日撸 Java 三百行day38
文章目录
- 说明
- day38
- 1.Dijkstra 算法思路分析
- 2.Prim 算法思路分析
- 3.对比
- 4.代码
说明
闵老师的文章链接: 日撸 Java 三百行(总述)_minfanphd的博客-CSDN博客
自己也把手敲的代码放在了github上维护:https://github.com/fulisha-ok/sampledata
day38
1.Dijkstra 算法思路分析
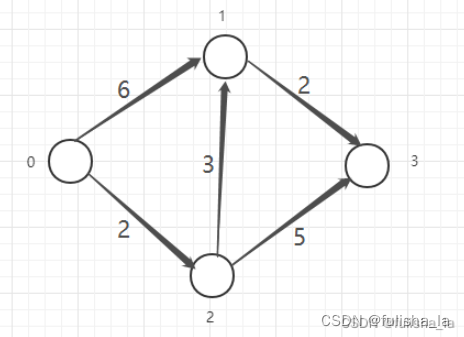
假设以顶点0出发
(1)0到各个顶点距离为:<0,1> 6;<0,2> 2 ;<0,3> ∞;选取最小距离<0,2> 2
(2)加入<0,2>一条边,看0到剩余顶点距离:
<0,1>: 原<0,1> 6,在加入<0,2>,则可以借助<0,2>,<0,2><2,1> 5;选取最小距离5<0,3>:原<0,3> ∞,在加入<0,2>,<0,2><2,3> 7;选取最小距离7
比较5和7选取最小的距离5 0->1: 5
(3)加入<0,2><2,1>边,看0到剩余顶点的距离
<0,3>:原<0,2><2,3> 7,在加入<2,1>,<0,2><2,1><1,3>7; 选取最小距离<0,2><2,3> 7
节点遍历完,找到0到各点最短距离 0->3: 7
在这个过程中进一步思考:
在实现这个过程中需要借助一些数组来存储数据:
开始顶点到每一个顶点的最短距离需要有一个数组来存储,并且在每循环一次都需要检查这个数组是否需要更新
开始顶点到某个顶点不一定是直连路径,则需要存储开始顶点到某个顶点的路径,则也需要一个数组来存储路径。
顶点是否已经确定为最短路径结点,需要一个数组来做一个标志。
2.Prim 算法思路分析
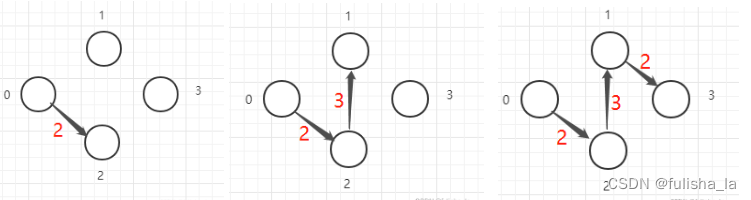
prim算法为最小生成树,过程:任意选一个顶点(如选0顶点)
从0顶点到与之相连的结点之间距离最短的顶点,图中为2
在0,2结点中选择距离最短的结点,则为 1 节点
在0,1,2结点中选择距离最短的结点,则为3节点
当结点树n = 边树n-1即构建成功
3.对比
Dijkstra 算法是求单源最短路径,可以算出开始顶点到其他顶点的最短路径,但是如果权重有负数,则dijstra并不能计算出正确的结果。而prim算法是构建最小生成树的一种策略。
Dijkstra 求单源最短路径时,我们要给定一个顶点,去找到其他结点的最短路径,而最小生成树是任意选择一个顶点开始。
Dijkstra 算法适用于有向图,而Prim更适合无向图(我认为主要是有向图在两个节点来回可能权重不同)
4.代码
- 在dijkstra中主要分为三个for循环,一个大的for循环:一次循环就可以确定从v0顶点到某个顶点的最短路径,在大循环中的第一个循环是找出v0结点到剩余未访问结点中的最短路径,第三个循环是:已经确定某个顶点是最短路径,去更新tempDistanceArray,tempParentArray这两个数组。
public int[] dijikstra(int paraSource) {// Step 1. Initialize.int[] tempDistanceArray = new int[numNodes];for (int i = 0; i < numNodes; i++) {tempDistanceArray[i] = weightMatrix.getValue(paraSource, i);}int[] tempParentArray = new int[numNodes];Arrays.fill(tempParentArray, paraSource);// -1 for no parent.tempParentArray[paraSource] = -1;// Visited nodes will not be considered further.boolean[] tempVisitedArray = new boolean[numNodes];tempVisitedArray[paraSource] = true;// Step 2. Main loops.int tempMinDistance;int tempBestNode = -1;for (int i = 0; i < numNodes - 1; i++) {// Step 2.1 Find out the best next node.tempMinDistance = Integer.MAX_VALUE;for (int j = 0; j < numNodes; j++) {// This node is visited.if (tempVisitedArray[j]) {continue;}if (tempMinDistance > tempDistanceArray[j]) {tempMinDistance = tempDistanceArray[j];tempBestNode = j;}}tempVisitedArray[tempBestNode] = true;// Step 2.2 Prepare for the next round.for (int j = 0; j < numNodes; j++) {// This node is visited.if (tempVisitedArray[j]) {continue;}// This node cannot be reached.if (weightMatrix.getValue(tempBestNode, j) >= MAX_DISTANCE) {continue;}if (tempDistanceArray[j] > tempDistanceArray[tempBestNode]+ weightMatrix.getValue(tempBestNode, j)) {// Change the distance.tempDistanceArray[j] = tempDistanceArray[tempBestNode]+ weightMatrix.getValue(tempBestNode, j);// Change the parent.tempParentArray[j] = tempBestNode;}}// For testSystem.out.println("The distance to each node: " + Arrays.toString(tempDistanceArray));System.out.println("The parent of each node: " + Arrays.toString(tempParentArray));}// Step 3. Output for debug.System.out.println("Finally");System.out.println("The distance to each node: " + Arrays.toString(tempDistanceArray));System.out.println("The parent of each node: " + Arrays.toString(tempParentArray));return tempDistanceArray;}
- 在prim算法中,与dijkstra算法最大的区别在与第三个循环中,在更新tempDistanceArray是累加之前的边,而在prim算法中则不需要累加,只需要判断从这个已选结点出发到其他结点的距离是否需要更新
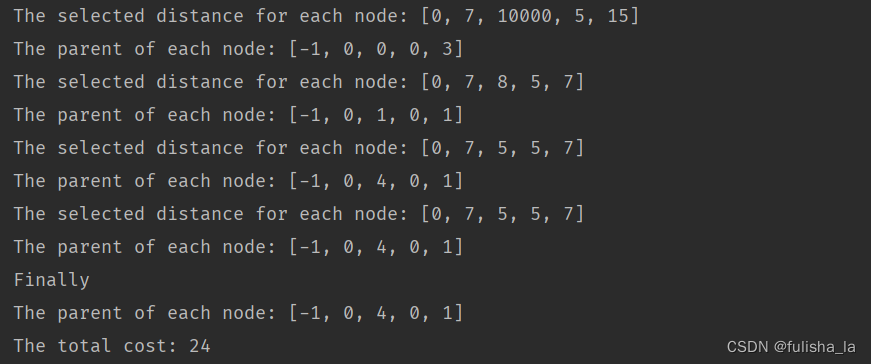
public int prim() {// Step 1. Initialize.// Any node can be the source.int tempSource = 0;int[] tempDistanceArray = new int[numNodes];for (int i = 0; i < numNodes; i++) {tempDistanceArray[i] = weightMatrix.getValue(tempSource, i);}int[] tempParentArray = new int[numNodes];Arrays.fill(tempParentArray, tempSource);// -1 for no parent.tempParentArray[tempSource] = -1;// Visited nodes will not be considered further.boolean[] tempVisitedArray = new boolean[numNodes];tempVisitedArray[tempSource] = true;// Step 2. Main loops.int tempMinDistance;int tempBestNode = -1;for (int i = 0; i < numNodes - 1; i++) {// Step 2.1 Find out the best next node.tempMinDistance = Integer.MAX_VALUE;for (int j = 0; j < numNodes; j++) {// This node is visited.if (tempVisitedArray[j]) {continue;}if (tempMinDistance > tempDistanceArray[j]) {tempMinDistance = tempDistanceArray[j];tempBestNode = j;}}tempVisitedArray[tempBestNode] = true;// Step 2.2 Prepare for the next round.for (int j = 0; j < numNodes; j++) {// This node is visited.if (tempVisitedArray[j]) {continue;}// This node cannot be reached.if (weightMatrix.getValue(tempBestNode, j) >= MAX_DISTANCE) {continue;}// Attention: the difference from the Dijkstra algorithm.if (tempDistanceArray[j] > weightMatrix.getValue(tempBestNode, j)) {// Change the distance.tempDistanceArray[j] = weightMatrix.getValue(tempBestNode, j);// Change the parent.tempParentArray[j] = tempBestNode;}}// For testSystem.out.println("The selected distance for each node: " + Arrays.toString(tempDistanceArray));System.out.println("The parent of each node: " + Arrays.toString(tempParentArray));}int resultCost = 0;for (int i = 0; i < numNodes; i++) {resultCost += tempDistanceArray[i];}// Step 3. Output for debug.System.out.println("Finally");System.out.println("The parent of each node: " + Arrays.toString(tempParentArray));System.out.println("The total cost: " + resultCost);return resultCost;}
-
单元测试
-
dijkstra算法(从顶点0出发)
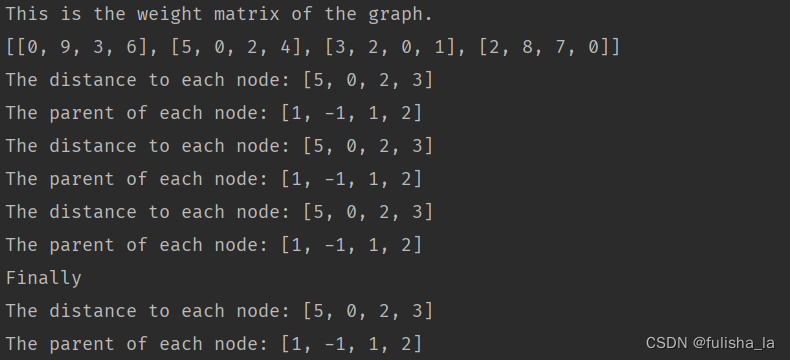
-
prim算法
相关文章:
日撸 Java 三百行day38
文章目录 说明day381.Dijkstra 算法思路分析2.Prim 算法思路分析3.对比4.代码 说明 闵老师的文章链接: 日撸 Java 三百行(总述)_minfanphd的博客-CSDN博客 自己也把手敲的代码放在了github上维护:https://github.com/fulisha-ok/…...
玩转肺癌目标检测数据集Lung-PET-CT-Dx ——④转换成PASCAL VOC格式数据集
文章目录 关于PASCAL VOC数据集目录结构 ①创建VOC数据集的几个相关目录XML文件的形式 ②读取dcm文件与xml文件的配对关系③创建VOC格式数据集④创建训练、验证集 本文所用代码见文末Github链接。 关于PASCAL VOC数据集 pascal voc数据集是关于计算机视觉,业内广泛…...

两种使用 JavaScript 实现网页高亮关键字的方法
随着各种类型的信息源变得越来越多,我们常常需要通过搜索引擎来找到自己需要的信息。在搜索结果中,通常会高亮显示与我们搜索的关键词相关的内容,这样我们就能更快地找到自己需要的信息。 在本文中,我们将探讨如何使用 JavaScrip…...
【SpringBoot】SpringBoot集成ElasticSearch
文章目录 第一步,导入jar包,注意这里的jar包版本可能和你导入的不一致,所以需要修改第二步,编写配置类第三步,填写yml第四步,编写util类第五步,编写controller类第六步,测试即可 第一…...
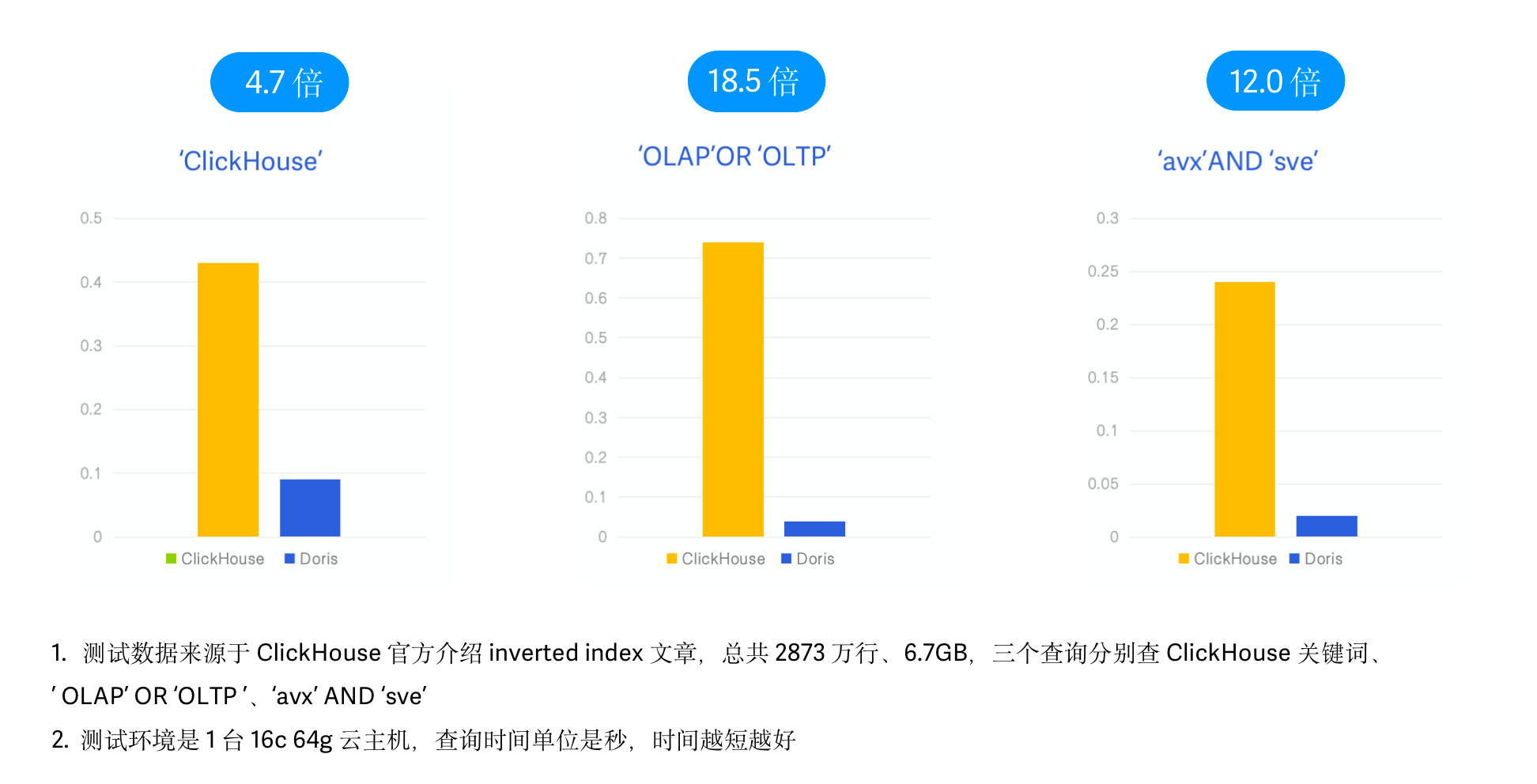
从 Elasticsearch 到 Apache Doris,10 倍性价比的新一代日志存储分析平台
作者介绍:肖康,SelectDB 技术副总裁 导语 日志数据的处理与分析是最典型的大数据分析场景之一,过去业内以 Elasticsearch 和 Grafana Loki 为代表的两类架构难以同时兼顾高吞吐实时写入、低成本海量存储、实时文本检索的需求。Apache Doris…...

探讨Redis缓存问题及解决方案:缓存穿透、缓存击穿、缓存雪崩与缓存预热(如何解决Redis缓存中的常见问题并提高应用性能)
Redis是一种非常流行的开源缓存系统,用于缓存数据以提高应用程序性能。但是,如果我们不注意一些缓存问题,Redis也可能会导致一些性能问题。在本文中,我们将探讨Redis中的一些常见缓存问题,并提供解决方案。 一、缓存穿…...
)
【Python】怎么在pip下载的时候设置镜像?(常见的清华镜像、阿里云镜像以及中科大镜像)
一、清华镜像 在使用 pip 命令下载 Python 包时,可以通过设置 pip 的镜像源为清华镜像来加快下载速度。 以下是如何设置清华镜像源的步骤: 打开终端或命令行窗口执行以下命令添加清华镜像源: pip config set global.index-url https://py…...
【AI面试】目标检测中one-stage、two-stage算法的内容和优缺点对比汇总
在深度学习领域中,图像分类,目标检测和目标分割是三个相对来说较为基础的任务了。再加上图像生成(GAN,VAE,扩散模型),keypoints关键点检测等等,基本上涵盖了图像领域大部分场景了。 …...

stack、queue和priority_queue的使用介绍--C++
目录 一、stack介绍 使用方法 二、queue介绍 queue的使用 三、priority_queeue 优先级队列介绍 一、stack介绍 1. stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入与提取操作。 2. stack是作为容器…...

python遍历数组
在Python中,有多种方式可以遍历数组,以下是其中的几种方式: 1. 使用for循环: my_list [1, 2, 3, 4, 5] for x in my_list: print(x) 2. 使用while循环和索引: my_list [1, 2, 3, 4, 5] i 0 while i < len(m…...
红黑树理论详解与Java实现
文章目录 基本定义五大性质红黑树和2-3-4树的关系红黑树和2-3-4树各结点对应关系添加结点到红黑树注意事项添加的所有情况 添加导致不平衡叔父节点不是红色节点(祖父节点为红色)添加不平衡LL/RR添加不平衡LR/RL 叔父节点是红色节点(祖父节点为…...

container的讲解
我们做开发经常会遇到这样的一个需求,要开发一个响应式的网站,但是我们需要我们的元素样式跟随着我们的元素尺寸大小变化而变化。而我们常用的媒体查询(Media Queries)检测的是视窗的宽高,根本无法满足我们的业务需求&…...

JavaScript 箭头函数
(许多人所谓的成熟,不过是被习俗磨去了棱角,变得世故而实际了。那不是成熟,而是精神的早衰和个性的消亡。真正的成熟,应当是独特个性的形成,真实自我的发现,精神上的结果和丰收。——周国平&…...

简单理解Transformer注意力机制
这篇文章是对《动手深度学习》注意力机制部分的简单理解。 生物学中的注意力 生物学上的注意力有两种,一种是无意识的,零一种是有意识的。如下图1,由于红色的杯子比较突出,因此注意力不由自主指向了它。如下图2,由于…...

Vue3面试题:20道含答案和代码示例的练习题
Vue3中响应式数据的实现原理是什么? 答:Vue3中使用Proxy对象来实现响应式数据。当数据发生变化时,Proxy会自动触发更新。 const state {count: 0 }const reactiveState new Proxy(state, {set(target, key, value) {target[key] valueco…...

Oracle数据库创建用户
文章目录 1 查看当前连接的容器2 查看pdb下库的信息3 将连接改到XEPDB1下,并查看当前连接4 创建表空间5 创建用户6 用户赋权7 删除表空间、用户7.1 删除表空间7.2 删除用户 8 CDB与PDB的概念 1 查看当前连接的容器 SQL> show con_name;CON_NAME ---------------…...
)
互联网摸鱼日报(2023-04-30)
互联网摸鱼日报(2023-04-30) InfoQ 热门话题 被ChatGPT带火的大模型,如何实际在各行业落地? Service Mesh的未来在于网络 百度 Prometheus 大规模业务监控实战 软件技术栈商品化:应用优先的云服务如何改变游戏规则…...

第二章--第一节--什么是语言生成
一、什么是语言生成 1.1. 说明语言生成的概念及重要性 语言生成是指使用计算机程序来生成符合人类自然语言规范的文本的过程。它是自然语言处理(NLP)领域中的一个重要分支,涉及到语言学、计算机科学和人工智能等领域的交叉应用。语言生成技术可以被广泛地应用于自动问答系…...

HTML <!--...--> 标签
实例 HTML 注释: <!--这是一段注释。注释不会在浏览器中显示。--><p>这是一段普通的段落。</p>浏览器支持 元素ChromeIEFirefoxSafariOpera<!--...-->YesYesYesYesYes 所有浏览器都支持注释标签。 定义和用法 注释标签用于在源代码中…...

TinyML:使用 ChatGPT 和合成数据进行婴儿哭声检测
故事 TinyML 是机器学习的一个领域,专注于将人工智能的力量带给低功耗设备。该技术对于需要实时处理的应用程序特别有用。在机器学习领域,目前在定位和收集数据集方面存在挑战。然而,使用合成数据可以以一种既具有成本效益又具有适应性的方式训练 ML 模型,从而消除了对大量…...

告别虚拟机卡顿:在Proxmox VE 7.0上丝滑安装中兴新支点NewStartOS 4.3.8社区版
告别虚拟机卡顿:在Proxmox VE 7.0上丝滑安装中兴新支点NewStartOS 4.3.8社区版 虚拟化技术已成为现代IT基础设施的核心组件,而Proxmox VE作为开源的虚拟化管理平台,凭借其稳定性和灵活性赢得了众多技术团队的青睐。在众多虚拟化应用场景中&am…...

理想汽车AI组织架构重组
把公司拆成心脏、大脑和手脚——理想汽车这波AI组织架构重组到底在赌什么? 导读:李想用一场2小时的全员会,把一家年营收千亿的公司按人体器官逻辑重新组装。这不是比喻,这是组织结构图上的真实节点。从造车到"造人"&…...

解读民法典基本规定第十条
民法典: 第一编 总则,第一章 基本规定 第十条 处理民事纠纷,应当依照法律;法律没有规定的,可以适用习惯,但是不得违背公序良俗。 一句话核心 先按国法判,国法没写明白,就按当地老规矩、民间习俗…...

从零到跑通:Windows下OTB100数据集与Matlab评测环境保姆级避坑指南
从零到跑通:Windows下OTB100数据集与Matlab评测环境保姆级避坑指南 刚接触目标跟踪领域的研究者,往往需要从经典数据集评测开始。OTB(Object Tracking Benchmark)作为目标跟踪领域的基石数据集,包含100个具有挑战性的视…...

面壁智能开源端侧多模态大模型MiniCPM-V 4.6,性能登顶同尺寸榜首,降低开发门槛
【导语:5月13日,面壁智能联合清华大学与OpenBMB开源社区,发布并开源新一代端侧多模态大模型MiniCPM-V 4.6。该模型以轻量级参数实现性能与效率突破,在评测中超越竞品,还降低了运行内存需求和计算成本,支持多…...
的三种手动确认模式实战:basicAck、basicNack、basicReject到底怎么选?)
SpringBoot项目里RabbitMQ消息确认(ACK)的三种手动确认模式实战:basicAck、basicNack、basicReject到底怎么选?
SpringBoot项目中RabbitMQ消息确认模式的深度实战指南 1. 消息确认机制的核心价值与业务场景 在分布式系统中,消息队列承担着解耦生产者和消费者的重要职责。RabbitMQ作为最流行的消息中间件之一,其消息确认机制(ACK)是确保数据…...

簧片继电器可靠性设计与关键技术解析
1. Reed Relay可靠性设计的关键技术解析簧片继电器(Reed Relay)作为电子系统中的关键切换元件,其可靠性直接影响整个设备的长期稳定性。与传统电磁继电器相比,簧片继电器具有独特的结构优势和技术特点。本文将深入剖析提升簧片继电…...

百度网盘群晖套件终极指南:3步实现NAS云存储完美整合
百度网盘群晖套件终极指南:3步实现NAS云存储完美整合 【免费下载链接】synology-baiduNetdisk-package 项目地址: https://gitcode.com/gh_mirrors/sy/synology-baiduNetdisk-package 想在群晖NAS上直接管理百度网盘文件?这个开源套件让你轻松实…...

从零到一:DPDK高性能网络开发实战指南
1. 为什么你需要了解DPDK? 如果你正在开发需要处理高吞吐量网络数据的应用,比如视频流服务器、金融交易系统或者云计算平台,传统的Linux网络栈可能会成为性能瓶颈。我亲身经历过一个项目,用传统方式开发的网关每秒只能处理30万包…...

从泊松比到广义胡克定律:物理仿真中的材料形变建模指南
1. 泊松比:材料形变的"性格密码" 第一次接触泊松比这个概念时,我正对着橡胶减震器的仿真结果发愁——明明设置了正确的杨氏模量,为什么变形效果总是不对劲?直到导师指着屏幕问:"你考虑过这个橡胶材料的…...