DDPG算法详解
DQN算法详解
一.概述
概括来说,RL要解决的问题是:让agent学习在一个环境中的如何行为动作(act), 从而获得最大的奖励值总和(total reward)。
这个奖励值一般与agent定义的任务目标关联。
agent需要的主要学习内容:第一是行为策略(action policy), 第二是规划(planning)。
其中,行为策略的学习目标是最优策略, 也就是使用这样的策略,可以让agent在特定环境中的行为获得最大的奖励值,从而实现其任务目标。
行为(action)可以简单分为:
- 连续的:如赛 车游戏中的方向盘角度、油门、刹车控制信号,机器人的关节伺服电机控制信号。
- 离散的:如围棋、贪吃蛇游戏。 Alpha Go就是一个典型的离散行为agent。
DDPG是针对连续行为的策略学习方法。
二.DDPG的定义和应用场景
在RL领域,DDPG主要从:PG -> DPG -> DDPG 发展而来。
基本概念:
PG
R.Sutton 在2000年提出的Policy Gradient 方法,是RL中,学习连续的行为控制策略的经典方法,其提出的解决方案是:
通过一个概率分布函数 , 来表示每一步的最优策略, 在每一步根据该概率分布进行action采样,获得当前的最佳action取值;即:
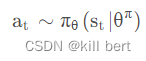
生成action的过程,本质上是一个随机过程;最后学习到的策略,也是一个随机策略(stochastic policy).
DPG
Deepmind的D.Silver等在2014年提出DPG: Deterministic Policy Gradient, 即确定性的行为策略,每一步的行为通过函数μ 直接获得确定的值:
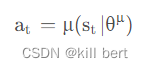
这个函数μ即最优行为策略,不再是一个需要采样的随机策略。
为何需要确定性的策略?简单来说,PG方法有以下缺陷:
- 即使通过PG学习得到了随机策略之后,在每一步行为时,我们还需要对得到的最优策略概率分布进行采样,才能获得action的具体值;而action通常是高维的向量,比如25维、50维,在高维的action空间的频繁采样,无疑是很耗费计算能力的;
- 在PG的学习过程中,每一步计算policy gradient都需要在整个action space进行积分:
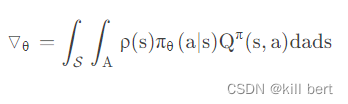
DDPG
Deepmind在2016年提出DDPG,全称是:Deep Deterministic Policy Gradient,是将深度学习神经网络融合进DPG的策略学习方法。
相对于DPG的核心改进是: 采用卷积神经网络作为策略函数μ 和Q 函数的模拟,即策略网络和Q网络;然后使用深度学习的方法来训练上述神经网络。
Q函数的实现和训练方法,采用了Deepmind 2015年发表的DQN方法 ,即 Alpha Go使用的Q函数方法。
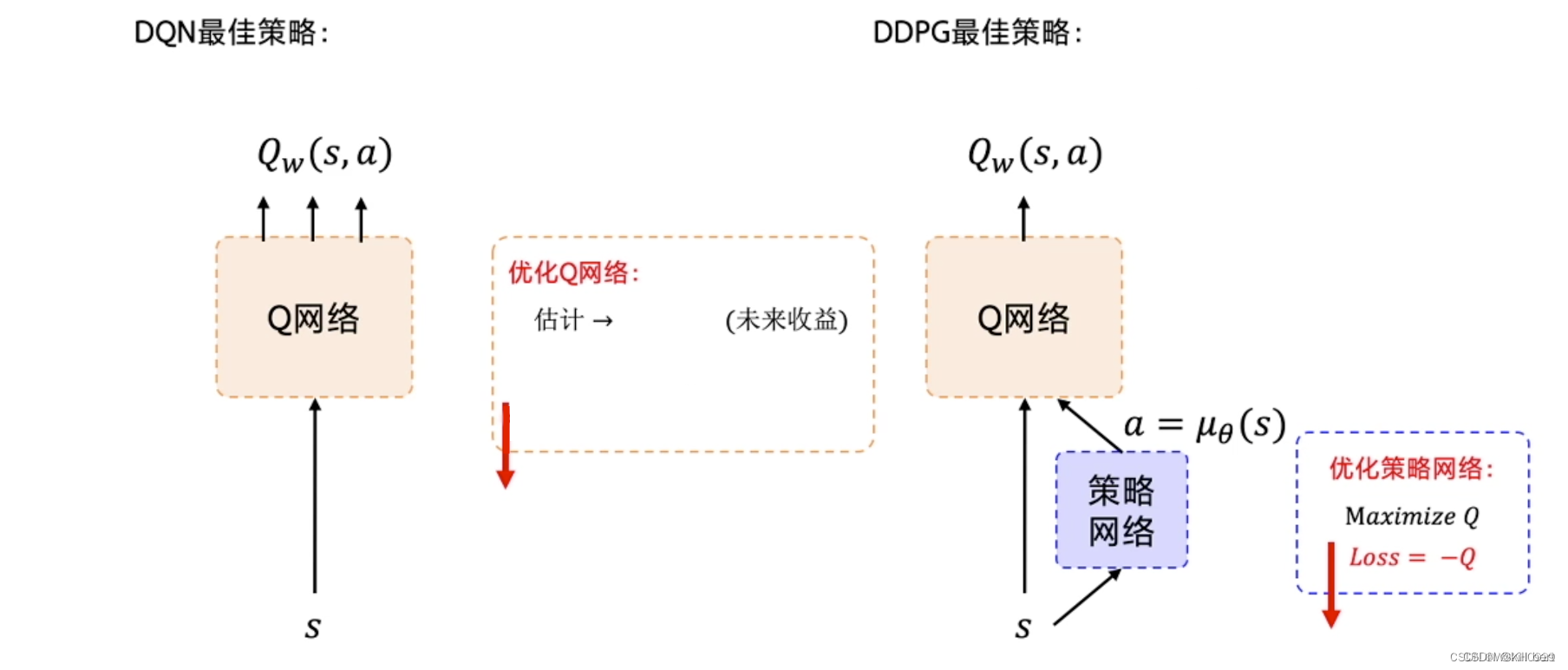
1.DDQN解决问题方法
- 使用卷积神经网络来模拟策略函数和Q函数,并用深度学习的方法来训练,证明了在RL方法中,非线性模拟函数的准确性和高性能、可收敛;
而DPG中,可以看成使用线性回归的机器学习方法:使用带参数的线性函数来模拟策略函数和Q函数,然后使用线性回归的方法进行训练。 - experience replay memory的使用:actor同环境交互时,产生的transition数据序列是在时间上高度关联(correlated)的,如果这些数据序列直接用于训练,会导致神经网络的overfit,不易收敛。
DDPG的actor将transition数据先存入experience replay buffer, 然后在训练时,从experience replay buffer中随机采样mini-batch数据,这样采样得到的数据可以认为是无关联的。 - target 网络和online 网络的使用, 使的学习过程更加稳定,收敛更有保障。

四、 代码详解
import gym
import paddle
import paddle.nn as nn
from itertools import count
from paddle.distribution import Normal
import numpy as np
from collections import deque
import random
import paddle.nn.functional as F
# 定义评论家网络结构
# DDPG这种方法与Q学习紧密相关,可以看作是连续动作空间的深度Q学习。
class Critic(nn.Layer):def __init__(self):super(Critic, self).__init__()self.fc1 = nn.Linear(3, 256)self.fc2 = nn.Linear(256 + 1, 128)self.fc3 = nn.Linear(128, 1)self.relu = nn.ReLU()def forward(self, x, a):x = self.relu(self.fc1(x))x = paddle.concat((x, a), axis=1)x = self.relu(self.fc2(x))x = self.fc3(x)return x# 定义演员网络结构
# 为了使DDPG策略更好地进行探索,在训练时对其行为增加了干扰。 原始DDPG论文的作者建议使用时间相关的 OU噪声 ,
# 但最近的结果表明,不相关的均值零高斯噪声效果很好。 由于后者更简单,因此是首选。
class Actor(nn.Layer):def __init__(self, is_train=True):super(Actor, self).__init__()self.fc1 = nn.Linear(3, 256)self.fc2 = nn.Linear(256, 128)self.fc3 = nn.Linear(128, 1)self.relu = nn.ReLU()self.tanh = nn.Tanh()self.noisy = Normal(0, 0.2)self.is_train = is_traindef forward(self, x):x = self.relu(self.fc1(x))x = self.relu(self.fc2(x))x = self.tanh(self.fc3(x))return xdef select_action(self, epsilon, state):state = paddle.to_tensor(state,dtype="float32").unsqueeze(0)with paddle.no_grad():action = self.forward(state).squeeze() + self.is_train * epsilon * self.noisy.sample([1]).squeeze(0)return 2 * paddle.clip(action, -1, 1).numpy()# 重播缓冲区:这是智能体以前的经验, 为了使算法具有稳定的行为,重播缓冲区应该足够大以包含广泛的体验。
# 如果仅使用最新数据,则可能会过分拟合,如果使用过多的经验,则可能会减慢模型的学习速度。 这可能需要一些调整才能正确。
class Memory(object):def __init__(self, memory_size: int) -> None:self.memory_size = memory_sizeself.buffer = deque(maxlen=self.memory_size)def add(self, experience) -> None:self.buffer.append(experience)def size(self):return len(self.buffer)def sample(self, batch_size: int, continuous: bool = True):if batch_size > len(self.buffer):batch_size = len(self.buffer)if continuous:rand = random.randint(0, len(self.buffer) - batch_size)return [self.buffer[i] for i in range(rand, rand + batch_size)]else:indexes = np.random.choice(np.arange(len(self.buffer)), size=batch_size, replace=False)return [self.buffer[i] for i in indexes]def clear(self):self.buffer.clear()# 定义软更新的函数
def soft_update(target, source, tau):for target_param, param in zip(target.parameters(), source.parameters()):target_param.set_value(target_param * (1.0 - tau) + param * tau)# 定义环境、实例化模型env = gym.make('Pendulum-v1')
actor = Actor()
critic = Critic()
actor_target = Actor()
critic_target = Critic()# 定义优化器
critic_optim = paddle.optimizer.Adam(parameters=critic.parameters(), learning_rate=3e-5)
actor_optim = paddle.optimizer.Adam(parameters=actor.parameters(), learning_rate=1e-5)# 定义超参数
explore = 50000
epsilon = 1
gamma = 0.99
tau = 0.001memory_replay = Memory(50000)
begin_train = False
batch_size = 32learn_steps = 0#writer = LogWriter('logs')# 训练循环
for epoch in count():state = env.reset()episode_reward = 0for time_step in range(200):action = actor.select_action(epsilon, state)next_state, reward, done, _ = env.step([action])episode_reward += rewardreward = (reward + 8.1) / 8.1memory_replay.add((state, next_state, action, reward))if memory_replay.size() > 1280:learn_steps += 1if not begin_train:print('train begin!')begin_train = Trueexperiences = memory_replay.sample(batch_size, False)batch_state, batch_next_state, batch_action, batch_reward = zip(*experiences)batch_state = paddle.to_tensor(batch_state, dtype="float32")batch_next_state = paddle.to_tensor(batch_next_state, dtype="float32")batch_action = paddle.to_tensor(batch_action, dtype="float32").unsqueeze(1)batch_reward = paddle.to_tensor(batch_reward, dtype="float32").unsqueeze(1)# 均方误差 y - Q(s, a) , y是目标网络所看到的预期收益, 而 Q(s, a)是Critic网络预测的操作值。# y是一个移动的目标,评论者模型试图实现的目标;这个目标通过缓慢的更新目标模型来保持稳定。with paddle.no_grad():Q_next = critic_target(batch_next_state, actor_target(batch_next_state))Q_target = batch_reward + gamma * Q_nextcritic_loss = F.mse_loss(critic(batch_state, batch_action), Q_target)critic_optim.clear_grad()critic_loss.backward()critic_optim.step()#writer.add_scalar('critic loss', critic_loss.numpy(), learn_steps)# 使用Critic网络给定值的平均值来评价Actor网络采取的行动。 我们力求使这一数值最大化。# 因此,我们更新了Actor网络,对于一个给定状态,它产生的动作尽量让Critic网络给出高的评分。critic.eval()actor_loss = - critic(batch_state, actor(batch_state))# print(actor_loss.shape)actor_loss = actor_loss.mean()actor_optim.clear_grad()actor_loss.backward()actor_optim.step()critic.train()#writer.add_scalar('actor loss', actor_loss.numpy(), learn_steps)soft_update(actor_target, actor, tau)soft_update(critic_target, critic, tau)env.render()if epsilon > 0:epsilon -= 1 / explorestate = next_state#writer.add_scalar('episode reward', episode_reward, epoch)if epoch % 10 == 0:print('Epoch:{}, episode reward is {}'.format(epoch, episode_reward))if epoch % 200 == 0:paddle.save(actor.state_dict(), 'model/ddpg-actor' + str(epoch) + '.para')paddle.save(critic.state_dict(), 'model/ddpg-critic' + str(epoch) + '.para')print('model saved!')
相关文章:
DDPG算法详解
DQN算法详解 一.概述 概括来说,RL要解决的问题是:让agent学习在一个环境中的如何行为动作(act), 从而获得最大的奖励值总和(total reward)。 这个奖励值一般与agent定义的任务目标关联。 agent需要的主要学习内容:第一是行为策略…...

继续学c++
由于c里面有很多和c语言很像的东西,这里就来总结一点不像的或者要注意的,或者是我已经快忘记的; 先来一个浮点型也就是实型类型的总结; 知道浮点型有这两个类型:float和double型; 然后float型占四个字节…...
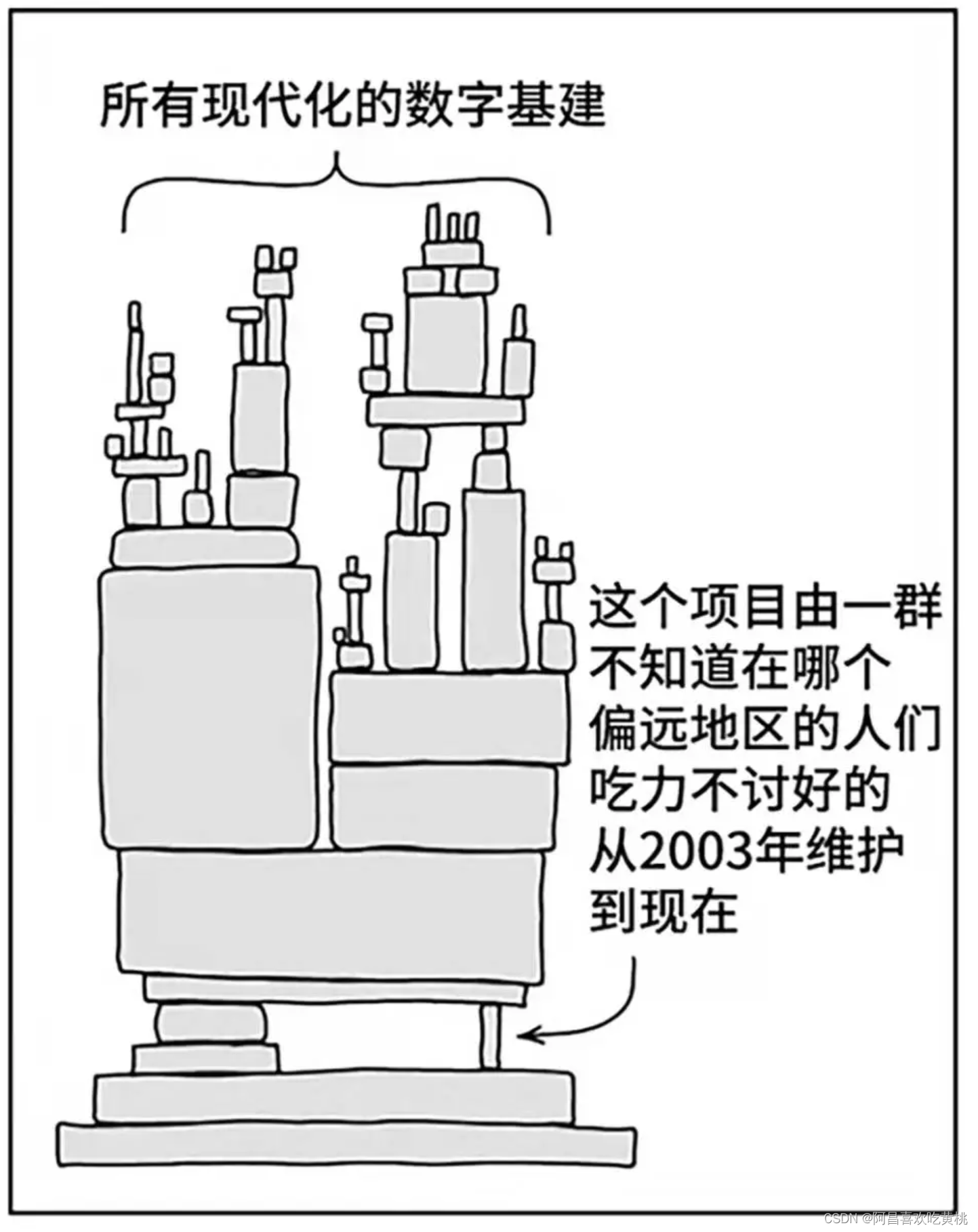
Day949.遗留系统之殇:为什么要对遗留系统进行现代化? -遗留系统现代化实战
遗留系统之殇:为什么要对遗留系统进行现代化? Hi,我是阿昌,今天学习记录是关于遗留系统之殇:为什么要对遗留系统进行现代化?的内容。 不知道你是否跟曾经一样,身处一个遗留系统的漩涡之中&…...

DAY 45 Nginx服务配置
Nginx概述 Nginx: Nginx 是开源、高性能、高可靠的 Web 和反向代理服务器,而且支持热部署,几乎可以做到 7 * 24 小时不间断运行,即使运行几个月也不需要重新启动,还能在不间断服务的情况下对软件版本进行热更新。 对…...

如何收集K8S容器化部署的服务的日志?
做开发的同学都知道日志的重要性,日志的种类一般有接口日志、错误日志、关键步骤日志、用户操作日志等。本文主要详细讲解使用kubernetes容器化部署的服务该如何记录和收集日志。 一、使用标准输出方式 将想要记录的日志内容输出到stdout或stderr即可(…...

python删除csv文件中的某几列或行
1. 读取数据 用pandas中的read_csv()函数读取出csv文件中的数据: import pandas as pddf pd.read_csv("comments.csv") df.head(2)用drop函数进行文件中数据的删除行或者删除列操作。 2. 删除列操作 方法一:假设我们要删除的列的名称为 ‘观众ID’,‘…...
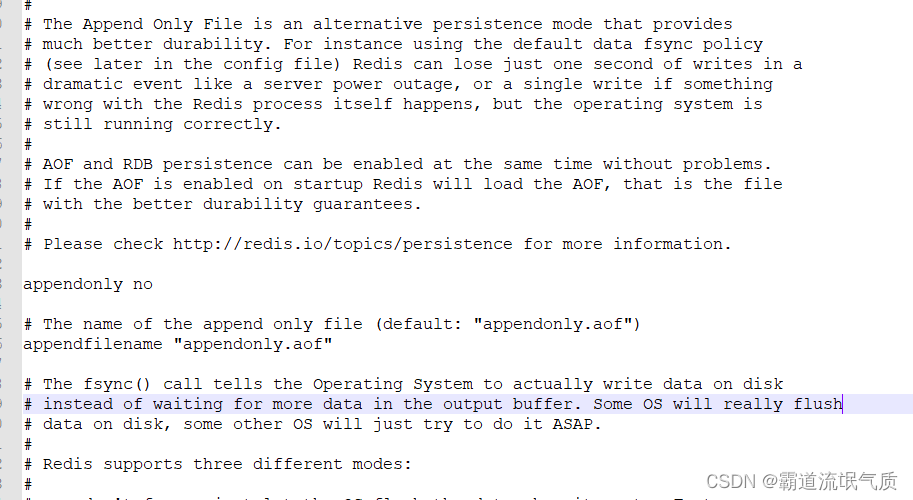
Redis持久化机制导致服务自启动后恢复数据过长无法使用以及如何关闭
场景 若依前后端分离版手把手教你本地搭建环境并运行项目: 若依前后端分离版手把手教你本地搭建环境并运行项目_霸道流氓气质的博客-CSDN博客 在上面搭建前后端分离的项目后,如果需要在windows服务上进行部署。 若依前后端分离版本,Windo…...
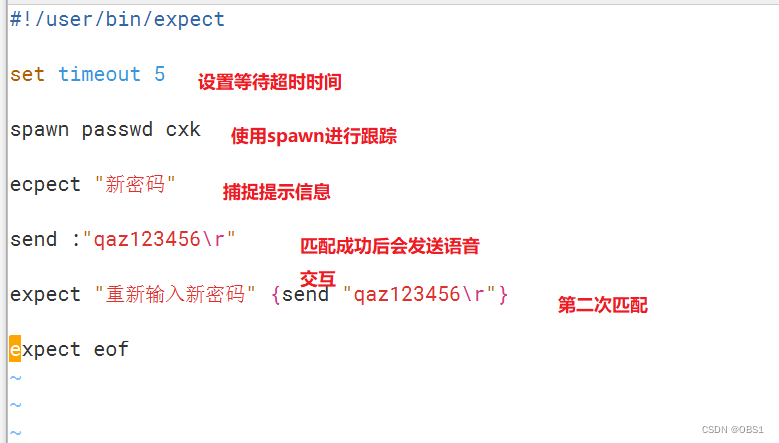
DAY 37 shell免交互
Here Document 概述 常用的交互程序:read,ftp,passwd,su,sudo cat也可配合免交互的方式重定向输出到文件 Here Document 的作用 使用I/O重定向的方式将命令列表提供给交互式程序标准输入的一种替代品 格式 命令 …...
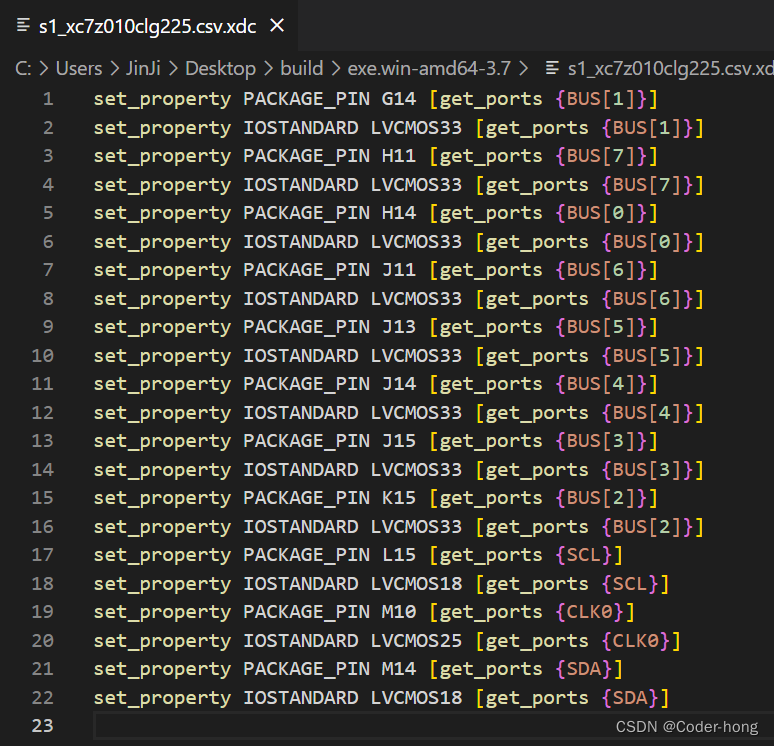
用python脚本从Cadence导出xdc约束文件
用python脚本从Cadence导出xdc约束文件 概述转换方法先导出csv文件修改CSV文件 CSV转XDC检查输出XDC文件csv2xdc源代码下载 概述 在Cadence设计完成带有FPGA芯片的原理图的时候,往往需要将FPGA管脚和网络对应关系导入vivado设计软件中,对于大规模FPGA管…...

【C++ 六】内存分区、引用
内存分区、引用 文章目录 内存分区、引用前言1 内存分区模型1.1 程序运行前1.2 程序运行后1.3 new 操作符 2 引用2.1 引用基本使用2.2 引用注意事项2.3 引用做函数参数2.4 引用做函数返回值2.5 引用本质2.6 常量引用 总结 前言 本文包含内存分区、引用基本使用、引用注意事项、…...

markdown基本语法
来自神秘人儿的投稿! markdown的使用,可以参考https://markdown.com.cn/basic-syntax/ 标题:用 # 表示 段落:enter即可,两端之间有一个空行 换行:一行的末尾加两个或者多个空格,两端之间没有…...

第十篇 Spring 集成Redis
《Spring》篇章整体栏目 ————————————————————————————— 【第一章】spring 概念与体系结构 【第二章】spring IoC 的工作原理 【第三章】spring IOC与Bean环境搭建与应用 【第四章】spring bean定义 【第五章】Spring 集合注入、作用域 【第六章】…...
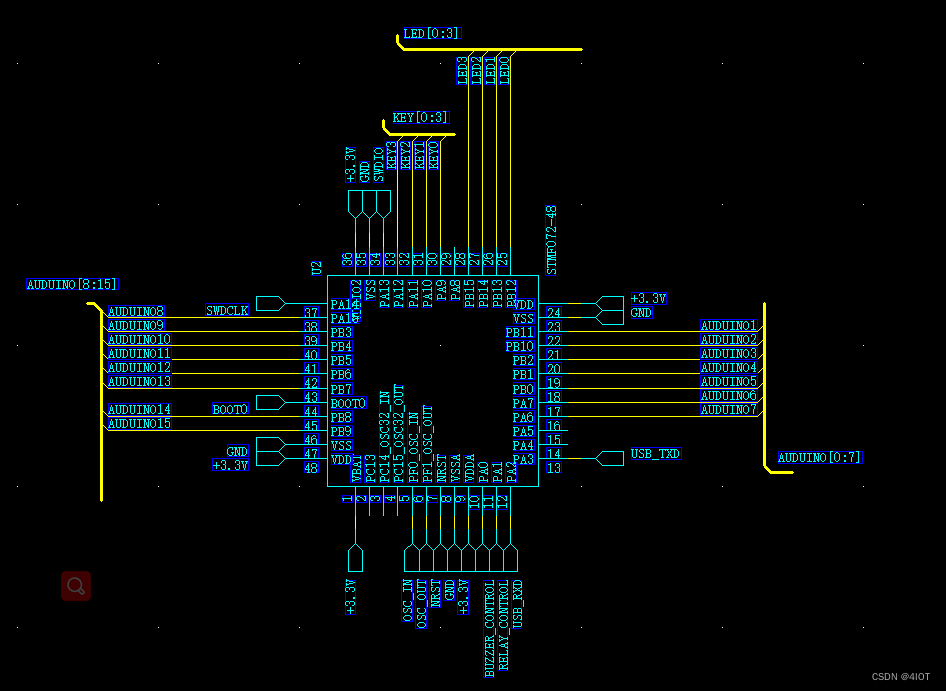
PADS-LOGIC项目原理图设计
最小板原理图设计 目录 1 菜单与工具使用 2 常用设置 2.1选项卡 2.2 图纸设置 2.3 颜色设置 3 设计技巧 3.1 模块化设计思路 3.2 元件放置 3.3 走线及连接符 4 原理图绘制 4.1 POWER原理图设计 4.2 MCU原理图设计 4.2.1晶振电路 4.2.2复位电路 4.2.3 BOOT电路 …...

36岁大龄程序员被裁,找了2个月工作,年包从100万降到50万,要不要接?
为了找到工作,你愿意接受降薪多少? 一位36岁的杭州程序员问: 36岁被裁,找了2个月工作,年包从100万降到50万,真心纠结,要不要接? 网友们分成了旗帜鲜明的两派,一派人认为不…...

Android Retrofit 源码分析
1、简介 Retrofit 是一种基于 Java 的 RESTful Web Service 客户端库,它可以将网络请求抽象出来并支持多种转换器,可以将 JSON、XML 和其他格式的响应数据自动转换为 Java 对象。Retrofit 通过注解的方式来描述 REST API 调用,使开发人员能够…...

CDN如何阻止网络攻击
随着网络技术的发展,网络攻击事件也越来越多,对企业和个人的安全和稳定造成严重威胁。为此,高防CDN应运而生,成为广大用户保障网络安全的重要工具。什么是高防CDN?高防CDN的特点有哪些?高防CDN如何阻止网络攻击?接下来让我们一…...

Mybatis-Plus -04 条件构造器与代码生成器
Mybatis-Plus--条件构造器与代码生成器 1 条件构造器1.1 > < 1.2 in notin1.3 between...1.4 orderBy...1.5 like... 2 代码生成器2.1 引入依赖2.2 生成器代码 1 条件构造器 通过条件构造器可以更加轻松的完成条件查询与更新(底层就是动态SQL) 1.1 > < ge 小于 &l…...

MapReduce高级篇——全局计数器
MapReduce Counter 计数器 概念 在执行MapReduce程序的时候,控制台输出日志中通常下面片段,可以发现输出信息中的核心词是counter,中文叫做计数器 在执行MapReduce城西过程中,许多时候,用户希望了解程序的运行情况,H…...

轻松掌握K8S目录持久卷PV/PVC的kubectl操作知识点04
1、介绍 在docker中可以将容器中的目录挂载出来,在k8s中pod可以部署在不同节点,假如该节点的机器宕机了,k8s可能就会将此Pod转移到其他机器,就不是原先的机器了。k8s有自己的一套挂载方案,如下图所示, 原…...
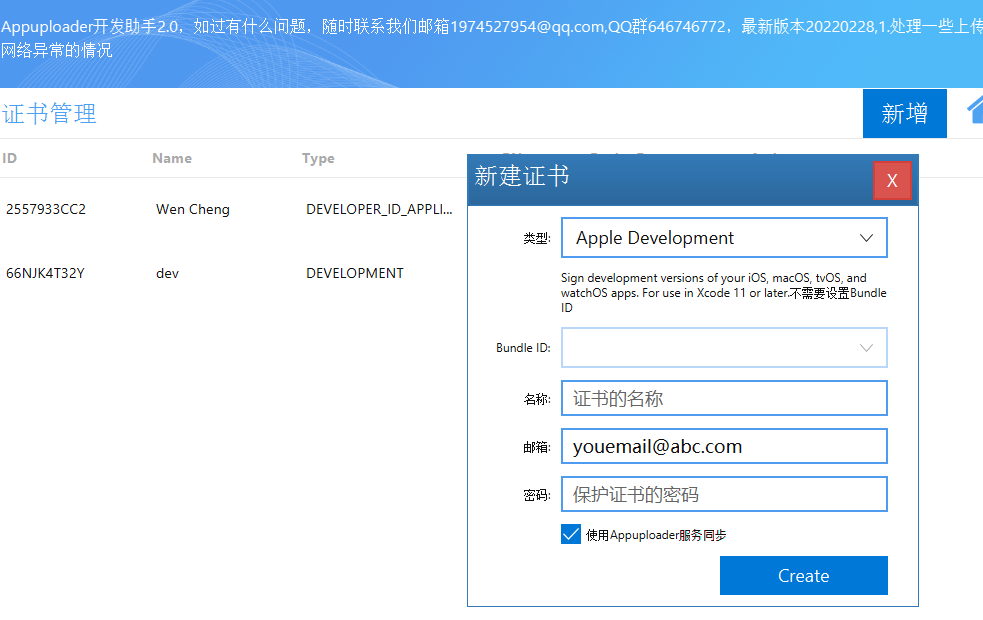
Appuploader证书申请教程
转载:IOS证书制作教程 点击苹果证书 按钮 点击新增 输入证书密码,名称 这个密码不是账号密码,而是一个保护证书的密码,是p12文件的密码,此密码设置后没有其他地方可以找到,忘记了只能删除证书重新制作&…...

用Logisim搞定Educoder交通灯实训:从数码管驱动到状态机集成的保姆级避坑指南
用Logisim征服Educoder交通灯实训:从零搭建到联调的全链路实战手册 第一次打开Educoder平台的交通灯实训项目时,我盯着那些闪烁的数码管和错综复杂的线路图,感觉像在破解某种外星密码。三小时后,当我的第一个状态机模块终于通过测…...

Allegro 16.6 高效布线实战:Region规则、Xnet等长与模块复用的进阶技巧
Allegro 16.6 高效布线实战:Region规则、Xnet等长与模块复用的进阶技巧 在高速PCB设计领域,Allegro 16.6作为行业标杆工具,其深度功能往往决定了设计效率的天花板。当面对BGA封装密度突破1000pin、信号速率迈入10Gbps时代的复杂主板时&#x…...

开源自动驾驶系统终极指南:从入门到精通
开源自动驾驶系统终极指南:从入门到精通 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Trending/op/openpilo…...

免费额度即将失效?ElevenLabs 2024.6.1新规生效前,必须完成的5项额度迁移准备
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs免费额度机制的本质解析 ElevenLabs 的免费额度并非按“每月重置”的静态配额,而是一种基于账户生命周期的动态信用池(Credit Pool),其底层由实…...

AI助手API开发资源全指南:从入门到实战的宝藏清单
1. 项目概述:一个为AI助手API开发者量身打造的“藏宝图”如果你正在或打算基于OpenAI的Assistant API、Anthropic的Claude API,或是其他主流AI平台的助手接口来构建应用,那么你大概率会遇到一个经典困境:官方文档虽然详尽…...

Redis高效开发工具集:从SCAN迭代到数据迁移的Python实践
1. 项目概述:一个Redis开发者的“瑞士军刀”如果你和我一样,日常开发中重度依赖Redis,那你一定遇到过这些场景:想快速查看某个大Key的内存占用,得写脚本遍历;想分析某个Pattern下的所有键,得手动…...

Go语言SDK开发实战:为AI编程助手Cursor构建高效API客户端
1. 项目概述:一个为AI编程助手Cursor定制的Go语言SDK如果你和我一样,日常重度依赖Cursor这类AI编程助手来提升开发效率,同时又是个Go语言的忠实拥趸,那你肯定遇到过这样的场景:想用Go写个脚本,自动化处理一…...

AI智能体任务控制中心:构建可管理复杂项目的协作框架
1. 项目概述:为智能体装上“任务控制中心” 最近在折腾AI智能体(Agent)开发的朋友,可能都遇到过这样的场景:你精心设计了一个能联网搜索、处理文档、调用API的智能体,它单次任务的表现堪称完美。但当你试图…...

Flutter桌面端窗口控制:从隐藏标题栏到自定义全屏交互
1. 为什么需要自定义窗口控制? 当你用Flutter开发Windows桌面应用时,系统默认的标题栏和窗口样式往往显得格格不入。想象一下,你精心设计了一套深色主题的UI,结果顶部突然冒出一条灰白色的标准标题栏——就像给西装革履的绅士戴了…...

如何高效使用Diablo Edit2:暗黑破坏神II存档修改的全面解决方案
如何高效使用Diablo Edit2:暗黑破坏神II存档修改的全面解决方案 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 想要在暗黑破坏神II中打造理想角色,却苦于漫长的刷怪过程&a…...