显著性检测时采用t检验要求数据来自正态分布,样本过小可能导致要求不满足
2)从含义上看,如果出现X=(1,1, 1)向量,其标准差为0,分母为0所以无法计算pearson相关系数
应用:
1)求两样品的不同特征之间的相关系数,从而用于降维
2)根据相关度进行聚类
与余弦的联系:
pearson相关系数实际上是做了标准化的cos,pearson是余弦相似度在维度缺失情况下的一种改进如何理解皮尔逊相关系数(Pearson Correlation Coefficient)?
5 K-means聚类
5.1 基本思想
- 先给定K个划分,迭代样本与簇的隶属关系,每次都比之前一次好一些
- 迭代若干次后,就能得到比较好的结果
5.2 步骤
- 初始化:选择K个初始的簇中心(怎么选)
- 分配:逐个计算每个样本到中心的距离,将样本归属到距离最小的那个簇中心的簇中
- 更新:每个簇内部计算平均值,更新簇中心
- 迭代:重复步骤2和步骤3,知道满足停止条件,比如集群中心不再显著变化,或者达到设定的迭代次数

5.3 K-means特点
- 优点
- 简单,效果不错
- 缺点
- 对异常值敏感:计算距离时我们使用L2距离的平方。这样对离群点很敏感,会把中心点拉偏
- 对初始值敏感
- 对某些分布聚类效果不好
5.4 K-means的变种
-
K-medoids:针对K-means的缺点改进
- 计算新的簇中心的时候不再选择均值,而是选择中位数
- 抗噪能力得到加强
- 为避免平方计算对离群点的敏感,把平方变成绝对值
- 限制聚类中心点必须来自数据点
- 求中心点的计算方法,由原来的直接计算重心,变成计算完重心后,在重心附近找一个数据点作为新的中心点
- K-medoids重拟合步骤直接求平均的K-means要复杂一些


-
二分K-means
- K-means的损失函数, 每个点到中心点位置的MSE
- 分别计算四个簇的MSE,会发现有两个簇的MSE很小,一个簇的MSE很大
- 选择合并簇中心点比较近,MSE很小的簇,切分簇中心离其他簇中心比较远,MSE比较大的簇,重新进行K-means聚类
-
K-means++
- 现在目前的模型基本使用的是K-means++
- K-means++改变初始中心点的位置
- 目标:初始化簇中心点稍微远一些
- 步骤:1)随机选择第一个中心点; 2)计算每个样本到第一个中心点的距离;3)将距离转化为概率;4)概率化选择
5.5 K-means的损失函数
- K-means的理论基础是假设各簇之间符合同方差的高斯分布模型

- 通过最大似然估计得到K-means的迭代方法
- 这个函数是个非凸函数,根据初始值不同只能得到局部最优解
5.6 K的选择
K值的选择是执行K均值聚类时需要仔细考虑的问题,选择的不合适可能导致聚类结果不准确或不具有实际意义
5.6.1 肘部法(Elbow Method)
K=n的时候,损失函数为0
K=1的时候,损失函数=原始数据的方差
所以,K应选择一个最佳的拐点,肘部法

5.6.2 轮廓系数(Silhouette Coefficient)
轮廓系数结合了聚类的凝聚度(Cohesion)和分离度(Separation),用于评估聚类的结果:
- 簇内距离:同一簇内,其他点到某个点的距离的平局值
- 簇间距离:某个点到其他簇每个点的平均值

最终目的是为了使簇内部距离最小化,簇间距离最大化。所以SC越靠近1,说明b越大于a,即外部距离大,内部距离小,说明分类效果越好
然而,当我们根据不同的K计算出几个SC值差不多时,并不是盲目选更大的SC,如下面的例子:

n_clusters = 2 SC : 0.7049
n_clusters = 3,SC : 0.5882
n_clusters = 4,SC : 0.6505
n_clusters = 5,SC : 0.5637
n_clusters = 6,SC: 0.4504
每次聚类后,每个样本得到一个轮廓系数,当SC=1时,说明这个点与周围簇距离较远,结果非常好,当SC=0时,说明这个点可能处在两个簇的边界上,当值为负时,该点可能被误分
从上面结果来说,K取2和4其实都不错,但可以从下图看出,K取2的话,第0簇的宽度远宽于第1簇(也就是说黑色数量比绿色多太多),而K取4的话,每个簇其差别不大。所以选K=4更好


5.6.3 误差平方和(SSE)
误差平方和(The sum of squares due to error):真实值和误差值的差的平方,再求整体和

例如:数据-0.2、0.4、-0.8、1.3、-0.7为真实值和误差值的差

SSE是松散度的衡量,所以SSE越小越好。随着聚类迭代,其值越来越小,知道最后区域稳定
5.6.4 CH系数(Calinski-Harabasz Index)
CH系数:类别内部数据的协方差越小越好,类别之间的协方差越大越好,这样的Calinski-Harabasz分数s会高,分数s高则聚类效果好。

其中,tr为矩阵的迹,Bk是类别之间的协方差矩阵,Wk是类别内部数据的协方差矩阵,m是训练集样本数量,k是类别数量
5.6.5 小结
- SSE:误差平方和越小越好
- 肘部法:下降突然变缓时即认为是最佳K值
- SC系数:取值为[-1, 1],其值越大越好
- CH系数:分数S高则聚类效果越好,CH需要达到的目的,用尽量少的类别聚类尽量多的样本,同时获取较好的聚类效果
6 Canopy聚类
Canopy聚类只进行一次划分聚类,是基于距离阈值进行的快速聚类算法,而这些阈值通常需要进行调整以得到满意的聚类结果。实际应用中适合K-means聚类结合使用,一般是先用Canopy聚类,将K值计算出来,然后用K-means进行迭代

Canopy聚类步骤:
- 设置超参数T1、T2 T1>T2
- while D 非空:
- 随机产生d属于D作为中心点
- 计算所有点到d的距离
- 所有距离<t1的点归属于d的中心点
- 从D中删除d及距离小于t2的点
聚类效果:

7 层次聚类
层次聚类(Hierarchical Clustering)是聚类算法的一种,通过计算不同类别的数据点间的相似度来创建一颗有层次的嵌套聚类树,在聚类树中,不同类别的原始数据点是树的最低层,树的顶层是一个聚类的根节点,创建聚类树有自上而下和自下而上分列两种方法。

7.1 层次聚类的步骤
假设有6个样本点(A/B/C/D/E/F),层次聚类步骤如下:
- 最开始假设每个样本点是一个簇,计算每个样本间的相似度(也就是距离),得到一个相似矩阵
- 寻找各个类之间的最近的两个类,即若B、C的相似度最高,合并簇B和C,现在变为A,BC,D,E,F
- 更新簇类间的相似矩阵,若BC和D相似度最高,归为一个簇类,则变为A,BCD,E,F
- 更新簇类间的相似矩阵,若簇类E和F的相似度最高,归为一类,则变为A,BCD,EF
- 重复第四步,簇类BCD和EF相似度最高,合并为一个簇,则变为A,BCDEF
- 最后合并A,BCDEF为一个簇类,结束

7.2 层次聚类算法分类
-
自顶向下
先上图

自顶乡下的层次聚类,最开始所有的对象均属于一个cluster,每次按一定的准则将某个cluster划分为多个cluster,如此往复,直至每个数据点均属于一个cluster
-
自底向上

自底向上,是将每个数据点看做一个簇,每次计算相似度,合并,如此循环下去,直至属于一个簇为止
7.3 层次聚类相关模型
7.3.1 Single-Linkage算法

此算法是构造一个棵二叉树,用叶节点代表数据,而二叉树的每一个内部节点代表一个聚类,这是一个自下而上的聚类。
7.3.2 Complete-Linkage算法

与Single-Linkage算法相似,Complete-Linkage的迭代思想是一样的,不同的是合并类时,Single-Linkage是用两个类中距离最小的两个点作为类之间的距离,而Complete-Linkage恰恰相反,用距离最远的两个数据点之间的距离作为两个类之间的距离
8 密度聚类
前面介绍了划分聚类和层次聚类算法,下面介绍密度聚类算法:DB-SCAN算法
DB-SCAN是一个基于密度的聚类。在聚类不规则形态的点,如果用K-means,效果不会很好。而通过DB-SCAN就可很好地把同一密度区域的点聚在一起

8.1 关键概念
-
核心对象(Core Object),也就是密度达到一定程度的点
- 若 xj 的∈ - 邻域至少包含 MinPts 个样本,即 ,则 是一个核心对象
-
密度直达(directly-density-reachable),密度可达(directly-reachable):核心对象之间可以是密度直达或密度可达

-
密度相连(density-connected):所有密度可达的和点点就是构成密度相连
- 对xi和xj,若存在xk使得xi与xj,均由xk密度可达,则称xi和xj密度相连

8.2 算法伪代码

这个过程用直白的语言描述就是:
- 对于一个数据集,先规定最少点密度 MinPts 和半径范围。
- 先找出核心对象:如果在半径范围内点密度大于 MinPts,则这个点是核心对象。把所有的核心对象放到一个集合中。
- 从这个核心对象集合中,随机找一个核心对象,判断其它的数据点与它是否密度直达,如果是,则归入聚类簇中。
- 继续判断其它点与聚类簇中的点是否密度直达,直到把所有的点都检查完毕,这时候归入聚类簇中的所有点是一个密度聚类。
相关文章:
机器学习3-聚类
1 聚类解决的问题 知识发现,发现事物之间的潜在关系异常值检测特征提取 数据压缩的例子新闻自动分组、用户分群、图像分割、像素压缩等等 2 与监督学习比较 监督学习是需要给定X、Y,X为特征,Y为标签,选择模型,学习&a…...

html中的css
css (cascading style sheets,串联样式表,也叫层叠样式表) css规范一般约定: 1.存放CSS样式文件的目录一般命名为style或css。 2.在项目初期,会把不同类别的样式放于不同的CSS文件,是为了CSS编…...

36. Spring Boot 2.1.3.RELEASE 中实现监控信息可视化并添加邮件报警功能
1. 创建 Spring Boot Admin Server 项目 1.1 添加依赖 在 pom.xml 中添加 Spring Boot Admin Server 和邮件相关依赖: <dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-w…...

Linux: 已占用接口
Linux: 已占用接口 1. netstat(适用于旧系统)1.1 书中对该命令的介绍 2. ss(适用于新系统,替代 netstat)3. lsof(查看详细进程信息)4. fuser(快速查找占用端口的进程)5. …...
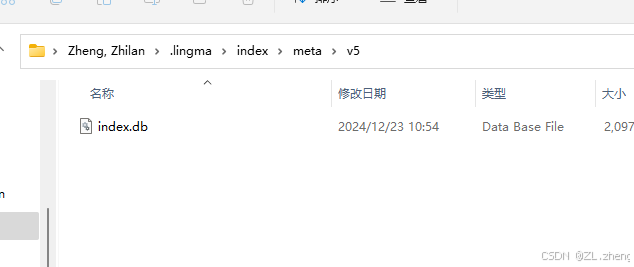
Vscode的通义灵码占用空间过大问题【.lingma】
C盘空间发现没装几个软件但是空间占用太离谱了, 最后排查发现是一个.lingma的文件夹问题,这个文件夹用了我居然差不多一百G的空间, 点进去。删除掉ai训练时产生的dbc文件就好了, windowsI 打开系统设置,搜索存储&#…...

鸿蒙Next如何自定义标签页
前言 项目需求是展示标签,标签的个数不定,一行展示不行就自行换行。但是,使用鸿蒙原生的 Grid 后发现特别的难看。然后就想着自定义控件。找了官方文档,发现2个重要的实现方法,但是,官方的demo中讲的很少&…...
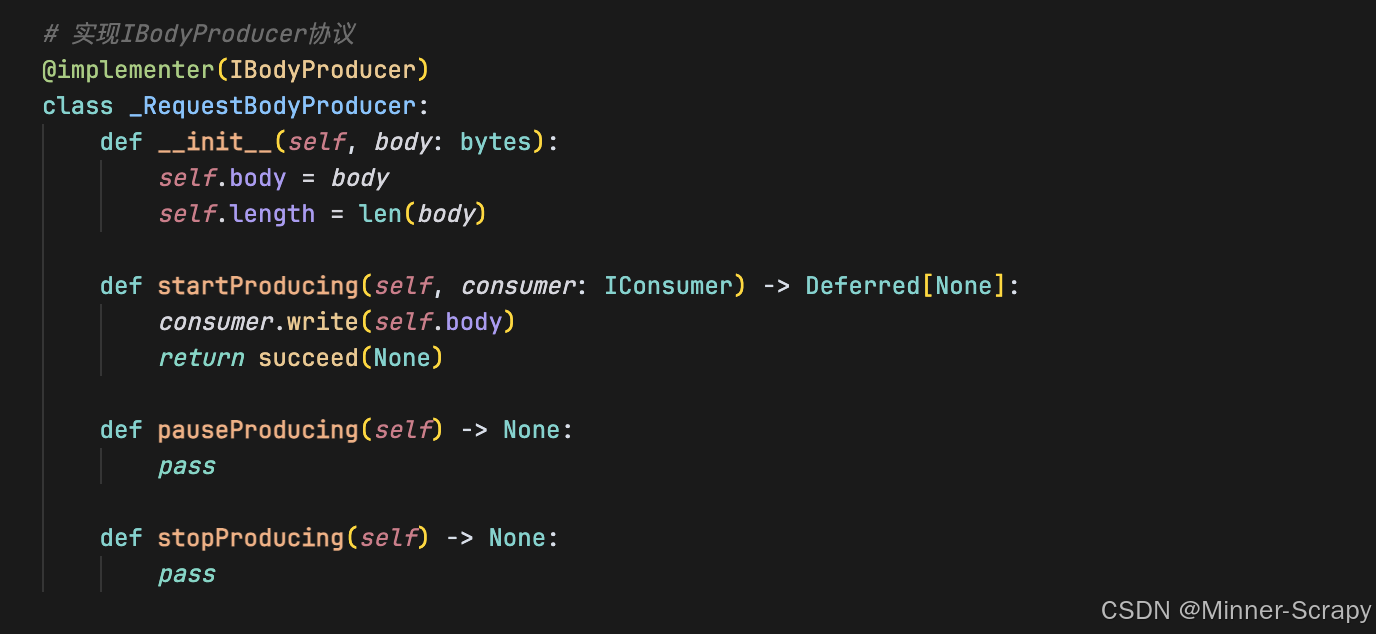
知识拓展:Python 接口实现方式对比:Protocol vs @implementer
Python 接口实现方式对比:Protocol vs implementer 1. 两种接口实现方式 1.1 Python Protocol(结构化子类型) from typing import Protocolclass DownloadHandlerProtocol(Protocol):def download_request(self, request: Request, spider:…...

开源程序wordpress在海外品牌推广中的重要作用
WordPress作为全球最流行的开源内容管理系统(CMS),在全球网站搭建中占据超过40%的市场份额。其强大的功能、灵活性和易用性使其成为企业进行海外品牌推广的首选平台。以下是WordPress在海外品牌推广中的重要性分析: 1. 多语言支持与本地化 WordPress通…...
】爬虫“反水”:助力数字版权保护的逆向之旅)
【Python爬虫(89)】爬虫“反水”:助力数字版权保护的逆向之旅
【Python爬虫】专栏简介:本专栏是 Python 爬虫领域的集大成之作,共 100 章节。从 Python 基础语法、爬虫入门知识讲起,深入探讨反爬虫、多线程、分布式等进阶技术。以大量实例为支撑,覆盖网页、图片、音频等各类数据爬取ÿ…...
)
k8s面试题总结(五)
1.考虑一种情况,即公司希望通过维持最低成本来提高其效率和技术运营速度。您认为公司将如何实现这一目标? 公司可以通过构建 CI/CD 管道来实现 DevOps 方法,但是这里可能出现的一个问题是配置可能需要一段时间才能启动并运行。 因此&#x…...

文章精读篇——用于遥感小样本语义分割的可学习Prompt
题目:Learnable Prompt for Few-Shot Semantic Segmentation in Remote Sensing Domain 会议:CVPR 2024 Workshop 论文:10.48550/arXiv.2404.10307 相关竞赛:https://codalab.lisn.upsaclay.fr/competitions/17568 年份&#…...

Spring Boot2.0之十 使用自定义注解、Json序列化器实现自动转换字典类型字段
前言 项目中经常需要后端将字典类型字段值的中文名称返回给前端。通过sql中关联字典表或者自定义函数不仅影响性能还不能使用mybatisplus自带的查询方法,所以推荐使用自定义注解、Json序列化器,Spring的缓存功能实现自动转换字典类型字段。以下实现Spri…...

从电子管到量子计算:计算机技术的未来趋势
计算机发展的历史 自古以来人类就在不断地发明和改进计算工具,从结绳计数到算盘,计算尺,手摇计算机,直到1946年第一台电子计算机诞生,虽然电子计算机至今虽然只有短短的半个多世纪,但取得了惊人的发展吗,已经经历了五代的变革。计算机的发展和电子技术的发展密切相关,…...

将CUBE或3DL LUT转换为PNG图像
概述 在大部分情况下,LUT 文件通常为 CUBE 或 3DL 格式。但是我们在 OpenGL Shader 中使用的LUT,通常是图像格式的 LUT 文件。下面,我将教大家如何将这些文件转换为 PNG 图像格式。 条形LUT在线转换(不是8x8网络)&am…...

python文件的基本操作,文件读写
1.文件 1.1文件就是存储在某种长期存储设备上的一段数据 1.2文件操作 打开文件-->读写文件-->关闭文件 注意:可以只打开和关闭文件不进行任何操作 1.3文件对象的方法 1.open():创建一个file对象,默认以只读模式打开 2.read(n):n表示从文件中…...

华为认证考试证书下载步骤(纸质+电子版)
华为考试证书可以通过官方渠道下载相应的电子证书,部分高级认证如HCIE还支持申请纸质证书。 一、华为电子版证书申请步骤如下: ①访问华为培训与认证网站 打开浏览器,登录华为培训与认证官方网站 ②登录个人账号 在网站首页,点…...

正式页面开发-登录注册页面
整体路由设计: 登录和注册的切换是切换组件或者是切换内容(v-if和 v-else),因为点击两个之间路径是没有变化的。也就是登录和注册共用同一个路由。登录是独立的一级路由。登录之后进到首页,有三个大模块:文章分类&…...

nss刷题5(misc)
[HUBUCTF 2022 新生赛]最简单的misc 打开后是一张图片,没有其他东西,分离不出来,看看lsb,红绿蓝都是0,看到头是png,重新保存为png,得到一张二维码 扫码得到flag [羊城杯 2021]签到题 是个动图…...

深入Linux序列:进程的终止与等待
在之前的学习中,我们知道我们的进程在运行结束的时候,那么它并不会立即进入死亡状态,而是先进入僵尸状态,维持僵尸状态一段时间,那么此时在僵尸状态中的进程,那么它的内核数据已经移出内存被清理了…...

蓝桥杯之日期问题2
文章目录 需求11.1 代码 2.需求22.1代码 需求1 2020 年春节期间,有一个特殊的日期引起了大家的注意:2020 年 2 月 2 日。因为如果将这个日期按 “yyyymmdd” 的格式写成一个 8 位数是 20200202,恰好是一个回文数。我们称这样的日期是回文日期…...

Unity-MCP协议:可嵌入、可协商的AI上下文通信标准
1. 这不是又一个“AI插件”,而是Unity开发工作流的底层重定义你有没有过这样的时刻:在Unity里反复调整Animator Controller的过渡条件,只为让角色转身动画不穿模;写完一段NavMesh寻路逻辑,却要花两小时调试Agent卡在斜…...

Ventoy终极指南:一个U盘启动所有系统,告别重复格式化烦恼 [特殊字符]
Ventoy终极指南:一个U盘启动所有系统,告别重复格式化烦恼 😎 【免费下载链接】Ventoy A new bootable USB solution. 项目地址: https://gitcode.com/GitHub_Trending/ve/Ventoy 还在为每次安装系统都要重新制作启动盘而烦恼吗&#x…...

Unity安卓打包实战指南:从环境配置到APK生成全链路排错
1. 这不是“入门教程”,而是一份写给真实开发现场的生存指南你打开Unity,新建一个3D项目,拖进一个Cube,点击Play——它动了。你松了口气,觉得“Unity好像也没那么难”。但当你把APK打包发给测试同事,对方回…...

基于Arduino与应变片传感器的高精度厨房电子秤DIY全攻略
1. 项目概述:用Arduino打造一台高精度厨房电子秤作为一个喜欢在厨房里折腾的硬件爱好者,我经常遇到需要精确称量食材的场合。市面上的电子秤要么精度不够,要么价格不菲,要么功能单一。于是,我萌生了自己动手做一台的想…...

BLE蓝牙扫描深度剖析:扫描原理、核心参数、前后台差异
一、前言BLE设备交互分为两大角色:广播端(外设Peripheral)与扫描端(中心Central)。上一篇博客详解了四大广播模式,本文聚焦配套核心能力——BLE扫描机制。绝大多数蓝牙开发疑难问题:前台能扫后台…...

告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略
告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略当GIS初学者第一次安装ArcGIS 10.6时,往往会被其庞大的安装体积所震惊。许多用户习惯性地点击"下一步",结果发现C盘空间被迅速吞噬,系统运行变得迟缓。本文将深…...

全链路压测实战:双十一级别的流量,我是这样扛住的
作为一名在质量保障领域摸爬滚打多年的测试工程师,我深知传统的单接口压测在如今分布式架构下的无力感。当业务流量达到双十一这种脉冲式、高并发的级别时,任何一个非核心链路上的“短板”都可能引发系统性的雪崩。全链路压测不再是选择题,而…...

【审计专栏】【财务领域】 第四十九篇 人在企业中的核心资产和核心利益01
编号 类型 企业 (行业/企业产品/企业利益链/生态位与层级) 业务领域 企业性质 企业中人的角色/岗位/利益矩阵 人在企业中的核心资产/附属资产 资产的业务-财务数学模型及数字/数值 关联知识 1 核心经营性资产(如IP、数据、品牌) 行业:人工智能 产品:工业视觉检…...

Python strip 与 rstrip 函数区别
Python strip 与 rstrip 函数区别 文章目录Python strip 与 rstrip 函数区别一、核心作用二、基础语法三、基础使用示例四、指定删除特定字符五、常用业务场景一、核心作用 函数作用范围strip()移除字符串首尾空白字符rstrip()仅移除字符串右侧末尾字符,左侧保持不…...

3分钟快速解决Windows热键冲突检测难题:Hotkey Detective终极指南
3分钟快速解决Windows热键冲突检测难题:Hotkey Detective终极指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...