例子 DQN + CartPole: 深入思考一下,强化学习确实是一场智能冒险之旅!
强化学习的概念
在技术人员眼里,深度学习、强化学习,或者是大模型,都只是一些算法。无论是简单,还是复杂,我们都是平静的看待。当商业元素日益渗透进技术领域,人人言必称大模型的时候。技术人该反思一下,是否确实是我们自己太乏味了。今天在翻看强化学习的时候,它确实是机器学习领域里非常重要的一个方面,如何描述它的概念,可以让普罗大众知道它的价值呢?尝试不要用学术化或者技术化的语言,试试标题党的口吻,可能更好理解。
夸张地描述强化学习

哇塞!听好了哈,强化学习简直就是一场超级疯狂、令人惊掉下巴的智能冒险之旅!
想象一下,有个超级聪明的 “小家伙”,它就像一个充满好奇的探险家,被扔进了一个千变万化、神秘莫测的奇妙世界。这个世界里到处都是复杂的规则、隐藏的陷阱和闪闪发光的宝藏。而强化学习,就是赋予这个 “小家伙” 一套超绝的生存秘籍,让它能在这个疯狂世界里摸爬滚打,不断探索。
它可不是瞎闯哦!每一次行动,不管是成功还是失败,都会得到世界给予的或大或小、或甜或苦的 “反馈”。就好像在玩一场超大型的、没有尽头的电子游戏,每一次操作,游戏都会告诉你是得分了还是被扣分了。而这个 “小家伙”,就靠着这些反馈,像个疯狂的学习机器一样,不断调整自己的行为。
它会不断尝试新的路径,从一次次的跌倒中爬起来,总结经验,变得越来越聪明,越来越厉害!在强化学习的神奇魔力下,这个 “小家伙” 从最初的懵懂无知,到最后能像武林高手一样,在这个复杂世界里游刃有余,精准地找到那些隐藏在深处的宝藏,避开所有危险,这能力简直逆天!它就像是一个自学成才的超级英雄,在强化学习的神奇力量加持下,一步步成长为能征服任何复杂环境的无敌存在,简直是智能领域里最让人拍案叫绝、目瞪口呆的奇迹啦!
正统的描述强化学习

强化学习是机器学习中的一个重要分支,它主要研究智能体(agent)如何在环境中采取一系列行动,以最大化累积奖励。以下是对强化学习定义的具体介绍:
主体与环境
智能体:可以是机器人、软件程序或其他能够感知环境并执行动作的实体。智能体具有自主性,能够根据自身的策略决定在每个时刻采取何种行动。
环境:是智能体所处的外部世界,它包含了各种状态和规则。环境会根据智能体采取的行动发生变化,并向智能体反馈相应的奖励信号。
核心要素
状态:用于描述环境在某一时刻的状况。例如在机器人导航任务中,机器人的位置、周围障碍物的分布等信息构成了环境的状态。智能体通过感知环境来获取当前状态。
动作:智能体在每个状态下可以采取的行为。比如在游戏中,智能体可能的动作包括上下左右移动、攻击、跳跃等。智能体根据自身的策略选择要执行的动作。
奖励:是环境给予智能体的反馈信号,用于衡量智能体在某一时刻采取的动作的好坏。奖励可以是正的(表示动作得到了积极的反馈)、负的(表示动作导致了不好的结果)或零。智能体的目标是最大化长期累积奖励。
策略:是智能体根据当前状态选择动作的规则或函数。策略可以是确定性的,即对于每个状态都有唯一确定的动作;也可以是随机性的,根据一定的概率分布选择动作。智能体通过学习不断调整策略,以获得更多的奖励。
学习过程
强化学习的过程就是智能体与环境不断交互的过程。在每个时间步,智能体观察当前环境的状态,根据自己的策略选择一个动作并执行。环境接收到动作后,会转移到一个新的状态,并根据新状态和动作给智能体返回一个奖励。智能体根据这个奖励和新状态来更新自己的策略,以便在未来能够采取更好的行动,获得更多的奖励。通过不断地重复这个过程,智能体逐渐学习到在不同状态下应该采取什么动作,以实现长期奖励的最大化。
强化学习广泛应用于机器人控制、游戏、自动驾驶、资源管理等众多领域,为解决复杂的决策问题提供了一种有效的方法。
DQN + CartPole
DQN
DQN(Deep Q-Network)算法是一种将深度神经网络与 Q-learning 算法相结合的强化学习算法,它利用深度神经网络来逼近 Q 函数,能够自动学习从环境状态到最优动作价值的映射,从而让智能体在复杂的环境中通过不断试错来学习并选择最优的行为策略以最大化长期累积奖励,其具有能够处理高维感知数据、有效学习复杂环境中的最优策略等优点,在游戏、机器人控制等多个领域有广泛应用。

DQN 是深度学习和强化学习结合的一个算法。在没有深度学习的强化学习体系中,模型的状态和对应的动作是用表(或者其它形式)来记录。而有了深度学习,就可以用神经网络来记忆了,因此也就和深度学习结合起来了。深度神经网络,可以看成是一个黑盒,这个黑盒具有记忆的功能。但这个黑盒的记忆,有时不是完全准确的,它有一定的概率出错。这个实际和人类的记忆是一样的。人类的记忆是不完全准确的,偶尔会出现错误。这是因为人类记忆的形成、存储和提取过程受到多种因素的影响,比如记忆容易受到情绪、期望、暗示等因素的干扰,导致记忆内容出现偏差,像目击证人在回忆事件时可能会因为事后他人的提问方式等产生错误记忆;记忆还会随着时间的推移而逐渐模糊和失真,人们可能会遗忘一些细节,或者将不同事件的记忆混淆在一起;此外,个体的认知能力、知识经验等也会影响记忆的准确性,人们可能会根据自己的经验和理解对记忆进行重构,从而产生错误。
既然如此,为什么要用神经网络?
DQN 是在 Q-learning 上加入深度神经网络得到的,比较他们两者的差异,就可以明白其中的原因。
DQN(Deep Q-Network)算法相比Q-learning算法有以下几方面优势:
处理高维数据能力更强
- Q-learning:通常使用表格来存储状态-动作值函数(Q值),对于状态空间和动作空间较小的问题能很好地工作,但当状态空间维度很高时,表格的规模会呈指数级增长,导致存储和计算成本极高,甚至难以处理。
- DQN:引入了深度神经网络,能够自动提取高维数据中的特征,将原始的高维状态映射到一个低维的特征空间中进行处理,大大降低了数据处理的复杂度,使其可以应用于像图像、语音等复杂的高维数据输入的场景,比如在Atari游戏中,能直接以游戏画面作为输入来学习最优策略。
泛化能力更好
- Q-learning:依赖于对每个具体状态-动作对的Q值进行估计和更新,对未曾经历过的状态-动作对,只能通过插值等方法进行估计,泛化能力有限。
- DQN:深度神经网络具有强大的函数拟合能力,通过学习大量的状态-动作样本,能够捕捉到状态之间的相似性和规律性,从而对从未见过的新状态也能给出合理的Q值估计,表现出更好的泛化能力,能在不同但相似的环境中快速适应并做出较好的决策。
CartPole
一个经典的控制理论和强化学习领域的基准问题,通常由一辆可在水平轨道上移动的小车和一个通过铰链连接在小车上的杆子组成,任务是通过控制小车的左右移动让杆子尽可能长时间地保持直立不倒,常被用于评估各种控制算法和强化学习算法的性能。

算法代码
引入相关的库,如没有,需要先安装。可以考虑安装Anaconda,不过注意公司规模要小于100人,个人学习的话没问题。IDE可以用Jupyter Notebook,或者 PyCharm,也可以是VS Code,看个人偏好。
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import random
from collections import deque
import time
下面这段代码使用 PyTorch 框架定义了一个简单的全连接神经网络类 DQN,用于实现 DQN 算法中的 Q 网络。该网络接收环境的状态作为输入,输出每个可能动作对应的 Q 值,帮助智能体在强化学习任务中选择最优动作。
class DQN(nn.Module):def __init__(self, input_dim, output_dim):super(DQN, self).__init__()self.fc1 = nn.Linear(input_dim, 64)self.fc2 = nn.Linear(64, 64)self.fc3 = nn.Linear(64, output_dim)def forward(self, x):x = torch.relu(self.fc1(x))x = torch.relu(self.fc2(x))return self.fc3(x)
DQNAgent 类封装了一个 DQN 智能体的核心功能,包括经验存储、动作选择、经验回放等。智能体通过与环境交互收集经验,利用这些经验更新 Q 网络,以学习在不同状态下的最优动作策略。
# 定义 DQN 智能体
class DQNAgent:def __init__(self, state_dim, action_dim):self.state_dim = state_dimself.action_dim = action_dimself.memory = deque(maxlen=2000)self.gamma = 0.95 # 折扣因子self.epsilon = 1.0 # 探索率self.epsilon_min = 0.01self.epsilon_decay = 0.995self.learning_rate = 0.001self.model = DQN(state_dim, action_dim)self.optimizer = optim.Adam(self.model.parameters(), lr=self.learning_rate)self.criterion = nn.MSELoss()def remember(self, state, action, reward, next_state, done):self.memory.append((state, action, reward, next_state, done))def act(self, state):if np.random.rand() <= self.epsilon:return random.randrange(self.action_dim)state = torch.FloatTensor(state).unsqueeze(0)act_values = self.model(state)action = torch.argmax(act_values).item()return actiondef replay(self, batch_size):minibatch = random.sample(self.memory, batch_size)for state, action, reward, next_state, done in minibatch:state = torch.FloatTensor(state).unsqueeze(0)next_state = torch.FloatTensor(next_state).unsqueeze(0)target = rewardif not done:target = (reward + self.gamma * torch.max(self.model(next_state)).item())target_f = self.model(state)target_f[0][action] = targetself.optimizer.zero_grad()loss = self.criterion(self.model(state), target_f)loss.backward()self.optimizer.step()if self.epsilon > self.epsilon_min:self.epsilon *= self.epsilon_decay
DQNAgent 类实现了一个基于 DQN 算法的强化学习智能体,通过经验回放和 ϵ - 贪心策略,智能体能够在与环境的交互中不断学习,逐步优化自己的动作策略。
下面代码主要包含三个部分:训练智能体的函数 train_agent、运行训练好的模型并进行图形化展示的函数 run_trained_model 以及主函数。在主函数中,首先创建 CartPole-v1 环境,然后实例化 DQNAgent 智能体,接着调用 train_agent 函数对智能体进行训练,最后调用 run_trained_model 函数运行训练好的模型并展示其表现。
# 训练智能体
def train_agent(agent, env, episodes=5, batch_size=32):for episode in range(episodes):state = env.reset()total_reward = 0done = Falsewhile not done:action = agent.act(state)next_state, reward, done, _ = env.step(action)agent.remember(state, action, reward, next_state, done)state = next_statetotal_reward += rewardif len(agent.memory) > batch_size:agent.replay(batch_size)print(f"Episode: {episode + 1}/{episodes}, Reward: {total_reward}")return agent# 运行训练好的模型并进行图形化展示
def run_trained_model(agent, env, episodes=50):for episode in range(episodes):state = env.reset()total_reward = 0done = Falsewhile not done:env.render()time.sleep(0.2)state = torch.FloatTensor(state).unsqueeze(0)act_values = agent.model(state)action = torch.argmax(act_values).item()next_state, reward, done, _ = env.step(action)state = next_statetotal_reward += rewardprint(f"Episode {episode + 1}: Total Reward = {total_reward}")env.close()# 主函数
if __name__ == "__main__":env = gym.make('CartPole-v1')state_dim = env.observation_space.shape[0]action_dim = env.action_space.nagent = DQNAgent(state_dim, action_dim)# 训练智能体trained_agent = train_agent(agent, env)# 运行训练好的模型run_trained_model(trained_agent, env)
整体代码
可以复制粘贴直接在 Jupyter Notebook 或者 PyCharm 里运行。
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import random
from collections import deque
import time# 定义 DQN 网络
class DQN(nn.Module):def __init__(self, input_dim, output_dim):super(DQN, self).__init__()self.fc1 = nn.Linear(input_dim, 64)self.fc2 = nn.Linear(64, 64)self.fc3 = nn.Linear(64, output_dim)def forward(self, x):x = torch.relu(self.fc1(x))x = torch.relu(self.fc2(x))return self.fc3(x)# 定义 DQN 智能体
class DQNAgent:def __init__(self, state_dim, action_dim):self.state_dim = state_dimself.action_dim = action_dimself.memory = deque(maxlen=2000)self.gamma = 0.95 # 折扣因子self.epsilon = 1.0 # 探索率self.epsilon_min = 0.01self.epsilon_decay = 0.995self.learning_rate = 0.001self.model = DQN(state_dim, action_dim)self.optimizer = optim.Adam(self.model.parameters(), lr=self.learning_rate)self.criterion = nn.MSELoss()def remember(self, state, action, reward, next_state, done):self.memory.append((state, action, reward, next_state, done))def act(self, state):if np.random.rand() <= self.epsilon:return random.randrange(self.action_dim)state = torch.FloatTensor(state).unsqueeze(0)act_values = self.model(state)action = torch.argmax(act_values).item()return actiondef replay(self, batch_size):minibatch = random.sample(self.memory, batch_size)for state, action, reward, next_state, done in minibatch:state = torch.FloatTensor(state).unsqueeze(0)next_state = torch.FloatTensor(next_state).unsqueeze(0)target = rewardif not done:target = (reward + self.gamma * torch.max(self.model(next_state)).item())target_f = self.model(state)target_f[0][action] = targetself.optimizer.zero_grad()loss = self.criterion(self.model(state), target_f)loss.backward()self.optimizer.step()if self.epsilon > self.epsilon_min:self.epsilon *= self.epsilon_decay# 训练智能体
def train_agent(agent, env, episodes=5, batch_size=32):for episode in range(episodes):state = env.reset()total_reward = 0done = Falsewhile not done:action = agent.act(state)next_state, reward, done, _ = env.step(action)agent.remember(state, action, reward, next_state, done)state = next_statetotal_reward += rewardif len(agent.memory) > batch_size:agent.replay(batch_size)print(f"Episode: {episode + 1}/{episodes}, Reward: {total_reward}")return agent# 运行训练好的模型并进行图形化展示
def run_trained_model(agent, env, episodes=50):for episode in range(episodes):state = env.reset()total_reward = 0done = Falsewhile not done:env.render()time.sleep(0.2)state = torch.FloatTensor(state).unsqueeze(0)act_values = agent.model(state)action = torch.argmax(act_values).item()next_state, reward, done, _ = env.step(action)state = next_statetotal_reward += rewardprint(f"Episode {episode + 1}: Total Reward = {total_reward}")env.close()# 主函数
if __name__ == "__main__":env = gym.make('CartPole-v1')state_dim = env.observation_space.shape[0]action_dim = env.action_space.nagent = DQNAgent(state_dim, action_dim)# 训练智能体trained_agent = train_agent(agent, env)# 运行训练好的模型run_trained_model(trained_agent, env)
相关文章:
例子 DQN + CartPole: 深入思考一下,强化学习确实是一场智能冒险之旅!
强化学习的概念 在技术人员眼里,深度学习、强化学习,或者是大模型,都只是一些算法。无论是简单,还是复杂,我们都是平静的看待。当商业元素日益渗透进技术领域,人人言必称大模型的时候。技术人该反思一下&a…...

java 实现xxl-job定时任务自动注册到调度中心
xxl-job 自动注册(执行器和任务) 前言 xxl-job是一个功能强大、简单易用、高可用且可扩展性强的分布式定时任务框架/分布式任务调度平台。它适用于各种需要定时任务调度的场景,并可根据业务需求进行灵活配置和扩展。 xxl-job简介 xxl-job是一个开源的分布式定时任务框架,…...
esp32串口通信
1、线路图 2、打开电脑的串口终端 3、eps32通过串口往电脑的串口终端输出信息: from machine import UART, Pin import time# 初始化UART0,波特率设置为115200 uart UART(0, baudrate115200, tx1, rx3)# 主循环 while True:# 要发送的消息#某些串口终…...

蓝桥杯备赛-前缀和-可获得的最小取值
问题描述 妮妮学姐手头有一个长度为 nn 的数组 aa,她想进行 kk 次操作来取出数组中的元素。每次操作必须选择以下两种操作之一: 取出数组中的最大元素。取出数组中的最小元素和次小元素。 妮妮学姐希望在进行完 kk 次操作后,取出的数的和最…...

UniApp 中封装 HTTP 请求与 Token 管理(附Demo)
目录 1. 基本知识2. Demo3. 拓展 1. 基本知识 从实战代码中学习,上述实战代码来源:芋道源码/yudao-mall-uniapp 该代码中,通过自定义 request 函数对 HTTP 请求进行了统一管理,并且结合了 Token 认证机制 请求封装原理ÿ…...

边缘计算+多模态感知:户外监控核心技术解析与工程部署实践!户外摄像头监控哪种好?户外摄像头监控十大品牌!格行视精灵VS海康威视VS大华横评!
一、核心参数解析与选型逻辑 1.环境适应性设计 极端天气防护:优先选择IP66/67防护等级的设备,例如格行视精灵通过IP67防水防尘设计可应对暴雨、沙尘暴等复杂环境,其密封轴承结构可有效防止水汽侵蚀内部电路。 温度耐受范围:北方…...

Spring项目-抽奖系统(实操项目)(ONE)
^__^ (oo)\______ (__)\ )\/\ ||----w | || || 一:前言: 随着互联网技术的快速发展,线上营销活动已成为企业吸引用户、…...

STM32-智能小车项目
项目框图 ST-link接线 实物图: 正面: 反面: 相关内容 使用L9110S电机模块 电机驱动模块L9110S详解 | 良许嵌入式 测速模块 语音模块SU-03T 网站:智能公元/AI产品零代码平台 一、让小车动起来 新建文件夹智能小车项目 在里面…...
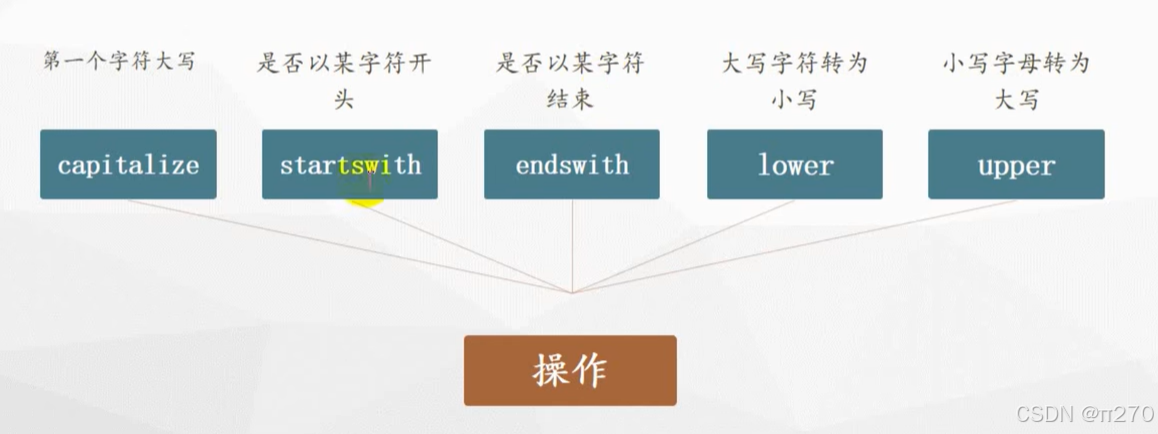
Python:字符串常见操作
find(子字符串,开始位置下标,结束位置下标) 注意:开始位置和结束位置下标可以省略,表示在整个字符串中查找 stasdfghjkl print(st.find(a))#输出结果为0,表明a在第一个位置默认从零开始,找不到则返回-1 …...
)
Redis 哈希(Hash)
Redis 哈希(Hash) 概述 Redis 哈希(Hash)是一种特殊的键值对类型,它允许存储结构化的数据,例如一个对象或记录。每个哈希值可以包含多个字段,每个字段又可以存储一个字符串值。这使得Redis哈希非常适合用于存储对象的…...

Windows对比MacOS
Windows对比MacOS 文章目录 Windows对比MacOS1-环境变量1-Windows添加环境变量示例步骤 1:打开环境变量设置窗口步骤 2:添加系统环境变量 2-Mac 系统添加环境变量示例步骤 1:打开终端步骤 2:编辑环境变量配置文件步骤 3࿱…...

react 路由跳转的几种方式
在 React 中,路由跳转通常通过 react-router-dom(或类似的路由库)来实现。以下是几种常见的路由跳转方式: 1. 使用 <Link> 组件 <Link> 是最简单的路由跳转方式,它会生成一个 <a> 标签,…...

2.你有什么绝活儿?—Java能做什么?
1、Java的绝活儿:要问Java有什么绝活,我觉得它应该算是一位魔法师,会的绝活儿有很多,要说最能拿得出手的当属以下三个。 1.1 平台无关性:Java可以在任何地方施展魔法,无论是Windows、Linux还是Mac…...

2025年2月文章一览
2025年2月编程人总共更新了17篇文章: 1.2025年1月文章一览 2.《Operating System Concepts》阅读笔记:p2-p8 3.《Operating System Concepts》阅读笔记:p9-p12 4.《Operating System Concepts》阅读笔记:p13-p16 5.《Operati…...

C++ | 面向对象 | 类
👻类 👾语法格式 class className{Access specifiers: // 访问权限DataType variable; // 变量returnType functions() { } // 方法 };👾访问权限 class className {public:// 公有成员protected:// 受保护成员private:// 私有成员 }…...

leetcode:2164. 对奇偶下标分别排序(python3解法)
难度:简单 给你一个下标从 0 开始的整数数组 nums 。根据下述规则重排 nums 中的值: 按 非递增 顺序排列 nums 奇数下标 上的所有值。 举个例子,如果排序前 nums [4,1,2,3] ,对奇数下标的值排序后变为 [4,3,2,1] 。奇数下标 1 和…...
)
Visionpro cogToolBlockEditV2.Refresh()
在 C# 中使用 cogToolBlockEditV2.Refresh() 方法主要用于刷新 CogToolBlockEditV2 控件的显示状态,适用于动态更新界面或重新加载工具块(ToolBlock)的场景。以下是具体说明和典型应用场景。 基本作用 刷新控件显示:当修改了与 C…...

Apache Spark中的依赖关系与任务调度机制解析
Apache Spark中的依赖关系与任务调度机制解析 在Spark的分布式计算框架中,RDD(弹性分布式数据集)的依赖关系是理解任务调度、性能优化及容错机制的关键。宽依赖(Wide Dependency)与窄依赖(Narrow Dependency)作为两种核心依赖类型,直接影响Stage划分、Shuffle操作及容…...

网络基础III
目录 一、网络层 1.1IP协议 1.2网段划分(🔺) 1.3特殊的ip地址 1.4ip地址的数量限制 1.5私有ip和公网ip 1.6路由 二、数据链路层 2.1认识以太网 2.2以太网帧格式 2.3认识mac地址 2.4mac地址和ip地址 2.5认识MTU 2.6MTU对IP协议的…...
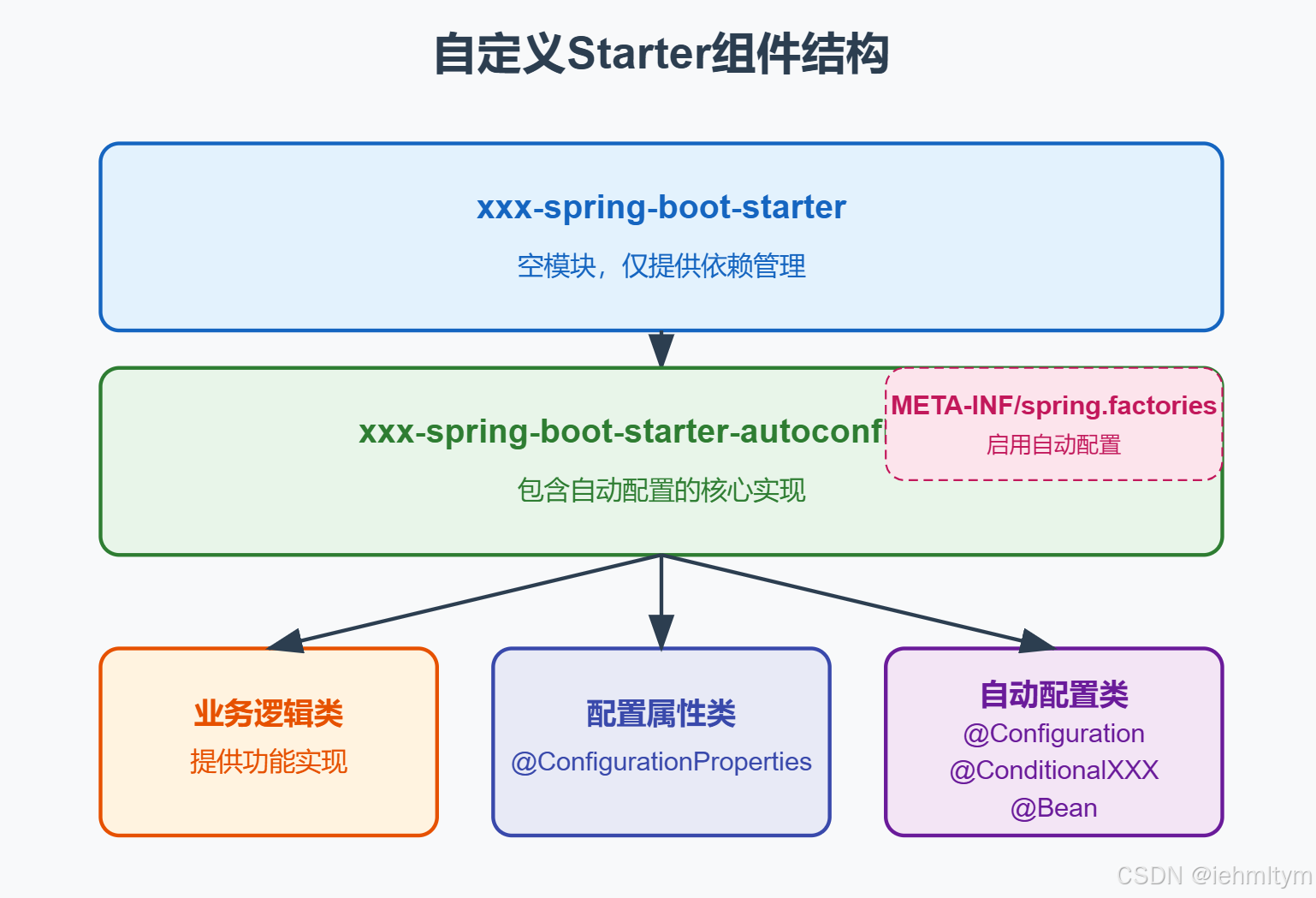
【SpringBoot】自动配置原理与自定义启动器
Spring Boot 自动配置原理与自定义启动器 目录标题 Spring Boot 自动配置原理与自定义启动器摘要1. 引言2. Spring Boot自动配置原理分析2.1 自动配置的核心流程2.2 核心注解与配置文件解析2.2.1 EnableAutoConfiguration2.2.2 spring.factories 文件 2.3 自动配置类剖析2.4 配…...

ScienceDecrypting:三步永久解锁加密PDF,让学术文献重获自由
ScienceDecrypting:三步永久解锁加密PDF,让学术文献重获自由 【免费下载链接】ScienceDecrypting 破解CAJViewer带有效期的文档,支持破解科学文库、标准全文数据库下载的文档。无损破解,保留文字和目录,解除有效期限制…...

OpenClaw用户指南通过Taotoken CLI快速写入配置并开始使用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 OpenClaw用户指南:通过Taotoken CLI快速写入配置并开始使用 对于使用OpenClaw构建智能体工作流的开发者而言࿰…...

QKeyMapper终极指南:免费开源按键映射工具,5分钟让你的键盘鼠标手柄随心所欲
QKeyMapper终极指南:免费开源按键映射工具,5分钟让你的键盘鼠标手柄随心所欲 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支…...

ComfyUI视频助手套件:解锁AI视频创作的无限可能性
ComfyUI视频助手套件:解锁AI视频创作的无限可能性 【免费下载链接】ComfyUI-VideoHelperSuite Nodes related to video workflows 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-VideoHelperSuite 在AI视频创作日益普及的今天,ComfyUI视频…...

机器学习增强恒电位分子动力学:原子尺度模拟锂枝晶生长机制
1. 项目概述:当机器学习“遇见”分子动力学,我们如何看清锂枝晶的生长?在锂金属电池的研究中,锂枝晶的生长问题就像一个挥之不去的幽灵,它直接关系到电池的安全性和循环寿命。我们总在说“枝晶刺穿隔膜导致短路”&…...

NVIDIA显卡性能深度调校指南:解锁200+隐藏参数的游戏优化利器
NVIDIA显卡性能深度调校指南:解锁200隐藏参数的游戏优化利器 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 还在为游戏画面撕裂、输入延迟过高而烦恼?NVIDIA Profile Inspector…...

机器学习预测因果边界:从数据稀缺子群体到精准决策
1. 项目概述与核心挑战在医疗、经济、政策评估等关键决策领域,我们常常需要回答一个核心问题:“如果我采取了某项干预措施,结果会有什么不同?”这本质上是一个因果推断问题,它超越了简单的相关性分析,旨在揭…...

NVIDIA Profile Inspector终极指南:解锁显卡隐藏功能,5步优化游戏性能
NVIDIA Profile Inspector终极指南:解锁显卡隐藏功能,5步优化游戏性能 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 你是否经常觉得游戏画面不够流畅?或者发现显卡…...
)
别再为DBSCAN调参发愁了!用Python的sklearn轻松上手OPTICS聚类(附实战代码)
用OPTICS算法告别DBSCAN调参噩梦:Python实战全解析当面对不规则形状或密度不均的数据集时,密度聚类算法往往能大显身手。DBSCAN作为其中最著名的代表,却让无数数据科学家又爱又恨——它的表现极度依赖两个关键参数ε和MinPts的选择࿰…...

比系统自带强在哪?深度体验WizTree v4.16:磁盘分析老手的新选择
WizTree v4.16:重新定义磁盘空间分析的效率革命当你的C盘突然亮起红色警告,或是发现SSD剩余空间以每天1GB的速度神秘消失时,大多数人的第一反应是打开Windows自带的磁盘清理工具。但真正经历过数据洪流洗礼的IT老手,往往会默默启动…...