论文导读 | 大语言模型上的精调策略
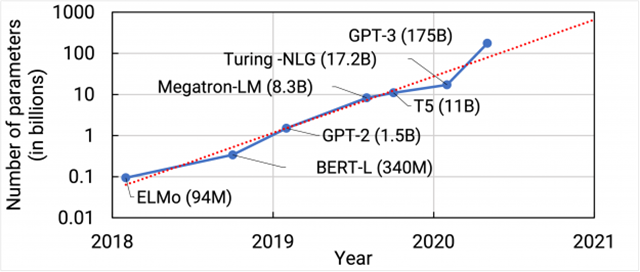
随着预训练语言模型规模的快速增长,在下游任务上精调模型的成本也随之快速增加。这种成本主要体现在两方面上:一,计算开销。以大语言模型作为基座,精调的显存占用和时间成本都成倍增加。随着模型规模扩大到10B以上,几乎不可能在消费级显卡或者单卡上进行训练;二,存储开销。如果对于每一个下游任务,我们都需要精调全量模型并存储相应的参数,那么所需要的存储开销也是相当惊人的。以GPT-3 175B为例,为仅仅一个任务存储精调模型的全量参数就需要350/700GB(取决于精度)。因此,如何在兼顾精调的表现的同时提升效率,是一个重要的研究问题。
本篇文章将介绍差值精调策略(delta tuning)。这类方法的核心思路是,通过只训练少量参数,并冻结其他模型参数,逼近甚至达到全量参数精调的效果。具体而言,现有的主流方法可以总结为三类:添加参数方法(addition-based),限制参数方法(Specification-based)和重参数化方法(reparameterization-based)。
一、添加参数方法
1.1 Adapter方法

Houlsby et al.[1]最早提出了adapter方法,即在语言模型的每个transformer层中添加少量可学习的参数,并冻结其余参数,如图所示。为了减少参数量,作者采用了两层FFN作为adapter的网络结构进行降维-升维。为了使得初始化结果等价于原始网络,作者采用了残差连接并零初始化adapter结构。实验表明,在多项任务上,仅使用0.5%-8%的训练参数就能逼近全量参数精调的效果,并且训练速度能提升约60%。需要注意的是,由于引入了串行的额外模块,模型的推理速度会略微下降4%-6%。
1.2 连续化提示学习
1.2.1 Prompt tuning[2]

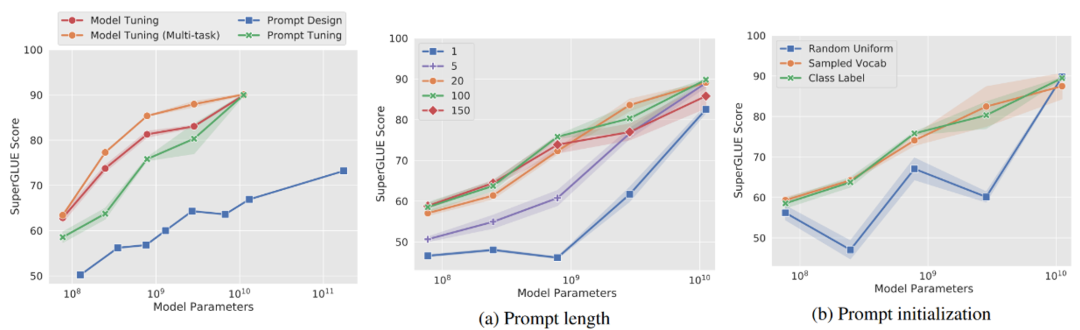
提示工程是语言模型随着规模增大而产生的新范式。针对不同的任务,提示工程会在输入文本中添加特定的token,并预测[MASK]位置的单词,然后将预测结果映射回任务的标签空间,如图所示。随着近几年的探索,提示工程经历了手工设计-离散空间搜索-连续空间搜索的几个阶段。为了使得prompt模板可以通过梯度下降学习,在连续空间搜索这一方式中,prompt直接作为固定长度的embedding添加到了输入层,并且这部分参数是可学习的。
由于只有prompt embedding的参数需要调整,因此prompt tuning的可学习参数也是相当少的。但相对应的,学习这部分参数的难度会较大,即训练的收敛速度会比较慢,而且它的效果对于prompt的长度、初始化方式等非常敏感。此外,在模型的规模比较小时,prompt tuning的表现和全量精调以及其余方法的差距都比较大。随着模型规模的增长,这个差距才会逐渐缩小。
1.2.2 Prefix tuning[3]
Prompt tuning只在embedding层加入了可学习的参数,但transformer在计算的过程中,每层都会计算self-attention,因此每层隐状态的输入长度都是P+N的(P为prompt长度,N为原始文本长度)。Prefix tuning的做法更进一步,将每层模板对应位置都替换成了可学习参数(而非通过attention从上一层聚合)。为了提升训练的稳定性,作者同时使用了重参数化技巧,降低embedding的维度,并通过MLP将其升维到隐状态的语义空间中。
作者在文本生成任务上进行了实验。令人惊讶的是,在低资源少样本的训练条件下,prefix tuning的效果能超过全量精调。这有可能是出于全量精调的过拟合问题影响了其泛化性能。
二、限制参数方法
为了缩减训练的参数量,一个自然的想法是,我们直接冻结部分参数不变,然后在剩余参数上进行梯度下降学习。具体到选取哪些参数,有些研究者提出了可学习的方法,但出于简化考虑,我们只介绍几种经验性选取的方式。
一个出于直觉的考虑是,越靠近输入的层的语义空间编码的语义更通用,越靠近输出的层的语义空间编码的语义更贴近具体的任务。因此,一个直观的做法是,只精调最后一层(或最后几层)的参数,维持其余参数不变。除此之外,Zaken et al.[4]发现,只精调网络中所有的误差项(bias),维持矩阵乘法权重不变,也能在下游任务上取得95%的表现。
三、重参数化方法
语言模型的神奇之处在于,只需要少量(数百-数千条)训练样本,我们就能训练海量(数亿-百亿)的参数,并且能取得良好的泛化效果。关于这个现象,Aghajanyan et al.[5]提出的解释是,PLM往往具有很低的本征维度。
什么是本征维度呢?考虑精调的训练过程,其实相当于在预训练初始化之上学习领域对应的参数
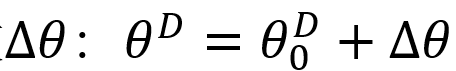
,其中D为参数的维度。那么,假设能找到一个维数很低的子空间,并通过投影等映射方式将其升维到原始空间,
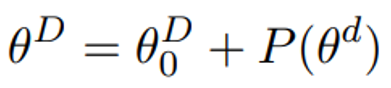
同时能达到和在原始空间中精调类似的效果,那么我们就称这个子空间的最大维度为PLM的本征维度。为了量化衡量“达到类似的效果”,作者定义其为在具体的任务上达到原始的90%的表现分数。因此,这样定义的本征维度是特定于任务的。
由于使用简单的密集投影的计算复杂度和空间复杂度都是O(Dd)的,考虑到D的范围在100M-100B之间,因此这样子的计算代价是不可接受的。作为替代,作者使用了Fastfood[6]变换作为替代:

最后,作者还考虑到为每层分别添加了超参数并学习不同的映射:
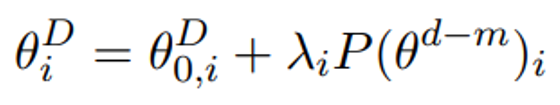
在实验部分,除了发现PLM的本征维度都很低以外,作者还发现,规模越大的模型,本征维度反而会更小,并且,在较难的任务上本征维度会更大。
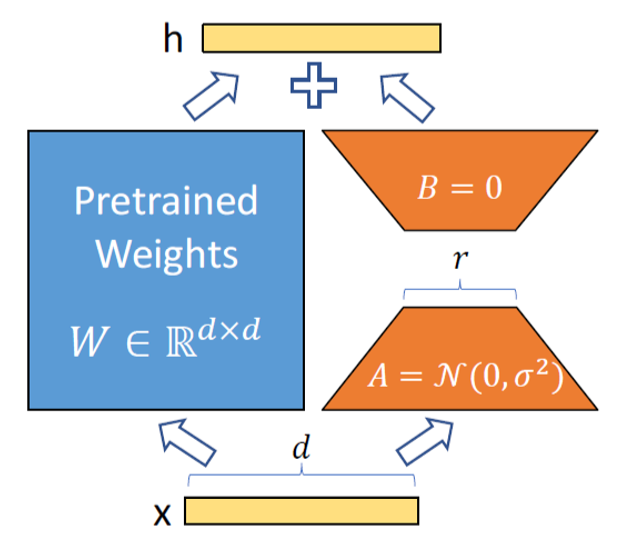
在本征维度假设之上,Hu et al.[6]提出了模型参数的低秩近似方法LoRA。即,对于所有参数矩阵的改变量,都通过ΔW=BA进行低秩分解。其中,为了保证零初始化,矩阵B采用零初始化,矩阵A则从正态分布中采样。相比于adapter方法,LoRA可以保证训练参数的收敛等价于原始网络(adapter等价于MLP),同时不会在推理阶段引起额外的延时。此外,LoRA能够极大地节省显存和存储占用,并提升训练的速度(约25%)。以GPT-3 175B为例,LoRA的精调显存占用可以从1.2TB减小为350GB,同时存储占用从350GB减为35MB。
参考文献
[1] Houlsby, Neil, et al. "Parameter-efficient transfer learning for NLP." International Conference on Machine Learning. PMLR, 2019.
[2] Lester, Brian, Rami Al-Rfou, and Noah Constant. "The Power of Scale for Parameter-Efficient Prompt Tuning." Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021.
[3] Li, Xiang Lisa, and Percy Liang. "Prefix-Tuning: Optimizing Continuous Prompts for Generation." Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021.
[4] Zaken, Elad Ben, Yoav Goldberg, and Shauli Ravfogel. "BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models." Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2022.
[5] Aghajanyan, Armen, Sonal Gupta, and Luke Zettlemoyer. "Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning." Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021.
[6] Hu, Edward J., et al. "LoRA: Low-Rank Adaptation of Large Language Models." International Conference on Learning Representations. 2022.
[7] Ding, Ning, et al. "Delta tuning: A comprehensive study of parameter efficient methods for pre-trained language models." arXiv preprint arXiv:2203.06904 (2022).


相关文章:
论文导读 | 大语言模型上的精调策略
随着预训练语言模型规模的快速增长,在下游任务上精调模型的成本也随之快速增加。这种成本主要体现在两方面上:一,计算开销。以大语言模型作为基座,精调的显存占用和时间成本都成倍增加。随着模型规模扩大到10B以上,几乎…...

进阶自动化测试,这3点你一定要知道的...
自动化测试指软件测试的自动化,在预设状态下运行应用程序或系统,预设条件包括正常和异常,最后评估运行结果。将人为驱动的测试行为转化为机器执行的过程。 自动化测试框架一般可以分为两个层次,上层是管理整个自动化测试的开发&a…...

网络编程套接字API
一. linux平台 1.创建套接字 成功返回文件描述符,失败返回-1 int socket (int __domain, int __type, int __protocol) ;2.套接字绑定IP地址和端口号 成功返回0,失败返回-1 int bind (int __fd, __CONST_SOCKADDR_ARG __addr, socklen_t __len);3.开启…...

数字藏品的价值和意义
2022年以来,数字藏品概念在国内火热起来。从年初的《关于防范 NFT相关金融风险的倡议》到8月份央行数字货币 DCEP的正式面世,从中国香港首个“NFT”艺术品在香港拍卖市场成交到国内多家互联网大厂推出数字藏品平台,越来越多的企业开始试水数字…...
)
Unity物理系统脚本编程(上)
一、获取刚体组件Rigidbody 当一个物体挂载了刚体时,即可在脚本中获取该物体的刚体组件,代码如下 Rigidbody rigid; void Start() { rigidGetComponent<Rigidbody>(); } 一般将刚体变量命名为rigid并定义为一个字段,方便复用. 二、施…...
Java基础(十七)File类与IO流
1. java.io.File类的使用 1.1 概述 File类及本章下的各种流,都定义在java.io包下。一个File对象代表硬盘或网络中可能存在的一个文件或者文件目录(俗称文件夹),与平台无关。(体会万事万物皆对象)File 能新…...

跑步课程导入能力,助力科学训练
HUAWEI Health Kit为开发者提供用户自定义的跑步课程导入接口,便于用户在华为运动健康App和华为智能穿戴设备上查看来自生态应用的训练课表,开启科学、适度的运动训练。 跑步课程导入能力支持生态应用在获取用户的华为帐号授权后,将跑步课程…...

MySQL---8、创建和管理表
1、基础知识 1.1 一条数据存储的过程 创建数据库-->确认字段-->创建数据表-->插入数据1.2 标识符的命名规则 1、数据库名、表名不得超过30个字符,变量名限制为29个 2、必须只能包含A-Z、a-z、0-9,、_共63个字符 3、数据库名、表名、字段名等对象名中间不…...

图像分类简单介绍
文章目录 图像分类简单介绍什么是图像分类图像分类的背景和意义传统的图像分类方法基于深度学习的图像分类方法总结 图像分类简单介绍 图像分类是计算机视觉领域的一个基本任务,其目标是将输入的图像分配给某个预定义的类别(即标签)。在本教…...

很多博主用Markdown格式文章?直呼真不错!
概述 Markdown 是一种轻量级标记语言,它可以使我们专注于写作内容,而不用过多关注排版,很多博主、作家等都用它来撰写文章~ 本文将给各位小伙伴介绍 Markdown 语法的使用,本篇文章索奇就是用的纯 markdown 语法来写的~ 标题 一级…...

【2023/05/07】汇编语言
Hello!大家好,我是霜淮子,2023倒计时第2天。 Share Stray birds of summer come to my window to sing and fly away. And yellow leaves of autumn,which have no songs,flutter and full there with a sigh. 译文: 夏天的鸟&…...

AI 生成第3篇测试文章:怎么编写测试计划?
背景 在软件开发过程中,测试是十分重要的环节,测试计划是测试的基础和重要的组成部分。一个完善的测试计划能够指导测试工作,明确测试范围和要求,提高测试效率,保证软件质量和可靠性。本文将从测试计划的定义、编写步…...

怎么洗稿容易过稿-在线洗稿软件
自媒体洗稿软件 即使您是一位优秀的自媒体写作人员,也难免遇到让人头疼的撰写问题,例如无法处理大量原始文本、需要手动删除冗余信息、缺少时间针对每篇文章进行深入修改等问题。但是,现在有了我们的一款自媒体洗稿软件,您再也不需…...

图书馆客流人数统计分析系统方案
智慧客流人数统计分析系统可以帮助图书馆管理者更好地管理人群流量。系统能够自动统计区域内的人流量高峰期,并通过数据分析提供更加合理的管控,从而提区域内人群流动性,避免拥堵的情况。 AI客流视觉监控 客流量管控分析系统意义 讯鹏客流量管…...

linux命令之crontab详解
crontab 提交和管理用户的需要周期性执行的任务 更多linux命令详解:linux命令在线工具 补充说明 crontab命令 被用来提交和管理用户的需要周期性执行的任务,与windows下的计划任务类似,当安装完成操作系统后,默认会安装此服务工…...
浅谈一下接口工具(jmeter、postman、swagger等)
一、接口都有哪些类型? 接口一般分为两种:1.程序内部的接口 2.系统对外的接口 系统对外的接口:比如你要从别的网站或服务器上获取资源或信息,别人肯定不会把 数据库共享给你,他只能给你提供一个他们写好的方法来获取…...
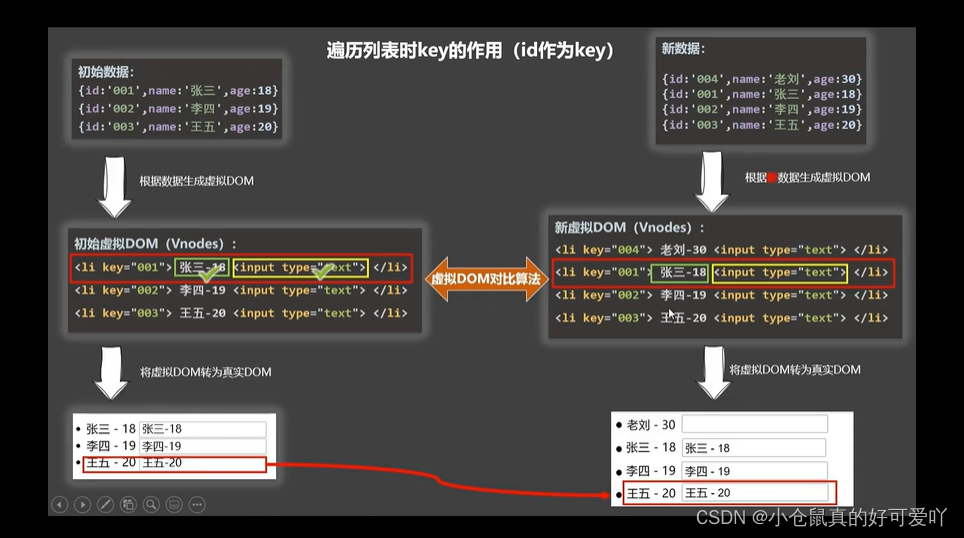
面试题:react、 vue中的key有什么作用? (key的内部原理)
面试题:react、 vue中的key有什么作用? (key的内部原理) 1.虚拟DOM中key的作用: key是虚拟DOM对象的标识,当状态中的数据发生变化时,Vue会根据【新数据】生成【新的虚拟DON】,随后Vue进行【新虚拟DOM】与【旧虚拟DOM】的差异比较࿰…...
C++之继承
目录 一、继承的概念及定义 1.1继承的概念 1.2继承的定义 1.2.1继承的格式 1.2.2继承基类成员访问方式的变化 二、基类和派生类对象赋值转换 三、继承中的作用域 4.派生类的默认成员函数 五、继承与友元 六、继承与静态成员 七、菱形继承及菱形虚拟继承 7.1菱形继承的问…...

轻松掌握!Pandas的数据添加技巧,3秒学会更高效的方法
在Pandas中,如果你想高效地向一个DataFrame添加一行数据,千万不要使用.append()方法!因为这种方法需要创建新的对象然后再赋值,效率较低,尤其是DataFrame较大时。 本文将介绍3种Pandas添加一行数据更高效的方法&#x…...

层次结构工程命名建议
对于这种多层次的结构,我们可以采用一些通用的命名方式来描述不同的层次。以下是一种可能的方式,仅供参考: 第一层:模块/模块组件 可以采用名词或形容词名词的方式来命名,例如: Action: 动作Behavior: 行…...

强化学习在并行机构人形机器人控制中的应用
1. 项目概述在机器人控制领域,强化学习(RL)正逐渐成为解决复杂动力学系统问题的有力工具。然而,当面对具有并行驱动机构的人形机器人时,传统RL训练方法往往面临一个关键挑战:大多数仿真环境无法准确模拟闭环运动链(Closed Kinemat…...

如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优
如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcode.co…...

别再盲跑了!手把手教你用Arduino Zero在IDE 2.0里设置断点单步调试
告别盲跑时代:Arduino Zero与IDE 2.0的源码级调试实战指南 当你的Arduino项目逻辑越来越复杂,仅靠串口打印调试就像在迷宫里摸黑前行——直到遇见Arduino Zero与IDE 2.0的调试组合。本文将揭示如何用这套工具实现 源码级精准调试 ,即使你手…...

PvZ Toolkit终极指南:三步掌握植物大战僵尸最强修改器
PvZ Toolkit终极指南:三步掌握植物大战僵尸最强修改器 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit PvZ Toolkit是一款专为植物大战僵尸PC版设计的综合修改器工具,能够让你…...

对比按量计费与Token Plan套餐的实际成本差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按量计费与Token Plan套餐的实际成本差异 在构建和运营基于大模型的应用时,成本控制是一个核心的工程考量。Taotok…...

UE5 Cesium项目里,如何把默认的飞行Pawn换成建筑漫游Pawn?保姆级迁移教程
UE5 Cesium项目建筑漫游Pawn迁移实战:从飞行模式到精细化浏览的完整指南当你在UE5中结合Cesium插件构建数字孪生场景时,DynamicPawn提供的全球飞行体验令人印象深刻。但当视角聚焦到单体建筑或室内空间时,那种仿佛操控无人机般的操作方式就显…...

收藏干货|2026 版双非零基础入局大模型开发,RAG 与 Agent 就业上岸全攻略
日常总能收到不少初学伙伴的私信,大家普遍都有同一个疑惑:二本及普通院校学历,零基础入门 RAG、Agent 大模型应用开发,究竟能不能顺利入职?行业后续发展前景又如何? 本篇 2026 年全新内容,不空谈…...

实测对比,使用Taotoken聚合接口后Agent任务延迟与稳定性观感
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 实测记录:使用 Taotoken 聚合接口后 Agent 任务延迟与稳定性观感 效果展示类,记录将原有基于单一 API 的 A…...

AI算法工程师如何进行数据预处理?这5个步骤让你的数据更优质
在AI模型开发与测试的全流程中,数据质量直接决定了最终模型的效果上限——哪怕是最先进的大语言模型,用劣质数据训练出来也只能输出劣质结果。对于软件测试从业者来说,不管是参与AI模型的功能测试、性能测试,还是负责测试数据集的…...

DSP、FPGA、STM32大对决:谁才是嵌入式开发的“天选之子”?
在嵌入式开发的广阔天地里,DSP、FPGA 和 STM32(作为通用 MCU 的典型代表)可以说是三款绕不开的核心处理器。很多初学者甚至有一定经验的工程师在选择时都会陷入纠结:我的项目到底该选哪一个?为了帮你彻底理清思路&…...