[论文笔记]SimMIM:a Simple Framework for Masked Image Modeling

文章地址:https://arxiv.org/abs/2111.09886
代码地址:https://github.com/microsoft/SimMIM
文章目录
- 摘要
- 文章思路
- 创新点
- 文章框架
- Masking strategy
- Prediction head
- Prediction target
- Evaluation protocols
- 性能实验
- 实验设置
- Mask 策略
- 预测头
- 目标分辨率
- 预测目标
- 比较实验
- 与基于 ViT 的不同模型比较
- 与不同大小的 Swin Transformer 比较
- 可视化结果
- 学习能力
- 预测与重建对比
- mask patch size 大小
- 结论
摘要
本文介绍了SimMIM,这是一个用于掩模图像建模的简单框架。我们简化了最近提出的相关方法,而不需要特殊的设计,例如通过离散VAE或聚类进行分块掩蔽和标记化。为了研究是什么使掩蔽图像建模任务学习良好的表示,我们系统地研究了我们框架中的主要组件,并发现每个组件的简单设计都揭示了非常强的表示学习性能:1)对具有适度大的掩蔽补丁大小(例如,32)的输入图像进行随机掩蔽,可以生成强大的文本前任务;2) 通过直接回归预测原始像素的RGB值并不比具有复杂设计的补丁分类方法差;3) 预测头可以像线性层一样轻,性能不会比较重的预测头差。使用ViT-B,我们的方法通过在该数据集上进行预训练,在ImageNet-1K上实现了83.8%的top 1微调精度,超过了以前的最佳方法+0.6%。当应用于具有约6.5亿个参数的更大模型SwinV2H时,仅使用ImageNet-1K数据,它在ImageNet-1 K上就实现了87.1%的top 1精度。我们还利用这种方法来解决大规模模型训练所面临的数据匮乏问题,即3B模型(SwinV2-G)被成功训练,以在四个具有代表性的视觉基准上实现最先进的精度,使用的标记数据比以前的实践(JFT-3B)少40倍。
文章思路
类似于 MAE ,SimMIM 也是基于 mask 建模的一种框架,但是该框架更简单。
整体框架来说,SimMIM 主要步骤为 mask 输入图片,将图像输入 encoder ,再经过一个 predictor head 即可得到输出结果,只将 encoder 用于下游任务。
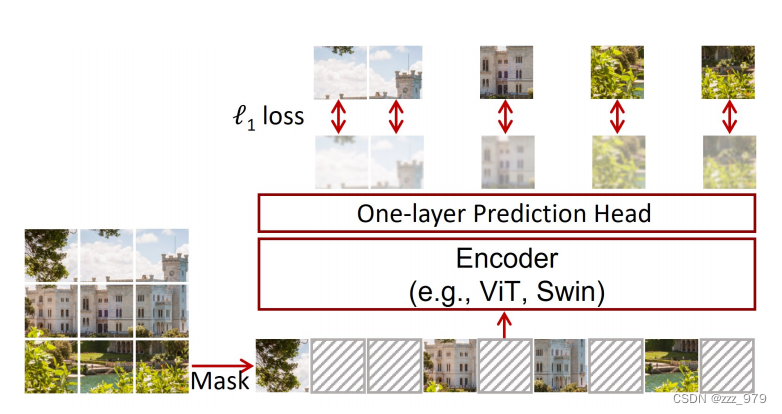
与 MAE 相对比,二者区别在于:
-
MAE 的 mask patch size 大小和切割图像的 patch size 大小一致,SimMIM 的 mask patch size 比切割图像的 patch size 大,为其整数倍;即 SimMIM 中可以屏蔽多个图像的小 patch
例如:下图中蓝色格子表示图像切割的 patch ,橙色阴影表示 mask patch
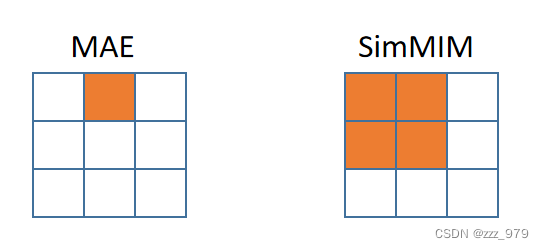
-
MAE 的 encoder 和 decoder 均采用 transformer 结构,SimMIM 只在 encoder 中使用了 transformer ,预测任务由一个简单的 predictor 承担,相当于 decoder 只使用了一层 MLP
创新点
在本文中,我们提出了一个简单的框架,该框架与视觉信号的性质非常一致,并且能够学习与以前更复杂的方法类似甚至更好的表示:输入图像块的随机掩蔽,使用线性层将掩蔽区域的原始像素值与l1损失。这个简单框架背后的关键设计和见解包括:
-
随机掩蔽应用于图像 patch ,这对视觉 Transformer 来说既简单又方便。对于掩蔽像素,较大的 patch 大小或较高的 mask ratio 都会导致找到接近的可见像素的机会较小。
-
使用原始像素回归任务。这个简单的任务并不比通过标记化、聚类或离散化专门定义类的分类方法差。
-
采用了一种非常轻的预测头(例如,线性层),它实现了与较重的预测头类似或略好的传输性能。超轻的预测头的使用在预训中带来了显著的加速,虽然较重的预测头或较高的分辨率通常会产生更大的预测能力,但这种更大的能力并不一定有利于下游微调任务。
文章框架
SimMIM方法通过掩码图像建模来学习表示,该方法对输入图像信号的一部分进行掩码,并预测在掩码区域的原始信号。该框架由4个主要组件组成:
- Masking strategy
给定一张输入图像,选择掩码的区域,对所选区域进行掩码。经过掩码后的图像作为模型输入。 - Encoder architecture.
encoder 提取掩码图像上潜在的特征表示。经过学习的 encoder 可用于不同的下游任务。在本文中,主要考虑两种典型的 vision Transformer 架构: vanilla ViT 和 Swin Transformer。 - Prediction head.
Prediction head 将特征表示转换为掩码区域中的原始信号。相当于一个简单的 decoder 。 - Prediction target.
Prediction target 定义了要预测的原始信号的形式和损失类型。
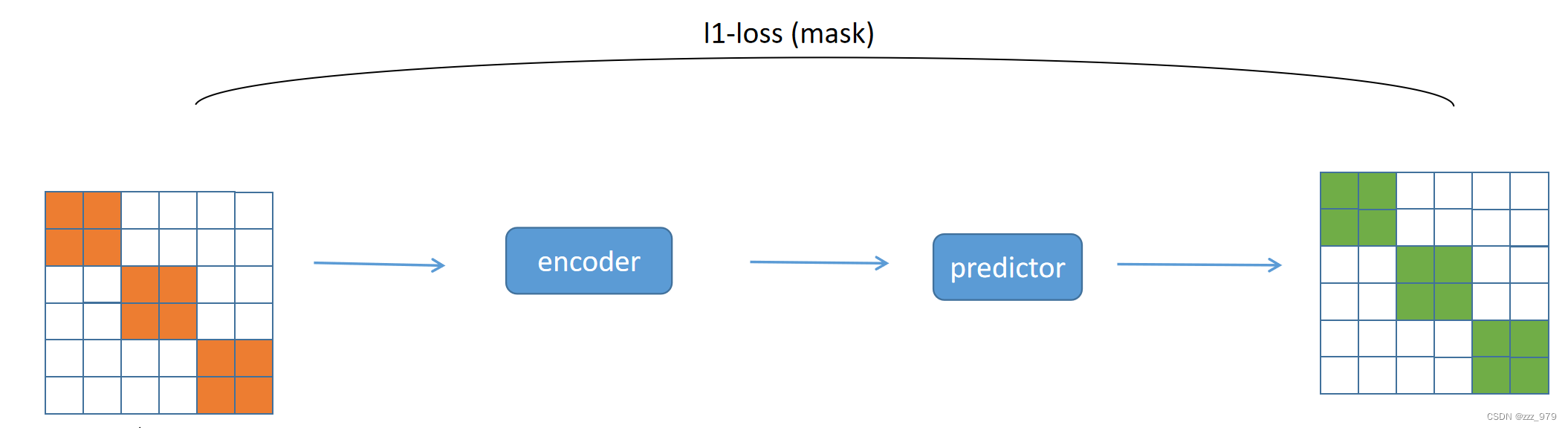
Masking strategy
使用可学习的 mask token 向量来替换每个 masked patch , token 向量维度与 patch embedding 之后的其他可见 patch 的维度相同

作者尝试了不同的掩码方式:
-
Patch对齐的随机掩码策略(右四-右一)。
对于Swin Transformer,考虑相同的不同分辨率的补丁大小(4×4 ~ 32×32),默认采用32×32的补丁大小。
对于ViT,采用32×32作为默认掩码补丁大小。 -
其他掩码策略。
①中心区域掩码策略(左二),让其在图像上随机移动;
②块级掩码策略(左三),利用分别为16x16和32x32的两种掩码块进行掩码
Prediction head
Prediction head 可以是任意形式和容量,只要其输入符合编码器输出并且其输出实现预测目标即可。
一些早期工作遵循AutoEncoder,采用重型预测头(decoder)。在本文中,我们展示了预测头可以做得非常轻,就像线性层一样轻。我们还尝试了较重的头部,如2层MLP、反向Swin-T和反向Swin-B。
Prediction target
- 原始像素值回归
像素值在颜色空间中是连续的。一个直接的选项是通过回归来预测 mask 区域的原始像素。一般来说,视觉架构通常生成下采样分辨率的特征图。
(1)为了预测输入图像的全分辨率下的所有像素值,作者将 feature map 中的每个特征向量映射回原始分辨率,并让该向量负责相应的原始像素的预测。
例如,在 Swin Transformer 编码器生成的32×下采样特征图上,我们应用输出维度为 3072 = 32×32×3 的 1 × 1 卷积(线性)层来表示 32×32 像素的 RGB 值
(2)在掩码像素上使用 L1-loss. 在实验中还考虑了 L2 和 smooth-L1 损失效果与之类似,默认采用 L1 损失。
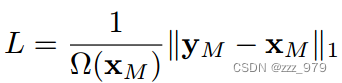
x, y 分别为输入 RGB 值和预测值;M 为 mask 像素集合;Ω(·) 是元素的个数。
- 其他预测目标
①Color clustering: 在iGPT中,利用大量自然图像,通过 k-means 将 RGB 值分成 512 个簇。然后每个像素被分配到最近的簇中心。这种方法需要一个额外的聚类步骤来生成 9 位调色板。
②Vision tokenization:在BEiT中,采用离散 VAE (dVAE) 网络将图像 patch 转换为 dVAE tokens 。token 可用作为分类目标。在这种方法中,需要预训练一个额外的 dVAE 网络。
③Channel-wise bin color discretization:将R、G、B通道分别进行分类,每个通道离散为相同的bins。
Evaluation protocols
主要通过对 ImageNet-1K 图像分类进行微调来评估学习到的表征的质量,这在实践中是一个更有用的场景。
在系统级比较中,我们遵循先前的工作,报告了线性探测的先前主导度量的性能。但是,在应用中并不会考虑这个线性探测指标,因为我们的主要目标是学习可以很好地补充下游任务的表示。
性能实验
实验设置
在预训练中,采用带余弦学习率调度器的AdamW优化器,训练100个epoch。训练超参数为:batch size为2048,基础学习率为 8e-4,权衰减为0.05,β1 = 0.9, β2 = 0.999, 预热10个epoch。
采用 Swin-B 作为默认骨干网络。默认的输入图像大小为192×192,并将窗口大小调整为 6 以适应改变的输入图像大小。ImageNet-1K 图像分类数据集用于预训练和微调。
采用数据增强:随机调整大小裁剪,比例范围为[0.67,1],宽高比范围为[3/ 4,4 /3],然后进行随机翻转和颜色归一化步骤。
SimMIM组件的默认选项是:一个随机 mask 策略,patch 大小为32×32,mask ratio 为0.6;目标图像大小为192×192的线性预测头;掩码像素预测的L1损失。
在微调中,使用 AdamW 优化器、100 epoch 训练和带有10 epoch 预热的余弦学习率调度器。微调超参数为:batch size 大小为2048,基础学习率为5e-3,权衰减为0.05,β1 = 0.9, β2 = 0.999,随机深度比为0.1,分层学习率衰减为0.9。采用数据增强:RandAug、Mixup、Cutmix、label smoothing和random erase。
Mask 策略
不同掩码策略在不同掩码率的微调精度不同,取得的结果差距不大,其中random+masked patch size=32x32+mask ratio=0.5可取得最优的效果83.0%
采用较小的 masked patch size(4x4,8x8,16x16),模型效果随着 mask ratio 的增加而提升;当采用较大的 masked patch size(32x32)时,在较宽的 mask ratio 范围(10%-70%)上表现稳定;而对于更大的 masked patch size(64x64),需要采用较小的 mask ratio 才能得到较好的结果。
masked patch size 和 mask ratio 影响的是MIM任务的难度,两者越大,MIM任务越难,要想取得较好的模型训练效果,MIM任务的难度要适当大一些。
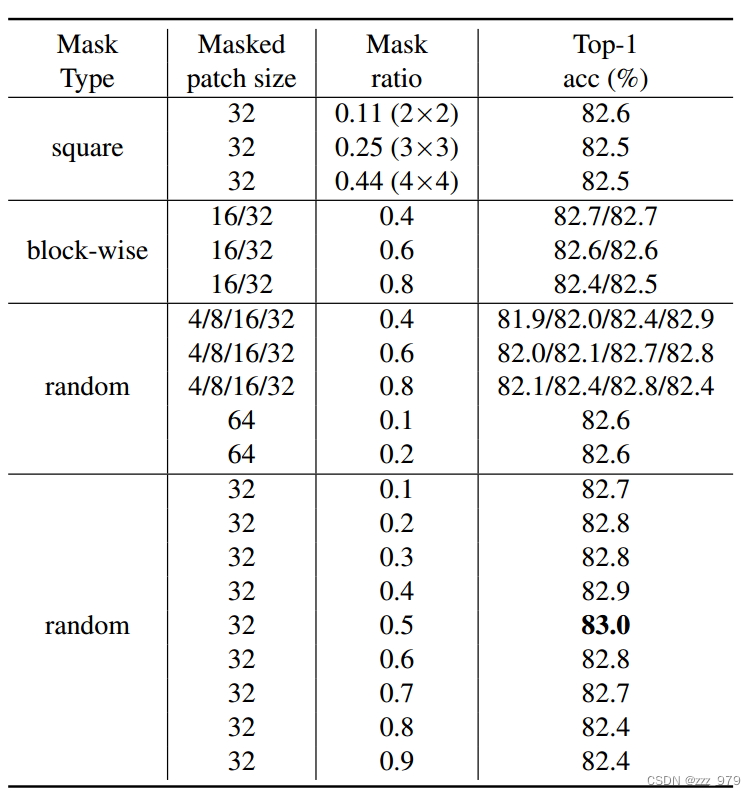
为解释上述现象,作者提出假设:假设一个**大 mask patch size ** 的中心像素距离可见像素足够远。因此,即使使用了较低的 mask ratio ,它也会迫使网络学习相对较长的连接。使用更大的 mask ratio 也会增加预测距离。这也证明了相对较小的patch尺寸有利于微调性能,然而,这些较小 patch 的总体精度不如较大的高,patch过大,观测精度也会下降,这可能是由于预测距离太大。
为验证这一猜想,论文提出了 AvgDist 指标来进一步分析 masked patch size 和 mask ratio 对模型的影响,这里AvgDist指标计算的是所有 masked patch 到最近的 visible patch 的平均欧式距离,它综合了masked patch size和mask ratio对MIM任务的影响。
从下图可以看出,AvgDist随着mask ratio的增加而增加,对于较小的masked patch size,其AvgDist在较大的mask ratio下依然较小,而较大的masked patch size,其AvgDist在较小的mask ratio下就比较大。
从右图可以看出,AvgDist在[10, 20]区间内都可以取得较好的finetune效果,这个可以用来指导选择不同masked patch size和mask ratio组合。
预测头
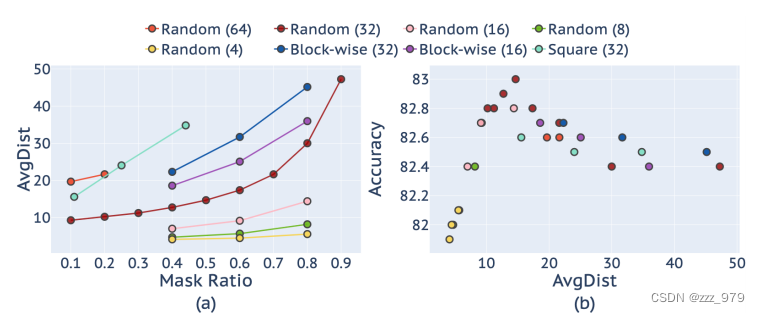
作者尝试了不同的 predictor head ,一层线性层,两层线性层,反向 Swin-T 和 反向 Swin-B ,简单的predictor反而具有更好的效果,需要的参数少,训练代价也小。
同时单层线性层和多层MLP具有相同效果,说明在微调度量下,单个线性层头显示出具有竞争力甚至是最优的传输性能。这表明,如果我们的目标是学习好的特征进行微调,那么在对比学习方法中重要的预测头设计在掩模图像建模可能是不必要的。
分析原因在于:较强的预测能力并不一定意味着较好的下游性能。因为大部分的容量都浪费在了预测头上,而预测头并不会被用于下游的任务。
MAE 也指出 decoder 的设计对 finetune 性能影响较小,但是却会影响 linear probing 效果,如果采用较轻的 decoder,那么 encoder 的后面部分层就要承担一部分像素预测任务,但这个却不是图像分类任务所需要的,所以会带来 linear probing 的下降,所以如果要想得到比较好的linear probing 效果,就需要设计一个适当的 decode r以将预测任务集中在 decoder 上。
目标分辨率
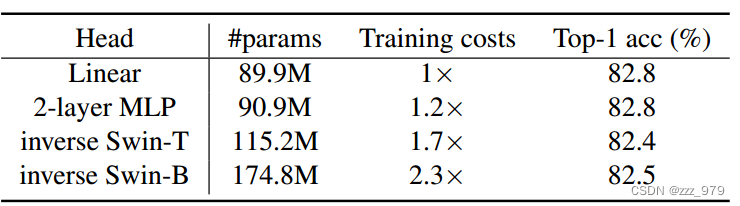
大范围的分辨率(例如,1212-192192)表现同样出色。性能仅在 6*6 的低分辨率下下降,可能是因为此选项丢弃了太多信息。

预测目标
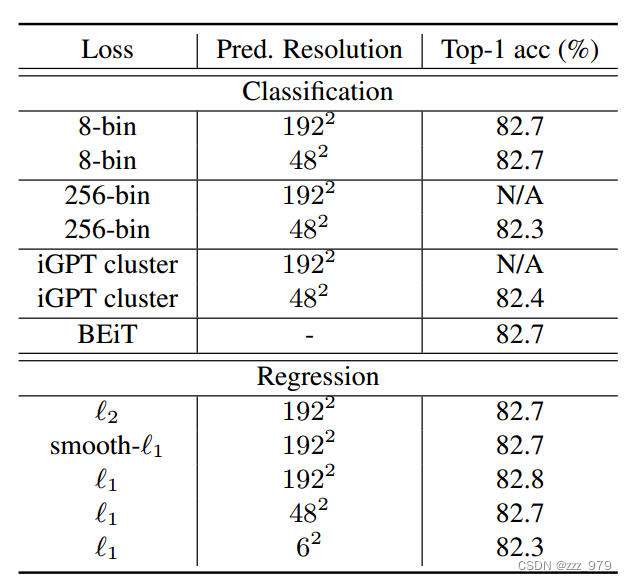
对比其它类型的targets,比如像BEiT那样用dVAE将回归变成分类任务,或者像IGPT那样采用color clustering。从下表的对比结果可以看到直接回归像素值并不比这些更复杂的设计差。
- ℓ1、smooth-ℓ1 和 ℓ2 的三个损失 表现相似;
- 通过 颜色聚类 或 tokenization 仔细定义的类的性能比本文的稍差;
- 通过 channel-wise equal-sized 通道级的等大小的 bin(作为替代选项提出)的 简单颜色离散化方法与 ℓ1 损失具有竞争力,但它需要仔细调整 bin 数量(例如,8-bin)
同时,对于损失计算范围也很重要。预测任务只在 masked 区域计算损失,重建任务是在所有区域计算损失 。下表说明,只在masked 区域计算损失,即完成预测任务的结果较好。这也表明,这两种任务在内部机制上有根本的不同。
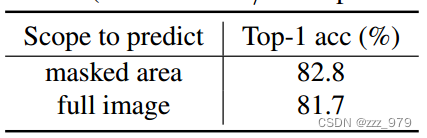
比较实验
与基于 ViT 的不同模型比较
比较SimMIM与使用ViTB进行微调和线性探测的其他方法。SimMIM通过微调达到了83.8%的Top-1准确率,比之前的最佳方法高出了0.6%。SimMIM由于其简单性,保留了最高的训练效率,比DINO、MoCo v3、ViT和BEiT(不包括dVAE训练前的时间)分别高出2.0×、1.8×、~ 4.0×和1.5×。
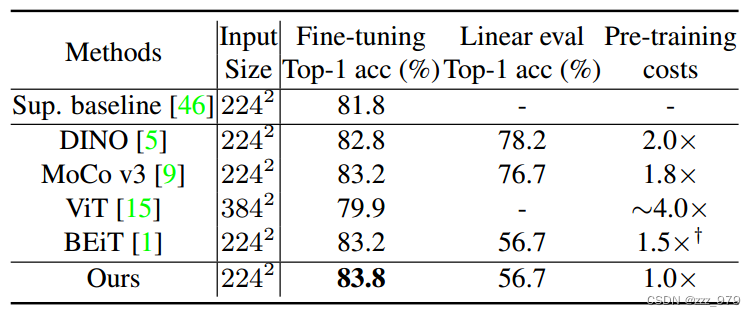
与不同大小的 Swin Transformer 比较
SimMIM在不同模型尺寸下的结果,并与有监督的任务进行比较。在SimMIM预训练下,所有的Swin-B、Swin-L、SwinV2-H的准确率都显著高于有监督的对照组。另外,分辨率为512x512 的SwinV2-H模型在ImageNet-1K上的top-1精度达到了87.1%,是仅使用ImageNet-1K数据的方法中精度最高的方法。
可视化结果
学习能力
下图分别表示:原始图像,随机 mask 及其预测结果,mask 部分主体及其预测结果,mask 所有主体及其预测结果。
结果表明:随机 mask 可以很好恢复 mask 部分,但其他部分会受到 mask 影响,产生阴影;mask 部分主体时,虽然无法完全恢复,但是能学习到主体的存在;mask 全部主体时,无法学习到主体存在,会将该部分背景化。
这也说明 encoder 学习到的是对物体的推理能力,而不是简单的从周围像素进行复制。

预测与重建对比
下图分别表示:原始图像,随机 mask ,预测结果(mask 区域计算 loss)和重构结果(所有区域计算 loss )。
图中看到的结果是重构结果更接近于原始图像,与消融实验中表格统计的Acc表现不一致,分析原可能是模型容量被浪费在恢复未掩码区域上,这可能对微调下游任务用处不大。

mask patch size 大小
下图展示了固定 mask ratio 为 0.6 时具有不同 mask patch size 大小的图像的恢复。可以看出,当 mask patch size 较小时,可以更好地恢复细节,该现象与消融实验中统计的 Acc 也相反。
说明,mask patch size 较小时,学习的表示迁移得更差。分析原因可能是使用较小的 mask patch size ,预测任务可以通过附近的像素或纹理轻松完成,并不利于 encoder 学习能力的训练,从而影响下游任务。

结论
本文提出了一个简单而有效的自监督学习框架 SimMIM,以利用 掩码图像建模 进行表示学习。该框架尽可能简单:
- 具有中等大小的掩码 patch 大小的随机掩码策略;
- 通过直接回归任务预测RGB值的原始像素;
- 预测头可以像线性层一样轻。
相关文章:
[论文笔记]SimMIM:a Simple Framework for Masked Image Modeling
文章地址:https://arxiv.org/abs/2111.09886 代码地址:https://github.com/microsoft/SimMIM 文章目录 摘要文章思路创新点文章框架Masking strategyPrediction headPrediction targetEvaluation protocols 性能实验实验设置Mask 策略预测头目标分辨率预…...
----索引/视图/范式)
mysql从零开始(4)----索引/视图/范式
接上文 mysql从零开始(3) 索引 索引是在数据库表的字段上添加的,是为了提高查询效率存在的一种机制。一张表的一个字段可以添加一个索引,也可以多个字段联合起来添加索引。索引相当于一本书的目录,是为了缩小扫描范围…...
Flutter框架:从入门到实战,构建跨平台移动应用的全流程解析
第一章:Flutter框架介绍 Flutter框架是由Google推出的一款跨平台移动应用开发框架。相比其他跨平台框架,Flutter具有更高的性能和更好的用户体验。本章将介绍Flutter框架的概念、特点以及与其他跨平台框架的比较,以及Flutter开发环境的搭建和…...

Spring AOP+注解方式实现系统日志记录
一、前言 在上篇文章中,我们使用了AOP思想实现日志记录的功能,代码中采用了指定连接点方式(Pointcut(“execution(* com.nowcoder.community.controller..(…))”)),指定后不需要在进行任何操作就可以记录日志了&…...

OpenGL 4.0的Tessellation Shader(细分曲面着色器)
细分曲面着色器(Tessellation Shader)处于顶点着色器阶段的下一个阶段,我们可以看以下链接的OpenGL渲染流水线的图:Rendering Pipeline Overview。它是由ATI在2001年率先设计出来的。 目录 细分曲面着色器细分曲面Patch细分曲面控…...

项目经理如何及时掌控项目进度?
延迟是指超出计划的时间,而无法掌控则意味着管理者对实际情况一无所知。 为了解决这些问题,我们需要建立好的制度和沟通机制。例如使用项目管理软件来跟踪进度、定期开会并避免沟通障碍等。 管理者可以建立相关制度: 1、建立进度记录制度。…...

HTML <applet> 标签
HTML5 中不支持 <applet> 标签在 HTML 4 中用于定义嵌入式小程序(插件)。 实例 一个嵌入的 Java applet: <applet code="Bubbles.class" width="350" height="350"> Java applet that draws animated bubbles. </applet&g…...
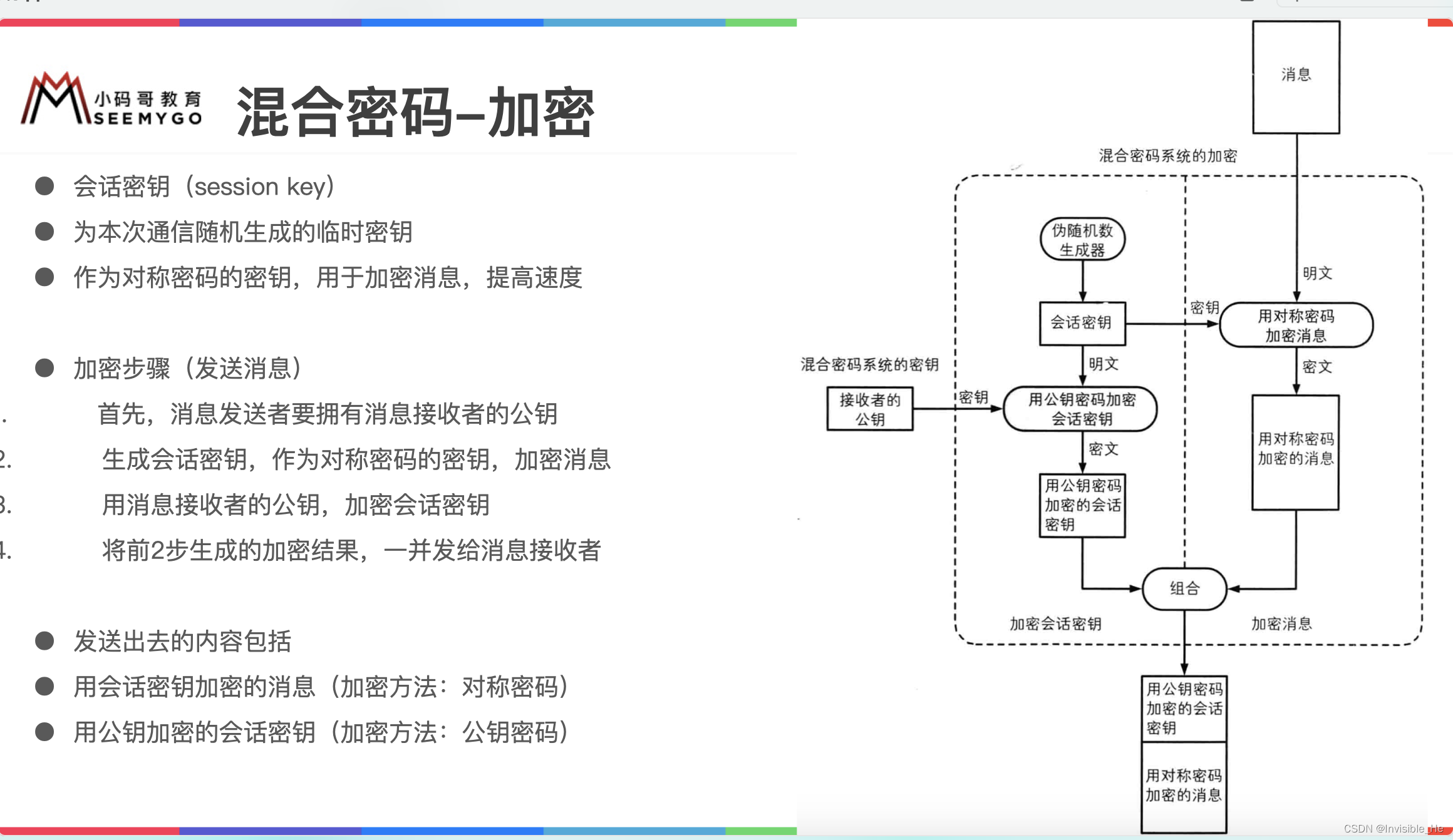
加密与解密
加密与解密 加密方式分类 加密方式主要分为两种 一种是对称加密一种是非对称加密 对称加密 对称和非对称两种方式主要说的是加密和解密两个过程。 如果对数据用一个钥匙进行了加密,那么, 你想成功读取到这个加密了的数据的话,就必须对这…...
京东金融Android瘦身探索与实践
作者:京东科技 冯建华 一、背景 随着业务不断迭代更新,App的大小也在快速增加,2019年~2022年期间一度超过了117M,期间我们也做了部分优化如图1红色部分所示,但在做优化的同时面临着新的增量代码,包体积一直…...
open3d-ml 读取SemanticKITTI Dataset
目录 1. 下载dataset 2. 读取并做可视化 3. 源码阅读 3.1 读取点云数据-bin格式 3.2 读取标注数据-.label文件 3.3 读取配置 3.4 test 3.5 train 1. 下载dataset 以SemanticKITTI为例。下载链接:http://semantic-kitti.org/dataset.html#download 把上面三…...
6.其他函数
1.时间日期类 -- current_date() 返回当前日期 -- date_add(date, n) 返回从date开始n天之后的日期 -- date_sub(date, n) 返回从date开始n天之前的日期 -- datediff(date1, date2) 返回date1-date2的日期差 -- year(date) 返回…...
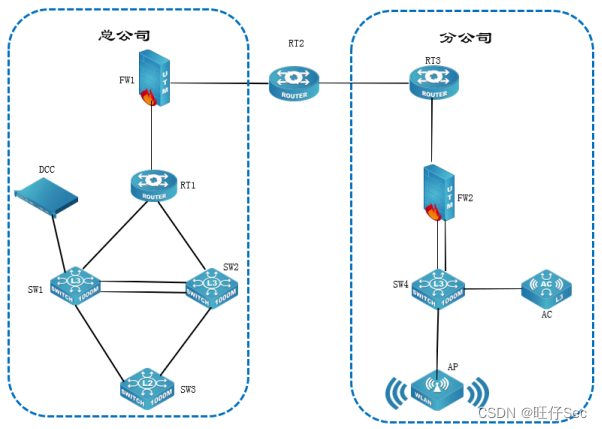
2023年宜昌市中等职业学校技能大赛 “网络搭建与应用”竞赛题-1
2023年宜昌市中等职业学校技能大赛 “网络搭建与应用”竞赛题 一、竞赛内容分布 “网络搭建及应用”竞赛共分二个部分,其中: 第一部分:企业网络搭建部署项目,占总分的比例为50%; 第二部分:企业网络服…...
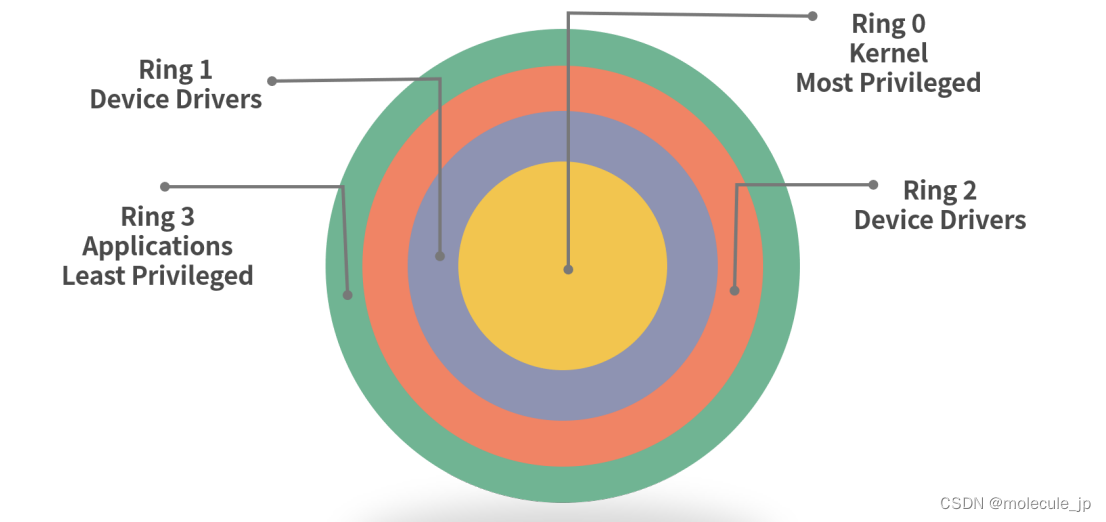
Linux权限划分的原则
考察的不仅是一个具体的指令,还考察对技术层面的认知。 如果对 Linux 权限有较深的认知和理解,那么完全可以通过查资料去完成具体指令的执行。更重要的是,认知清晰的程序员可以把 Linux 权限管理的知识迁移到其他的系统设计中。 权限抽象 一…...

PhotoScan拼接无人机航拍RGB照片
目录 背景 拼接步骤 1.新建并保存项目 2.添加照片 3.对齐照片 4.添加标记(Markers) 5.添加地面控制点 6.建立批处理任务 7.使用批处理文件进行批处理 8.导出DEM 9.导出DOM 背景 本文介绍使用地面控制点(GCPs)拼接…...

【设计模式】责任链模式的介绍及其应用
责任链的介绍 责任链模式是一种对象的行为模式。在责任链模式里,很多对象由每一个对象对其下家的引用而连接起来形成一条链。请求在这个链上传递,直到链上的某一个对象决定处理此请求。发出这个请求的客户端并不知道链上的哪一个对象最终处理这个请求&a…...

一些思考关于行业,关于方向,关于人生路线
一些碎碎念 选择与视角工程与科研平台与信息敢问路在何方 选择与视角 两年前的秋招时几乎速通了出现在学校招聘会上的几乎出现的每一个offer,那也是我人生第一次收获到如此多的肯定与选择,为此我在b站上上传了一期就业解读,作为一个冷门到几…...

fbx sdk的使用介绍
我们平时需要围绕fbx写一些小工具,虽说使用ascii格式的fbx可以直接进行字符串解析,并且网上也有一些基于ascii解析的开源库,但在制作一些通用的工具时,使用fbx sdk进行编写肯定是最好的。 1.下载fbx sdk和cmake 要用cmake生成vi…...

mvvm模式
mvvm是Model-View-ViewModel的缩写,是前端的一种架构模式 M - Model,模型 对应data数据 V - View,视图 对应用户界面,DOM元素 VM - ViewModel,视图模型 对应vue实例对象,是连接model和view的桥梁 …...
Spring/SpringBoot常用注解总结
为什么要写这篇文章? 最近看到网上有一篇关于 SpringBoot 常用注解的文章被转载的比较多,我看了文章内容之后属实觉得质量有点低,并且有点会误导没有太多实际使用经验的人(这些人又占据了大多数)。所以,自…...

2023 年第八届数维杯大学生数学建模挑战赛 B 题 节能列车运行控制优化策略
在城市交通电气化进程快速推进的同时,与之相应的能耗增长和负面效应也 在迅速增加。城市轨道交通中的快速增长的能耗给城轨交通的可持续性发展带来 负担。2018 年,北京、上海、广州地铁负荷占全市总负荷的 1.5%-2.5%,成为了 城市电网的最大单体负荷[1]。…...

CentOS 7下‘Development Tools’和‘开发工具’组有区别吗?实测告诉你答案
CentOS 7下‘Development Tools’与‘开发工具’的隐藏关联:技术细节全解析在Linux系统管理中,yum的软件包组功能一直是个既实用又充满谜团的领域。特别是当系统语言环境与软件包元数据语言不一致时,开发者们常常会遇到一个有趣的现象&#x…...

MBTI性格测试
简介 MBTI(Myers‑Briggs Type Indicator,迈尔斯‑布里格斯类型指标)是基于荣格心理类型理论发展出的性格类型工具,由凯瑟琳库克布里格斯及其女儿伊莎贝尔布里格斯迈尔斯创建。它通过四对偏好维度将个体的认知与行为倾向归纳为 16…...

新能源车轻量化为什么开始盯上高强镁合金?
续航,是悬在每一台纯电动汽车头上的达摩克利斯之剑。多充一度电、多堆一些正极材料,是一条路;但还有另一条路——把车造得更轻。 SAE(美国汽车工程师学会)的测算已经被反复引用:整车每减重100千克ÿ…...

GEO生成引擎优化:当AI成为信息分发的主角,品牌如何抢占对话窗口?
当用户不再"搜索-浏览",而是直接"AI提问-获取答案",传统SEO的逻辑正在被彻底改写。2026年,GEO(Generative Engine Optimization,生成式引擎优化)已经从概念走向规模化落地。本文从技术…...

网络配置工具类详解
CNet 网络配置工具类详解平台:仅支持 Linux,大量使用 ioctl 系统调用一、概述 CNet 是一个 纯静态方法的网络配置工具类,封装了 Linux 下常用的网络操作:功能类别涵盖内容IP 地址读取/设置本机 IP、子网掩码网关读取/添加/删除/设…...

AI IDE 革命:程序员正在被重新定义
很多开发者第一次使用 Cursor 的 CtrlK 或 Composer(高级多文件编辑模式)时,都会有一种强烈的、甚至让人有些脊背发凉的冲击感。 因为: 它已经不再是那个我们熟悉的、只能在原地等待光标落下的: “代码自动补全插件&am…...

uWSGI目录穿越漏洞CVE-2018-7490深度利用与防御实战
1. 这不是“读文件”那么简单:uWSGI目录穿越在真实攻防链中的定位与误判代价你刚在Vulfocus靶场里跑通了CVE-2018-7490的PoC,用curl "http://target:8080/?p../../../../etc/passwd"成功读出了root:x:0:0:root:/root:/bin/bash,截…...

3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行
3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk or KernelSU (root so…...

国内大学生常用的AI写作辅助平台有哪些?
国内高校学生常用的 AI 写作辅助平台,以本土化全流程工具为主,结合通用大模型与专项功能模块,覆盖选题构思、大纲搭建、初稿撰写、语言润色、降重处理、查重检测及格式排版等关键环节,以下是主流平台详解与对比: 一、本…...

人工智能的伦理与安全:这3个问题,软件测试从业者必须重视
随着大语言模型、生成式AI的爆发式落地,人工智能已经从实验室走向千行百业的生产场景,深刻改变着软件开发与交付的逻辑。对于直接把控产品质量关口的软件测试从业者来说,我们的职责早已不再是单纯验证功能可用性、排查性能bug那么简单——AI系…...