深度学习与文本聚类:一篇全面的介绍与实践指南

深度学习与文本聚类:一篇全面的介绍与实践指南
在信息爆炸的时代,文本聚类成为了信息处理的重要任务之一。文本聚类可以帮助我们从海量的文本数据中提取有价值的信息和知识,这对于商业智能、搜索引擎、新闻推荐等应用具有重要的意义。然而,传统的文本聚类方法面临着许多挑战,比如需要手动选择特征、需要对文本进行预处理等。随着深度学习技术的发展,越来越多的研究者开始使用深度学习方法来解决文本聚类的问题。本文将介绍基于深度学习的文本聚类方法,讲解其原理,并结合实例代码进行演示。
1. 什么是文本聚类?
文本聚类是将相似的文本归为同一类别的任务。与分类不同,文本聚类不需要预先确定类别,而是根据文本数据的相似度来自动将文本分为不同的类别。文本聚类是无监督学习的一种形式,可以用于数据挖掘、信息检索、文本分类等任务。
2. 传统的文本聚类方法
传统的文本聚类方法通常涉及以下步骤:
1.特征选择:选择合适的文本特征表示方式。
2.相似度度量:根据文本特征之间的相似度度量来计算文本之间的相似度。
3.聚类算法:根据文本之间的相似度将文本聚类成不同的类别。
常见的文本聚类算法包括K-Means、层次聚类、密度聚类等。
然而,传统的文本聚类方法存在一些问题。首先,特征选择需要手动进行,需要领域专家参与,这一过程非常耗时且容易受到主观因素的影响;其次,传统的相似度度量方法无法充分捕捉文本之间的语义信息,因此在处理语义相似但表现形式不同的文本时会出现困难;最后,传统的聚类算法容易陷入局部最优解,而且聚类效果往往难以控制。
3. 基于深度学习的文本聚类方法
随着深度学习技术的发展,越来越多的研究者开始使用深度学习方法来解决文本聚类问题。基于深度学习的文本聚类方法可以概括为以下步骤:
-
文本表示:使用深度神经网络对文本进行表示学习,将文本映射到低维向量空间中。
-
相似度计算:计算不同文本在低维向量空间中的相似度。
-
聚类算法:根据相似度将文本聚类成不同的类别。
下面将详细介绍每一步骤。
- 文本表示
传统的文本表示方法通常使用词袋模型或TF-IDF来表示文本,这种方法将每个文本看作一个高维向量,每个维度表示一个词语在文本中出现的次数或TF-IDF值。但是,这种方法无法处理词语之间的语义关系,也无法捕捉文本的上下文信息。
为了解决这些问题,基于深度学习的文本聚类方法使用深度神经网络对文本进行表示学习,将文本映射到低维向量空间中。常用的文本表示方法包括:
-
Bag-of-Words (BOW):将文本看作一个无序的词集合,将每个词转换为一个向量,然后将所有向量加和,得到文本的向量表示。
-
Word Embedding:将每个词映射到一个低维向量空间中,这个空间是通过神经网络从大规模文本数据中学习得到的。通过将词向量加和或求平均值,可以得到文本的向量表示。
-
Convolutional Neural Networks (CNNs):通过卷积操作和池化操作,CNNs能够自动学习文本中的局部特征,并将它们组合成整体特征,得到文本的向量表示。
-
Recurrent Neural Networks (RNNs):通过循环神经网络结构,RNNs能够捕捉文本的上下文信息,并得到文本的向量表示。
-
Transformer:通过自注意力机制,Transformer能够处理文本中的长距离依赖关系,并得到文本的向量表示。
- 相似度计算
计算文本之间的相似度是文本聚类的关键步骤。在基于深度学习的文本聚类中,一般采用余弦相似度或欧几里得距离来计算文本之间的相似度。
余弦相似度是一种常用的相似度计算方法,它可以在低维向量空间中度量向量之间的夹角。
- 聚类算法
聚类算法是将相似的文本归为同一类别的核心步骤。在基于深度学习的文本聚类中,常用的聚类算法包括:
- K-Means:K-Means是一种基于距离的聚类算法,它将文本聚类成K个不同的类别,其中K是用户指定的聚类数目。K-Means的算法流程为:
-
随机选择K个中心点;
-
对于每个文本,将其分配到与之最近的中心点所代表的类别中;
-
对于每个类别,重新计算其中心点的位置;
-
重复步骤2-3,直到中心点不再发生变化。
- 层次聚类:层次聚类是一种自底向上的聚类算法,它将每个文本都看作一个初始的类别,并逐步合并相似的类别,直到所有文本都被聚类到一个类别中。层次聚类的算法流程为:
-
计算每个文本之间的相似度;
-
将每个文本看作一个初始的类别;
-
重复步骤4-5,直到所有文本都被聚类到一个类别中。
-
寻找相似度最高的两个类别,并将它们合并成一个新的类别;
-
重新计算新类别与其他类别之间的相似度。
- 密度聚类:密度聚类是一种基于密度的聚类算法,它将文本聚类成不同的密度区域。密度聚类的核心思想是,聚类的区域应该满足一定的密度要求,即密度高于某个阈值。密度聚类的算法流程为:
-
计算每个文本之间的密度;
-
标记每个文本是否为核心点、边界点或噪声点;
-
对于每个核心点,以其为中心构建一个聚类簇;
-
对于每个边界点,将其归属到与之距离最近的核心点所代表的聚类簇中;
-
去除所有噪声点。
4. 结合代码讲解
下面我们将结合代码来演示基于深度学习的文本聚类方法。我们将使用Python编程语言以及深度学习框架Keras来实现一个简单的文本聚类应用。具体流程如下:
-
准备数据集:我们将使用20 Newsgroups数据集来演示文本聚类。该数据集共有20个不同的新闻组,每个组包含数百条新闻。我们将选择其中的5个组作为聚类的对象。
-
文本预处理:我们将使用NLTK库来进行文本预处理,包括分词、去除停用词、词形还原等。
-
文本表示:我们将使用Word Embedding方法来表示文本。我们将使用Keras提供的Embedding层来实现这个过程。
-
相似度计算:我们将使用余弦相似度来计算文本之间的相似度。
-
聚类算法:我们将使用K-Means算法来将文本聚类成5个不同的类别。
下面是完整的代码实现:
import numpy as np
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import TruncatedSVD
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from keras.layers import Input, Embedding, Flatten, Dense
from keras.models import Model
from keras.optimizers import Adam
from sklearn.cluster import KMeans
from sklearn.metrics.pairwise import cosine_similarity# 准备数据集
newsgroups = fetch_20newsgroups(subset='all', categories=['rec.autos', 'rec.motorcycles', 'rec.sport.baseball', 'rec.sport.hockey', 'sci.med'])
data = newsgroups.data# 文本预处理
stop_words = set(stopwords.words('english'))
lemmatizer = WordNetLemmatizer()def preprocess(text):tokens = word_tokenize(text.lower())tokens = [lemmatizer.lemmatize(token) for token in tokens if token.isalpha() and token not in stop_words]return " ".join(tokens)data = [preprocess(text) for text in data]# 文本表示
vectorizer = CountVectorizer(max_features=10000)
X = vectorizer.fit_transform(data)svd = TruncatedSVD(n_components=300, n_iter=10, random_state=42)
X = svd.fit_transform(X)# 构建模型
input_layer = Input(shape=(300,))
embedding_layer = Embedding(input_dim=300, output_dim=128)(input_layer)
flatten_layer = Flatten()(embedding_layer)
output_layer = Dense(units=5, activation='softmax')(flatten_layer)model = Model(inputs=input_layer, outputs=output_layer)
model.compile(optimizer=Adam(lr=0.001), loss='categorical_crossentropy')# 训练模型
y = KMeans(n_clusters=5).fit_predict(X)
y = np.eye(5)[y]model.fit(X, y, batch_size=128, epochs=10, verbose=1)# 聚类结果展示
similarities = cosine_similarity(X)
for i in range(5):cluster = np.where(y[:,i] == 1)[0]cluster_similarities = similarities[cluster][:,cluster]cluster_center = np.argmax(np.mean(cluster_similarities, axis=0))cluster_texts = [data[j] for j in cluster if j != cluster_center]print(f"Cluster {i+1}: {len(cluster_texts)} texts")for j, text in enumerate(cluster_texts[:10]):print(f"\t{j+1}. {text}")
代码中,我们首先准备数据集,选择20 Newsgroups数据集中的5个组作为聚类的对象。然后使用NLTK库进行文本预处理,包括分词、去除停用词、词形还原等。接着使用CountVectorizer和TruncatedSVD进行文本表示,将文本映射到低维向量空间中。接下来构建模型,使用Keras的Embedding层将文本向量表示为向量序列,然后使用全连接层将向量序列压缩为一个向量,并使用Softmax层将该向量分类为5个不同的类别。最后使用K-Means算法将文本聚类成5个不同的类别。
在训练完模型后,我们使用余弦相似度计算文本之间的相似度,并将每个文本分配到最相似的类别中。最后,我们将聚类结果输出,并展示每个聚类簇中的前10个文本。
5. 总结
本文介绍了基于深度学习的文本聚类方法,讲解了其原理,并结合实例代码进行了演示。与传统的文本聚类方法相比,基于深度学习的文本聚类方法能够自动学习文本特征表示,不需要手动选择特征,并且能够充分捕捉文本之间的语义信息,从而提高聚类的效果。如果您正在处理大量文本数据,可以考虑使用基于深度学习的文本聚类方法来提高工作效率。
相关文章:
深度学习与文本聚类:一篇全面的介绍与实践指南
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️ 👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…...
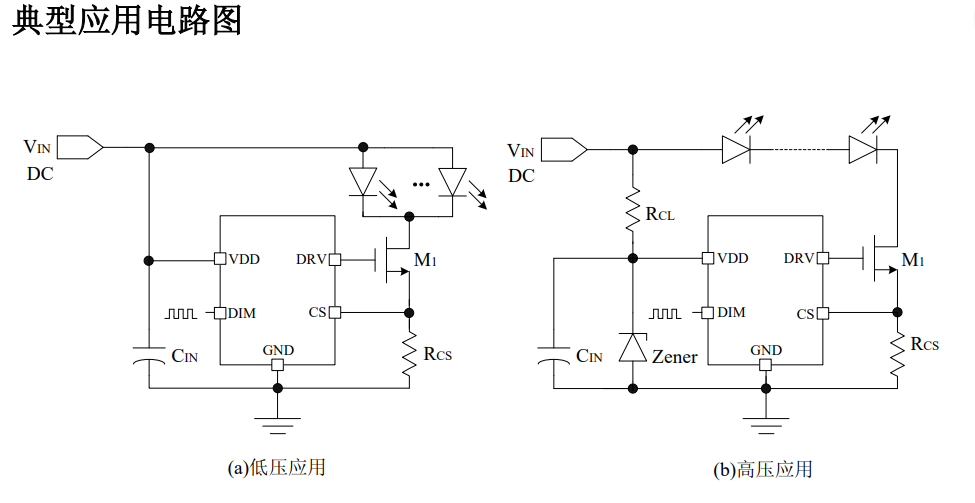
AP5153 线性降压恒流驱动芯片 2.5A
AP5153 是一种 PWM 调光的、低压 差的 LED 线性降压恒流驱动器。 AP5153 仅需要外接一个电阻和一个 NMOS 管就可以构成一个完整的 LED 恒 流驱动电路, 调节该外接电阻就可以调节 输出电流,输出电流可调范围为 20mA 到 3.0A。 AP5153 还可以通过在 DIM…...
)
Unity物理系统脚本编程(下)
一、修改物理材质 Unity对物体表面材料的性质做了件化处理,仅有5种常用属性: Dynamic Friction(动态摩擦系数)Static Friction(静态摩擦系数)Bounciness(弹性系数)Friction Combine…...

容器技术的发展
容器技术的发展 近年来,随着计算机硬件、网络以及云计算等技术的迅速发展,云原生的概念也越来越受到业界人士的广泛关注,越来越多的应用场景开始拥抱云原生,其中容器技术的发展起着至关重要的作用。本章将介绍容器技术的基础知识…...

Python Flask request中常见存储参数的介绍
Python Flask request中常见存储参数的介绍 首先从flask模块中导入请求对象: from flask import requestrequest.form 通过method属性可以操作当前请求方法,通过使用form属性处理表单数据(本质也是得到一个字典,如果传输的是字…...

php+vue网盘系统的设计与实现
该网盘系统的开发和设计根据用户的实际情况出发,对系统的需求进行了详细的分析,然后进行系统的整体设计,最后通过测试使得系统设计的更加完整,可以实现系统中所有的功能,在开始编写论文之前亲自到图书馆借阅php书籍&am…...
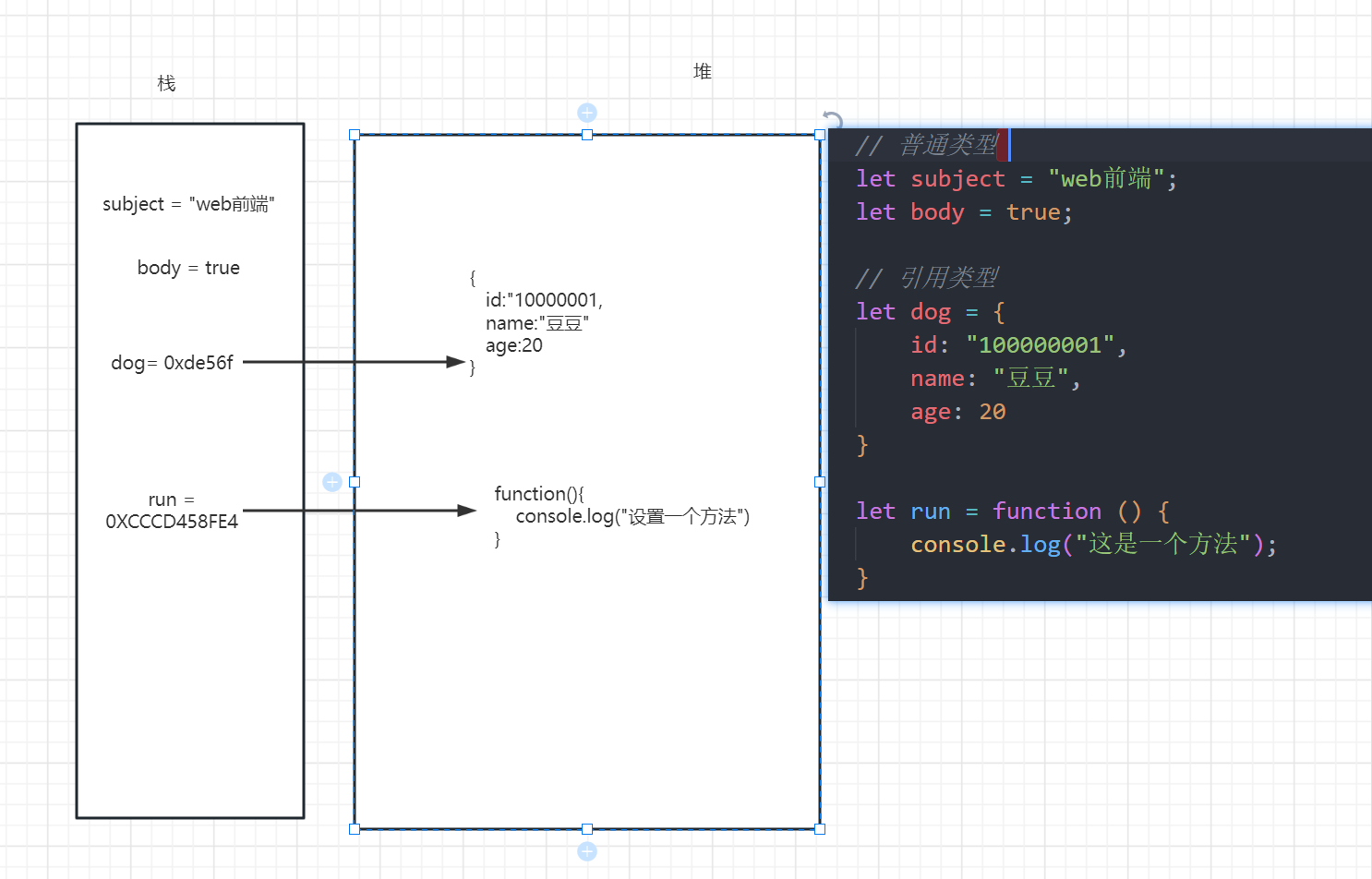
[前端]深浅拷贝
一、回顾变量类型 基础类型 boolean(bool) number string null undefined 引用类型 object function array 基本类型与引用类型的存储 基本类型一般存储在 栈 (栈小) 栈一旦确认 大小就固定 可能会造成溢出栈一般是先进后出用于存储…...

文章纠错免费软件-文字校对软件免费下载
自动校对稿件的软件 自动校对稿件的软件是一种基于自然语言处理(Natural Language Processing, NLP)和机器学习(Machine Learning)技术的工具,可以较为准确地检测和纠正文本中出现的语法、拼写、标点符号以及其他笔误…...

【Redis】Redis缓存雪崩、缓存穿透、缓存击穿(热key问题)
目录 一、缓存穿透 1、概念 2、解决办法 1.缓存空对象 2.布隆过滤 二、缓存雪崩 1、概念 2、解决办法 1.给key设置随机的过期时间TTL 2.业务添加多级缓存 3.利用集群提供服务可用性 4.缓存业务添加降级限流 三、缓存击穿 1、概念 2、解决办法 1.互斥锁 2.逻辑…...

为什么很多程序员喜欢linux系统?
a> Linux哪些行业在运用? Linux系统运用极其广泛,不少用户只知道windows,是因为,Linux的运用主要是在企业端。现在科技极其发达,我们手机在手,就能干很多事情,只需点一点屏幕,轻松…...
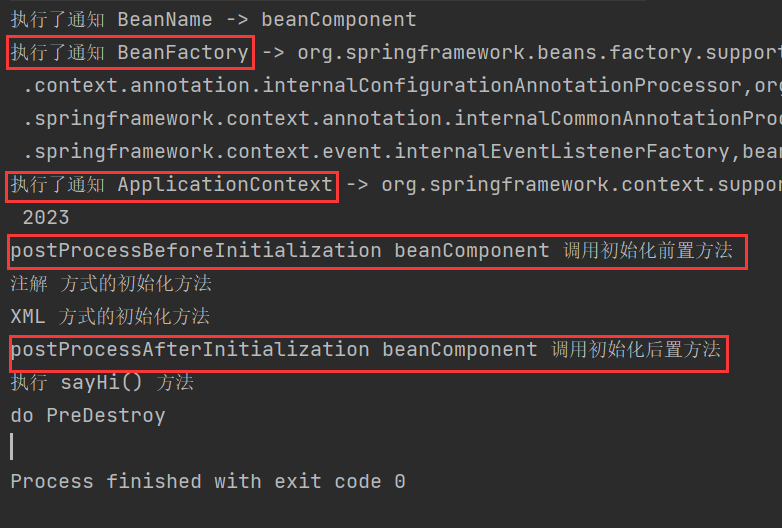
Bean 作用域和生命周期
✏️作者:银河罐头 📋系列专栏:JavaEE 🌲“种一棵树最好的时间是十年前,其次是现在” 目录 lombok的使用案例引入作用域定义singleton单例作用域prototype原型作用域(多例作用域)request请求作用域session会话作用域ap…...

PMP考试常见13个固定套路
一、变更批准之后 变更批准后要做三件事: 1、在变更日志中记录 2、通知相关干系人 3、更新项目管理计划 二、风险的情景题 1、先判断风险识别了,还是风险发生了。 2、若是风险识别,按风险管理程序走; 3、若是风险发生,则应采取应急措施…...
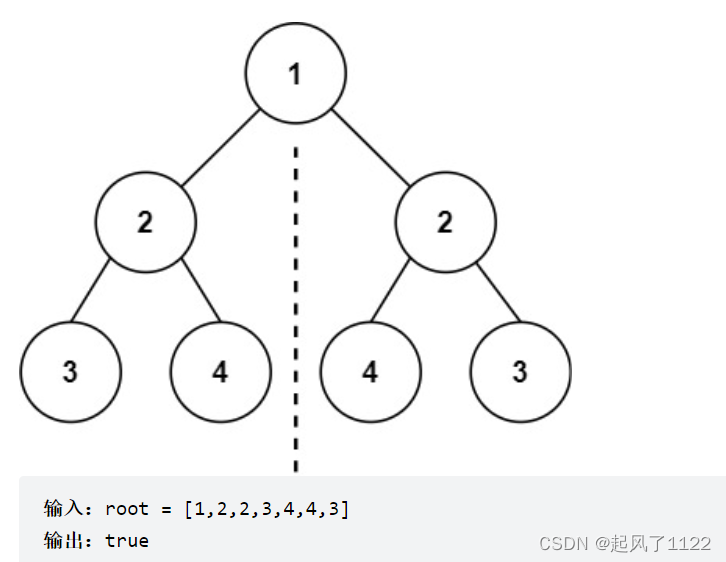
Leecode101 ——对称二叉树
对称二叉树:Leecode 101 leecode 101 对称二叉树 根据题目描述,首先想清楚,对称二叉树要比较的是哪两个节点。对于二叉树是否对称,要比较的是根节点的左子树与根节点的右子树是不是相互翻转的,其实也就是比较两个树,…...
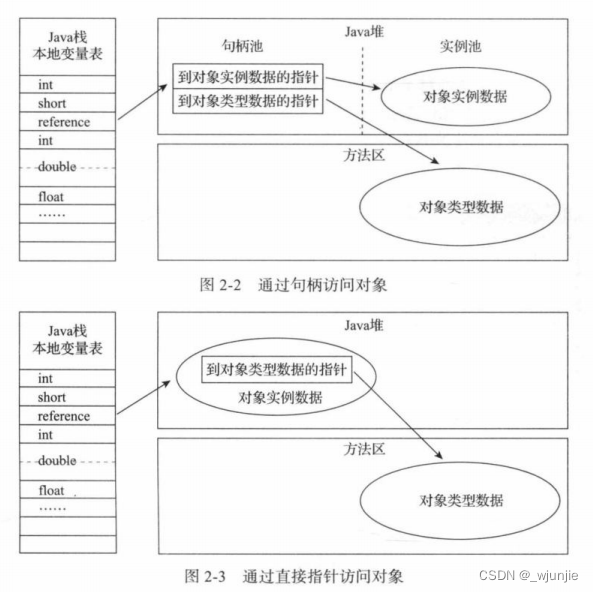
JVM学习随笔03——Java堆中new一个对象的步骤
目录 一、进行类加载 二、堆中分配内存 1、怎么输出GC日志: 2、内存分配的两种方式: 3、内存分配过程中并发控制的两种方式: 三、内存空间初始化 四、对象头初始化(对象头包含哪些信息?) 五、执行构…...
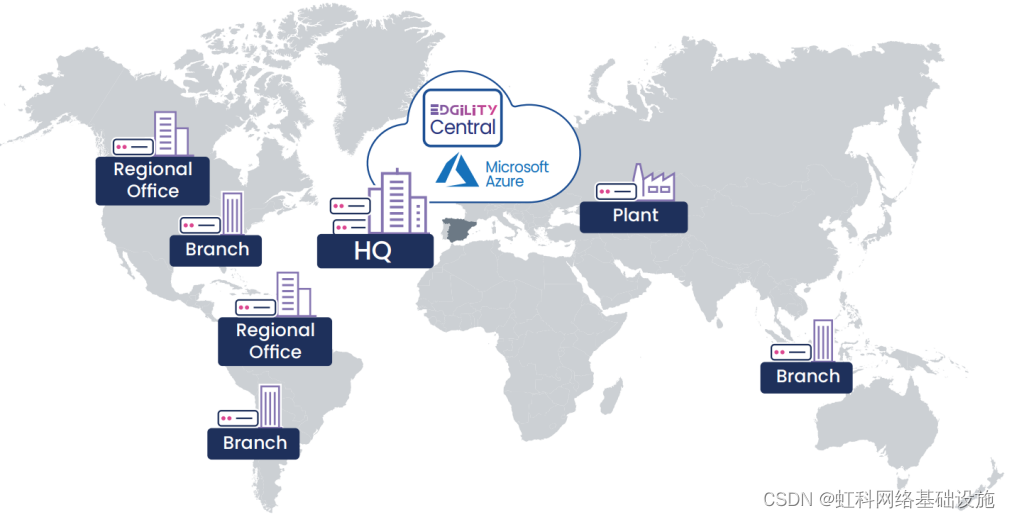
虹科方案 | CEMEX 使用HK-Edgility 智能边缘计算平台简化其企业 WAN 管理和运营
一、应对价值 130 亿美元的跨国企业的网络挑战 “我们选择 Edgility 是因为其卓越的管理和协调功能,它为我们提供了一个端到端的工具集,可以经济高效地部署和管理我们边缘设备的生命周期。” —— Fernando Garcia -Villaraco Casero, CEMEX 全球IT 战略…...

rk3568 系统移植和编译
1。 硬件问题 尽量根据原版 evb 开发版 pcb 进行布线和移植,切记不可自行走线。 emmc 和 ddr4 选型都有要求的,按照硬件手册进行设计 2。软件问题 2.1 目前固件系统选用1.3.2 版本进行设计 解压后运行 .repo/repo/repo sync -c 更新代码 2.2 ubo…...

深度解析C++异常处理机制:分类、处理方式、常见错误及11新增功能
C 基础知识 八 异常处理 上篇 一、基础1. 异常的概念2. 异常的分类2.1 内置异常2.2 自定义异常 3. 异常的处理方式3.1 try-catch 语句3.2 throw 语句3.3 noexcept 修饰符3.4 finally 语句块 二、 异常处理机制1 try-catch 语句块2 异常处理流程3 标准异常类 三、 抛出异常1 thr…...
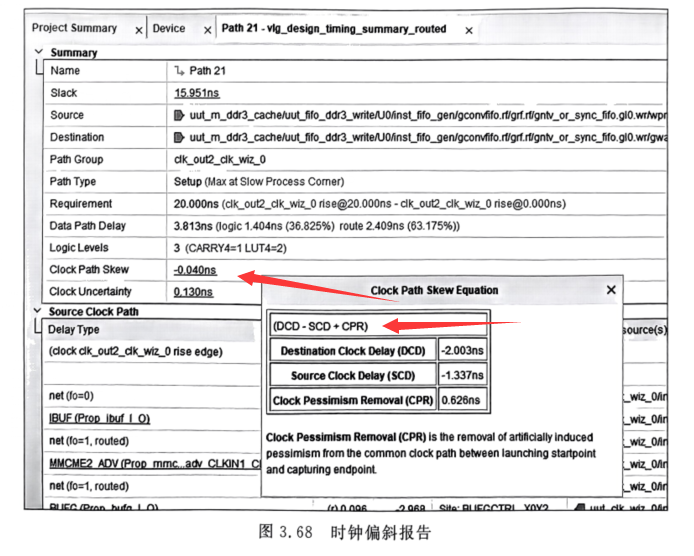
FPGA时序约束(四)主时钟、虚拟时钟和时钟特性的约束
系列文章目录 FPGA时序约束(一)基本概念入门及简单语法 FPGA时序约束(二)利用Quartus18对Altera进行时序约束 FPGA时序约束(三)时序约束基本路径的深入分析 文章目录 系列文章目录前言主时钟约束跨时钟域…...

JNI开发
文件结构(选中的为生成的) CMake构建不需要执行命令,会自动生成so文件打包进apk Android mk构建需要执行命令生成so文件,再打包进apk。命令如下。 # 在jni目录下执行 # 生成com_demo_cppproject_OtherNdkTest.h头文件 javac -h .…...

JAVA有哪些特点?
JAVA有以下特点: 综上所述,Java作为一种先进的面向对象编程语言,具有简单、可移植、健壮、高性能、多线程、动态性、跨平台、开放性和安全性等众多特点,已经成为广泛使用的编程语言之一。 简单易学:JAVA语言的语法与C语…...

量子计算中Loschmidt回声相位测量的创新方法
1. 量子计算中的Loschmidt回声相位测量方法概述Loschmidt回声是量子动力学中一个重要的概念,它描述了量子系统在时间反演演化后与初始状态的相似程度。在量子计算领域,精确测量Loschmidt回声的相位信息对于理解量子系统的非平衡态行为、计算能量本征值以…...

写论文的神助攻!好用的AI写作辅助软件,逻辑清晰质量高
作为一名刚完成毕业论文的过来人,我太懂写论文的痛苦了 —— 选题迷茫、文献浩如烟海、框架混乱、逻辑不清、反复修改、查重降重反复折腾... 直到我发现了这套 AI 写作工具组合,简直是论文写作的 "开挂神器",效率直接拉满ÿ…...
)
Claude端到端测试设计:从零搭建可审计、可回放、可量化的AI服务测试流水线(含开源Schema校验工具)
更多请点击: https://codechina.net 第一章:Claude端到端测试设计 端到端测试是验证Claude模型在真实用户交互链路中行为一致性的关键手段。它覆盖从原始提示输入、上下文管理、流式响应生成,到输出解析与业务校验的全路径,确保模…...
)
告别硬编码!在UE5.1里用蓝图动态配置MySQL连接参数(控件蓝图实战)
动态配置MySQL连接:UE5.1控件蓝图的工程化实践在游戏开发中,数据库连接往往是项目架构中不可或缺的一环。传统硬编码方式虽然简单直接,却带来了维护困难、安全性差、灵活性低等一系列问题。本文将深入探讨如何在UE5.1中构建一个完全动态化的M…...

Raspberry Pi Debug Probe:RP2040嵌入式开发的调试利器与实战指南
1. 项目概述:为什么你需要一个Raspberry Pi Debug Probe?如果你玩过树莓派Pico或者任何基于RP2040芯片的开发板,肯定遇到过这样的场景:写好的代码,点一下“上传”,然后……就没有然后了。板子上的LED没按你…...
)
【Veo 2提示词SOP白皮书】:从模糊意图到像素级输出的8步标准化工作流(附NASA级测试用例库)
更多请点击: https://intelliparadigm.com 第一章:Veo 2提示词工程的本质与范式跃迁 Veo 2并非单纯升级的视频生成模型,而是一次提示词工程范式的根本性重构——它将传统“指令式提示”(prompt-as-command)转向“意图…...

【2026实测】怎么提高论文原创度?盘点8款主流降AI工具,附结构级优化指南
写文章最怕碰到什么,是辛辛苦苦自己码出来的字,却被标了极高的AI值。目前很多文本审核机制对内容的原创度要求极高,纯手写的初稿也可能因为句式太工整被判定为机器生成的。 为了帮几个快被这事折腾疯了的学弟学妹找条出路,我花了…...
)
别再纠结了!给激光焊接新手讲透单模和多模激光到底怎么选(附M²因子解读)
激光焊接设备选型指南:单模与多模激光的实战抉择 当你第一次站在激光焊接设备采购的十字路口,面对"单模"和"多模"这两个专业术语时,那种迷茫感我深有体会。五年前,我作为产线技术负责人,需要为汽车…...
和Python脚本,5分钟批量生成你的分割数据集)
告别手动标注!用SAM(Segment Anything)和Python脚本,5分钟批量生成你的分割数据集
5分钟批量生成分割数据集:SAM自动化标注全流程实战 在计算机视觉领域,数据标注一直是制约模型开发效率的瓶颈。传统手工标注不仅耗时费力,还容易引入人为误差。Meta开源的Segment Anything Model(SAM)彻底改变了这一局…...

让B站缓存视频重获自由:一个简单实用的格式转换工具
让B站缓存视频重获自由:一个简单实用的格式转换工具 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 还记得那个周末的下午吗…...