第N2周:中文文本分类-Pytorch实现
目录
- 一、前言
- 二、准备工作
- 三、数据预处理
- 1.加载数据
- 2.构建词典
- 3.生成数据批次和迭代器
- 三、模型构建
- 1. 搭建模型
- 2. 初始化模型
- 3. 定义训练与评估函数
- 四、训练模型
- 1. 拆分数据集并运行模型
一、前言
🍨 本文为🔗365天深度学习训练营 中的学习记录博客
🍖 原作者:K同学啊|接辅导、项目定制
● 难度:夯实基础⭐⭐
● 语言:Python3、Pytorch3
● 时间:4月23日-4月28日
🍺要求:
1、熟悉NLP的基础知识
二、准备工作
环境搭建
Python 3.8
pytorch == 1.8.1
torchtext == 0.9.1
三、数据预处理
1.加载数据

import torch
import torch.nn as nn
import os,PIL,pathlib,warningswarnings.filterwarnings("ignore") #忽略警告信息# win10系统
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
import pandas as pd# 加载自定义中文数据
train_data = pd.read_csv('./data/train.csv', sep='\t', header=None)
train_data.head()
# 构造数据集迭代器
def coustom_data_iter(texts, labels):for x, y in zip(texts, labels):yield x, ytrain_iter = coustom_data_iter(train_data[0].values[:], train_data[1].values[:])
2.构建词典
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
# conda install jieba -y
import jieba# 中文分词方法
tokenizer = jieba.lcutdef yield_tokens(data_iter):for text,_ in data_iter:yield tokenizer(text)vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"]) # 设置默认索引,如果找不到单词,则会选择默认索引
vocab(['我','想','看','和平','精英','上','战神','必备','技巧','的','游戏','视频'])
label_name = list(set(train_data[1].values[:]))
print(label_name)
text_pipeline = lambda x: vocab(tokenizer(x))
label_pipeline = lambda x: label_name.index(x)print(text_pipeline('我想看和平精英上战神必备技巧的游戏视频'))
print(label_pipeline('Video-Play'))
3.生成数据批次和迭代器
from torch.utils.data import DataLoaderdef collate_batch(batch):label_list, text_list, offsets = [], [], [0]for (_text,_label) in batch:# 标签列表label_list.append(label_pipeline(_label))# 文本列表processed_text = torch.tensor(text_pipeline(_text), dtype=torch.int64)text_list.append(processed_text)# 偏移量,即语句的总词汇量offsets.append(processed_text.size(0))label_list = torch.tensor(label_list, dtype=torch.int64)text_list = torch.cat(text_list)offsets = torch.tensor(offsets[:-1]).cumsum(dim=0) #返回维度dim中输入元素的累计和return text_list.to(device),label_list.to(device), offsets.to(device)# 数据加载器,调用示例
dataloader = DataLoader(train_iter,batch_size=8,shuffle =False,collate_fn=collate_batch)
三、模型构建
1. 搭建模型
from torch import nnclass TextClassificationModel(nn.Module):def __init__(self, vocab_size, embed_dim, num_class):super(TextClassificationModel, self).__init__()self.embedding = nn.EmbeddingBag(vocab_size, # 词典大小embed_dim, # 嵌入的维度sparse=False) # self.fc = nn.Linear(embed_dim, num_class)self.init_weights()def init_weights(self):initrange = 0.5self.embedding.weight.data.uniform_(-initrange, initrange) # 初始化权重self.fc.weight.data.uniform_(-initrange, initrange) self.fc.bias.data.zero_() # 偏置值归零def forward(self, text, offsets):embedded = self.embedding(text, offsets)return self.fc(embedded)
2. 初始化模型
num_class = len(label_name)
vocab_size = len(vocab)
em_size = 64
model = TextClassificationModel(vocab_size, em_size, num_class).to(device)
3. 定义训练与评估函数
import timedef train(dataloader):model.train() # 切换为训练模式total_acc, train_loss, total_count = 0, 0, 0log_interval = 50start_time = time.time()for idx, (text,label,offsets) in enumerate(dataloader):predicted_label = model(text, offsets)optimizer.zero_grad() # grad属性归零loss = criterion(predicted_label, label) # 计算网络输出和真实值之间的差距,label为真实值loss.backward() # 反向传播torch.nn.utils.clip_grad_norm_(model.parameters(), 0.1) # 梯度裁剪optimizer.step() # 每一步自动更新# 记录acc与losstotal_acc += (predicted_label.argmax(1) == label).sum().item()train_loss += loss.item()total_count += label.size(0)if idx % log_interval == 0 and idx > 0:elapsed = time.time() - start_timeprint('| epoch {:1d} | {:4d}/{:4d} batches ''| train_acc {:4.3f} train_loss {:4.5f}'.format(epoch, idx, len(dataloader),total_acc/total_count, train_loss/total_count))total_acc, train_loss, total_count = 0, 0, 0start_time = time.time()def evaluate(dataloader):model.eval() # 切换为测试模式total_acc, train_loss, total_count = 0, 0, 0with torch.no_grad():for idx, (text,label,offsets) in enumerate(dataloader):predicted_label = model(text, offsets)loss = criterion(predicted_label, label) # 计算loss值# 记录测试数据total_acc += (predicted_label.argmax(1) == label).sum().item()train_loss += loss.item()total_count += label.size(0)return total_acc/total_count, train_loss/total_count
四、训练模型
1. 拆分数据集并运行模型
from torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset
# 超参数
EPOCHS = 10 # epoch
LR = 5 # 学习率
BATCH_SIZE = 64 # batch size for trainingcriterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=LR)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.1)
total_accu = None# 构建数据集
train_iter = coustom_data_iter(train_data[0].values[:], train_data[1].values[:])
train_dataset = to_map_style_dataset(train_iter)split_train_, split_valid_ = random_split(train_dataset,[int(len(train_dataset)*0.8),int(len(train_dataset)*0.2)])train_dataloader = DataLoader(split_train_, batch_size=BATCH_SIZE,shuffle=True, collate_fn=collate_batch)valid_dataloader = DataLoader(split_valid_, batch_size=BATCH_SIZE,shuffle=True, collate_fn=collate_batch)for epoch in range(1, EPOCHS + 1):epoch_start_time = time.time()train(train_dataloader)val_acc, val_loss = evaluate(valid_dataloader)# 获取当前的学习率lr = optimizer.state_dict()['param_groups'][0]['lr']if total_accu is not None and total_accu > val_acc:scheduler.step()else:total_accu = val_accprint('-' * 69)print('| epoch {:1d} | time: {:4.2f}s | ''valid_acc {:4.3f} valid_loss {:4.3f} | lr {:4.6f}'.format(epoch,time.time() - epoch_start_time,val_acc,val_loss,lr))print('-' * 69)
相关文章:
第N2周:中文文本分类-Pytorch实现
目录 一、前言二、准备工作三、数据预处理1.加载数据2.构建词典3.生成数据批次和迭代器 三、模型构建1. 搭建模型2. 初始化模型3. 定义训练与评估函数 四、训练模型1. 拆分数据集并运行模型 一、前言 🍨 本文为🔗365天深度学习训练营 中的学习记录博客 …...
Salesforce许可证和版本有什么区别,购买帐号时应该如何选择?
Salesforce许可证分配给特定用户,授予他们访问Salesforce产品和功能的权限。Salesforce版本和许可证是不同的概念,但极易混淆。 Salesforce版本:这是对组织购买的Salesforce产品和功能的访问权限。大致可分为Essentials、Professional、Ente…...
接口测试怎么做?全网最详细从接口测试到接口自动化详解,看这篇就够了...
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 抛出一个问题&…...

DataStore入门及在项目中的使用
首先给个官网的的地址:应用架构:数据层 - DataStore - Android 开发者 | Android Developers 小伙伴们可以直接看官网的资料,本篇文章是对官网的部分细节进行补充 一、为什么要使用DataStore 代替SharedPreferences SharedPreferences&a…...

用Python爬取中国各省GDP数据
介绍 在数据分析和经济研究中,了解中国各省份的GDP数据是非常重要的。然而,手动收集这些数据可能是一项繁琐且费时的任务。幸运的是,Python提供了一些强大的工具和库,使我们能够自动化地从互联网上爬取数据。本文将介绍如何使用P…...
深度学习-第T5周——运动鞋品牌识别
深度学习-第T5周——运动鞋品牌识别 深度学习-第T5周——运动鞋品牌识别一、前言二、我的环境三、前期工作1、导入数据集2、查看图片数目3、查看数据 四、数据预处理1、 加载数据1、设置图片格式2、划分训练集3、划分验证集4、查看标签 2、数据可视化3、检查数据4、配置数据集 …...

自媒体的孔雀效应:插根鸡毛还是专业才华?
自媒体时代,让许多原本默默无闻的人找到了表达自己的平台。有人声称,现在这个时代,“随便什么人身上插根鸡毛就可以当孔雀了”。可是,事实真的如此吗? 首先,我们不能否认的是,自媒体确实为大众提…...

Linux系统优化
一、系统启动流程 1.centos6 centos6开机启动流程,传送门 2.centos7启动流程 二、系统启动运行级别 2.1 什么是运行级别 运行级别:指操作系统当前正在运行的功能级别; [rootweb01 ~]# ll /usr/lib/systemd/system lrwxrwxrwx. 1 root root…...

Java笔记_22(反射和动态代理)
Java笔记_22 一、反射1.1、反射的概述1.2、获取class对象的三种方式1.3、反射获取构造方法1.4、反射获取成员变量1.5、反射获取成员方法1.6、综合练习1.6.1、保存信息1.6.2、跟配置文件结合动态创建 一、反射 1.1、反射的概述 什么是反射? 反射允许对成员变量,成…...
前端web入门-HTML-day01
(创作不易,感谢有你,你的支持,就是我前行的最大动力,如果看完对你有帮助,请留下您的足迹) 目录 HTML初体验 HTML 定义 标签语法 总结: HTML 基本骨架 基础知识: 总结&#…...

创建一个Go项目
创建一个Go项目 1.创建项目 package mainfunc main() {println("你好啊,简单点了!") }如果是本地的话可以采用go run 项目名的方式。 可以采用go run --work 项目名的方式,此时可以展示日志信息。 如果是只编译的话 go build 项…...

从 Spring 的创建到 Bean 对象的存储、读取
目录 创建 Spring 项目: 1.创建一个 Maven 项目: 2.添加 Spring 框架支持: 3.配置资源文件: 4.添加启动类: Bean 对象的使用: 1.存储 Bean 对象: 1.1 创建 Bean: 1.2 存储 B…...

【一文吃透归并排序】基本归并·原地归并·自然归并 C++
目录 1 引入情境基本归并排序实现 C 2 原地归并排序2-1 死板的解法2-2 原地工作区2-3 链表归并排序 3 自底向上归并排序4 两路自然归并排序4-1 形式化描述4-2 代码实现 1 引入情境 归并思想:假设有两队小孩,都是从矮到高排序,现在通过一扇门后…...

读《Spring Boot 3核心技术与最佳实践》有感
我是谁? 👨🎓作者:bug菌 ✏️博客:CSDN、掘金、infoQ、51CTO等 🎉简介:CSDN/阿里云/华为云/51CTO博客专家,C站历届博客之星Top50,掘金/InfoQ/51CTO等社区优质创作者&am…...

板子短路了?
有段时间没更新了,主要是最近有点忙,当然也因为有点“懒”。 做这行业的都知道,下半年都是比较忙的,相信大家也是! 相信做硬件的小伙伴们,遇到过短路的板子已经不计其数了。 短路带来的危害:…...

一行代码绘制高分SCI限制立方图
一、概述 Restricted cubic splines (RCS)是一种基于样条函数的非参数化模型,它可以可靠地拟合非线性关系,可以自适应地调整分割结点。在统计学和机器学习领域,RCS通常用来对连续型自变量进行建模,并在解释自变量与响应变量的关系…...
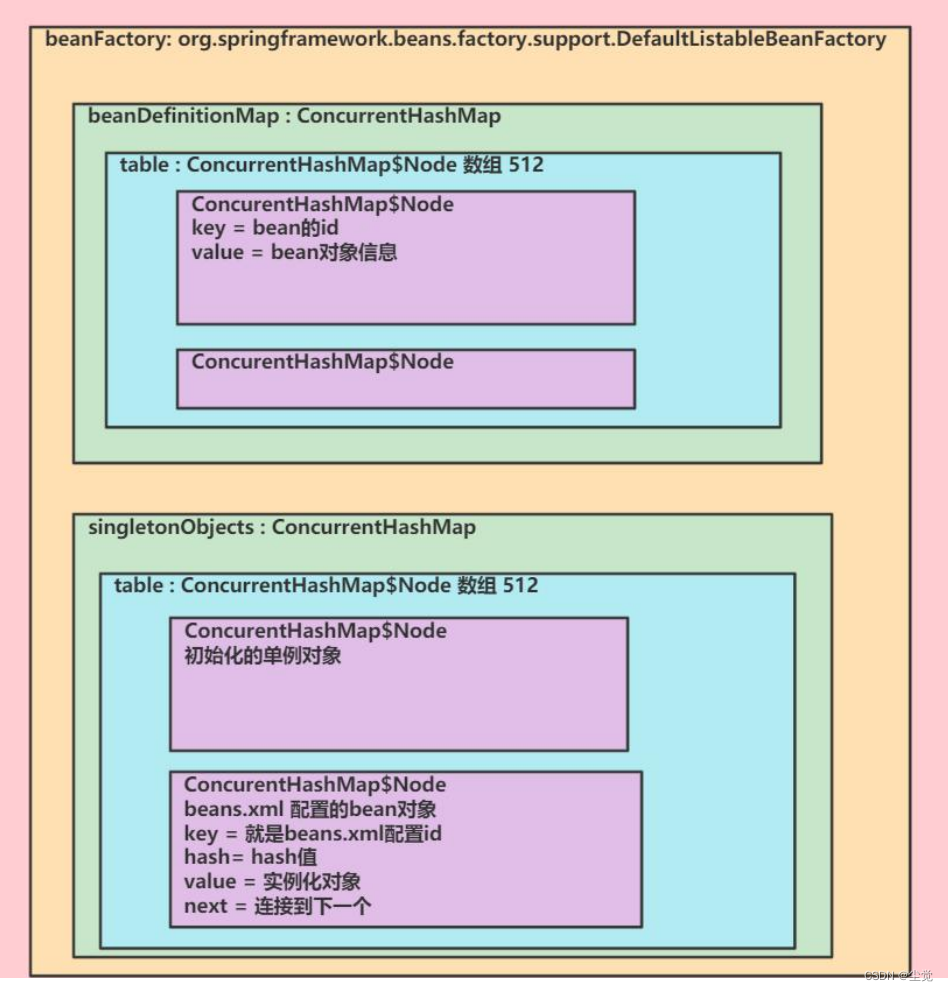
spring 容器结构/机制debug分析--Spring 学习的核心内容和几个重要概念--IOC 的开发模式--综合解图
目录 Spring Spring 学习的核心内容 解读上图: Spring 几个重要概念 ● 传统的开发模式 解读上图 ● IOC 的开发模式 解读上图 代码示例—入门 xml代码 注意事项和细节 1、说明 2、解释一下类加载路径 3、debug 看看 spring 容器结构/机制 综合解图 Spring Spr…...
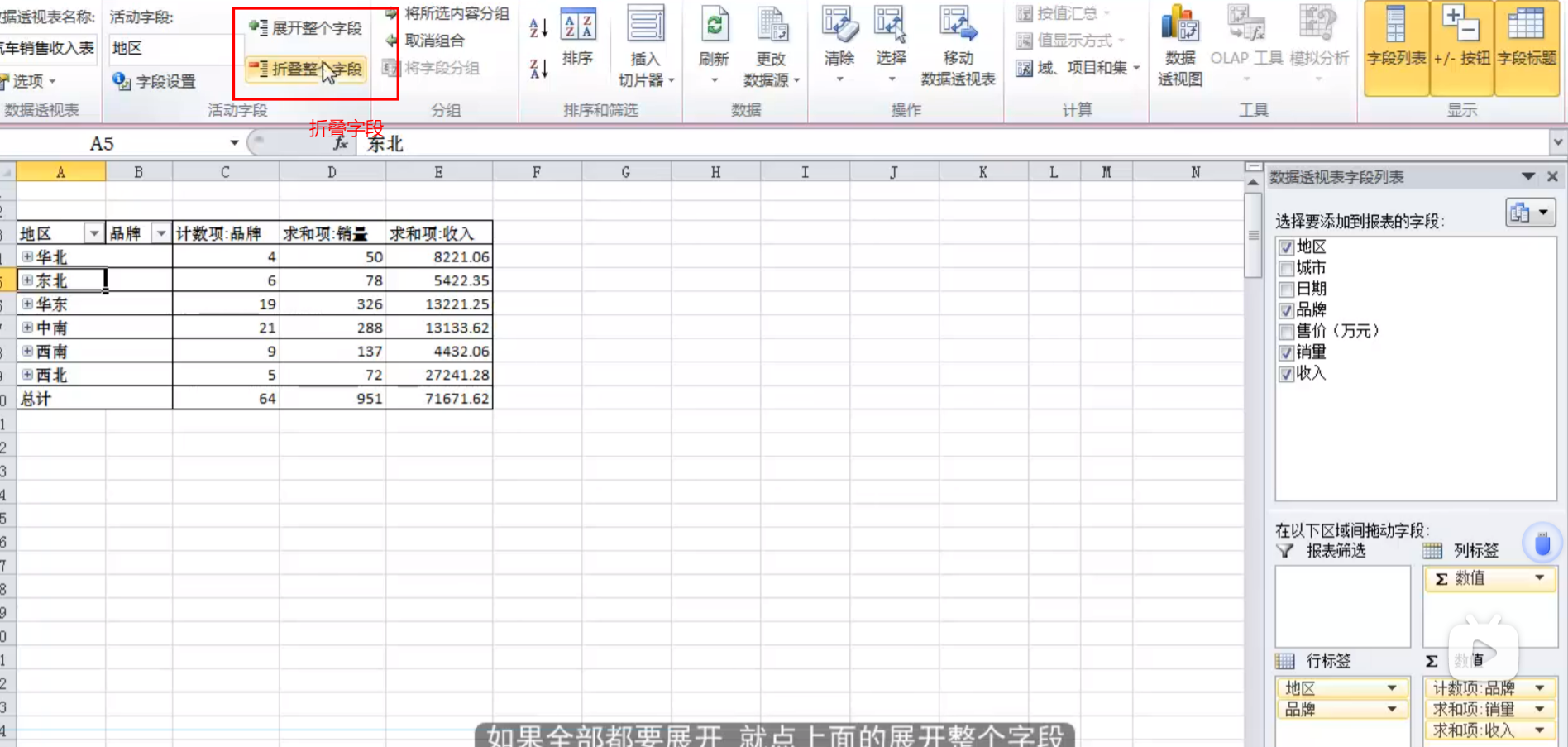
excel实战小测第四
【项目背景】 本项目为某招聘网站部分招聘信息,要求对“数据分析师”岗位进行招聘需求分析,通过对城市、行业、学历要求、薪资待遇等不同方向进行相关性分析,加深对数据分析行业的了解。 结合企业真实招聘信息,可以帮助有意转向数…...
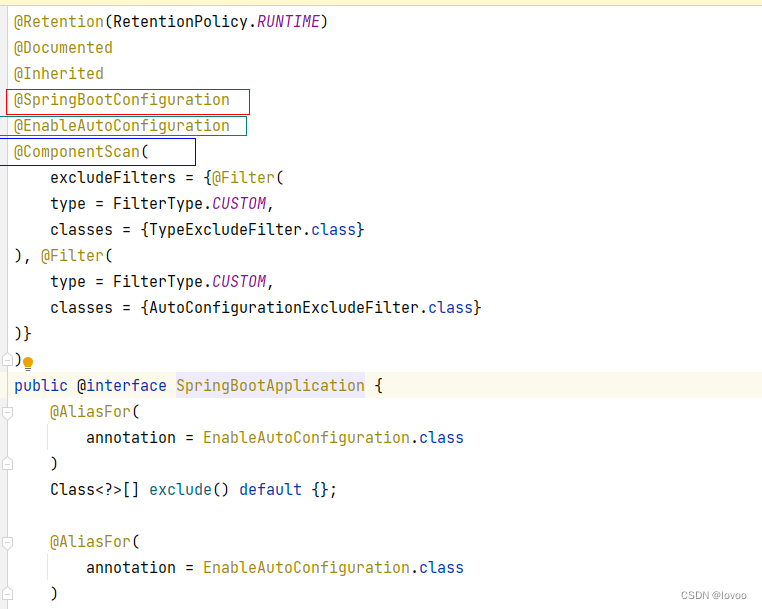
什么是SpringBoot自动配置
概述: 现在的Java面试基本都会问到你知道什么是Springboot的自动配置。为什么面试官要问这样的问题,主要是在于看你有没有对Springboot的原理有没有深入的了解,有没有看过Springboot的源码,这是区别普通程序员与高级程序员最好的…...
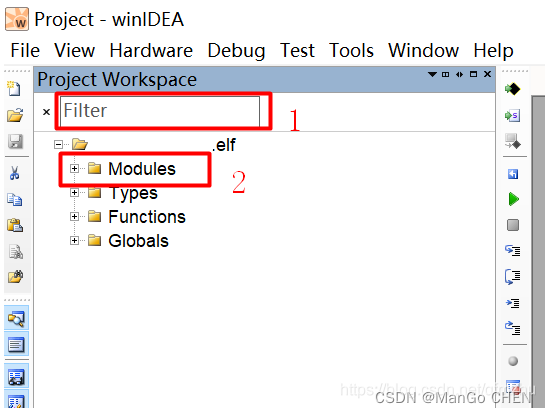
基于IC5000烧录器使用winIDEA烧写+调试程序(S32K324的软件烧写与调试)
目录 一、iSYSTEM简介二、如何使用iSYSTEM winIDEA烧写调试程序2.1 打开winIDEA:2.2 新建一个Workspace;2.3 硬件配置:2.4 选择CPU芯片型号:2.5 加载烧写文件:2.6 开始烧录程序:2.7 程序调试Debug:2.7.1 运行程序&…...

开发者的第二曲线:2026年最赚钱的5个技术副业
在技术范式加速重构的2026年,软件质量保障的重要性已从“成本中心”跃升为“价值中心”。对于敏锐的软件测试从业者而言,这不仅是职业的深化,更是将专业壁垒转化为财富增长的绝佳契机。传统的“接私活”模式正在被更具复利效应和杠杆价值的“…...

如何跨越语言盲区,让学术表达精准落地
当我们完成了精妙的实验设计,获得了宝贵的数据,准备向世界展示科研成果时,却常常在“最后一公里”遭遇阻碍。这种阻碍并非源于科研本身的深度,而是来自于语言表达的信心不足与自查盲区。你是否也有过这样的经历:对着屏…...

小觅相机‘凉了’之后,我们如何用它的SDK和开源工具链构建自己的SLAM数据集?
从废弃硬件到研究利器:小觅相机SDK与开源工具链的SLAM数据集构建指南 当一款硬件产品的厂商突然消失,官网关闭、技术支持中断,那些被遗弃的设备往往会被贴上"电子垃圾"的标签。但作为一名SLAM研究者或爱好者,你是否想过…...

别再花钱买内网穿透服务了!手把手教你用frp+Linux云服务器搭建自己的专属通道
零成本打造私有内网穿透通道:frp与Linux云服务器实战指南 你是否曾为远程访问家中NAS、调试开发环境或搭建私有云服务而烦恼?市面上动辄数百元的商业内网穿透服务不仅价格高昂,还常受限于带宽和稳定性。本文将带你用一台基础配置的Linux云服…...

GLM-4.1V-9B-Base行业实践:农业病虫害田间照片识别与防治建议辅助
GLM-4.1V-9B-Base行业实践:农业病虫害田间照片识别与防治建议辅助 1. 农业场景下的视觉AI需求 在现代农业生产中,病虫害防治一直是困扰农户的核心问题。传统识别方法依赖农技人员现场勘查,效率低下且成本高昂。根据农业农村部数据ÿ…...

巧用Google Maps与ScreenToGif:零行程数据也能轻松生成动态路线图
1. 从零开始制作动态路线图的必备工具 最近有个朋友问我:"想给客户展示项目选址的交通路线,但实地考察还没开始,怎么做出专业的动态路线图?"这让我想起自己两年前第一次做商业提案时的窘境——当时为了展示物流配送路线…...

Vivado平台下PCIe IP核选型指南:从硬核到XDMA的实战抉择
1. PCIe技术基础与Vivado开发环境搭建 第一次接触PCIe接口开发时,我被各种专业术语搞得晕头转向。后来才发现,理解PCIe就像理解高速公路系统一样简单。PCIe本质上是一种点对点的高速串行总线,就像城市间修建的多车道高速公路。每个"车道…...

Z-Image-GGUF中文支持实测:古风建筑、水墨山水、国潮设计等本土化效果展示
Z-Image-GGUF中文支持实测:古风建筑、水墨山水、国潮设计等本土化效果展示 1. 引言:当AI绘画遇上东方美学 最近在测试各种文生图模型时,我发现了一个挺有意思的现象:很多国外开发的AI绘画工具,在处理中国传统文化元素…...

Qwen2-VL-2B-Instruct一键部署教程:基于Ubuntu 20.04的GPU环境快速搭建
Qwen2-VL-2B-Instruct一键部署教程:基于Ubuntu 20.04的GPU环境快速搭建 你是不是也遇到过这种情况?看到一个很酷的多模态大模型,想立刻上手试试,结果被复杂的依赖安装、环境配置、驱动适配搞得头大,折腾半天还没跑起来…...

Bootstrap4 导航栏详解
Bootstrap4 导航栏详解 引言 Bootstrap 是一个流行的前端框架,它为开发者提供了丰富的组件和工具,以快速构建响应式、移动优先的网站和应用程序。导航栏是网站的重要组成部分,它能够帮助用户轻松地在网站的不同页面之间导航。Bootstrap4 提供…...