HTTP协议
目录
一、HTTP协议
1.http
2.url
url的组成:
url的保留字符:
3.http协议格式编辑
①http request
②http response
4.对request做出响应
5.GET与POST方法
①GET
②POST
7.HTTP常见Header
①Content-Type:: 数据类型(text/html等)在上文我们使用过。
②Content-Length: 正文的长度。
③Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上。
④User-Agent: 声明用户的操作系统和浏览器版本信息。
⑤referer: 表示当前页面是从哪个页面跳转过来的。
⑥Location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问。
⑦Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能。
一、HTTP协议
1.http
上篇文章我们体验了定制协议的繁琐,这次我们来讲述下真正成熟的有很多人使用的协议,例如:http、https、smtp、dns等。
Http协议:超文本传输协议。
客户端通过使用Http协议来向服务端获取资源。
2.url
我们俗称的“网址”就是url。

协议方案名:上例是http://,表示使用http协议。后面我会讲到https,这是http协议的加密版本,现在多数都使用的都是https。
登录信息:我们这次不考虑,一般会省略掉,在正文中携带登录信息。
服务器地址:是资源所在的网站名或服务器的名字,又称为域名。在网络通信中域名必须被转换为IP地址。
端口号:HTTP 协议的默认端口是80,如果省略了这个参数,服务器就会返回80端口的网站。在上上一篇文章中讲到网络之间的通信就是进程之间的通信,通过域名(IP地址)+端口号的方式就可以在全网中确定唯一一个进程。我们发现一些url会缺省port,一般由浏览器自动添加,而这些url对应的port都是公开的,一旦服务上线端口号就已经确定,httpserver->80,httpsserver->443,sshd->22。
文件路径:资源在服务器的位置。
查询字符串:提供给服务器的额外信息。
片段标识符:也叫做锚点,锚点是网页内部的定位点,浏览器加载页面之后,回滚到锚点锁定位的位置。
url的组成:
26个英文字母 10个阿拉伯数字 连词号(-)句典(.) 下划线(_)
url的保留字符:
有10个保留字符,只能在给定位置出现。
如果在其他位置去使用保留字符,就必须使用转义形式。

其中罗列一部分,都是关于特殊符号的转义,那我要在url中体现汉语怎么办?
我们可以现场搜索一下,见见实际情况。 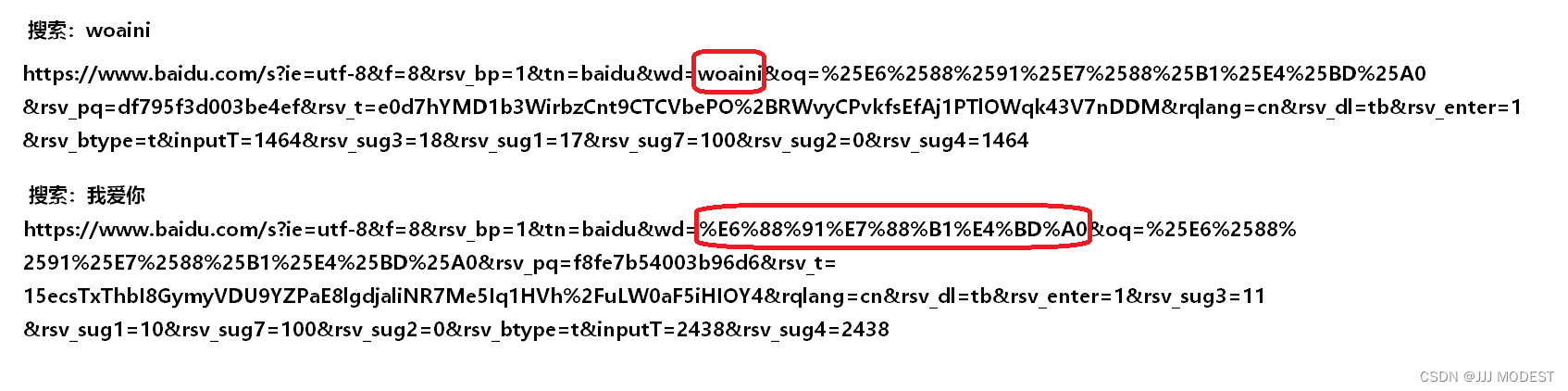
我们会发现汉字也会被转义,转义的规则为:将需要转码的字符转换为16进制,从右到左取四位,每两位做一位,前面加上%,编码成%XY格式。
3.http协议格式
注意:
method为请求方法,常见的get方法、post方法。
key:空格value
http/1.1为当前版本为1.1
现在我们可以通过上节课代码,我们运行server,通过浏览器来访问我们的server,将接收到的东西打印出来,我们就可以真正的见到http request。
①http request
在浏览器中输入你主机的IP地址:你的server绑定的端口号。
 上图中关于服务器版本的信息,当我们换个浏览器使用就会有不同的效果。
上图中关于服务器版本的信息,当我们换个浏览器使用就会有不同的效果。
如图我是用iphone的safari浏览器依据我们的ip与port来访问的。
至于浏览器会表现出如此现象是因为我们做为服务器没有向浏览器响应发送任何东西。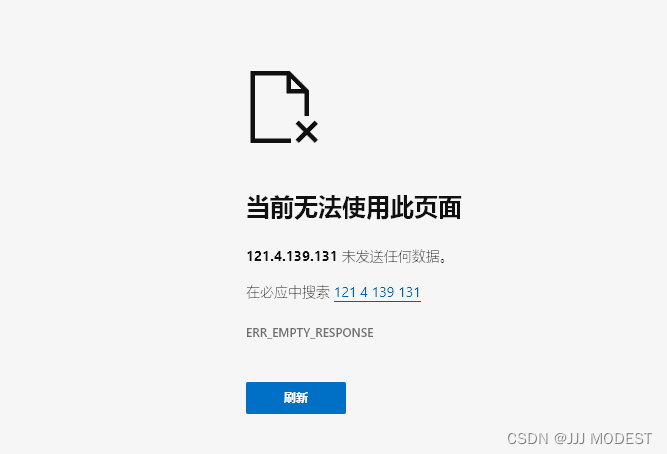
上文的tcpserver的代码是上篇文章写的,很是臃肿,于是我删删减减,得到了simple版本。
void handlerHttpRequest(int sock)
{cout<<"++++++++++++++++++++++++"<<endl;char buffer[1024];ssize_t sz = read(sock, buffer, sizeof(buffer));if (sz > 0){cout << buffer << endl;}
}class Tcpserver
{
public:Tcpserver(uint16_t port, const string &ip = ""): _sock(-1), _port(port), _ip(ip){_quit = false;}~Tcpserver(){if (_sock >= 0)close(_sock);}public:void init(){_sock = socket(AF_INET, SOCK_STREAM, 0);if (_sock < 0){exit(1);}struct sockaddr_in local;memset(&local, 0, sizeof(local));local.sin_family = AF_INET;local.sin_port = htons(_port);_ip.empty() ? INADDR_ANY : (inet_aton(_ip.c_str(), &local.sin_addr));if (bind(_sock, (const sockaddr *)&local, sizeof(local)) < 0){exit(2);}if (listen(_sock, 5) < 0){exit(3);}}void start(){signal(SIGCHLD, SIG_IGN);while (!_quit){struct sockaddr_in peer;socklen_t len = sizeof(peer);int servicesock = accept(_sock, (struct sockaddr *)&peer, &len);if (_quit)break;if (servicesock < 0){cerr << "accept error ..." << endl;continue;}int clientport = ntohs(peer.sin_port);string clientip = inet_ntoa(peer.sin_addr);pid_t pid = fork();assert(pid != -1);if (pid == 0){if (fork() > 0)exit(4);handlerHttpRequest(servicesock);exit(0);}close(servicesock);wait(nullptr);}}void safequit(){_quit = true;}private:int _sock;uint16_t _port;string _ip;// 安全退出bool _quit;
};Tcpserver *svrp = nullptr;
void sighandler(int sig)
{if (sig == 3 && svrp != nullptr)svrp->safequit();cout << "server quit" << endl;
}上文我们可以看到http request的响应代码。接下来我们看一下http response的响应代码。
②http response
接下来,我们可以通过命令行的方式向baidu发送request获得response。
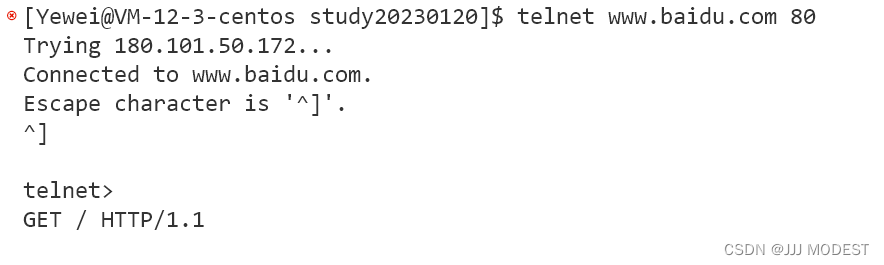
进入telnet后按ctrl+],再按回车输入GET / HTTP/1.1,然后按两下回车。
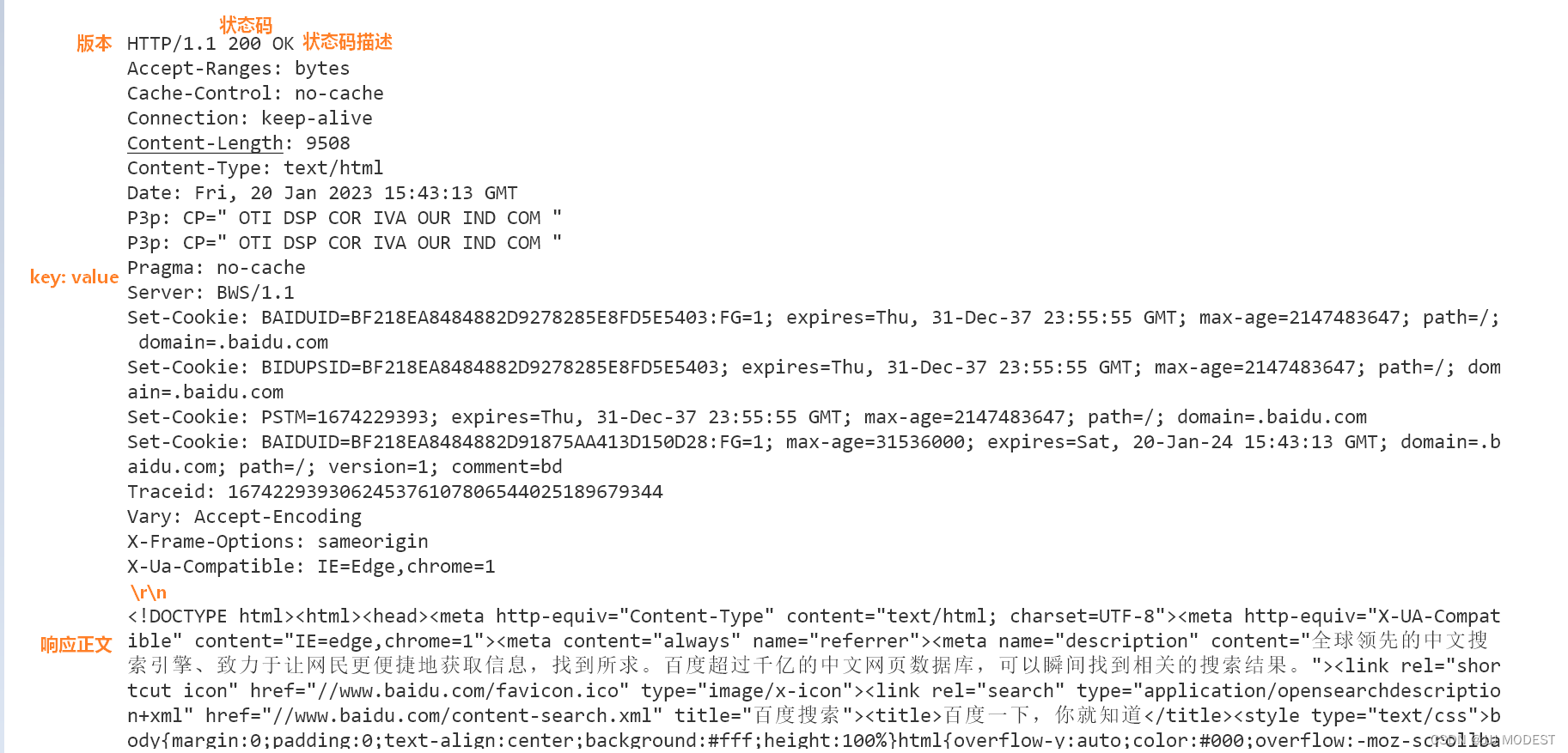
4.对request做出响应
上文我们对浏览器的request并没有做出任何响应,server仅仅是将接收到的http request中的内容,下文我们将对request做出响应。当然不是无所依据的responce,我们可以参照上文百度做出的responce。
这个函数的参数神似我们使用过的write,将flags设置为0,就和write等价。
代码:
void handlerHttpRequest(int sock)
{char buffer[1024];ssize_t sz = read(sock, buffer, sizeof(buffer));if (sz > 0){cout << buffer << endl;}// response string response;response += "HTTP/1.0 200 OK\r\n"; // response请求行response += "\r\n"; // 本行为\r\n为请求报头与正文的分界线 请求报头暂且为空response += "Hello world!"; // 正文send(sock,response.c_str(),response.size(),0);
}结果:

单纯Hello world!有点单一,我们可以让它成为这个网页的大标题,这个工作将由浏览器接收到我们的正文部分然后渲染就可以得到效果了。
代码:
response += "<html><h1>Hello world!</h1></html>"; // 正文
结果:

再次升级,我们将响应报头完善下。
Content-Type 内容类型 指出我们正文所对应的类型。
上文中的正文内容为.html,Content-Type就应该填text/html。
具体的对照类型,可以看这篇博客。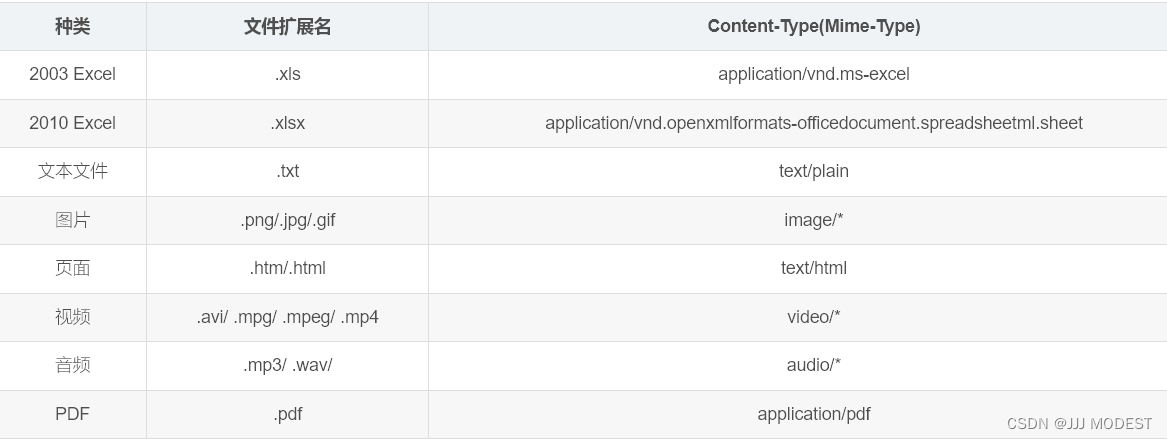
代码:
// response string response;response += "HTTP/1.0 200 OK\r\n"; // response请求行response += "Content-Type: text/html\r\n";response += "\r\n"; // 本行为\r\n为请求报头与正文的分界线 请求报头暂且为空response += "<html><h1>Hello world!</h1></html>"; // 正文
结果跟上文无疑。
如何保证将响应行与响应报头读完整呢?读到空行就可以保证。那如何保证正文读取完整呢?这就是响应报头中的内容来保证的。
Content-Length负责记录正文的长度。
代码:
// responsestring html = "<html><h1>Hello world!</h1></html>";string response;response += "HTTP/1.0 200 OK\r\n"; // response请求行response += "Content-Type: text/html\r\n";response += ("Content-Length: " + to_string(html.size()) + "\r\n");response += "\r\n"; // 本行为\r\n为请求报头与正文的分界线 请求报头暂且为空response += html; // 正文结果:这次通过使用telnet来检验成果,浏览器不会显示。
作为建设服务器的人员将网页构建的代码写到服务器中,是否有点挫,那应该放在什么地方?先前我们在讲url的时候提到过文件路径,由客户端依据文件路径请求资源,服务器依据请求放回资源。所有我们的html等资源都是放在文件里。
至于文件路径是否要从linux根目录中开始写,写到目标文件为止,会写出很长一段文件路径。其实不用,如果客户端要访问a/b/c.html,我们能说a文件就是linux的根目录吗,不能,这是web根目录,具体可以看下方代码。
request = "/a/b/c.html";path = "linux/server/web"; // web根目录path += request; ->linux/server/web/a/b/c.html // 最终的文件路径这次我们将我们的html放在文件中,由客户端申请客户端返回。
我们的主页在当前工作路径下的wwwroot里。
代码:
#define CRLF "\r\n"
#define SPACE " "
#define SPACE_LEN strlen(SPACE)
#define HOME_PAGE "index.html"
#define WEB_ROOT "./wwwroot"// 负责将http_request中的文件路径提取出来
string getPath(string http_request)
{ssize_t pos = http_request.find(CRLF);if (pos == string::npos)return "";string request_line = http_request.substr(0, pos);// GET /a/b/c http/1.1ssize_t firstSpace = request_line.find(SPACE);if (firstSpace == string::npos)return "";ssize_t secondSpace = request_line.rfind(SPACE);if (secondSpace == string::npos)return "";string path = request_line.substr(firstSpace + SPACE_LEN, secondSpace - (firstSpace + SPACE_LEN));if (path.size() == 1 && path[0] == '/')path += HOME_PAGE; // 如果只发了/ ,我们就将我们网址的主页返回过去return path;
}// 负责打开文件将文件的内容读取出来
string readFile(const string &path)
{ifstream in(path, std::ifstream::binary);if (!in.is_open())return "404";string content;string line;while (getline(in, line))content += line;in.close();return content;
}void handlerHttpRequest(int sock)
{char buffer[10240];ssize_t sz = read(sock, buffer, sizeof(buffer));if (sz > 0){cout << buffer;}string path = getPath(buffer);cout << "path->" << path << endl;string resource = WEB_ROOT;resource += path;cout << "resource->" << resource << endl;string html = readFile(resource);string response;response += "HTTP/1.0 200 OK\r\n"; // response请求行response += "Content-Type: text/html\r\n";response += ("Content-Length: " + to_string(html.size()) + "\r\n");response += "\r\n"; // 本行为\r\n为请求报头与正文的分界线 请求报头暂且为空response += html; // 正文send(sock, response.c_str(), response.size(), 0);
}index.html:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>http server</title>
</head>
<body><h3>TEST</h3><p>Hello World!</p>
</body>
</html>telnet中的结果:无论是请求/ 还是/index.html 结果都一样因为我们当前只有一个主页。

web中的结果:

5.GET与POST方法
①GET
下面我们来鉴别POST方法与GET方法的区别。
我们都知道上网的行为一般分两种:
1.从远端获取资源到本地 使用GET方法 //GET / HTTP/1.1
2.将本地的资源上传到远端 可以使用POST方法也可以使用GET方法。
我们这次使用表单将信息填写,然后先用GET方法发送。
代码:
<!DOCTYPE html>
<html><head><meta charset="utf-8"><title>http server</title>
</head><body><h3>TEST</h3><p>Hello World!</p><form action="abc/qwe/index.html" method="get">Username: <input type="text" name="user"><br>Password: <input type="password" name="passwd"><br><input type="submit" value="Submit"></form>
</body></html>
 现象:我们将信息填入点击submit
现象:我们将信息填入点击submit

提交过后会发现会出现404,那是因为网页代码中我们指定将数据提交的网址(abc/qwe/index.html)在服务器中并不存在。

我们主要来分析下当前的url。

我们会发现在HTTP协议中GET方法会以明文的方式 将我们对应的参数信息,拼接到url中。
②POST
下面来看看POST方法。
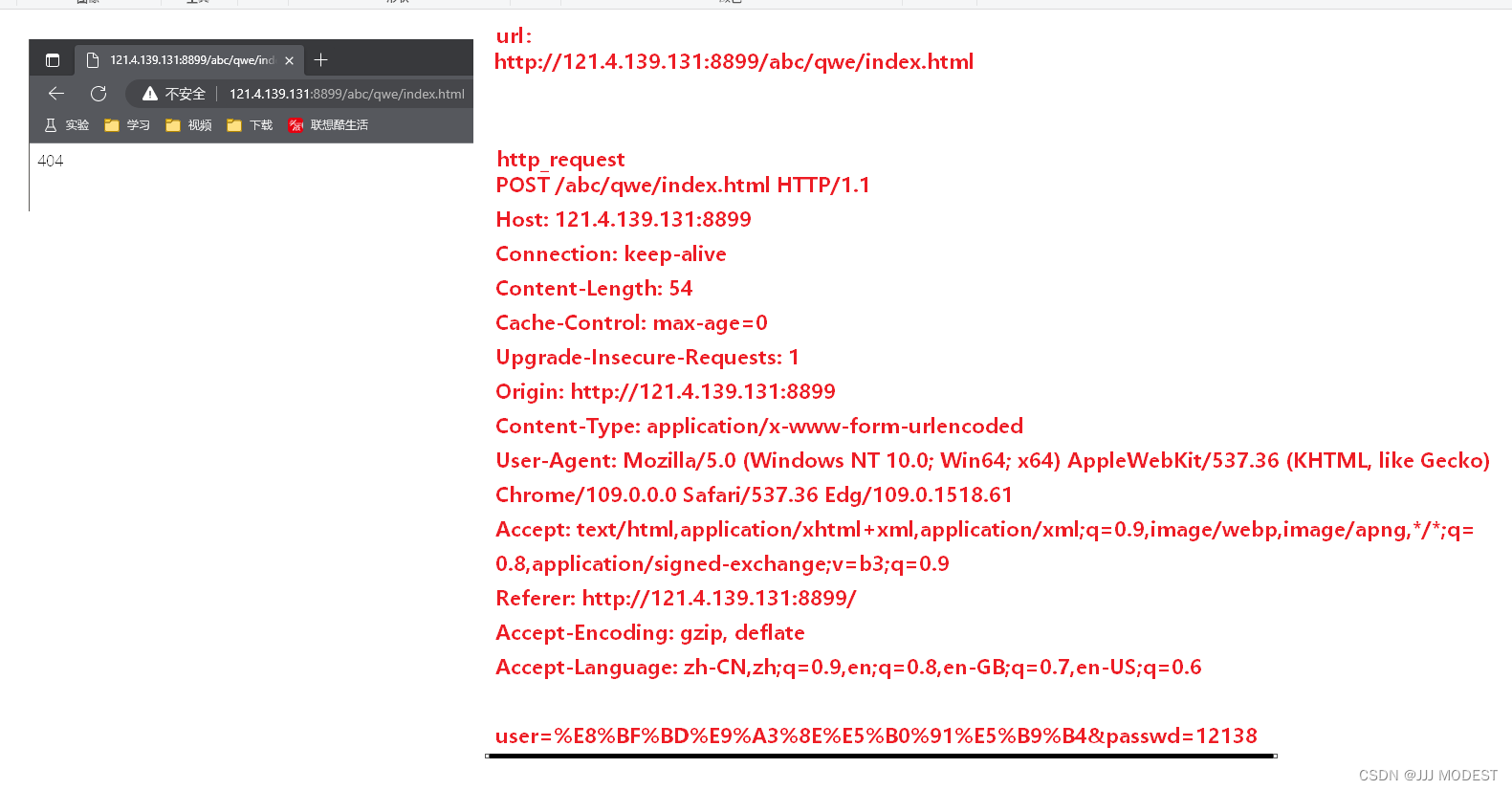
我们会发现GET方法中会将信息拼接在url中,而POST方法不一样,它是将信息拼接到http requset中的正文中。
总结:
1. GET方法通过url传参
2. POST方法通过正文传参
3. GET方法传参不私密
4. POST方法传参通过正文,相对私密。至于为什么不说安全与不安全,HTTP协议在某种角度来说就是不安全的,不管通过GET还是POST方法提交数据都会通过抓包等软件获取到url或者正文,所以说都是不安全的,下面我们会学习HTTPS现在主流安全可靠的协议。
5. 网页中内容较少一般通过GET方法传参,内容较多通过POST方法传参。
6.HTTP状态码
最常见的状态码,比如200(OK),404(Not Found),403(Forbidden),302(Redirect,重定向),504(Bad Gateway)。
我们向服务器申请一个并不存在的资源将会返回什么状态码呢?
会返回4XX,因为客户端申请的资源并不存在,服务器就算穷举也找不到,所以这是客户端出错。
什么时候会返回5XX呢?
客户端申请一些任务,服务器去执行,在其中会申请内存,线程,进程等手段执行任务,当服务器中一些资源到达载荷就会返回5XX。
我们主要研究下3XX。
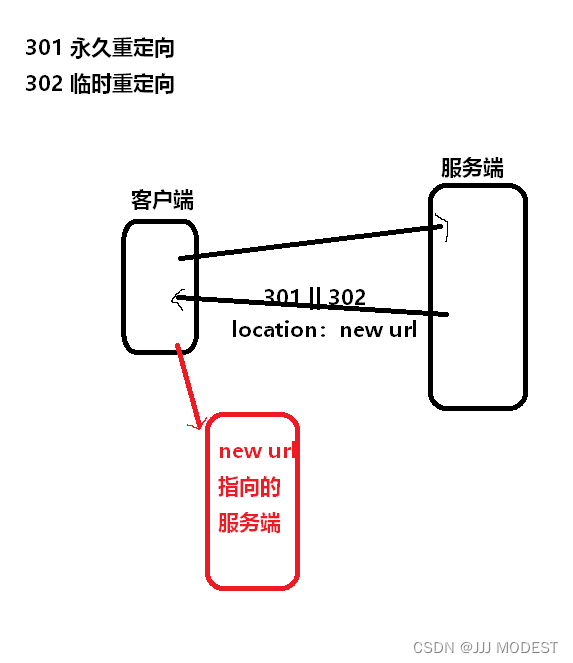
客户端向服务端发起请求,服务端响应中携带301 || 302 和new url,浏览器就会自动跳转到新的服务端去获得资源。
我们通过我们简单的代码,也可以验证下。
代码:
void handlerHttpRequest(int sock)
{char buffer[10240];ssize_t sz = read(sock, buffer, sizeof(buffer));if (sz > 0){cout << buffer;}string response = "HTTP/1.1 302 Moved Temporarily\r\n";response += "Location: www.baidu.com\r\n";response += "\r\n";send(sock, response.c_str(), response.size(), 0);
}现象:
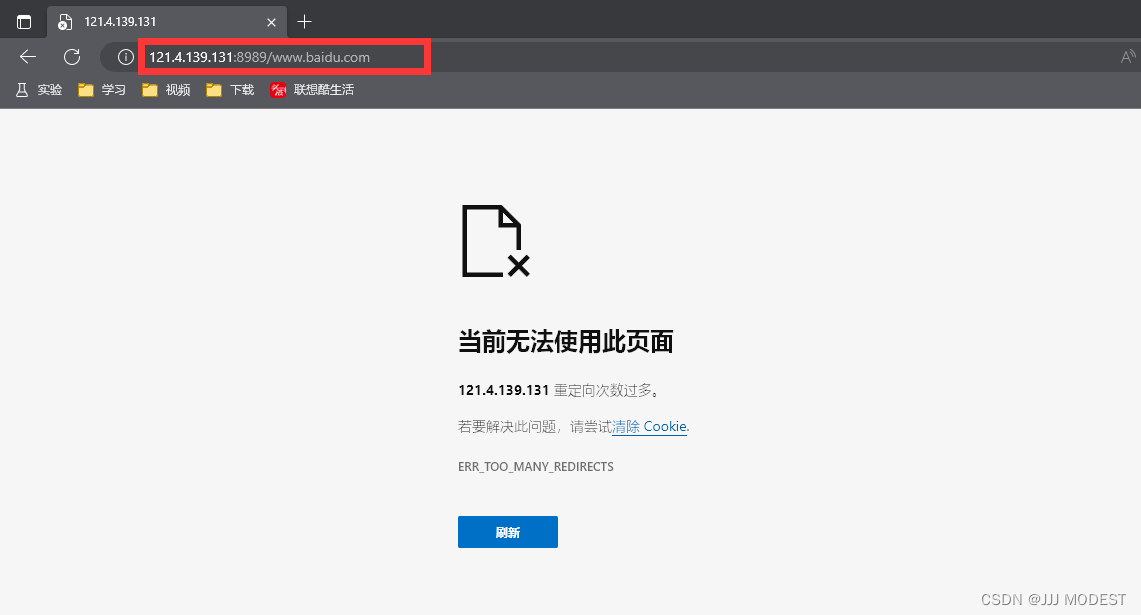
至于为什么没有显示我们重定向之后的页面呢,因为浏览器作为客户端并行的向我们的服务端发送请求,服务端则是向每一个请求都返回重定向,所以会显示出图片中的错误。
当然我们此时也没有完全写对,Location之后一定跟的是网址。写成www.baidu.com只是目前的站内跳转,要实现不同的域也就是服务器跳转,代码要变成:
response += "Location: https://www.baidu.com/\r\n";
现象:将IP地址和端口输入回车之后,就会跳转到我们重定向之后的界面。

什么时候会用到301或者302呢?
301作为永久重定向,一般是在网站更换网址时使用,比如,当时的url取的很随意当想改变跟换一个更好听的时候,会发现当前访问旧网址的人很多,为了避免再换url时损失大量用户,可以在用户访问旧url时,使用永久重定向跳转到新的url。
302作为临时重定向,当该网站临时维护时,不想拒绝访问的用户,可以用到临时重定向使网站跳转到另一个可以提供服务的网站。
7.HTTP常见Header
①Content-Type:: 数据类型(text/html等)在上文我们使用过。
②Content-Length: 正文的长度。
③Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上。
④User-Agent: 声明用户的操作系统和浏览器版本信息。
我们通过Windows环境下的浏览器打开qq的官网观察下载页面,会发现下载页面直接为Windows版本下载。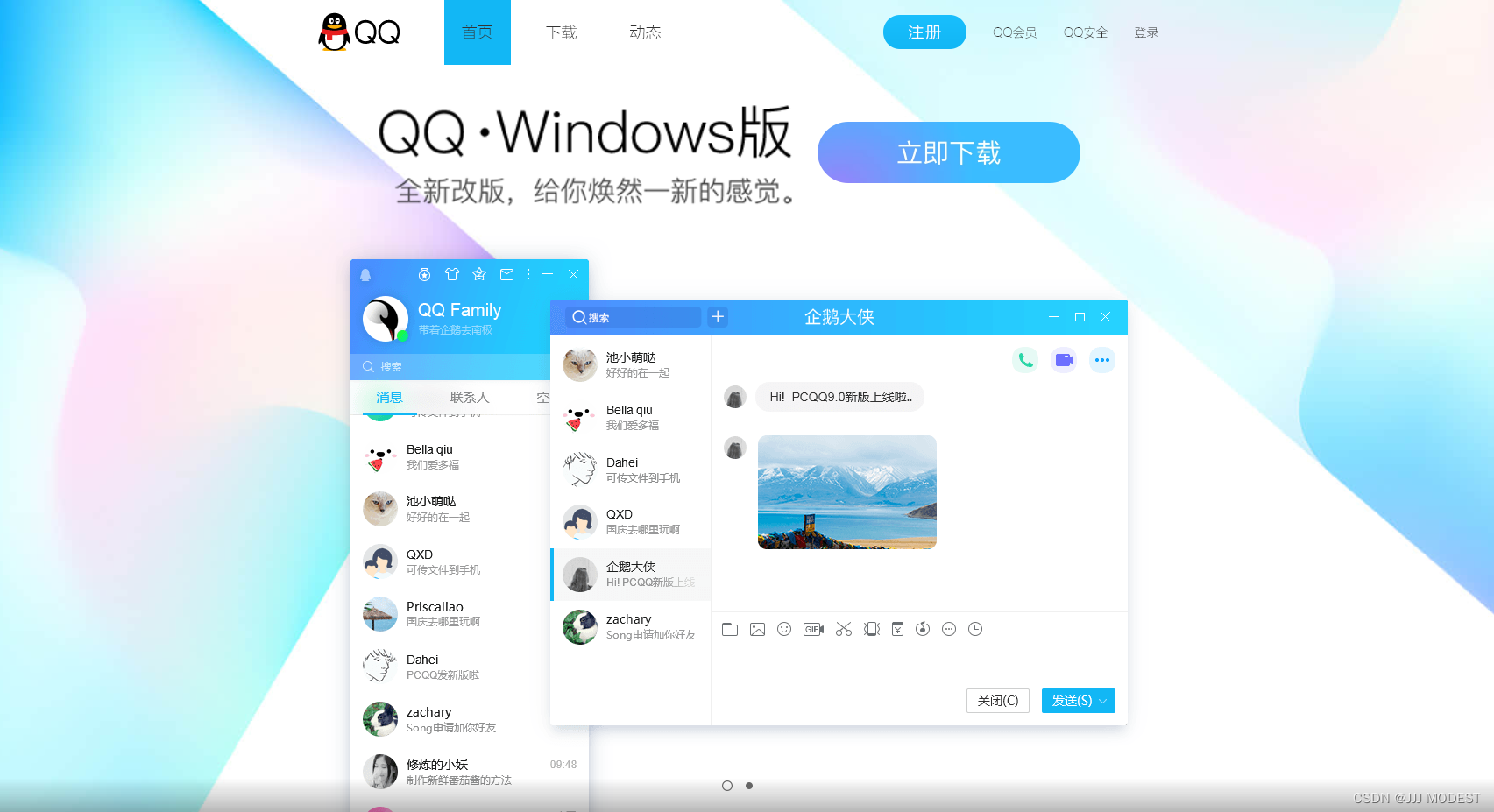
通过手机浏览器打开qq的官网,会发现下载页面会变为qq手机版。

这是依据什么来改变响应界面呢,与User-Agent这个信息密切相关。
⑤referer: 表示当前页面是从哪个页面跳转过来的。
⑥Location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问。
⑦Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能。
在讲Cookie之前我们要知道HTTP协议的特点之一是无状态,什么是无状态呢,简单就是HTTP协议本事并不会记录你请求资源的行为,请求过了再请求HTTP协议本事并不会记录你当前已经请求过了。但是我们当前所知道的浏览记录等信息都是显而易见被记录下来的信息,这些信息都是依靠HTTP周边策略来实现的,比如说Cookie策略。
这个Cookie在哪其作用呢?
像我们每次登入一个常用的网站,关闭之后再次进入,会发现登陆的账号还在保持登陆状态,这就是cookie起了作用,当我们禁止cookie就会发现每次登陆之后关闭再打开,会让你再次登陆,并不会延续你上次登陆的用户。
我们尝试讲Cookie体现在代码中
代码:

现象:

一般流程为我们客户端讲登陆信息输入,登录信息就会被记录到服务器中,当再次访问网站时, 登陆信息就会通过Set-Cookie发送到客户端。
当然Cookie不仅仅是存在于服务端,也有可能存在于浏览器维护的文件中。
我的登录信息这么简单的存储在本地文件中,那木马病毒等不正当手段随便就可以获取我的登陆信息岂不是我的上网安全岌岌可危,所以我们要使用Cookie和Session组合起来的方式来保证安全。
客户端输入登陆信息,然后将登陆信息发给服务端,服务端根据登陆信息形成Session文件,该文件的文件名具有唯一性,该文件名被称为session_id。服务端再将该session_id发给客户端,客户端会将session_id写入本地的cookie中。在cookie中的表现只出现session_id。下次登陆时客户端就会将session_id发送给服务端,服务端依据session_id来判断是否有权利享有对应的资源。
那这个session_id会不会也会被轻易盗取,也是会的,这个问题没有根本解决。但是session_id丢掉之后,你丢掉的只是session_id,你的信息会保存在服务端。大型的服务端有很不错的防护系统。至于更多的知识,感兴趣的同学可以去了解一下更细致的讲解。
关于Cookie和Session的要点:
Cookie的Expires属性指定了cookie的生存期,默认情况下coolie是暂时存在的,他们存储的值只在浏览器会话期间存在,当用户退出浏览器后这些值也会丢失,如果想让cookie存在一段时间,就要为expires属性设置为未来的一个过期日期。现在已经被max-age属性所取代,max-age用秒来设置cookie的生存期。因此当没有设定过期时间时,则退出当前会话时cookie失效。
Session可以存放各种类别的数据,相比只能存储字符串的cookie,能给开发人员存储数据提供很大的便利。
SessionID可以存储每个用户Session的代号,是一个不重复的长整型数字。
单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
目前此篇文章就写到这里,关于HTTPS协议将会在下篇与大家见面,如有错误请指出,感谢观看,我们下次再见。
相关文章:
HTTP协议
目录 一、HTTP协议 1.http 2.url url的组成: url的保留字符: 3.http协议格式编辑 ①http request ②http response 4.对request做出响应 5.GET与POST方法 ①GET ②POST 7.HTTP常见Header ①Content-Type:: 数据类型(text/html等)在上文…...

javafx学习教程
1.舞台,场景,布局,控件,回调 2.舞台:窗口,一个舞台一个窗口,舞台有舞台基础属性,舞台监听事件,做一些回调 3.fxml里面可以写 页面的布局,控件,然…...
百度百科创建词条教程合集分享,赶紧收藏起来
每一个企业、品牌、人物、产品想要提升自己的知名度,都要创建一个属于自己的百度百科词条,互联网时代,百度搜索引擎的地位是不可撼动的,每天都有上亿的用户在百度上搜索相关内容,百度百科词条在网络营销中占据着举足轻…...
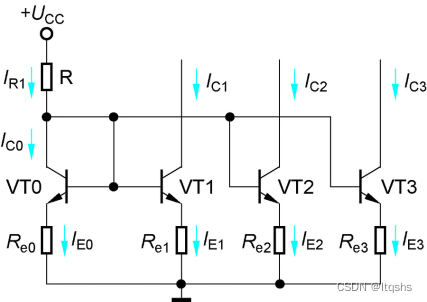
镜像恒流源电路分析
在改进型差动放大器中,用恒流源取代射极电阻RE,既为差动放大电路设置了合适的静态工作电流,又大大增强了共模负反馈作用,使电路具有了更强的抑制共模信号的能力,且不需要很高的电源电压,所以,恒…...

奥威软件宏昊化工启动BI项目,打造智能制造标杆
近日,中国纺织行业领先企业宏昊化工有限公司成功启动了与奥威签订的BI项目,期望通过BI的建立进一步提升企业数字化经营能力和核心竞争力。 奥威bi数据分析软件 在全球经济形势不明朗,国内外市场竞争加剧叠加疫情反复的情况下,化工…...
GitHub访问问题与FastGithub下载及使用(详细篇)
前言 📜 “ 作者 久绊A ” 专注记录自己所整理的Java、web、sql等,IT技术干货、学习经验、面试资料、刷题记录,以及遇到的问题和解决方案,记录自己成长的点滴 目录 前言 FastGithub的介绍 FastGithub的下载 FastGithub的安装及…...

这个打上实时补丁的Linux内核,大家可以看一下
前言最近看到一个关于实时Linux内核的开源项目,是一个比较牛逼的公司发起的,想推荐给大家。Linux的实时性一直是被很多开发者诟病的,一个分时系统怎么能在工业领域发挥自己的长处呢,我认为研究Linux的实时性是非常有必要的&#x…...

三维形体的表面积
三维形体的表面积 在 N * N 的网格上,我们放置一些 1 * 1 * 1 的立方体。 每个值 v grid[i][j] 表示 v 个正方体叠放在对应单元格 (i, j) 上。 请你返回最终形体的表面积。 例子: 输入:[[2,1],[1,0]]输出:18 解题思路࿱…...

二维码数据压缩实践 | 使用python对二维码数据进行压缩 |不乱码,支持中文
当前二维码的应用越来越广泛,包括疫情时期的健康码也是应用二维码的典型案例,最近需要通过一张二维码显示较多文本数据,也就是对二维码数据进行压缩,使用CSDN搜索了半天居然没有能简单使用的代码,很多事例代码解决不了…...
C语言学习_DAY_3_基本数据类型_运算符与表达式【C语言学习笔记】
目录 I. 基本数据类型 II. 复杂的输出和输入语句编写 III. 运算符与表达式 III.I 算术运算符 III.II 关系运算符 III.III 逻辑运算符 III.IV 位运算符 III.V 三目运算符 III.VI 逗号运算符 高质量博主,点个关注不迷路🌸🌸dz…...
)
c++练习题(4)
题号:1 设int a3,b2;则a*b的结果是() A、2 B、7 C、3 D、8 题号:2 一个程序单位中不包括以下哪项() A、伪代码 B、函数 C、预处理指令 D、全局声明 题号:3 若a-14,…...
腾讯云 cos 字体在CDN上跨域处理
问题描述:项目中用到了字体的静态资源,把静态资源放到了腾讯云对象存储提供的 COS 上,同时启用它的CDN来加速。但是,调试的过程中发现报错:CSS加载字体跨域了,字体图标无法正常显示。 原因:字体…...

api是什么意思?又该如何使用呢?
一、应用程序编程接口 API(Application Programming Interface,应用程序编程接口)是一些预先定义的函数,目的是提供应用程序与开发人员基于某软件或硬件的以访问一组例程的能力,而又无需访问源码,或理解内部工作机制的细节。 API全称 "…...
JavaScript------面向对象
目录 一、面向对象编程(OOP) 基本概念 二、类 1、语法 2、通过类创建对象 3、类的属性 4、类的方法 5、构造函数 三、面向对象的三个特点 1、封装 如何确保数据的安全(实现封装的方式): 2、继承 在子类中&a…...

charles+夜神模拟器抓包
1.资料地址: 链接:https://pan.baidu.com/s/1w9qYfFPJcduN4If50ICccw 提取码:a7xa2.安装charles 和夜神模拟器并配置参考地址: https://www.beierblog.com/archives/%E4%BA%B2%E6%B5%8B%E5%AE%8C%E5%85%A8%E5%8F%AF%E8%A1%8Ccharles%E6%8A%93%E5%8C%85%E…...
【STC15单片机】模拟I2C操作AT24C02数据读取【更新中】
目录 I2C时序结构 I2C代码 AT24C02代码(继承I2C底层代码) PCF8591 PCB上线的长短可能影响数据传输的时间,写I2C时序可能就要加一点延时 I2C时序结构 起始条件:SCL高电平期间,SDA从高电平切换到低电平终止条件&…...

Hadoop
Hadoop Hadoop1.x 2.x 3.x区别 Hadoop1.x组成:MapReduce负责计算和资源调度,HDFS负责数据存储,Common辅助工具。 Hadoop2.x组成:MapReduce负责计算,Yarn负责资源调度,HDFS负责数据存储,Commo…...

ArrayList源码+扩容机制分析
1. ArrayList 简介 ArrayList 的底层是数组队列,相当于动态数组。与 Java 中的数组相比,它的容量能动态增长。在添加大量元素前,应用程序可以使用ensureCapacity操作来增加 ArrayList 实例的容量。这可以减少递增式再分配的数量。 ArrayLis…...
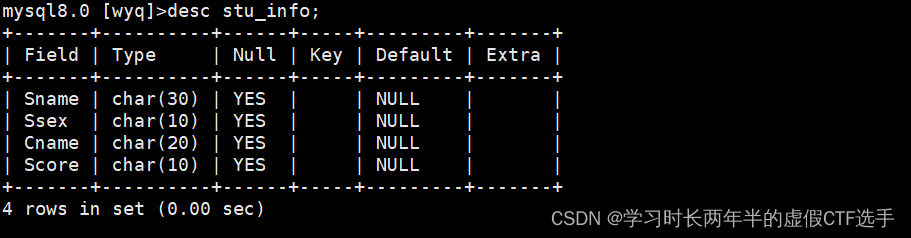
数据库(第四次作业)
学生表:Student (Sno, Sname, Ssex , Sage, Sdept) 学号,姓名,性别,年龄,所在系 Sno为主键 课程表:Course (Cno, Cname,) 课程号,课程名 Cno为主键 学生选课表:SC (Sno, Cno, Score)…...

传统档案管理,为什么影响企业上市进度?
企业上市,对于很多创业者来说,是他们奋发努力的首要目标。企业通过上市,进行股权融资,扩大经营规模,加速促进公司成长,最终达到企业的可持续发展。而要实现成功上市,企业除了需要满足股份公司上…...

开源AI应用构建平台Casibase:从架构设计到生产部署全解析
1. 项目概述:一个开源的AI应用构建平台最近在折腾AI应用开发的朋友,估计都绕不开一个核心痛点:想法很多,但落地太难。从模型选型、API对接、到前端交互、数据管理,每一个环节都够喝一壶。特别是当你想把多个模型、多种…...

终极二维码修复指南:如何用QrazyBox轻松恢复损坏的QR码数据
终极二维码修复指南:如何用QrazyBox轻松恢复损坏的QR码数据 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 你是否曾经遇到过这样的情况?打印出来的二维码模糊不清&…...

Ruoyi微服务全家桶:从零到一的部署启动实战指南
1. 环境准备:搭建基础服务 第一次接触Ruoyi微服务全家桶时,我花了整整两天时间才把环境跑通。现在回想起来,如果当时有人告诉我这些关键步骤,至少能节省80%的时间。我们先从最基础的环境搭建开始,这是整个项目能够正常…...

避坑指南:用MOT17训练YOLOv7检测器时,为什么你的mAP上不去?可能是数据划分的锅
MOT17数据集划分陷阱:为什么你的YOLOv7检测器性能不达标? 当你在MOT17数据集上训练YOLOv7检测器时,是否遇到过这样的困境:损失曲线看起来完美,训练集准确率节节攀升,但验证集mAP却始终徘徊在低水平…...
:涵盖217家认证出版机构、11种非标准署名格式及4类灰色地带处理协议)
Perplexity出版社信息查询终极清单(2024Q3独家更新):涵盖217家认证出版机构、11种非标准署名格式及4类灰色地带处理协议
更多请点击: https://intelliparadigm.com 第一章:Perplexity出版社信息查询 Perplexity 是一家以 AI 增强研究为定位的技术出版与知识平台,其核心产品并非传统纸质出版物,而是基于实时网络检索、引用溯源与结构化摘要的交互式问…...

5分钟完整指南:Sabaki围棋软件打造专业级对弈环境
5分钟完整指南:Sabaki围棋软件打造专业级对弈环境 【免费下载链接】Sabaki An elegant Go board and SGF editor for a more civilized age. 项目地址: https://gitcode.com/gh_mirrors/sa/Sabaki Sabaki是一款优雅的围棋棋盘和SGF编辑器,专为追求…...

SIFT和ORB到底怎么选?图像配准实战对比,看完这篇你就懂了
SIFT与ORB图像配准实战指南:如何根据项目需求选择最佳算法 在计算机视觉领域,图像配准是许多应用的基础环节,从医疗影像分析到增强现实,从卫星图像处理到工业检测,都离不开高效准确的特征匹配技术。当开发者面对SIFT和…...

环境配置与基础教程:保姆级教程:在 Mac M 芯片上利用 MPS 加速 YOLO 训练与推理的完整环境搭建
写在前面:为什么你的 Mac 也能跑深度学习? 几年前,如果有人告诉你用 MacBook 训练深度学习模型,你大概会笑出声。那时候 Mac 上的 PyTorch 只能依赖 CPU 吭哧吭哧地算,训练一个小模型都要等到天荒地老。但自从 Apple Silicon 芯片(M1、M2、M3、M4,以及最新的 M5)横空出…...

终极指南:如何构建React Native Navigation企业级应用的架构设计经验
终极指南:如何构建React Native Navigation企业级应用的架构设计经验 【免费下载链接】react-native-navigation A complete native navigation solution for React Native 项目地址: https://gitcode.com/gh_mirrors/re/react-native-navigation React Nati…...

动态路由协议与BGP路径属性:网络工程师的核心必修课
1. 从“路标”到“地图”:动态路由协议的核心价值 在网络世界里,路由器就像一个个十字路口的交通警察。如果每个路口都需要手动设置去往所有目的地的路牌,那不仅工作量巨大,一旦某条路临时施工或封闭,整个城市的交通都…...