深度学习模型压缩与优化加速
1. 简介
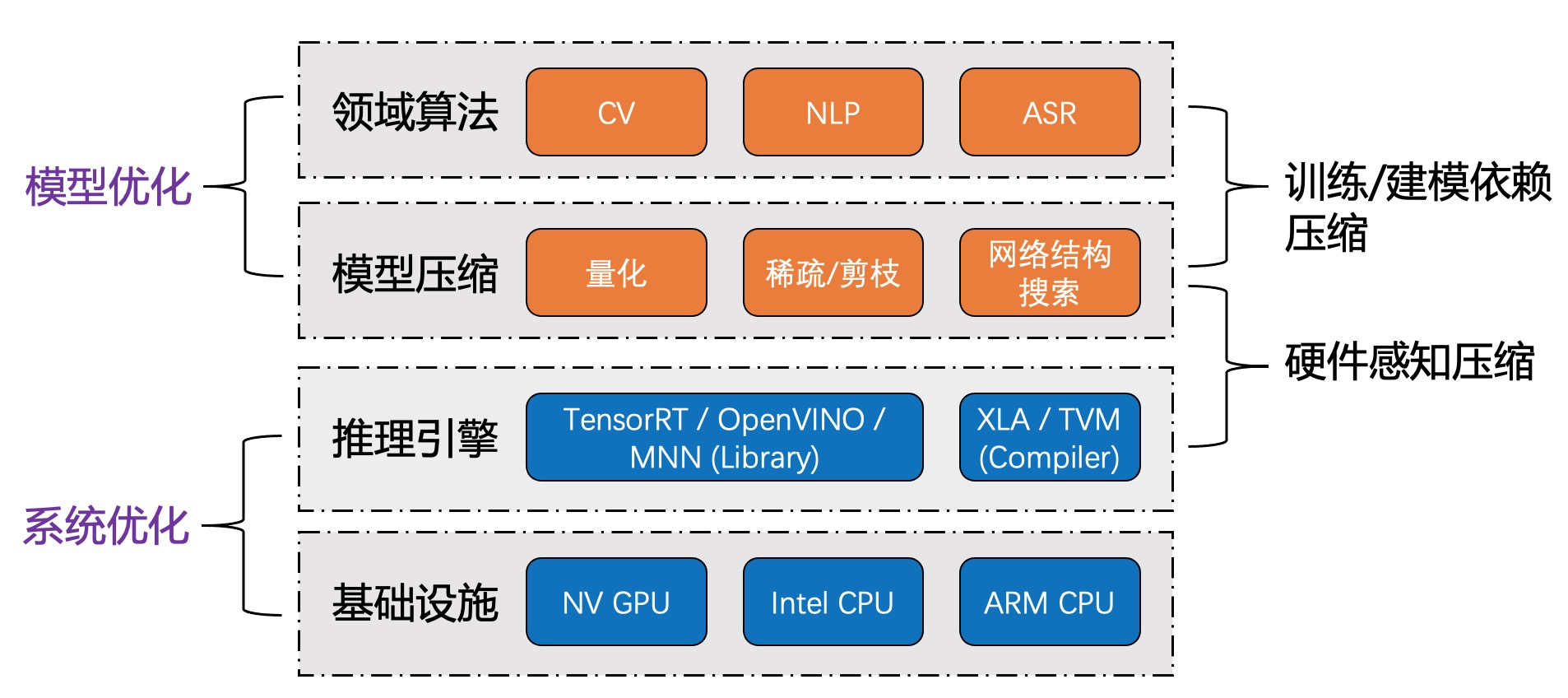
深度学习(Deep Learning)因其计算复杂度或参数冗余,在一些场景和设备上限制了相应的模型部署,需要借助模型压缩、系统优化加速、异构计算等方法突破瓶颈,即分别在算法模型、计算图或算子优化以及硬件加速等层面采取必要的手段:
- 模型压缩算法能够有效降低参数冗余,从而减少存储占用、通信带宽和计算复杂度,有助于深度学习的应用部署,具体可划分为如下几种方法(量化、剪枝与NAS是主流方向):
- 线性或非线性量化:1/2bits, INT4, INT8, FP16和BF16等;
- 结构或非结构剪枝:Sparse Pruning, Channel pruning和Layer drop等;
- 网络结构搜索 (NAS: Network Architecture Search):ENAS、Evolved Transformer、NAS FCOS、NetAdapt等离散搜索,DARTS、AdaBert、Proxyless NAS、FBNet等可微分搜索,SPOS、FairNAS、BigNAS、HAT、DynaBert与AutoFormer等One-shot搜索;
- 其他:权重矩阵的低秩分解、知识蒸馏与网络结构精简设计(Mobile-net, SE-net, Shuffle-net, PeleeNet, VoVNet, MobileBert, Lite-Transformer, SAN-M)等;
- 系统优化是指在特定系统平台上,通过Runtime层面性能优化,以提升AI模型的计算效率,具体包括:
- Op-level的算子优化:FFT Conv2d (7×7, 9×9), Winograd Conv2d (3×3, 5×5) 等;
- Layer-level的快速算法:Sparse-block net [1] 等;
- Graph-level的图优化:BN fold、Constant fold、Op fusion和计算图等价变换等;
- 优化工具与库(手工库、自动编译):TensorRT (Nvidia), MNN (Alibaba), TVM (Tensor Virtual Machine), Tensor Comprehension (Facebook) 和OpenVINO (Intel) 等;
- 异构计算方法借助协处理硬件引擎(通常是PCIE加速卡、ASIC加速芯片或加速器IP),完成深度学习模型在数据中心或边缘计算领域的实际部署,包括GPU、FPGA或DSA (Domain Specific Architecture) ASIC等。异构加速硬件可以选择定制方案,通常能效、性能会更高,目前市面上流行的AI芯片或加速器可参考 [2]。显然,硬件性能提升带来的加速效果非常直观,例如2080ti与1080ti的比较(以复杂的PyramidBox人脸检测算法为例,由于2080ti引入了Tensor Core加速单元,FP16计算约提速36%);另外,针对数据中心部署应用,通常会选择通用方案以构建计算平台(标准化、规模化支持业务逻辑计算),需要考虑是否有完善的生态支持,例如NVIDIA的CUDA,或者Xilinx的xDNN:
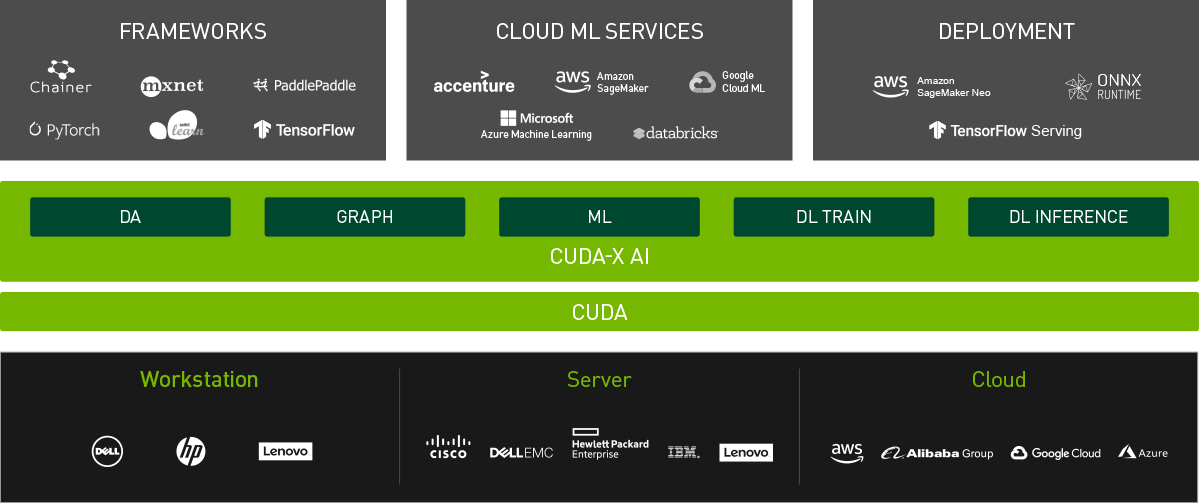
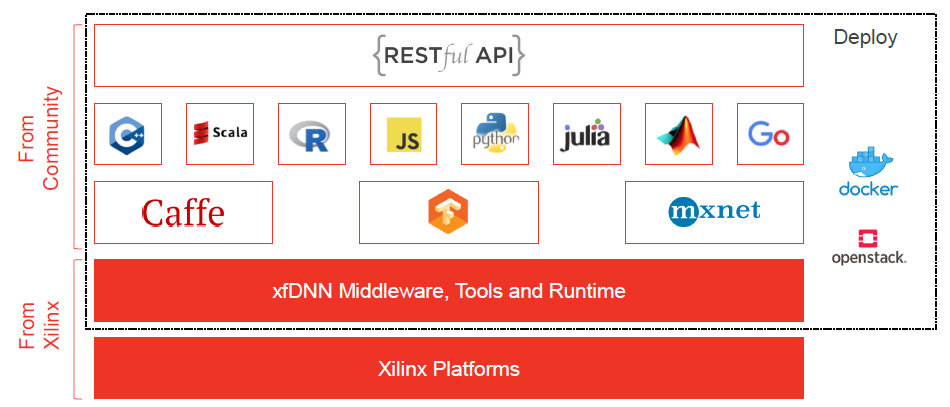
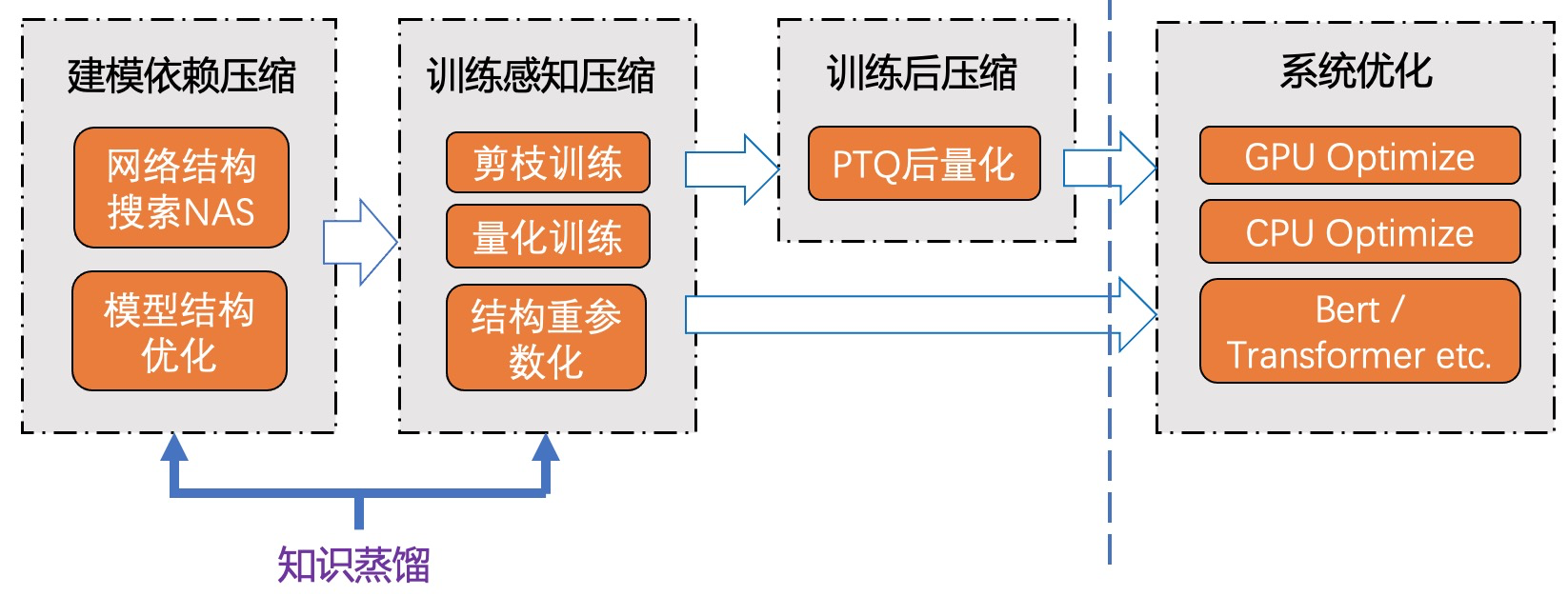
- 此外,从模型优化与系统优化的角度分析,领域算法建模与模型压缩通常紧密相关;推理优化手段的选择,通常也与基础设施或硬件平台相关联;而要想达到极致的模型压缩与推理优化效果,更需要硬件感知的反馈(Hardware-aware Compression):
2. 基于Roofline Model评估理论性能
基于计算平台的峰值算力与最高带宽约束,以及AI模型的理论计算强度(前向推理的计算量与内存交换量的比值),Roofline model为AI模型区分了两个性能评估区间,即Memory-bound区间与Compute-bound区间:
- Memory-bound:表示模型的计算强度相对较低,理论性能受限于存储访问。此时平台带宽越高,AI模型的访存开销越低。MobileNet、DenseNet属于典型的Memory-bound型模型;
- Compute-bound:表示模型的计算强度超过了平台限制(Imax),能够100%利用平台算力。此时,平台算力越高,AI模型推理耗时越低。VGG属于典型的Compute-bound型模型;

3. 高性能推理引擎——TensorRT/TVM/MNN基础
TensorRT是NVIDIA推出的面向GPU应用部署的深度学习优化加速工具,即是推理优化引擎、亦是运行时执行引擎。TensorRT采用的原理如下图所示,可分别在图优化、算子优化、Memory优化与INT8 Calibration等层面提供推理优化支持,具体可参考[3] [4]:
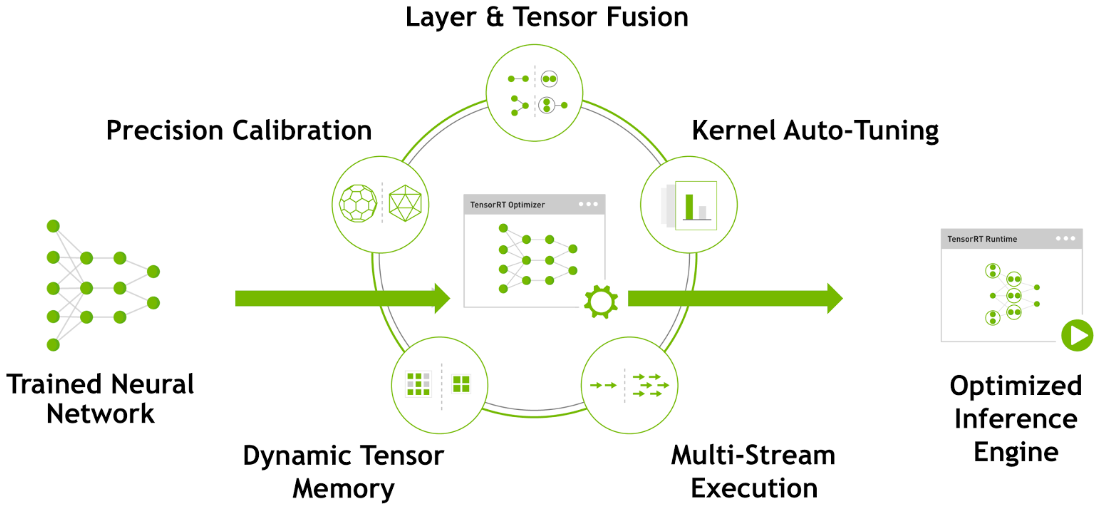
TensorRT能够优化重构由不同深度学习框架训练的深度学习模型:
- 全图自动优化:首先,对于Caffe、TensorFlow、MXNet或PyTorch训练的模型,若包含的操作都是TensorRT支持的,则可以直接通过TensorRT生成推理优化引擎;并且,对于PyTorch模型,亦可采用Trtorch执行推理优化;此外,亦可借助ONNX中间格式,通过(TF, PyTorch) -> ONNX -> TensorRT方式,执行优化转换 [27];等等;
- 全图手工优化:对于MXnet, PyTorch或其他框架训练的模型,若包含的操作都是TensorRT支持的,可以采用TensorRT API重建网络结构,并间接实现推理优化;
- 手工/自动分图:若训练的网络模型包含TensorRT不支持的Op:
手工分图:将深度网络手工划分为两个部分,一部分包含的操作都是TensorRT支持的,可以转换为TensorRT计算图。另一部分可采用其他框架实现,如MXnet或PyTorch,并建议使用C++ API实现,以确保更高效的Runtime执行;
Custom Plugin:不支持的Op可通过Plugin API实现自定义,并添加进TensorRT计算图,以支持算子的Auto-tuning,从而丰富TensorRT的Op-set完备性,例如Faster Transformer的自定义扩展 [26];Faster Transformer是较为完善的系统工程,能够实现标准Bert/Transformer的高性能计算;
TFTRT自动分图:TensorFlow模型可通过tf.contrib.tensorrt转换,其中不支持的操作会保留为TensorFlow计算节点;FP32 TF TRT优化流程如下:
from tensorflow.contrib import tensorrt as trtdef transfer_trt_graph(pb_graph_def, outputs, precision_mode, max_batch_size):trt_graph_def = trt.create_inference_graph(input_graph_def = pb_graph_def,outputs = outputs,max_batch_size = max_batch_size,max_workspace_size_bytes = 1 << 25,precision_mode = precision_mode,minimum_segment_size = 2)return trt_graph_deftrt_gdef = transfer_trt_graph(graph_def, output_name_list,'FP32', batch_size)
input_node, output_node = tf.import_graph_def(trt_gdef, return_elements=[input_name, output_name])with tf.Session(config=config) as sess:out = sess.run(output_node, feed_dict={input_node: batch_data})复制
PyTorch自动分图:基于Torchscript执行自动分图,避免custom plugin或手工分图的低效率支持,提升模型优化的支持效率;并降低用户使用TensorRT的门槛,自动完成计算图转换与优化tuning;对于不支持的Op或Sub-graph,采用Libtorch作为Runtime兜底(参考NVIDIA官方提供的优化加速工具Torch-TensorRT,可作为PyTorch编程范式的扩展):
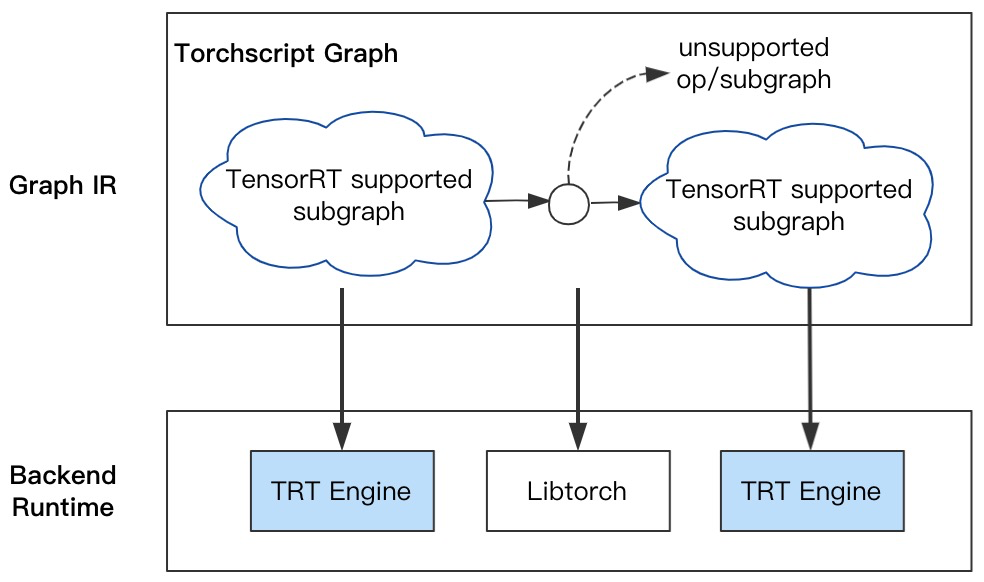
- INT8 Calibration:TensorRT的INT8量化需要校准(Calibration)数据集,能够反映真实应用场景,样本数量少则3~5个即可满足校准需求;且要求GPU的计算功能集sm >= 6.1;
在1080ti平台上,基于TensorRT4.0.1,Resnet101-v2的优化加速效果如下:
| Network | Precision | Framework / GPU: 1080ti (P) | Avg. Time (Batch=8, unit: ms) | Top1 Val. Acc. (ImageNet-1k) |
|---|---|---|---|---|
| Resnet101 | FP32 | TensorFlow | 36.7 | 0.7612 |
| Resnet101 | FP32 | MXnet | 25.8 | 0.7612 |
| Resnet101 | FP32 | TRT4.0.1 | 19.3 | 0.7612 |
| Resnet101 | INT8 | TRT4.0.1 | 9 | 0.7574 |
在1080ti/2080ti平台上,基于TensorRT5.1.5,Resnet101-v1d的FP16加速效果如下(由于2080ti包含Tensor Core,因此FP16加速效果较为明显):
| 网络 | 平台 | 数值精度 | Batch=8 | Batch=4 | Batch=2 | Batch=1 |
|---|---|---|---|---|---|---|
| Resnet101-v1d | 1080ti | FP32 | 19.4ms | 12.4ms | 8.4ms | 7.4ms |
| FP16 | 28.2ms | 16.9ms | 10.9ms | 8.1ms | ||
| INT8 | 8.1ms | 6.7ms | 4.6ms | 4ms | ||
| 2080ti | FP32 | 16.6ms | 10.8ms | 8.0ms | 7.2ms | |
| FP16 | 14.6ms | 9.6ms | 5.5ms | 4.3ms | ||
| INT8 | 7.2ms | 3.8ms | 3.0ms | 2.6ms |
相比于自动编译优化(以TVM为例):TensorRT的Kernel auto-tuning主要在一些手工优化的Op-set上执行Auto-tuning;而TVM则是基于Relay IR、计算表达与Schedule定义的搜索空间,通过EA、XGBoost或Grid search等搜索策略,执行自动编译优化、生成lower Graph IR(包含计算密集算子的优化op、以及基本的图优化),最终通过后端编译器(LLVM、nvcc等)生成指定硬件平台的优化执行代码。TVM的优化流程如下图所示:

具体而言,TVM提供了AutoTVM与AutoScheduler两种自动优化方式。AutoScheduler又称之为TVM Ansor,能够基于Cost model性能预估和进化算法执行自动寻优,搜索获得最佳的Schedule设置(tiling、op fusion、buffer与inline等)。以Intel CPU应用部署为例,基于TVM Ansor tuning,通过设置SIMD指令(如AVX512、VNNI)和多线程加速,能取得、甚至超过OpenVINO的加速效果。
有关TVM的details具体参考官网:Getting Started With TVM — tvm 0.8.dev0 documentation
有关TVM Ansor的具体介绍,可参考:深度学习编译系列之 ANSOR 技术分享 – 知乎
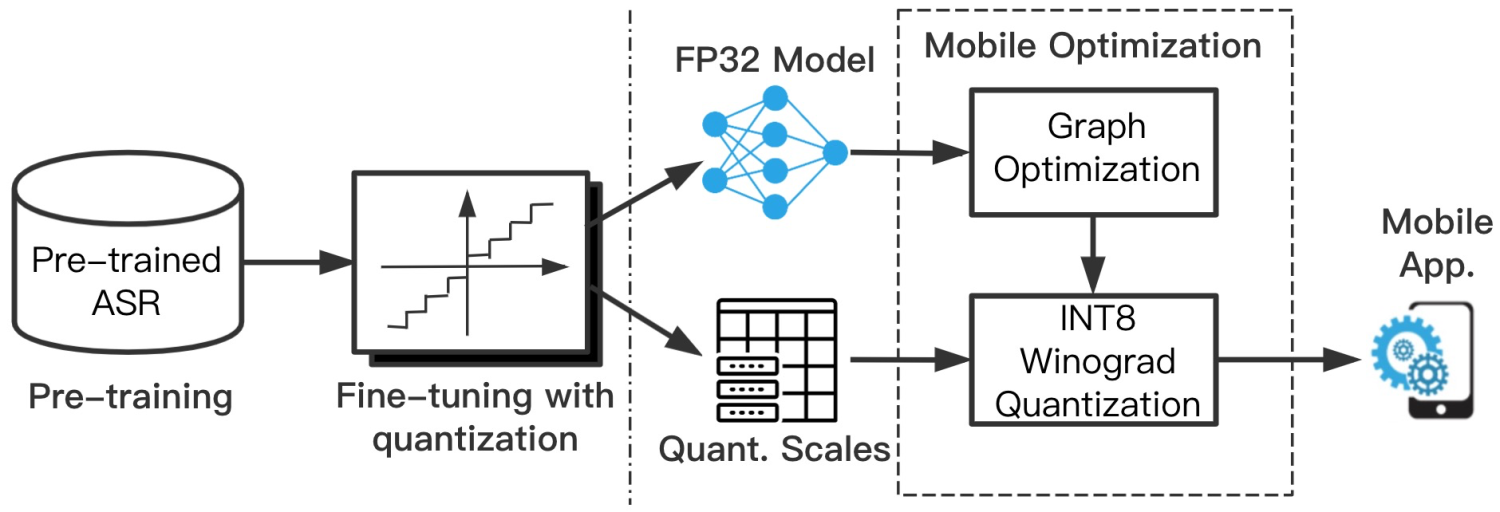
针对移动端应用部署:TVM自动编译优化也能取得理想的优化加速效果,但是由于移动端需要适配多种OS、与多种设备,因此TVM的tuning成本限制了其在移动端的应用推广。MNN是阿里淘系技术部推出的面向移动端推理部署的轻量型计算引擎,能够为多种深度学习模型的计算实现提供高效率的算子支持(包括FP32、FP16与INT8算子),并通过半自动方式提供优化tuning支持。并且,用户通过自定义的量化表或稀疏表,可以为MNN传递模型量化参数或稀疏率等信息,以支持计算图的量化优化或稀疏化。以量化训练(QAT: Quantization-aware Training)与MNN量化转换为例,可以构建从ASR模型的大规模预训练、到量化训练微调、再到MNN量化优化的工具链路:
4. 网络剪枝
深度学习模型因其稀疏性或过拟合倾向,可以被裁剪为结构精简的网络模型,具体包括结构性剪枝与非结构性剪枝:
- 非结构剪枝:通常是连接级、细粒度的剪枝方法,精度相对较高,但依赖于特定算法库或硬件平台的支持,如Deep Compression [5], Sparse-Winograd [6] 算法等;
- 结构剪枝:是filter级或layer级、粗粒度的剪枝方法,精度相对较低,但剪枝策略更为有效,不需要特定算法库或硬件平台的支持,能够直接在成熟深度学习框架上运行:
- 如局部方式的、通过Layer by Layer方式的、最小化输出FM重建误差的Channel Pruning [7], ThiNet [8], Discrimination-aware Channel Pruning [9];
- 全局方式的、通过训练期间对BN层Gamma系数施加L1正则约束的Network Slimming [10];
- 全局方式的、按Taylor准则对Filter作重要性排序的Neuron Pruning [11];
- 全局方式的、可动态重新更新Pruned filters参数的剪枝方法 [12];
- 基于GAN思想的GAL方法 [24],可裁剪包括Channel, Branch或Block等在内的异质结构;
- 借助Geometric Median确定卷积滤波器冗余性的剪枝策略 [28];
- 基于搜索策略的自动剪枝:基于Reinforcement Learning (RL),实现每一层剪枝率的连续、精细控制,并可结合资源约束完成自动模型压缩 (AMC) [31];以及NetAdapt,在满足平台资源约束的条件下,精简化预训练模型结构,同时确保识别精度最大化;
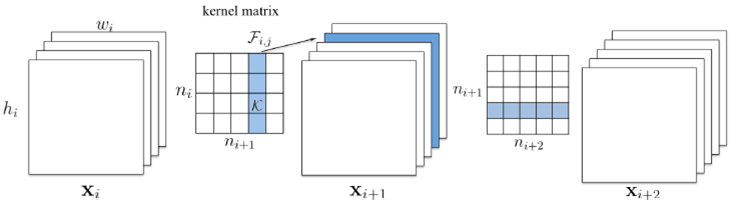
以Channel Pruning为例,结构剪枝的规整操作如下图所示,可兼容现有的、成熟的深度学习框架和推理优化框架:
5. 模型量化
模型量化是指权重或激活输出可以被聚类到一些离散、低精度(Reduced precision)的数值点上,通常依赖于特定算法库或硬件平台的支持:
- 二值化网络:XNORnet [13], ABCnet with Multiple Binary Bases [14], Bin-net with High-Order Residual Quantization [15], Bi-Real Net [16];
- 三值化网络:Ternary weight networks [17], Trained Ternary Quantization [18];
- W1-A8 或 W2-A8量化: Learning Symmetric Quantization [19];
- INT8量化:TensorFlow-lite [20], TensorRT [21], Quantization Interval Learning [25];
- INT4量化:NVIDIA Iterative Online Calibration [29], LSQ [30];
- 其他(非线性):Intel INQ [22], log-net, CNNPack [23] 等;
- PTQ策略(Post-Training Quantization):针对预训练模型,通过适当调整kernel参数分布、或补偿量化误差,可有效提升量化效果;另外也可以通过权重不变的训练(基于Calibration-set),按优化方式实现量化参数的Refine,如AdaRound、AdaQuant [32]与BRECQ;
- 关于量化的比较系统性的概念论述,参考论文:Quantizing deep convolutional networks for efficient inference: A whitepaper;
若模型压缩之后,推理精度存在较大损失,可通过Fine-tuning予以恢复,并在训练过程中结合适当的Tricks,例如针对ImageNet分类模型的剪枝后微调,可结合Label Smoothing、Mix-up、Knowledge Distillation、Focal Loss等。 此外,模型压缩、优化加速策略可以联合使用,进而可获得更为极致的压缩比与加速比。例如结合Network Slimming与TensorRT INT8优化,在1080ti Pascal平台上,Resnet101-v1d在压缩比为1.4倍时(Size=170MB->121MB,FLOPS=16.14G->11.01G),经TensorRT int8量化之后,推理耗时仅为7.4ms(Batch size=8)
相关文章:
深度学习模型压缩与优化加速
1. 简介 深度学习(Deep Learning)因其计算复杂度或参数冗余,在一些场景和设备上限制了相应的模型部署,需要借助模型压缩、系统优化加速、异构计算等方法突破瓶颈,即分别在算法模型、计算图或算子优化以及硬件加速等层…...

Kali 更换源(超详细,附国内优质镜像源地址)
1.进入管理员下的控制台。 2. 输入密码后点击“授权”。 3.在控制台内输入下面的内容。 vim /etc/apt/sources.list 4.敲击回车后会进入下面的页面。 5.来到这个页面后的第一部是按键盘上的“i”键,左下角出现“插入”后说明操作正确。 6.使用“#”将原本的源给注释…...

Java版工程项目管理系统平台+java版企业工程系统源码+助力工程企业实现数字化管理
Java版工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离 功能清单如下: 首页 工作台:待办工作、消息通知、预警信息,点击可进入相应的列表 项目进度图表:选择(总体或单个)项目显示1…...
搜索引擎测试报告
文章目录 一、项目背景二、项目功能三、测试目的四、测试环境五、测试计划1、功能测试2、自动化测试 六、测试结果 一、项目背景 java官方文档是我们在学习java语言中不可或缺的权威资料。相比于各种网站的Java资料,官方文档无论是语言表达还是组织方式都要更加全面…...

4年的测试工程师,你遇到过自身瓶颈期吗?又是怎样度过的?
从毕业到现在已经快4年啦,一直软件测试行业混迹。我不是牛人,但是自我感觉还算是个合格的测试工程师,有必要写下自己将近4年来的经历,给自我以提示,给刚入行的朋友提供点参考。 貌似这一点适应的行业最广,…...

【Python零基础学习入门篇④】——第四节:Python的列表、元组、集合和字典
⬇️⬇️⬇️⬇️⬇️⬇️ ⭐⭐⭐Hello,大家好呀我是陈童学哦,一个普通大一在校生,请大家多多关照呀嘿嘿😁😊😘 🌟🌟🌟技术这条路固然很艰辛,但既已选择&…...

3.6 cache存储器
学习步骤: 我会采取以下几个步骤来学习Cache存储器: 确定学习目标:Cache存储器作为一种高速缓存存储器,通常用于提高计算机系统的运行效率。因此,我需要明确学习Cache存储器的目的,包括了解其原理、结构和…...
Ubuntu零基础安装
Ubuntu零基础安装 首先我们需要安装VM,再安装ubuntu。 1、安装VM 进入VM官网 VM官网地址 选择下载试用版 下载Windows版本 下载完成后,点击安装包进行安装 至此就安装完毕了。 桌面会出现VM的图标。 点击打开,弹出如下画面: …...

热门的常用 API 大全分享
天气/环境 空气质量查询: 查询国内3400个城市的整点观测,获取指定城市的整点观测空气质量。未来7天生活指数:支持国内3400个城市以及国际4万个城市的天气指数数据,包括晨练、洗车、穿衣(12项,有详细说明&a…...
利用粒子群算法设计无线传感器网络中的最优安全路由模型(Matlab代码实现)
目录 💥1 概述 📚2 运行结果 🎉3 参考文献 👨💻4 Matlab代码 💥1 概述 无线传感器网络(WSN)由数十个、数百个甚至数千个自主传感器组成。这些传感器以无线方式嵌入环境中&…...

2023年华东杯数学建模B 题 期货价格相关性问题-思路解析
题目背景: 许多金融标的都有其内在的关联,如何从量价数据找到这种关联是一个有趣的 问题。例如在万得的“煤焦钢矿”板块中,有螺纹钢、铁矿石、不锈钢、热轧卷板、 硅铁、焦煤、焦炭、锰硅、线材 9 个品种。这些品种有些是上下游关系&…...
SAP UI5 之Controls (控件) 笔记三
文章目录 官网 Walkthrough学习-Controls控件1.0.1 在index.html中使用class id 属性控制页面展示的属性1.0.2 我们在index.js文件中引入 text文本控制1.0.3打开浏览器查看结果 官网 Walkthrough学习-Controls控件 Controls控件 在前面展示在浏览器中的Hello World 是在Html …...

哈希表题目:设计地铁系统
文章目录 题目标题和出处难度题目描述要求示例数据范围 解法思路和算法代码复杂度分析 题目 标题和出处 标题:设计地铁系统 出处:1396. 设计地铁系统 难度 6 级 题目描述 要求 一个地铁系统正在收集乘客在不同站之间的花费时间。他们在使用这些数…...
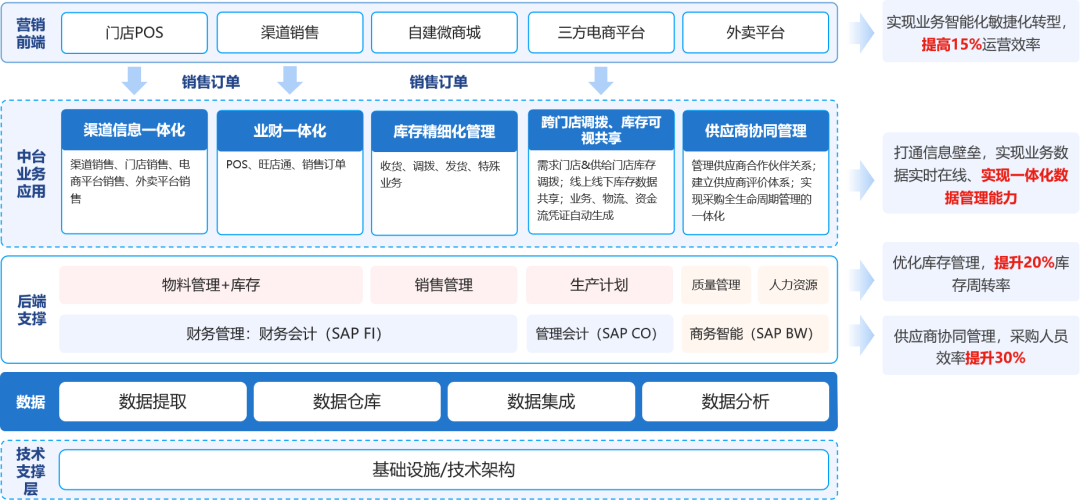
云时通OMS:为零售品牌商打造高效的全渠道订单管理!
传统的零售企业围绕“人、货、场” 三要素来展开营销,其目标是基于“场”将货销售给更多的人。随着数字技术的应用,新零售模式下的“场”除了传统的线下店铺外,还拓展了多元化的线上渠道,比如小程序、企业APP、第三方平台、电商直…...

有必要给孩子买台灯吗?分享四款高品质的护眼台灯
有必要使用护眼台灯,尤其是有近视现象的孩子们。 现在很多孩子小学就开始近视了,保护视力刻不容缓呀! 很多人不知道,其实劣质光线是最大的眼睛杀手 给孩子随便买便宜的台灯,看着一样能用,其实时间久了 对孩子眼睛的…...

模板方法模式
模板方法模式 模板方法模式定义:使用场景角色定义抽象模板: 为抽象模板,它的方法分为两类AbstractClass1. 基本方法: 也叫做基本操作,是由子类实现的方法,并且在模板方法被调用。2. 模板方法: 可以有一个或几个,一般是一个具体方法…...
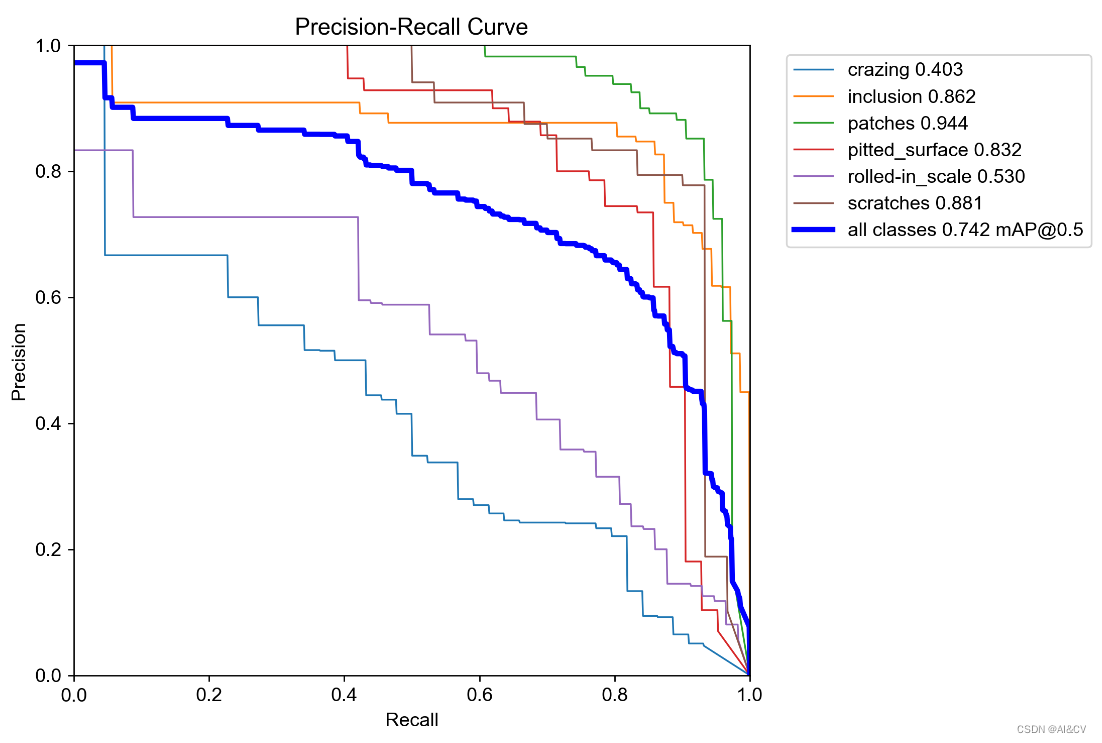
基于Yolov5的NEU-DET钢材表面缺陷检测,优化组合新颖程度较高:CVPR2023 DCNV3和InceptionNeXt,涨点明显
1.钢铁缺陷数据集介绍 NEU-DET钢材表面缺陷共有六大类,分别为:crazing,inclusion,patches,pitted_surface,rolled-in_scale,scratches 每个类别分布为: 训练结果如下: 2.基于yolov5s的训练 map值: 2.1 Inception-MetaNeXtStage 对应博客:https://cv2023.blog.csdn.n…...

【HarmonyOS】自定义组件之ArkUI实现通用标题栏组件
【关键字】 标题栏、常用内置组件整合、ArkUI、自定义组件 1、写在前面 在上一篇文章中我们通过Java语言实现了一个通用的标题栏组件,有需要的可以看下,文章地址: 华为开发者论坛 现在很多朋友都已经转战ArkTS语言了,那么今天…...

C#开发的OpenRA游戏的加载地图流程
C#开发的OpenRA游戏的加载地图流程 OpenRA游戏里,地图是一个很关键的数据, 因为地图里包括了地面状态,地面上建筑物状态, 还有玩家在地图上的布局情况,以及各种活动限制的条件。 在OpenRA里,需要把地图目录:OpenRA\mods\cnc\maps 里所有的文件进行加载, 并且保存在缓…...
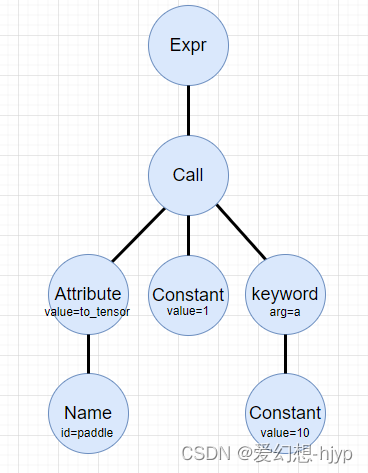
python ast 详解与用法
目录 基本概念节点类型ast.Assignast.Nameast.Constantast.Callast.Attribute 结点的遍历ast源码示例 结点的修改示例 参考链接 基本概念 在 python 中,我们可以通过自带的 ast 模块来对解析遍历语法树,通过ast.parse()可以将字符串代码解析为抽象语法树…...

OpenClaw 消息路由与广播机制深度解析
OpenClaw 消息路由与广播机制深度解析 作者: Social Agent (小社) 日期: 2026-03-18 研究模块: channels/channel-routing + broadcast-groups + group-messages 一、消息路由的核心设计 1.1 确定性路由,而非 AI 决策 OpenClaw 消息路由最重要的设计决策是:路由是确定性的…...

TEdit地图编辑器:从零开始掌握泰拉瑞亚世界创作
TEdit地图编辑器:从零开始掌握泰拉瑞亚世界创作 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets you change w…...

在Nodejs后端服务中集成Taotoken实现稳定高效的多模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Nodejs后端服务中集成Taotoken实现稳定高效的多模型调用 对于构建AI功能的后端Node.js开发者而言,直接对接单一模型供…...
)
从继电器到边缘计算:拆解PAC控制器里的‘智能手机’架构(以Codesys/倍福为例)
从继电器到边缘计算:拆解PAC控制器里的‘智能手机’架构 在工业自动化领域,PAC(可编程自动化控制器)正逐渐取代传统PLC,成为智能制造的核心大脑。这种转变类似于功能手机向智能手机的进化——从单一功能到开放平台&…...

Windows 10/11 环境下 OpenClaw v2.7.1 安装避坑与常见问题解决方案
🦞 OpenClaw v2.7.1 Windows 一键部署教程|5 分钟搭建本地 AI 智能体 在本地 AI 自动化工具快速普及的当下,OpenClaw(小龙虾)凭借全程可视化、一键部署、本地运行的特点,成为 Windows 平台上易用性突出的 …...
)
别再死记硬背了!用这三个二极管等效模型,轻松搞定电路分析(附典型例题)
二极管电路分析的三大黄金法则:从理论到实战的思维跃迁 在电子工程领域,二极管就像电路世界里的"单向阀门",看似简单却暗藏玄机。许多初学者面对复杂二极管电路时,往往陷入盲目试错的困境——要么死记硬背公式ÿ…...
)
别再死记硬背!用Python+OpenCV实战推导相机内外参与FOV公式(附代码)
用PythonOpenCV实战推导相机内外参与FOV公式:从代码中理解数学本质 在计算机视觉领域,相机参数的数学推导常常让开发者陷入公式记忆的困境。本文提供一种全新的学习路径——通过Python代码动态模拟相机成像过程,将抽象的数学公式转化为可交互…...

告别 Origin 内卷|虎贲等考 AI 科研绘图,一键出期刊级学术图
很多做毕业论文、发期刊、做课题的同学和科研人,都卡在同一个难题上:论文写得再好,却栽在科研绘图上。想用专业软件,Origin、Visio、GraphPad 上手难、参数复杂、调试半天出不来一张合格图;用 Excel、PPT 随手做图&…...

自动化规则同步:从设计原理到Go/Python实战实现
1. 项目概述:一个自动化同步规则的“守门人”在运维和网络安全领域,我们每天都在和各种规则打交道:防火墙规则、入侵检测规则、内容过滤规则……这些规则是保障系统安全、优化网络流量的核心防线。然而,随着业务扩展和多环境部署&…...

工作5年的Go程序员,转大模型开发3个月,我踩过的所有坑
文章目录前言一、第一个大坑:以为大模型就是调API,结果连面试门都没入二、第二个大坑:技术栈转换,从Go的天堂掉进Python的地狱三、第三个大坑:Go调用大模型推理,踩不完的性能和内存坑四、第四个大坑&#x…...