Oracle 数据库基础入门(四):分组与联表查询的深度探索(上)
在 Oracle 数据库的学习进程中,分组查询与联表查询是进阶阶段的重要知识点,它们如同数据库操作的魔法棒,能够从复杂的数据中挖掘出有价值的信息。对于 Java 全栈开发者而言,掌握这些技能不仅有助于高效地处理数据库数据,更是构建强大后端应用的关键。接下来,让我们深入探究这两个重要的数据库操作技巧。
目录
一、分组查询
(一)分组查询基础
(二)复合分组
(三)having 过滤
一、分组查询
(一)分组查询基础
分组查询允许我们根据指定的字段将数据进行分组,然后对每个组进行聚合统计操作。其语法结构为:
Select [字段列表] from 表的表名 [where 条件筛选] [order by 排序字段 asc/desc] [ group by 分组字段];
数据库的核心价值之一便是对数据进行聚合统计,以方便管理和分析。为了更好地理解分组查询,我们先创建一个goods_info表,并插入一些示例数据。
create table goods_info (id number primary key, -- 商品id,主键good_name nvarchar2(100) not null, -- 商品名称,不允许为空good_price number(10, 2) not null, -- 商品价格,不允许为空good_store number, -- 库存数量good_sales number, -- 销量good_type nvarchar2(50), -- 商品类型make_address nvarchar2(200) -- 生产地地址
);-- 插入第1条数据
INSERT INTO goods_info (id, good_name, good_price, good_store, good_sales, good_type, make_address)
VALUES (1, '苹果iPhone 13', 6999.00, 100, 500, '手机', '中国深圳');-- 插入第2条数据
INSERT INTO goods_info (id, good_name, good_price, good_store, good_sales, good_type, make_address)
VALUES (2, '华为Mate 40 Pro', 7999.00, 50, 300, '手机', '中国深圳');-- 插入第3条数据
INSERT INTO goods_info (id, good_name, good_price, good_store, good_sales, good_type, make_address)
VALUES (3, '小米11 Ultra', 3999.00, 75, 450, '手机', '中国东莞');
-- 插入第4条数据
INSERT INTO goods_info (id, good_name, good_price, good_store, good_sales, good_type, make_address)
VALUES (4, '美的电饭煲', 1299.00, 200, 1500, '家用电器', '中国北京');-- 插入第5条数据
INSERT INTO goods_info (id, good_name, good_price, good_store, good_sales, good_type, make_address)
VALUES (5, '海尔洗衣机', 1599.00, 150, 1200, '家用电器', '中国北京');-- 插入第6条数据
INSERT INTO goods_info (id, good_name, good_price, good_store, good_sales, good_type, make_address)
VALUES (6, '索尼Xperia 1 III', 599.00, 100, 800, '手机', '中国东莞');-- 插入第7条数据
INSERT INTO goods_info (id, good_name, good_price, good_store, good_sales, good_type, make_address)
VALUES (7, '戴森吸尘器', 2999.00, 60, 350, '家用电器', '中国北京');-- 插入第8条数据
INSERT INTO goods_info (id, good_name, good_price, good_store, good_sales, good_type, make_address)
VALUES (8, '飞利浦空气净化器', 299.00, 500, 2000, '家用电器', '中国北京');
特别要注意的是,分组之后,select后面可以跟分组字段以及聚合函数。例如:
- 按照商品类型,分别统计不同的商品类型有多少种对应的产品:
select good_type,count(*) from goods_info group by good_type;
- 按照商品类型,分别统计不同的商品类型的最高价:
select good_type,max(good_price) from goods_info group by good_type;
- 按照商品类型,分别统计不同的商品类型的最低价、平均价、总价:
selectgood_type,max(good_price) as maxPrice,min(good_price) as minPrice,avg(good_price) as avgPrice,sum(good_price) as sumPrice
fromgoods_info
group bygood_type;
在 Java 全栈开发中,当我们开发一个电商数据分析模块时,可能会利用这些分组查询来统计不同商品类型的销售情况,然后通过 Java 代码将统计结果展示在前端页面上,为运营人员提供数据支持。
(二)复合分组
复合分组是在分组的基础上,进一步对数据进行分组。这就好比对书籍先按照类别分组,然后在每个类别中再按照作者分组。例如,按照商品类型和生产地,统计不同的商品类型在不同生产地分别有多少种对应的商品:
selectgood_type,make_address,count(*)
fromgoods_info
group bygood_type,make_address;
通过复合分组,我们可以获取更细致的数据统计信息。以下是一些练习题:

- 按照学生姓名分组,统计不同的学生总分是多少,并按照总分进行降序排列:
selectname,sum( score ) as total
fromstudent_exam_info
group byname
order bytotal desc;
- 按照考试科目分组统计,不同科目最高分、最低分、平均分是多少:
select subject,max(score),min(score),avg(score) from student_exam_info group by subject;
- 查询语文科目,不同的班级各自的平均分是多少:
select class_name,avg(score) from student_exam_info where subject = '语文' group by class_name;
(三)having 过滤
having关键字用于对聚合后的结果进行再次过滤。其语法为:
select [字段列表] from 表的表名 [where 条件筛选] [order by 排序字段 asc/desc] [group by 分组字段] [having 聚合过滤条件];
例如,按照学生姓名分组,统计不同的学生总分,只想看总分大于等于 260 以上的学生:
selectname,sum( score ) as total
fromstudent_exam_info
group byname
having sum( score ) >= 260
order by total desc;
又如,查询语文科目,不同的班级各自的平均分,并查询平均分高于 90 以上的班级:
select class_name,avg(score) from student_exam_info where subject = '语文' group by class_name having avg(score) >= 90;
这里需要注意where和having的区别:where执行在分组聚合之前,用于对原始数据进行筛选;而having执行在分组聚合之后,用于对聚合后的结果进行过滤。在 Java 全栈开发中,当我们从数据库获取分组统计数据时,需要根据业务需求合理使用where和having,确保获取到准确的数据。
(三)where 与 having 的区别总结
- 执行顺序:
where执行在分组聚合之前,用于对原始数据进行过滤,以减少参与分组聚合的数据量;而having执行在分组聚合之后,用于对聚合后的结果进行筛选。 - 适用对象:
where子句不能使用聚合函数,因为此时聚合操作尚未进行;而having子句主要用于对聚合函数的结果进行条件判断。
在实际的 Java 全栈开发项目中,正确理解和运用where与having的区别至关重要。例如,在一个电商订单数据分析系统中,如果要统计每个用户的订单总金额,并筛选出订单总金额大于 1000 元的用户,我们需要使用group by对用户进行分组,使用sum函数计算订单总金额,然后使用having子句筛选出符合条件的用户。而如果要先筛选出特定时间段内的订单数据,再进行分组统计,那么对时间段的筛选就应该使用where子句。
三、企业工作小技巧
- 合理使用索引:在进行分组查询时,如果分组字段上有索引,查询性能会得到显著提升。例如,在
goods_info表中,如果经常按照good_type进行分组查询,可以考虑在good_type字段上创建索引。但要注意,索引并非越多越好,过多的索引会增加数据插入和更新的时间开销,因为数据库在插入或更新数据时,不仅要更新表数据,还要更新相关的索引。 - 避免复杂分组:尽量避免在一个查询中使用过多的分组字段或复杂的分组逻辑,因为这可能会导致查询性能急剧下降。如果业务需求确实复杂,可以考虑将大查询拆分成多个小查询,逐步进行数据处理。例如,在一个涉及多个维度分组统计的报表生成场景中,如果直接进行多维度复合分组查询,可能会因为数据量过大而导致查询超时。此时,可以先按照主要维度进行分组统计,将结果存储在临时表中,然后再对临时表进行二次分组统计,以降低查询复杂度。
- 结合 Java 代码优化:在 Java 全栈开发中,不要仅仅依赖数据库进行所有的数据处理。可以在数据库层面进行必要的分组和聚合操作,然后将结果返回给 Java 代码进行进一步的处理和筛选。例如,在统计学生成绩时,数据库查询返回每个学生的总分和平均分,Java 代码可以根据业务规则对这些数据进行进一步的筛选和分析,如计算每个学生的成绩排名等,这样可以减轻数据库的负担,提高系统的整体性能。
通过对 Oracle 数据库分组查询的深入学习和实践,我们掌握了一种强大的数据处理工具。在未来的 Java 全栈开发工作中,灵活运用分组查询能够帮助我们高效地解决各种数据统计和分析问题,为企业提供有价值的数据支持。希望大家不断练习,将这些知识转化为实际的开发能力。
因为篇幅原因后续的联合查询&子查询将在下一篇补充完整
Oracle 数据库基础入门(四):分组与联表查询的深度探索(下)-CSDN博客
相关文章:
Oracle 数据库基础入门(四):分组与联表查询的深度探索(上)
在 Oracle 数据库的学习进程中,分组查询与联表查询是进阶阶段的重要知识点,它们如同数据库操作的魔法棒,能够从复杂的数据中挖掘出有价值的信息。对于 Java 全栈开发者而言,掌握这些技能不仅有助于高效地处理数据库数据࿰…...

基于SpringBoot的绿城郑州爱心公益网站设计与实现现(源码+SQL脚本+LW+部署讲解等)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

创建一个简单的spring boot+vue前后端分离项目
一、环境准备 此次实验需要的环境: jdk、maven、nvm和node.js 开发工具:idea或者Spring Tool Suite 4,前端可使用HBuilder X,数据库Mysql 下面提供maven安装与配置步骤和nvm安装与配置步骤: 1、maven安装与配置 1…...

标签使用笔记
文章目录 文件夹结构可以有多个功能吗?标签是如何保存的 标签做成对外接口保存、修改查询删除标签列表标签表设计标签和分类的区别 虽然大体知道怎么设计做,但是整理出来更清晰,那么整理下。 一般来说有两种索引就够。 1、标题文字索引。 # 用于搜索文章…...

Unity图集使用事项
一. 图集布局算法 紧密填充是一种常见的图集布局算法,它的主要目标是尽可能地减少图集的空间浪费。该算法会根据图像的形状和大小,将它们紧密地排列在图集中,以确保最小化空白区域的存在。这样可以有效地利用内存,并减少图集的尺…...

Flutter 学习之旅 之 flutter 在 Android 端读取相册图片显示
Flutter 学习之旅 之 flutter 在 Android 端读取相册图片显示 目录 Flutter 学习之旅 之 flutter 在 Android 端读取相册图片显示 一、简单介绍 二、简单介绍 image_picker 三、安装 image_picker 四、简单案例实现 五、关键代码 代码说明: 一、简单介绍 Fl…...
)
RagFlow专题二、RagFlow 核心架构(数据检索、语义搜索与知识融合)
深入解析 RagFlow 核心架构:数据检索、语义搜索与知识融合 在前一篇文章中,我们对 RagFlow 的核心理念、与传统 RAG 的区别以及其适用场景进行了深入探讨。我们了解到,RagFlow 通过动态优化检索、增强生成质量以及实时知识管理,使得大模型在复杂任务中的表现更加稳定和高效…...

解决各大浏览器中http地址无权限调用麦克风摄像头问题(包括谷歌,Edge,360,火狐)后续会陆续补充
项目场景: 在各大浏览器中http地址调用电脑麦克风摄像头会没有权限,http协议无法使用多媒体设备 原因分析: 为了用户的隐私安全,http协议无法使用多媒体设备。因为像摄像头和麦克风属于可能涉及重大隐私问题的API,ge…...

【SpringBoot+Vue】博客项目开发二:用户登录注册模块
后端用户模块开发 制定参数交互约束 当前,我们使用MybatisX工具快速生成的代码中,包含了一个实体类,这个类中包含我们数据表中的所有字段。 但因为有些字段,是不应该返回到前端的,比如用户密码,或者前端传…...

(十 二)趣学设计模式 之 享元模式!
目录 一、 啥是享元模式?二、 为什么要用享元模式?三、 享元模式的实现方式四、 享元模式的优缺点五、 享元模式的应用场景六、 总结 🌟我的其他文章也讲解的比较有趣😁,如果喜欢博主的讲解方式,可以多多支…...

leetcode第77题组合
原题出于leetcode第77题https://leetcode.cn/problems/combinations/ 1.树型结构 2.回溯三部曲 递归函数的参数和返回值 确定终止条件 单层递归逻辑 3.代码 二维数组result 一维数组path void backtracking(n,k,startindex){if(path.sizek){result.append(path);return ;}…...
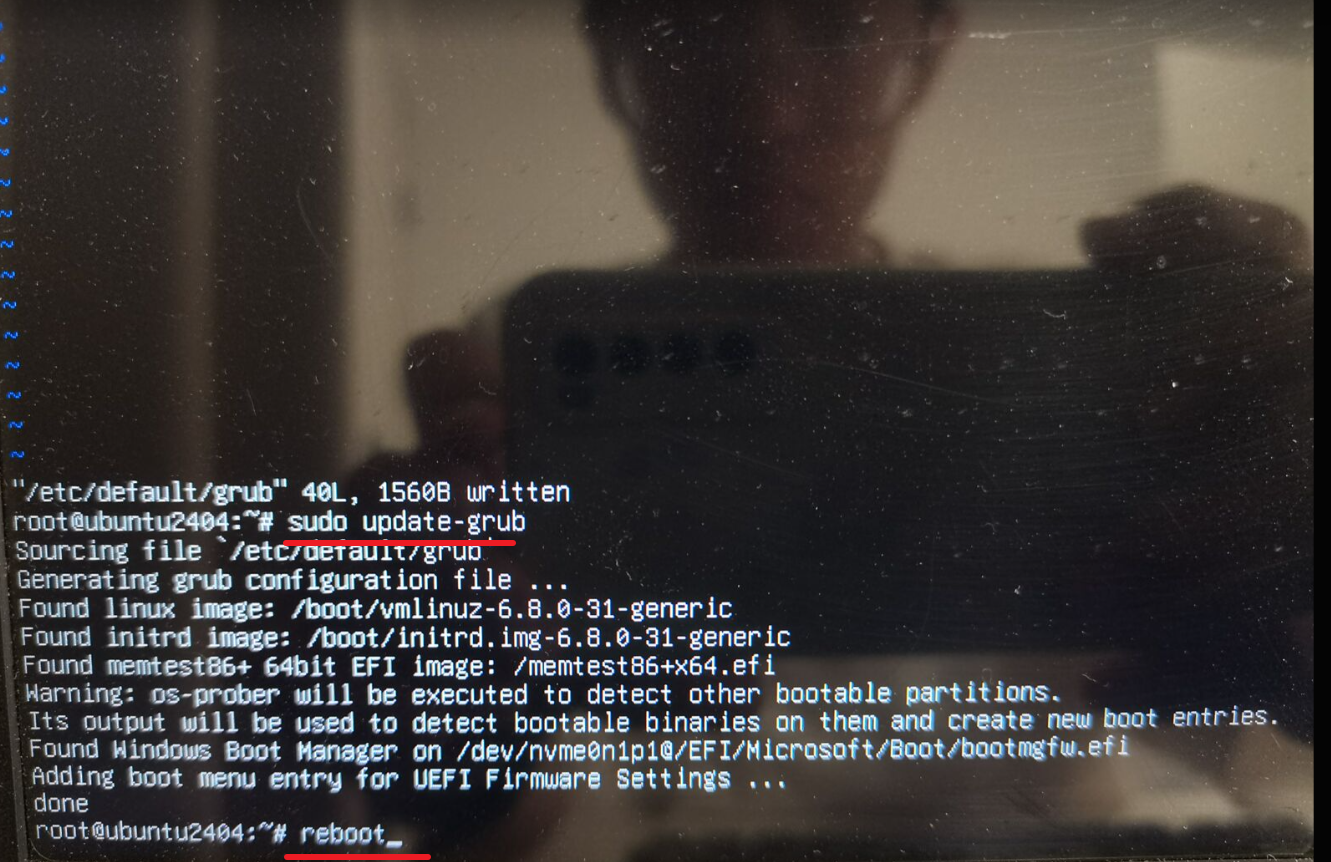
Linux | Ubuntu 与 Windows 双系统安装 / 高频故障 / UEFI 安全引导禁用
注:本文为 “buntu 与 Windows 双系统及高频故障解决” 相关文章合辑。 英文引文,机翻未校。 How to install Ubuntu 20.04 and dual boot alongside Windows 10 如何将 Ubuntu 20.04 和双启动与 Windows 10 一起安装 Dave’s RoboShack Published in…...

Docker入门指南:Windows下docker配置镜像源加速下载
Windows下docker配置镜像源加速下载 docker的官方镜像是海外仓库,默认下载耗时较长,而且经常出现断站的现象,因此需要配置国内镜像源。 国内镜像源概述 国内现有如下镜像源可以使用 "http://hub-mirror.c.163.com", "http…...

web前端基础修炼手册
目录 引言 1. 安装插件 2. 前端三剑客 3. 开发者模式 第一章 HTML 1.文件结构 2. 常见标签 2.1 注释标签 2.2 标题标签 2.3 段落标签 2.4 换行标签 2.5 格式化标签 2.6 图片标签 2.7 超链接标签 2.8 表格标签 2.9 列表标签 2.10 form标签 2.11 input 标签 2.12 la…...

【无标题】Ubuntu22.04编译视觉十四讲slambook2 ch4时fmt库的报错
Ubuntu22.04编译视觉十四讲slambook2 ch4时fmt库的报错 cmake ..顺利,make后出现如下报错: in function std::make_unsigned<int>::type fmt::v8::detail::to_unsigned<int>(int): trajectoryError.cpp:(.text._ZN3fmt2v86detail11to_unsi…...

macos下myslq图形化工具之Sequel Ace
什么是Sequel Ace 官方github:https://github.com/Sequel-Ace/Sequel-Ace Sequel Ace 是一款快速、易于使用的 Mac 数据库管理应用程序,用于处理 MySQL 和 MariaDB 数据库。 Sequel Ace 是一款开源项目,采用 MIT 许可证。用户可以通过 Ope…...

【AHK】资源管理器自动化办公实例/自动连点设置
此处为一个自动连续点击打开检查的自动化操作案例,没有quicker的鼠键录制,不常用了,做个备份 #MaxThreadsPerHotkey 2 ; 这个是核心!!!!确保可以同时运行多个热键或标签global isRunning : tru…...

通用查询类接口数据更新的另类实现
文章目录 一、简要概述二、java工程实现1. 定义main方法2. 测试运行3. 源码放送 一、简要概述 我们在通用查询类接口开发的另类思路中,关于接口数据的更新,提出了两种方案: 文件监听 #mermaid-svg-oJQjD6jQ8T19XlHA {font-family:"tre…...

Linux ls 命令
Linux ls(英文全拼: list directory contents)命令用于显示指定工作目录下之内容(列出目前工作目录所含的文件及子目录)。 语法 ls [-alrtAFR] [name...] 参数 : -a 显示所有文件及目录 (. 开头的隐藏文件也会列出)-d 只列出目…...

【问题记录】Go项目Docker中的consul访问主机8080端口被拒绝
【问题记录】Go项目Docker中的consul访问主机8080端口被拒绝 问题展示解决办法 问题展示 在使用docker中的consul服务的时候,通过命令行注册相应的服务(比如cloudwego项目的demo_proto以及user服务)失败。 解决办法 经过分析,是…...

冬季施工安全措施,附: 冬季施工总安全技术交底
冬季施工安全措施,附: 冬季施工总安全技术交底 冬季施工特点 1 冬季施工由于施工条件及环境不利,是工程质量事故的多发季节,尤以混凝土工程、钢结构工程居多。如何在冬季施工、抢赶工期的条件下保证项目的质量目标,是施工技术和施工组织的难点。 3 质量事故出现的隐蔽性…...

STM32 SysTick定时器深度配置:从原理到多场景实战应用
1. 项目概述:SysTick,一个被低估的“心脏起搏器”在STM32的世界里,SysTick定时器常常被开发者们视为一个“简单”的延时工具,或者仅仅是操作系统的心跳节拍器。但在我十多年的嵌入式开发生涯中,我越来越深刻地体会到&a…...

C++内联函数性能分析
C内联函数性能分析内联函数通过在调用点展开函数体来消除函数调用开销。理解内联机制和使用场景对于编写高性能代码至关重要。inline关键字建议编译器内联函数。#include #includeinline int add(int a, int b) { return a b; }inline int multiply(int a, int b) { return a …...
)
从单机到团队协作:手把手教你用SVN在Windows上搭建个人小型项目版本库(含汉化与日常使用图解)
从单机到团队协作:Windows环境下SVN轻量化部署与实战指南 在个人开发和小型团队协作中,版本控制是保证代码安全和团队高效协作的基石。对于Windows平台的开发者而言,SVN(Subversion)以其简单可靠的特点,成为…...

Genie入门指南:5分钟快速部署你的第一个大数据作业
Genie入门指南:5分钟快速部署你的第一个大数据作业 【免费下载链接】genie Distributed Big Data Orchestration Service 项目地址: https://gitcode.com/gh_mirrors/genie/genie Genie是一款强大的分布式大数据编排服务(Distributed Big Data Or…...

Windows下C语言编译指南
学习C语言入门有一定难度,需勤加练习。多数人使用Windows系统,那么在Windows环境下如何编译运行C语言程序?掌握合适工具与方法是关键。1、 学习C语言时,我使用的是Visual C 6.0编译器。如今,Windows系统下还可使用功能…...

ubuntu24 主题经验
ubuntu24 使用起来非常令我兴奋,源于他的成熟度、超快的网速。一、主题来源网站 https://www.gnome-look.org/s/Gnome/browse?cat135&page11&ordrating二、主题安装文件夹 & 设置创建文件夹 ~/.themes 下载的主题直接扔到这个文件夹。好处有…...

瑞萨RZ系列核心板选型指南:从A55到RISC-V的嵌入式开发实战
1. 项目概述:当国产方案商遇上日系芯片巨头在嵌入式开发这个圈子里混久了,你会发现一个有趣的现象:很多项目在启动时,面临的第一个灵魂拷问往往不是“功能怎么实现”,而是“平台怎么选”。是追求极致的性能,…...

WenShape文生3D模型:基于One-2-3-45框架的开源3D资产生成工具项目深度解析
WenShape文生3D模型:基于One-2-3-45框架的开源3D资产生成工具项目深度解析 项目简介 WenShape 是一个基于 One-2-3-45 技术框架开发的开源“文生3D”模型生成系统,旨在通过文本指令快速、高效地生成高质量3D模型资产。该项目由 unitagain 维护࿰…...

3个核心功能揭秘:JiYuTrainer如何让极域电子教室不再束缚你的学习自由
3个核心功能揭秘:JiYuTrainer如何让极域电子教室不再束缚你的学习自由 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 你是否曾在学校机房被极域电子教室的全屏广播困…...