Kafka - 高吞吐量的七项核心设计解析
文章目录
- 概述
- 一、顺序磁盘I/O (分区+顺序追加)
- 1.1 存储架构设计
- 1.2 性能对比实验
- 1.3 存储优化策略
- 二、零拷贝技术:颠覆传统的数据传输革命
- 2.1 传统模式痛点
- 2.2 Kafka优化方案
- 三、页缓存机制:操作系统的隐藏加速器
- 3.1 实现原理
- 3.2 优势对比
- 四、日志索引设计:海量数据的快速检索
- 4.1 存储结构
- 4.2 查询流程
- 五、批量处理:吞吐量的倍增器
- 5.1 生产者配置
- 5.2 消费者配置
- 六、压缩算法:空间与时间的权衡艺术
- 6.1 压缩效率对比
- 6.2 压缩过程
- 七、Reactor网络模型:高并发的基石
- 7.1 模型演进
- 7.2 核心参数
- 小结

概述
在消息中间件领域,Apache Kafka以卓越的吞吐性能著称。虽然RocketMQ在某些场景下展现出更高的吞吐能力,但其架构设计仍深受Kafka启发。接下来我们将从存储设计、网络优化、内存管理等维度,深入剖析Kafka实现百万级TPS的七大关键技术,揭示其高性能背后的设计哲学。
一、顺序磁盘I/O (分区+顺序追加)
1.1 存储架构设计
Kafka采用「分区+顺序追加」的写入模式,每个分区对应物理磁盘上的独立日志文件 。
生产者消息按分区严格顺序追加到文件尾部,避免传统数据库的随机写入模式。
1.2 性能对比实验
根据ACM Queue的研究数据 :
- 顺序读磁盘:53.2 MB/s
- 随机读内存:36.7 MB/s
- 随机读磁盘:0.5 KB/s
结论:顺序磁盘操作性能比随机内存访问提升45%,比随机磁盘访问高出5个数量级。
1.3 存储优化策略
数据如果一直落盘不删除也不行,所以Kafka也提供了两种可配置的数据删除策略,一种是基于时间,另一种就是基于分区文件的大小,以此来保障磁盘的数据存储容量。
| 策略类型 | 配置参数 | 作用 |
|---|---|---|
| 时间策略 | log.retention.hours | 过期数据自动删除 |
| 容量策略 | log.segment.bytes | 控制单个Segment大小 |
二、零拷贝技术:颠覆传统的数据传输革命
2.1 传统模式痛点
传统文件传输需经历四次拷贝:
- DMA拷贝到内核缓存
- CPU拷贝到用户缓存
- CPU拷贝到Socket缓存
- DMA拷贝到网卡


2.2 Kafka优化方案
使用Linux的sendfile系统调用实现零拷贝:
sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
- in_fd:消息文件描述符
- offset:消费者偏移量
- count:读取字节数
Java NIO通过FileChannel.transferTo()封装此能力,实现数据从页缓存直通网卡。
三、页缓存机制:操作系统的隐藏加速器
如果只是消息到磁盘的顺序读写,还不足以成为高性能的典型,所以Kafka还利用了操作系统的页缓存技术,利用内存来提升I/O效率。
页缓存通过内存映射文件(memory mapped file)实现文件到物理内存的直接映射。完成映射之后,对物理内存的操作会被同步到磁盘上(操作系统在适当的时候)。相比用户态的内存,页缓存有如下两个优势。
- 避免用户态对象的内存额外占用,例如使用Java堆时,Java对象的内存消耗比较大,通常是所存储数据的两倍甚至更多。
- 避免用户态的内存垃圾回收,用户态的内存垃圾回收会导致运行复杂和缓慢。
因此,利用基于操作系统的页缓存,Kafka的数据都在内存操作,性能又进一步提升。
3.1 实现原理
通过mmap将磁盘文件映射到进程地址空间,形成虚拟内存与物理内存的映射关系。当访问虚拟内存地址时:
- 命中页缓存:直接读取物理内存
- 未命中页缓存:触发缺页中断加载数据
3.2 优势对比
| 维度 | 用户态缓存 | 页缓存 |
|---|---|---|
| 内存占用 | 数据量2倍+ | 1:1映射 |
| GC影响 | 频繁STW | 无影响 |
| 数据同步 | 需手动flush | 内核自动管理 |
四、日志索引设计:海量数据的快速检索
之前说了Kafka的数据存储是按照分区存储的,但是写入文件的最小单位是段(segment),即一个分区有多个段,那么如何提升数据存储和读取性能呢?Kafka采取了跳表加索引查询的模式
4.1 存储结构
partition-0/
├── 00000000000000000000.index
├── 00000000000000000000.log
├── 00000000000000000000.timeindex
- 日志文件:存储实际消息(Segment分段存储)
- 索引文件:稀疏索引,记录offset与物理位置的映射
4.2 查询流程
- 使用跳表定位目标Segment
- 二分法查询.index文件获取物理偏移
- 从.log文件指定位置顺序扫描

消费者拉取消息的时候首先从日志的segment里的跳表结构查询到消息的偏移量,例如上图中查询到的消息偏移量是3,再在索引文件里按照消息偏移量查询它在日志文件里对应的日志偏移量,例如图中消息偏移量为3,在.index文件里对应的日志偏移量是1360,接下来直接访问位置1360获取消息message3。通过跳表加索引的结构,不仅数据查询的效率提升了,数据查询的并行度也提升了
五、批量处理:吞吐量的倍增器
数据的批量读取和写入主要是为了解决频繁的网络I/O带来的性能消耗问题,例如以极端情况来看,假设有10000条消息,一次网络请求读写10000条与每次读写1条且用10000次完成相比,显然是前一种方式更具性能优势,其实这也是前面讲到的粘连分区的一个优势,它可以将每次分区的容量填充率变得更高,减少消息的网络I/O传输,从而实现更低的网络时延。同样,在“零拷贝”里面的批量获取容量也是类似的道理。
5.1 生产者配置
batch.size=16384 // 批次大小(16KB)
linger.ms=5 // 等待时间
当满足size或time任一条件即触发发送。
5.2 消费者配置
fetch.min.bytes=1
fetch.max.wait.ms=500
通过「预读取+拉取窗口」机制减少网络交互次数。
六、压缩算法:空间与时间的权衡艺术
网络I/O传输中最大的损耗由每次传输的消息大小来确定,对于需要在广域网上的数据中心之间发送消息的数据流水线尤其如此。进行数据压缩虽然会消耗少量的CPU资源,但是对Kafka而言,网络I/O资源的占用和优化同样也需要考虑。
- 如果只是对单个消息进行压缩,压缩率就会很低,所以Kafka采用了批量压缩,即将多个消息一起压缩而不是压缩单个消息。
- Kafka允许使用递归的消息集合,批量的消息可以通过压缩格式传输并且在日志中也可以保持压缩格式,直到被消费者解压缩。
- Kafka支持多种压缩协议,包括Gzip和Snappy压缩协议。
6.1 压缩效率对比
| 算法 | 压缩率 | CPU消耗 | 适用场景 |
|---|---|---|---|
| Gzip | 高 | 高 | 带宽敏感 |
| Snappy | 中 | 低 | CPU敏感 |
| LZ4 | 中高 | 极低 | 实时系统 |
6.2 压缩过程
[消息1][消息2]...[消息N] → 压缩 → [压缩块]
七、Reactor网络模型:高并发的基石
Kafka在客户端和服务器端之间通信实现的Reactor网络模型是一种事件驱动模型。

- 选择器(selector):也可以称为多路复用器,它是Java NIO的核心组件,用于检测NIO通道的状态是否可读或可写。
- 接收器(acceptor):用于监听网络连接端口和请求。
- OP_WRITE:NIO的可写状态,调用Writer_handler处理。
- OP_READ:NIO的可读状态,调用Read_handler处理。
- OP_CONNECT:NIO的可连接状态,由客户端主动连接触发,调用接收器处理。
对于一些小容量的业务场景,这种单线程的模式基本够用,但是对于高负载、高并发的应用场景,这种单线程的模式并不适合,主要有以下几个原因
- 并发性问题:一个NIO线程同时处理数十万甚至百万级的链路,性能是无法支撑的。
- 吞吐量问题:如果超时发生重试,会加重服务器端的处理负载,从而导致大量处理积压。
- 可靠性问题:如果单个线程出现故障,整个系统将无法使用,会造成单点故障。
7.1 模型演进
传统BIO模型:1连接1线程 → 线程数爆炸
单Reactor单线程:无法应对高并发
Kafka多Reactor多线程:
Acceptor Threads(N) ↓
Processor Threads(M)↓
Handler Thread Pool(P)
7.2 核心参数
num.network.threads=3 // 网络线程数
num.io.threads=8 // IO处理线程
因此,要实现一个高并发的处理服务,需要对以上架构进行优化,例如采取多线程处理模式,同时将接收线程的逻辑尽量简化,相当于将接收线程作为一个接入层。Kafka的Reactor网络模型就是依据这些因素进行优化的

Kafka采取了多线程处理请求机制,如图中处理线程池所示,并且依据网卡的个数(在Kafka源码里面采用EndPoint表示)启动相应的接收监听线程(图中的接收器),从整体上来看实现了多线程接收监听器以及多线程处理器,保障了在消息请求接入层的处理性能,并且解决了高可用问题
小结
Kafka的高吞吐设计体现了多个层级的优化协同:
- 存储层:顺序I/O+页缓存突破磁盘瓶颈
- 网络层:零拷贝+批量压缩降低传输损耗
- 计算层:Reactor模型+多线程提升并发能力
- 架构层:分区+Segment实现水平扩展

相关文章:
Kafka - 高吞吐量的七项核心设计解析
文章目录 概述一、顺序磁盘I/O (分区顺序追加)1.1 存储架构设计1.2 性能对比实验1.3 存储优化策略 二、零拷贝技术:颠覆传统的数据传输革命2.1 传统模式痛点2.2 Kafka优化方案 三、页缓存机制:操作系统的隐藏加速器3.1 实现原理3.2 优势对比 四、日志索引…...
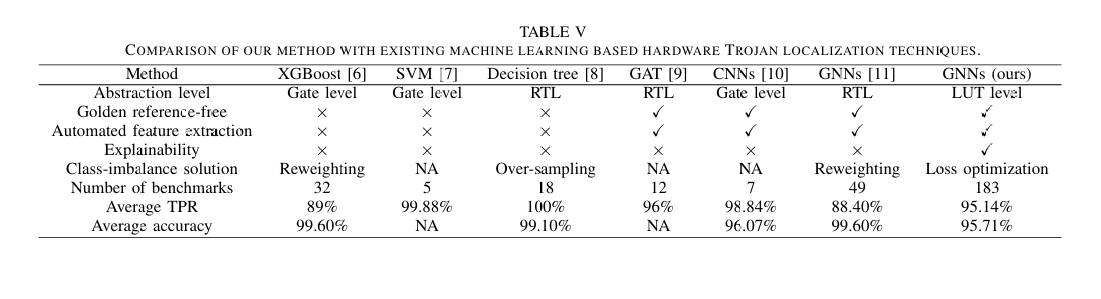
Towards Precise and Explainable Hardware Trojan Localization at LUT Level
文章 《Towards Precise and Explainable Hardware Trojan Localization at LUT Level》 TCAD’2025 《LUT层次的精细可解释木马定位》 期刊介绍 《IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems》(TCAD)是集成电路…...

Python实现鼠标点击获取窗口进程信息
最近遇到挺无解的一个问题:电脑上莫名其妙出现一个白色小方块,点击没有反应,关也关不掉,想知道它和哪个软件有关还是显卡出了问题,也找不到思路,就想着要不获取一下它的进程号看看。 于是写了一个Python脚本…...

Mac安装jdk教程
在Mac上安装JDK(Java Development Kit)的步骤如下: 一、下载JDK安装包 访问Oracle官网: 打开浏览器,访问Oracle JDK下载页面。 选择JDK版本: 根据你的开发需求选择合适的JDK版本。例如,JDK 11…...

【HeadFirst系列之HeadFirst设计模式】第14天之与设计模式相处:真实世界中的设计模式
与设计模式相处:真实世界中的设计模式 设计模式是软件开发中的经典解决方案,它们帮助我们解决常见的设计问题,并提高代码的可维护性和可扩展性。在《Head First设计模式》一书中,作者通过生动的案例和通俗的语言,深入…...

JDBC 完全指南:掌握 Java 数据库交互的核心技术
JDBC 完全指南:掌握 Java 数据库交互的核心技术 一、JDBC 是什么?为什么它如此重要? JDBC(Java Database Connectivity)是 Java 语言中用于连接和操作关系型数据库的标准 API。它允许开发者通过统一的接口访问不同的数…...

Vue父子组件传递笔记
Vue父子组件传递笔记 props 父组件向子组件进行传值 (1)在父组件APP.vue <template><div> <!-- 给子组件Child.vue传递以msg的信号,传递的信息内容为messages --><Child :msg"messages"></Child>…...

文件上传漏洞与phpcms漏洞安全分析
目录 1. 文件上传漏洞简介 2. 文件上传漏洞的危害 3. 文件上传漏洞的触发条件 1. 文件必须能被服务器解析执行 2. 上传目录必须支持代码执行 3. 需要能访问上传的文件 4. 例外情况:非脚本文件也可能被执行 4. 常见的攻击手法 4.1 直接上传恶意文件 4.2 文件…...

【deepseek】辅助思考生物学问题:ICImapping构建遗传图谱gap较大
基于ICImapping构建遗传图谱的常见问题与解答 问题一:染色体两端标记间遗传距离gap较大 答疑一 标记密度不足(如芯片设计时分布不均)重组概率低基因组结构变异软件算法限制 Deepseek的解释 #### 1. **染色体末端的重组率较低** - **现象*…...

linux磁盘非lvm分区
linux磁盘非lvm分区 类似于windows划分C盘、D盘,并且不需要多个磁盘空间合一 图形化直接分区 通过gparted 这个提供直观的图形化分区,类似windows的磁盘管理工具 下载方式: 乌班图/debian系列: sudo apt install gparted红帽…...

Windows下sql server2012安装流程
准备工作 确认系统要求:确保 Windows 系统为 Windows 7 或更高版本,且为 64 位操作系统,CPU 在 2GHz 以上,内存 4GB 或更高。 下载安装包:从微软官方网站或其他可靠渠道下载 SQL Server 2012 安装包。 关闭相关软件&am…...

css之英文换行样式
在 CSS 中,要实现英文文本自动换行但不从单词中间断开的效果,可以使用 word-wrap 或 overflow-wrap 属性。以下是相关的 CSS 属性和它们的配置: 使用 overflow-wrap 或 word-wrap /* This property is used to handle word breaking */ .wo…...

绝美焦糖暖色调复古风景画面Lr调色教程,手机滤镜PS+Lightroom预设下载!
调色教程 通过 Lr 软件丰富的工具和功能,对风景照片在色彩、影调等方面进行调整。例如利用基本参数调整选项,精准控制照片亮度、对比度、色温、色调等基础要素;运用 HSL 面板可对不同色彩的色相、饱和度以及明亮度进行单独调节;利…...

文件解析:doc、docx、pdf
1.doc解析 ubuntu/debian系统应先安装工具 apt-get install python-dev libxml2-dev libxslt1-dev antiword unrtf poppler-utils pstotext tesseract-ocr \ flac ffmpeg lame libmad0 libsox-fmt-mp3 sox libjpeg-dev swig pip install textract解析: import te…...

计算机网络基础:VLAN(虚拟局域网)
1. VLAN 虚拟局域网:可以用来隔离广播 广播和广播域: arp 出不了路由器,只能攻击内网 路由器可以隔离广播(物理隔离)缺点是成本高、不灵活 2. VLAN 隔离广播 静态VLAN:基于交换机端口号划分 动态VLAN&am…...
——循环结构)
C++学习笔记(十一)——循环结构
循环结构的作用 循环结构用于重复执行某一代码块,直到满足特定条件后退出循环。 C 提供了以下三种循环结构: for 循环(确定次数的循环)while 循环(条件控制的循环)do-while 循环(至少执行一次的…...

【C++】二叉树相关算法题
一、根据二叉树创建字符串 题目描述: 给你二叉树的根节点 root ,请你采用前序遍历的方式,将二叉树转化为一个由括号和整数组成的字符串,返回构造出的字符串。 空节点使用一对空括号对 “()” 表示,转化后需要省略所有…...

物联网IoT系列之MQTT协议基础知识
文章目录 物联网IoT系列之MQTT协议基础知识物联网IoT是什么?什么是MQTT?为什么说MQTT是适用于物联网的协议?MQTT工作原理核心组件核心机制 MQTT工作流程1. 建立连接2. 发布和订阅3. 消息确认4. 断开连接 MQTT工作流程图MQTT在物联网中的应用 …...

【大学生体质】智能 AI 旅游推荐平台(Vue+SpringBoot3)-完整部署教程
智能 AI 旅游推荐平台开源文档 项目前端地址 ☀️项目介绍 智能 AI 旅游推荐平台(Intelligent AI Travel Recommendation Platform)是一个利用 AI 模型和数据分析为用户提供个性化旅游路线推荐、景点评分、旅游攻略分享等功能的综合性系统。该系统融合…...
】)
【Node.js入门笔记1---初始Node.js)】
Node.js入门笔记1 初始Node.js1.Node.js简介2.Node.js中js的运行环境3.Node.js 可以做什么4.Node.js 怎么学 初始Node.js 1.Node.js简介 Node.js 是一个基于 Chrome V8 引擎 的 JavaScript 运行时环境,用于在服务器端运行 JavaScript 代码。它让开发者可以用 Java…...

杰理701N可视化SDK:从stream.bin生成到工程导入的EQ调音闭环
1. 杰理701N可视化SDK与EQ调音基础 第一次接触杰理701N的开发者可能会好奇,这个可视化SDK到底能做什么?简单来说,它就像给声学工程师配了一把"声音雕刻刀"。通过图形化界面,你可以实时调整蓝牙耳机、音箱等设备的音效表…...

Flutter GetX实战:从Provider迁移到GetX,我的开发效率提升了多少?
Flutter GetX实战:从Provider迁移到GetX的效率革命 当Flutter开发团队面临状态管理方案的选择时,往往会陷入一种甜蜜的烦恼——官方推荐的Provider虽然稳定可靠,但第三方库GetX却以"全家桶"式的解决方案不断吸引开发者的目光。作为…...

FPGA高速ADC数据采集实战——基于AD9253 LVDS接口与ISERDESE2设计
1. AD9253高速ADC核心特性解析 AD9253这颗14位125MSPS四通道ADC芯片,在通信和医疗成像领域堪称经典。我经手过的多个雷达项目中,它的信噪比表现总能带来惊喜——75.3dBFS的实测数据比手册标称值还要稳定。但真正让工程师们又爱又恨的,是它那个…...

轻量级爬虫框架slacrawl:基于规则驱动的模块化数据采集实践
1. 项目概述:一个轻量级、模块化的网页爬虫框架最近在做一个需要从多个网站定时抓取结构化数据的小项目,找了一圈现成的工具,要么太重(像Scrapy,学起来成本高),要么太死板(很多脚本只…...

CircuitPython开发进阶:从库文档解读到内存优化与异步编程实战
1. 从“能用”到“精通”:为什么你需要深入理解CircuitPython库文档刚接触CircuitPython时,我们往往是从复制粘贴示例代码开始的。这没什么问题,快速让一个LED闪烁起来,或者让传感器读出数据,那种即时反馈的成就感是驱…...

基于Panel与LLM构建智能数据可视化应用的架构与实践
1. 项目概述与核心价值最近在数据可视化与交互应用开发领域,一个名为holoviz-topics/panel-chat-examples的项目仓库引起了我的注意。乍一看,这似乎只是将聊天界面(Chat Interface)与 Panel 这个强大的 Python 交互式仪表盘库结合…...

基于MCP协议构建AI数据连接器:从原理到SQL查询服务器实践
1. 项目概述:一个连接AI与数据源的“翻译官”最近在折腾AI应用开发,特别是想让大语言模型(LLM)能直接、安全地访问我自己的数据库、API或者文件系统时,遇到了一个普遍难题:怎么让AI理解并操作这些外部数据源…...
基于Circuit Playground Express与NeoPixel的四季交互灯光装置设计与实现
1. 项目概述与核心思路几年前,我在一个艺术展上看到一组悬挂在枯树枝上的玻璃瓶,里面装着会呼吸般变幻光线的LED灯,那种静谧又灵动的美感让我念念不忘。作为一个喜欢把代码和电路“藏”进生活场景里的硬件爱好者,我一直在琢磨如何…...

AI Agent架构深度解析:从核心原理到工程实践
1. 项目概述:一次关于AI Agent的深度技术探险最近在GitHub上看到一个名为“tvytlx/ai-agent-deep-dive”的项目,光看标题就让人眼前一亮。这显然不是一个简单的“Hello World”式教程,而是一次对AI Agent(智能体)技术的…...

【仿真学习框架】HoloMotion 从入门到精通:全身人形控制 Foundation Model 完全指南
HoloMotion 从入门到精通:全身人形控制 Foundation Model 完全指南 目标读者:具身智能研究者、人形机器人开发者、RL/机器人学习工程师 目录 第1章 HoloMotion 全景概览 1.1 什么是 HoloMotion 1.2 技术定位:"小脑"基座模型 1.3 4-Any 愿景与路线图 1.4 核心能力矩…...