【Python】【进阶篇】二十一、Python爬虫的多线程爬虫
目录
- 二十一、Python爬虫的多线程爬虫
- 21.1 多线程使用流程
- 21.2 Queue队列模型
- 21.3 多线程爬虫案例
- 1) 案例分析
- 2) 完整程序
二十一、Python爬虫的多线程爬虫
网络爬虫程序是一种 IO 密集型程序,程序中涉及了很多网络 和 本地磁盘的 IO 操作,这会消耗大量的时间,从而降低程序的执行效率,而 Python 提供的多线程能够在一定程度上提升 IO 密集型程序的执行效率。
21.1 多线程使用流程
Python 提供了两个支持多线程的模块,分别是 _thread 和 threading。其中 _thread 模块偏底层,它相比于 threading 模块功能有限,因此推荐大家使用 threading 模块。 threading 中不仅包含了 _thread 模块中的所有方法,
还提供了一些其他方法,如下所示:
- threading.currentThread() 返回当前的线程变量。
- threading.enumerate() 返回一个所有正在运行的线程的列表。
- threading.activeCount() 返回正在运行的线程数量。
线程的具体使用方法如下所示:
from threading import Thread
#线程创建、启动、回收
t = Thread(target=函数名) # 创建线程对象
t.start() # 创建并启动线程
t.join() # 阻塞等待回收线程
创建多线程的具体流程:
t_list = []
for i in range(5):t = Thread(target=函数名)t_list.append(t)t.start()
for t in t_list:t.join()
除了使用该模块外,您也可以使用 Thread 线程类来创建多线程。
在处理线程的过程中要时刻注意线程的同步问题,即多个线程不能操作同一个数据,否则会造成数据的不确定性。通过 threading 模块的 Lock
对象能够保证数据的正确性。
比如,使用多线程将抓取数据写入磁盘文件,此时,就要对执行写入操作的线程加锁,这样才能够避免写入的数据被覆盖。当线程执行完写操作后会主动释放锁,继续让其他线程去获取锁,周而复始,直到所有写操作执行完毕。具体方法如下所示:
from threading import Lock
lock = Lock()
# 获取锁
lock.acquire()
wirter.writerows("线程锁问题解决")
# 释放锁
lock.release()
21.2 Queue队列模型
对于 Python 多线程而言,由于 GIL 全局解释器锁的存在,同一时刻只允许一个线程占据解释器执行程序,当此线程遇到 IO
操作时就会主动让出解释器,让其他处于等待状态的线程去获取解释器来执行程序,而该线程则回到等待状态,这主要是通过线程的调度机制实现的。
由于上述原因,我们需要构建一个多线程共享数据的模型,让所有线程都到该模型中获取数据。queue(队列,先进先出)
模块提供了创建共享数据的队列模型。比如,把所有待爬取的 URL 地址放入队列中,每个线程都到这个队列中去提取 URL。queue 模块的具体使用方法如下:
# 导入模块
from queue import Queue
q = Queue() #创界队列对象
q.put(url) 向队列中添加爬取一个url链接
q.get() # 获取一个url,当队列为空时,阻塞
q.empty() # 判断队列是否为空,True/False
21.3 多线程爬虫案例
下面通过多线程方法抓取小米应用商店(https://app.mi.com/)中应用分类一栏,所有类别下的 APP 的名称、所属类别以及下载详情页 URL。如下图所示:

抓取下来的数据 demo 如下所示:
三国杀,棋牌桌游,http://app.mi.com/details?id=com.bf.sgs.hdexp.mi
1) 案例分析
通过搜索关键字可知这是一个动态网站,因此需要抓包分析。
刷新网页来重新加载数据,可得知请求头的 URL 地址,如下所示:
https://app.mi.com/categotyAllListApi?page=0&categoryId=1&pageSize=30
其中查询参数 pageSize 参数值不变化,page 会随着页码的增加而变化,而类别 Id 通过查看页面元素,如下所示
<ul class="category-list">
<li><a class="current" href="/category/15">游戏</a></li>
<li><a href="/category/5">实用工具</a></li>
<li><a href="/category/27">影音视听</a></li>
<li><a href="/category/2">聊天社交</a></li>
<li><a href="/category/7">图书阅读</a></li>
<li><a href="/category/12">学习教育</a></li>
<li><a href="/category/10">效率办公</a></li>
<li><a href="/category/9">时尚购物</a></li>
<li><a href="/category/4">居家生活</a></li>
<li><a href="/category/3">旅行交通</a></li>
<li><a href="/category/6">摄影摄像</a></li>
<li><a href="/category/14">医疗健康</a></li>
<li><a href="/category/8">体育运动</a></li>
<li><a href="/category/11">新闻资讯</a></li>
<li><a href="/category/13">娱乐消遣</a></li>
<li><a href="/category/1">金融理财</a></li>
</ul>
因此,可以使用 Xpath 表达式匹配 href 属性,从而提取类别 ID 以及类别名称,表达式如下:
基准表达式:xpath_bds = '//ul[@class="category-list"]/li'
提取 id 表达式:typ_id = li.xpath('./a/@href')[0].split('/')[-1]
类型名称:typ_name = li.xpath('./a/text()')[0]
点击开发者工具的 response 选项卡,查看响应数据,如下所示:
{
count: 2000,
data: [
{
appId: 1348407,
displayName: "天气暖暖-关心Ta从关心天气开始",
icon: "http://file.market.xiaomi.com/thumbnail/PNG/l62/AppStore/004ff4467a7eda75641eea8d38ec4d41018433d33",
level1CategoryName: "居家生活",
packageName: "com.xiaowoniu.WarmWeather"
},
{
appId: 1348403,
displayName: "贵斌同城",
icon: "http://file.market.xiaomi.com/thumbnail/PNG/l62/AppStore/0e607ac85ed9742d2ac2ec1094fca3a85170b15c8",
level1CategoryName: "居家生活",
packageName: "com.gbtc.guibintongcheng"
},
...
...
通过上述响应内容,我们可以从中提取出 APP 总数量(count)和 APP (displayName)名称,以及下载详情页的
packageName。由于每页中包含了 30 个 APP,所以总数量(count)可以计算出每个类别共有多少页。
pages = int(count) // 30 + 1
下载详情页的地址是使用 packageName 拼接而成,如下所示:
link = 'http://app.mi.com/details?id=' + app['packageName']
2) 完整程序
完整程序如下所示:
# -*- coding:utf8 -*-
import requests
from threading import Thread
from queue import Queue
import time
from fake_useragent import UserAgent
from lxml import etree
import csv
from threading import Lock
import jsonclass XiaomiSpider(object):def __init__(self):self.url = 'http://app.mi.com/categotyAllListApi?page={}&categoryId={}&pageSize=30'# 存放所有URL地址的队列self.q = Queue()self.i = 0# 存放所有类型id的空列表self.id_list = []# 打开文件self.f = open('XiaomiShangcheng.csv','a',encoding='utf-8')self.writer = csv.writer(self.f)# 创建锁self.lock = Lock()def get_cateid(self):# 请求url = 'http://app.mi.com/'headers = { 'User-Agent': UserAgent().random}html = requests.get(url=url,headers=headers).text# 解析parse_html = etree.HTML(html)xpath_bds = '//ul[@class="category-list"]/li'li_list = parse_html.xpath(xpath_bds)for li in li_list:typ_name = li.xpath('./a/text()')[0]typ_id = li.xpath('./a/@href')[0].split('/')[-1]# 计算每个类型的页数pages = self.get_pages(typ_id)#往列表中添加二元组self.id_list.append( (typ_id,pages) )# 入队列self.url_in()# 获取count的值并计算页数def get_pages(self,typ_id):# 获取count的值,即app总数url = self.url.format(0,typ_id)html = requests.get(url=url,headers={'User-Agent':UserAgent().random}).json()count = html['count']pages = int(count) // 30 + 1return pages# url入队函数,拼接url,并将url加入队列def url_in(self):for id in self.id_list:# id格式:('4',pages)for page in range(1,id[1]+1):url = self.url.format(page,id[0])# 把URL地址入队列self.q.put(url)# 线程事件函数: get() -请求-解析-处理数据,三步骤def get_data(self):while True:# 判断队列不为空则执行,否则终止if not self.q.empty():url = self.q.get()headers = {'User-Agent':UserAgent().random}html = requests.get(url=url,headers=headers)res_html = html.content.decode(encoding='utf-8')html=json.loads(res_html)self.parse_html(html)else:break# 解析函数def parse_html(self,html):# 写入到csv文件app_list = []for app in html['data']:# app名称 + 分类 + 详情链接name = app['displayName']link = 'http://app.mi.com/details?id=' + app['packageName']typ_name = app['level1CategoryName']# 把每一条数据放到app_list中,并通过writerows()实现多行写入app_list.append([name,typ_name,link])print(name,typ_name)self.i += 1# 向CSV文件中写入数据self.lock.acquire()self.writer.writerows(app_list)self.lock.release()# 入口函数def main(self):# URL入队列self.get_cateid()t_list = []# 创建多线程for i in range(1):t = Thread(target=self.get_data)t_list.append(t)# 启动线程t.start()for t in t_list:# 回收线程 t.join()self.f.close()print('数量:',self.i)if __name__ == '__main__':start = time.time()spider = XiaomiSpider()spider.main()end = time.time()print('执行时间:%.1f' % (end-start))
运行上述程序后,打开存储文件,其内容如下:
在我们之间-单机版,休闲创意,http://app.mi.com/details?id=com.easybrain.impostor.gtx粉末游戏,模拟经营,http://app.mi.com/details?id=jp.danball.powdergameviewer.bnn三国杀,棋牌桌游,http://app.mi.com/details?id=com.bf.sgs.hdexp.mi腾讯欢乐麻将全集,棋牌桌游,http://app.mi.com/details?id=com.qqgame.happymj快游戏,休闲创意,http://app.mi.com/details?id=com.h5gamecenter.h2mgc皇室战争,战争策略,http://app.mi.com/details?id=com.supercell.clashroyale.mi地铁跑酷,跑酷闯关,http://app.mi.com/details?id=com.kiloo.subwaysurf
...
...
相关文章:
【Python】【进阶篇】二十一、Python爬虫的多线程爬虫
目录 二十一、Python爬虫的多线程爬虫21.1 多线程使用流程21.2 Queue队列模型21.3 多线程爬虫案例1) 案例分析2) 完整程序 二十一、Python爬虫的多线程爬虫 网络爬虫程序是一种 IO 密集型程序,程序中涉及了很多网络 和 本地磁盘的 IO 操作,这会消耗大…...
)
Python从入门到精通14天(eval、literal_eval、exec函数的使用)
eval、literal_eval、exec函数的使用 eval函数literal_eval函数exec函数三者的区别 eval函数 eval()是Python中的内置函数,它可以将一个字符串作为参数,并将该字符串作为Python代码执行。它的语法格式为:eval(expression,globalsNone,locals…...
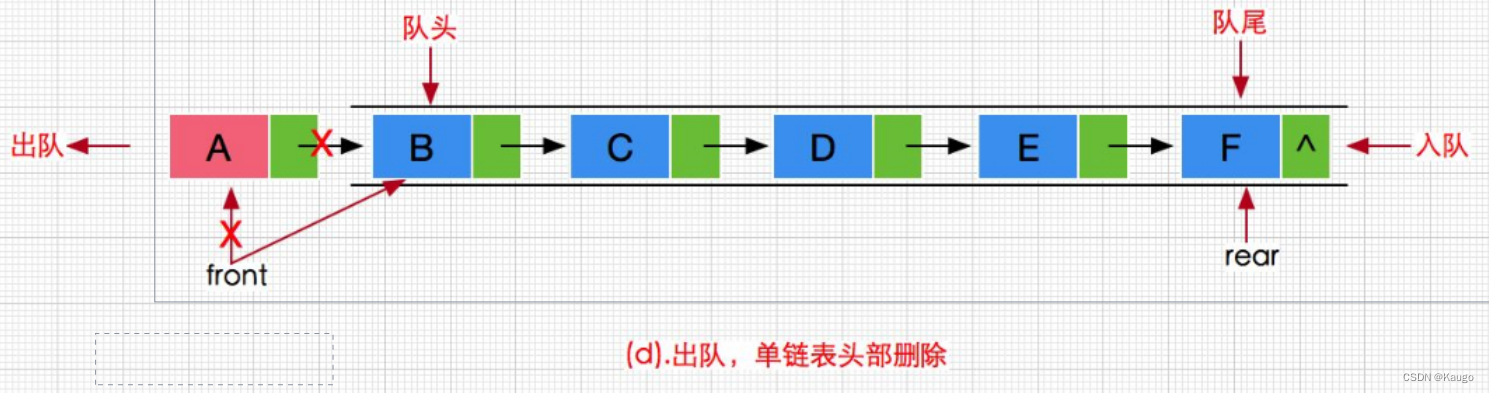
队列的基本操作(C语言链表实现)初始化,入队,出队,销毁,读取数据
文章目录 前言一、队列基本变量的了解二、队列的基本操作2.1队列的初始化(QueueInit)2.2入队(QueuePush)2.3判断是否为空队(QueueEmpty)2.4出队(QueuePop)2.5队列的队头数据…...
项目支付接入支付宝【沙箱环境】
前言 订单支付接入支付宝,使用支付宝提供的沙箱机制模拟为订单付款。我这里主要记录一下沙箱环境如何接入到系统中,具体细节的实现。按照官方文档来就可以了。 1、使用步骤 这里有几个重要数据要拿到,一个是支付宝的公钥和私钥,…...

程序员应该如何提升自己
作为一名程序员,以下是您可以考虑的一些方法来提高自己的技能和知识: 深入学习编程语言和相关工具:了解您使用的编程语言和相关工具的基本原理和高级特性,以便更好地理解其工作方式并更有效地使用它们。 刻意练习:刻意…...

全球上线!ABB中国涡轮增压器分拆 – 数据清理阶段完成
ABB是数字行业的技术前沿者,拥有四项主营业务:电气化,工业自动化,运动控制以及机器人和离散自动化。ABB总部位于瑞士苏黎世,业务遍及100多个国家,拥有约105,000名员工。2021年,该公司…...
)
手写简易 Spring(三)
文章目录 三. 手写简易 Spring(三)1. Bean 对象初始化和销毁方法1. XML 添加 init-method 与实现 InitializingBean 接口注册初始化2. XML 添加 destroy-method 与实现 DisposableBean 接口注册销毁3. DefaultSingletonBeanRegistry 优秀的解耦方法 2. 定…...

设计模式-看懂UML类图和时序图
这里不会将UML的各种元素都提到,只讲类图中各个类之间的关系; 能看懂类图中各个类之间的线条、箭头代表什么意思后,也就足够应对 日常的工作和交流; 同时,应该能将类图所表达的含义和最终的代码对应起来; 1…...

2023年全国最新安全员精选真题及答案57
百分百题库提供安全员考试试题、建筑安全员考试预测题、建筑安全员ABC考试真题、安全员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 101.(单选题)遇有()及以上强风、浓雾等…...

数字图像处理基础
图像增强:不论方法,只要能够得到较好的图像即可 图像复原:找到图像退化的原因,把噪声过滤得到较好的图像 RGB——HSI(色调 饱和度 亮度)彩色图像处理需要用到灰度图像处理 直方图均衡,灰度概率密度函数接近均匀分布&a…...
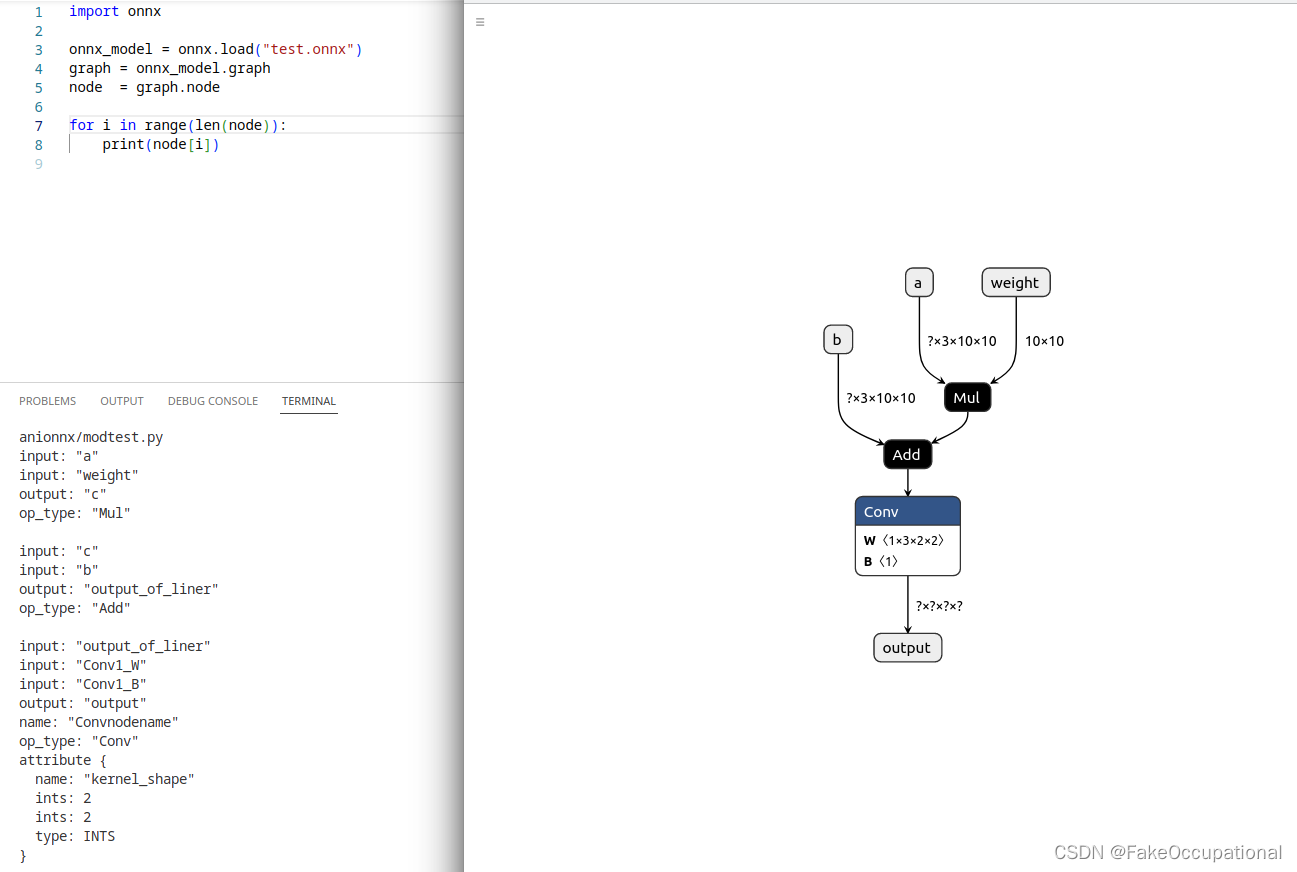
onnx手动操作
使用onnx.helper可以进行onnx的制造组装操作: 对象描述ValueInfoProto 对象张量名、张量的基本数据类型、张量形状算子节点信息 NodeProto算子名称(可选)、算子类型、输入和输出列表(列表元素为数值元素)GraphProto对象用张量节点和算子节点组成的计算图对象ModelP…...
虚拟机安装Centos7,ping不通百度
虚拟机安装Centos7,ping不通百度 一、虚拟机网络配置 网络适配器选择桥接模式,不勾选复制物理网络连接状态。 同时虚拟机使用默认配置都是桥接。 二、配置静态IP 1、首先,查看宿主机的IP和网关 2、配置静态ip的文件地址及修改命令如下&…...

leetCode算法第一天
今天开始刷算法题,提升自己的算法思维和代码能力,加油! 文章目录 无重复字符的最长子串最长回文子串N形变换字符串转换整数 无重复字符的最长子串 leetCode链接 https://leetcode.cn/problems/longest-substring-without-repeating-characte…...

怎么将太大的word文档压缩变小,3个高效方法
怎么将太大的word文档压缩变小?word文档是我们在办公中使用较多的文件格式之一,相信小伙伴们会遇到这样的问题,编辑完成word文档之后发现,编辑完的文档体积太大了,无论是发送给客户还是上传到邮箱中都不方便࿰…...

mvc+动态代理
不使用MVC的时候系统存在的缺陷 一个Servlet都负责了那些工作? 负责了接收数据负责了核心的业务处理负责了数据表中的CRUD负责了页面的数据展示… 分析银行转账项目存在那些问题? 代码的复用性太差。(代码的重用性太差) 因为没…...
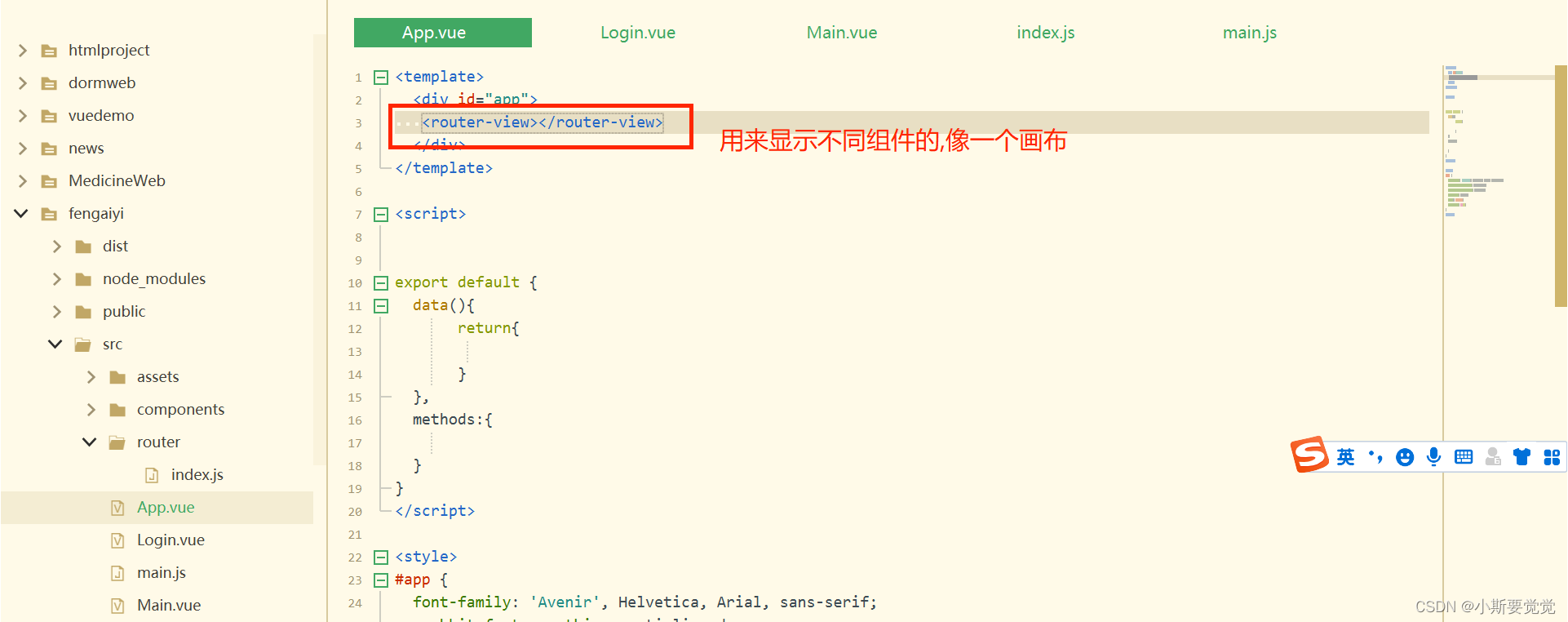
vue-cli(vue脚手架方式搭建)
1.首先安装node前端环境,可以帮助我们去下载其他的组件 下载完成后,去自己的电脑找到node的文件路径,复制去配置环境变量,在path中配 环境搭配完成后,在cmd中进行测试 ,输入一下两个命令进行测试 2.在hbuilderX中创建一个vue-cli项目(标准的前段项目) 3.组件路由 (1)安装 v…...

CentOS 安装 Docker
文章目录 一、更新yum源二、查看docker是否曾经安装过三、安装所需要的软件包四、设置yum源(也可以设置成国内的阿里源等)五、查看docker版本六、.安装docker (默认全部选y)七、查看docker安装版本八、docker 启动/停止/重启/开机…...

别搞了 软件测试真卷不动了...
内卷可以说是 2022年最火的一个词了。2023 年刚开始,在很多网站看到很多 软件测试的 2022 年度总结都是:软件测试 越来越卷了(手动狗头),2022 年是被卷的一年。前有几百万毕业生虎视眈眈,后有在职人员带头“…...
OJ刷题 第十二篇
21308 - 特殊的三角形 时间限制 : 1 秒 内存限制 : 128 MB 有这样一种特殊的N阶的三角形,当N等于3和4时,矩阵如下: 请输出当为N时的三角形。 输入 输入有多组数据,每行输入一个正整数N,1<N<100 输出 按照给出…...

【计算机专业应届生先找培训还是先找个工作过渡一下?】
计算机专业应届生先找培训还是先找个工作过渡一下? 计算机应届生是先培训还是先工作,这个问题应该困扰了很多专业技能一般的同学,尤其是学历方面还没有优势的普通本专科院校。都说技术与学历优秀的人进大厂,技术一般学历优秀的人能…...

MCP服务器生产级部署:从Docker到Kubernetes的完整工程化实践
1. 项目概述:一个为MCP服务器量身定制的部署蓝图如果你正在开发或使用一个基于模型上下文协议(Model Context Protocol, MCP)的服务器,并且为如何将其优雅、可靠地部署到生产环境而头疼,那么你很可能需要的…...

基于HTML5 Canvas的轻量级图像标注库visual-annotator集成指南
1. 项目概述:一个为开发者打造的视觉标注利器如果你做过图像识别、目标检测或者任何需要处理大量图片标注的计算机视觉项目,那你一定对标注工具不陌生。从早期的LabelImg到后来的CVAT、Label Studio,工具的选择往往决定了你项目前期数据准备的…...

2025-2026年国内PCB厂家:五大产品专业评测 解决散热不均致焊点脱落痛点
摘要 当企业将PCB选型从通用需求转向高精尖领域适配,决策者面临如何在技术复杂度与成本可控间取得平衡的现实挑战:是追求极致性能,还是优先保障供应链稳定?根据Prismark Partners发布的2024年全球PCB产业报告,全球PCB…...
)
基于节点电价的电网对电动汽车接纳能力评估模型研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Hermes Agent 工具如何配置接入 Taotoken 提供的模型服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent 工具如何配置接入 Taotoken 提供的模型服务 Hermes Agent 是一个流行的开源智能体框架,它允许开发者通过…...

SAP F110自动付款:从零到精通的配置全景图
1. SAP F110自动付款入门指南 第一次接触SAP F110自动付款功能时,我也被那一堆配置项搞得晕头转向。记得当时为了搞清楚银行确定逻辑,整整花了两天时间反复测试。现在回想起来,如果有个系统性的指导手册,至少能节省一半时间。F110…...

科技领跑公益,擎天租机器人“天团”助阵2026渣打上海10公里跑
5月16日,“渣打上海10公里跑”在上海世博庆典广场开跑。国内领先机器人一站式应用平台擎天租携旗下多款明星机器人参与,通过机器人与体育活动的跨界融合,为现场4500名跑者带来了一场科技感十足的助跑盛宴。本次赛事涵盖了10公里个人跑及2公里…...

等保2.0合规实战:Redis安全配置核查与加固指南
1. Redis安全配置入门:为什么等保2.0要求这么严格? 我第一次接触Redis安全配置是在一次等保2.0合规检查中。当时客户系统因为Redis默认配置导致数据泄露,整个项目组连夜加班整改。从那以后,我就养成了每次部署Redis必做安全检查的…...

揭秘开源驾驶辅助系统openpilot:如何用代码重新定义汽车智能化体验
揭秘开源驾驶辅助系统openpilot:如何用代码重新定义汽车智能化体验 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/Gi…...
)
Jetson Nano玩家必看:Windows下用Diskpart彻底格式化SD卡(解决烧录后不识别问题)
Jetson Nano玩家必备技能:Windows下彻底格式化SD卡的终极指南 当你兴奋地将Linux系统镜像烧录到SD卡,准备在Jetson Nano上大展拳脚时,却发现Windows资源管理器里那张卡"消失"了——这不是灵异事件,而是分区表变化导致的…...