ETL工具 - Kettle 转换算子介绍
一、Kettle 转换算子
上篇文章对 Kettle 中的输入输出算子进行了介绍,本篇文章继续对转换算子进行讲解。
下面是上篇文章的地址:
ETL工具 - Kettle 输入输出算子介绍
转换是ETL里面的T(Transform),主要做数据转换,数据清洗的工作。
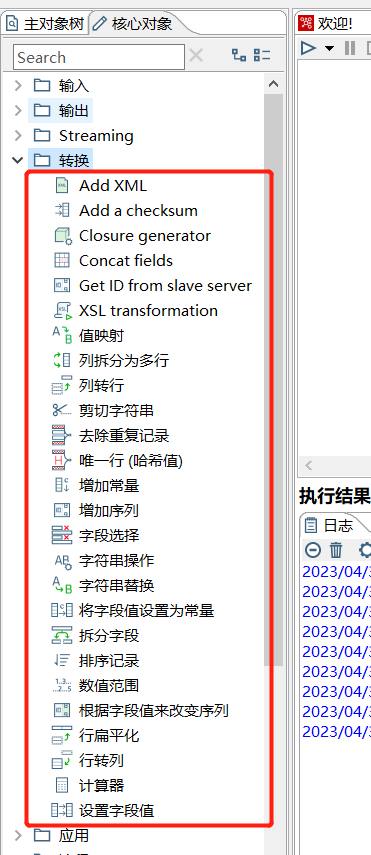
二、转换算子介绍
数据输入以上篇文章中的表输入,表结构如下:
CREATE TABLE `user` (`id` int(0) NOT NULL AUTO_INCREMENT,`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,`age` int(0) NULL DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
INSERT INTO `user` VALUES (1, '小明', 90);
INSERT INTO `user` VALUES (2, '小红', 91);
INSERT INTO `user` VALUES (3, '小兰', 92);
INSERT INTO `user` VALUES (4, '小爱', 93);
INSERT INTO `user` VALUES (5, '张三', 94);
INSERT INTO `user` VALUES (6, '李四', 95);
INSERT INTO `user` VALUES (7, '王五', 96);
INSERT INTO `user` VALUES (8, '赵六', 97);
表输入控件:
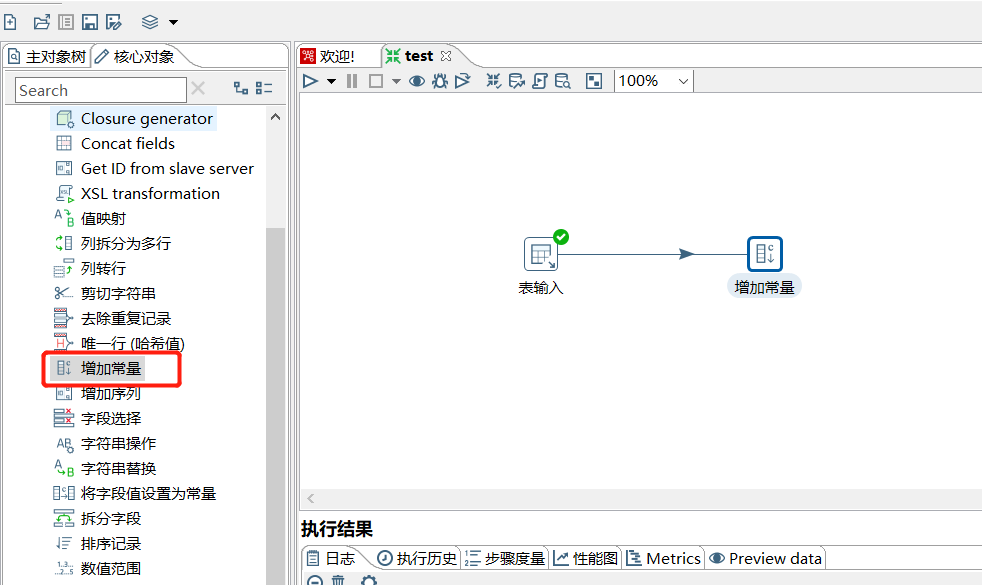
2.1 增加常量
增加常量就是在本身的数据流里面添加一列常量数据,值都是相同的内容。
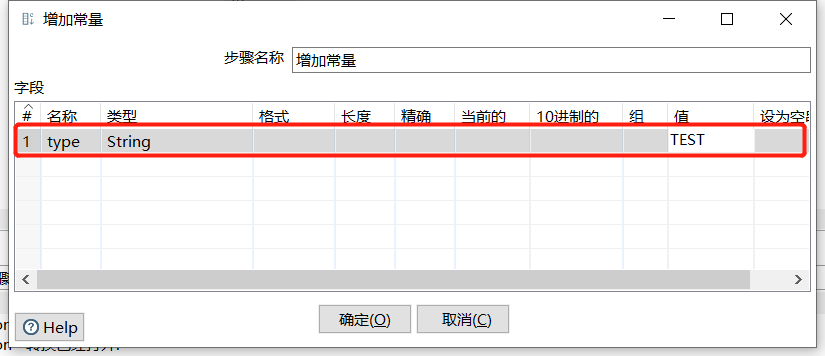
运行后预览数据:
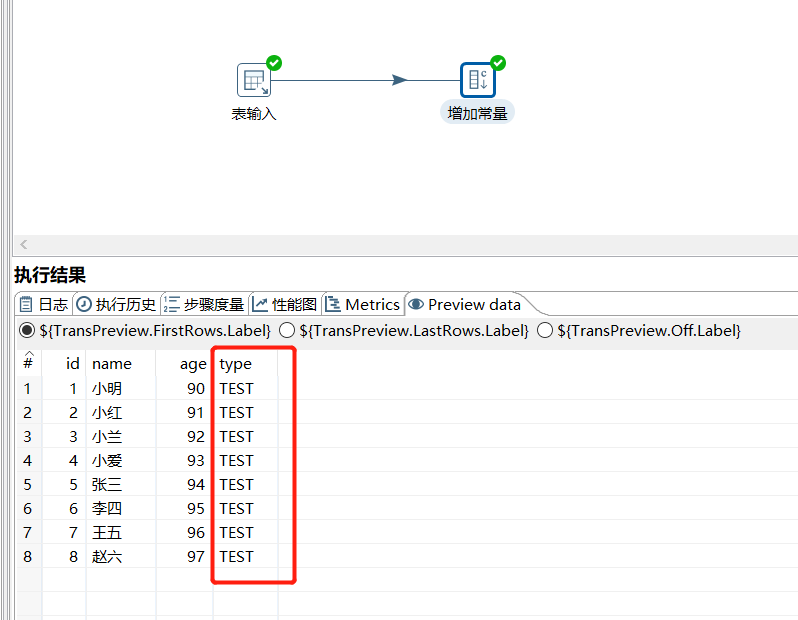
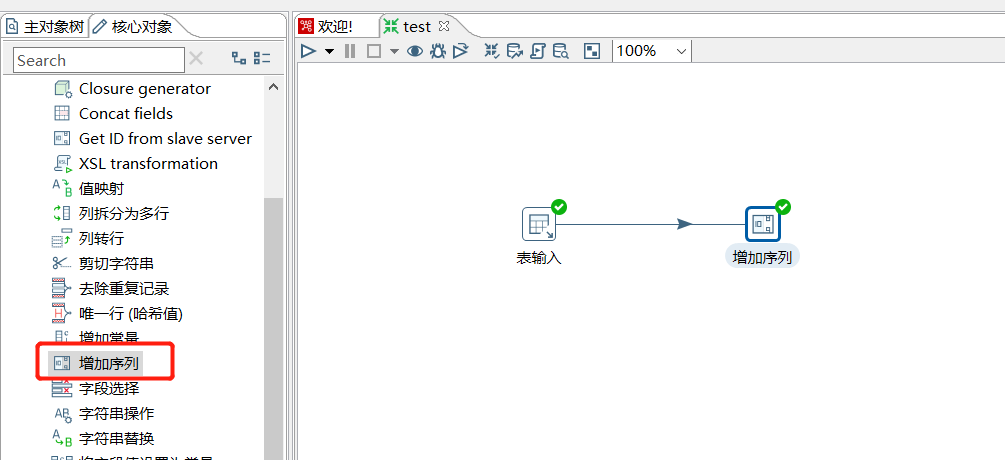
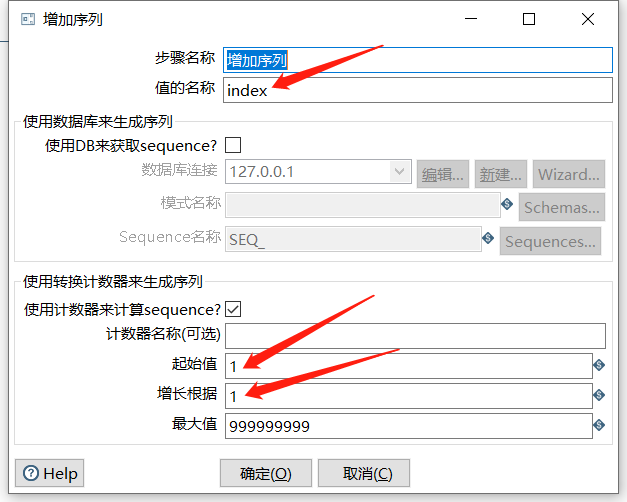
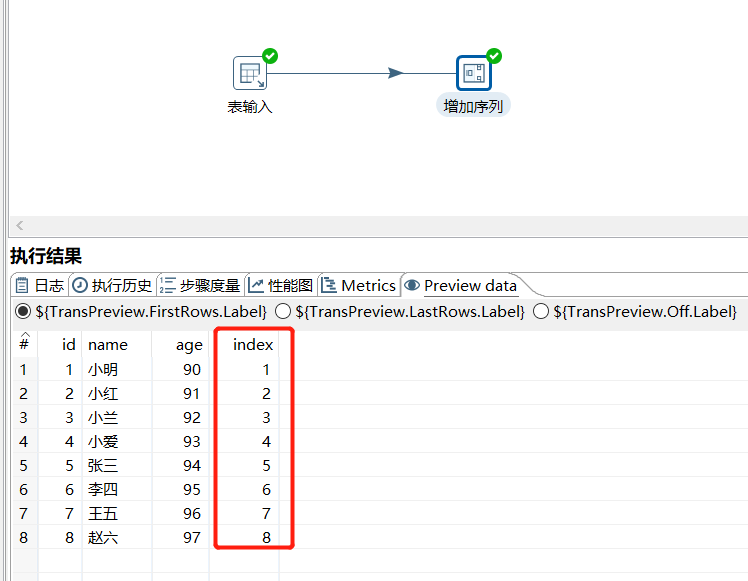
2.2 增加序列
增加序列同样给数据流添加一个字段,但可以自定义该序列字段的递增步长:
运行后预览数据:
2.3 值映射
值映射就是把字段的一个值映射成其他的值:
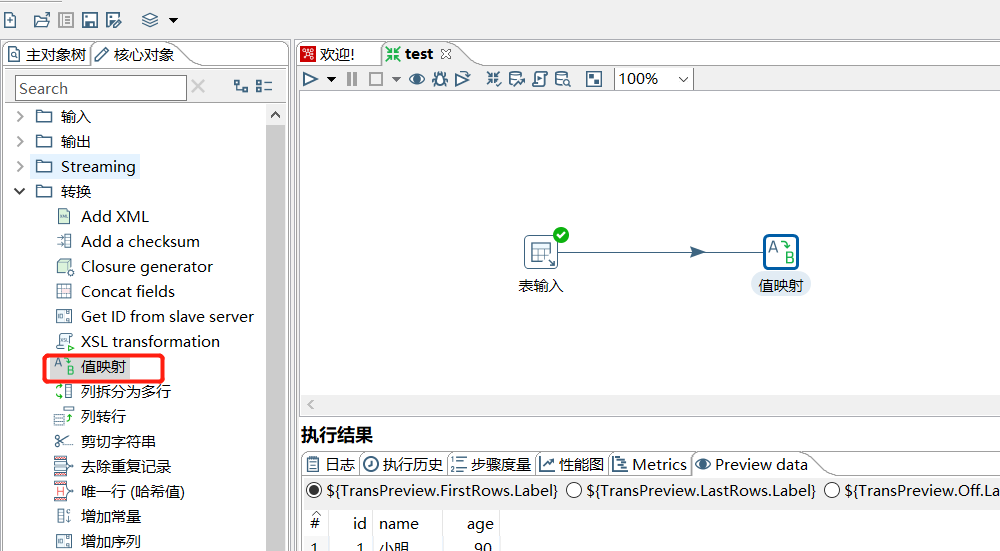
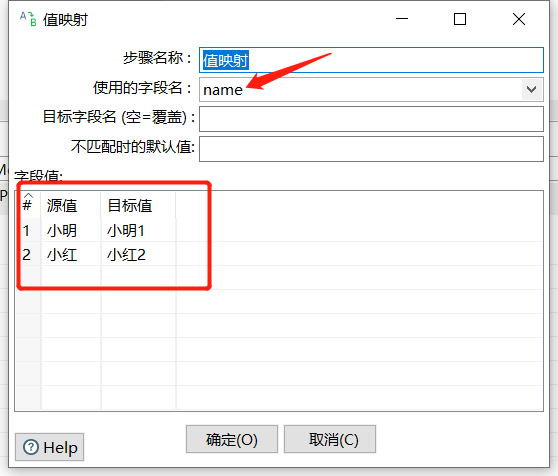
运行后预览数据:
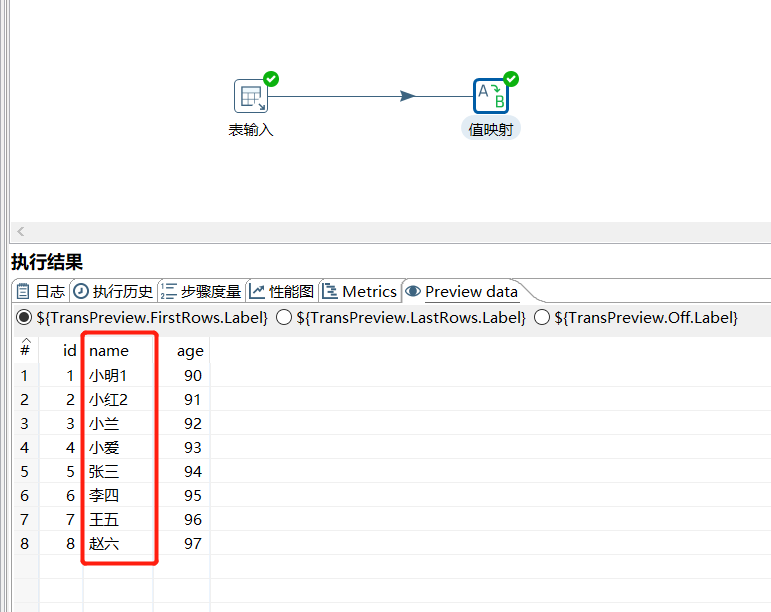
2.4 Concat fields
将多个字段连接起来形成一个新的字段:
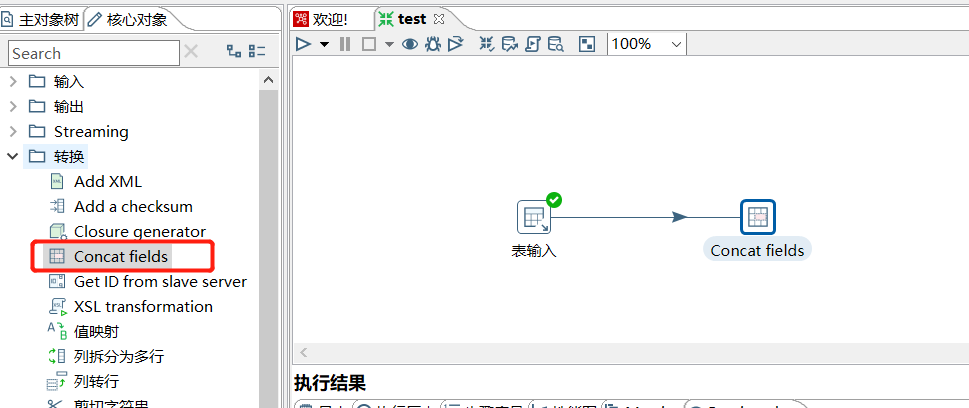
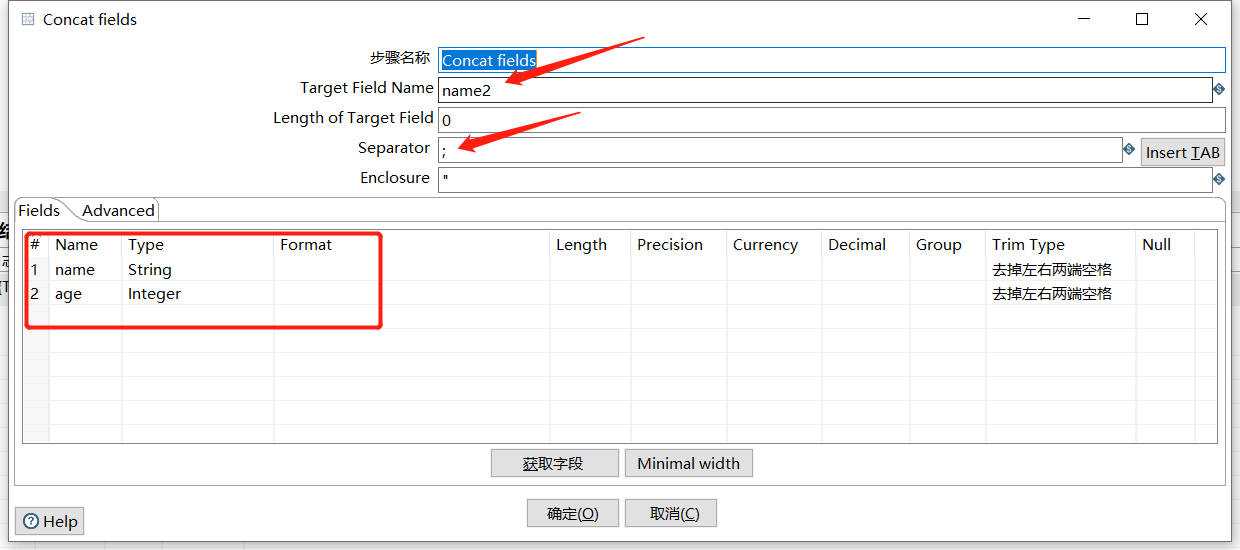
运行后预览数据:
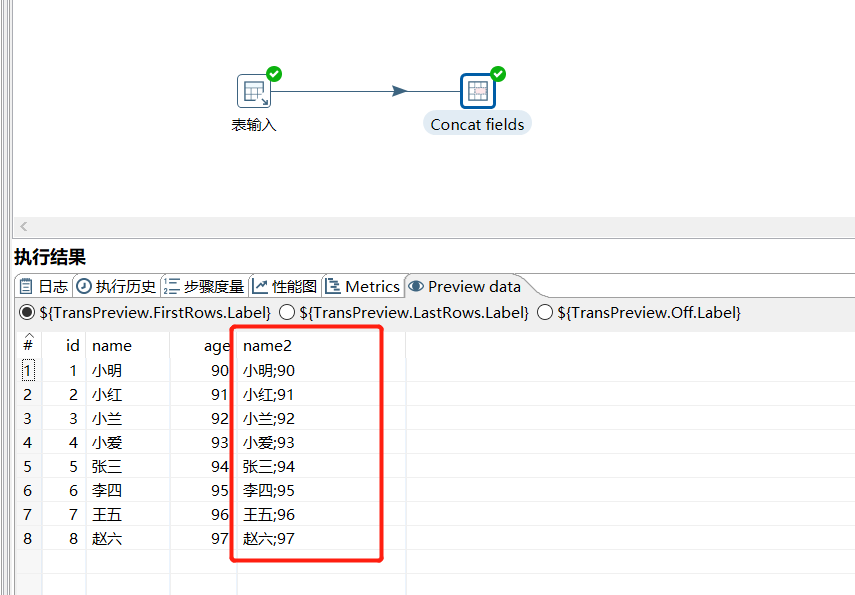
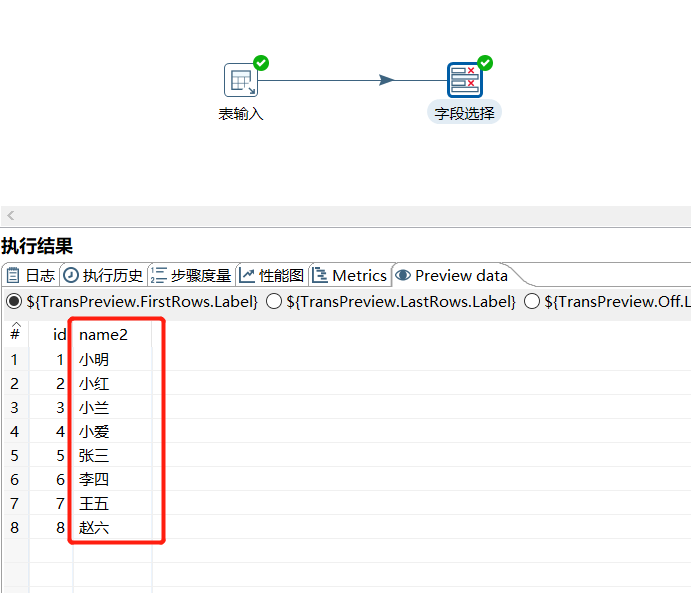
2.5 字段选择
可以从数据流中进行选择字段、改变名称、修改数据类型等:
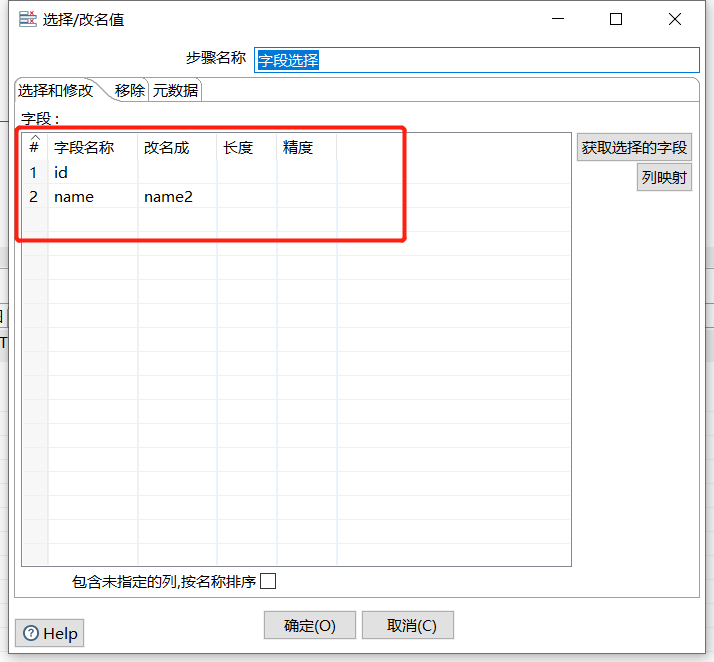
运行后预览数据:
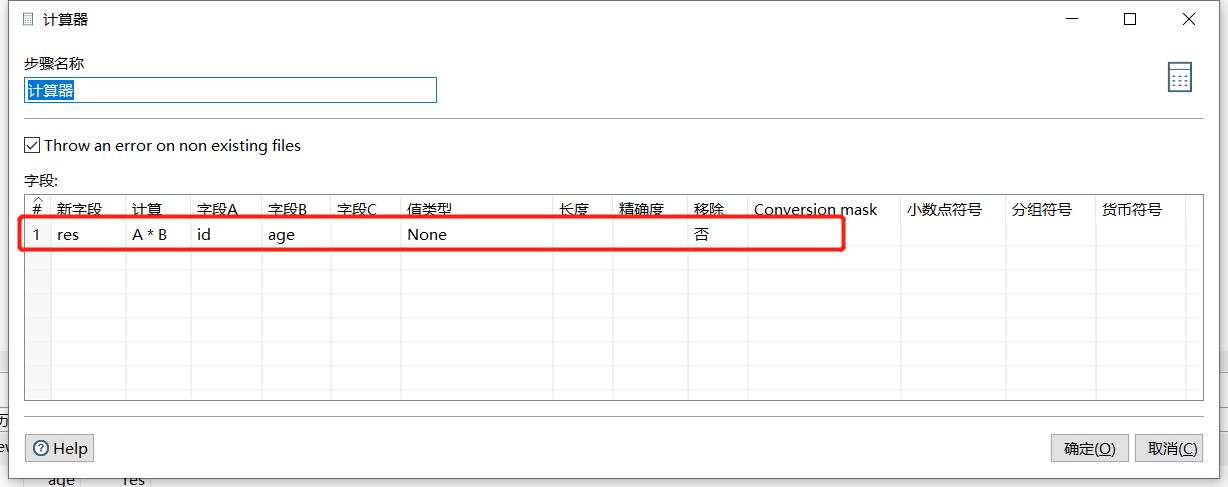
2.6 计算器
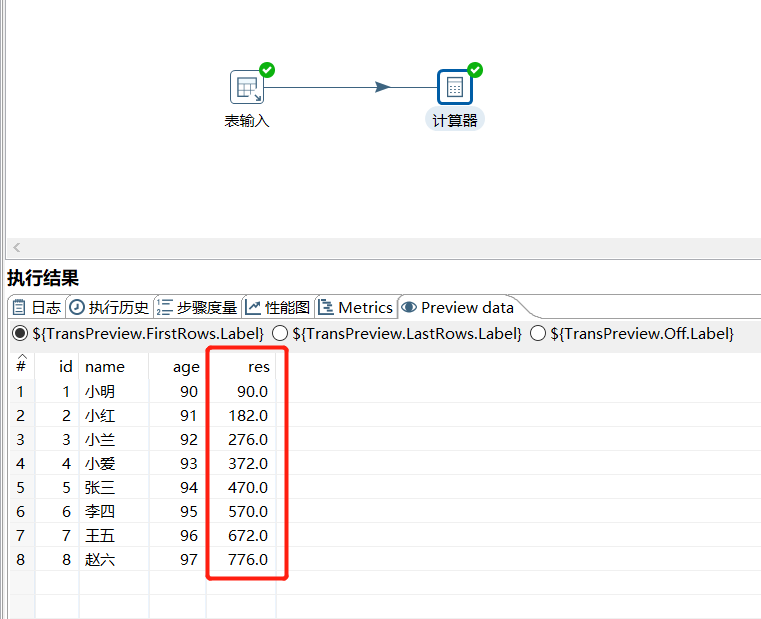
一个函数集合,可以通过里面的多个计算函数对已有字段进行计算,例如计算 id*age 的值:
运行后预览数据:
2.7 剪切字符串
根据输入流字段,从摸个位置开始剪切出新的字段:
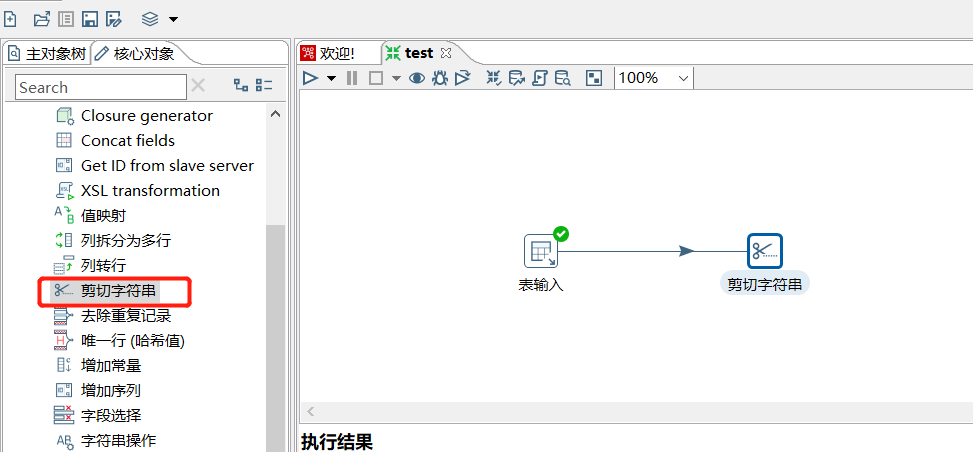
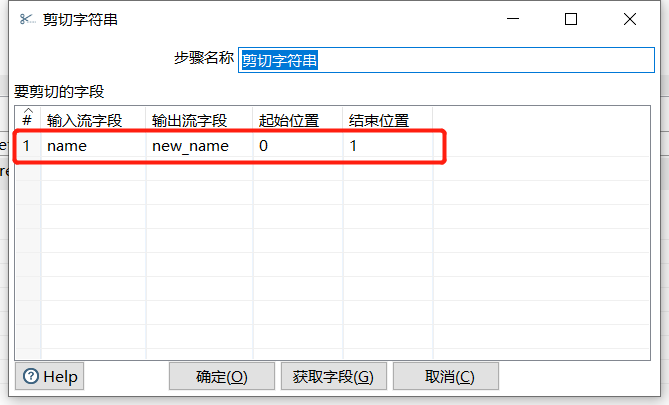
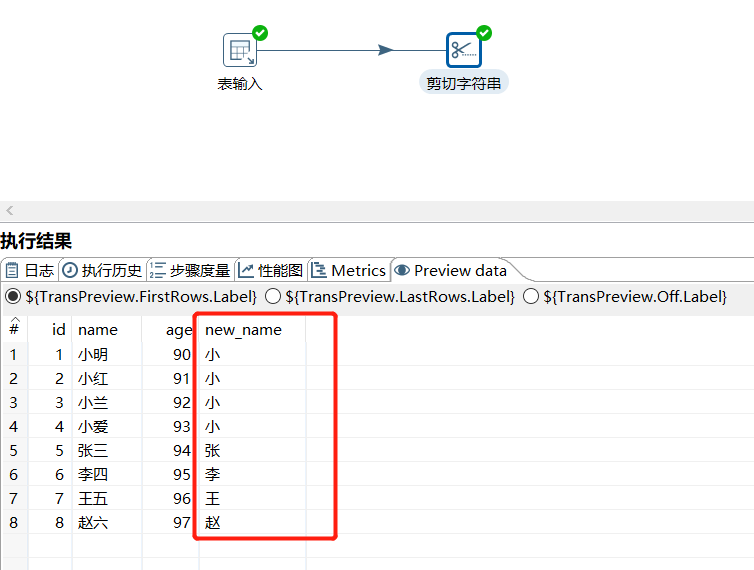
运行后预览数据:
2.8 字符串替换
根据输入流字段,替换某个字符形成新的字段:
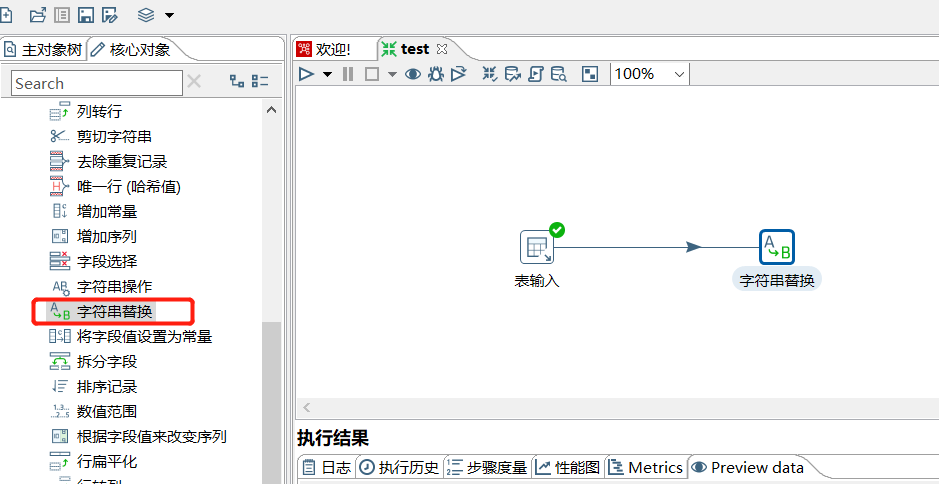
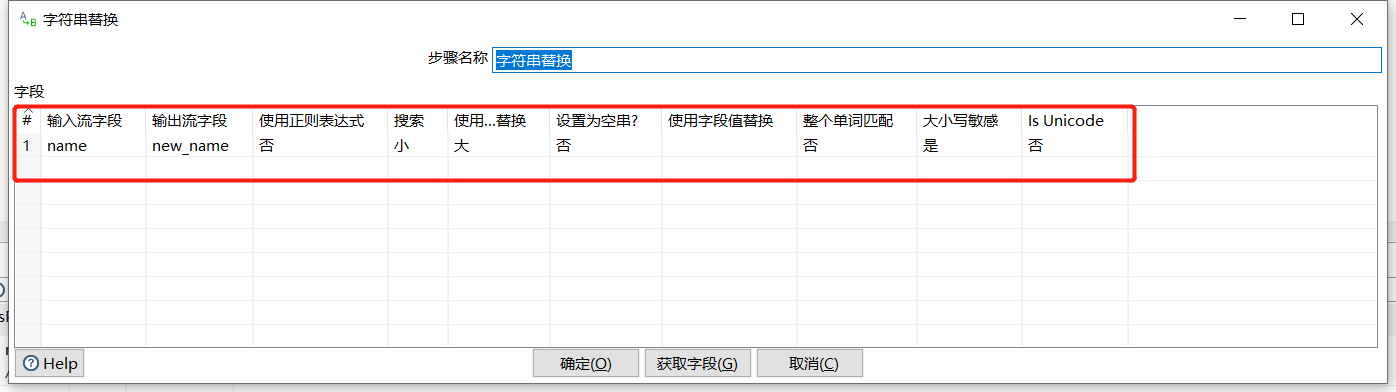
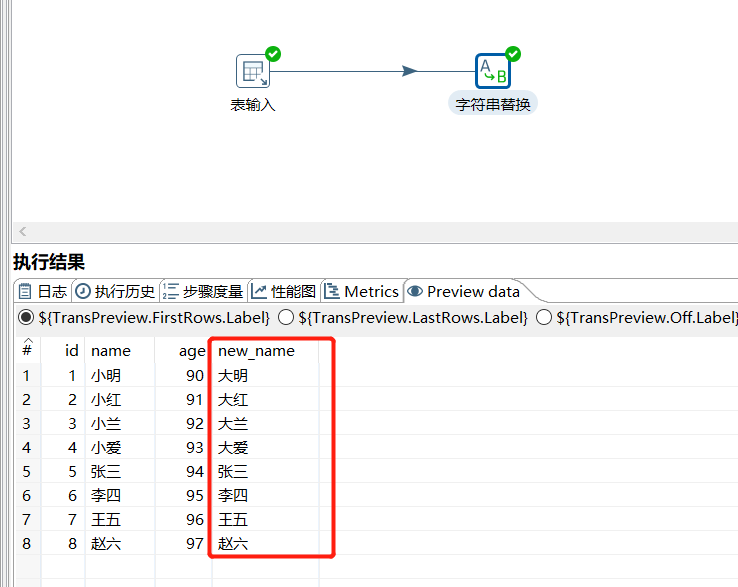
运行后预览数据:
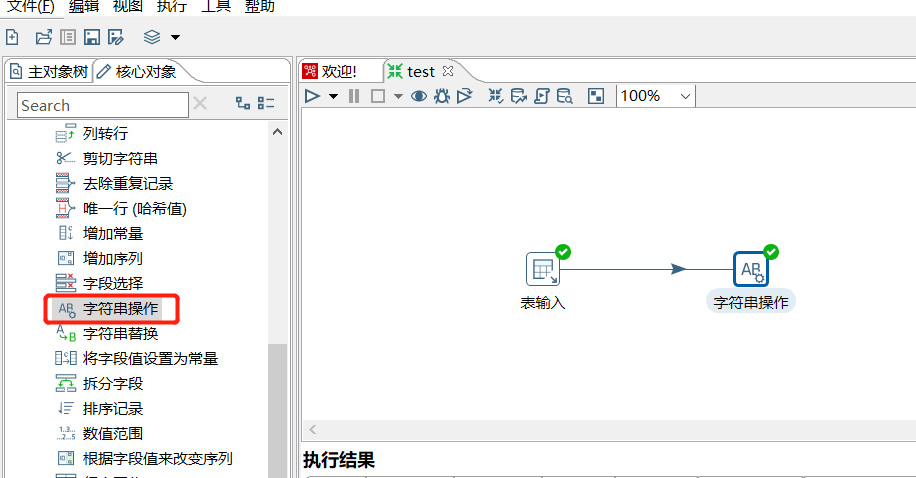
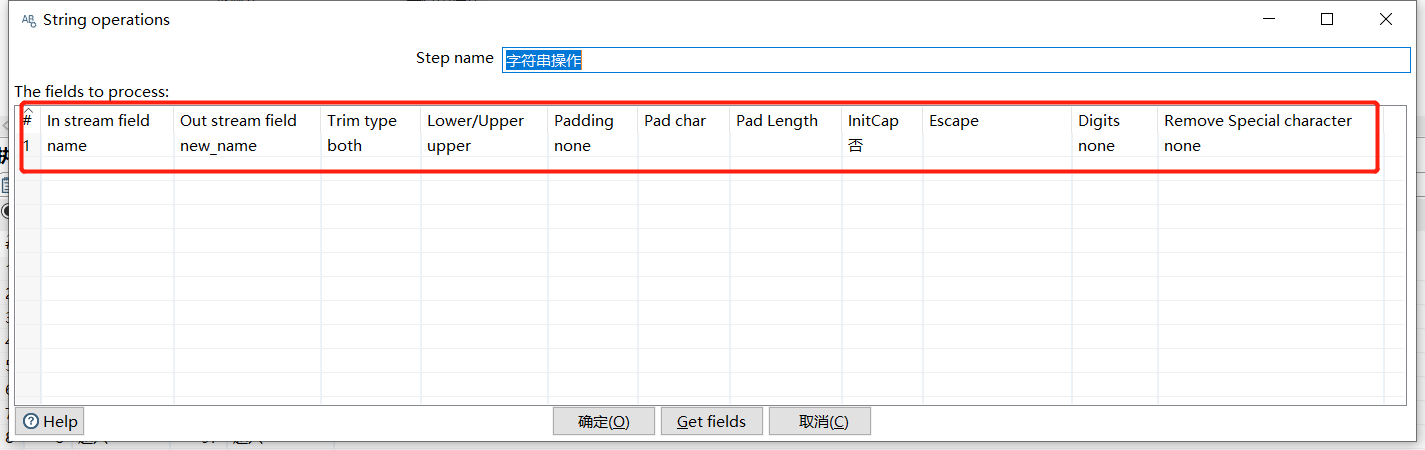
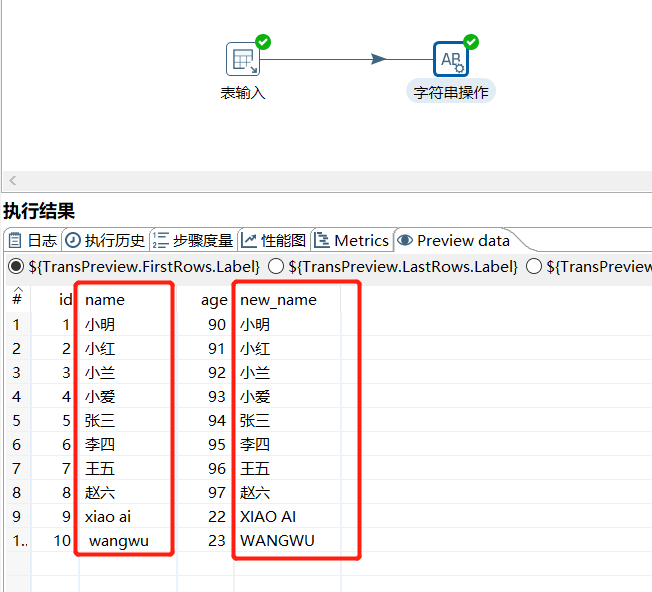
2.9 字符串操作
可以去除字符串两端的空格和大小写切换:
这里再对user表增加两个测试数据:
INSERT INTO `test`.`user`(`id`, `name`, `age`) VALUES (9, 'xiao ai', 22);
INSERT INTO `test`.`user`(`id`, `name`, `age`) VALUES (10, ' wangwu ', 23);
运行后预览数据:
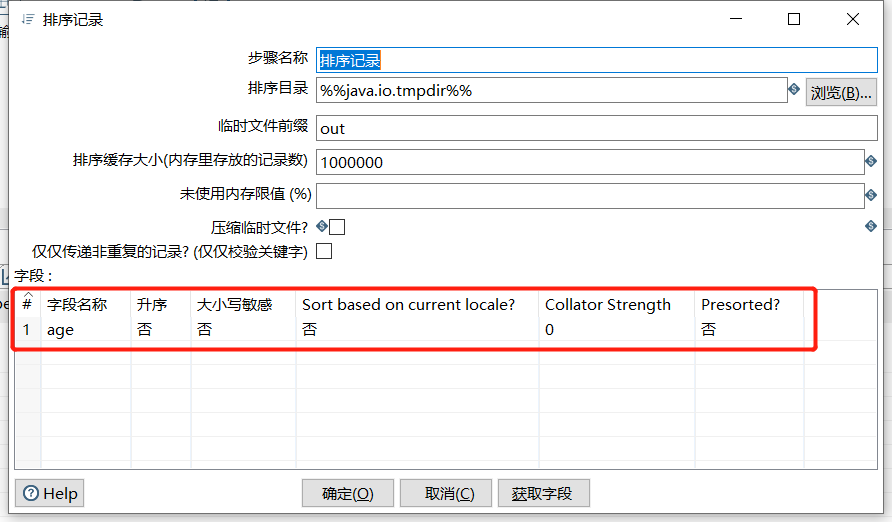
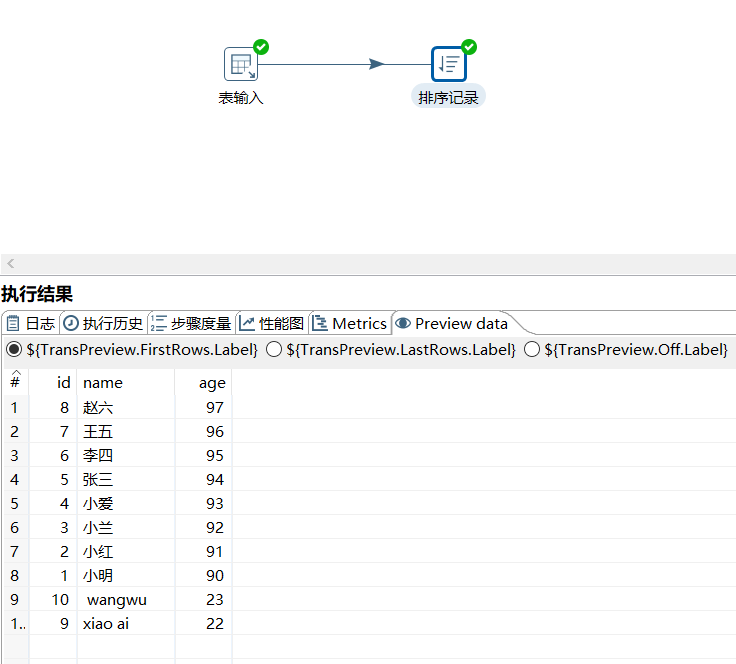
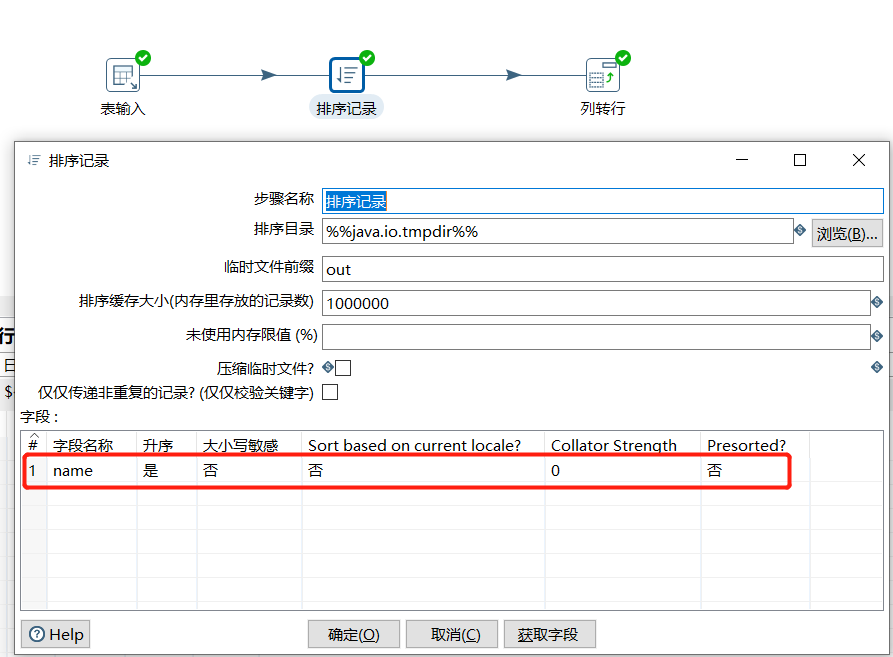
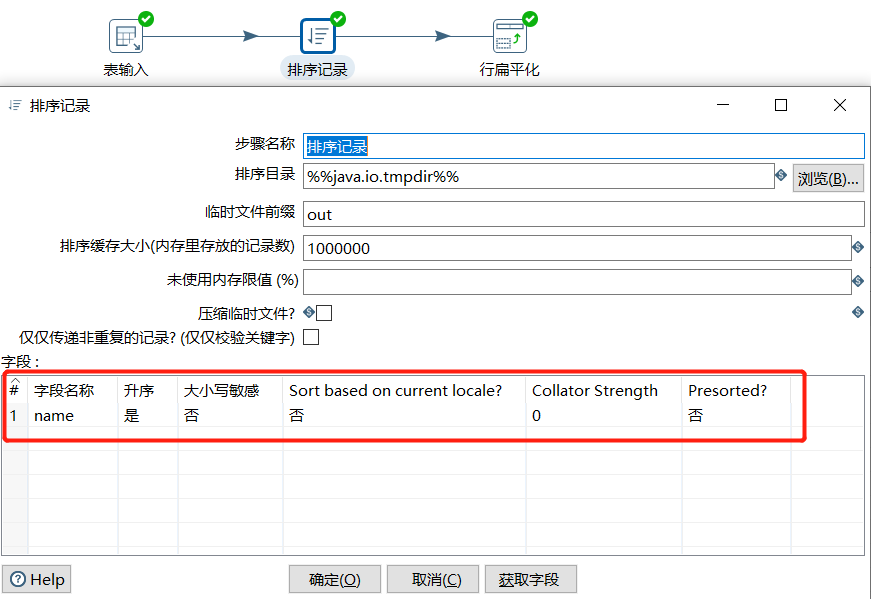
2.10 排序记录
根据指定字段进行升序或者降序排列:
运行后预览数据:
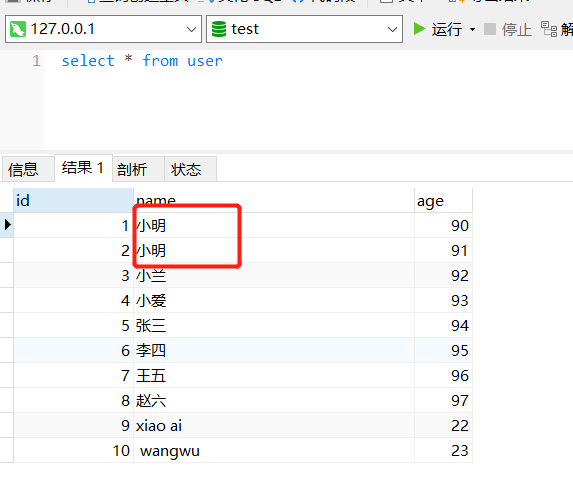
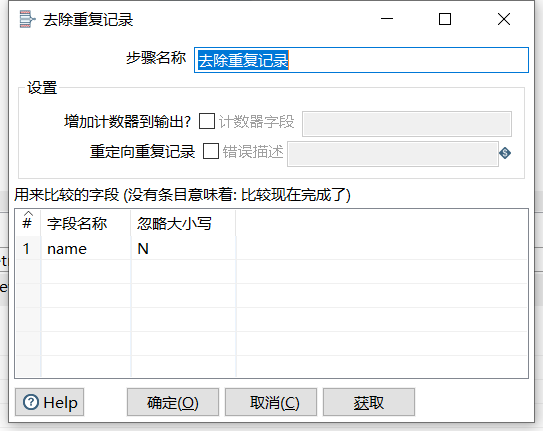
2.11 去除重复记录
去除数据流里面相同的数据行,使用之前要求必须先对数据进行排序:
对数据库中添加两个名字相同的数据:
运行后预览数据:
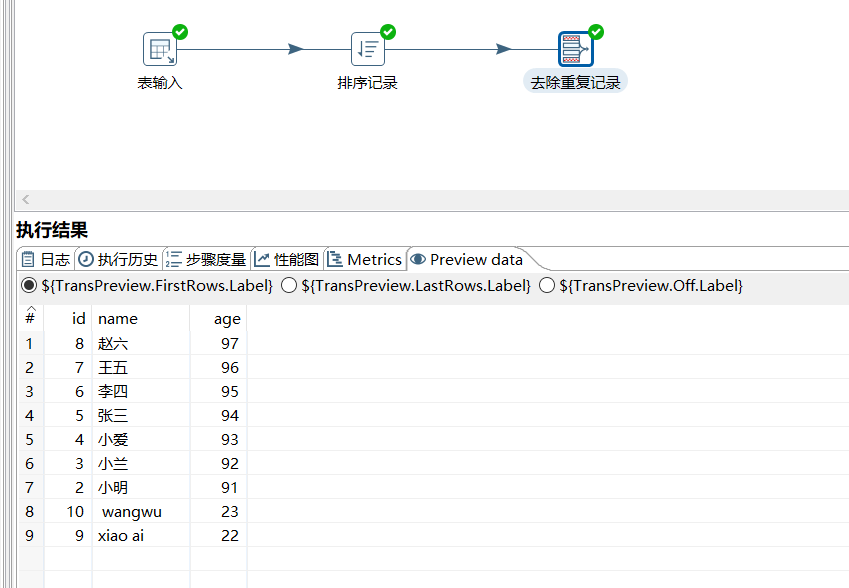
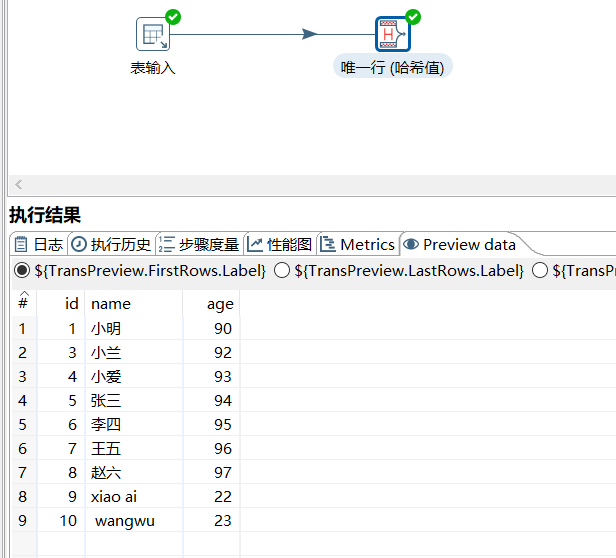
2.12 唯一行 (哈希值)
根据哈希值只允许保留一行,同样可以实现去重的效果:
运行后预览数据:
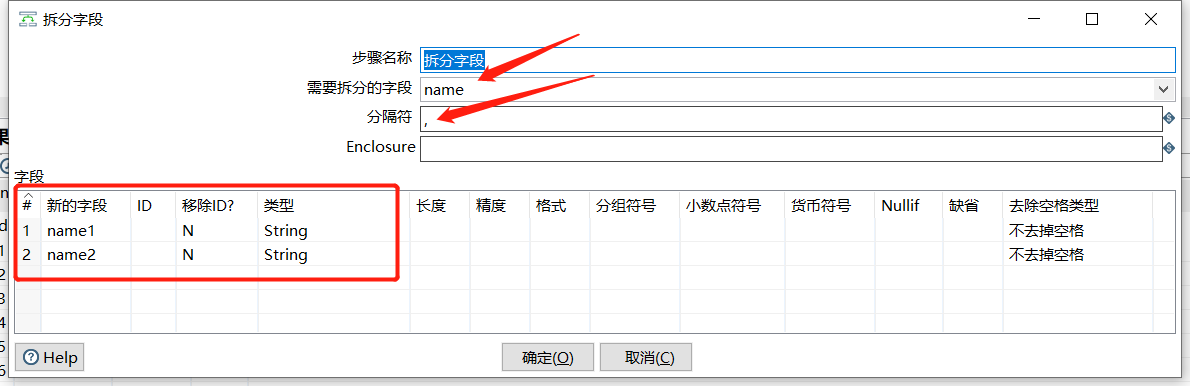
2.13 拆分字段
把字段按照分隔符拆分成两个或多个字段,需要注意,字段拆分后,原字段就会从数据流中消失:
再添加两条测试数据:
INSERT INTO `test`.`user`(`id`, `name`, `age`) VALUES (11, '小王,小七', 22);
INSERT INTO `test`.`user`(`id`, `name`, `age`) VALUES (12, '小八,小九', 23);
运行后预览数据:
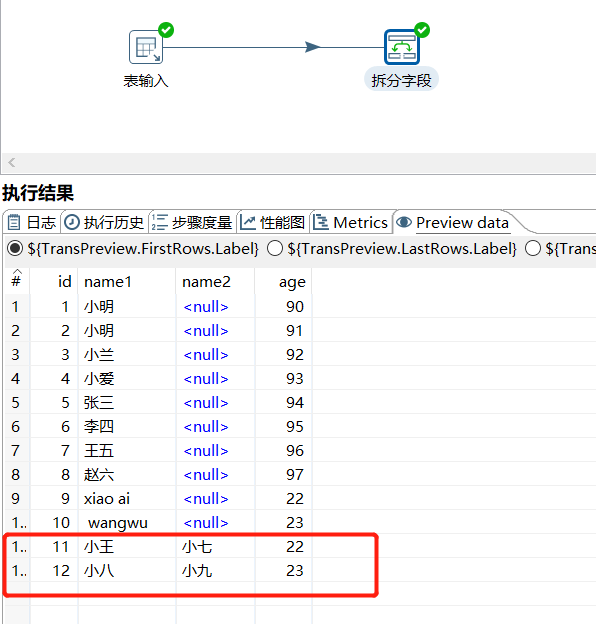
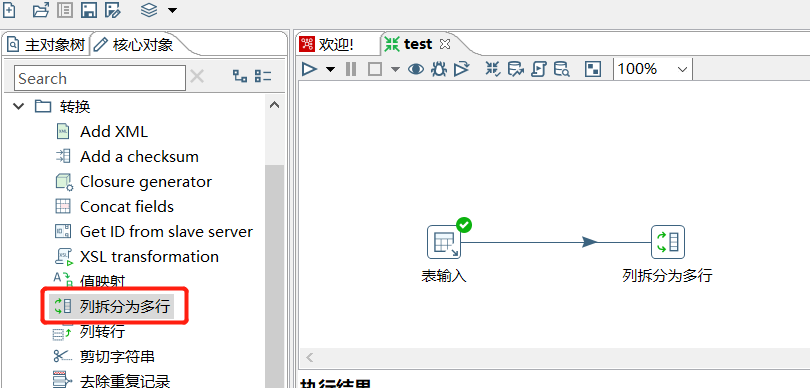
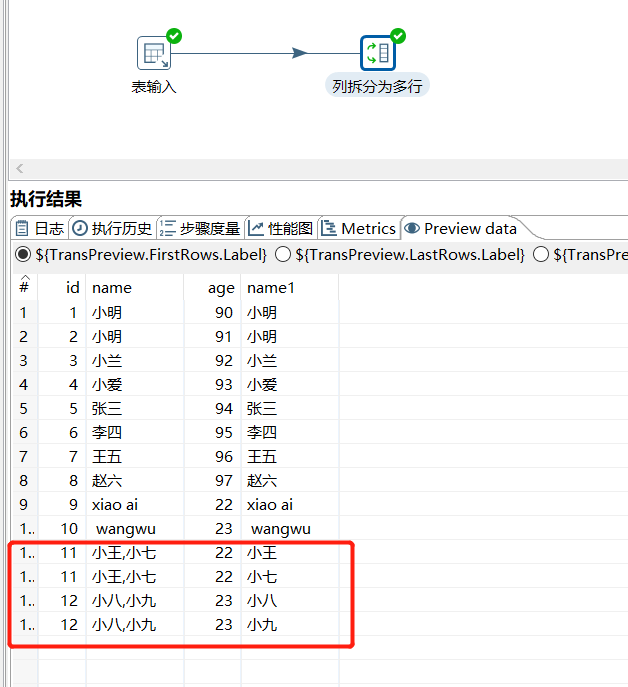
2.14 列拆分为多行
某个字段根据指定分隔符进行拆分成多行,其他字段相同:
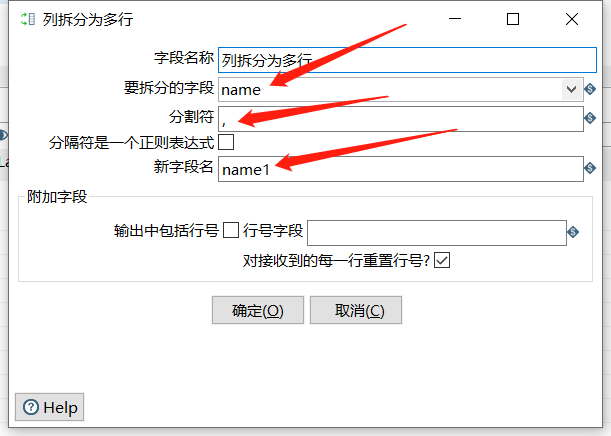
运行后预览数据:
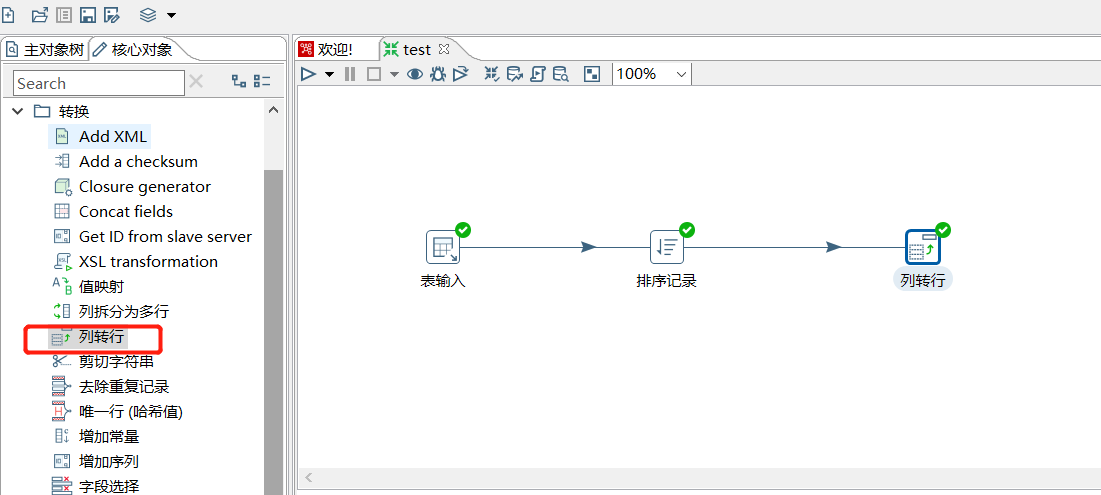
2.15 列转行
多列转一行,如果数据一列有相同的值,可以按照指定的字段,将其中一列的字段内容变成不同的列字段,列转行之前数据流必须按照分组字段进行排序,否则数据会错乱:
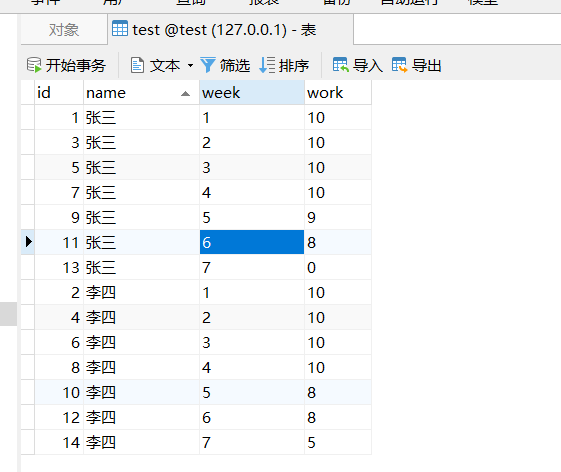
创建新测试表:
CREATE TABLE `test` (`id` int NOT NULL AUTO_INCREMENT,`name` varchar(255) DEFAULT NULL,`week` varchar(255) DEFAULT NULL,`work` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
写入测试数据:
INSERT INTO `test`.`test`(`id`, `name`, `week`, `work`) VALUES (1, '张三', '1', '10');
INSERT INTO `test`.`test`(`id`, `name`, `week`, `work`) VALUES (3, '张三', '2', '10');
INSERT INTO `test`.`test`(`id`, `name`, `week`, `work`) VALUES (5, '张三', '3', '10');
INSERT INTO `test`.`test`(`id`, `name`, `week`, `work`) VALUES (7, '张三', '4', '10');
INSERT INTO `test`.`test`(`id`, `name`, `week`, `work`) VALUES (9, '张三', '5', '9');
INSERT INTO `test`.`test`(`id`, `name`, `week`, `work`) VALUES (11, '张三', '6', '8');
INSERT INTO `test`.`test`(`id`, `name`, `week`, `work`) VALUES (13, '张三', '7', '0');
INSERT INTO `test`.`test`(`id`, `name`, `week`, `work`) VALUES (2, '李四', '1', '10');
INSERT INTO `test`.`test`(`id`, `name`, `week`, `work`) VALUES (4, '李四', '2', '10');
INSERT INTO `test`.`test`(`id`, `name`, `week`, `work`) VALUES (6, '李四', '3', '10');
INSERT INTO `test`.`test`(`id`, `name`, `week`, `work`) VALUES (8, '李四', '4', '10');
INSERT INTO `test`.`test`(`id`, `name`, `week`, `work`) VALUES (10, '李四', '5', '8');
INSERT INTO `test`.`test`(`id`, `name`, `week`, `work`) VALUES (12, '李四', '6', '8');
INSERT INTO `test`.`test`(`id`, `name`, `week`, `work`) VALUES (14, '李四', '7', '5');
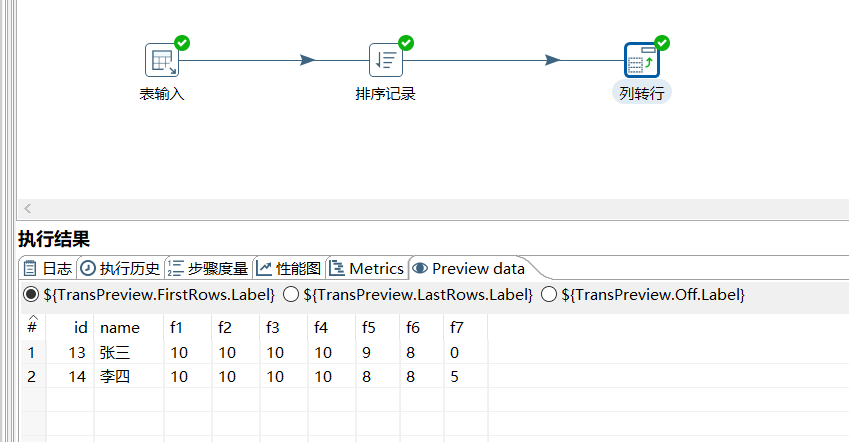
下面根据 name 分组后 week 的值转为列展示 work 字段:
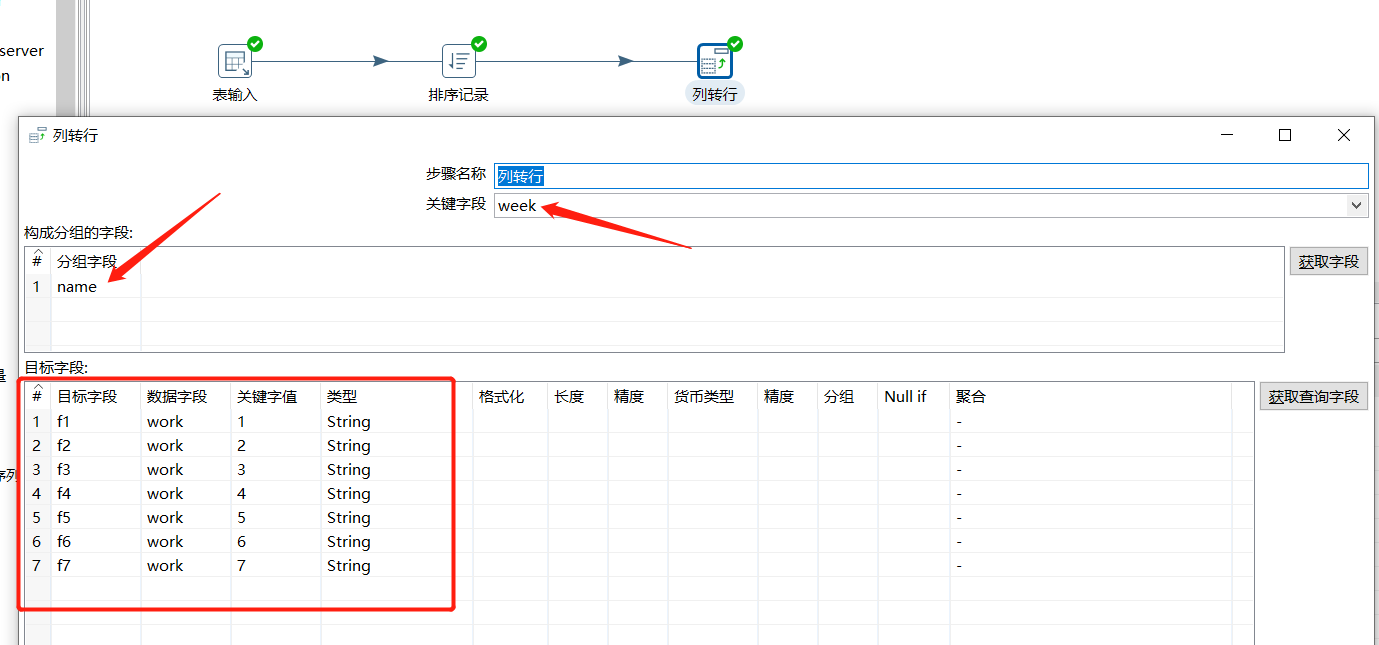
运行后预览数据:
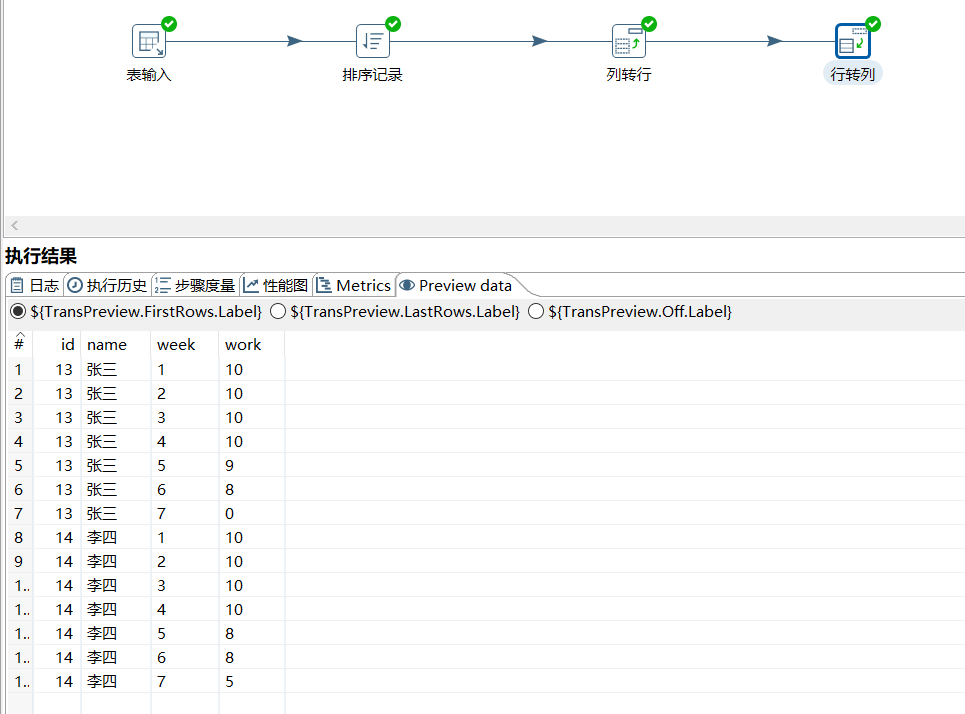
2.16 行转列
和上一个控件相反,将数据行变为数据列,下面将上一步处理的还原会最初的效果:
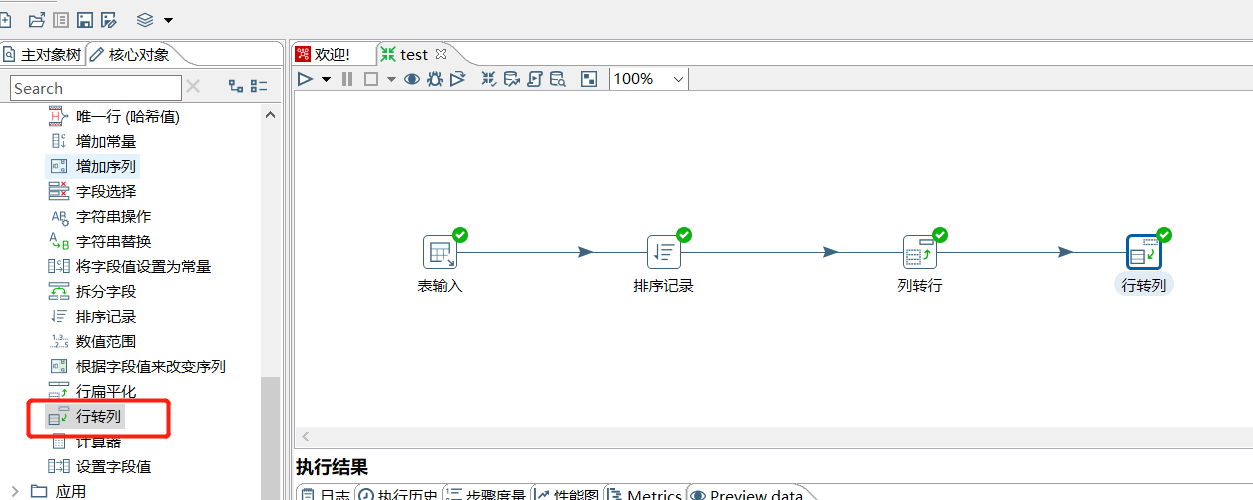
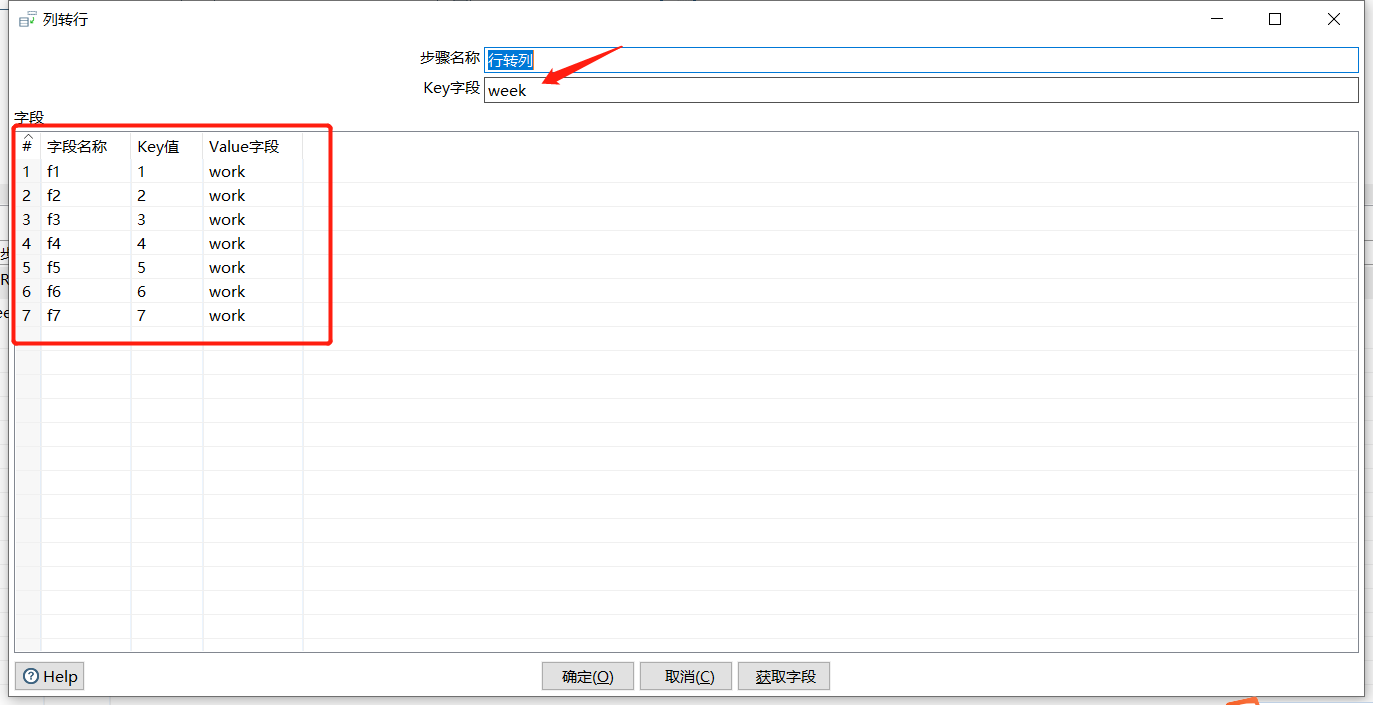
运行后预览数据:
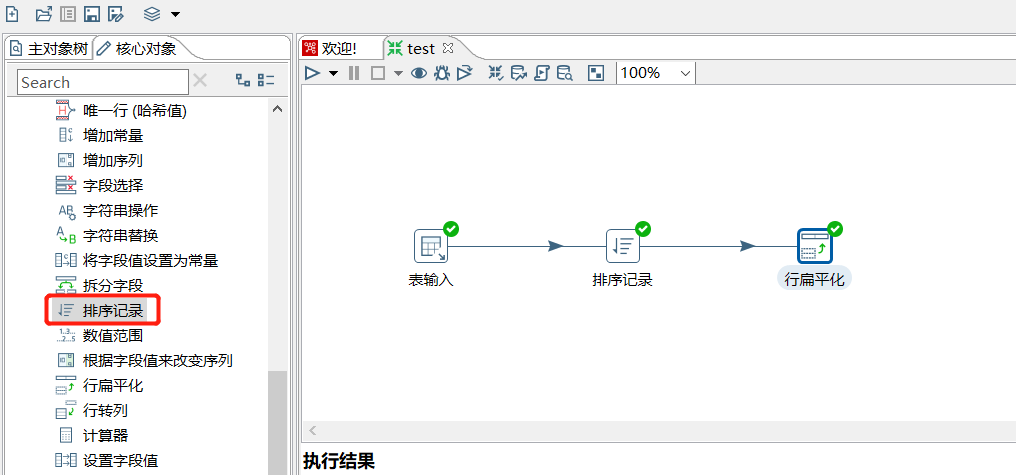
2.17 行扁平化
把同一组的多行数据合并成为一行,使用之前需要对数据进行排序,每个分组的数据条数要保证一致,否则数据会有错乱:
创建新的测试表:
CREATE TABLE `user3` (`id` int NOT NULL AUTO_INCREMENT,`name` varchar(255) DEFAULT NULL,`grade` int DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=20 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
写入测试数据:
INSERT INTO `test`.`user3`(`id`, `name`, `grade`) VALUES (11, '小明', 90);
INSERT INTO `test`.`user3`(`id`, `name`, `grade`) VALUES (12, '小明', 91);
INSERT INTO `test`.`user3`(`id`, `name`, `grade`) VALUES (13, '小明', 96);
INSERT INTO `test`.`user3`(`id`, `name`, `grade`) VALUES (14, '小兰', 90);
INSERT INTO `test`.`user3`(`id`, `name`, `grade`) VALUES (15, '小兰', 88);
INSERT INTO `test`.`user3`(`id`, `name`, `grade`) VALUES (16, '小兰', 60);
INSERT INTO `test`.`user3`(`id`, `name`, `grade`) VALUES (17, '李四', 70);
INSERT INTO `test`.`user3`(`id`, `name`, `grade`) VALUES (18, '李四', 71);
INSERT INTO `test`.`user3`(`id`, `name`, `grade`) VALUES (19, '李四', 72);
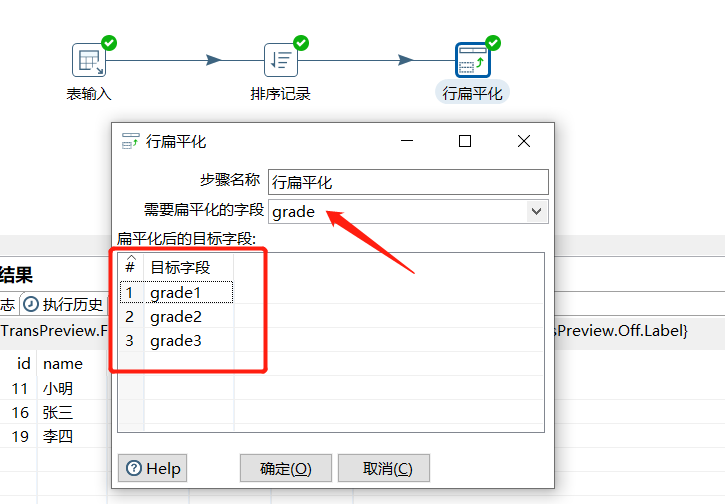
运行后预览数据:

相关文章:
ETL工具 - Kettle 转换算子介绍
一、Kettle 转换算子 上篇文章对 Kettle 中的输入输出算子进行了介绍,本篇文章继续对转换算子进行讲解。 下面是上篇文章的地址: ETL工具 - Kettle 输入输出算子介绍 转换是ETL里面的T(Transform),主要做数据转换&am…...

界面设计的读书笔记
所见即所得,属于绝大多数的人。 所想即所想,属于极少数的人。 当复杂度,超出了大脑的负荷,人会觉得很累,直到放弃追求。 地图的显示,必须有足够多的描述性的数据。 点信息 :标签,位…...
C#底层库--自定义进制转换器(可去除特殊字符,非Convert.ToString方式)
系列文章 C#底层库–程序日志记录类 本文链接:https://blog.csdn.net/youcheng_ge/article/details/124187709 C#底层库–MySQLBuilder脚本构建类(select、insert、update、in、带条件的SQL自动生成) 本文链接:https://blog.csd…...

Doris(24):Doris的函数—聚合函数
1 APPROX_COUNT_DISTINCT(expr) 返回类似于 COUNT(DISTINCT col) 结果的近似值聚合函数。 它比 COUNT 和 DISTINCT 组合的速度更快,并使用固定大小的内存,因此对于高基数的列可以使用更少的内存。 select city,approx_count_distinct(user_id) from site_visit group by c…...

干货! ICLR:将语言模型绑定到符号语言中个人信息
点击蓝字 关注我们 AI TIME欢迎每一位AI爱好者的加入! ╱ 作者简介╱ 承洲骏 上海交通大学硕士生,研究方向为代码生成,目前在香港大学余涛老师的实验室担任研究助理。 个人主页:http://blankcheng.github.io 谢天宝 香港大学一年级…...
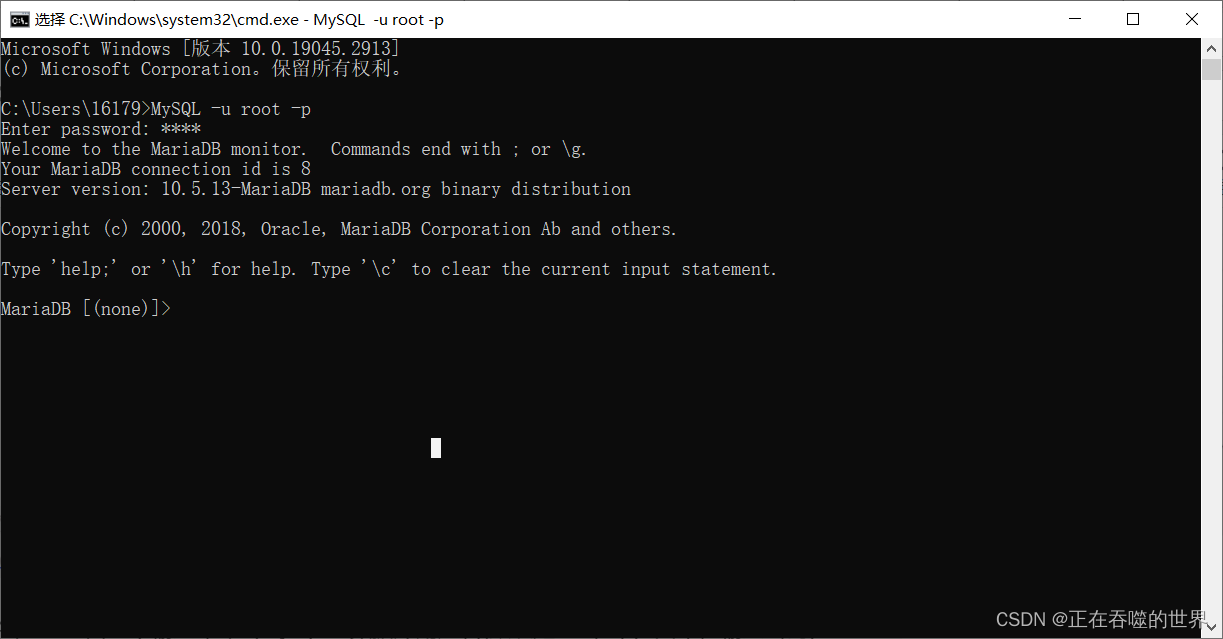
Windows安装mariadb,配置环境变量(保姆级教学)
软件下载地址:https://mariadb.com/downloads/ 1.双击下载好的软件 2.点击next 3.勾选我同意,点击next 4.这里那你可以设置你要安装的路径,也可以使用默认的,之后点击next 5.如图所示,设置完点击next 6.接下来就默…...
)
华为OD机试 - 积木最远距离(Python)
题目描述 小华和小薇一起通过玩积木游戏学习数学。 他们有很多积木,每个积木块上都有一个数字,积木块上的数字可能相同。 小华随机拿一些积木挨着排成一排,请小薇找到这排积木中数字相同且所处位置最远的2块积木块,计算他们的距离,小薇请你帮忙替她解决这个问题。 输入描…...

关于对于springcloud中的注册中心和consume消费者和provier服务者之间的关系理解
关于对于springcloud中的注册中心和consume消费者和provier服务者之间的关系理解 pringCloud provider(服务提供方) consumer(服务调用方) server(注册中心) 运行原理 Provider 第一步 provider注册到se…...

【学习笔记】「JOISC 2022 Day1」错误拼写
久违的字符串计数题。 显然只用考虑 [ i : j ] [i:j] [i:j]这一段拼成的串。不难得出结论:设 n x t i nxt_i nxti表示 i i i之后第一个本质不同的字符的位置,那么 n x t i ≤ j nxt_i\le j nxti≤j,并且 s i ? s n x t i s_i?s_{nxt_i…...
码出高效:Java开发手册笔记(线程池及其源码)
码出高效:Java开发手册笔记(线程池及其源码) 码出高效:Java开发手册笔记(线程池及其源码) 码出高效:Java开发手册笔记(线程池及其源码)前言一、线程池的作用线程的生命周…...
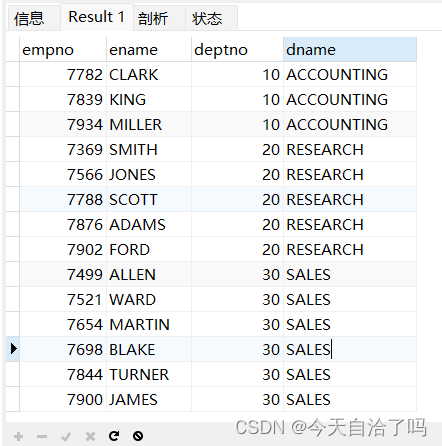
【MySQL】交叉连接、自然连接和内连接查询
一、引入 实际开发中往往需要针对两张甚至更多张数据表进行操作,而这多张表之间需要使用主键和外键关联在一起,然后使用连接查询来查询多张表中满足要求的数据记录。一条SQL语句查询多个表,得到一个结果,包含多个表的数据。效率高…...

长/短 链接/轮询 和websocket
短连接和长连接 短连接: http协议底层基于socket的tcp协议,每次通信都会新建一个TCP连接,即每次请求和响应过程都经历”三次握手-四次挥手“优点:方便管理缺点:频繁的建立和销毁连接占用资源 长连接: 客…...

数据库的事务
数据库的事务 1、事务是什么 TRANSACTION(事务)是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。 2、事务可以做什么 数据库事务通常包含了一个序列的对数据库的读/写操作。包含有以下两个目的: …...

专利进阶(二):专利撰写常用技术及算法汇总(持续更新中)
文章目录 一、前言二、常用技术及算法2.1 区跨链技术2.2 聚类算法2.3 边缘算法2.4 蚁群算法2.4.1 路径构建2.4.2 信息素更新 2.5 哈希算法2.5.1 常见算法 2.6 数字摘要2.72.82.92.10 三、拓展阅读 一、前言 专利撰写过程中使用已有技术或算法解决新问题非常常见,本…...
C#手术麻醉临床信息系统源码,实现体征数据自动采集绘制
手麻系统源码,自动生成电子单据 基于C# 前端框架:Winform后端框架:WCF 数据库:sqlserver 开发的手术麻醉临床信息系统源码,应用于医院手术室、麻醉科室的计算机软件系统。该系统针对整个围术期,对病人进…...

现代CMake高级教程 - 第 7 章:变量与缓存
双笙子佯谬老师的【公开课】现代CMake高级教程课程笔记 第 7 章:变量与缓存 重复执行 cmake -B build 会有什么区别? ❯ cmake -B build -- The C compiler identification is GNU 11.3.0 -- The CXX compiler identification is GNU 11.3.0 -- Detec…...

SQL知识汇总
什么时候用存储过程合适 当一个事务涉及到多个SQL语句时或者涉及到对多个表的操作时就要考虑用存储过程;当在一个事务的完成需要很复杂的商业逻辑时(比如,对多个数据的操作,对多个状态的判断更改等)要考虑;…...
区位码-GB2312
01-09区为特殊符号 10-15区为用户自定义符号区(未编码) 16-55区为一级汉字,按拼音排序 56-87区为二级汉字,按部首/笔画排序 88-94区为用户自定义汉字区(未编码) 特殊符号 区号:01 各类符号 0 1 2 3 4 …...
文本识别、截图识别保存和多文件识别
一、源码 github源码 二、介绍 采用Tesseract OCR识别 采用多线程进行图片识别 界面 选择 文件是可以识别本地的多张图片文件夹是识别文件夹里面的所有图片的内容截图 可以复制到剪切板、可以识别也可以直接保存 重置 是清除选择的图片和识别结果语言选择 是选择不同的模型…...
针对近日ChatGPT账号大批量封禁的理性分析
文 / 高扬 这两天不太平。 3月31号,不少技术圈的朋友和我闲聊说,ChatGPT账号不能注册了。 我不以为然,自己有一个号足够了,并不关注账号注册的事情。 后面又有不少朋友和我说ChatGPT账号全部不能注册了,因为老美要封锁…...

rust-rdkafka社区生态与最佳实践:知名项目使用案例分享
rust-rdkafka社区生态与最佳实践:知名项目使用案例分享 【免费下载链接】rust-rdkafka A fully asynchronous, futures-based Kafka client library for Rust based on librdkafka 项目地址: https://gitcode.com/gh_mirrors/ru/rust-rdkafka rust-rdkafka是…...

软考高级信息系统项目管理师备考笔记-第14章项目沟通管理
第14章项目沟通管理备考知识点及历年真题 一、历年真题分布 2023年5月 选择题3分 案例6分 2023年11月 选择题3分 案例5分第一批、案例10分第二批 2024年5月 选择题3分 案例16分第一批 2025年5月 选择题2分 案例4分第一批、案例9分第二批 二、备考学习笔记 14.1 …...

终极指南:Windows上无需模拟器安装安卓应用的完整教程
终极指南:Windows上无需模拟器安装安卓应用的完整教程 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上运行安卓应用,但厌倦了…...

OAI 5G核心网搭建后,如何用Docker命令进行日常运维和故障排查?
OAI 5G核心网Docker运维实战:从日志分析到故障排查 当OAI 5G核心网完成基础部署后,真正的挑战才刚刚开始。面对由多个容器组成的复杂系统,如何快速定位AMF拒绝注册的原因?SMF的PDU会话建立失败该如何排查?本文将分享一…...

终极指南:如何通过AKShare金融数据接口库快速获取全球交易所数据
终极指南:如何通过AKShare金融数据接口库快速获取全球交易所数据 【免费下载链接】akshare AKShare is an elegant and simple financial data interface library for Python, built for human beings! 开源财经数据接口库 项目地址: https://gitcode.com/gh_mirr…...

Arcgis制图进阶:比例尺参数深度解析与实战样式定制
1. 比例尺参数配置的核心逻辑 比例尺在ArcGIS中远不止是一个简单的标注工具,它直接影响地图的专业性和信息传达效率。我经手过上百个制图项目,发现90%的比例尺问题都源于对参数逻辑理解不透彻。比例尺参数系统其实是一个精密的视觉计算器,它…...
)
别只盯着YOLOv5了!从R-CNN到DETR:手把手带你看懂目标检测算法演进史(附论文精读笔记)
从R-CNN到DETR:目标检测算法的范式革命与技术演进 当计算机视觉领域的研究者翻开2023年的顶会论文时,会发现目标检测任务已经呈现出与五年前截然不同的技术图景。这个看似"古老"的计算机视觉基础任务,正在经历着从传统卷积到Transf…...

面向非技术人员的AI智能体实战:零代码自动化工作流构建指南
1. 项目概述:面向非工程师的AI智能体实战训练营如果你是一名市场、销售、运营或行政人员,每天被重复性的文档处理、数据分析、内容制作和跨平台沟通所淹没,看着工程师同事用代码自动化一切,自己却只能手动操作,那么你很…...

OBS Source Record插件完全掌握指南:实现多源独立录制的终极解决方案
OBS Source Record插件完全掌握指南:实现多源独立录制的终极解决方案 【免费下载链接】obs-source-record 项目地址: https://gitcode.com/gh_mirrors/ob/obs-source-record 你是否曾经在直播或录制视频时,想要单独保存某个特定的画面源…...

告别云服务器:手把手教你用QEMU在Ubuntu 18.04上搭建专属内核调试环境
从零构建QEMU内核调试环境:Ubuntu 18.04下的UEFI开发实战手册 当深夜的调试灯亮起,你是否还在为云服务器高昂的费用和网络延迟苦恼?本文将带你用一台普通Ubuntu机器,打造媲美物理机的内核开发环境。不同于常规教程,我…...