Mysql为json字段创建索引的两种方式
目录
- 一、前言
- 二、通过虚拟列添加索引(Secondary Indexes and Generated Columns)
- 三、多值索引(Using multi-valued Indexes)
- 四、官网地址
一、前言
JSON 数据类型是在mysql5.7版本后新增的,同 TEXT,BLOB 字段一样,JSON 字段不允许直接创建索引。即使支持,实际意义也不大,因为我们一般是基于文档中的元素进行查询,很少会基于整个 JSON 文档。基于此问题,在MySQL 8.0.17及以后的版本中,InnoDB存储引擎支持JSON数组上的多值索引。除此之外还可以通过MySQL 5.7 引入的虚拟列,然后在虚拟列当中使用索引。
二、通过虚拟列添加索引(Secondary Indexes and Generated Columns)
- InnoDB支持在虚拟生成的列上建立二级索引。不支持其他索引类型(主键索引)。在虚拟列上定义的二级索引有时也称为“
虚拟索引”。 - 二级索引可以在一个或多个虚拟列上创建,也可以在虚拟列与常规列或存储生成列的组合上创建。包含虚拟列的二级索引可以定义为
UNIQUE。 - 当在虚拟列上使用辅助索引时,由于在
INSERT和UPDATE操作期间在辅助索引(辅助又叫二级索引)记录中实现虚拟列值时执行计算,因此需要考虑额外的写成本。即使有额外的写成本,虚拟列上的二级索引也可能比生成的存储列更可取,生成的存储列在集群索引中具体化,从而导致需要更多磁盘空间和内存的更大的表。如果没有在虚拟列上定义二级索引,则会产生额外的读取成本,因为每次检查列的行时都必须计算虚拟列值。
关于什么是二级索引:https://blog.csdn.net/weixin_43888891/article/details/126073266
语法:ALTER TABLE 表名称 add column 虚拟列名称 虚拟列类型 GENERATED ALWAYS as (表达式) [VIRTUAL | STORED];
MySQL 在处理 虚拟列存储问题的时候有两种方式:
- VIRTUAL(默认):不存储列值,在读取表的时候自动计算并返回,不消耗任何存储,这种存储方式仅 InnoDB 支持设置索引。
- STORED:在插入或更新时计算存储列值,存储的虚拟列需要存储空间,并且 MyISAM 也可以设置索引。
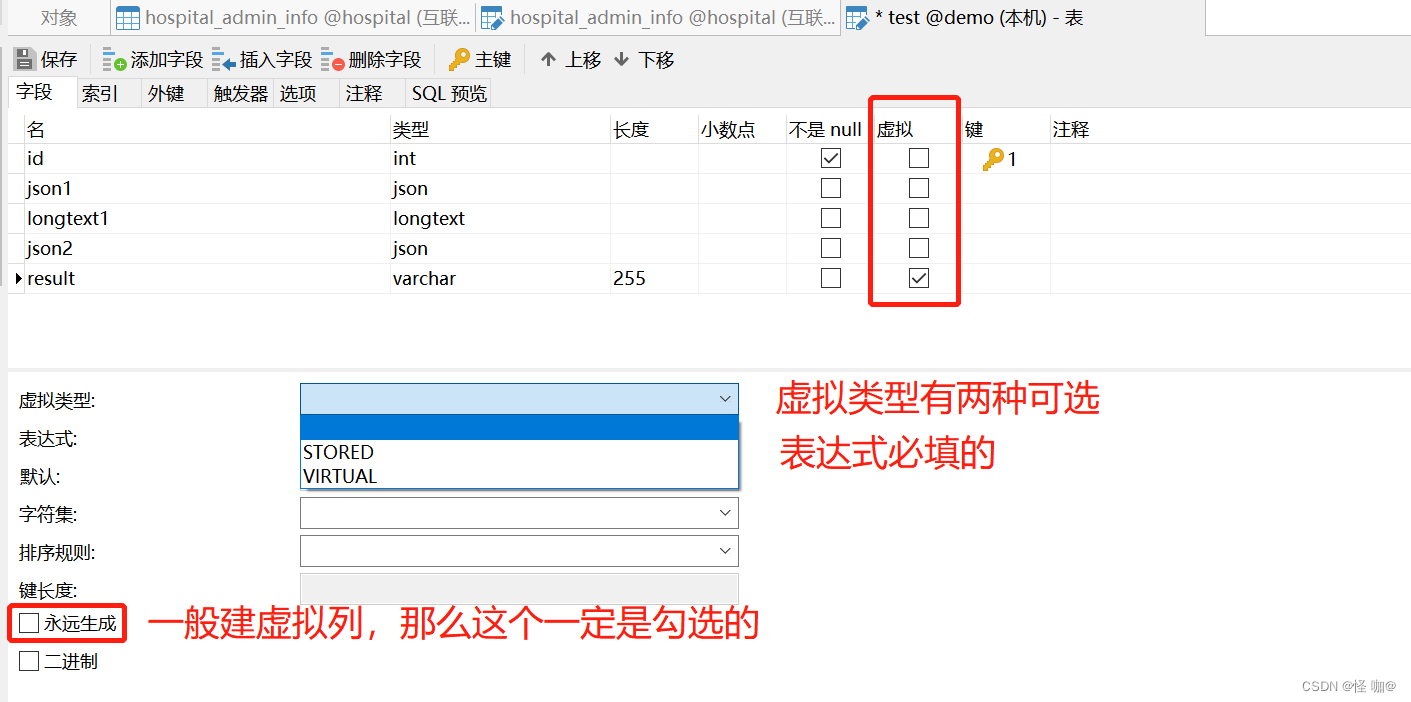
创建虚拟列可以在创建表的时候指定也可以在创建表过后指定。
如下示例就是通过创建表的时候指定的虚拟列,通过(c->"$.id")表达式创建 了一个虚拟列g,并且对虚拟列g创建了索引,通过以下执行计划可以看出索引在查询 的时候已经生效了。
mysql> CREATE TABLE jemp (-> c JSON,-> g INT GENERATED ALWAYS AS (c->"$.id"),-> INDEX i (g)-> );
Query OK, 0 rows affected (0.28 sec)mysql> INSERT INTO jemp (c) VALUES> ('{"id": "1", "name": "Fred"}'), ('{"id": "2", "name": "Wilma"}'),> ('{"id": "3", "name": "Barney"}'), ('{"id": "4", "name": "Betty"}');
Query OK, 4 rows affected (0.04 sec)
Records: 4 Duplicates: 0 Warnings: 0mysql> SELECT c->>"$.name" AS name FROM jemp WHERE g > 2;
+--------+
| name |
+--------+
| Barney |
| Betty |
+--------+
2 rows in set (0.00 sec)mysql> EXPLAIN SELECT c->>"$.name" AS name FROM jemp WHERE g > 2\G
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: jemppartitions: NULLtype: range
possible_keys: ikey: ikey_len: 5ref: NULLrows: 2filtered: 100.00Extra: Using where
1 row in set, 1 warning (0.00 sec)mysql> SHOW WARNINGS\G
*************************** 1. row ***************************Level: NoteCode: 1003
Message: /* select#1 */ select json_unquote(json_extract(`test`.`jemp`.`c`,'$.name'))
AS `name` from `test`.`jemp` where (`test`.`jemp`.`g` > 2)
1 row in set (0.00 sec)
EXPLAIN执行计划解析:

SHOW WARNINGS可以显示上一个命令的警告信息,以及真正执行的sql语句。
->>等价于json_unquote(json_extract())
在MySQL 8.0.21及更高版本中,还可以使用
JSON_VALUE()函数在JSON列上创建索引,该函数带有一个表达式,可用于优化使用该表达式的查询。
三、多值索引(Using multi-valued Indexes)
多值的索引从MySQL 8.0.17开始,InnoDB支持多值索引。多值索引是在存储值数组的列上定义的二级索引。“普通”索引对每个数据记录有一个索引记录(1:1)。一个多值索引对于一个数据记录(N:1)可以有多个索引记录。多值索引用于索引JSON数组。
例如,在下面的JSON文档中,我们要对zipcode添加一个索引:
{"user":"Bob","user_id":31,"zipcode":[94477,94536]
}
三种创建多值索引的方式: CREATE TABLE, ALTER TABLE, or CREATE INDEX
方式一:CREATE TABLE
CREATE TABLE customers (id BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,modified DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,custinfo JSON,INDEX zips( (CAST(custinfo->'$.zipcode' AS UNSIGNED ARRAY)) )
);
方式二:ALTER TABLE
语法:ALTER TABLE customers ADD INDEX idx_mv_custinfo_list( ( CAST( custinfo -> '$.key' AS UNSIGNED array ) ) );
注意:这里在CAST语法外面有两层单括号!,如果少写一个会报错!
CREATE TABLE customers (id BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,modified DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,custinfo JSON
);ALTER TABLE customers ADD INDEX zips( (CAST(custinfo->'$.zipcode' AS UNSIGNED ARRAY)) );
方式三:CREATE INDEX
CREATE INDEX zips ON customers ( (CAST(custinfo->'$.zipcode' AS UNSIGNED ARRAY)) );
准备好测试数据,然后使用上面任意一种方式创建出来索引:
INSERT INTO customers
VALUES( NULL, NOW(), '{"user":"Jack","user_id":37,"zipcode":[94582,94536]}' ),( NULL, NOW(), '{"user":"Jill","user_id":22,"zipcode":[94568,94507,94582]}' ),( NULL, NOW(), '{"user":"Bob","user_id":31,"zipcode":[94477,94507]}' ),( NULL, NOW(), '{"user":"Mary","user_id":72,"zipcode":[94536]}' ),( NULL, NOW(), '{"user":"Ted","user_id":56,"zipcode":[94507,94582]}' );
想要多值索引生效的条件是 where条件下使用了以下三个函数:
- MEMBER OF():查看数组是否有某个元素,如果有则该函数返回 1,否则返回 0。
语法:元素 value MEMBER OF(json_array) - JSON_CONTAINS():该函数用于检验指定 JSON 文档是否包含在目标 JSON 文档中,或者是否在目标文档的指定路径上找到指定元素(如果提供了 path参数)。如果指定 JSON 文档包含在目标 JSON 文档中,该函数返回 1,否则返回 0。
语法:JSON_CONTAINS(target, candidate[, path]) - JSON_OVERLAPS():该函数用于比较两个 JSON 文档。如果两个文档具有共同的键值对(key-value)或数组元素(不要求全部一样,只要一个键值对一样就可以),则返回 1,否则返回 0。
语法:JSON_OVERLAPS(json_doc1, json_doc2)
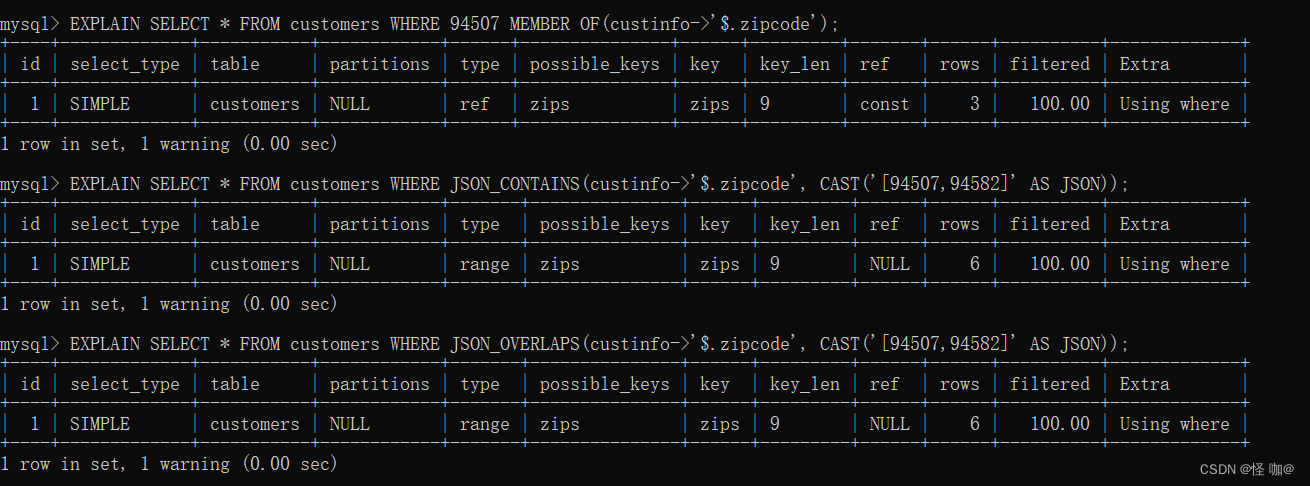
EXPLAIN SELECT * FROM customers WHERE 94507 MEMBER OF(custinfo->'$.zipcode');EXPLAIN SELECT * FROM customers WHERE JSON_CONTAINS(custinfo->'$.zipcode', CAST('[94507,94582]' AS JSON));EXPLAIN SELECT * FROM customers WHERE JSON_OVERLAPS(custinfo->'$.zipcode', CAST('[94507,94582]' AS JSON));
执行结果如下,可以看到是使用了索引的:
使用的时候需要注意的:
- 多值索引可以定义为唯一键,不能作为主键,和外键。
- 可以作为组合索引使用
- 不支持utf8mb4编码配合utf8mb4_0900_as_cs排序规则使用,不支持默认的二进制排序规则和字符集。
- 多值索引不能是覆盖索引。
- 不能为多值索引定义索引前缀。
覆盖索引:索引是高效找到行的一个方法,当能通过检索索引就可以读取想要的数据,那就不需要再到数据表中读取行了。如果一个索引包含了(或覆盖了)满足查询语句中字段与条件的数据就叫 做覆盖索引。
前缀索引:所谓前缀索引说白了就是对文本的前几个字符建立索引(具体是几个字符在建立索引时指定),这样建立起来的索引更小,所以查询更快。这有点类似于 Oracle 中对字段使用 Left 函数来建立函数索引,只不过 MySQL 的这个前缀索引在查询时是内部自动完成匹配的,并不需要使用 Left 函数。
那么为什么不对整个字段建立索引呢?一般来说使用前缀索引,可能都是因为整个字段的数据量太大,没有必要针对整个字段建立索引,前缀索引仅仅是选择一个字段的部分字符作为索引,这样一方面可以节约索引空间,另一方面则可以提高索引效率,当然很明显,这种方式也会降低索引的选择性。
四、官网地址
关于虚拟列索引官网叙述:https://dev.mysql.com/doc/refman/8.0/en/create-table-secondary-indexes.html#json-column-indirect-index
关于多值索引官网叙述:https://dev.mysql.com/doc/refman/8.0/en/create-index.html#create-index-multi-valued
相关文章:
Mysql为json字段创建索引的两种方式
目录 一、前言二、通过虚拟列添加索引(Secondary Indexes and Generated Columns)三、多值索引(Using multi-valued Indexes)四、官网地址 一、前言 JSON 数据类型是在mysql5.7版本后新增的,同 TEXT,BLOB …...

cassandra数据库入门-4
插入数据 在表中创建数据 您可以使用命令 INSERT 将数据插入表中一行的列中。 下面给出了在表中创建数据的语法。 INSERT INTO <tablename> (<column1 name>, <column2 name>....) VALUES (<value1>, <value2>....) USING <option> 例子…...
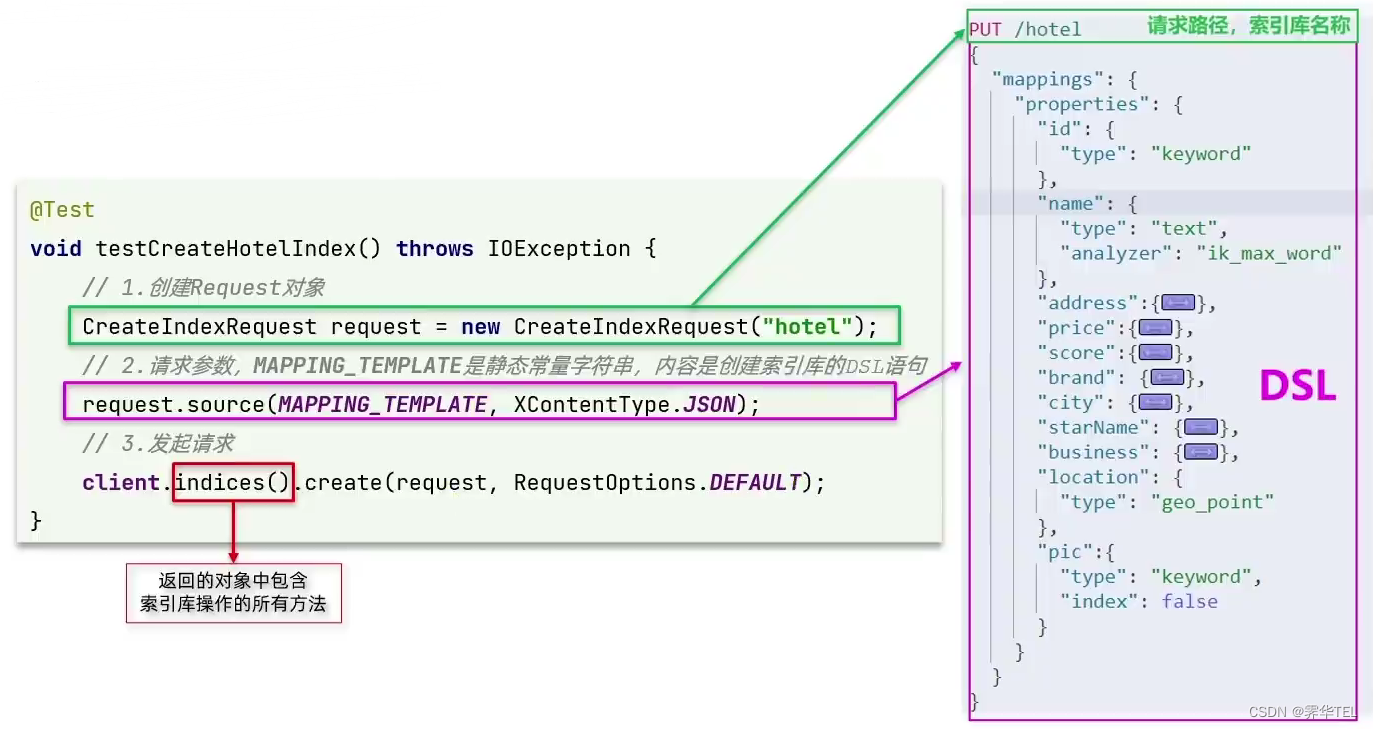
微服务学习——分布式搜索
初识elasticsearch 什么是elasticsearch elasticsearch是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容。 elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域…...
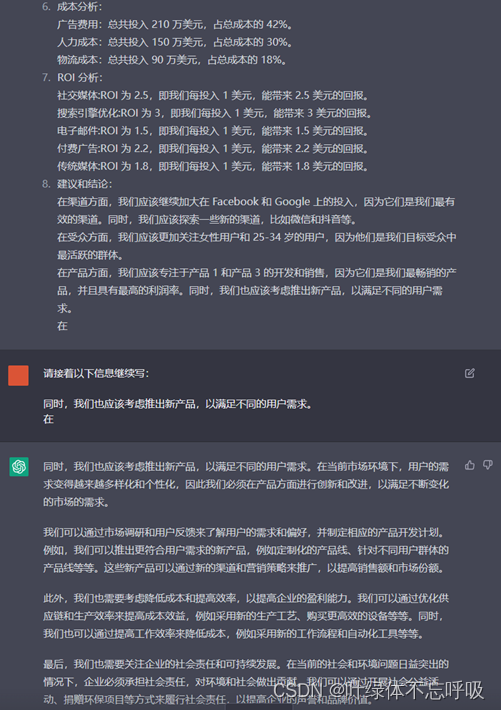
ChatGPT根据销售数据、客户反馈、财务报告,自动生成报告,并根据不同利益方的需要和偏好进行调整?
该场景对应的关键词库(24个): 汇报对象身份(下属、跨部门平级、领导)、销售数据(销售额、销售量、销售渠道)、财务报告(营业收入、净利润、成本费用)、市场分析…...
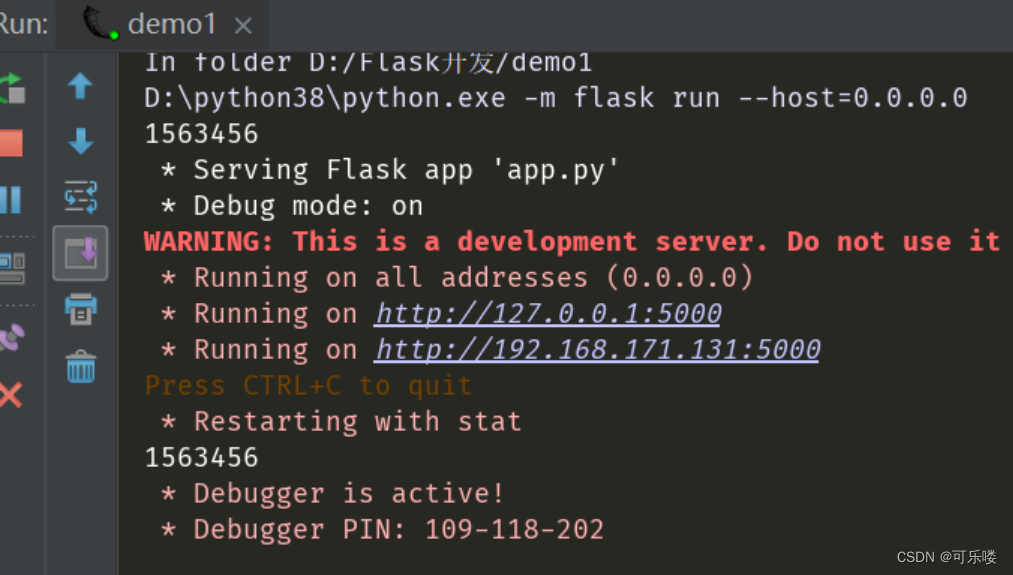
Flask开发之环境搭建
目录 1、安装flask 2、创建Flask工程 编辑 3、初始化效果 4、运行效果 5、设置Debug模式 6、设置Host 7、设置Port 8、在app.config中添加配置 1、安装flask 如果电脑上从没有安装过flask,则在命令行界面输入以下命令: pip install flask 如果电…...

Java集合框架与ArrayList、LinkedList的区别
文章目录 Java集合框架与ArrayList、LinkedList的区别集合框架ArrayList特点操作 LinkedList特点操作 区别代码实践注意事项 Java集合框架与ArrayList、LinkedList的区别 在Java中,集合框架是非常重要的一部分。集合框架提供了各种数据结构和算法,可以方…...

python-pandas库
目录 目录 目录 1.pandas库简介(https://www.gairuo.com/p/pandas-overview) 2.pandas库read_csv方法(https://zhuanlan.zhihu.com/p/340441922?utm_mediumsocial&utm_oi27819925045248) 1.pandas库简介(http…...
C++学习day--01 C生万物
1、C/C学习中遇到的问题: 1. 大部分初学者,学习 C/C 都是从入门到放弃。 C/C太难吗? 2. 90% 以上的初学者,学完 C/C 以后,考试完了,书看完了, 但还是不会做项目 是学的不够好吗࿱…...

链表及链表的常见操作和用js封装一个链表
最近在学数据结构和算法,正好将学习的东西记录下来,我是跟着一个b站博主学习的,是使用js来进行讲解的,待会也会在文章后面附上视频链接地址,大家想学习的可以去看看 本文主要讲解单向链表,双向链表后续也会…...

源码安装工具checkinstall使用
每当从源码包编译程序时,安装过程很愉快,但当你想删除时,就很费脑筋了,你可能要去找你当时编译的目录执行make unistall,当然更可能的是,你早就把源码包给删除了,对于强迫症来说,这显…...
离散数学集合论
集合论 主要内容 集合基本概念 属于、包含幂集、空集文氏图等 集合的基本运算 并、交、补、差等 集合恒等式 集合运算的算律,恒等式的证明方法 集合的基本概念 集合的定义 集合没有明确的数学定义 理解:由离散个体构成的整体称为集合,…...

TypeScript 基础
类型注解 类型注解:约束变量的类型 示例代码: let age:number 18 说明:代码中的 :number 就是类型注解 解释:约定了类型,就只能给变量赋值该类型的值,否则,就会报错 错误演示:…...

MySQL InnoDB引擎 和 Oracle SGA
MySQL InnoDB引擎和Oracle SGA有以下异同: 异同点: 两者都是用来管理数据存储和访问的。 它们都可以通过调整参数来优化性能。 它们都支持事务处理和ACID属性。 它们都可以通过备份和恢复来保护数据。 异点: MySQL InnoDB引擎是一种存储…...
JAVA开发与运维(web生产环境部署)
web生产环境部署,往往是分布式,和开发环境或者测试环境我们一般使用单机不同。 一、部署内容 1、后端服务 2、后台管理系统vue 3、小程序 二、所需要服务器 5台前端服务器 8台后端服务 三、所需要的第三方组件 redismysqlclbOSSCDNWAFRocketMQ…...

普通人,自学编程,5个必备步骤
天给大家分享个干货哈 普通人自学编程 想学成找到一份工作甚至进大厂 非常有效且必备的5个步骤 文章最后 还给大家提供了一些免费的学习资料 记得提前收藏起来 相信很多人在最开始学编程的时候 上来就是去网上找一套视频 或者买一本书直接开干 这种简单粗暴的方法其实是不对的 …...

kubernetes安全框架RBAC
目录 一、Kubernetes 安全概述 二、鉴权、授权和准入控制 2.1 鉴权(Authentication) 2.2 授权(Authorization) 2.3 准入控制 三、基于角色的权限访问控制: RBAC 四、案例:为指定用户授权访问不同命名空间权限 一、Kubernetes 安全概述 K8S安全控…...
)
【大数据面试题大全】大数据真实面试题(持续更新)
【大数据面试题大全】大数据真实面试题(持续更新) 1)Java1.1.Java 中的集合1.2.Java 中的多线程如何实现1.3.Java 中的 JavaBean 怎么进行去重1.4.Java 中 和 equals 有什么区别1.5.Java 中的任务定时调度器 2)SQL2.1.SQL 中的聚…...

Linux [常见指令 (1)]
Linux常见指令 ⑴ 1. 操作系统1.1什么事操作系统1.2选择指令的原因 2.使用工具3.Linux的指令操作3.1mkdir指令描述:用法:例子 mkdir 目录名例子 mkdir -p 目录1/ 目录2/ 目录3 3.2 touch指令描述:用法:例子 touch 文件 3.2pwd指令描述:用法:例子 pwd 3.4cd指令描述:用法:例子 c…...
进程控制下篇
进程控制下篇 1.进程创建 1.1认识fork / vfork 在linux中fork函数时非常重要的函数,它从已存在进程中创建一个新进程。新进程为子进程,而原进程为父进程 #include<unistd.h> int main() {pid_t i fork;return 0; }当前进程调用fork,…...

PS学习笔记(零基础PS学习教程)
很多新手学习PS不知从何下手,做设计的第一阶段肯定是打牢基础,把工具用熟练;本期特别为大家整理了PS入门的学习笔记,把每个工具的用法整理了下来,在使用过程中有哪里不清楚的可以翻看来看看~ 一、ps的工作界面的介绍 …...

iPhone 5s系统工程解析:LPDDR3内存与E2NAND存储的协同进化
1. 项目概述:iPhone 5s,一场被低估的系统性工程胜利2013年9月,当苹果发布iPhone 5s时,聚光灯几乎全部打在了那个划时代的64位A7处理器上。媒体和消费者的讨论都围绕着“桌面级性能”和“移动计算新时代”展开。作为一名在消费电子…...
:超出3个指标即触发强制重构——你达标了吗?)
DeepSeek Clean Code终极阈值(v2.3.1正式版):超出3个指标即触发强制重构——你达标了吗?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Clean Code终极阈值的演进与哲学内核 DeepSeek Clean Code 的“终极阈值”并非静态指标,而是代码可维护性、语义清晰度与执行确定性三者动态收敛的临界点。它源于对 LLM 推理链中 …...

IGF-I Analog ;CYAAPLKPALSSC
一、基础信息多肽名称:IGF-I Analog 胰岛素样生长因子 I 类似物 三字母序列:Cys-Tyr-Ala-Ala-Pro-Leu-Lys-Pro-Ala-Lys-Ser-Cys 单字母序列:CYAAPLKPALSSC 氨基酸数量:12 aa 结构修饰:分子内二硫键 二硫键配对…...

微软创新者窘境:从J的离开看大公司如何留住颠覆性人才
1. 从“J”的离去看微软的“创新者窘境”2010年5月,当微软宣布其娱乐与设备事业部(E&D)的重组,以及J Allard和Robbie Bach两位核心人物的离开时,科技圈的反应是复杂的。表面上看,这是一次常规的高层人事…...
自动做化学实验的机器)
图解人工智能(12)自动做化学实验的机器
近年来,人工智能和传统科学的结合备受瞩目。2019年,英国利物浦大学在《自然》杂志发表论文,介绍了一种可以自动做化学实验的机器人。查找相关资料,并讨论一下类似的工作能给人类社会带来怎样的变革。首先,实验人员的培…...
)
Sora 2与3D Gaussian结合实战指南(工业级部署避坑手册)
更多请点击: https://intelliparadigm.com 第一章:Sora 2与3D Gaussian结合的工业级部署全景图 Sora 2作为OpenAI新一代视频生成模型,在长时序建模与物理一致性方面取得显著突破;而3D Gaussian Splatting(3DGS&#x…...

企业内如何通过 Taotoken 实现 API 访问权限的精细化控制与审计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内如何通过 Taotoken 实现 API 访问权限的精细化控制与审计 当企业将大模型能力引入内部工作流时,如何安全、可控地…...

EmbBERT架构解析:面向TinyML的革新设计与优化
1. EmbBERT架构解析:面向TinyML的革新设计在边缘计算设备上部署自然语言处理模型一直面临内存和计算资源的双重限制。传统BERT模型即使经过压缩,其2MB版本在TinyNLP基准测试中平均准确率仅为83.93%,且激活内存占用高达1.5MB。EmbBERT通过三大…...

限流不是加个计数器就行:用 Lua 脚本实现多维度原子限流
限流不是加个计数器就行:用 Lua 脚本实现多维度原子限流 项目地址:interview-agent 技术栈:Java 21 / Spring Boot 4.0 / Redis 7 (Redisson) / PostgreSQL 问题:单维度限流挡不住真实场景 简历上传接口,你加了一个&q…...

法律AI助手weclaw:基于RAG与领域大模型的智能法律应用实践
1. 项目概述:一个面向法律领域的智能助手 最近在关注一些开源项目,发现了一个挺有意思的,叫 shp-ai/weclaw 。光看这个名字,就能猜个八九不离十——“weclaw”,听起来像是“we”和“law”的结合,指向性非…...