机器学习:强化学习的epsilon贪心算法
强化学习(Reinforcement Learning, RL)是一种机器学习方法,旨在通过与环境交互,使智能体(Agent)学习如何采取最优行动,以最大化某种累积奖励。它与监督学习和无监督学习不同,强调试错探索(Exploration-Exploitation)以及基于奖励信号的学习。

强化学习任务通常用马尔可夫决策过程来描述:机器处于环境 E E E中,状态空间 X X X,其中每个状态 x ∈ X x \in X x∈X是机器感知到的环境的描述,机器能采取的动作构成了动作空间 A A A,若某个动作 a ∈ A a \in A a∈A作用在当前状态 x x x上,则潜在的转移函数 P P P将使得环境从当前状态按照某种概率转移到另一个状态,在转移到另一个状态的同时,环境会根据潜在的“奖赏”函数 R R R反馈给机器一个奖赏。
在环境中状态的转移、奖赏的返回是不受机器控制的,机器只能通过选择要执行的动作来影响环境,也只能通过观察转移后的状态和返回的奖赏来感知环境。
机器要做的是通过在环境中不断地尝试而学得一个“策略”,根据这个“策略”在状态 x x x下就能知道要执行得动作。
在强化学习任务中,学习的目的就是要找到能使长期累积奖赏最大化的策略。
强化学习与监督学习来说,强化学习是没有人直接告诉机器在什么状态下应该做什么动作,只有等到最终结果揭晓,才能通过“反思”之前的动作是否正确来进行学习,因此,强化学习在某种意义上可看作具有“延迟标记信息”的监督学习问题。
强化学习任务的最终奖赏是在多步动作之后才能观察到,这里考虑简单情形:最大化单步奖赏,即仅考虑一步操作。单步强化学习任务对应了一个理论模型:k-摇臂赌博机。
k- 摇臂赌博机:有k个摇臂,赌徒在投入一个硬币后可选择按下其中一个摇臂,每个摇臂以一定的概率吐出硬币,但这个概率赌徒并不知道。赌徒的目标是通过一定的策略最大化自己的奖赏,即获得最多的硬币。
若仅为获知每个摇臂的期望奖赏,则可采用“仅探索”法:将所有的尝试机会平均分配给每个摇臂,最后以每个摇臂各自的平均吐币概率作为其奖赏的近似评估。若仅为执行奖赏最大的动作,则可采用“仅利用”法:按下目前最优的摇臂。“仅探索”法会失去很多选择最优摇臂的机会;“仅利用”法可能经常选不到最优摇臂。
ϵ \epsilon ϵ贪心法是基于一个概率来对探索和利用进行折中:每次尝试时,以 ϵ \epsilon ϵ的概率进行探索,以 1 − ϵ 1 - \epsilon 1−ϵ的概率进行利用。
则平均奖赏为:
Q ( k ) = 1 n ∑ i = 1 n v i Q(k) = \frac{1}{n} \sum_{i=1}^nv_i Q(k)=n1i=1∑nvi
可以改成增量计算:
Q n ( k ) = 1 n ( ( n − 1 ) × Q n − 1 ( k ) + v n ) = Q n − 1 ( k ) + 1 n ( v n − Q n − 1 ( k ) ) Q_n(k) = \frac {1}{n} ( (n - 1) \times Q_{n-1}(k) + v_n) \\ = Q_{n-1}(k) + \frac{1}{n}(v_n - Q_{n-1}(k)) Qn(k)=n1((n−1)×Qn−1(k)+vn)=Qn−1(k)+n1(vn−Qn−1(k))
代码
k-摇臂赌博机实现:
import numpy as npclass KArmedBandit:def __init__(self, k=10, true_reward_mean=0, true_reward_std=1):"""k: 摇臂数量true_reward_mean: 奖励均值的均值true_reward_std: 奖励均值的标准差"""self.k = kself.q_true = np.random.normal(true_reward_mean, true_reward_std, k) # 每个摇臂的真实均值def step(self, action):"""执行动作(拉某个摇臂),返回奖励"""reward = np.random.normal(self.q_true[action], 1) # 以 q*(a) 为均值的正态分布return rewardϵ \epsilon ϵ贪心实现:
from data_processing import KArmedBandit
import numpy as np
import matplotlib.pyplot as pltdef select_action(epsilon:float, q_estimates:np.ndarray):"""根据 epsilon-greedy 策略选择动作"""if np.random.rand() < epsilon: # 随机选择return np.random.choice(len(q_estimates)) # else:return np.argmax(q_estimates) # 选择估计奖励最高的动作
def update_estimates(q_estimates:np.ndarray, action:int, reward:float, action_counts:np.ndarray):"""更新动作的估计奖励"""action_counts[action] += 1q_estimates[action] += (reward - q_estimates[action]) / action_counts[action]return q_estimates, action_countsdef start(k:int, epsilon:float, epochs:int, stps:int):"""开始运行 epsilon-greedy 算法"""q_estimates = np.zeros(k) # 每个摇臂的估计奖励action_counts = np.zeros(k) # 每个摇臂被选择的次数avg_rewards = np.zeros(stps) # 记录每次拉摇臂的奖励for epoch in range(epochs):bandit = KArmedBandit(k)rewards = []for step in range(stps):action = select_action(epsilon, q_estimates)reward = bandit.step(action)q_estimates, action_counts = update_estimates(q_estimates, action, reward, action_counts)rewards.append(reward) # 记录奖励avg_rewards += np.array(rewards) # 记录每次拉摇臂的奖励avg_rewards /= epochsreturn avg_rewardsif __name__ == '__main__':k = 10epsilon = 0.1epochs = 2000stps = 1000avg_rewards = start(k, epsilon, epochs, stps)plt.plot(avg_rewards)plt.xlabel('Steps')plt.ylabel('Average reward')plt.title('RL: epsilon-greedy Performance')plt.show()

深入理解强化学习(一)- 概念和术语 - 知乎 (zhihu.com)
相关文章:
机器学习:强化学习的epsilon贪心算法
强化学习(Reinforcement Learning, RL)是一种机器学习方法,旨在通过与环境交互,使智能体(Agent)学习如何采取最优行动,以最大化某种累积奖励。它与监督学习和无监督学习不同,强调试错…...

MongoDB—(一主、一从、一仲裁)副本集搭建
MongoDB集群介绍: MongoDB 副本集是由多个MongoDB实例组成的集群,其中包含一个主节点(Primary)和多个从节点(Secondary),用于提供数据冗余和高可用性。以下是搭建 MongoDB 副本集的详细步骤&am…...

MyBatis TypeHandler 详解与实战:FastJson 实现字符串转 List
在 MyBatis 中,TypeHandler 是实现 Java 类型与数据库类型双向转换 的核心组件。无论是处理基础数据类型还是复杂的 JSON、枚举或自定义对象,它都能通过灵活的扩展机制满足开发需求。本文将通过一个 将数据库 JSON 字符串转换为 List<User> 的案例…...
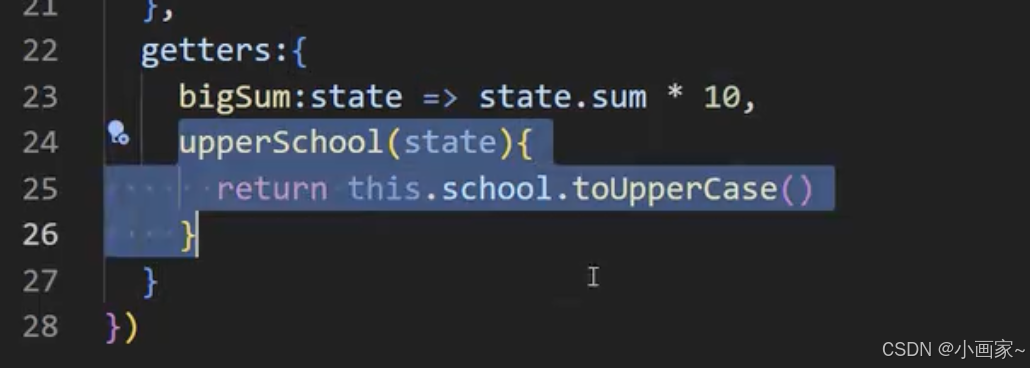
第二十八:5.5.【storeToRefs】5.6.【getters】
LoveTalk.vue: 调用: // 方法 const talkStore useTalkStore() function getLoveTalk(){ talkStore.getATalk() } 如果是要简短的形式调用: const talkStore useTalkStore() // user hooks 的形式调用 const {schoole,local} talkStore // …...

APISIX Dashboard上的配置操作
文章目录 登录配置路由配置消费者创建后端服务项目配置上游再创建一个路由测试 登录 http://192.168.10.101:9000/user/login?redirect%2Fdashboard 根据docker 容器里的指定端口: 配置路由 通过apisix 的API管理接口来创建(此路由,直接…...

MinIO在 Docker中修改登录账号和密码
MinIO在 Docker中修改登录账号和密码 随着云计算和大数据技术的快速发展,对象存储服务逐渐成为企业数据管理的重要组成部分。MinIO 作为一种高性能、分布式的对象存储系统,因其简单易用、高效可靠的特点而备受开发者青睐。然而,在实际应用中…...

英文论文查重,Turnitin和IThenticate两个系统哪个更合适?
Turnitin系统和IThenticate系统都是检测英文论文的查重系统,但是两者之间还是有一些不一样的。 下面针对这两个系统给大家具体分析一下。 一、Turnitin系统 Turnitin检测系统: https://truth-turnitin.similarity-check.com Turnitin是世界上主流的…...

pnpm的基本用法
以下是 pnpm 的核心命令和使用指南,涵盖从安装依赖到项目管理的常见操作: 1. 基础命令 (1) 安装依赖 pnpm install # 安装 package.json 中的所有依赖 pnpm install <包名> # 安装指定包(自动添加到 dependencies…...

【实战中提升自己】防火墙篇之双ISP切换与VRRP切换对于用户的体验
! 拓扑与说明 某公司的网络架构,这样的架构在目前的网络中是在常见的,假设您接收一个这样的网络,应该如何部署,该实战系列,就是一步一步讲解,如何规划、设计、部署这样一个环境,这…...

Go在1.22版本修复for循环陷阱
记录 前段时间升级Go版本碰到一个大坑,先记录。 先上代码案例: func main() {testClosure() }func testClosure() {for i : 0; i < 5; i {defer func() {fmt.Println(i)}()} }在1.22之下(不包括1.22)版本: 输出的…...

Nginx+PHP+MYSQL-Ubuntu在线安装
在 Ubuntu 上配置 Nginx、PHP 和 MySQL 的步骤如下: 1. 更新系统包 首先,确保系统包是最新的: sudo apt update sudo apt upgrade2. 安装 Nginx 安装 Nginx: sudo apt install nginx启动并启用 Nginx 服务: sudo…...

SpringDataJPA使用deleteAllInBatch方法逻辑删除失效
概述 在使用Spring Boot JPA时,执行批量删除操作时,遇到逻辑删除失效的问题。具体而言,当使用deleteAllInBatch方法时,数据会被物理删除,而不是进行逻辑删除;但是当使用deleteAll时,逻辑删除操…...

DOM Node
DOM Node 引言 在Web开发中,DOM(Document Object Model)节点是构建网页和交互式应用程序的核心。DOM节点是文档的构建块,可以用来表示HTML和XML文档中的任何部分。本文将详细介绍DOM节点的基本概念、类型、操作方法以及在实际开发中的应用。 什么是DOM节点? DOM节点是…...

基于STM32的智能家居能源管理系统
1. 引言 传统家庭能源管理存在能耗监控粗放、设备联动不足等问题,难以适应绿色低碳发展需求。本文设计了一款基于STM32的智能家居能源管理系统,通过多源能耗监测、负荷预测与优化调度技术,实现家庭能源的精细化管理与智能优化,提…...

智慧园区后勤单位消防安全管理:安全运营和安全巡检
//智慧园区消防管理困境大曝光 智慧园区,听起来高大上,但消防管理却让人头疼不已。各消防子系统各自为政,像一座座孤岛,信息不共享、不协同。 消防设施管理分散,不同区域、企业的设备标准不一样,维护情况…...

HTML 日常开发常用标签
文章目录 HTML 日常开发常用标签1、基本结构标签2、内容标签3、多媒体标签4、表单标签5、列表和定义标签6、表格标签7、链接和图像8、元数据9、语义化标签(HTML5新增)10、框架和内联11、交互12、过时或不推荐使用的标签 HTML 日常开发常用标签 1、基本结…...

Spring事务失效六大场景
引言 Spring事务一般我们采用注解实现,但是我们构造事务实现的时候常常没察觉失效的情况,本篇文章总结事务失效的六大情况,帮助我们深刻理解事务失效的边界概念 1. 方法自调用 这个主要是针对声明式事务的,经过前面的介绍&…...
)
【缓冲区】数据库备份的衍生问题,缓冲区在哪里?JVMor操作系统?(二)
【缓冲区】数据库备份的衍生问题,缓冲区在哪里?JVMor操作系统?(二 完结) 缓冲区既属于操作系统,也属于 JVM,具体取决于你讨论的是哪个层面的缓冲区。下面我会详细解释这两者的区别和联系。 1. …...

如何免费使用稳定的deepseek
0、背景: 在AI辅助工作中,除了使用cursor做编程外,使用deepseek R1进行问题分析、数据分析、代码分析效果非常好。现在我经常会去拿行业信息、遇到的问题等去咨询R1,也给了自己不少启示。但是由于官网稳定性很差,很多…...

钉钉小程序(企业内部应用)开发--钉钉小程序web-view嵌套H5与小程序之间的通信(H5跳转钉钉小程序小程序postMessage)
钉钉小程序代码:嵌套H5 pages/login/index.axml <web-view src"{{urlH5}}" onMessage"test"></web-view> H5向小程序发送信息: H5代码: 通过以下代码我一直报错dd没有被定义 if (navigator.userAgent.to…...

为什么92%的Sora 2初学者卡在第4步?——帧一致性崩塌诊断工具包+时间轴锚点校准法
更多请点击: https://kaifayun.com 第一章:Sora 2视频生成的核心原理与环境准备 Sora 2并非OpenAI官方发布的模型,而是社区基于Sora技术理念构建的开源复现与增强框架,其核心依托于时空联合建模的扩散变换器(Spacetim…...

别再死记硬背了!用Multisim仿真+图解,5分钟搞懂三极管共射放大电路工作原理
用Multisim仿真图解5分钟掌握三极管共射放大电路三极管共射放大电路是电子技术中最基础也最关键的电路之一,但传统教材中复杂的公式推导和静态图解往往让初学者望而生畏。本文将带你用Multisim仿真软件,通过可视化的方式直观理解电路工作原理,…...

Kerberos身份认证原理与实战排错指南
1. 为什么今天还要花时间搞懂 Kerberos?——一个被低估的“老协议”正在悄悄支撑着你的日常你每天登录公司内网查邮件、访问财务系统提交报销、用 Jenkins 构建代码、甚至在 Windows 域环境中打开一台同事的共享文件夹……这些看似顺滑的操作背后,大概率…...

政企数据安全:危机与出路
随着数字化转型的浪潮席卷全球,公共部门积累的数据量呈爆炸式增长。从公民个人信息到公共服务记录,从财政预算到基础设施管理数据——这些宝贵资源在提升政府治理效率的同时,也悄然成为网络犯罪分子的“新猎物”。当公共数据逐渐成为数字时代…...

从入门到实践:EEG公开数据集分类与应用场景全解析
1. EEG公开数据集入门指南刚接触脑电信号分析的研究者,常常会被一个问题困扰:"我应该从哪里获取可靠的EEG数据?"作为一个在这个领域摸爬滚打多年的研究者,我完全理解这种困惑。记得我第一次接触EEG研究时,光…...

PlayAI语音合成质量到底如何?12款竞品横向对比+5项MOS/LSD/STOI硬指标揭榜
更多请点击: https://kaifayun.com 第一章:PlayAI语音合成质量评测报告 PlayAI 是一款面向开发者与内容创作者的实时语音合成(TTS)服务,支持多语种、多音色及情感可控输出。本报告基于客观可复现的评测流程࿰…...

AI圈神秘领袖Ilya一幅画引爆全网,OpenAI三件大事暗示AGI时代将至?
AI圈神秘精神领袖Ilya在Instagram上传一幅画引发疯狂解读,与此同时,OpenAI连续公布数学成果、升级Codex、筹备IPO,释放AGI到来的强烈信号。Ilya画作引猜测Ilya上传的画中,罗丹的「思考者」踩在芯片Die Shot上,右下角签…...
)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战) 在游戏开发团队中,版本控制系统是协作的基石,但传统工具如SVN往往让非技术成员望而生畏。当美术资源频繁更新、策划案不断迭代时&…...

艾尔登法环存档迁移终极指南:3分钟解决角色转移难题
艾尔登法环存档迁移终极指南:3分钟解决角色转移难题 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 还在为《艾尔登法环》存档版本不兼容而烦恼吗?EldenRingSaveCopier 是你的终极解决…...

【python】ImportError: DLL load failed while importing QtWidgets: 找不到指定的程序。重新安装后搞定
文章目录前言一、PyQt6引用后报错二、使用步骤总结前言 想做个好看的界面,引用了PyQt6,却产生了新问题。 pip install pyqt6-tools,优先做这个动作进行修复。 一、PyQt6引用后报错 python里引用: from PyQt6.QtWidgets import…...