Python 之 NumPy 切片索引和广播机制
文章目录
- 一、切片和索引
- 1. 一维数组
- 2. 二维数组
- 二、索引的高级操作
- 1. 整数数组索引
- 2. 布尔数组索引
- 三、广播机制
- 1. 广播机制规则
- 2. 对于广播规则另一种简单理解
一、切片和索引
- ndarray 对象的内容可以通过索引或切片来访问和修改(),与 Python 中 list 的切片操作一样。
- ndarray 数组可以基于 0 - n 的下标进行索引(先行后列,都是从 0 开始)。
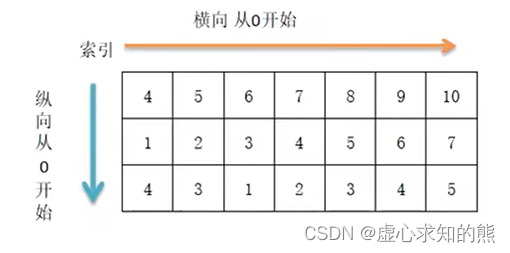
- 区别在于:数组切片是原始数组视图(这就意味着,如果做任何修改,原始都会跟着更改)。 这也意味着,如果不想更改原始数组,我们需要进行显式的复制,从而得到它的副本(.copy())。
冒号分隔切片参数 [start:stop:step]。- 在开始之前,先导入numpy包
import numpy as np
1. 一维数组
- 通过 numpy.arange() 生成一个等区间的数组(起始值默认为 0,步长默认为 1,终止值设置为 10)。
ar1 = np.arange(10)
ar1
#array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
- 从索引 2 开始到索引 7 停止,间隔为 2。
ar2 = ar1[2:7:2]
ar2
#array([2, 4, 6])
- 这里需要解释以下冒号的作用:
- 如果只放置一个参数,如果是 [2],将返回与该索引相对应的单个元素;如果为 [2:],表示从该索引开始以后的所有项都将被提取;如果为 [:2],表示不限制开始元素,但会在该元素截止。
- 如果使用了两个参数,如 [2:7],那么则提取两个索引(不包括停止索引)之间的项。
- 返回索引对应的数据(注意是从0开始的)。
print('ar1:',ar1)
print('ar1[4]:',ar1[4])
#ar1: [0 1 2 3 4 5 6 7 8 9]
#ar1[4]: 4
- 通过 numpy.arange() 生成一个等区间的数组(起始值设置为 1,终止值设置为 20,步长设置为 2)。
ar3 = np.arange(1,20,2)
ar3
#array([ 1, 3, 5, 7, 9, 11, 13, 15, 17, 19])
- 那么,我们如何取出元素 9?
- 由于索引是从 0 开始的,因此,我们输出 ar3[4] 即可。
- (1) 从该索引开始以后的所有项都将被提取
- 从索引 2 开始,提取出后面所有数据。
print(ar3)
ar3[2:]
#[ 1 3 5 7 9 11 13 15 17 19]
#array([ 5, 7, 9, 11, 13, 15, 17, 19])
- (2) 从索引开始,到索引结束(不包含结束)
- 从索引 2 开始到索引 7(包含索引 7)。
print(ar3)
ar3[2:7]
ar3[:-2]
#[ 1 3 5 7 9 11 13 15 17 19]
#array([ 1, 3, 5, 7, 9, 11, 13, 15])
- (3) 步长
- 取所有数据,步长为 -1(负数代表从右往左数)。
ar3[::-1]
#array([19, 17, 15, 13, 11, 9, 7, 5, 3, 1])
- 取数据 1 到 17 之间, 并且间隔一位的数据。
ar3[1:-2:2]
print(ar3)
print(ar3[:6])
print(ar3[6:])
#[ 1 3 5 7 9 11 13 15 17 19]
#[ 1 3 5 7 9 11]
#[13 15 17 19]
- (4) 为什么切片和区间会忽略最后一个元素
- 计算机科学家 edsger w.dijkstra(艾兹格·W·迪科斯彻),delattr 这一风格的解释应该是比较好的:
- (1) 当只有最后一个位置信息时,我们可以快速看出切片和区间里有几个元素:range(3) 和 my_list[:3]。
- (2) 当起始位置信息都可见时,我们可以快速计算出切片和区间的长度,用有一个数减去第一个下表(stop-start)即可。
- (3) 这样做也让我们可以利用任意一个下标把序列分割成不重叠的两部分,只要写成 my_list[:x] 和 my_list[x:] 就可以了。
2. 二维数组
- 同样适用上述索引提取方法:
- 我们定义 4 行 5 列的数据。
- np.arange(20) 表示起始值默认为 0,终止值设置为 20,步长默认为 1。
- reshape(4,5) 表示生成一个 4 行 5 列的二维数组。
ar4_5 = np.arange(20).reshape(4,5)
ar4_5
#array([[ 0, 1, 2, 3, 4],
# [ 5, 6, 7, 8, 9],
# [10, 11, 12, 13, 14],
# [15, 16, 17, 18, 19]])
- 我们通过 ar4_5.ndim 返回 ar4_5 的秩(也就是几维)。
ar4_5.ndim
#2
- 切片表示的是下一维度的一个元素,所以其代表一维数组。
ar4_5[2]
#array([10, 11, 12, 13, 14])
- 我们也可以通过二次索引取得一维数组当中的元素。
ar4_5[2][2]
#12
- 打印出 ar4_5 整体数组,便于后续的操作观察。
print(ar4_5)
#[[ 0 1 2 3 4]
# [ 5 6 7 8 9]
# [10 11 12 13 14]
# [15 16 17 18 19]]
- 我们可以取出从第三行和第四行的元素。
ar4_5[2:]
#array([[10, 11, 12, 13, 14],
# [15, 16, 17, 18, 19]])
- 注意:切片还可以使用省略号 “…”,如果在行位置使用省略号,那么返回值将包含所有行元素,反之,则包含所有列元素。
- 例如,我们需要取得第二列数据(由于索引是从 0 开始的,因此 第二列的元素就是 1)。
- 取出的就是每一行和第二列交叉的数据,也就是 1,6,11,16。
ar4_5[...,1]
#array([ 1, 6, 11, 16])
- 我们需要返回第二列后的所有项。
ar4_5[...,1:]
#array([[ 1, 2, 3, 4],
# [ 6, 7, 8, 9],
# [11, 12, 13, 14],
# [16, 17, 18, 19]])
- 我们需要返回第 2 行第 3 列的数据(对于取出单个数值,两种方法是一样的)。
ar4_5[1,2] # 对应(1,2) 的元素
#7
- 对于返回第 2 行第 3 列的数据,我们也可以使用如下方法。
ar4_5[1][2]
#7
- 对于上述关于取出单个数据的方法,是否可以映射到取出一列元素呢?
- 如下例子所示,答案是否定的。
- 首先,我们执行第一步操作,就是 ar4_5[…]。此时,代表取出 ar4_5 的每一行元素,也就是打印 ar4_5 本身。
- 然后,我们执行第二步操作 ar4_5[…][1] ,就是切片,在 ar4_5 本身上打印处第二行,也就是 [5, 6, 7, 8, 9]。
ar4_5[...][1]
array([5, 6, 7, 8, 9])
二、索引的高级操作
- 在 NumPy 中还可以使用高级索引方式,比如整数数组索引、布尔索引,以下将对两种种索引方式做详细介绍。
1. 整数数组索引
- 我们先创建一个二维数组。
x = np.array([[1,2],[3,4],[5,6]])
y = x[[0,1,2],[0,1,0]]
y
#array([1,4,5])
- 其中,[0,1,2] 代表行索引,[0,1,0] 代表列索引,表示 y 分别获取 x 中的 (0,0)、(1,1) 和 (2,0) 表示的数据。
- 然后,我们先创建一个 43 的数组,创建完成之后,获取了 43 数组中的四个角上元素,它们对应的行索引是 [0,0] 和 [3,3],列索引是 [0,2] 和 [0,2]。
b = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9,10,11]])
a = b[[0,0,3,3],[0,2,0,2]] # (0,0) (0,2) (3,0) (3,2)r = np.array([[0,0] ,[3,3]]).reshape(4) #用r代替[0,0,3,3]
l = np.array([[0,2] ,[0,2]]).reshape(4) #用l代替[0,2,0,2]
s = b[r,l].reshape((2,2))
s
#array([[ 0, 2],
# [ 9, 11]])
- 然后,我们先创建一个 3*3 的数组,创建完成之后,行取出第 2 行和第 3 行的元素,列取出第 2 列和第 3 列的数据。
- 这里需要注意的是,不包含终止索引值。
a = np.array([[1,2,3], [4,5,6],[7,8,9]])
b = a[1:3, 1:3]
b
#array([[5, 6],
# [8, 9]])
- 也就是 1:3 == [1,2]。
- 高级索引操作与常规的索引操作相同,都可以使用 … 表示所有行,1: 表示从第二列开始的所有列。
c = a[1:3,[1,2]]
d = a[...,1:]
print(b)
print(c)
print(d)
#[[5 6]
# [8 9]]
#[[5 6]
# [8 9]]
#[[2 3]
# [5 6]
# [8 9]]
- 在了解了上述高级索引操作之后,我们可以尝试创建一个 8x8 的国际象棋棋盘矩阵,其中黑块代表是 0,白块代表是 1,具体棋盘如下所示。
- [0 1 0 1 0 1 0 1]
- [1 0 1 0 1 0 1 0]
- [0 1 0 1 0 1 0 1]
- [1 0 1 0 1 0 1 0]
- [0 1 0 1 0 1 0 1]
- [1 0 1 0 1 0 1 0]
- [0 1 0 1 0 1 0 1]
- [1 0 1 0 1 0 1 0]]
- 对于上述棋盘,我们可以先生成一个 8x8 的全 0 数组,然后将对应的元素设置为 1 即可。
- (1) 通过行索引从 1 开始,步长为 2,不设置终止值,将第 1,3,5,7 行元素全部设置为 1。
- (2) 通过列索引从 0 开始,步长为 2,不设置终止值,将第 1,3,5,7 行元素对应的列元素设置为 0。
- (3) 通过列索引从 1 开始,步长为 2,不设置终止值,将第 1,3,5,7 列元素全部设置为 1。
- (4) 通过行索引从 0 开始,步长为 2,不设置终止值,将第 1,3,5,7 行元素对应的行元素设置为 0。
- 具体实现代码如下所示。
Z = np.zeros((8, 8), dtype=int)
Z[1::2,::2] = 1
Z[::2,1::2] = 1
Z
#array([[0, 0, 0, 0, 0, 0, 0, 0],
# [1, 0, 1, 0, 1, 0, 1, 0],
# [0, 0, 0, 0, 0, 0, 0, 0],
# [1, 0, 1, 0, 1, 0, 1, 0],
# [0, 0, 0, 0, 0, 0, 0, 0],
# [1, 0, 1, 0, 1, 0, 1, 0],
# [0, 0, 0, 0, 0, 0, 0, 0],
# [1, 0, 1, 0, 1, 0, 1, 0]])
2. 布尔数组索引
- 当输出的结果需要经过布尔运算(如比较运算)时,此时会使用到另一种高级索引方式,即布尔数组索引。
- 下面示例返回数组中大于 6 的的所有元素:
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print(x.shape)
x[x>6]
#(4, 3)
#array([ 7, 8, 9, 10, 11])
- 布尔索引所实现的是通过一维数组中的每个元素的布尔型数值对一个与一维数组有着同样行数或列数的矩阵进行符合匹配。
- 这种作用,其实是把一维数组中布尔值为 True 的相应行或列给抽取了出来。
- 这里需要注意的是,一维数组的长度必须和想要切片的维度或轴的长度一致。
- 练习
- (1) 提取出数组中所有奇数。
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
x[x%2 == 1]
#array([ 1, 3, 5, 7, 9, 11])
- (2) 将奇数值修改为 -1。
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
x[x%2 == 1] = -1
x
#array([[ 0, -1, 2],
# [-1, 4, -1],
# [ 6, -1, 8],
# [-1, 10, -1]])
- 筛选出指定区间内数据
- & 表示和。
- | 表示或。
- 将数组 x 中大于 4 并且小于 9 的数据提取出来。
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
x[(x>4) & (x<9)]
#array([5, 6, 7, 8])
- 将数组 x 中小于4或者大于 9 的数据提取出来。
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
x[(x<4) | (x>9)]
#array([ 0, 1, 2, 3, 10, 11])
- True 和 False 的形式表示需要和不需要的数据
- 我们先创建 3*4 的数组,元素通过 np.arange(12) 自动生成,表示从起始值 0 到终止值(不包括终止值)12,步长是 1。
a3_4 = np.arange(12).reshape((3,4))
a3_4
#array([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])
- 将行变量和列变量分别用 True 和 False 表示,其中行变量和列变量按如下代码设置。
row1 = np.array([False,True,True])
column1 = np.array([True,False,True,False])
- a3_4 是 3 行, 做切片时也提供 3 个元素的数组,轴的长度一致。
- 通过 row1 和 column1 中的 True 和 False 就可以输出我们需要的元素,True 表示需要,False 表示不需要。
a3_4[row1]
#array([[ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])a3_4[:,column1]
#array([[ 0, 2],
# [ 4, 6],
# [ 8, 10]])
- 那么我们是否可以用两个一维布尔数组进行切片呢?我们继续进行试验得到如下结果:
a3_4[row1,column1]
#array([ 4, 10])
- 从结果上看,它实际上等价于下面的代码。
a3_4[[1, 2],[0, 2]]
- 输出的相当于是坐标序号为 (0,1),(2,2) 的数。
- 索引形状不匹配
- 从上面的结果可以知道,能够进行切片的前提是:两个一维布尔数组中 True 的个数需要相等,否则会出现下面的情况。
- 行变量当中存在 2 个 True 元素,列变量当中存在 3 个 True 元素。
row2 = np.array([False,True,True])
column2 = np.array([True,False,True,True])
- 其中,行变量和列变量当中的 True 元素个数不一致,会导致错误。
- a3_4[row2, column2] 就相当于 a3_4[[1,2],[0,2,3]]。
- 报错信息如下:indexError: shape mismatch: indexing arrays could not be broadcast together with shapes (2,) (3,)。
- 是因为所选索引形状不匹配:索引数组无法与该形状一起广播。
- 当访问 numpy 多维数组时,用于索引的数组需要具有相同的形状(行和列)。numpy 将有可能去广播,所以,若要为了实现不同维度的选择, 可分两步对数组进行选择。
- (1) 例如我需要选择第 1 行和最后一行的第 1,3,4 列时,先选择行,再选择列。
- (2) 先读取数组 a3_4 的第一行和最后一行,保存到 temp ,然后再筛选相应的列即可。
a3_4
#array([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])
- 那么,我们需要选择第 1 行和最后一行的第 1,3,4 列元素,操作步骤如下:
- (1) 先选行。
temp = a3_4[[0,-1],:]
temp
#array([[ 0, 1, 2, 3],
# [ 8, 9, 10, 11]])
- (2) 再选择列。
temp[:,[0,2,3]]
temp
#array([[ 0, 2, 3],
# [ 8, 10, 11]])
- (3) 合并一条。
a3_4[[0,-1],:][:,[0,2,3]]
- 但是,如果有一个一维数组长度是 1 时,这时又不会报错:
- 比如说,如果我们需要提取第二行,第 1,3 列的数据。
a3_4[[1],[0,2]]
#array([4, 6])
- 以上相当于 (1,0) 和 (1,2)。
- 数组索引及切片的值更改会修改原数组
- 一个标量赋值给一个索引/切片时,会自动改变/传播原始数组。
ar = np.arange(10)
print(ar)
ab = ar[:]
ar[5] = 100
print(ab)
#[0 1 2 3 4 5 6 7 8 9]
#[ 0 1 2 3 4 100 6 7 8 9]
- 可以使用复制操作。
ar = np.arange(10)
b = ar.copy()
- 或者可以使用 b = np.array(ar)。
b[7:9] = 200
print('ar:',ar)
print('b:',b)
三、广播机制
- 广播(Broadcast)是 numpy 对不同形状(shape)的数组进行数值计算的方式, 对数组的算术运算通常在相应的元素上进行。
- 如果两个数组 a 和 b 形状相同,即满足 a.shape == b.shape,那么 a*b 的结果就是 a 与 b 数组对应位相乘。这要求维数相同,且各维度的长度相同。
a = np.array([1,2,3,4])
b = np.array([10,20,30,40])
c = a * b
print (c)
#[ 10 40 90 160]
- 但如果两个形状不同的数组呢?它们之间就不能做算术运算了吗?
- 当然不是!为了保持数组形状相同,NumPy 设计了一种广播机制, 这种机制的核心是对形状较小的数组,在横向或纵向上进行一定次数的重复,使其与形状较大的数组拥有相同的维度。
a = np.array([[ 0, 0, 0],[10,10,10],[20,20,20],[30,30,30]])
b = np.array([1,2,3])
print(a + b)
- 下面的图片展示了数组 b 如何通过广播来与数组 a 兼容。
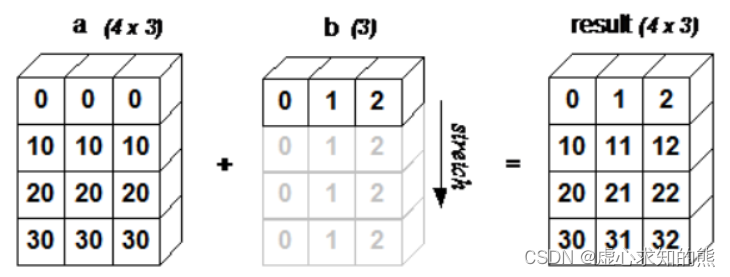
- 4x3 的二维数组与长为 3 的一维数组相加,等效于把数组 b 在二维上重复 4 次再运算。
1. 广播机制规则
- 广播具有如下规则:
- (1) 让所有输入数组都向其中形状最长的数组看齐,形状中不足的部分都通过在前面加 1 补齐。
- (2) 输出数组的形状是输入数组形状的各个维度上的最大值。
- (3) 如果输入数组的某个维度和输出数组的对应维度的长度相同或者其长度为 1 时,这个数组能够用来计算,否则出错。
- (4) 当输入数组的某个维度的长度为 1 时,沿着此维度运算时都用此维度上的第一组值。
- ** 为了更清楚的理解这些规则看,来看几个具体的示例**
- 我们通过 np.ones() 生成一个全 1 数组,np.arange() 生成一个有规律元素的数组。
- 两个数组的形状分别为 M.shape=(2,3),a.shape=(3,)。
- 可以看到,根据规则 1,数组 a 的维度更小,所以在其左边补 1,变为 M.shape -> (2,3), a.shape -> (1,3)。
- 根据规则 2,第一个维度不匹配,因此扩展这个维度以匹配数组:M.shape ->(2,3), a.shape -> (1,3)。
- 现在两个数组的形状匹配了,可以看到它们的最终形状都为(2,3)。
M = np.ones((2,3))
print(M)
a = np.arange(3)
print(a)
M + a
#[[1. 1. 1.]
# [1. 1. 1.]]
#[0 1 2]
#array([[1., 2., 3.],
# [1., 2., 3.]])
- 我们通过 np.arange() 生成两个有规律元素数组,其中一个设置为三行一列,便于对广播机制进行验证。
- 两个数组的形状设置为 a.shape=(3,1), b.shape=(3,)。
- 规则 1 告诉我们,需要用 1 将 b 的形状补全:a.shape -> (3,1), b.shape -> (1,3)。
- 规则 2 告诉我们,需要更新这两个数组的维度来相互匹配:a.shape -> (3,3), b.shape -> (3,3)
- 因为结果匹配,所以这两个形状是兼容的。
a = np.arange(3).reshape((3,1))
print('a:',a)
b = np.arange(3)
print('b:',b)
a + b
#a: [[0]
# [1]
# [2]]
#b: [0 1 2]
#array([[0, 1, 2],
# [1, 2, 3],
# [2, 3, 4]])
2. 对于广播规则另一种简单理解
- (1) 将两个数组的维度大小右对齐,然后比较对应维度上的数值。
- (2) 如果数值相等或其中有一个为1或者为空,则能进行广播运算。
- (3) 输出的维度大小为取数值大的数值。否则不能进行数组运算。
- 数组 a 大小为(2, 3),数组 b 大小为 (1,),对其进行右对齐操作。
2 31
----------2 3
- 所以最后两个数组运算的输出大小为:(2, 3),下面对其进行代码验证。
a = np.arange(6).reshape(2, 3)
print('a:', a)
b = np.array([5])
print('b:',b)
c = a * b
c
#a: [[0 1 2]
# [3 4 5]]
#b: [5]
#array([[ 0, 5, 10],
# [15, 20, 25]])
- 数组 a 大小为 (2, 1, 3),数组 b 大小为 (4, 1),对其进行右对齐操作。
2 1 34 1
----------2 4 3
- 所以最后两个数组运算的输出大小为:(2, 4, 3)。
a= np.arange(6).reshape(2, 1, 3)
print('a:',a)
print('-'*10)
b = np.arange(4).reshape(4, 1)
print('b:',b)
print('-'*10)
c = a + b
print(c,c.shape)
#a: [[[0 1 2]]
#
# [[3 4 5]]]
#----------
#b: [[0]
# [1]
# [2]
# [3]]
#----------
#[[[0 1 2]
# [1 2 3]
# [2 3 4]
# [3 4 5]]
#
# [[3 4 5]
# [4 5 6]
# [5 6 7]
# [6 7 8]]] (2, 4, 3)
- 从这里能够看出:
- (1) 两个数组右对齐以后,对应维度里的数值要么相等,要么有一个为 1,要么缺失取大值。
- (2) 除此之外就会报错。像下面的两个数组就不能做运算。
- 数组 a 大小为 (2, 1, 3),数组 b 大小为 (4, 2),对其进行右对齐操作。
2 1 34 2
----------
- 2 跟 3 不匹配,此时就不能做运算。
a = np.arange(6).reshape(2, 1, 3)
print('a:',a)
print('-'*10)
b = np.arange(8).reshape(4, 2)
print('b:',b)
print('-'*10)
a + b
#a: [[[0 1 2]]
#
# [[3 4 5]]]
#----------
#b: [[0 1]
# [2 3]
# [4 5]
# [6 7]]
#----------
#---------------------------------------------------------------------------
#ValueError Traceback (most recent call last)
#<ipython-input-68-2ebfaa0877fb> in <module>
# 9 print('-'*10)
# 10 # 运行报错
#---> 11 a + b
#
#ValueError: operands could not be broadcast together with shapes (2,1,3) (4,2)
- 广播机制能够处理不同大小的数组,数组之间必须满足广播的规则,否则就会报错。
- 事实上,相同大小的数组运算也遵循广播机制。
相关文章:
Python 之 NumPy 切片索引和广播机制
文章目录一、切片和索引1. 一维数组2. 二维数组二、索引的高级操作1. 整数数组索引2. 布尔数组索引三、广播机制1. 广播机制规则2. 对于广播规则另一种简单理解一、切片和索引 ndarray 对象的内容可以通过索引或切片来访问和修改(),与 Pytho…...
Redis【包括Redis 的安装+本地远程连接】
Redis 一、为什么要用缓存? 缓存定义 缓存是一个高速数据交换的存储器,使用它可以快速的访问和操作数据。 程序中的缓存 在我们程序中,如果没有使用缓存,程序的调用流程是直接访问数据库的; 如果多个程序调用一个数…...
深度学习训练营_第P3周_天气识别
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍦 参考文章:Pytorch实战 | 第P3周:彩色图片识别:天气识别**🍖 原作者:K同学啊|接辅导、项目定制**␀ 本次实验有两个新增任务&…...
)
“华为杯”研究生数学建模竞赛2006年-【华为杯】C题:维修线性流量阀时的内筒设计问题(附获奖论文及matlab代码)
赛题描述 油田采油用的油井都是先用钻机钻几千米深的孔后,再利用固井机向四周的孔壁喷射水泥砂浆得到水泥井管后形成的。固井机上用来控制砂浆流量的阀是影响水泥井管质量的关键部件,但也会因磨损而损坏。目前我国还不能生产完整的阀体,固井机仍依赖进口。由于损坏的内筒已…...

数据结构:带环单链表基础OJ练习笔记(leetcode142. 环形链表 II)(leetcode三题大串烧)
目录 一.前言 二.leetcode160. 相交链表 1.问题描述 2.问题分析与求解 三.leetcode141. 环形链表 1.问题描述 2.代码思路 3.证明分析 下一题会用到的重要小结论: 四.leetcode142. 环形链表 II 1.问题描述 2.问题分析与求解 Judgecycle接口…...

数模美赛如何找数据 | 2023年美赛数学建模必备数据库
2023美赛资料分享/思路答疑群:322297051 欧美相关统计数据(一般美赛这里比较多) 1、http://www.census.gov/ 美国统计局(统计调查局或普查局)官方网站 The Census Bureau Web Site provides on-line access to our …...

SSTI漏洞原理及渗透测试
模板引擎(Web开发中) 是为了使 用户界面 和 业务数据(内容)分离而产生的,它可以生成特定格式的文档, 利用模板引擎来生成前端的HTML代码,模板引擎会提供一套生成HTML代码的程序,之后…...
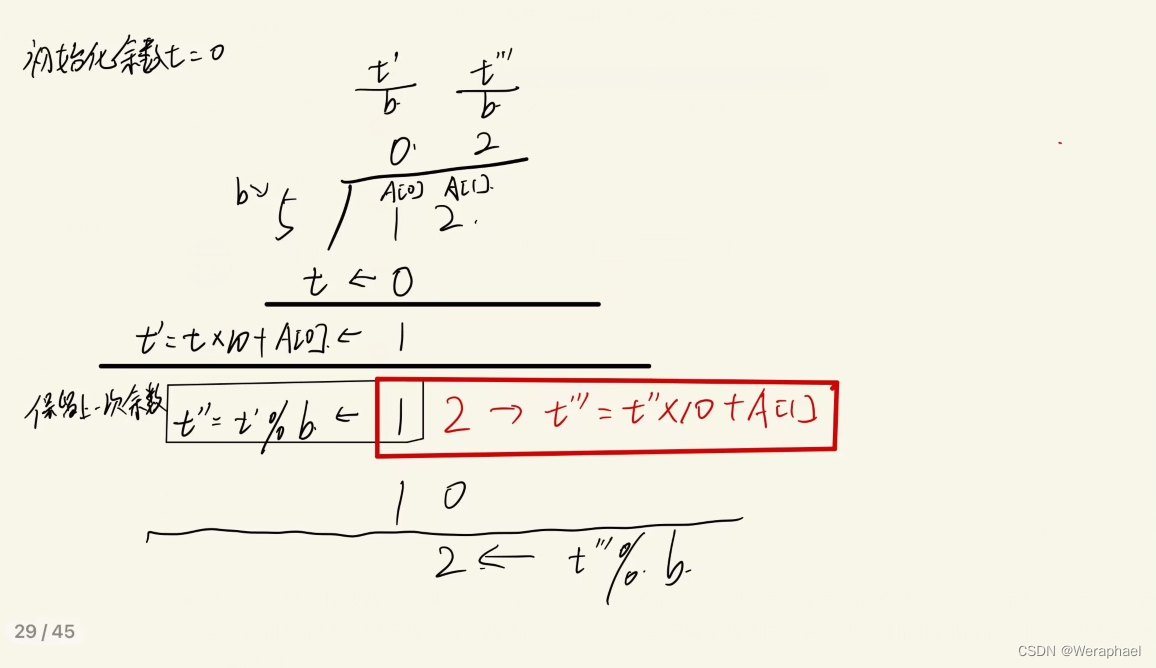
【算法基础】高精度除法
👦个人主页:Weraphael ✍🏻作者简介:目前是C语言 算法学习者 ✈️专栏:【C/C】算法 🐋 希望大家多多支持,咱一起进步!😁 如果文章对你有帮助的话 欢迎 评论💬…...
, loss.backward(), optimizer.step()的理解及使用)
optimizer.zero_grad(), loss.backward(), optimizer.step()的理解及使用
optimizer.zero_grad,loss.backward,optimizer.step用法介绍optimizer.zero_grad():loss.backward():optimizer.step():用法介绍 这三个函数的作用是将梯度归零(optimizer.zero_grad())&#x…...

融资、量产和一栈式布局,这家Tier 1如此备战高阶智驾决赛圈
作者 | Bruce 编辑 | 于婷从早期的ADAS,到高速/城市NOA,智能驾驶的竞争正逐渐升级,这对于车企和供应商的核心技术和产品布局都是一个重要的考验。 部分智驾供应商已经在囤积粮草,响应变化。 2023刚一开年,智能驾驶领域…...
centos7.8安装oralce11g
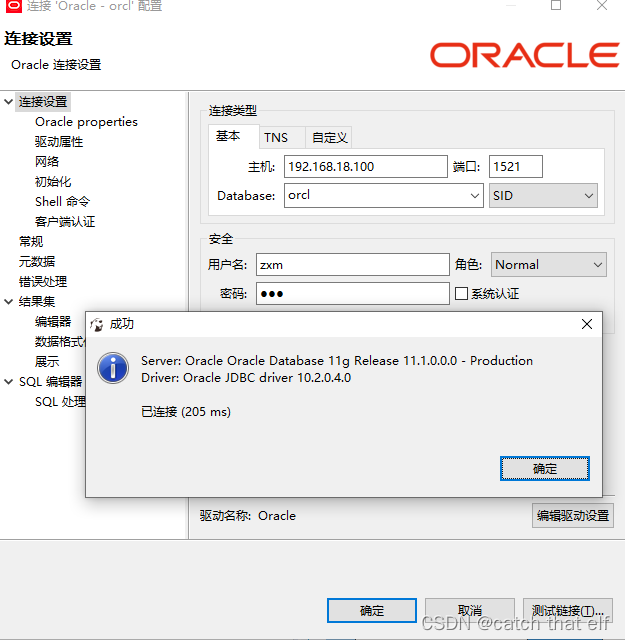
文章目录环境安装文件准备添加用户操作系统环境配置解压安装问题解决创建用户远程连接为了熟悉rman备份操作,参照大神的博客在centos中安装了一套oracle11g,将安装步骤记录如下环境安装文件准备 这里准备一台centos7.8 虚拟机 配置ip 192.168.18.100 主…...

【蓝桥杯集训·每日一题】AcWing 3956. 截断数组
文章目录一、题目1、原题链接2、题目描述二、解题报告1、思路分析2、时间复杂度3、代码详解三、知识风暴一维前缀和一、题目 1、原题链接 3956. 截断数组 2、题目描述 给定一个长度为 n 的数组 a1,a2,…,an。 现在,要将该数组从中间截断,得到三个非空子…...
万丈高楼平地起:Linux常用命令
目录 系统管理命令 man命令 ls命令 cd命令 useradd命令 passwd命令 free命令 whoami命令 ps命令 date命令 pwd命令 shutdown命令 文件目录管理命令 touch命令 cat命令 mkdir命令 rm命令 cp命令 mv命令 find命令 more指令 less指令 head指令 tail指令 …...
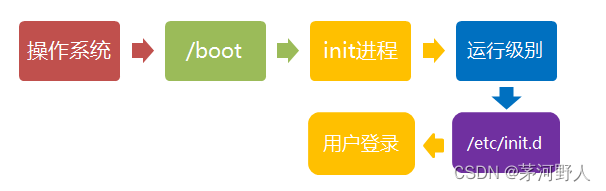
Linux(Linux的连接使用)
连接Linux我们一般使用CRT或者Xshell工具进行连接使用。 如CRT使用SSH的方式 输出主机,账户,密码那些就可以连接上了。 Linux系统是一个文件型操作系统,有一句话说Linux的一切皆是文件。Linux系统的启动大致有下面几个步骤 Linux系统有7个运…...
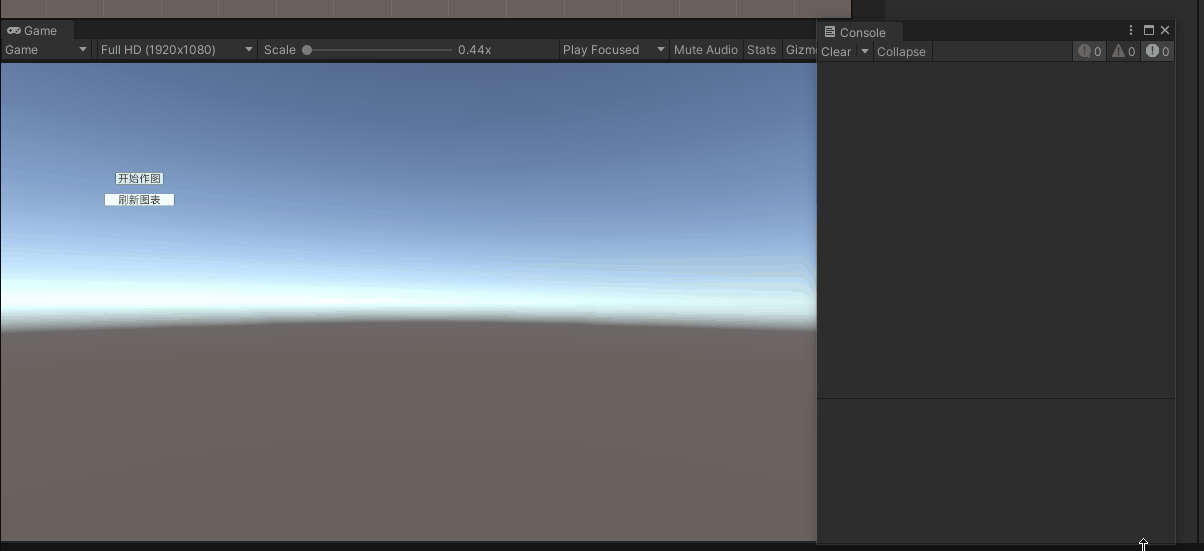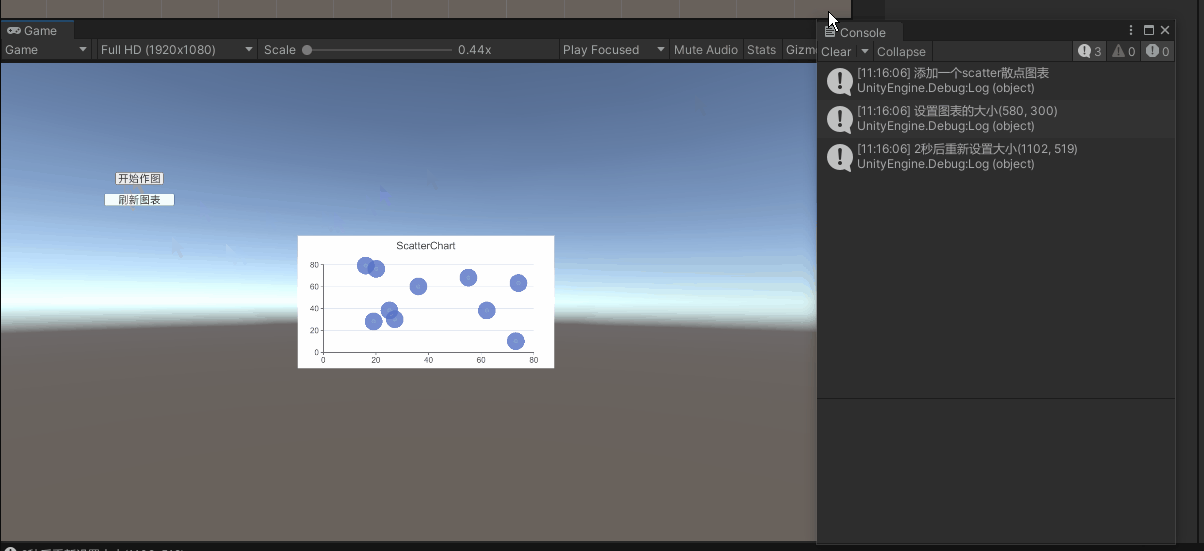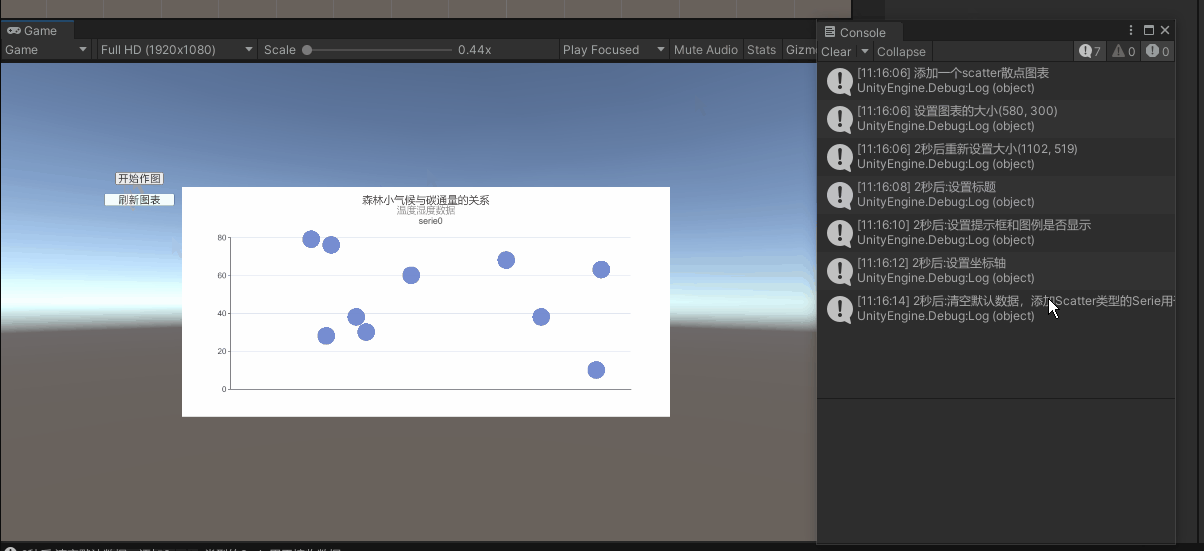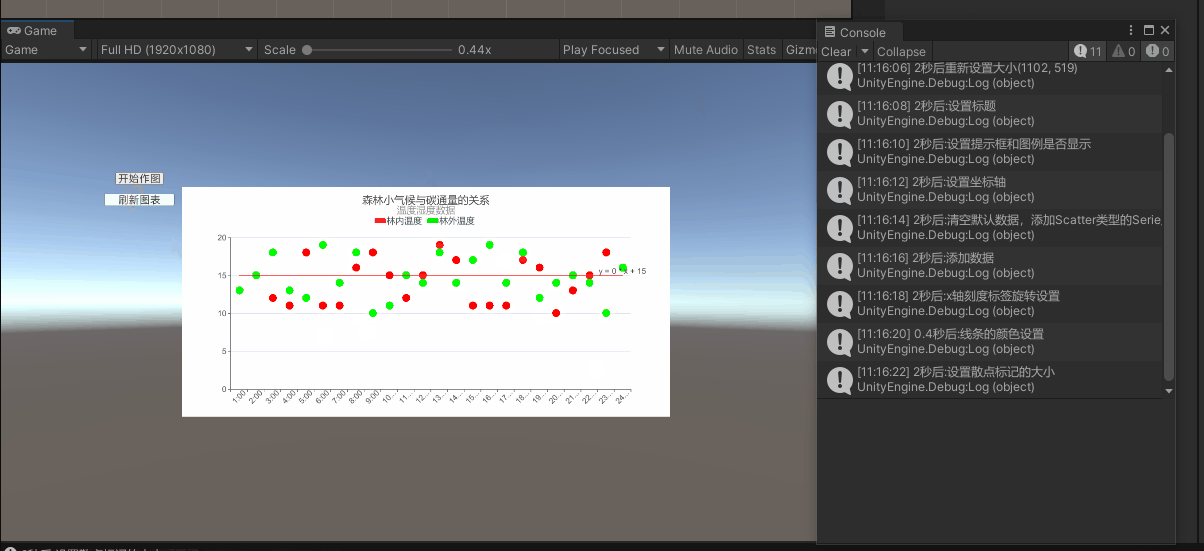
Unity中画2D图表(2)——用XChart包绘制散点分布图 + 一条直线方程
散点图用于显示关系。 对于 【相关性】 ,散点图有助于显示两个变量之间线性关系的强度。 对于 【回归】 ,散点图常常会添加拟合线。 举例1:你可以展示【年降雨量】与【玉米亩产量】的关系 举例2:你也可以分析各个【节假日】与【大…...

Go 排序包 sort
写在前面的使用总结: 排序结构体 实现Len,Less,Swap三个函数 package main import ( "fmt" "sort") type StuScore struct { name string score int } type StuScores []StuScore func (s StuScores) Len(…...
Java Email 发HTML邮件工具 采用 freemarker模板引擎渲染
Java Email 发HTML邮件工具 采用 freemarker模板引擎 1.常用方式对比 Java发送邮件有很多的实现方式 第一种:Java 原生发邮件mail.jar和activation.jar <!-- https://mvnrepository.com/artifact/javax.mail/mail --> <dependency><groupId>jav…...
Calico 介绍与原理(二))
CNI 网络流量分析(六)Calico 介绍与原理(二)
文章目录CNI 网络流量分析(六)Calico 介绍与原理(二)CNIIPAM指定 IP指定非 IPAM IPCNI 网络流量分析(六)Calico 介绍与原理(二) CNI 支持多种 datapath,默认是 linuxDa…...

短视频标题的几种类型和闭坑注意事项
目录 短视频标题的几种类型 1、悬念式 2、蹭热门式 3、干货式 4、对比式方法 5、总分/分总式方法 6、挑战式方式 7、启发激励式 8、讲故事式 02注意事项 1、避免使用冷门、生僻词汇 标题是点睛之笔,核心是视频内容 短视频标题的几种类型 1、悬念式 通过…...
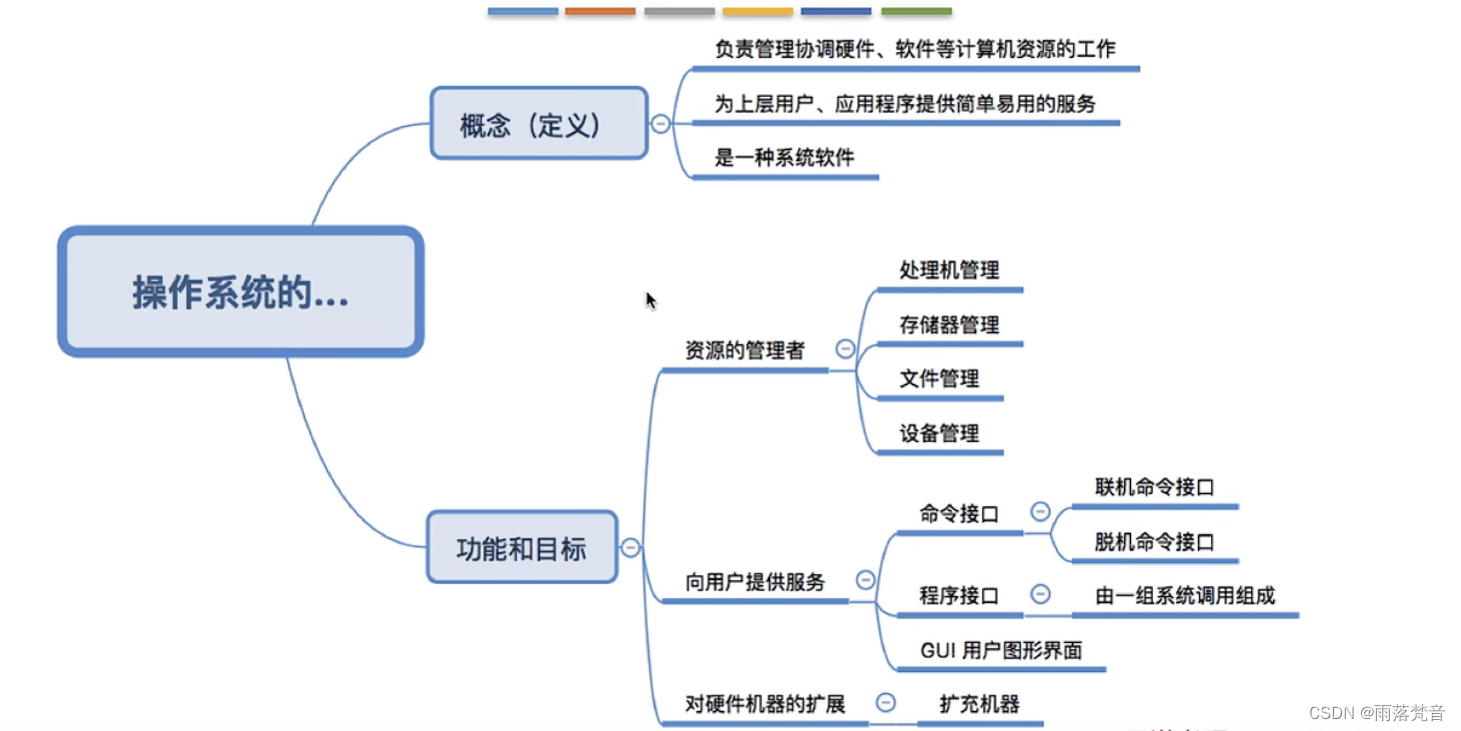
操作系统——1.操作系统的概念、定义和目标
目录 1.概念 1.1 操作系统的种类 1.2电脑的组成 1.3电脑组成的介绍 1.4操作系统的概念(定义) 2.操作系统的功能和目标 2.1概述 2.2 操作系统作为系统资源的管理者 2.3 操作系统作为用户和计算机硬件间的接口 2.3.1用户接口的解释 2.3.2 GUI 2.3.3接…...

CQDs-PEG/Biotin/@SiO2/Polymer,PEG修饰碳量子点的特性
中英文名称: CQDs-PEG,PEG修饰碳量子点 CQDs-Biotin,生物素偶联碳量子点 CQDsSiO2,二氧化硅包覆碳量子点 CQDsPolymer,聚合物包覆碳量子点 碳量子点(Carbon Quantum Dots, CQDs)作为一类新型零维…...

何为可编程控制器?可编程控制器4大内容介绍
可编程控制器在控制中常为使用,因此本文将从4大方面对可编程控制器予以介绍,以增进大家对可编程控制器的了解。这4大方面包括:1.何为可编程控制器?2. 可编程控制器的基本组成,3. 可编程控制器发展史,以及4. 可编程控制…...

开源工具any2card:任意格式内容智能转换结构化卡片实战指南
1. 项目概述:从“任意格式”到“卡片”的智能转换革命最近在折腾个人知识库和内容管理时,我遇到了一个老生常谈但又无比棘手的问题:信息格式的碎片化。我的资料散落在各处,有PDF论文、网页文章、TXT笔记、甚至是一些图片里的文字。…...

ColorControl:让Windows显示控制变得简单直观的跨设备管理工具
ColorControl:让Windows显示控制变得简单直观的跨设备管理工具 【免费下载链接】ColorControl Easily change NVIDIA display settings and/or control LG TVs 项目地址: https://gitcode.com/gh_mirrors/co/ColorControl 当您在Windows系统中切换显示模式时…...
)
从仿真到实践:三相SPWM并网逆变器的电流环PI参数整定心得(附PSIM波形分析)
从仿真到实践:三相SPWM并网逆变器的电流环PI参数整定实战解析 当你在PSIM中完成开环逆变器仿真后,看着屏幕上完美的SPWM波形,可能会产生一种错觉——并网控制的核心难题已经解决。直到你第一次尝试加入电流环控制,才发现真正的挑战…...

3分钟掌握清华PPT模板:免费打造专业学术演示文稿的终极方案
3分钟掌握清华PPT模板:免费打造专业学术演示文稿的终极方案 【免费下载链接】THU-PPT-Theme 清华主题PPT模板 项目地址: https://gitcode.com/gh_mirrors/th/THU-PPT-Theme 还在为学术汇报、毕业答辩或重要演讲的PPT设计而头疼吗?清华大学视觉设计…...

你的串口通信稳定吗?STM32CubeMX配置USART1的避坑指南与稳定性测试
STM32串口通信稳定性实战:从配置陷阱到压力测试全解析 当你的嵌入式设备在实验室运行良好,却在现场频繁出现数据丢失或乱码时,问题往往出在那些容易被忽视的细节上。串口通信作为嵌入式系统中最基础的调试与数据交互接口,其稳定性…...

如何用Layerdivider快速实现智能图像分层:面向设计师和开发者的完整指南
如何用Layerdivider快速实现智能图像分层:面向设计师和开发者的完整指南 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider Layerdivider是一款强…...

终极免费风扇控制软件:FanControl完整配置与优化指南
终极免费风扇控制软件:FanControl完整配置与优化指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/…...
)
别再让UDP丢包坑了你!手把手教你用C语言实现应用层分包组包(附完整代码)
从零构建高可靠UDP传输:C语言实现应用层分包组包实战指南 在实时音视频、在线游戏等对延迟极度敏感的领域,UDP协议因其无连接、低开销的特性成为首选。但许多开发者第一次使用UDP发送大文件时都会遇到这样的场景:明明局域网测试一切正常&…...