PaddlePaddle NLP学习笔记1 词向量
文章目录
- 1.语言模型 Language Model
- 1.1 语言模型是什么
- 1.2 语言模型计算什么
- 1.3 n-gram Language Model
- 2.神经网络语言模型NNLM
- 2.1 N-gram模型的问题
- 3. 词向量
- 3.1 词向量(word Embedding)
- word2vec 词向量训练算法
- 3.2 如何把词转换为词向量?
- 3.3如何让向量具有语义信息?
- 3.4 词向量算法CBOW和Skip-gram
- 3.5 用神经网络实现CBOW
- 4. 使用PaddleNLP加载词向量
- 5.使用VisualDL进行词向量可视化
- 6.系统环境
====================================
课程链接:零基础学习深度学习(第2版)
====================================
1.语言模型 Language Model
1.1 语言模型是什么
从前面的文字中推断出后续会出现的文字
eg. 今天欢迎大家来到飞桨学习课程---->今天欢迎大家来到飞桨学习___
通过语言模型推断出“课程’’
1.2 语言模型计算什么
计算这句话产生的文字的概率 词语同时出现的概率 条件概率等
1.3 n-gram Language Model
和前面n个词的关系
eg.
- 飞桨\学习 two-gram 与前面两个词有关
- 来到\飞桨\学习 tree-gram 与前面三个词有关
2.神经网络语言模型NNLM
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hMOACs4j-1681110145461)(C:\Users\朱振宇\AppData\Roaming\Typora\typora-user-images\image-20230409181006049.png)]](https://img-blog.csdnimg.cn/fc7e3ee3c47743d0ad85ad5d0087e908.png)
2.1 N-gram模型的问题
- 无法建模出更远距离的依赖关系
- 无法建模出词之间的相似度
- 泛化能力不够,对于训练集中没有出现过的n元组条件概率为0的情况,只能用平滑法赋予他们概率
2.2 平滑法
3. 词向量
3.1 词向量(word Embedding)
word2vec 词向量训练算法
Mikolov提出的经典word2vec算法就是通过上下文来学习语义信息。包括两个经典算法CBOW,Skip-gram。
-
高维空间的降维操作
-
是一种表示自然语言中单词的方法,即把每个词都表示为一个N维空间的一个点,即一个高维空间内的向量,通过这种方式,将自然语言计算转化为向量计算。
在自然语言处理任务中,词向量(Word Embedding)是表示自然语言里单词的一种方法,即把每个词都表示为一个N维空间内的点,即一个高维空间内的向量。通过这种方法,实现把自然语言计算转换为向量计算。
如图所示的词向量计算任务中,先把每个词(如queen,king等)转换成一个高维空间的向量,这些向量在一定意义上可以代表这个词的语义信息。再通过计算这些向量之间的距离,就可以计算出词语之间的关联关系,从而达到让计算机像计算数值一样去计算自然语言的目的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4nNt0vCu-1681110145462)(C:\Users\朱振宇\AppData\Roaming\Typora\typora-user-images\image-20230409191301669.png)]
3.2 如何把词转换为词向量?
3.3如何让向量具有语义信息?
3.4 词向量算法CBOW和Skip-gram
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cqEuRBiZ-1681110145463)(C:\Users\朱振宇\AppData\Roaming\Typora\typora-user-images\image-20230409191943887.png)]](https://img-blog.csdnimg.cn/0a78f4cf2f58467d96fa661264692491.png)
CBOW
给定一句话:Pineapples are spiked and yellow
- 使用上下文的词向量来预测中心词
- 中心词:“spiked"
- 上上文:“Pineapples are and yellow”
- 中心词的所限定的语义就被传递到上下文的词向量中,如“spiked->pineapple”,从而达到学习语义信息的目的
- 其他带刺的植物的向量表示就会靠近pineapple
Wvxn 是词向量

Skip-gram
给定一句话:Pineapples are spiked and yellow
- 使用中心词的词向量来预测上下文
- 中心词:“spiked"
- 上上文:“Pineapples are and yellow”
- 上下文定义的语义被传入到中心词的表示中,如“pineapple->spiked”
- spiked,prickly等词的向量表示就会逐渐的越来越相似
cbow比skip-gram训练快且更加稳定一些,然而,skip-gram比cbow更好地处理生僻字或者是一些评率低的字
3.5 用神经网络实现CBOW
给定一句话:Pineapples are spiked and yellow
C=4, V=5000, N=128
- 输入层:一个形状为C*V的one-hot的张量,其中C表示上下文中词的个数,对于eg中的句子C的值为4,V表示词表的大小
- 该张量的每一行都是一个上下文词的one-hot向量表示,比如[Pineapples,are,and,yellow]
- 隐藏层:一个形状为V*N的参数张量W1,一般称为word-embedding,N表示每个词的向量表示长度
- 输入张量的word embedding W1进行矩阵乘法,就会得到一个形状为C*N的张量
- 最后通过softamx函数,得到中心词的预测概率
实现Skip-gram的pycharm代码
preparedata.pyy
import sys
import requests
from collections import OrderedDict
import math
import random
import numpy as np
import paddle
from paddle.nn import Embedding
import paddle.nn.functional as F
import paddle.nn as nn# 读取text8数据
def load_text8():with open("./text8.txt", "r") as f:corpus = f.read().strip("\n")f.close()return corpus# 对语料进行预处理(分词)
def data_preprocess(corpus):# 由于英文单词出现在句首的时候经常要大写,所以我们把所有英文字符都转换为小写,# 以便对语料进行归一化处理(Apple vs apple等)corpus = corpus.strip().lower()corpus = corpus.split(" ")return corpus# 构造词典,统计每个词的频率,并根据频率将每个词转换为一个整数id
def build_dict(corpus):# 首先统计每个不同词的频率(出现的次数),使用一个词典记录word_freq_dict = dict()for word in corpus:if word not in word_freq_dict:word_freq_dict[word] = 0word_freq_dict[word] += 1# 将这个词典中的词,按照出现次数排序,出现次数越高,排序越靠前# 一般来说,出现频率高的高频词往往是:I,the,you这种代词,而出现频率低的词,往往是一些名词,如:nlpword_freq_dict = sorted(word_freq_dict.items(), key=lambda x: x[1], reverse=True)# 构造3个不同的词典,分别存储,# 每个词到id的映射关系:word2id_dict# 每个id出现的频率:word2id_freq# 每个id到词的映射关系:id2word_dictword2id_dict = dict()word2id_freq = dict()id2word_dict = dict()# 按照频率,从高到低,开始遍历每个单词,并为这个单词构造一个独一无二的idfor word, freq in word_freq_dict:curr_id = len(word2id_dict)word2id_dict[word] = curr_idword2id_freq[word2id_dict[word]] = freqid2word_dict[curr_id] = wordreturn word2id_freq, word2id_dict, id2word_dict# 把语料转换为id序列
def convert_corpus_to_id(corpus, word2id_dict):# 使用一个循环,将语料中的每个词替换成对应的id,以便于神经网络进行处理corpus = [word2id_dict[word] for word in corpus]return corpus# 使用二次采样算法(subsampling)处理语料,强化训练效果
def subsampling(corpus, word2id_freq):# 这个discard函数决定了一个词会不会被替换,这个函数是具有随机性的,每次调用结果不同# 如果一个词的频率很大,那么它被遗弃的概率就很大def discard(word_id):return random.uniform(0, 1) < 1 - math.sqrt(1e-4 / word2id_freq[word_id] * len(corpus))corpus = [word for word in corpus if not discard(word)]return corpus# 构造数据,准备模型训练
# max_window_size代表了最大的window_size的大小,程序会根据max_window_size从左到右扫描整个语料
# negative_sample_num代表了对于每个正样本,我们需要随机采样多少负样本用于训练,
# 一般来说,negative_sample_num的值越大,训练效果越稳定,但是训练速度越慢。
def build_data(corpus, word2id_dict, word2id_freq, max_window_size=3, negative_sample_num=4):# 使用一个list存储处理好的数据dataset = []# 从左到右,开始枚举每个中心点的位置for center_word_idx in range(len(corpus)):# 以max_window_size为上限,随机采样一个window_size,这样会使得训练更加稳定window_size = random.randint(1, max_window_size)# 当前的中心词就是center_word_idx所指向的词center_word = corpus[center_word_idx]# 以当前中心词为中心,左右两侧在window_size内的词都可以看成是正样本positive_word_range = (max(0, center_word_idx - window_size), min(len(corpus) - 1, center_word_idx + window_size))positive_word_candidates = [corpus[idx] for idx in range(positive_word_range[0], positive_word_range[1] + 1) ifidx != center_word_idx]vocab_size = len(word2id_freq)# 对于每个正样本来说,随机采样negative_sample_num个负样本,用于训练for positive_word in positive_word_candidates:# 首先把(中心词,正样本,label=1)的三元组数据放入dataset中,# 这里label=1表示这个样本是个正样本dataset.append((center_word, positive_word, 1))# 开始负采样i = 0while i < negative_sample_num:negative_word_candidate = random.randint(0, vocab_size - 1)if negative_word_candidate not in positive_word_candidates:# 把(中心词,正样本,label=0)的三元组数据放入dataset中,# 这里label=0表示这个样本是个负样本dataset.append((center_word, negative_word_candidate, 0))i += 1return dataset# 构造mini-batch,准备对模型进行训练
# 我们将不同类型的数据放到不同的tensor里,便于神经网络进行处理
# 并通过numpy的array函数,构造出不同的tensor来,并把这些tensor送入神经网络中进行训练
def build_batch(dataset, batch_size, epoch_num):# center_word_batch缓存batch_size个中心词center_word_batch = []# target_word_batch缓存batch_size个目标词(可以是正样本或者负样本)target_word_batch = []# label_batch缓存了batch_size个0或1的标签,用于模型训练label_batch = []for epoch in range(epoch_num):# 每次开启一个新epoch之前,都对数据进行一次随机打乱,提高训练效果random.shuffle(dataset)for center_word, target_word, label in dataset:# 遍历dataset中的每个样本,并将这些数据送到不同的tensor里center_word_batch.append([center_word])target_word_batch.append([target_word])label_batch.append(label)# 当样本积攒到一个batch_size后,我们把数据都返回回来# 在这里我们使用numpy的array函数把list封装成tensor# 并使用python的迭代器机制,将数据yield出来# 使用迭代器的好处是可以节省内存if len(center_word_batch) == batch_size:yield np.array(center_word_batch).astype("int64"), \np.array(target_word_batch).astype("int64"), \np.array(label_batch).astype("float32")center_word_batch = []target_word_batch = []label_batch = []if len(center_word_batch) > 0:yield np.array(center_word_batch).astype("int64"), \np.array(target_word_batch).astype("int64"), \np.array(label_batch).astype("float32")if __name__ == '__main__':corpus = load_text8()corpus = data_preprocess(corpus)word2id_freq, word2id_dict, id2word_dict = build_dict(corpus)vocab_size = len(word2id_freq)corpus = convert_corpus_to_id(corpus, word2id_dict)corpus = subsampling(corpus, word2id_freq)corpus_light = corpus[:int(len(corpus) * 0.2)]dataset = build_data(corpus_light, word2id_dict, word2id_freq)for _, batch in zip(range(10), build_batch(dataset, 128, 3)):print(batch)break
SkipGram.py
from prepare_data import *# 定义skip-gram训练网络结构
# 使用paddlepaddle的2.0.0版本
# 一般来说,在使用paddle训练的时候,我们需要通过一个类来定义网络结构,这个类继承了paddle.nn.layer
class SkipGram(nn.Layer):def __init__(self, vocab_size, embedding_size, init_scale=0.1):# vocab_size定义了这个skipgram这个模型的词表大小# embedding_size定义了词向量的维度是多少# init_scale定义了词向量初始化的范围,一般来说,比较小的初始化范围有助于模型训练super(SkipGram, self).__init__()self.vocab_size = vocab_sizeself.embedding_size = embedding_size# 使用Embedding函数构造一个词向量参数# 这个参数的大小为:[self.vocab_size, self.embedding_size]# 数据类型为:float32# 这个参数的初始化方式为在[-init_scale, init_scale]区间进行均匀采样self.embedding = Embedding(num_embeddings=self.vocab_size,embedding_dim=self.embedding_size,weight_attr=paddle.ParamAttr(initializer=paddle.nn.initializer.Uniform(low=-init_scale, high=init_scale)))# 使用Embedding函数构造另外一个词向量参数# 这个参数的大小为:[self.vocab_size, self.embedding_size]# 这个参数的初始化方式为在[-init_scale, init_scale]区间进行均匀采样self.embedding_out = Embedding(num_embeddings=self.vocab_size,embedding_dim=self.embedding_size,weight_attr=paddle.ParamAttr(initializer=paddle.nn.initializer.Uniform(low=-init_scale, high=init_scale)))# 定义网络的前向计算逻辑# center_words是一个tensor(mini-batch),表示中心词# target_words是一个tensor(mini-batch),表示目标词# label是一个tensor(mini-batch),表示这个词是正样本还是负样本(用0或1表示)# 用于在训练中计算这个tensor中对应词的同义词,用于观察模型的训练效果def forward(self, center_words, target_words, label):# 首先,通过self.embedding参数,将mini-batch中的词转换为词向量# 这里center_words和eval_words_emb查询的是一个相同的参数# 而target_words_emb查询的是另一个参数center_words_emb = self.embedding(center_words)target_words_emb = self.embedding_out(target_words)# 我们通过点乘的方式计算中心词到目标词的输出概率,并通过sigmoid函数估计这个词是正样本还是负样本的概率。word_sim = paddle.multiply(center_words_emb, target_words_emb)word_sim = paddle.sum(word_sim, axis=-1)word_sim = paddle.reshape(word_sim, shape=[-1])pred = F.sigmoid(word_sim)# 通过估计的输出概率定义损失函数,注意我们使用的是binary_cross_entropy_with_logits函数# 将sigmoid计算和cross entropy合并成一步计算可以更好的优化,所以输入的是word_sim,而不是predloss = F.binary_cross_entropy_with_logits(word_sim, label)loss = paddle.mean(loss)# 返回前向计算的结果,飞桨会通过backward函数自动计算出反向结果。return pred, losscorpus = load_text8()
corpus = data_preprocess(corpus)
word2id_freq, word2id_dict, id2word_dict = build_dict(corpus)
vocab_size = len(word2id_freq)corpus = convert_corpus_to_id(corpus, word2id_dict)
corpus = subsampling(corpus, word2id_freq)corpus_light = corpus[:int(len(corpus) * 0.2)]
dataset = build_data(corpus_light, word2id_dict, word2id_freq)# 开始训练,定义一些训练过程中需要使用的超参数
batch_size = 512
epoch_num = 3
embedding_size = 200
step = 0
learning_rate = 0.001# 定义一个使用word-embedding查询同义词的函数
# 这个函数query_token是要查询的词,k表示要返回多少个最相似的词,embed是我们学习到的word-embedding参数
# 我们通过计算不同词之间的cosine距离,来衡量词和词的相似度
# 具体实现如下,x代表要查询词的Embedding,Embedding参数矩阵W代表所有词的Embedding
# 两者计算Cos得出所有词对查询词的相似度得分向量,排序取top_k放入indices列表
def get_similar_tokens(query_token, k, embed):W = embed.numpy()x = W[word2id_dict[query_token]]cos = np.dot(W, x) / np.sqrt(np.sum(W * W, axis=1) * np.sum(x * x) + 1e-9)flat = cos.flatten()indices = np.argpartition(flat, -k)[-k:]indices = indices[np.argsort(-flat[indices])]for i in indices:print('for word %s, the similar word is %s' % (query_token, str(id2word_dict[i])))# 通过我们定义的SkipGram类,来构造一个Skip-gram模型网络
skip_gram_model = SkipGram(vocab_size, embedding_size)# 构造训练这个网络的优化器
adam = paddle.optimizer.Adam(learning_rate=learning_rate, parameters=skip_gram_model.parameters())# 使用build_batch函数,以mini-batch为单位,遍历训练数据,并训练网络
for center_words, target_words, label in build_batch(dataset, batch_size, epoch_num):# 使用paddle.to_tensor,将一个numpy的tensor,转换为飞桨可计算的tensorcenter_words_var = paddle.to_tensor(center_words)target_words_var = paddle.to_tensor(target_words)label_var = paddle.to_tensor(label)# 将转换后的tensor送入飞桨中,进行一次前向计算,并得到计算结果pred, loss = skip_gram_model(center_words_var, target_words_var, label_var)# 程序自动完成反向计算loss.backward()# 程序根据loss,完成一步对参数的优化更新adam.step()# 清空模型中的梯度,以便于下一个mini-batch进行更新adam.clear_grad()# 每经过100个mini-batch,打印一次当前的loss,看看loss是否在稳定下降step += 1if step % 1000 == 0:print("step %d, loss %.3f" % (step, loss.numpy()[0]))# 每隔10000步,打印一次模型对以下查询词的相似词,这里我们使用词和词之间的向量点积作为衡量相似度的方法,只打印了5个最相似的词if step % 10000 == 0:get_similar_tokens('movie', 5, skip_gram_model.embedding.weight)get_similar_tokens('one', 5, skip_gram_model.embedding.weight)get_similar_tokens('chip', 5, skip_gram_model.embedding.weight)具体实现的讲解可以去看百度飞桨团队的讲解
4. 使用PaddleNLP加载词向量
import paddle
from paddlenlp.embeddings import TokenEmbedding, list_embedding_name
paddle.set_device("cpu")# 查看预训练embedding名称:
print(list_embedding_name()) # ['w2v.baidu_encyclopedia.target.word-word.dim300']# 初始化TokenEmbedding, 预训练embedding没下载时会自动下载并加载数据
token_embedding = TokenEmbedding(embedding_name="w2v.baidu_encyclopedia.target.word-word.dim300")# 查看token_embedding详情
# print(token_embedding)# 使用token_embedding.cosine_sim API 可以轻松地计算两个词汇之间的cosine相似度
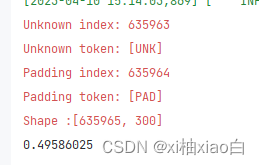
if __name__ == '__main__':score = token_embedding.cosine_sim("中国", "美国")print(score)
使用PaddleNLP可以大大简化操作的步骤,运行结果如下

5.使用VisualDL进行词向量可视化
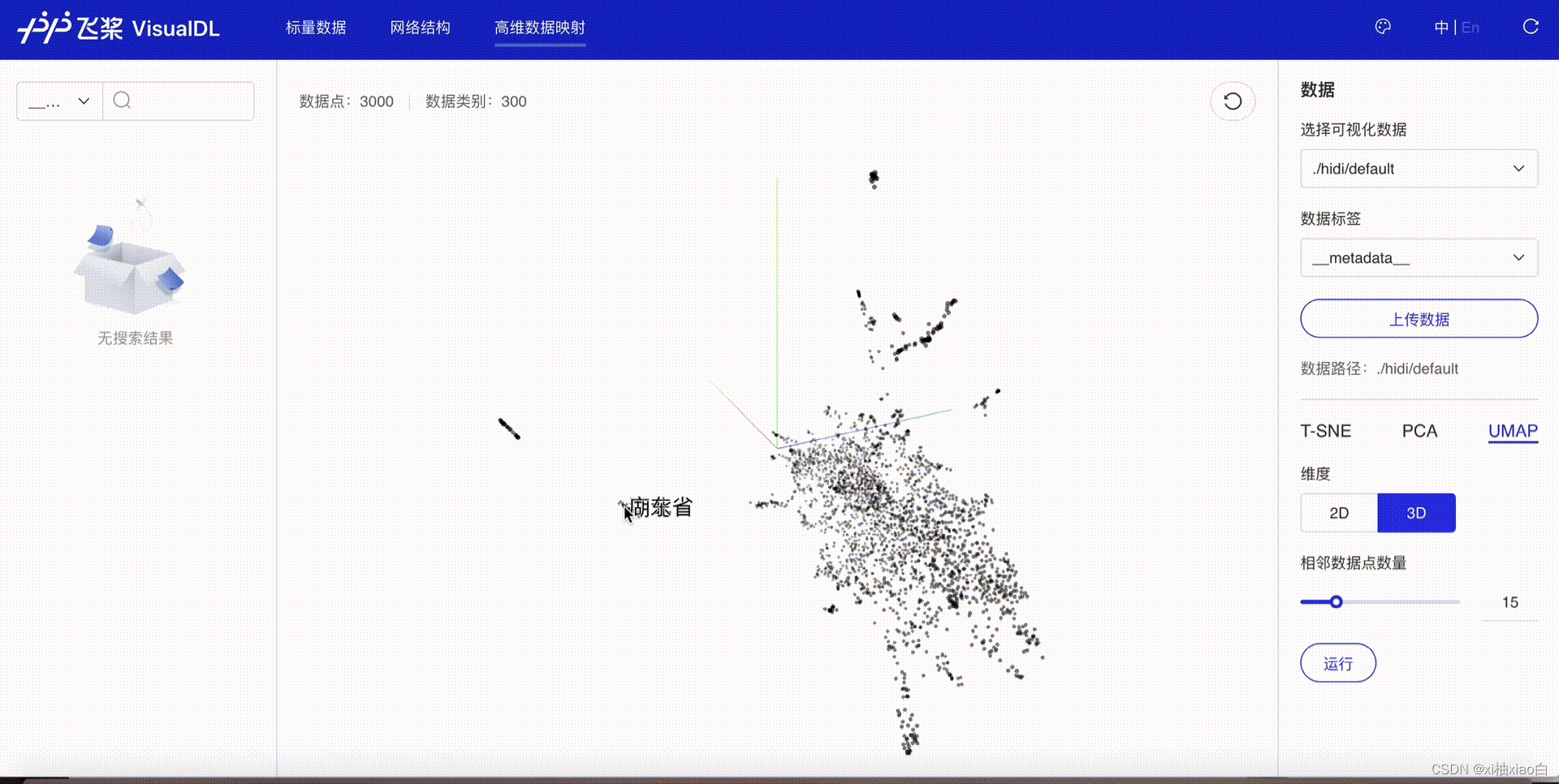
运行代码如下
# 引入VisualDL的LogWriter记录日志
from visualdl import LogWriter
import paddle
from paddlenlp.embeddings import TokenEmbedding, list_embedding_name
from visualdl.server import apppaddle.set_device("cpu")# 查看预训练embedding名称:
print(list_embedding_name()) # ['w2v.baidu_encyclopedia.target.word-word.dim300']# 初始化TokenEmbedding, 预训练embedding没下载时会自动下载并加载数据
token_embedding = TokenEmbedding(embedding_name="w2v.baidu_encyclopedia.target.word-word.dim300")# 获取词表中前1000个单词
labels = token_embedding.vocab.to_tokens(list(range(0,1000)))
test_token_embedding = token_embedding.search(labels)with LogWriter(logdir='./visualize') as writer:writer.add_embeddings(tag='test', mat=test_token_embedding, metadata=labels)if __name__ == '__main__':app.run(logdir="./visualize")运行结果如下

按照提示,浏览器进入给出的网址就可以进入查看开头的效果。
6.系统环境
乱下的 不知道为什么就这么多依赖包了 主要是那几个Paddle的包要正确
Windows11 miniconda
(paddle_learn) D:\python_project\paddle_learn\NLP\NLPtest1>pip list
Package Version
aiofiles 23.1.0
aiohttp 3.8.4
aiosignal 1.3.1
altair 4.2.2
anyio 3.6.2
astor 0.8.1
async-timeout 4.0.2
attrdict 2.0.1
attrs 22.2.0
Babel 2.12.1
bce-python-sdk 0.8.79
Brotli 1.0.9
certifi 2022.12.7
cffi 1.15.1
charset-normalizer 3.1.0
click 8.1.3
colorama 0.4.6
colorlog 6.7.0
contourpy 1.0.7
cycler 0.11.0
datasets 2.10.1
decorator 5.1.1
dill 0.3.4
easydict 1.10
entrypoints 0.4
fastapi 0.95.0
ffmpy 0.3.0
filelock 3.11.0
Flask 2.2.3
Flask-Babel 2.0.0
fonttools 4.39.3
frozenlist 1.3.3
fsspec 2023.3.0
future 0.18.3
gevent 22.10.2
geventhttpclient 2.0.2
gradio 3.24.1
gradio_client 0.0.8
greenlet 2.0.2
grpcio 1.52.0
h11 0.14.0
httpcore 0.16.3
httpx 0.23.3
huggingface-hub 0.13.4
idna 3.4
importlib-metadata 6.1.0
importlib-resources 5.12.0
itsdangerous 2.1.2
jieba 0.42.1
Jinja2 3.1.2
joblib 1.2.0
jsonschema 4.17.3
kiwisolver 1.4.4
linkify-it-py 2.0.0
lxml 4.9.2
markdown-it-py 2.2.0
MarkupSafe 2.1.2
matplotlib 3.7.1
mdit-py-plugins 0.3.3
mdurl 0.1.1
mpmath 1.3.0
multidict 6.0.4
multiprocess 0.70.12.2
numpy 1.24.2
onnx 1.13.1
opencv-contrib-python 4.7.0.72
opencv-python 4.7.0.72
opt-einsum 3.3.0
orjson 3.8.7
packaging 23.0
paddle-bfloat 0.1.7
paddle2onnx 1.0.6
paddlefsl 1.1.0
paddlehub 2.3.1
paddlenlp 2.5.2
paddlepaddle-gpu 2.4.2
pandas 1.5.3
Pillow 9.5.0
pip 23.0.1
pkgutil_resolve_name 1.3.10
protobuf 3.20.0
psutil 5.9.4
pyarrow 11.0.0
pycparser 2.21
pycryptodome 3.17
pydantic 1.10.6
pydub 0.25.1
Pygments 2.14.0
pyparsing 3.0.9
pyrsistent 0.19.3
python-dateutil 2.8.2
python-multipart 0.0.6
python-rapidjson 1.10
pytils 0.4.1
pytz 2022.7.1
PyYAML 6.0
pyzmq 25.0.1
rarfile 4.0
requests 2.28.2
responses 0.18.0
rfc3986 1.5.0
rich 13.3.2
scikit-learn 1.2.2
scipy 1.10.1
semantic-version 2.10.0
sentencepiece 0.1.96
seqeval 1.2.2
setuptools 65.6.3
six 1.16.0
sniffio 1.3.0
starlette 0.26.1
sympy 1.11.1
threadpoolctl 3.1.0
tools 0.1.9
toolz 0.12.0
tqdm 4.65.0
tritonclient 2.31.0
typer 0.7.0
typing_extensions 4.5.0
uc-micro-py 1.0.1
urllib3 1.26.15
uvicorn 0.21.1
visualdl 2.4.2
websockets 10.4
Werkzeug 2.2.3
wheel 0.38.4
wincertstore 0.2
x2paddle 1.4.0
xxhash 3.2.0
yarl 1.8.2
zipp 3.15.0
zope.event 4.6
zope.interface 6.0
相关文章:
PaddlePaddle NLP学习笔记1 词向量
文章目录1.语言模型 Language Model1.1 语言模型是什么1.2 语言模型计算什么1.3 n-gram Language Model2.神经网络语言模型NNLM2.1 N-gram模型的问题3. 词向量3.1 词向量(word Embedding)word2vec 词向量训练算法3.2 如何把词转换为词向量?3.3如何让向量具有语义信息…...

无重复全排列 [2*+]
目录 无重复全排列 [2*+] 程序设计 程序分析 无重复全排列 [2*+] 输出N个数的无重复全排列 Input 输入一个数值N 1<=N=50 Output 输出N个数的无重复全排列,每个数之间用空格隔开 最后一行输出无重复全排列的个数。 Sample Input 3 Sample Output 1 2...

【血泪建议】软件测试岗位现状,可惜之前没人告诉我,肠子都晦青了....
谈到现状,国内的软件测试行情目前呈现了两极分化的极端情况。 一个是早期的手工测试人员吐槽工作不好做,即使有工作也是外包,而且薪资太低;一方面是很多互联网企业感叹自动化测试人才难找,有技术的自动化测试工程师&a…...
Elastic(ELK) Stack 架构师成长路径
Elastic Stack(ELK Stack)是一个开源的日志分析平台,由 Elasticsearch、Logstash 和 Kibana 三个组件组成,主要用于数据搜索、分析和可视化。要成为一名 ELK Stack 架构师,需要遵循一定的成长路径,以便逐步…...

Netty的高性能体现在哪些方面
文章目录Netty的高性能体现在哪些方面1. 非阻塞I/O2. 零拷贝3. 内存池4. 线程模型Netty的高性能体现在哪些方面 Netty是一个高性能、异步事件驱动的网络应用程序框架,它具有出色的稳定性和灵活性。在现代的分布式系统和互联网应用中,Netty已经成为构建高…...
CompletableFuture详解
1、概述 咱们都知道可以通过继承Thread类或者实现Runnable接口两种方式实现多线程。但是有时候我们希望得到多线程异步任务执行后的结果,也就是异步任务执行后有返回值,Thread和Runnable是不能实现的。当我们需要返回值的时候怎么办呢? Java…...

(学习日记)2023.3.10
写在前面: 由于时间的不足与学习的碎片化,写博客变得有些奢侈。 但是对于记录学习(忘了以后能快速复习)的渴望一天天变得强烈。 既然如此 不如以天为单位,以时间为顺序,仅仅将博客当做一个知识学习的目录&a…...

【图像分割】Meta分割一切(SAM)模型环境配置和使用教程
注意:python>3.8, pytorch>1.7,torchvision>0.8 Feel free to ask any question. 遇到问题欢迎评论区讨论. 官方教程: https://github.com/facebookresearch/segment-anything 1 环境配置 1.1 安装主要库: (1&…...

AJ入门路线
一.AspectJ 入门 概述安装示例代码切入点表达式thisJoinPointStaticPart 和 thisJoinPoint与Spring 切面写法的对比总结 初步了解了aspectJ的使用,我们可以了解以下几点: 1)aspectJ的使用是在编译期,通过特殊的编译器可以在不改变…...

多商户商城小程序源码开发需具备哪些功能?
随着电商的进一步发展,传统企业为了更好的占领市场也纷纷向电商市场迈进,着手打造属于自己的商城系统。多商户商城系统是一种多商户、多商品、多支付的电子商务平台,功能丰富,涵盖多个行业,能够满足多种商家和用户的需…...

【动态规划模板】最长公共|上升子序列问题
最长公共子序列🍉 给定两个长度分别为N和M的字符串A和B,求既是A的子序列又是B的子序列的字符串长度最长是多少。 输入格式 第一行包含两个整数 N 和 M。 第二行包含一个长度为N的字符串,表示字符串A。 第三行包含一个长度为M的字符串&am…...
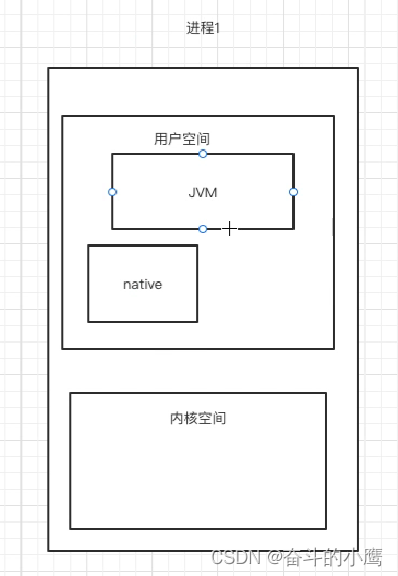
Android系统启动流程--zygote进程的启动流程
在上一篇init进程启动流程中已经提到,在init中会解析一个init.rc文件,解析后会执行其中的命令来启动zygote进程、serviceManager进程等,下面我们来看一下: //文件路径:system/core/init/init.cppstatic void LoadBoot…...
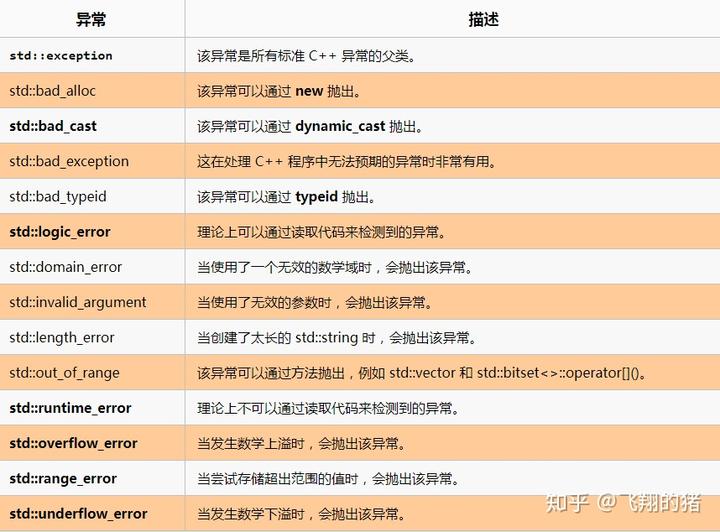
C++程序设计——异常
一、C异常概念 异常处理是一种处理错误的方式,当一个函数发现自己无法处理的错误时,就可以抛出异常,让函数的直接或间接的调用者处理这个错误。 (1)throw:当问题出现时,程序会通过throw关键字抛…...

2022年第十三届蓝桥杯web开发—东奥大抽奖【题目、附官方解答】
冬奥大抽奖 介绍 蓝桥云课庆冬奥需要举行一次抽奖活动,我们一起做一个页面提供给云课冬奥抽奖活动使用。 准备 开始答题前,需要先打开本题的项目代码文件夹,目录结构如下: ├── css │ └── style.css ├── effect.g…...

一份两年前一个月的工作经历没写在简历上,背调前主动坦白,却被背调公司亮了红灯,到手的offer没了!...
只因为简历上漏写了一份一个月的工作,就被亮了背调红灯,这公平吗?一位网友就被狠狠坑了一把,来看下他的遭遇:他有一份两年前、时长一个月的工作经历没写在简历上,背调前主动和背调公司还有招聘方hr都说了这…...
C++游戏分析与破解方法介绍
1、C游戏简介 目前手机游戏直接用C开发的已经不多,使用C开发的多是早期的基于cocos2dx的游戏,因此我们这里就以cocos2d-x为例讲解C游戏的分析与破解方法。 Cocos2d-x是一个移动端游戏开发框架,可以使用C或者lua进行开发,也可以混…...

食堂总是拥挤不堪?解决用餐拥挤,教你一招
随着近几年科技的快速发展,行业里出现了很多新的名词,比如智慧社区、智慧旅游、智慧建筑,那么智慧食堂是什么呢?它又是如何实现全自助、全智能消费? 在先进的智能技术以及市场需求带动下,智慧食堂经历了由传…...

ubuntu系统安装时 MBR和GPT的区别
主引导记录(Master Boot Record , MBR)是指一个存储设备的开头 512 字节。它包含操作系统的引导器和存储设备的分区表。 全局唯一标识分区表(GUID Partition Table,缩写:GPT)是一个实体硬盘…...
我在windows10下,使用msys64 mingw64终端
系列文章目录 文章目录系列文章目录前言一、MSYS2是什么?前言 msys2官网 MSYS2 (Minimal SYStem 2) 是一个MSYS的独立改写版本,主要用于 shell 命令行开发环境。 同时它也是一个在Cygwin (POSIX 兼容性层)…...
)
个人2023FALL CS申请总结(PhD/MPhil/保研夏令营)
个人2023FALL CS申请总结(PhD/MPhil/保研夏令营)写在最前个人BG及申请情况个人BG申请情况MPhilPhD收获一句话总结:心态爆炸没用,脸皮够厚够勇就行 写在最前 真是一场恶战。有几天,我每天早上都海投几封套瓷邮件&…...

Source Han Serif CN:企业级开源字体终极实战指南
Source Han Serif CN:企业级开源字体终极实战指南 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 在当今数字化时代,企业面临字体选择的两难困境:商…...

Arm Neoverse CMN-700互连架构与协议寄存器配置指南
1. Arm Neoverse CMN-700一致性互连架构解析在现代多核处理器设计中,一致性互连网络如同城市交通系统般重要。Arm Neoverse CMN-700作为第二代Coherent Mesh Network解决方案,其架构设计充分考虑了数据中心和边缘计算的严苛需求。与传统的总线或环形拓扑…...

抖音批量下载神器:5分钟学会免费高效下载视频、音乐和直播
抖音批量下载神器:5分钟学会免费高效下载视频、音乐和直播 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback s…...

轻量级监控系统Monikhao:自托管部署与核心架构解析
1. 项目概述:一个轻量级、可自托管的监控解决方案最近在折腾个人服务器和家庭网络监控时,发现了一个挺有意思的项目:khaodius/monikhao。乍一看这个名字,可能会觉得有点陌生,但如果你对自建监控系统有需求,…...

Python自动化Excel数据抓取:OpenClaw技能实战指南
1. 项目概述:从Excel表格到智能数据抓取如果你每天的工作都离不开Excel,并且经常需要从各种网页、文档甚至PDF里手动复制粘贴数据,然后费劲地整理到表格里,那你一定对“Excel大师”这个称号既向往又头疼。我们总希望Excel能更“聪…...

基于Sovereign-MCP-Servers构建私有AI工具链:从协议原理到Docker化部署
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想给Claude、Cursor这类工具加上“联网”和“执行”能力时,绕不开一个概念:MCP(Model Context Protocol)。简单说,MCP就是一套标准协议,它能让…...

Ruby专属LLM应用框架ruby_llm:从基础集成到生产部署实战
1. 项目概述:一个为Ruby语言量身打造的LLM应用框架如果你是一名Ruby开发者,最近被各种大语言模型(LLM)的应用搞得心痒痒,但看着满世界的Python库和框架感到无从下手,那么crmne/ruby_llm这个项目可能就是你在…...

faah:轻量级自动化任务编排器,简化运维与数据处理工作流
1. 项目概述:一个被低估的自动化利器最近在整理自己的自动化工具链时,又翻出了kiron0/faah这个项目。说实话,第一次看到这个仓库名,我也有点懵——“faah”?这名字听起来不像是一个典型的工具。但点进去之后࿰…...

MedAgentBench:大语言模型在医学诊断中的动态评估与智能体构建实践
1. 项目概述:当大语言模型成为医学诊断的“实习生”最近在医学人工智能的圈子里,一个名为MedAgentBench的项目引起了我的注意。它来自斯坦福大学机器学习组,这个名字本身就自带光环。简单来说,这不是一个直接看病的AI,…...

Deep Lake:AI数据湖与向量数据库一体化管理实践
1. 项目概述:当数据湖遇上深度学习如果你正在构建一个AI应用,无论是图像识别、自然语言处理还是多模态模型,数据管理绝对是你绕不开的“硬骨头”。数据分散在各个文件夹、云存储、数据库里,格式五花八门,加载速度慢&am…...