【Spark分布式内存计算框架——Spark Core】11. Spark 内核调度(下)
8.5 Spark 基本概念
Spark Application运行时,涵盖很多概念,主要如下表格:

官方文档:http://spark.apache.org/docs/2.4.5/cluster-overview.html#glossary
- Application:指的是用户编写的Spark应用程序/代码,包含了Driver功能代码和分布在集群中多个节点上运行的Executor代码;
- Driver:Spark中的Driver即运行上述Application的Main()函数并且创建SparkContext,SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;
- Cluster Manager:指的是在集群上获取资源的外部服务,Standalone模式下由Master负责,Yarn模式下ResourceManager负责;
- Executor:是运行在工作节点Worker上的进程,负责运行任务,并为应用程序存储数据,是执行分区计算任务的进程;
- RDD:Resilient Distributed Dataset弹性分布式数据集,是分布式内存的一个抽象概念;
- DAG:Directed Acyclic Graph有向无环图,反映RDD之间的依赖关系和执行流程;
- Job:作业,按照DAG执行就是一个作业,Job==DAG;
- Stage:阶段,是作业的基本调度单位,同一个Stage中的Task可以并行执行,多个Task组成TaskSet任务集;
- Task:任务,运行在Executor上的工作单元,1个Task计算1个分区,包括pipline上的一系列操作;
8.6 Spark 并行度
Spark作业中,各个stage的task数量,代表了Spark作业在各个阶段stage的并行度!
资源并行度与数据并行度
在Spark Application运行时,并行度可以从两个方面理解:
1)、资源的并行度:由节点数(executor)和cpu数(core)决定的
2)、数据的并行度:task的数据,partition大小
- task又分为map时的task和reduce(shuffle)时的task;
- task的数目和很多因素有关,资源的总core数,spark.default.parallelism参数,spark.sql.shuffle.partitions参数,读取数据源的类型,shuffle方法的第二个参数,repartition的数目等等。
如果Task的数量多,能用的资源也多,那么并行度自然就好。如果Task的数据少,资源很多,有一定的浪费,但是也还好。如果Task数目很多,但是资源少,那么会执行完一批,再执行下一批。所以官方给出的建议是,这个Task数目要是core总数的2-3倍为佳。如果core有多少Task就有多少,那么有些比较快的task执行完了,一些资源就会处于等待的状态。
设置Task数量
将Task数量设置成与Application总CPU Core 数量相同(理想情况,150个core,分配150 Task)官方推荐,Task数量,设置成Application总CPU Core数量的2~3倍(150个cpu core,设置task数量为300~500)与理想情况不同的是:有些Task会运行快一点,比如50s就完了,有些Task可能会慢一点,要一分半才运行完,所以如果你的Task数量,刚好设置的跟CPU Core数量相同,也可能会导致资源的浪费,比如150 Task,10个先运行完了,剩余140个还在运行,但是这个时候,就有10个CPU Core空闲出来了,导致浪费。如果设置2~3倍,那么一个Task运行完以后,另外一个Task马上补上来,尽量让CPU Core不要空闲。
设置Application的并行度
参数spark.defalut.parallelism默认是没有值的,如果设置了值,是在shuffle的过程才会起作用。

案例说明
当提交一个Spark Application时,设置资源信息如下,基本已经达到了集群或者yarn队列的资源上限:
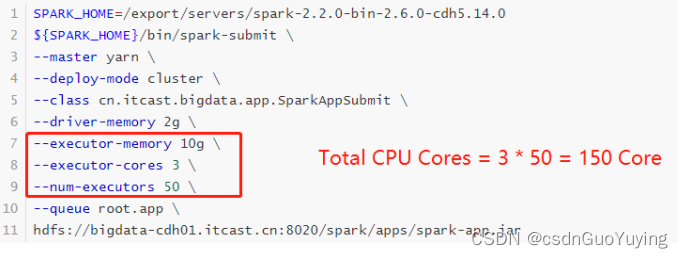
Task没有设置或者设置的很少,比如为100个task ,平均分配一下,每个executor 分配到2个task,每个executor 剩下的一个cpu core 就浪费掉了!
虽然分配充足了,但是问题是:并行度没有与资源相匹配,导致你分配下去的资源都浪费掉了。合理的并行度的设置,应该要设置的足够大,大到可以完全合理的利用你的集群资源。可以调整Task数目,按照原则:Task数量,设置成Application总CPU Core数量的2~3倍

实际项目中,往往依据数据量(Task数目)配置资源。
附录:Maven 依赖
在Maven Project中创建Maven Model,依赖pom.xml添加如下依赖:
<!-- 指定仓库位置,依次为aliyun、cloudera和jboss仓库 -->
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/nexus/content/groups/public</url>
</repository>
</repositories>
<properties>
<scala.version>2.11.12</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<spark.version>2.4.5</spark.version>
<hadoop.version>2.6.0-cdh5.16.2</hadoop.version>
<hbase.version>1.2.0-cdh5.16.2</hbase.version>
<mysql.version>8.0.19</mysql.version>
</properties>
<dependencies>
<!-- 依赖Scala语言 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Spark Core 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark SQL 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Hadoop Client 依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- HBase Client 依赖 -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-hadoop2-compat</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<!-- MySQL Client 依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.hankcs/hanlp -->
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.7.7</version>
</dependency>
</dependencies>
<build>
<outputDirectory>target/classes</outputDirectory>
<testOutputDirectory>target/test-classes</testOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resources</directory>
</resource>
</resources>
<!-- Maven 编译的插件 -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
相关文章:
【Spark分布式内存计算框架——Spark Core】11. Spark 内核调度(下)
8.5 Spark 基本概念 Spark Application运行时,涵盖很多概念,主要如下表格: 官方文档:http://spark.apache.org/docs/2.4.5/cluster-overview.html#glossary Application:指的是用户编写的Spark应用程序/代码&#x…...

Java中的函数
1.String.trim() : 主要有2个用法: 1、就是去掉字符串中前后的空白;这个方法的主要可以使用在判断用户输入的密码之类的。 2、它不仅可以去除空白,还可以去除字符串中的制表符,如 ‘\t’,\n等。 2.Integer.parseInt() : 字符串…...

实验6-霍纳法则及变治技术
目录 1.霍纳法则(Horners rule) 2.堆排序 3.求a的n次幂 1.霍纳法则(Horners rule) 【问题描述】用霍纳法则求一个多项式在一个给定点的值 【输入形式】输入三行,第一行是一个整数n,表示的是多项式的最高次数;第二行多项式的系数组P[0...n](从低到高存储);第三行是…...
IP地址:揭晓安欣警官自证清白的黑科技
《狂飙》这部电视剧,此从播出以来可谓是火爆了,想必大家都是看过的。剧中,主人公“安欣”是一名警察。一直在与犯罪分子做斗争。 莽村的李顺案中,有匿名者这个案件在网上发帖恶意造谣,说安欣是黑恶势力的保护伞&#…...
考研复试机试 | C++
目录1.盛水最多的容器<11>题目代码:2.整数转罗马数字题目:代码:3. 清华大学机试题 abc题目题解4.清华大学机试题 反序数题目描述代码对称平方数题目代码:5. 杭电上机题 叠筐题目:代码pass:关于清华大…...
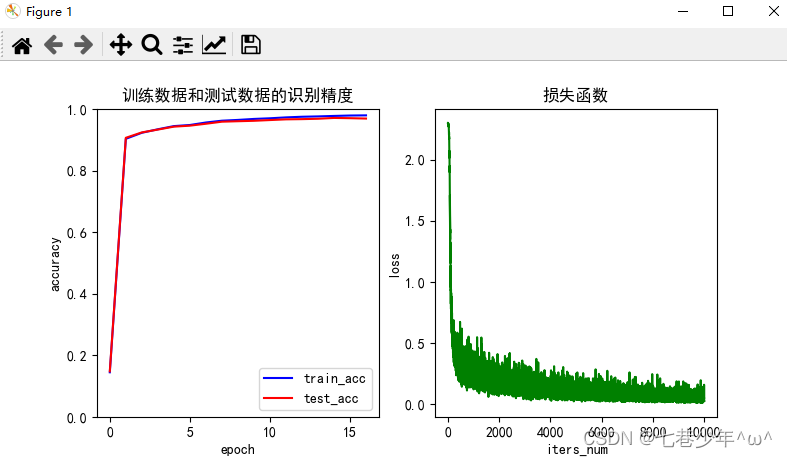
第四章.误差反向传播法—误差反向传播法实现手写数字识别神经网络
第四章.误差反向传播法 4.3 误差反向传播法实现手写数字识别神经网络 通过像组装乐高积木一样组装第四章中实现的层,来构建神经网络。 1.神经网络学习全貌图 1).前提: 神经网络存在合适的权重和偏置,调整权重和偏置以便拟合训练数据的过程称…...

IB学习者的培养目标有哪些?
IB课程强调要培养年轻人的探究精神,在富有渊博知识的同时,更要勤于思考,敢于思考,尊重和理解跨文化的差异,坚持原则维护公平,让这个世界充满爱与和平,让这个世界变得更加美好。上一次我们为大家…...
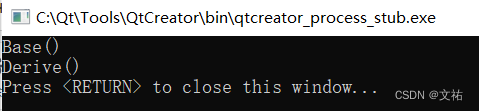
C++类基础(十三)
类的继承 ● 通过类的继承(派生)来引入“是一个”的关系( 17.2 — Basic inheritance in C) – 通常采用 public 继承( struct V.S. class ) – 注意:继承部分不是类的声明 – 使用基类的指针…...
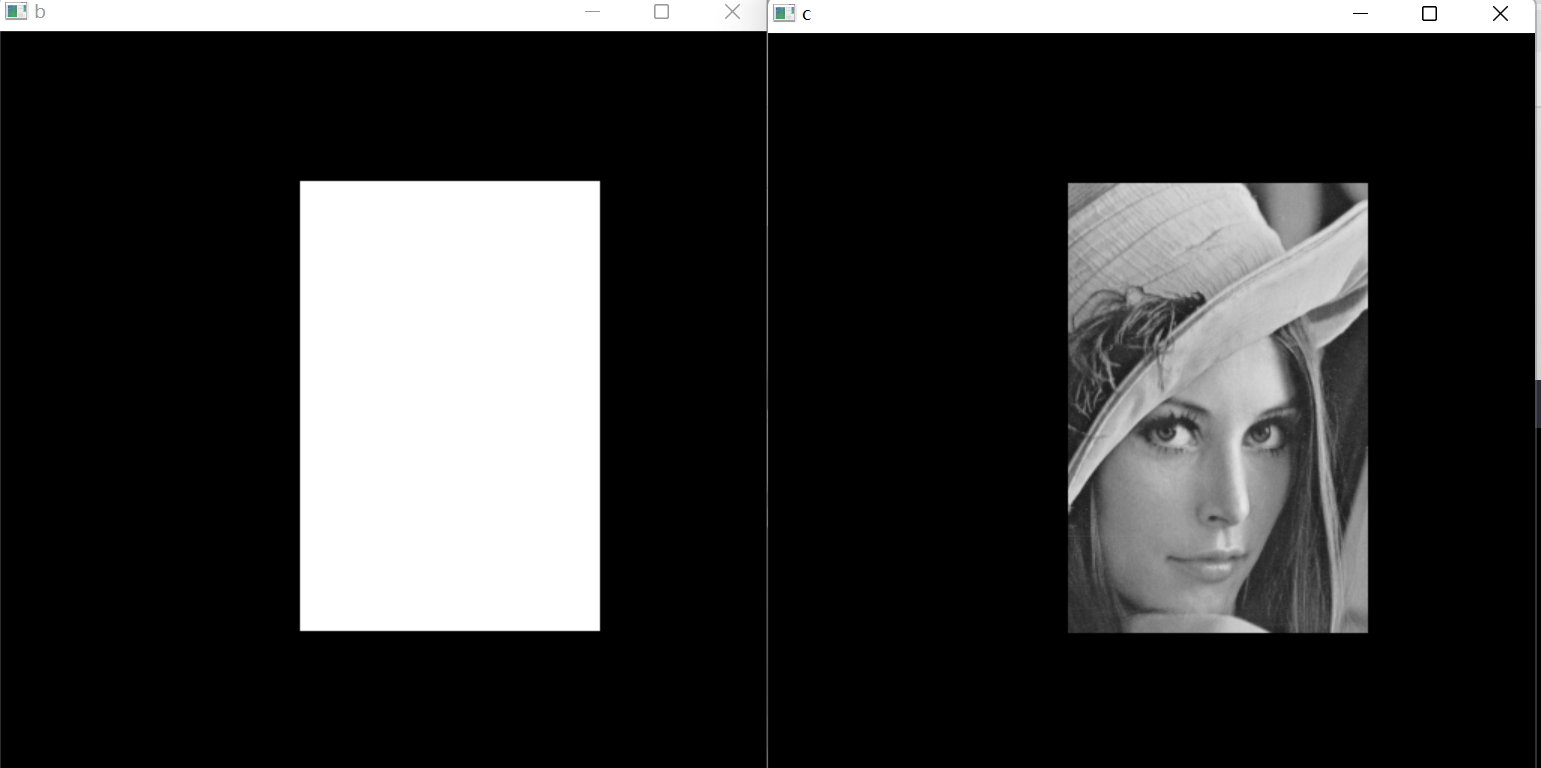
03 OpenCV图像运算
文章目录1 普通加法1 加号相加2 add函数2 加权相加3 按位运算1 按位与运算2 按位或运算、非运算4 掩膜1 普通加法 1 加号相加 在 OpenCV 中,图像加法可以使用加号运算符()来实现。例如,如果要将两幅图像相加,可以使用…...

【C语言学习笔记】:动态库
一、动态库 通过之前静态库那篇文章的介绍。发现静态库更容易使用和理解,也达到了代码复用的目的,那为什么还需要动态库呢? 1、为什么还需要动态库? 为什么需要动态库,其实也是静态库的特点导致。 ▶ 空间浪费是静…...
Zookeeper
zookeeper是一个分布式协调服务。所谓分布式协调主要是来解决分布式系统中多个进程之间的同步限制,防止出现脏读,例如我们常说的分布式锁。 zookeeper中的数据是存储在内存当中的,因此它的效率十分高效。它内部的存储方式十分类似于文件存储…...
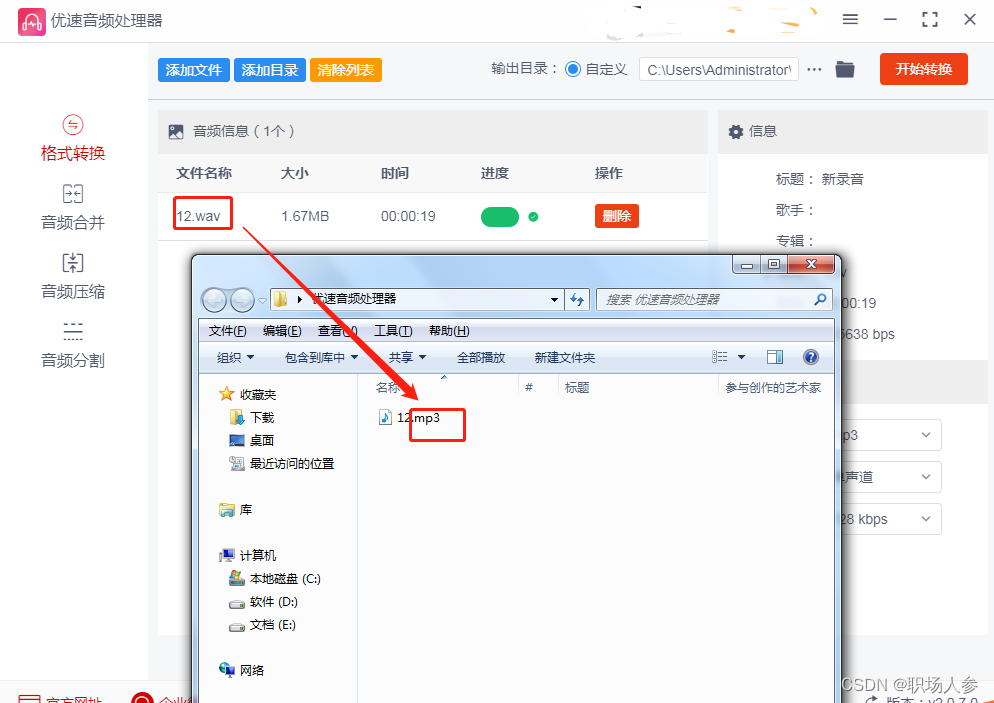
wav转mp3,wav转换成mp3教程
很多使用音频文件的小伙伴,总会接触到不同类型的音频格式,根据需求不同需要做相关的处理。比如有人接触到了wav格式的音频,这是windows系统研发的一种标准数字音频文件,是一种占用磁盘体积超级大的音频格式,通常用于录…...
springboot项目配置文件加密
1背景: springboot项目中要求不能采用明文密码,故采用配置文件加密. 目前采用有密码的有redis nacos rabbitmq mysql 这些配置文件 2技术 2.1 redis nacos rabbitmq 配置文件加密 采用加密方式是jasypt 加密 2.1.1 加密步骤 2.1.2 引入maven依赖 …...
公司招聘:33岁以上的和两年一跳的不要,开出工资我还以为看错了...
导读:对于公司来说,肯定是希望花最少的钱招到最优秀的员工,但事实上这个想法是不太现实的,虽然如今互联网不太好找工作,但要员工降薪去入职,相信还是有很大难度的,很多人宁可在家休息࿰…...

【置顶】:文章合集系列
【置顶】:文章合集系列 必看 文章中的所有内容仅供做个人学习使用,所有环境都在本地搭建并验证,任何人使用文中方法进行未经授权的渗透行为都与文章与我本人无关,请各位大佬不要进行未经授权的渗透行为…… 前言 之前更新过一段…...
Go的web开发Gin框架1(八)——Gin
一、重点内容: 知识要点有哪些? 1、了解Gin框架 2、导入使用Gin框架 3、尝试配合GORM开发 4、整合html,css,js 二、详细知识点介绍: 1、Gin框架介绍 Gin是一个golang的微框架,封装比较优雅&…...

吴思进——复杂美创始人首席执行官
杭州复杂美科技有限公司创始人兼CEO, 本科毕业于浙江大学机械专业,辅修过多门管理课程;1997年获经济学硕士学位,有关对冲基金的毕业论文被评为优秀;2008年创办杭州复杂美科技有限公司。 吴思进 中国电子学会区块链委员会专家&…...
)
apk简单介绍(组成以及打包安装流程)
apk简单介绍APK 的组成apk安装流程app的启动过程apk打包流程AIDLAIDL介绍为什么要设计这门语言它有哪些语法?默认支持的数据类型包括什么是apk打包流程了解打包流程能做什么操作APK 的组成 APK 其实是一个 zip 类型的压缩包,而一个典型的 APK 通常都会包…...

ffmpeg学习笔记之SDL视频播放器
看了雷神的 100行代码实现最简单的基于FFMPEGSDL的视频播放器(SDL1.x) 后手痒难耐,决定将里面的代码重新建一个 首先建立一个空项目,新建一个Mysimplest.cpp的文件。在里面写代码 #include <stdio.h>extern "C" …...
【Git】合并多条 commit 注释信息
文章目录1、查看 commit 记录2、合并 commit 注释1、查看 commit 记录 # 3 指的是查看最近 3 次的 commit 记录,如果要查看多次的可以修改数字 # -3 不加,则表示查看所有 commit 记录,一般还是用数字去指定 git log -32、合并 commit 注释 …...

从仿真卡死到波形完美:手把手调试Verilog Testbench时钟的那些坑
从仿真卡死到波形完美:手把手调试Verilog Testbench时钟的那些坑 数字电路仿真中,时钟信号就像交响乐团的指挥棒,一个微小的节奏错误就可能导致整个系统失序。刚接触Verilog仿真的工程师们,往往会在时钟生成这个看似简单的环节栽跟…...

构建个人技能知识库:从Markdown管理到自动化实践
1. 项目概述:一个技能库的诞生与价值最近在整理个人知识体系时,我一直在思考一个问题:如何将那些零散的、跨领域的“技能点”系统化地管理起来,形成一个可以持续迭代、随时取用的个人工具箱?这不仅仅是写一份简历上的技…...

一次搞清楚:Agent、Skill、Prompt、MCP
文章深入探讨了AI Agent在落地过程中面临的三大核心痛点:Prompt的临时性与不可复用性、Agent专业能力的难以沉淀与迁移、以及AI能力无法融入现有工程化流程。文章提出Agent Skills作为AI Agent的专业能力说明书,通过标准化能力描述与执行框架,…...

RCB-F9T-0,支持多频段多星座及纳秒级精度的多协议GNSS授时板
简介今天我要向大家介绍的是 u-blox 的多频段GNSS授时板——RCB-F9T-0。这是一款专为高精度授时应用设计的紧凑型定时板。该模块基于 u-blox ZED-F9T-00B 高精度授时模块,搭载AEC-Q100认证的GNSS芯片;集成SMB天线连接器和5V有源天线供电电路;…...

FastGithub终极提速方案:3步让GitHub访问速度翻倍
FastGithub终极提速方案:3步让GitHub访问速度翻倍 【免费下载链接】FastGithub github定制版的dns服务,解析访问github最快的ip 项目地址: https://gitcode.com/gh_mirrors/fa/FastGithub 对于开发者而言,GitHub访问缓慢已经成为日常开…...

终极指南:SpringAll安全框架实战——Shiro与Spring Security权限控制最佳实践
终极指南:SpringAll安全框架实战——Shiro与Spring Security权限控制最佳实践 【免费下载链接】SpringAll 循序渐进,学习Spring Boot、Spring Boot & Shiro、Spring Batch、Spring Cloud、Spring Cloud Alibaba、Spring Security & Spring Secur…...

从U盘到移动硬盘:深入拆解USB存储设备里的BOT和UASP协议栈
从U盘到移动硬盘:深入拆解USB存储设备里的BOT和UASP协议栈 当你将一块移动固态硬盘插入电脑的USB 3.2接口,期待每秒上千兆字节的传输速度时,是否想过这背后隐藏着怎样的协议魔法?在USB存储设备的世界里,BOT(…...

毕业季救星:Word 2016域代码终极指南,让你的参考文献列表和文内引用完美同步
学术写作效率革命:用Word域代码构建智能参考文献系统 每到毕业季,总有一群人在深夜里对着电脑屏幕抓狂——他们的论文参考文献编号像多米诺骨牌一样,因为中间插入了一个新引用而全部错乱。手动调整几十处引用编号不仅耗时,还容易出…...

别再死记硬背了!我用这5个C语言内存模型的实际案例,搞懂了嵌入式面试的底层逻辑
从崩溃现场到面试答案:5个嵌入式开发中的内存实战案例 凌晨三点的调试灯依然亮着,屏幕上的十六进制数字像某种神秘代码——这是许多嵌入式开发者都熟悉的场景。当系统突然崩溃,内存错误往往是最难追踪的幽灵问题。但有趣的是,这些…...

如何用开源工具Lano Visualizer让桌面音乐体验“看得见“?[特殊字符]
如何用开源工具Lano Visualizer让桌面音乐体验"看得见"?🎵 【免费下载链接】Lano-Visualizer A simple but highly configurable visualizer with rounded bars. 项目地址: https://gitcode.com/gh_mirrors/la/Lano-Visualizer 在数字时…...