Redis 布隆过滤器总结
Redis 布隆过滤器总结
适用场景
大数据判断是否存在来实现去重:这就可以实现出上述的去重功能,如果你的服务器内存足够大的话,那么使用 HashMap 可能是一个不错的解决方案,理论上时间复杂度可以达到 O(1) 的级别,但是当数据量起来之后,还是只能考虑布隆过滤器。
解决缓存穿透:我们经常会把一些热点数据放在 Redis 中当作缓存,例如产品详情。通常一个请求过来之后我们会先查询缓存,而不用直接读取数据库,这是提升性能最简单也是最普遍的做法,但是 如果一直请求一个不存在的缓存,那么此时一定不存在缓存,那就会有大量请求直接打到数据库上,造成 缓存穿透,布隆过滤器也可以用来解决此类问题。
在我们使用 Redis 时候,经常会面临这么一个问题,缓存穿透,意思是数据库和 redis 中都没有数据,缓存和db完全形同虚设。
面对这种问题,我们一般解决办法是设置null 的空值缓存,还有优雅点的实现方式就是布隆过滤器。
空值缓存
String key = stringRedisTemplate.opsForValue().get("key");if (StringUtil.isEmpty(key)){//查询dbObject k = "test";if (k!=null){//存redisstringRedisTemplate.opsForValue().set("key",k.toString(),100);return k.toString();}else {stringRedisTemplate.opsForValue().set("key","nullstr",10);return "";}}if ("nullstr".equals(key)){stringRedisTemplate.opsForValue().set("key","nullstr",10);return "";}
布隆过滤器
对于恶意攻击,向服务器请求大量不存在的数据造成的缓存穿透,还可以用布隆过滤器先做一次过滤,对于不 存在的数据布隆过滤器一般都能够过滤掉,不让请求再往后端发送。当布隆过滤器说某个值存在时,这个值可 能不存在;当它说不存在时,那就肯定不存在。
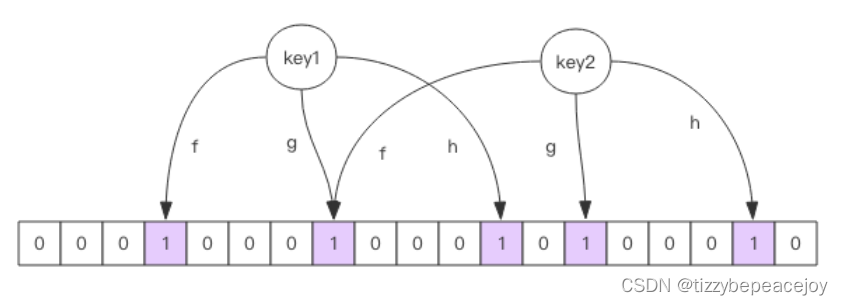
使用布隆过滤器需要把所有数据提前放入布隆过滤器,并且在增加数据时也要往布隆过滤器里放,使用时候不能删除,如果有必须重新初始化。
实现原理
布隆过滤器就是一个大型的位数组和几个不一样的无偏 hash 函数。
所谓无偏就是能够把元素的 hash 值算得 比较均匀。
向布隆过滤器中添加 key 时,会使用多个 hash 函数对 key 进行 hash 算得一个整数索引值然后对位数组长度 进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就 完成了 add 操作。
向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出来,看看位数组中这几个位 置是否都为 1,只要有一个位为 0,那么说明布隆过滤器中这个key 不存在。
如果都是 1,这并不能说明这个 key 就一定存在,只是极有可能存在,因为这些位被置为 1 可能是因为其它的 key 存在所致。如果这个位数组 比较稀疏,这个概率就会很大,如果这个位数组比较拥挤,这个概率就会降低。
这种方法适用于数据命中不高、 数据相对固定、 实时性低(通常是数据集较大) 的应用场景, 代码维护较为 复杂, 但是缓存空间占用很少。
布隆过滤器的优点:
-
时间复杂度低,增加和查询元素的时间复杂为O(N),(N为哈希函数的个数,通常情况比较小)
-
保密性强,布隆过滤器不存储元素本身
-
存储空间小,如果允许存在一定的误判,布隆过滤器是非常节省空间的(相比其他数据结构如Set集合)
布隆过滤器的缺点:
- 有点一定的误判率,但是可以通过调整参数来降低
- 无法获取元素本身
- 很难删除元素
数据结构
布隆过滤器它实际上是一个很长的二进制向量和一系列随机映射函数。以Redis中的布隆过滤器实现为例,Redis中的布隆过滤器底层是一个大型位数组(二进制数组)+多个无偏hash函数。
一个大型位数组(二进制数组):

多个无偏hash函数:
无偏hash函数就是能把元素的hash值计算的比较均匀的hash函数,能使得计算后的元素下标比较均匀的映射到位数组中。
如下就是一个简单的布隆过滤器示意图,其中k1、k2代表增加的元素,a、b、c即为无偏hash函数,最下层则为二进制数组。
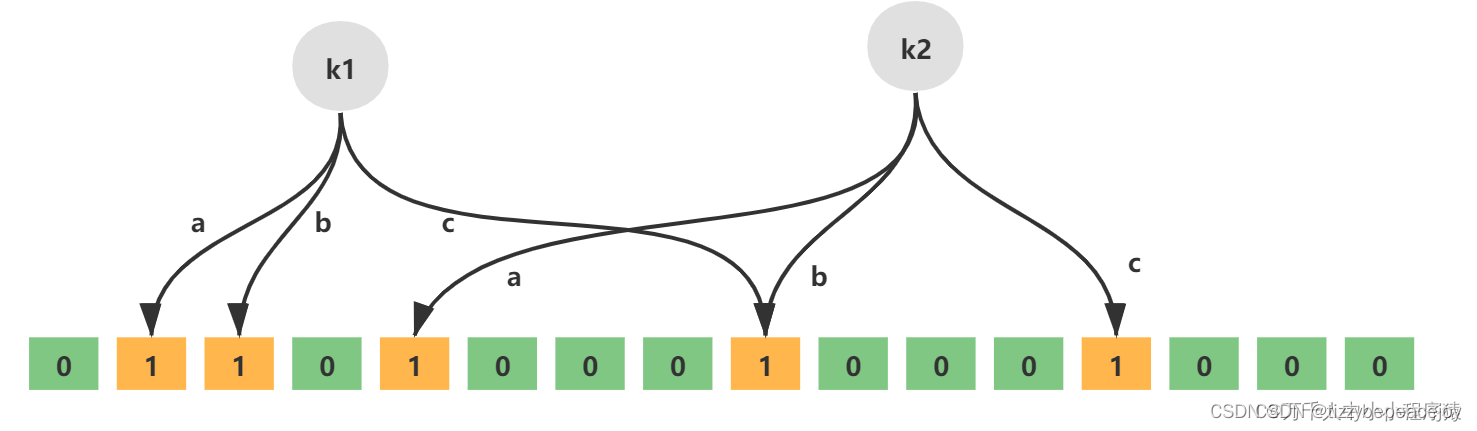
增加元素的步骤:
通过k个无偏hash函数计算得到k个hash值
依次取模数组长度,得到数组索引
将计算得到的数组索引下标位置数据修改为1
查询元素的步骤:
布隆过滤器最大的用处就在于判断某样东西一定不存在或者可能存在,而这个就是查询元素的结果。其查询元素的过程如下:
通过k个无偏hash函数计算得到k个hash值
依次取模数组长度,得到数组索引
判断索引处的值是否全部为1,如果全部为1则存在(这种存在可能是误判),如果存在一个0则必定不存在
误判的情况: hash函数无法完全避免hash冲突,可能会存在多个元素计算的hash值是相同的,那么它们取模数组长度后的到的数组索引也是相同的,这就是误判的原因。例如彭于晏和程序员(莫打我)的hash值取模后得到的数组索引都是1,但实际上存储的只有彭于晏,如果此时判断程序员在不在这里,误判就出现啦!因此布隆过滤器最大的缺点误判只要知道其判断元素是否存在的原理就很容易明白了!
布隆过滤器不支持删除元素。
代码演示
使用redisson
可以用redisson实现布隆过滤器,引入依赖
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.6.5</version></dependency>
实例代码
单Redis节点模式
Config config = new Config();config.useSingleServer().setAddress("redis://localhost:6379");//构造RedissonRedissonClient redisson = Redisson.create(config);RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");//初始化布隆过滤器:预计元素为 100000L ,误差率为3%,根据这两个参数会计算出底层的bit数组大小bloomFilter.tryInit(100000L,0.03);//将 test 插入到布隆过滤器中bloomFilter.add("test");bloomFilter.add("test2");//判断下面号码是否在布隆过滤器中System.out.println(bloomFilter.contains("test3"));//falseSystem.out.println(bloomFilter.contains("test4"));//falseSystem.out.println(bloomFilter.contains("test2"));//trueSystem.out.println(bloomFilter.count()); // 2个元素System.out.println(bloomFilter.getSize()); // 长度
yaml 配置
---
singleServerConfig:idleConnectionTimeout: 10000connectTimeout: 10000timeout: 3000retryAttempts: 3retryInterval: 1500password: nullsubscriptionsPerConnection: 5clientName: nulladdress: "redis://127.0.0.1:6379"subscriptionConnectionMinimumIdleSize: 1subscriptionConnectionPoolSize: 50connectionMinimumIdleSize: 32connectionPoolSize: 64database: 0dnsMonitoringInterval: 5000
threads: 0
nettyThreads: 0
codec: !<org.redisson.codec.JsonJacksonCodec> {}
"transportMode":"NIO"
集群配置
Config config = new Config();
config.useClusterServers().setScanInterval(2000) // 集群状态扫描间隔时间,单位是毫秒//可以用"rediss://"来启用SSL连接.addNodeAddress("redis://127.0.0.1:7000", "redis://127.0.0.1:7001").addNodeAddress("redis://127.0.0.1:7002");RedissonClient redisson = Redisson.create(config);
yaml配置
配置集群模式可以通过指定一个YAML格式的文件来实现。以下是YAML格式的配置文件样本。文件中的字段名称必须与ClusterServersConfig和Config对象里的字段名称相符。
---
clusterServersConfig:idleConnectionTimeout: 10000connectTimeout: 10000timeout: 3000retryAttempts: 3retryInterval: 1500password: nullsubscriptionsPerConnection: 5clientName: nullloadBalancer: !<org.redisson.connection.balancer.RoundRobinLoadBalancer> {}slaveSubscriptionConnectionMinimumIdleSize: 1slaveSubscriptionConnectionPoolSize: 50slaveConnectionMinimumIdleSize: 32slaveConnectionPoolSize: 64masterConnectionMinimumIdleSize: 32masterConnectionPoolSize: 64readMode: "SLAVE"nodeAddresses:- "redis://127.0.0.1:7004"- "redis://127.0.0.1:7001"- "redis://127.0.0.1:7000"scanInterval: 1000
threads: 0
nettyThreads: 0
codec: !<org.redisson.codec.JsonJacksonCodec> {}
"transportMode":"NIO"
哨兵配置
Config config = new Config();
config.useSentinelServers().setMasterName("mymaster")//可以用"rediss://"来启用SSL连接.addSentinelAddress("127.0.0.1:26389", "127.0.0.1:26379").addSentinelAddress("127.0.0.1:26319");RedissonClient redisson = Redisson.create(config);
yaml
配置哨兵模式可以通过指定一个YAML格式的文件来实现。以下是YAML格式的配置文件样本。文件中的字段名称必须与SentinelServersConfig和Config对象里的字段名称相符。
---
sentinelServersConfig:idleConnectionTimeout: 10000connectTimeout: 10000timeout: 3000retryAttempts: 3retryInterval: 1500password: nullsubscriptionsPerConnection: 5clientName: nullloadBalancer: !<org.redisson.connection.balancer.RoundRobinLoadBalancer> {}slaveSubscriptionConnectionMinimumIdleSize: 1slaveSubscriptionConnectionPoolSize: 50slaveConnectionMinimumIdleSize: 32slaveConnectionPoolSize: 64masterConnectionMinimumIdleSize: 32masterConnectionPoolSize: 64readMode: "SLAVE"sentinelAddresses:- "redis://127.0.0.1:26379"- "redis://127.0.0.1:26389"masterName: "mymaster"database: 0
threads: 0
nettyThreads: 0
codec: !<org.redisson.codec.JsonJacksonCodec> {}
"transportMode":"NIO"
主从模式
Config config = new Config();
config.useMasterSlaveServers()//可以用"rediss://"来启用SSL连接.setMasterAddress("redis://127.0.0.1:6379").addSlaveAddress("redis://127.0.0.1:6389", "redis://127.0.0.1:6332", "redis://127.0.0.1:6419").addSlaveAddress("redis://127.0.0.1:6399");RedissonClient redisson = Redisson.create(config);
yaml
配置主从模式可以通过指定一个YAML格式的文件来实现。以下是YAML格式的配置文件样本。文件中的字段名称必须与MasterSlaveServersConfig和Config对象里的字段名称相符。
---
masterSlaveServersConfig:idleConnectionTimeout: 10000connectTimeout: 10000timeout: 3000retryAttempts: 3retryInterval: 1500failedAttempts: 3password: nullsubscriptionsPerConnection: 5clientName: nullloadBalancer: !<org.redisson.connection.balancer.RoundRobinLoadBalancer> {}slaveSubscriptionConnectionMinimumIdleSize: 1slaveSubscriptionConnectionPoolSize: 50slaveConnectionMinimumIdleSize: 32slaveConnectionPoolSize: 64masterConnectionMinimumIdleSize: 32masterConnectionPoolSize: 64readMode: "SLAVE"slaveAddresses:- "redis://127.0.0.1:6381"- "redis://127.0.0.1:6380"masterAddress: "redis://127.0.0.1:6379"database: 0
threads: 0
nettyThreads: 0
codec: !<org.redisson.codec.JsonJacksonCodec> {}
"transportMode":"NIO"
详细配置 https://github.com/redisson/redisson/wiki/2.-%E9%85%8D%E7%BD%AE%E6%96%B9%E6%B3%95#241-%E9%9B%86%E7%BE%A4%E8%AE%BE%E7%BD%AE
使用Google 开源的 Guava 中自带的布隆过滤器
依赖
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>28.0-jre</version></dependency>代码实例
// 创建布隆过滤器对象BloomFilter<Integer> filter = BloomFilter.create(Funnels.integerFunnel(),1000,0.01);
// 判断指定元素是否存在System.out.println(filter.mightContain(1));System.out.println(filter.mightContain(2));
// 将元素添加进布隆过滤器filter.put(1);filter.put(2);System.out.println(filter.mightContain(1));System.out.println(filter.mightContain(2));
在我们的示例中,当 mightContain() 方法返回 true 时,我们可以 99% 确定该元素在过滤器中,当过滤器返回 false 时,我们可以 100% 确定该元素不存在于过滤器中。
Guava 提供的布隆过滤器的实现还是很不错的 ,但是它是单机使用 ,如果是分布式的场景,需要用到 Redis 中的布隆过滤器了
相关文章:
Redis 布隆过滤器总结
Redis 布隆过滤器总结 适用场景 大数据判断是否存在来实现去重:这就可以实现出上述的去重功能,如果你的服务器内存足够大的话,那么使用 HashMap 可能是一个不错的解决方案,理论上时间复杂度可以达到 O(1) 的级别,但是…...

云基础设施安全:7个保护敏感数据的最佳实践
导语:云端安全防护进行时! 您的组织可能会利用云计算的实际优势:灵活性、快速部署、成本效益、可扩展性和存储容量。但是,您是否投入了足够的精力来确保云基础设施的网络安全? 您应该这样做,因为数据泄露、…...

centos7安装nginx
1.配置环境 1).gcc yum install -y gcc2).安装第三方库 pcre-devel yum install -y pcre pcre-devel3).安装第三方库 zlib yum install -y zlib zlib-devel2.下载安装包并解压 nginx官网下载:http://nginx.org/en/download.html 或者 使用wget命令进行下载 wg…...
PyQt5 基础篇(一)-- 安装与环境配置
1 PyQt5 图形界面开发工具 Qt 库是跨平台的 C 库的集合,是最强大的 GUI 库之一,可以实现高级 API 来访问桌面和移动系统的各种服务。PyQt5 是一套 Python 绑定 Digia QT5 应用的框架。PyQt5 实现了一个 Python模块集,有 620 个类,…...
Java—JDK8新特性—函数式接口【内含思维导图】
目录 3.函数式接口 思维导图 3.1 什么是函数式接口 3.2 functionalinterface注解 源码分析 3.3 Lambda表达式和函数式接口关系 3.4 使用函数式接口 3.5 内置函数式接口 四大核的函数式接口区别 3.5.1 Supplier 函数式接口源码分析 3.5.2 Supplier 函数式接口使用 3.…...
【MySQL】外键约束和外键策略
一、什么是外键约束? 外键约束(FOREIGN KEY,缩写FK)是用来实现数据库表的参照完整性的。外键约束可以使两张表紧密的结合起来,特别是针对修改或者删除的级联操作时,会保证数据的完整性。 外键是指表…...
3. SQL底层执行原理详解
一条SQL在MySQL中是如何执行的 1. MySQL的内部组件结构1.1 Server层1.2 Store层 2. 连接器3. 分析器4. 优化器5. 执行器6. bin-log归档 本文是按照自己的理解进行笔记总结,如有不正确的地方,还望大佬多多指点纠正,勿喷。 1. MySQL的内部组件结…...
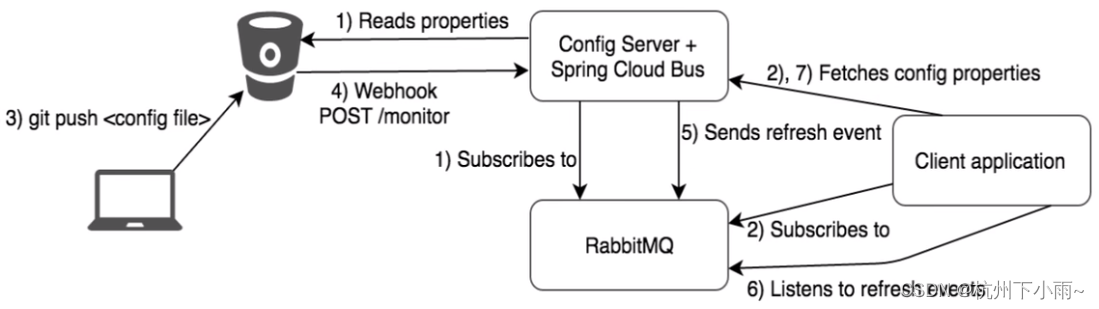
Bus动态刷新
Bus动态刷新全局广播配置实现 启动 EurekaMain7001ConfigcenterMain3344ConfigclientMain3355ConfigclicntMain3366 运维工程师 修改Gitee上配置文件内容,增加版本号发送POST请求curl -X POST "http://localhost:3344/actuator/bus-refresh" —次发送…...

逆波兰式的写法
一、什么是波兰式,逆波兰式和中缀表达式 6 *(37) -2 将运算数放在数值中间的运算式叫做中缀表达式 - * 6 3 7 2 将运算数放在数值前间的运算式叫做前缀表达式 6 3 7 * 2 - 将运算数放在数值后间的运算式叫做后缀表达式 二、生成逆波兰表达式 6 *(37) -2 生成…...

Linux系统日志介绍
Linux系统日志都是放在“/var/log”目录下面,各个日志文件的功能: /var/log/messages — 包括整体系统信息,其中也包含系统启动期间的日志。此外,mail,cron,daemon,kern和auth等内容也记录在va…...
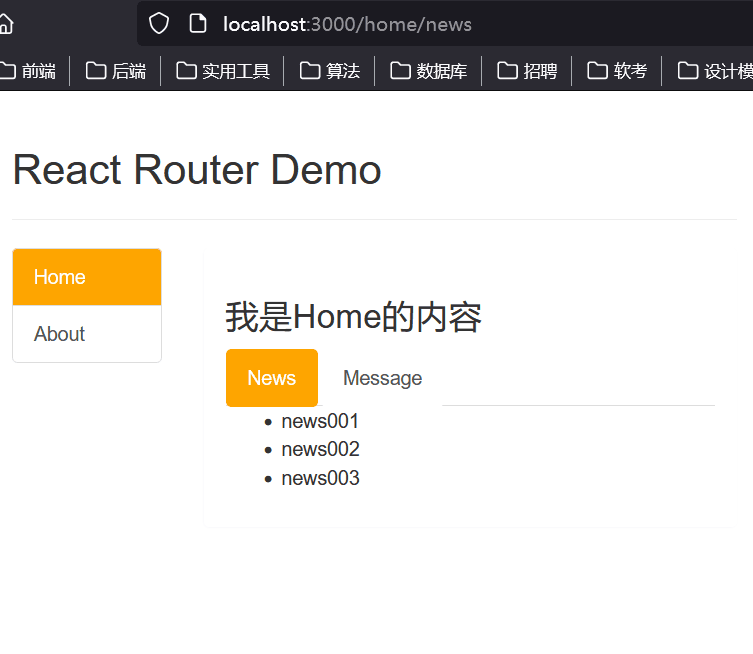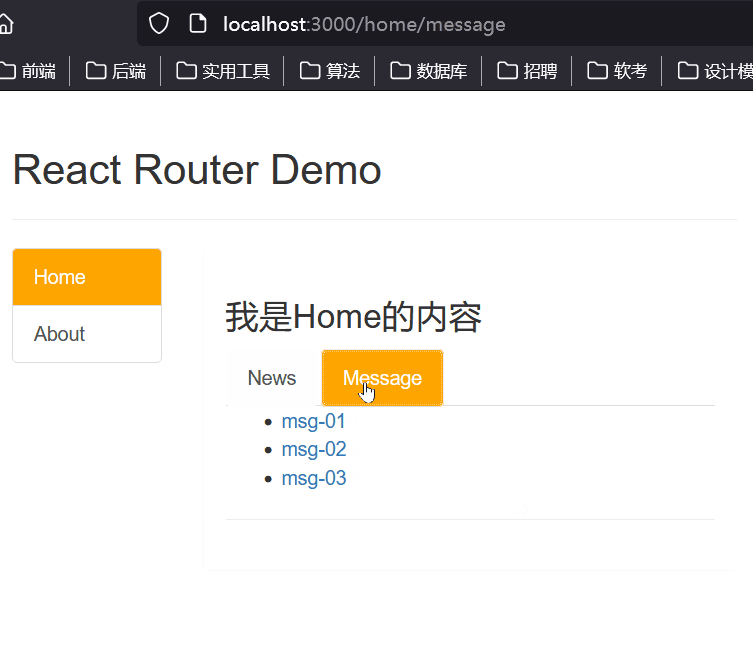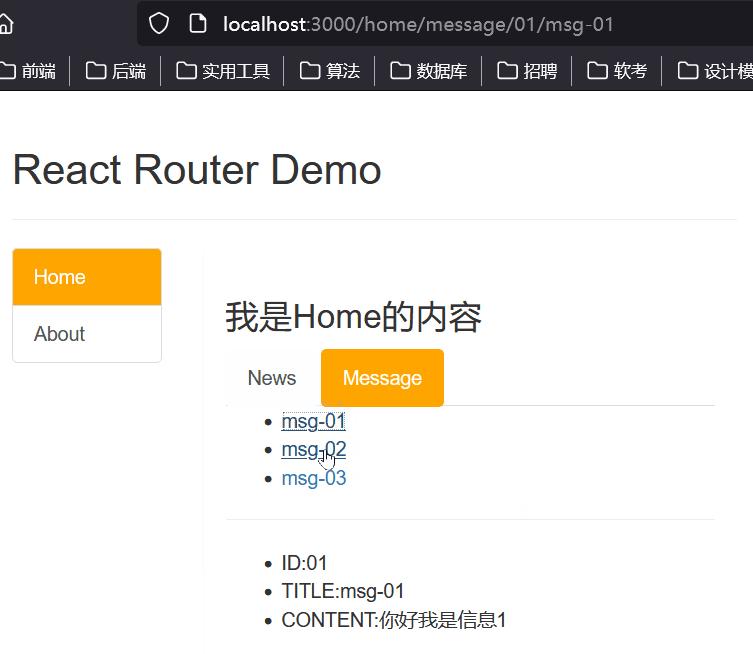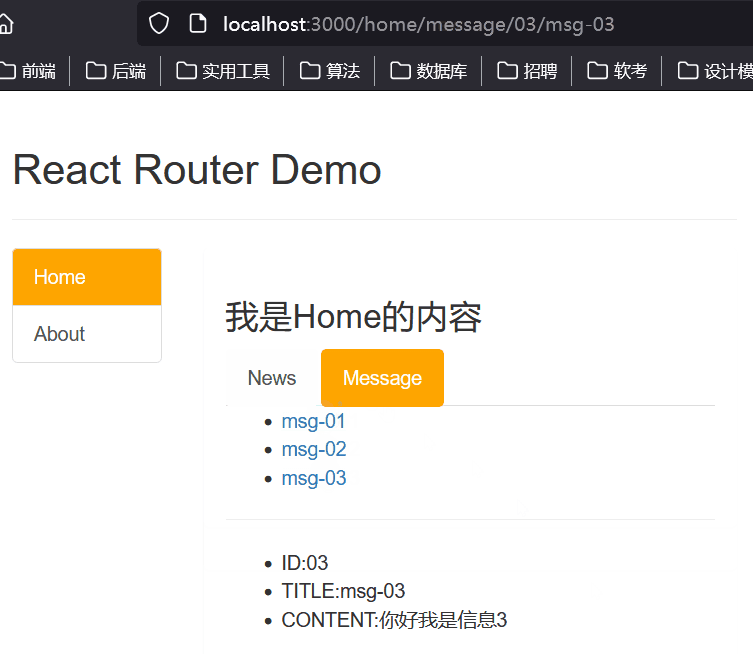
第三十二章 React路由组件的简单使用
1、NavLink的使用 一个特殊版本的 Link,当它与当前 URL 匹配时,为其渲染元素添加样式属性 <NavLink className"list-group-item" to"/home">Home</NavLink> <NavLink className"list-group-item" to&quo…...

“裸奔”时代下,我们该如何保护网络隐私?
当我们在互联网上进行各种活动时,我们的个人信息和数据可能会被攻击者窃取或盗用。为了保护我们的隐私和数据安全,以下是一些实用的技巧和工具,可以帮助您应对网络攻击、数据泄露和隐私侵犯的问题: 使用强密码:使用独特…...

c#笔记-方法
方法 方法定义 方法可以将一组复杂的代码进行打包。 声明方法的语法是返回类型 方法名 括号 方法体。 void Hello1() {for (int i 0; i < 10; i){Console.WriteLine("Hello");} }调用方法 方法的主要特征就是他的括号。 调用方法的语法是方法名括号。 He…...
)
054、牛客网算法面试必刷TOP101--堆/栈/队列(230509)
文章目录 前言堆/栈/队列1、BM42 用两个栈实现队列2、BM43 包含min函数的栈3、BM44 有效括号序列4、BM45 滑动窗口的最大值5、BM46 最小的K个数6、BM47 寻找第K大7、BM48 数据流中的中位数8、BM49 表达式求值 其它1、se基础 前言 提示:这里可以添加本文要记录的大概…...
怎么让chatGTP写论文-chatGTP写论文工具
chatGTP如何写论文 ChatGPT是一个使用深度学习技术训练的自然语言处理模型,可以用于生成自然语言文本,例如对话、摘要、文章等。作为一个人工智能技术,ChatGPT可以帮助你处理一些文字内容,但并不能代替人类的创造性思考和判断。以…...

springboot 断点上传、续传、秒传实现
文章目录 前言一、实现思路二、数据库表对象二、业务入参对象三、本地上传实现三、minio上传实现总结 前言 springboot 断点上传、续传、秒传实现。 保存方式提供本地上传(单机)和minio上传(可集群) 本文主要是后端实现方案&…...
2023河南省赛vp题解
目录 A题: B题 C题 D题 E题 F题 G题 H题 I题 J题 K题 L题 A题: 1.思路:考虑暴力枚举和双hash,可以在O(n)做完。 2.代码实现: #include<bits/stdc.h> #define sz(x) (int) x.size() #define rep(i,z,…...

港科夜闻|香港科大与香港资管通有限公司签署校企合作备忘录,成立校企合作基金促科研成果落地...
关注并星标 每周阅读港科夜闻 建立新视野 开启新思维 1、香港科大与香港资管通有限公司签署校企合作备忘录,成立校企合作基金促科研成果落地。“港科资管通领航基金”28日在香港成立,将致力于推动高校科研成果转化,助力香港国际创科中心建设。…...

Neo4j 笔记
启动命令 neo4j console Cypher句法由四个不同的部分组成, 每一部分都有一个特殊的规则: start——查找图形中的起始节点。 match——匹配图形模式, 可以定位感兴趣数据的子图形。 where——基于某些标准过滤数据。 return——返回感兴趣的…...
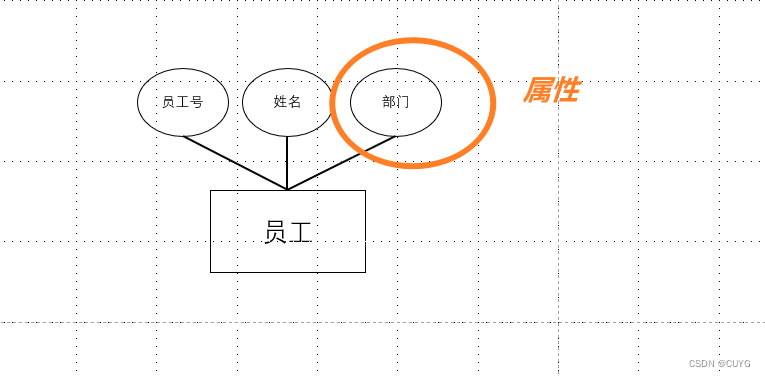
数据库基础应用——概念模型
1、实体(Entity) 客观存在并可相互区别的事物称为实体。实体可以是人、物、对象、概念、事物本身、事物之间的联系。(例如一名员工、一个部门、一辆汽车等等。) 2、属性(Attributre) 实体所具有的每个特性称为属性。(例如:员工由员…...

Visual Studio 项目属性页开发完全教程:从基础到高级
Visual Studio 项目属性页开发完全教程:从基础到高级 【免费下载链接】project-system The .NET Project System for Visual Studio 项目地址: https://gitcode.com/gh_mirrors/pr/project-system Visual Studio 项目属性页是开发者管理项目配置的核心界面&a…...
)
别再手动点菜单了!用这招让Cadence Virtuoso Schematic效率翻倍(附Net高亮快捷键配置)
电路设计效率革命:Cadence Virtuoso Schematic高阶快捷键配置指南 在集成电路设计的浩瀚宇宙中,Cadence Virtuoso如同设计师手中的光刻机,每一次精准操作都直接影响最终芯片的性能与可靠性。然而,当面对数百个晶体管组成的复杂模…...

硬件答辩问题总结
一、电源纹波是什么,为什么LDO的小,DCDC的大1.电源纹波电源纹波 是指直流电源输出电压上叠加的 交流波动成分,表现为电压在理想直流值附近上下波动。2.LDO 纹波小原理LDO 内部是一个 调整管(可变电阻) 串联在输入和输出…...

LangGraph状态机工程:构建复杂AI工作流的完整指南
传统RAG(检索增强生成)在处理简单的"单跳"问题时表现良好——“文章里提到了什么” “这个概念是什么意思”——但当问题涉及多个实体之间的关系、需要跨多个文档推理时,传统RAG就显得力不从心。GraphRAG(Graph-based R…...

uWSGI目录穿越漏洞CVE-2018-7490深度利用与防御实战
1. 这不是“读文件”那么简单:uWSGI目录穿越在真实攻防链中的定位与误判代价你刚在Vulfocus靶场里跑通了CVE-2018-7490的PoC,用curl "http://target:8080/?p../../../../etc/passwd"成功读出了root:x:0:0:root:/root:/bin/bash,截…...

Log4Shell漏洞深度解析:Spring Boot日志注入原理与四层修复方案
1. 这个漏洞不是“远程执行代码”那么简单——它是一次对Java生态信任链的系统性击穿Log4j CVE-2021-44228,业内常简称为“Log4Shell”,2021年12月爆发时,我正在给一家金融客户的Spring Boot微服务集群做灰度发布前的安全加固。凌晨三点收到告…...

第2章 谁在危险中——被AI替代的五类程序员
第2章 谁在危险中——被AI替代的五类程序员 核心问题:哪些程序员最容易被AI替代?背后的原因是什么? 2.1 问题定义:一场正在发生的结构性塌陷 2.1.1 数据不会说谎 2026年1月12日,Ravio发布了一份让整个科技圈沉默的报告:过去一年,初级开发者岗位招聘量暴跌73%。 不是…...

机器学习赋能矩方法:破解稀薄气体强非平衡流动模拟难题
1. 项目概述:当矩方法遇见机器学习在计算流体力学领域,模拟稀薄气体动力学和强非平衡流动,一直是个让工程师和科学家们头疼的“硬骨头”。想象一下,你正在设计一架高超音速飞行器,当它以数倍音速在大气层边缘飞行时&am…...

Hitboxer:终极SOCD按键重映射解决方案,彻底解决游戏按键冲突问题
Hitboxer:终极SOCD按键重映射解决方案,彻底解决游戏按键冲突问题 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 在激烈的游戏对战中,你是否曾因同时按下左右方向键而导致角色…...

音乐解锁工具终极指南:3分钟掌握加密音乐解密技巧
音乐解锁工具终极指南:3分钟掌握加密音乐解密技巧 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://g…...