tinyWebServer 学习笔记——二、HTTP 连接处理
文章目录
- 一、基础知识
- 1. epoll
- 2. 再谈 I/O 复用
- 3. 触发模式和 EPOLLONESHOT
- 4. HTTP 报文
- 5. HTTP 状态码
- 6. 有限状态机
- 7. 主从状态机
- 8. HTTP_CODE
- 9. HTTP 处理流程
- 二、代码解析
- 1. HTTP 类
- 2. 读取客户数据
- 2. epoll 事件相关
- 3. 接收 HTTP 请求
- 4. HTTP 报文解析
- 5. HTTP 请求响应
- 参考文献
一、基础知识
1. epoll
-
创建内核事件表:
int epoll_create(int size);size:不起作用,只是给内核一个提示,告诉它事件表需要多大;- 返回值:内核事件表的文件描述符;
-
修改内核事件表监控的文件描述符上的事件:
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);epfd:内核事件表的文件描述符;op:表示三种操作:注册(EPOLL_CTL_ADD)、修改(EPOLL_CTL_MOD)、删除(EPOLL_CTL_DEL);event:需要监听的事件:
标识符 事件类型 EPOLLIN 可读、对端 socket 关闭 EPOLLOUT 可写 EPOLLPRI 带外数据 EPOLLERR 错误 EPOLLHUP 文件描述符被挂断 EPOLLET 边缘触发模式 EPOLLONESHOT 只监听一次事件,每次见听完如需再次监听需重置 - 返回值:成功时返回 0 ,失败时返回 -1 并设置 errno 。
-
监听事件发生:
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);events:存储内核中发生的事件;maxevents:events的容量;timeout:超时时间:-1 表示阻塞,0 表示立即返回(非阻塞),大于 0 表示毫秒;- 返回值:就绪的文件描述符个数,超时时返回 0 ,出错时返回 -1 。
2. 再谈 I/O 复用
select:使用线性表描述文件描述符集合,存在上限,每次调用需要将所有文件描述符拷贝到内核态,需要遍历判断就绪事件,适用于少量活跃的 fd;poll:使用链表描述文件描述符集合,不存在上限,每次调用需要将所有文件描述符拷贝到内核态,需要遍历判断就绪事件,适用于少量活跃的 fd;epoll:使用红黑树描述文件描述符集合,存在上限,通过epoll_ctl将要监听的文件描述符注册到红黑树上,会将就绪事件存放在新建的链表中,适用于大量不活跃的 fd;
3. 触发模式和 EPOLLONESHOT
- LT :水平触发模式,当检测到就绪事件时,将其通知给应用程序,应用程序可以不立即处理该事件,等到下次调用
epoll_wait时会再次报告该事件; - ET :边缘触发模式,当检测到就绪事件时,将其通知给应用程序,应用程序必须立即处理,并且需要一次性处理完;
- EPOLLONESHOT :当某个 socket 的数据分两次到达时,系统可能会唤醒两个不同的线程来进行处理,若开启 EPOLLONESHOT ,则对于某个 socket 来说,只会有一个线程处理其事件,其他线程不能插手,完成一次处理后需要重置 EPOLLONESHOT 。
4. HTTP 报文
HTTP 报文分为请求报文和响应报文,前者由浏览器发送给服务器,后者由服务器应答浏览器,请求报文又分为 GET 和 POST 两种:
GET /562f25980001b1b106000338.jpg HTTP/1.1
Host:img.mukewang.com
User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36
Accept:image/webp,image/*,*/*;q=0.8
Referer:http://www.imooc.com/
Accept-Encoding:gzip, deflate, sdch
Accept-Language:zh-CN,zh;q=0.8
空行
请求数据为空
- 第 1 行:请求行,用来说明请求类型、要访问的资源、所使用的 HTTP 版本;
- 第 2 - 8 行:请求头部,通常包含如下信息:
- Host :服务器所在的域名;
- User-Agent :HTTP 客户端程序的信息,由浏览器定义并自动发送;
- Accept :说明用户代理可处理的媒体类型;
- Accept-Encoding :说明用户代理支持的内容编码;
- Accept-Language :说明用户代理能够处理的自然语言集;
- Content-Type :说明实现主体的媒体类型;
- Content-Length:说明实现主题的大小;
- Connection :连接管理,可以是 Keep-Alive 或 close ;
- 第 9 行:空行;
- 第 10 行:请求数据,也叫主体,可以添加任意其他数据;
POST / HTTP1.1 Host:www.wrox.com User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022) Content-Type:application/x-www-form-urlencoded Content-Length:40 Connection: Keep-Alive 空行 name=Professional%20Ajax&publisher=Wiley - GET 的请求数据通常为空,POST 则包含要请求的信息。
响应报文主要有四个部分组成:状态行、消息报头、空行、响应正文:
HTTP/1.1 200 OK
Date: Fri, 22 May 2009 06:07:21 GMT
Content-Type: text/html; charset=UTF-8
空行
<html><head></head><body><!--body goes here--></body>
</html>
- 第 1 行:状态行,由 HTTP 协议版本号、状态码、状态消息组成;
- 第 2 - 3 行:消息报头,用来说明客户端需要使用的附加信息:
- Date :生成响应的日期和时间;
- Content-Type :指定了 MIME 类型的 HTML ,编码类型是 UTF-8 ;
- 第 4 行:空行;
- 第 5 - 10 行:响应正文,为 HTML 语言。
5. HTTP 状态码
- 1xx :指示信息,表示请求已接收,继续处理;
- 2xx :成功,表示请求正常处理完毕:
- 200 OK :客户端请求被正常处理;
- 206 Partial Content :客户端进行了范围请求;
- 3xx :重定向,要完成请求需要进一步操作:
- 301 Moved Permanently :永久重定向,返回新的 URL ;
- 302 Found :临时重定向,返回临时的 URL ;
- 4xx :客户端错误:
- 400 Bad Request :语法错误;
- 403 Forbidden :请求被服务器拒绝;
- 404 Not Found :请求不存在,服务器上找不到请求的资源;
- 5xx :服务器端错误:
- 500 Internal Server Error :服务器执行时出错。
6. 有限状态机
有限状态机是一种抽象的理论模型,使用选择语句来实现。模型要求代码存在 n 个状态,使用当前状态 cur_state 来进行标记,每次处理完任务后都对其进行更改以实现状态跳转,代码如下:
STATE_MACHINE(){State cur_State = type_A;while(cur_State != type_C){Package _pack = getNewPackage();switch() {case type_A:process_pkg_state_A(_pack);cur_State = type_B;break;case type_B:process_pkg_state_B(_pack);cur_State = type_C;break;}}
}
7. 主从状态机
主从状态机也是一种抽象的理论模型,在本项目中从状态机负责读取 HTTP 请求的一行,主状态机负责对该行数据进行解析,主状态机内部调用从状态机,从状态机驱动主状态机,流程图如下:
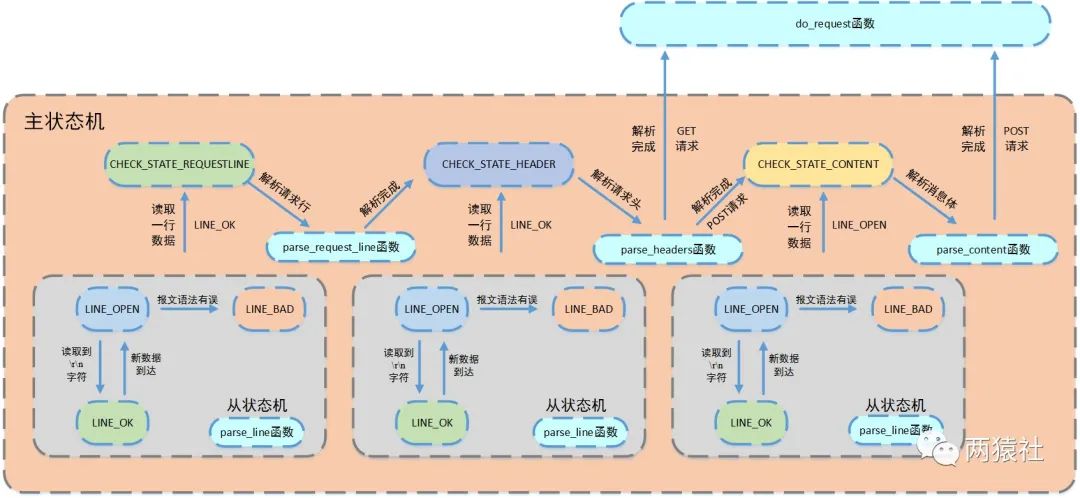
从模型的角度来看,从状态机负责通用的操作处理,主状态机负责特定的操作处理,主状态机需要使用从状态机提供的数据,从状态机需要被主状态机调用,每个状态机又是一个有限状态机。本项目中主从状态机各有三种状态:
- 主状态机:标识解析位置
- CHECK_STATE_REQUESTLINE :解析请求行;
- CHECK_STATE_HEADER :解析请求头;
- CHECK_STATE_CONTENT :解析消息体,仅用于解析 POST 请求;
- 从状态机:标识解析一行的读取状态:
- LINE_OK :完整读取一行;
- LINE_BAD :报文语法错误;
- LINE_OPEN :读取的行不完整。
8. HTTP_CODE
标识了 HTTP 请求的处理结果:
- NO_REQUEST :请求不完整,需要继续读取请求报文,跳转主程序继续检测可读事件;
- GET_REQUEST :获得了完整的请求,调用 do_request 完成请求资源映射;
- NO_RESOURCE :请求资源不存在,跳转 process_write 完成响应报文;
- BAD_REQUEST :语法错误或请求资源为目录,跳转 process_write 完成响应报文;
- FORBIDDEN_REQUEST :请求资源禁止访问,跳转 process_write 完成响应报文;
- FILE_REQUEST :请求资源可以正常访问,跳转 process_write 完成响应报文;
- INTERNAL_ERROR :服务器内部错误。
9. HTTP 处理流程
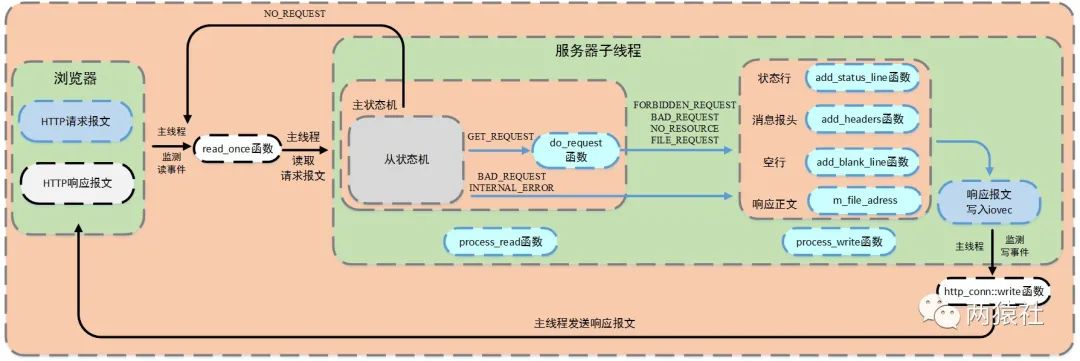
- 浏览器发出 HTTP 连接请求;
- 主线程创建 HTTP 对象,接收请求并将所有数据读入对应的缓存区;
- 主线程将 HTTP 对象插入任务队列;
- 工作线程从任务队列中取出一个任务;
- 工作线程调用 process_read 函数,通过主从状态机解析请求报文;
- 解析完成后,跳转 do_request 函数生成响应报文;
- 通过 process_write 写入缓存区;
- 发送数据给浏览器。
二、代码解析
1. HTTP 类
// http连接类
class http_conn
{
public:static const int FILENAME_LEN = 200; // 文件名最大长度static const int READ_BUFFER_SIZE = 2048; // 读缓存区大小static const int WRITE_BUFFER_SIZE = 1024; // 写缓存区大小// http连接的方法enum METHOD{GET = 0, // 申请获得资源POST, // 向服务器提交数据并修改HEAD, // 仅获取头部信息PUT, // 上传某个资源DELETE, // 删除某个资源TRACE, // 要求服务器返回原始HTTP请求的内容,可用来查看服务器对HTTP请求的影响OPTIONS, // 查看服务器对某个特定URL都支持哪些请求方法。也可把URL设置为* ,从而获得服务器支持的所有请求方法CONNECT, // 用于某些代理服务器,能把请求的连接转化为一个安全隧道PATH // 对某个资源做部分修改};// 主状态机状态enum CHECK_STATE{CHECK_STATE_REQUESTLINE = 0, // 检查请求行CHECK_STATE_HEADER, // 检查头部状态CHECK_STATE_CONTENT // 检查内容};// HTTP状态码enum HTTP_CODE{NO_REQUEST, // 请求不完整,需要继续读取请求报文数据GET_REQUEST, // 获取了完整请求BAD_REQUEST, // HTTP请求报文有语法错误NO_RESOURCE, // 无资源FORBIDDEN_REQUEST, // 禁止请求FILE_REQUEST, // 文件请求INTERNAL_ERROR, // 服务器内部错误CLOSED_CONNECTION // 关闭连接};// 从状态机状态enum LINE_STATUS{LINE_OK = 0, // 读取完成LINE_BAD, // 读取有错误LINE_OPEN // 未读完};public:// 构造函数http_conn() {}// 析构函数~http_conn() {}public:// 初始化套接字地址,函数内部会调用私有方法initvoid init(int sockfd, const sockaddr_in &addr, char *, int, int, string user, string passwd, string sqlname);// 关闭http连接void close_conn(bool real_close = true);// 处理HTTP请求的入口函数void process();// 读取浏览器端发来的全部数据bool read_once();// 响应报文写入函数bool write();// 地址sockaddr_in *get_address(){return &m_address;}// 同步线程初始化数据库读取表void initmysql_result(connection_pool *connPool);// 计时器标志int timer_flag;int improv;private:void init(); // 初始化HTTP_CODE process_read(); // 从m_read_buf读取,并处理请求报文bool process_write(HTTP_CODE ret); // 向m_write_buf写入响应报文数据HTTP_CODE parse_request_line(char *text); // 主状态机,解析http请求行HTTP_CODE parse_headers(char *text); // 主状态机,解析http请求头HTTP_CODE parse_content(char *text); // 主状态机,判断http请求内容HTTP_CODE do_request(); // 生成响应报文char *get_line() { return m_read_buf + m_start_line; }; // 用于将指针向后偏移,指向未处理的字符LINE_STATUS parse_line(); // 从状态机,分析一行的内容,返回状态void unmap(); // 关闭内存映射// 根据响应报文格式,生成对应8个部分,以下函数均由do_request调用bool add_response(const char *format, ...); // responsebool add_content(const char *content); // contentbool add_status_line(int status, const char *title); // status_linebool add_headers(int content_length); // headersbool add_content_type(); // content_typebool add_content_length(int content_length); // content_lengthbool add_linger(); // lingerbool add_blank_line(); // blank_linepublic:static int m_epollfd; // 最大文件描述符个数static int m_user_count; // 当前用户连接数MYSQL *mysql; // 数据库指针int m_state; // 读为0, 写为1private:int m_sockfd; // 当前fdsockaddr_in m_address; // 当前地址char m_read_buf[READ_BUFFER_SIZE]; // 存储读取的请求报文数据long m_read_idx; // 缓冲区中m_read_buf中数据的最后一个字节的下一个位置long m_checked_idx; // m_read_buf读取的位置m_checked_idxint m_start_line; // m_read_buf中已经解析的字符个数char m_write_buf[WRITE_BUFFER_SIZE]; // 存储发出的响应报文数据int m_write_idx; // 指示buffer中的长度CHECK_STATE m_check_state; // 主状态机状态METHOD m_method; // 请求方法// 以下为解析请求报文中对应的6个变量char m_real_file[FILENAME_LEN]; // 存储读取文件的名称char *m_url; // urlchar *m_version; // versionchar *m_host; // hostlong m_content_length; // content_lengthbool m_linger; // lingerchar *m_file_address; // 读取服务器上的文件地址struct stat m_file_stat; // 文件状态struct iovec m_iv[2]; // io向量机制iovec,标识两个缓存区int m_iv_count; // 表示缓存区个数int cgi; // 是否启用的POSTchar *m_string; // 存储请求头数据int bytes_to_send; // 待发送字节个数int bytes_have_send; // 已发送字节个数char *doc_root; // 文件根目录map<string, string> m_users; // 用户名密码对int m_TRIGMode; // 触发模式int m_close_log; // 是否关闭logchar sql_user[100]; // 用户名char sql_passwd[100]; // 用户密码char sql_name[100]; // 数据库名
};
2. 读取客户数据
// 循环读取客户数据,直到无数据可读或对方关闭连接
// 非阻塞ET工作模式下,需要一次性将数据读完
bool http_conn::read_once()
{// 超出最大读缓存限制if (m_read_idx >= READ_BUFFER_SIZE){return false;}// 标志有多少字节int bytes_read = 0;// LT读取数据if (0 == m_TRIGMode){// 接收数据,保存到读缓存区bytes_read = recv(m_sockfd, m_read_buf + m_read_idx, READ_BUFFER_SIZE - m_read_idx, 0);// 修改m_read_idx的读取字节数m_read_idx += bytes_read;// 未读到数据if (bytes_read <= 0){return false;}return true;}// ET读数据else{while (true){// 接收数据,保存到读缓存区bytes_read = recv(m_sockfd, m_read_buf + m_read_idx, READ_BUFFER_SIZE - m_read_idx, 0);// 读取异常if (bytes_read == -1){// 判断errno是否为重试或未发送完残留数据if (errno == EAGAIN || errno == EWOULDBLOCK)break;// 不是则出错return false;}// 读取为空else if (bytes_read == 0){return false;}// 修改m_read_idx的读取字节数m_read_idx += bytes_read;}return true;}
}
2. epoll 事件相关
主要有四个:设置非阻塞模式、注册事件、删除事件、重置 EPOLLONESHOT 事件:
// 对文件描述符设置非阻塞
int setnonblocking(int fd)
{int old_option = fcntl(fd, F_GETFL);int new_option = old_option | O_NONBLOCK;fcntl(fd, F_SETFL, new_option);return old_option;
}// 将内核事件表注册新事件,开启ET模式,选择开启EPOLLONESHOT
void addfd(int epollfd, int fd, bool one_shot, int TRIGMode)
{epoll_event event;event.data.fd = fd;// 触发组合模式:ET模式if (1 == TRIGMode)event.events = EPOLLIN | EPOLLET | EPOLLRDHUP;// 默认模式:LT监听、连接elseevent.events = EPOLLIN | EPOLLRDHUP;// one shot模式,保证一个socket只有一个线程操作if (one_shot)event.events |= EPOLLONESHOT;epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event);setnonblocking(fd);
}// 从内核事件表删除事件
void removefd(int epollfd, int fd)
{epoll_ctl(epollfd, EPOLL_CTL_DEL, fd, 0);close(fd);
}// 将事件重置为EPOLLONESHOT事件
void modfd(int epollfd, int fd, int ev, int TRIGMode)
{epoll_event event;event.data.fd = fd;if (1 == TRIGMode)event.events = ev | EPOLLET | EPOLLONESHOT | EPOLLRDHUP;elseevent.events = ev | EPOLLONESHOT | EPOLLRDHUP;epoll_ctl(epollfd, EPOLL_CTL_MOD, fd, &event);
}
3. 接收 HTTP 请求
浏览器发出 HTTP 连接,主线程创建 HTTP 对象以接受请求,并将所有数据读入对应的缓存区,然后将该对象插入工作队列,工作线程从工作队列中取出一个任务进行处理:
//创建MAX_FD个http类对象
http_conn* users=new http_conn[MAX_FD];//创建内核事件表
epoll_event events[MAX_EVENT_NUMBER];
epollfd = epoll_create(5);
assert(epollfd != -1);//将listenfd放在epoll树上
addfd(epollfd, listenfd, false);//将上述epollfd赋值给http类对象的m_epollfd属性
http_conn::m_epollfd = epollfd;while (!stop_server)
{//等待所监控文件描述符上有事件的产生int number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1);if (number < 0 && errno != EINTR){break;}//对所有就绪事件进行处理for (int i = 0; i < number; i++){int sockfd = events[i].data.fd;//处理新到的客户连接if (sockfd == listenfd){struct sockaddr_in client_address;socklen_t client_addrlength = sizeof(client_address);
//LT水平触发
#ifdef LTint connfd = accept(listenfd, (struct sockaddr *)&client_address, &client_addrlength);if (connfd < 0){continue;}if (http_conn::m_user_count >= MAX_FD){show_error(connfd, "Internal server busy");continue;}users[connfd].init(connfd, client_address);
#endif//ET非阻塞边缘触发
#ifdef ET//需要循环接收数据while (1){int connfd = accept(listenfd, (struct sockaddr *)&client_address, &client_addrlength);if (connfd < 0){break;}if (http_conn::m_user_count >= MAX_FD){show_error(connfd, "Internal server busy");break;}users[connfd].init(connfd, client_address);}continue;
#endif}//处理异常事件else if (events[i].events & (EPOLLRDHUP | EPOLLHUP | EPOLLERR)){//服务器端关闭连接}//处理信号else if ((sockfd == pipefd[0]) && (events[i].events & EPOLLIN)){}//处理客户连接上接收到的数据else if (events[i].events & EPOLLIN){//读入对应缓冲区if (users[sockfd].read_once()){//若监测到读事件,将该事件放入请求队列pool->append(users + sockfd);}else{//服务器关闭连接}}}
}
4. HTTP 报文解析
HTTP 报文解析流程如下:
process_read函数:通过 while 循环,将主从状态机进行封装,对报文的每一行进行处理:- 将从状态设为
LINE_OK,作为循环的入口条件; - 首先在循环中会解析请求行;
- 然后解析请求头,若是 GET 请求则到此为止,若是 POST 请求则继续;
- 解析消息体,同时处理从状态防止再次解析;
- 循环的判断条件有特殊含义,注释中已给出说明;
- 将从状态设为
parse_line函数:从状态机,负责解析一行数据:- 在 HTTP 报文中,每一行数据由 \r\n 作为结束,据此可以判断行;
- 每次找到并处理 \r\n 后,将其置为 \0\0 ;
- 读取中,若当前字符为 \r ,可能出现三种情况:
- 下一个字符为 \n ,将 m_checked_idx 指向下一行的开头,返回 LINE_OK ;
- 读到了缓存区末尾,标识还需要继续接收数据,返回 LINE_OPEN ;
- 其他,标识语法错误,返回 LINE_BAD ;
- 若当前字节为 \n ,则意味着中途没接收完整,对应上一种情况的第二条,此时判断前一个字符是否为 \r 即可;
- 若当前字符不为上述两种情况,则接收不完整,返回 LINE_OPEN ;
- 由于已将 \r\n 改为了 \0\0 ,因此主状态机可以直接进行字符串处理;
get_line函数:用于将指针向后偏移,指向未处理的字符,即处理一行数据;parse_request_line函数:主状态机,负责解析 HTTP 请求的请求行:- 初始状态为 CHECK_STATE_REQUESTLINE ;
- 从
m_read_buf中解析 HTTP 请求行,获取请求方法、目标 URL 和 HTTP 版本号; - 将状态改为 CHECK_STATE_HEADER ;
parse_headers函数:主状态机,负责解析 HTTP 请求的请求头:- 由于请求头和空行的处理使用的同一个函数,因此需要通过根据当前的 text 首位是不是 \0 来判断是空行还是请求头;
- 请求头有多行,因此需要根据具体含义进行解析;
- 如果是 GET 请求,则到此为止;如果是 POST 请求,则还需解析消息体(将状态改为 CHECK_STATE_CONTENT);
parse_content函数:主状态机,负责解析 HTTP 请求的消息体;
// 解析+响应的入口函数
void http_conn::process()
{// 报文解析,获取状态码HTTP_CODE read_ret = process_read();if (read_ret == NO_REQUEST){// 注册并监听读事件modfd(m_epollfd, m_sockfd, EPOLLIN, m_TRIGMode);return;}// 报文响应,是否成功bool write_ret = process_write(read_ret);if (!write_ret){close_conn();}// 注册并监听写事件modfd(m_epollfd, m_sockfd, EPOLLOUT, m_TRIGMode);
}// 用于将指针向后偏移,指向未处理的字符,即处理一行数据
char* http_conn::get_line() { return m_read_buf + m_start_line; }; // 解析http请求,调用了主状态机、从状态机
http_conn::HTTP_CODE http_conn::process_read()
{// 初始化从状态机状态、HTTP请求解析结果LINE_STATUS line_status = LINE_OK;HTTP_CODE ret = NO_REQUEST;char *text = 0;// 循环处理,由从状态机驱动// 前一部分判断条件用于处理请求数据(消息体),因为这部分最后面没有\r\n,无法用从状态机判断// 前一部分判断条件主要使用主状态机来判断消息体,而因为这部分处理完后状态并没有发生改变,因此还需要从状态机来标记只处理一次while ((m_check_state == CHECK_STATE_CONTENT && line_status == LINE_OK) || ((line_status = parse_line()) == LINE_OK)){// 指向读缓存区目标行的位置text = get_line();//m_start_line是每一个数据行在m_read_buf中的起始位置//m_checked_idx表示从状态机在m_read_buf中读取的位置m_start_line = m_checked_idx;LOG_INFO("%s", text);// 主状态机三种状态转换switch (m_check_state){// 解析请求行case CHECK_STATE_REQUESTLINE:{ret = parse_request_line(text);if (ret == BAD_REQUEST)return BAD_REQUEST;break;}// 解析请求头case CHECK_STATE_HEADER:{ret = parse_headers(text);if (ret == BAD_REQUEST)return BAD_REQUEST;//完整解析GET请求后,跳转到报文响应函数else if (ret == GET_REQUEST){return do_request();}break;}// 解析消息体case CHECK_STATE_CONTENT:{ret = parse_content(text);//完整解析POST请求后,跳转到报文响应函数if (ret == GET_REQUEST)return do_request();line_status = LINE_OPEN;break;}// 都不是则表示服务器错误default:return INTERNAL_ERROR;}}return NO_REQUEST;
}// 从状态机,用于分析出一行内容
// 返回值为行的读取状态,有LINE_OK,LINE_BAD,LINE_OPEN
//m_read_idx指向缓冲区m_read_buf的数据末尾的下一个字节
//m_checked_idx指向从状态机当前正在分析的字节
http_conn::LINE_STATUS http_conn::parse_line()
{char temp;// 逐字节读for (; m_checked_idx < m_read_idx; ++m_checked_idx){//temp为将要分析的字节temp = m_read_buf[m_checked_idx];//如果当前是\r字符,则有可能会读取到完整行if (temp == '\r'){//下一个字符达到了buffer结尾,则接收不完整,需要继续接收if ((m_checked_idx + 1) == m_read_idx)return LINE_OPEN;//下一个字符是\n,将\r\n改为\0\0else if (m_read_buf[m_checked_idx + 1] == '\n'){// 标记缓存结束,返回LINE_OKm_read_buf[m_checked_idx++] = '\0';m_read_buf[m_checked_idx++] = '\0';return LINE_OK;}//如果都不符合,则返回语法错误return LINE_BAD;}//如果当前字符是\n,也有可能读取到完整行//一般是上次读取到\r就到buffer末尾了,没有接收完整,再次接收时会出现这种情况else if (temp == '\n'){//前一个字符是\r,则接收完整if (m_checked_idx > 1 && m_read_buf[m_checked_idx - 1] == '\r'){m_read_buf[m_checked_idx - 1] = '\0';m_read_buf[m_checked_idx++] = '\0';return LINE_OK;}return LINE_BAD;}}// 没读到换行符和回车符,说明行未读完return LINE_OPEN;
}// 主状态机,解析http请求行,获得请求方法,目标url及http版本号
http_conn::HTTP_CODE http_conn::parse_request_line(char *text)
{//在HTTP报文中,请求行用来说明请求类型,要访问的资源以及所使用的HTTP版本,其中各个部分之间通过\t或空格分隔。//请求行中最先含有空格和\t任一字符的位置并返回m_url = strpbrk(text, " \t");//如果没有空格或\t,则报文格式有误if (!m_url){return BAD_REQUEST;}//将该位置改为\0,用于将前面数据取出*m_url++ = '\0';//取出数据,并通过与GET和POST比较,以确定请求方式char *method = text;if (strcasecmp(method, "GET") == 0)m_method = GET;else if (strcasecmp(method, "POST") == 0){m_method = POST;cgi = 1;}// 返回坏请求标志elsereturn BAD_REQUEST;//m_url此时跳过了第一个空格或\t字符,但不知道之后是否还有//将m_url向后偏移,通过查找,继续跳过空格和\t字符,指向请求资源的第一个字符m_url += strspn(m_url, " \t");//使用与判断请求方式的相同逻辑,判断HTTP版本号m_version = strpbrk(m_url, " \t");if (!m_version)return BAD_REQUEST;*m_version++ = '\0';// 移动到版本的位置进行标记m_version += strspn(m_version, " \t");//仅支持HTTP/1.1if (strcasecmp(m_version, "HTTP/1.1") != 0)return BAD_REQUEST;//对请求资源前7个字符进行判断//这里主要是有些报文的请求资源中会带有http://,这里需要对这种情况进行单独处理if (strncasecmp(m_url, "http://", 7) == 0){m_url += 7;// 记录网站根目录后面的地址,包括/符号m_url = strchr(m_url, '/');}//同样增加https情况if (strncasecmp(m_url, "https://", 8) == 0){m_url += 8;m_url = strchr(m_url, '/');}//一般的不会带有上述两种符号,直接是单独的/或/后面带访问资源if (!m_url || m_url[0] != '/')return BAD_REQUEST;// //当url为/时,显示欢迎界面if (strlen(m_url) == 1)strcat(m_url, "judge.html");//请求行处理完毕,将主状态机转移处理请求头m_check_state = CHECK_STATE_HEADER;return NO_REQUEST;
}// 主状态机,解析http请求的一个头部信息
http_conn::HTTP_CODE http_conn::parse_headers(char *text)
{// 头部信息为空if (text[0] == '\0'){//判断是GET还是POST请求if (m_content_length != 0){//POST需要跳转到消息体处理状态m_check_state = CHECK_STATE_CONTENT;return NO_REQUEST;}// 状态为获取请求return GET_REQUEST;}//解析请求头部连接字段else if (strncasecmp(text, "Connection:", 11) == 0){text += 11;//跳过空格和\t字符text += strspn(text, " \t");// 设置保持活跃标记if (strcasecmp(text, "keep-alive") == 0){//如果是长连接,则将linger标志设置为truem_linger = true;}}//解析请求头部内容长度字段else if (strncasecmp(text, "Content-length:", 15) == 0){text += 15;text += strspn(text, " \t");// 设置内容长度m_content_length = atol(text);}//解析请求头部HOST字段else if (strncasecmp(text, "Host:", 5) == 0){text += 5;text += strspn(text, " \t");// 保存hostm_host = text;}// 意外情况else{LOG_INFO("oop!unknow header: %s", text);}return NO_REQUEST;
}// 主状态机,处理content字段,判断http请求是否被完整读入
http_conn::HTTP_CODE http_conn::parse_content(char *text)
{//判断buffer中是否读取了消息体if (m_read_idx >= (m_content_length + m_checked_idx)){// 标记已读完的部分text[m_content_length] = '\0';// POST请求中最后为输入的用户名和密码m_string = text;// 还需读取请求return GET_REQUEST;}return NO_REQUEST;
}
5. HTTP 请求响应
HTTP 报文响应流程如下:
do_request函数:对解析后的请求进行分析,并对 URL 进行处理,返回请求的状态:- / :GET 请求,跳转 judge.html ,即欢迎页面;
- /0 :POST 请求,跳转 register.html ,即注册页面;
- /1 :POST 请求,跳转 log.html ,即登录页面;
- /2 :POST 请求,进行登录校验,成功跳转 welcome.html ,即资源请求成功页面;失败跳转 logError.html ,即登陆失败页面;
- /3 :POST 请求,进行注册校验,跳转同上;
- /5 :POST 请求,跳转 picture.html ,即图片请求页面;
- /6 :POST 请求,跳转 video.html ,即视频请求页面;
- /7 :POST 请求,跳转 fans.html ,即关注页面;
- 若资源存在且访问正常,就将其映射到内存中准备发送;
add_response函数:构造响应报文的公共接口,被各类消息报头构造函数调用;process_write函数:向m_write_buf中写入响应报文,响应报文分两种:- 一种是文件存在,通过 io 向量机制 iovec 声明 2 个 iovec ,第一个指向
m_write_buf,第二个指向 mmap 的地址m_file_address; - 第二种是请求出错,只申请一个 iovec ;
- 注册 EPOLLOUT 事件,服务器主线程监测到事件后调用
write函数;
- 一种是文件存在,通过 io 向量机制 iovec 声明 2 个 iovec ,第一个指向
write函数:将响应报文发送给浏览器端:- 根据已发送数据大小判断发送是否完成;
- 根据 EAGAIN 判断缓冲区是否已满;
- 每次发送数据后需要更新已发送字数;
- 发送完成后需要重置 HTTP 对象并重置 EPOLLONESHOT 事件。
// 响应http请求,检验、分配、响应请求所需的资源
http_conn::HTTP_CODE http_conn::do_request()
{//将初始化的m_real_file赋值为网站根目录strcpy(m_real_file, doc_root);// 记录文件路径长度int len = strlen(doc_root);// printf("m_url:%s\n", m_url);//找到m_url中/的位置const char *p = strrchr(m_url, '/');// //实现登录和注册校验,cgi=1启用post// *(p+1):0注册POST、1登录POST、2登录校验POST、3注册校验POST、5picture页面POST、6video页面POST、7fans页面POSTif (cgi == 1 && (*(p + 1) == '2' || *(p + 1) == '3')){// 根据标志判断是登录检测还是注册检测,即/符号后的第一位char flag = m_url[1];// 申请url空间char *m_url_real = (char *)malloc(sizeof(char) * 200);// 存入/strcpy(m_url_real, "/");// 存入/后的第二位之后的urlstrcat(m_url_real, m_url + 2);// 文件存储区在文件路径之后存入真实urlstrncpy(m_real_file + len, m_url_real, FILENAME_LEN - len - 1);// 释放真实url存储空间free(m_url_real);// 将用户名和密码提取出来// user=123&passwd=123char name[100], password[100];int i;for (i = 5; m_string[i] != '&'; ++i)name[i - 5] = m_string[i];name[i - 5] = '\0';int j = 0;for (i = i + 10; m_string[i] != '\0'; ++i, ++j)password[j] = m_string[i];password[j] = '\0';// 表示注册if (*(p + 1) == '3'){// 如果是注册,先检测数据库中是否有重名的// 没有重名的,进行增加数据char *sql_insert = (char *)malloc(sizeof(char) * 200);strcpy(sql_insert, "INSERT INTO user(username, passwd) VALUES(");strcat(sql_insert, "'");strcat(sql_insert, name);strcat(sql_insert, "', '");strcat(sql_insert, password);strcat(sql_insert, "')");// 没找到则insert数据if (users.find(name) == users.end()){m_lock.lock();int res = mysql_query(mysql, sql_insert);users.insert(pair<string, string>(name, password));m_lock.unlock();if (!res)strcpy(m_url, "/log.html");elsestrcpy(m_url, "/registerError.html");}elsestrcpy(m_url, "/registerError.html");}// 如果是登录,直接判断// 若浏览器端输入的用户名和密码在表中可以查找到,返回1,否则返回0else if (*(p + 1) == '2'){if (users.find(name) != users.end() && users[name] == password)strcpy(m_url, "/welcome.html");elsestrcpy(m_url, "/logError.html");}}//如果请求资源为/0,表示跳转注册界面if (*(p + 1) == '0'){char *m_url_real = (char *)malloc(sizeof(char) * 200);strcpy(m_url_real, "/register.html");strncpy(m_real_file + len, m_url_real, strlen(m_url_real));free(m_url_real);}//如果请求资源为/1,表示跳转登录界面else if (*(p + 1) == '1'){char *m_url_real = (char *)malloc(sizeof(char) * 200);strcpy(m_url_real, "/log.html");strncpy(m_real_file + len, m_url_real, strlen(m_url_real));free(m_url_real);}// 指向图片页面else if (*(p + 1) == '5'){char *m_url_real = (char *)malloc(sizeof(char) * 200);strcpy(m_url_real, "/picture.html");strncpy(m_real_file + len, m_url_real, strlen(m_url_real));free(m_url_real);}// 指向视频页面else if (*(p + 1) == '6'){char *m_url_real = (char *)malloc(sizeof(char) * 200);strcpy(m_url_real, "/video.html");strncpy(m_real_file + len, m_url_real, strlen(m_url_real));free(m_url_real);}// 指向粉丝页面else if (*(p + 1) == '7'){char *m_url_real = (char *)malloc(sizeof(char) * 200);strcpy(m_url_real, "/fans.html");strncpy(m_real_file + len, m_url_real, strlen(m_url_real));free(m_url_real);}// 指向原始路径elsestrncpy(m_real_file + len, m_url, FILENAME_LEN - len - 1);//通过stat获取请求资源文件信息,成功则将信息更新到m_file_stat结构体//失败返回NO_RESOURCE状态,表示资源不存在if (stat(m_real_file, &m_file_stat) < 0)return NO_RESOURCE;//判断文件的权限,是否可读,不可读则返回FORBIDDEN_REQUEST状态if (!(m_file_stat.st_mode & S_IROTH))return FORBIDDEN_REQUEST;//判断文件类型,如果是目录,则返回BAD_REQUEST,表示请求报文有误if (S_ISDIR(m_file_stat.st_mode))return BAD_REQUEST;//以只读方式获取文件描述符,通过mmap将该文件映射到内存中int fd = open(m_real_file, O_RDONLY);m_file_address = (char *)mmap(0, m_file_stat.st_size, PROT_READ, MAP_PRIVATE, fd, 0);//避免文件描述符的浪费和占用close(fd);//表示请求文件存在,且可以访问return FILE_REQUEST;
}// 构造响应报文的接口
bool http_conn::add_response(const char *format, ...)
{// 如果写入内容超出m_write_buf大小则报错if (m_write_idx >= WRITE_BUFFER_SIZE)return false;// 定义可变参数列表va_list arg_list;// 将变量arg_list初始化为传入参数va_start(arg_list, format);// 将数据format从可变参数列表写入缓冲区写,返回写入数据的长度int len = vsnprintf(m_write_buf + m_write_idx, WRITE_BUFFER_SIZE - 1 - m_write_idx, format, arg_list);// 如果写入的数据长度超过缓冲区剩余空间,则报错if (len >= (WRITE_BUFFER_SIZE - 1 - m_write_idx)){va_end(arg_list);return false;}// 更新m_write_idx位置m_write_idx += len;// 清空可变参列表va_end(arg_list);LOG_INFO("request:%s", m_write_buf);return true;
}// 添加状态行的接口
bool http_conn::add_status_line(int status, const char *title)
{return add_response("%s %d %s\r\n", "HTTP/1.1", status, title);
}// 添加消息报头的接口,具体的添加文本长度、连接状态和空行
bool http_conn::add_headers(int content_len)
{return add_content_length(content_len) && add_linger() &&add_blank_line();
}// 添加Content-Length的接口,表示响应报文的长度
bool http_conn::add_content_length(int content_len)
{return add_response("Content-Length:%d\r\n", content_len);
}// 添加文本类型的接口,这里是html
bool http_conn::add_content_type()
{return add_response("Content-Type:%s\r\n", "text/html");
}// 添加连接状态的接口,通知浏览器端是保持连接还是关闭
bool http_conn::add_linger()
{return add_response("Connection:%s\r\n", (m_linger == true) ? "keep-alive" : "close");
}// 添加空行的接口
bool http_conn::add_blank_line()
{return add_response("%s", "\r\n");
}// 添加文本content的接口
bool http_conn::add_content(const char *content)
{return add_response("%s", content);
}// 构造响应报文,处理好各缓存区的指针,为发送数据做准备
bool http_conn::process_write(HTTP_CODE ret)
{// 根据HTTP状态码构造响应头switch (ret){// 内部错误,500case INTERNAL_ERROR:{// 状态行add_status_line(500, error_500_title);// 消息报头add_headers(strlen(error_500_form));if (!add_content(error_500_form))return false;break;}// 报文语法有误,404case BAD_REQUEST:{add_status_line(404, error_404_title);add_headers(strlen(error_404_form));if (!add_content(error_404_form))return false;break;}// 资源没有访问权限,403case FORBIDDEN_REQUEST:{add_status_line(403, error_403_title);add_headers(strlen(error_403_form));if (!add_content(error_403_form))return false;break;}// 文件存在,200case FILE_REQUEST:{add_status_line(200, ok_200_title);// 如果请求的资源存在if (m_file_stat.st_size != 0){// 初始化各种指针add_headers(m_file_stat.st_size);// 第一个iovec指针指向响应报文缓冲区,长度指向m_write_idxm_iv[0].iov_base = m_write_buf;m_iv[0].iov_len = m_write_idx;// 第二个iovec指针指向mmap返回的文件指针,长度指向文件大小m_iv[1].iov_base = m_file_address;m_iv[1].iov_len = m_file_stat.st_size;m_iv_count = 2;// 发送的全部数据为响应报文头部信息和文件大小bytes_to_send = m_write_idx + m_file_stat.st_size;return true;}else{// 如果请求的资源大小为0,则返回空白html文件const char *ok_string = "<html><body></body></html>";add_headers(strlen(ok_string));if (!add_content(ok_string))return false;}}default:return false;}// 除FILE_REQUEST状态外,其余状态只申请一个iovec,指向响应报文缓冲区m_iv[0].iov_base = m_write_buf;m_iv[0].iov_len = m_write_idx;m_iv_count = 1;bytes_to_send = m_write_idx;return true;
}// 发送数据,即写入文件描述符
bool http_conn::write()
{int temp = 0;// 若要发送的数据长度为0// 表示响应报文为空,一般不会出现这种情况if (bytes_to_send == 0){// 将事件重置为EPOLLONESHOTmodfd(m_epollfd, m_sockfd, EPOLLIN, m_TRIGMode);// 初始化init();return true;}// 循环处理while (1){// 将响应报文的状态行、消息头、空行和响应正文发送给浏览器端temp = writev(m_sockfd, m_iv, m_iv_count);if (temp < 0){if (errno == EAGAIN){// 重新注册写事件modfd(m_epollfd, m_sockfd, EPOLLOUT, m_TRIGMode);return true;}unmap();return false;}// 正常发送,temp为发送的字节数bytes_have_send += temp;// 更新已发送字节数bytes_to_send -= temp;// 第一个iovec头部信息的数据已发送完,发送第二个iovec数据if (bytes_have_send >= m_iv[0].iov_len){// 不再继续发送头部信息m_iv[0].iov_len = 0;m_iv[1].iov_base = m_file_address + (bytes_have_send - m_write_idx);m_iv[1].iov_len = bytes_to_send;}// 继续发送第一个iovec头部信息的数据else{m_iv[0].iov_base = m_write_buf + bytes_have_send;m_iv[0].iov_len = m_iv[0].iov_len - bytes_have_send;}// 判断条件,数据已全部发送完if (bytes_to_send <= 0){// 释放内存unmap();// 在epoll树上重置EPOLLONESHOT事件modfd(m_epollfd, m_sockfd, EPOLLIN, m_TRIGMode);// 浏览器的请求为长连接if (m_linger){// 重新初始化HTTP对象init();return true;}// 不保持else{return false;}}}
}
参考文献
[1] 最新版Web服务器项目详解 - 04 http连接处理(上)
[2] 最新版Web服务器项目详解 - 05 http连接处理(中)
[3] 最新版Web服务器项目详解 - 06 http连接处理(下)
相关文章:
tinyWebServer 学习笔记——二、HTTP 连接处理
文章目录 一、基础知识1. epoll2. 再谈 I/O 复用3. 触发模式和 EPOLLONESHOT4. HTTP 报文5. HTTP 状态码6. 有限状态机7. 主从状态机8. HTTP_CODE9. HTTP 处理流程 二、代码解析1. HTTP 类2. 读取客户数据2. epoll 事件相关3. 接收 HTTP 请求4. HTTP 报文解析5. HTTP 请求响应 …...

深入浅析Linux Perf 性能分析工具及火焰图
Perf Event 子系统 Perf 是内置于 Linux 内核源码树中的性能剖析(profiling)工具。它基于事件采样的原理,以性能事件为基础,支持针对处理器相关性能指标与操作系统相关性能指标的性能剖析。可用于性能瓶颈的查找与热点代码的定位…...

java关键术语
java具有11个关键的术语,这些术语是从java的设计者所编写的白皮书中摘取,这些术语分别为:简单性、面向对象、分布式、健壮性、安全性、体系结构中立、可移植性、解释型、高性能、多线程、多态性。以下开始我们将逐一解说这些术语。 一、简单性 Java是C++语法的纯净版本,剔…...

1. 两数之和【简单】
题目 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。 你可以按任意顺…...

《编码——隐匿在计算机软硬件背后的语言》精炼——第17章(自动操作)
夫道成于学而藏于书,学进于振而废于穷。 文章目录 完善加法器加入代码的加法器扩大加数范围自由调用地址的加法器合并代码RAM和数据RAMJump指令硬件实现条件Jump指令零转移的硬件实现条件Jump指令的例子 总结 完善加法器 我们在第14章介绍了一个可以进行连加的加法…...

用Colab免费部署AI绘画云平台Stable Diffusion webUI
Google Colab 版的 Stable Diffusion WebUI 1.4 webui github 地址:https://github.com/sd-webui/stable-diffusion-webui 平台搭建 今天就来交大家如果来搭建和使用这个云平台。 第一步: 打开链接 https://colab.research.google.com/github/altryne/sd-webu…...

R.I.P,又一位程序员巨佬——左耳朵耗子陨落
震惊!谣言吧!求辟谣!默哀! 左耳朵耗子,在程序员这个群体里应该属于 GOAT 的存在了,虽然每个人心目中都有自己的 GOAT,但耗子叔的影响力可以说是有目共睹。 我也是在技术群刷到这张图片的&#…...

捷威信keithley吉时利2410数字源表 销售回收KEITHLEY2470新款源表
吉时利Keithley 2410 /2470高压源表/数字源表 产品概览 Keithley 2410 高压源表专为需要紧密耦合源和测量的测试应用而设计。Keithly 2410 提供精密电压和电流源以及测量功能。它既是高度稳定的直流电源,又是真正的仪器级 5-1/2 数字万用表。电源特性包括低噪声、…...

第二十九回:如何给ListView添加分隔线
文章目录 概念介绍添加方法使用属性装饰器 示例代码经验总结: 我们在上一章回中介绍了多种创建ListView的方式,本章回中将介绍" 如何给ListView添加分隔线".闲话休提,让我们一起Talk Flutter吧。 概念介绍 我们在这里说的分隔线也叫Divider,…...

用友 LRP计划维护视图
select planlotnumber 计划单号, demandId 自动编号, PartId 物料Id , sotype 单据类型(1:销售/2:预测), sodid 销售订单明细Id , socode 销售订单单号 , soseq 销售订单行号, PlanCode 计划单号 , DueDate 完工日期 , StartDate 开工日期 , UnitCode 主计量单位, C…...

数组--part 5--螺旋矩阵(力扣59/54)(剑指offer 29)
文章目录 基本算法思想leetcode 59 螺旋矩阵 IIleetcode 54 螺旋矩阵剑指Offer 29 顺时针打印矩阵 基本算法思想 建议先去把题目看了,再来思考相关的代码。 错误的想法:实际上这种题型并不存在算法,只涉及到模拟,但是模拟难度并…...
加密解密软件VMProtect入门使用教程(九)许可制度之许可系统功能
VMProtect是新一代软件保护实用程序。VMProtect支持德尔菲、Borland C Builder、Visual C/C、Visual Basic(本机)、Virtual Pascal和XCode编译器。 同时,VMProtect有一个内置的反汇编程序,可以与Windows和Mac OS X可执行文件一起…...

MySQL基础-事务详解
本文主要介绍MySQL事务 文章目录 前言事务定义事务四大特性(ACID) 事务操作事务并发问题事务隔离级别 前言 参考链接: 链接1链接2 事务定义 事务是一组操作的集合,他是一个不可分割的工作单位,事务会把所有的操作作…...

python 读写csv文件方法
csv是一种结构化文件,可以将文本转化成矩阵的形式,方便程序读取和处理。下面来介绍一下使用 python读写 csv文件的方法: 1.首先需要使用 pip安装 python包,然后将 csv文件解压到一个文件夹下 2.使用 pip安装 python包,…...

命令行更新Windows
命令行更新Windows powershell命令行更新安装 Windows Update module for Windows Powershell连接到 Windows Update 服务器并下载更新安装下载好的 Windows Update 更新 cmd执行Windows update更新检查更新下载 Windows Update 更新安装更新安装更新后重新启动设备 win10以下版…...

lwIP 多线程注意事项
关于 lwIP 多线程的总结: lwIP 内核不是线程安全的。如果在多线程环境中使用 lwIP,必须使用高层次的 Sequential 或 socket API。使用 raw API 时,需要自己保护好应用程序和协议栈核心代码。在无操作系统环境中使用 raw API: 使用…...
【工业革命的诞生是能量富余的结果】)
工业革命的本质是动力革命:人类使用能量的水平得到了飞跃(蒸汽动力取代畜力和水力,机械代替人工。)【工业革命的诞生是能量富余的结果】
文章目录 引言I 用能量守恒方式看工业革命的影响1.1 中学物理能量守恒1.2 看清历史事件的影响1.3 工业革命的意义1.4 透过现象看本质的方法II 工业革命的本质2.1 动力革命2.2 多余的能量造就了工业革命引言 人类文明进步的目的是改善人们的生活,任何文明都以养活更多的人口为…...

【Kubernetes】Windows安装kubectl
准备开始 kubectl版本和集群版本之间的差异必须在一个小版本号内。 例如:v1.27版本的客户端能与 v1.26、 v1.27 和 v1.28 版本的控制面通信。 用最新兼容版的 kubectl 有助于避免不可预见的问题。 下载 官方安装文档: https://kubernetes.io/zh/docs/tasks/tools…...

菜鸟健身-新手使用哑铃锻炼手臂的动作与注意事项
目录 一、前言 二、哑铃锻炼手臂的好处 三、哑铃锻炼手臂的注意事项 四、哑铃锻炼手臂的基本动作 1. 哑铃弯举 2. 哑铃推举 3. 哑铃飞鸟 五、哑铃锻炼手臂的进阶动作 1. 哑铃侧平举 2. 哑铃俯身划船 六、哑铃锻炼手臂的训练计划 七、总结 一、前言 哑铃是一种非常…...

二、LLC 谐振变换器
半桥 LLC 谐振变换器主电路结构 如图所示,半桥 LLC 谐振变换器主电路可以分为四个部分,即:逆变网络、谐振网络、变压器及整流滤波网络。两个 MOSFET(S1、S2)以及它们的体二极管(D1、D2)和寄生电…...

YOLOv8融合VMamba:目标检测性能跃升实战解析
1. 环境配置与依赖安装 在开始YOLOv8与VMamba的融合实验之前,我们需要先搭建好开发环境。这里我推荐使用Ubuntu 22.04系统配合Anaconda进行环境管理,实测下来这个组合最稳定。如果你用的是Windows系统,建议通过WSL2来运行Ubuntu环境ÿ…...

intv_ai_mk11开源可部署实践:在企业内网GPU服务器部署合规可控的AI对话服务
intv_ai_mk11开源可部署实践:在企业内网GPU服务器部署合规可控的AI对话服务 1. 项目概述 intv_ai_mk11是一款基于Llama架构的开源AI对话模型,专为企业内网环境设计。该模型具有7B参数规模,能够在GPU服务器上高效运行,为企业提供…...

法律大模型落地难?SITS2026用4类判决文书微调+2层事实校验机制,准确率跃升至92.7%,详解架构设计与审计留痕
第一章:SITS2026案例:AIAgent法律助手开发 2026奇点智能技术大会(https://ml-summit.org) SITS2026(Smart Intelligence Technology Summit 2026)中,AIAgent法律助手作为核心开源项目亮相,聚焦于中国司法…...

即时通讯平台开发:iOS工程师的视角
引言 即时通讯(IM)平台在现代企业中扮演着核心角色,支撑着团队协作、客户服务和业务运营。作为iOS开发工程师,我们不仅需要精通移动端技术,还需兼顾PC端开发,尤其在跨平台框架如Electron的应用中。本文将从技术角度深入探讨IM平台的功能开发、架构优化、性能调优及新技术…...

地缓存与 Redis 的数据一致性方案
本地缓存(如 Caffeine、Guava)与 Redis 组成的双层缓存架构,在提升性能的同时也带来了数据一致性的经典难题。由于本地缓存是进程内存储,当数据在 Redis 或数据库中更新时,如何同步更新所有应用实例的本地缓存,成为分布式系统中的核心挑战。 一、问题本质:为什么会出现不…...

艾尔登法环存档迁移终极指南:告别存档丢失的完整解决方案
艾尔登法环存档迁移终极指南:告别存档丢失的完整解决方案 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 在交界地的冒险中,最令人绝望的莫过于数百小时的游戏进度因存档损坏而瞬间消失…...

LRCGet:从离线音乐库到歌词生态系统的技术探索
LRCGet:从离线音乐库到歌词生态系统的技术探索 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 当你的音乐收藏从流媒体服务迁移到本地硬盘&…...

乙巳马年春联生成终端参数详解:PALM模型temperature与top_k设置
乙巳马年春联生成终端参数详解:PALM模型temperature与top_k设置 1. 引言:从“开门见喜”到“妙笔生花” 想象一下这个场景:你站在一扇威严的朱红大门前,门上整齐排列着金色的门钉,两位古老的门神在两侧守护。你只需在…...

新手友好:MedGemma 1.5从安装到问诊,完整流程一次跑通
新手友好:MedGemma 1.5从安装到问诊,完整流程一次跑通 1. 为什么需要本地医疗AI助手 在当今医疗信息爆炸的时代,我们经常需要查询各种健康问题和医疗知识。然而,传统的在线医疗咨询存在两个主要痛点:一是隐私安全问题…...
)
铁路沿线障碍物识别数据集 铁路输电线路异物识别数据集 电线杆鸟巢识别 输电线路塑料袋检测 铁路线路气球漂浮物识别 第10217期 (1)
铁路障碍物数据集简介 p图类别Classes (4) niaochao piaofuwu qiqiu suliaodai铁路障碍物 数据集核心信息表信息类别具体内容数据集类别计算机视觉领域 - 目标检测数据集数据数量包含 2541 张图像,对应 1 个数据集数据集格式种类以图像文件形式呈现,配套…...