学习路程八 langchin核心组件 Models补充 I/O和 Redis Cache
前序
之前了解了Models,Prompt,但有些资料又把这块与输出合称为模型输入输出(Model I/O):这是与各种大语言模型进行交互的基本组件。它允许开发者管理提示(prompt),通过通用接口调用语言模型,并从模型输出中提取信息。简单来说,这个组件负责与大语言模型“对话”,将请求传递给模型,并接收回复。
这篇文章就补充一下这个O(output)的内容。
输出解释器
Output Parsers(输出解析器),是langchain中提供给我们对模型响应内容进行格式化输出的。LLM的输出为文本,但在程序中除了显示文本,如果希望获得更多不同的结构化数据时,就可以使用langchain提供的输出解析器(Output Parsers)来完成了。输出解析器(Output Parsers)实际上就是结构化语言模型提供的响应处理工具类,其提供了如下两个方法给开发者使用,也是这些响应类必须实现的两个方法:
get_format_instructions() -> str :返回一个包含语言模型如何格式化输出的指令字符串。
invoke()-> Any:接受一个结构化言模型的响应对象,并将其解析为指定格式
Str输出解析器
import os
from langchain_deepseek import ChatDeepSeek
from langchain.prompts import PromptTemplate# 初始化模型
os.environ['DEEPSEEK_API_KEY'] = "sk-e2xxx"
chat_model = ChatDeepSeek(model="deepseek-chat",temperature=0.4,max_tokens=None,timeout=None,max_retries=2,)# 创建提示模板
prompt_template = PromptTemplate(input_variables=["context"],template="基于给定的文案,以幽默诙谐的风格生成一段回答文本:{context}",
)# 使用模型生成文本
context = "成都今天出太阳了,天气真好,我们翘班出去玩吧。"
prompt = prompt_template.format(context=context)
result = chat_model.invoke(prompt)
print(result)
回答内容很长,但是我们需要的只有content那串。引入StrOutputParser,把返回的结果,经过解析,就只有文本结果内容了
...
from langchain_core.output_parsers import StrOutputParser
res = StrOutputParser().invoke(input=result)
print(res)

List输出解析器
import os
from langchain_deepseek import ChatDeepSeek# 初始化模型
os.environ['DEEPSEEK_API_KEY'] = "sk-e24324xxx"
chat_model = ChatDeepSeek(model="deepseek-chat",temperature=0.4,max_tokens=None,timeout=None,max_retries=2,)
from langchain_core.output_parsers import CommaSeparatedListOutputParser
from langchain_core.prompts import PromptTemplateparser = CommaSeparatedListOutputParser()prompt = PromptTemplate.from_template(template="请列出5个{item}的不同叫法.\n{format_instructions}\n",partial_variables={"format_instructions": parser.get_format_instructions()},
)messages = prompt.invoke({'item': '土豆'})
print(messages)result = chat_model.invoke(messages)
res = parser.invoke(result)
print(res)"""
text='请列出5个土豆的不同叫法.\nYour response should be a list of comma separated values, eg: `foo, bar, baz` or `foo,bar,baz`\n'
['马铃薯', '洋芋', '土豆', '薯仔', '地蛋']
"""
Json输出解释器
其他内容大差不差,把 CommaSeparatedListOutputParser换成JsonOutputParser就行
from pydantic import BaseModel, Field
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplateclass JsonParser(BaseModel):question: str = Field(description='问题')answer: str = Field(description='答案')parser = JsonOutputParser(pydantic_object=JsonParser)prompt = PromptTemplate(template="回答问题.\n{format_instructions}\n{query}\n",input_variables=["query"],partial_variables={"format_instructions": parser.get_format_instructions()},
)# print(parser.get_format_instructions())messages = prompt.invoke({'query': '讲一个脑筋急转弯的问题和答案。'})
response = chat_model.invoke(messages)
content = parser.invoke(response)
print(content) """
{'question': '什么东西越洗越脏?', 'answer': '水'}
"""
stream输出解析器
如果输出内容很长,一直等处理完才返回结果也不大好,比如我们正常使用在线大模型,它都是几个字几个字往外吐的,不是最后直接给答案。
这里就需要用到stream输出解析器
import os
from langchain_deepseek import ChatDeepSeek# 初始化模型
os.environ['DEEPSEEK_API_KEY'] = "sk-e24xxx"
chat_model = ChatDeepSeek(model="deepseek-chat",temperature=0.4,max_tokens=None,timeout=None,max_retries=2,)from langchain_ollama.llms import OllamaLLM
from langchain_core.prompts import PromptTemplateprompt_template = PromptTemplate.from_template("你是一名名经验丰富的{role},{ability},{prompt}")
messages = prompt_template.invoke({"role": "修仙小说作家", "ability": "熟悉各种神话传说和修仙小说","prompt": "请你写一部与牧神记类似的小说,要求:全书至少600章,每一章字数在8000字以上,剧情紧凑,各个角色的个性分明"})
print(messages)for chunk in chat_model.stream(messages):print(chunk, end="", flush=True)

或者这样不好看,也可以用上面的字符串输出解释器来处理一下输出内容
from langchain_core.output_parsers import StrOutputParser# 修改一下输出这里
for chunk in chat_model.stream(messages):print(StrOutputParser().invoke(chunk), end="", flush=True)

到这里,就就开始慢慢帮我们写小说了。
Cache
如果每次问同样的,都调用大模型推理,那么会比较耗💰,可以把问题和答案记录下来,以后遇到同样的问题,则不必再使用大模型推理。
基于langchain提供的输出缓存,让LLM在遇到同一prompt时,直接调用缓存中的结果,也可以达到加速的效果。
# -*- coding: utf-8 -*-
# @Author : John
# @Time : 2025/02/27
# @File : langchain_cache.pyimport time
import redis
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
# from langchain_community.cache import InMemoryCache # 把输出缓存到内存中
from langchain_community.cache import RedisCache # 把输出缓存到Redis数据库中
from langchain.globals import set_llm_cacheimport os
from langchain_deepseek import ChatDeepSeek# 初始化模型
os.environ['DEEPSEEK_API_KEY'] = "sk-e243xxxf"
chat_model = ChatDeepSeek(model="deepseek-chat",temperature=0.4, # temperature 温度值,数值越趋向0,回答越谨慎,数值越趋向1,回答则越脑洞大开,主要控制大模型输出的创造力max_tokens=None,timeout=None,max_retries=2,)prompt_template = PromptTemplate.from_template("你是一个产品顾问。请给公司刚生产出来的 {production},取一个好听的名字和广告语。")
messages = prompt_template.invoke({"production": "充电宝"})# 开启缓存
redis = redis.Redis("localhost", port=6379, password="qwe123", db=2)
set_llm_cache(RedisCache(redis))timers = []
for _ in range(5):t1 = time.time()response = chat_model.invoke(messages)t2 = time.time()print(t2 - t1, response)timers.append(t2 - t1)print(timers)
可以看到输出结果都是一致的。只有第一次真正请求了deepseek,花了65s获得了结果,后面都是第一次结果保存到redis,从redis获取的。

相关文章:
学习路程八 langchin核心组件 Models补充 I/O和 Redis Cache
前序 之前了解了Models,Prompt,但有些资料又把这块与输出合称为模型输入输出(Model I/O):这是与各种大语言模型进行交互的基本组件。它允许开发者管理提示(prompt),通过通用接口调…...

图书数据采集:使用Python爬虫获取书籍详细信息
文章目录 一、准备工作1.1 环境搭建1.2 确定目标网站1.3 分析目标网站二、采集豆瓣读书网站三、处理动态加载的内容四、批量抓取多本书籍信息五、反爬虫策略与应对方法六、数据存储与管理七、总结在数字化时代,图书信息的管理和获取变得尤为重要。通过编写Python爬虫,可以从各…...

【DeepSeek系列】05 DeepSeek核心算法改进点总结
文章目录 一、DeepSeek概要二、4个重要改进点2.1 多头潜在注意力2.2 混合专家模型MoE2.3 多Token预测3.4 GRPO强化学习策略 三、2个重要思考3.1 大规模强化学习3.2 蒸馏方法:小模型也可以很强大 一、DeepSeek概要 2024年~2025年初,DeepSeek …...
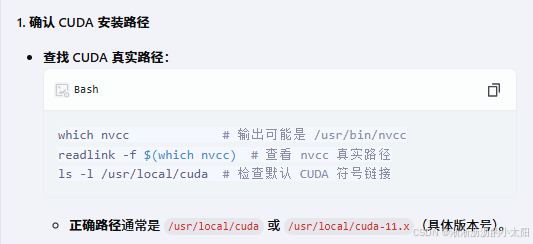
安装pointnet2-ops库
由于服务器没有连网,现在已在github中下载pointnet2_ops文件包并上传到服务器 (首先保证cuda版本和pytorch版本对应) 如何查找cuda的安装路径: 然后执行安装命令即可。...

DO-254航空标准飞行器电机控制器设计注意事项
DO-254航空标准飞行器电机控制器设计注意事项 1.核心要求1.1 设计保证等级(DAL)划分1.2生命周期管理1.3验证与确认2.电机控制器硬件设计的关键注意事项2.1需求管理与可追溯性2.2冗余与容错设计2.3验证与确认策略2.4元器件选型与管理2.5环境适应性设计2.6文档与配置管理3.应用…...

ABAP语言的动态程序
通过几个例子,由浅入深讲解 ABAP 动态编程。ABAP 动态编程主要通过 RTTS (Runtime Type Services) 来实现,包括 RTTI 和 RTTC: 运行时类型标识(RTTI) – 提供在运行时获取数据对象的类型定义的方法。运行时类型创建(R…...

开源电商项目、物联网项目、销售系统项目和社区团购项目
以下是推荐的开源电商项目、物联网项目、销售系统项目和社区团购项目,均使用Java开发,且无需付费,GitHub地址如下: ### 开源电商项目 1. **mall** GitHub地址:[https://github.com/macrozheng/mall](https://git…...

Docker教程(喂饭级!)
如果你有跨平台开发的需求,或者对每次在新机器上部署项目感到头疼,那么 Docker 是你的理想选择!Docker 通过容器化技术将应用程序与其运行环境隔离,实现快速部署和跨平台支持,极大地简化了开发和部署流程。本文详细介绍…...

HTML:自闭合标签简单介绍
1. 什么是自结束标签? 定义:自结束标签(Self-closing Tag)是指 不需要单独结束标签 的 HTML 标签,它们通过自身的语法结构闭合。语法形式: 在 HTML5 中:直接写作 <tag>,例如 …...

【和鲸社区获奖作品】内容平台数据分析报告
1.项目背景与目标 在社交和内容分享领域,某APP凭借笔记、视频等丰富的内容形式,逐渐吸引了大量用户。作为一个旨在提升用户互动和平台流量的分享平台,推荐算法成为其核心功能,通过精准推送内容,努力实现更高的点击率和…...

GitCode 助力 python-office:开启 Python 自动化办公新生态
项目仓库:https://gitcode.com/CoderWanFeng1/python-office 源于需求洞察,打造 Python 办公神器 项目作者程序员晚枫在运营拥有 14w 粉丝的 B 站账号 “Python 自动化办公社区” 时,敏锐察觉到非程序员群体对 Python 学习的强烈需求。在数字…...

超参数、网格搜索
一、超参数 超参数是在模型训练之前设置的,它们决定了训练过程的设置和模型的结构,因此被称为“超参数”。以KNN为例: 二、网格搜索 交叉验证(Cross-Validation)是在机器学习建立模型和验证模型参数时常用的方法&…...

or-tools编译命令自用备注
cmake .. -G "Visual Studio 17 2022" -A Win32 //vs2022 cmake .. -G "Visual Studio 15 2017" -A Win32 //vs2017 -DBUILD_DEPSON //联网下载 -DCMAKE_INSTALL_PREFIXinstall //带安装命令 -DCMAKE_CXX_FLAGS"/u…...
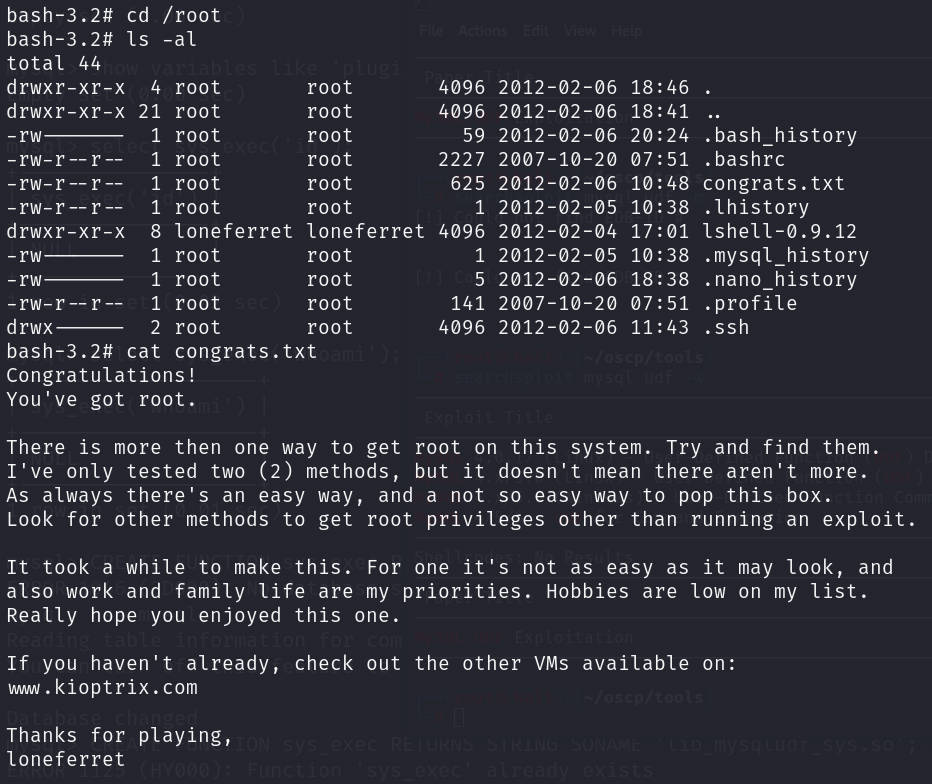
vulnhub靶场【kioptrix-4】靶机
前言 靶机:kioptrix-4,IP地址为192.168.1.75,后期IP地址为192.168.10.8 攻击:kali,IP地址为192.168.1.16,后期IP地址为192.168.10.6 都采用VMware虚拟机,网卡为桥接模式 这里的靶机…...

readline模块详解!!【Node.js】
“书到用时方恨少,事非经过不知难。” —— 陆游 目录 readline 是什么?基本用法:创建 Interface 类:核心流程: Interface 类的关键事件:line:close:pause:…...

软件测试的七大误区
随着软件测试对提高软件质量重要性的不断提高,软件测试也不断受到重视。但是,国内软件测试过程的不规范,重视开发和轻视测试的现象依旧存在。因此,对于软件测试的重要性、测试方法和测试过程等方面都存在很多不恰当的认识…...

【欢迎来到Git世界】Github入门
241227 241227 241227 Hello World 参考:Hello World - GitHub 文档. 1.创建存储库 r e p o s i t o r y repository repository(含README.md) 仓库名需与用户名一致。 选择公共。 选择使用Readme初始化此仓库。 2.何时用分支…...

解决 Ubuntu 24.04 虚拟机内无法ping 通 Hostname 的问题
问题背景 在 VMware 或 VirtualBox 中安装 Ubuntu 24.04 虚拟机时,遇到无法通过主机名(Hostname)进行网络通信的问题。例如,将虚拟机的主机名设置为 001,执行 ping 001 时返回 ping 0.0.0.1 并超时。此问题通常由 主机…...

给小白的oracle优化工具,了解一下
有时懒得分析或语句太长,可以尝试用oracle的dbms_sqldiag包进行sql优化, --How To Use DBMS_SQLDIAG To Diagnose Query Performance Issues (Doc ID 1386802.1) --诊断SQL 性能 SET ECHO ON SET LINESIZE 132 SET PAGESIZE 999 SET LONG 999999 SET SER…...

CT技术变迁史——CT是如何诞生的?
第一代CT(平移-旋转) X线球管为固定阳极,发射X线为直线笔形束,一个探测器,采用直线和旋转扫描相结合,即直线扫描后,旋转1次,再行直线扫描,旋转180完成一层面扫描,扫描时间3~6分钟。矩阵象素256256或320320。仅用于颅脑检查。 第二代CT (平移-旋转) 与第一代无质…...

机器学习原子间势与连续介质模型在柔性InSe扭转双层原子重构研究中的应用
1. 项目概述:当柔性二维材料遇上扭转角在二维材料的世界里,一个简单的“扭转”操作,往往能打开一扇通往新奇物理现象的大门。从魔角石墨烯中发现的超导和关联绝缘态,到过渡金属硫族化合物(TMDs)中的莫尔激子…...

对比直接使用原厂API,Taotoken在计费透明性上给我们的感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用原厂API,Taotoken在计费透明性上给我们的感受 在集成大模型能力到业务系统的过程中,API调用成…...
)
DeepSeek长上下文能力解密(官方未公开的context-aware attention调度机制)
更多请点击: https://codechina.net 第一章:DeepSeek长上下文能力解密(官方未公开的context-aware attention调度机制) DeepSeek系列模型在128K token上下文场景中展现出远超同规模模型的稳定性与推理一致性,其核心并…...

告别古板前端界面,这个 Github 狂揽 8.1万 Star 的 UI 开源项目,让你 AI 生成的 UI 界面审美直接拉满
大家好,我是Java1234_小锋老师。 先说结论:它到底解决什么问题? 如果你经常用 AI 写前端页面,大概率遇到过这种场景: 你说「帮我做一个 SaaS 落地页」,AI 确实能跑起来,但出来的界面总有点「…...

3个步骤解锁《塞尔达传说:旷野之息》终极存档编辑器
3个步骤解锁《塞尔达传说:旷野之息》终极存档编辑器 【免费下载链接】BOTW-Save-Editor-GUI A Work in Progress Save Editor for BOTW 项目地址: https://gitcode.com/gh_mirrors/bo/BOTW-Save-Editor-GUI 想象一下,当你在海拉鲁大陆冒险时&…...
:3个隐藏技能断层导致输出质量长期停滞)
AI视频生成“假熟练”陷阱(83%用户未察觉):3个隐藏技能断层导致输出质量长期停滞
更多请点击: https://kaifayun.com 第一章:AI视频生成工具学习曲线分析 AI视频生成工具的学习曲线呈现出显著的非线性特征:初学者可在数小时内完成基础视频合成,但要稳定产出符合商业标准的高质量内容,通常需跨越模型…...

终极指南:如何用roop-unleashed三分钟制作专业AI换脸视频
终极指南:如何用roop-unleashed三分钟制作专业AI换脸视频 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 你是否曾梦想过轻松制作专业级的AI换脸…...

3分钟快速上手:Unpaywall一键免费解锁学术论文付费墙
3分钟快速上手:Unpaywall一键免费解锁学术论文付费墙 【免费下载链接】unpaywall-extension Firefox/Chrome extension that gives you a link to a free PDF when you view scholarly articles 项目地址: https://gitcode.com/gh_mirrors/un/unpaywall-extension…...

TestDisk PhotoRec:免费开源数据恢复工具的终极完整指南
TestDisk & PhotoRec:免费开源数据恢复工具的终极完整指南 【免费下载链接】testdisk TestDisk & PhotoRec 项目地址: https://gitcode.com/gh_mirrors/te/testdisk 当您不小心删除了重要文件,或者硬盘分区突然消失时,那种恐慌…...
:从草稿到发布仅需11分钟)
AI新闻稿写作实战手册(含新华社/财新/36氪真实信源对照表):从草稿到发布仅需11分钟
更多请点击: https://codechina.net 第一章:AI新闻稿写作实战手册(含新华社/财新/36氪真实信源对照表):从草稿到发布仅需11分钟 三步完成合规新闻稿生成 使用本地部署的 Llama-3.1-70B-Instruct 模型配合结构化提示工…...