必须了解的内存屏障
目录
- 一,内存屏障
- 1,概念
- 2,内存屏障的效果
- 3,cpu中的内存屏障
- 二,JVM中提供的四类内存屏障指令
- 三,volatile 特性
- 1,保证内存可见性定义
- 2,禁止指令重排序
- 3,不保证原子性
一,内存屏障
1,概念
内存屏障是硬件之上、操作系统或JVM之下,对并发作出的最后一层支持。再向下是是硬件提供的支持;向上是操作系统或JVM对内存屏障作出的各种封装。内存屏障是一种标准,各厂商可能采用不同的实现
2,内存屏障的效果
即使指令的执行没有重排序,是按顺序执行的,但由于缓存的存在,仍然会出现数据的非一致性的情况。我们把这种普通读``普通写可以理解为是有延迟的延迟读、延迟写,因此即使读在前、写在后,因为有延迟,然后仍然会出现写在前、读在后的情况。
为了解决上述重排带来的问题,提出了as-if-serial原则,即不管怎么重排序,程序执行的结果在单线程里保持不变。为了遵守as-if-serial原则,我们需要一种特殊的指令来阻止特定的重排,使其保持结果一致,这种指令就是内存屏障。
内存屏障有两个效果:
- 阻止指令重排序:在插入内存屏障指令后,不管前面与后面任何指令,都不能与内存屏障指令进行重排,保证前后的指令按顺序执行,即保证了顺序性。
- 全局可见:插入的内存屏障,保证了其对内存操作的读写结果会立即写入内存,并对其他CPU核可见,即保证了可见性,解决了普通读写的延迟问题。例如,插入读屏障后,能够删除缓存,后续的读能够立刻读到内存中最新数据(至少当时看起来是最新)。插入写屏障后,能够立刻将缓存中的数据刷新入内存中,使其对其他CPU核可见。
3,cpu中的内存屏障
lfence:读屏障(load fence),即立刻让CPU Cache失效,从内存中读取数据,并装载入Cache中。
sfence: 写屏障(write fence), 即立刻进行flush,把缓存中的数据刷入内存中。
mfence: 全屏障 (memory fence),即读写屏障,保证读写都串行化,确保数据都写入内存并清除缓存。
二,JVM中提供的四类内存屏障指令
loadload:
读读,该屏障用来禁止处理器把上面的volatile读与下面的普通读重排序
storestore:
写写,该屏障可以保证在volatile写之前,其前面的所有普通写操作都已经刷新到主内存中
loadstore:
读写,该屏障用来禁止处理器把上面的volatile读与下面的普通写重排序
storeload:
写读,该屏障的作用是避免volatile与后面可能有的volatile读/写操作重排序
三,volatile 特性
1,保证内存可见性定义
(1)定义:
可见性的定义常见于各种并发场景中,以多线程为例:当一个线程修改了线程共享变量的值,其它线程能够立即得知这个修改。
从性能角度考虑,没有必要在修改后就立即同步修改的值——如果多次修改后才使用,那么只需要最后一次同步即可,在这之前的同步都是性能浪费。因此,实际的可见性定义要弱一些,只需要保证:当一个线程修改了线程共享变量的值,其它线程在使用前,能够得到最新的修改值。
(2)如何保证可见性
Java内存模型中定义的8种工作内存与主内存之间的原子操作

- read: 作用于主内存,将变量的值从主内存传输到工作内存,主内存到工作内存
- load: 作用于工作内存,将read从主内存传输的变量值放入工作内存变量副本中,即数据加载
- use: 作用于工作内存,将工作内存变量副本的值传递给执行引擎,每当JVM遇到需要该变量的字节码指令时会执行该操作
- assign: 作用于工作内存,将从执行引擎接收到的值赋值给工作内存变量,每当JVM遇到一个给变量赋值字节码指令时会执行该操作
- store: 作用于工作内存,将赋值完毕的工作变量的值写回给主内存
- write: 作用于主内存,将store传输过来的变量值赋值给主内存中的变量
由于上述只能保证单条指令的原子性,针对多条指令的组合性原子保证,没有大面积加锁,所以,JVM提供了另外两个原子指令: - lock: 作用于主内存,将一个变量标记为一个线程独占的状态,只是写时候加锁,就只是锁了写变量的过程。
- unlock: 作用于主内存,把一个处于锁定状态的变量释放,然后才能被其他线程占用
2,禁止指令重排序
(1)定义
重排序并没有严格的定义。整体上可以分为两种:
真·重排序:编译器、底层硬件(CPU等)出于“优化”的目的,按照某种规则将指令重新排序(尽管有时候看起来像乱序)。
伪·重排序:由于缓存同步顺序等问题,看起来指令被重排序了。
(2)问题来源
重排序问题无时无刻不在发生,源自三种场景:
- 编译器编译时的优化
- 处理器执行时的乱序优化
- 缓存同步顺序(导致可见性问题)
场景1、2属于真·重排序;场景3属于伪·重排序。场景3也属于可见性问题
(3)怎么禁止指令重排序
volatile有关禁止指令重排的行为
当第一个操作是 volatile 读时,不论第二个操作是什么,都不能重排序;这个操作保证了volatile读之后的操作不会被重排到volatile读之前
当第二个操作为 volatile 写时,不论第一个操作是什么,都不能重排序;这个操作保证了volatile写之前的操作不会被重排到volatile写之后
当第一个操作为 volatile 写时,第二个操作为 volatile 读时,不能重排序
3,不保证原子性
volatile变量的复合操作(如i++)是不具有原子性的,原因是 i++ 操作从字节码角度来看,是分为三步的
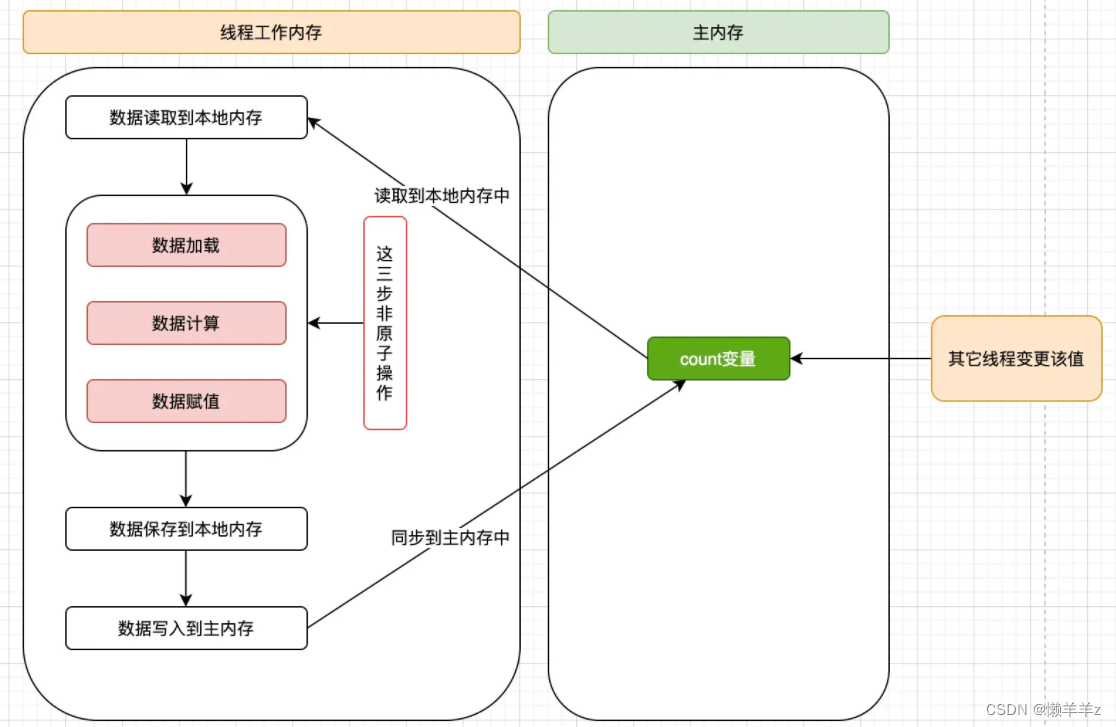
多线程环境下,数据计算和数据赋值操作可能多次出现,即操作非原子。若数据再加载之后,若主内存中 count变量发生修改之后,由于线程工作内存中的值在此之前已经加载,从而不会对变更操作做出相应变化,即私有内存和公共内存中变量不同步,进而导致数据不一致
对于volatile变量,JVM只是保证从主内存加载到线程工作内存的值是最新的,也就是数据加载时是最新的。
相关文章:
必须了解的内存屏障
目录 一,内存屏障1,概念2,内存屏障的效果3,cpu中的内存屏障 二,JVM中提供的四类内存屏障指令三,volatile 特性1,保证内存可见性定义2,禁止指令重排序3,不保证原子性 一&a…...
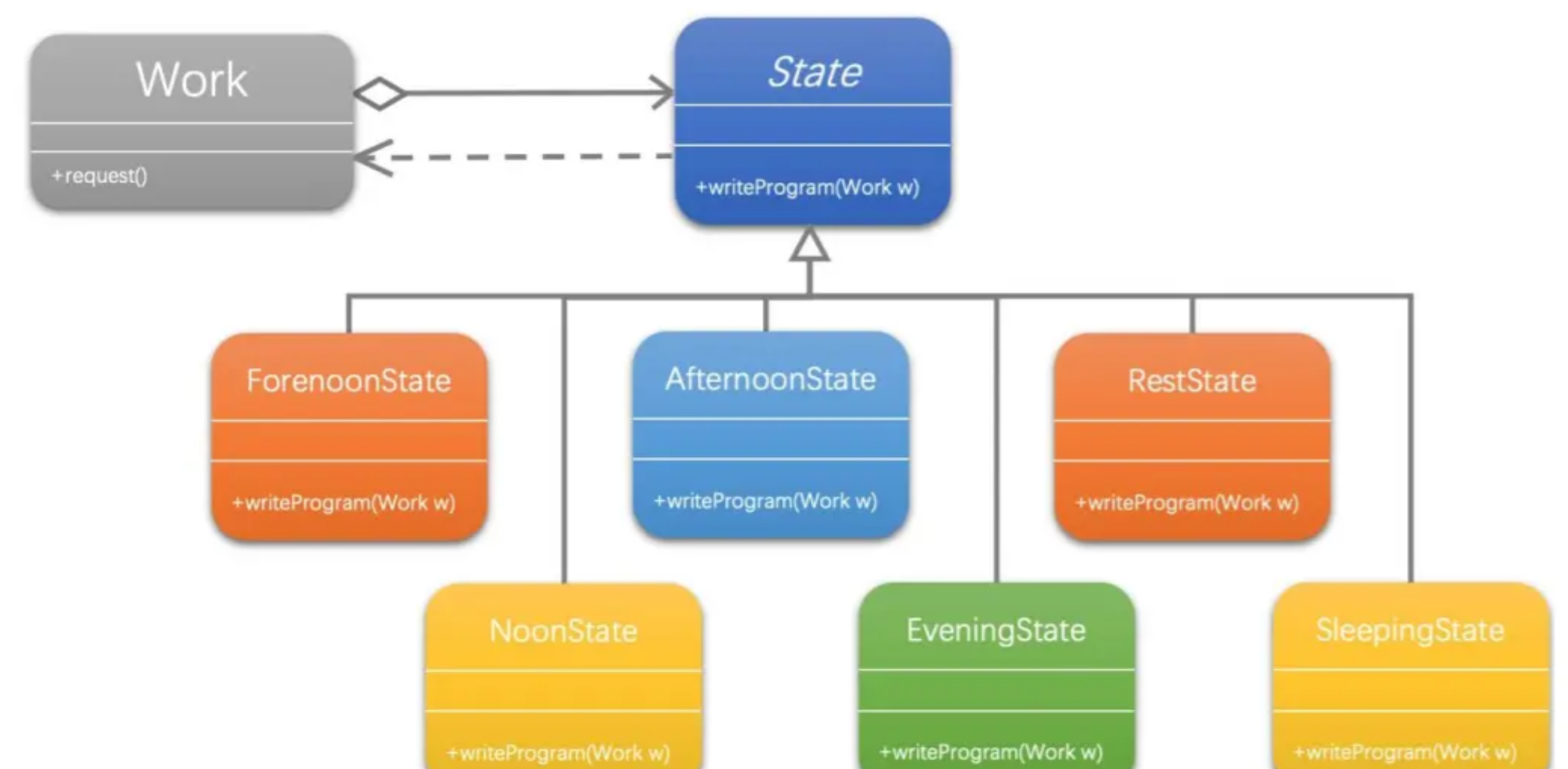
【设计模式】状态模式
文章目录 前言状态模式1、状态模式介绍1.1 存在问题1.2 解决问题1.3 状态模式结构图 2、具体案例说明状态模式2.1 不使用状态模式2.2 使用状态模式 3、状态模式总结 前言 状态模式主要解决的是当控制一个对象状态转换的条件表达式过于复杂时的情况。把状态的判断逻辑转移到表示…...

内核驱动支持浮点数运算
最近在调 iio 下的 ICM42686 驱动,因项目求需要在驱动对加速度和陀螺raw数据进行换算,避免不了浮点运算。内核编译时出现了报错,提示如下: drivers/iio/imu/tdk_icm42686/icm42686.o: In function gyro_data2float: /home/share/…...
)
Flink学习(一)
分布式计算框架 Java可以使用分布式计算来处理大规模的数据和计算任务,提高计算效率和性能。以下是一些Java分布式计算的例子: Apache Hadoop:Hadoop是一个开源的分布式计算框架,可以处理大规模数据集的分布式存储和处理。它使用Java编写,可以在分布式环境中运行MapReduc…...
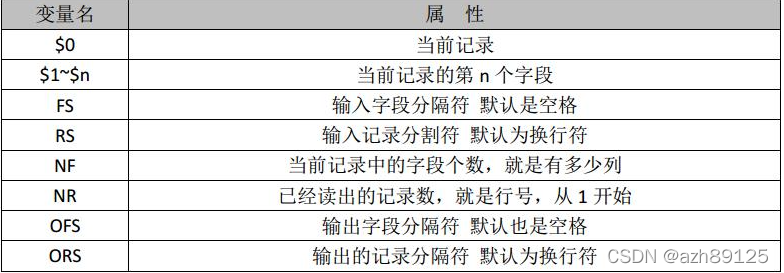
linux 常用命令awk
AWK 是一种处理文本文件的语言,是一个强大的文本分析工具。之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。 AWK用法 awk 用法:awk pattern {action} files 1.RS, ORS, F…...

MySQL学习---15、流程控制、游标
1、流程控制 解决复杂问题不可能是通过一个SQL语句完成,我们需要执行多个SQL操作。流程控制语句的作用就是控制存储过程中SQL语句的执行顺序,是我们完成复杂操作必不可少的一部分。只要是执行的程序,流程就分为三大类: 1、顺序结…...

信息调查的观念
每次做一件事前都要把这件事调查清楚,比如考一门科目我们要把和这门科目有关的资源都收集起来,然后把再从中筛选出有用的信息,如数值计算方法我们在考试前就可以把b站有关的学习资源网课或者前人总结的考试经验做个收集总结,做出对…...

leetcode 337. 打家劫舍 III
题目链接:leetcode 337 1.题目 小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为 root 。 除了 root 之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的…...

基于Docker的深度学习环境NVIDIA和CUDA部署以及WSL和linux镜像问题
基于Docker的深度学习环境部署 1. 什么是Docker?2. 深度学习环境的基本要求3. Docker的基本操作3.1 在Windows上安装Docker3.2 在Ubuntu上安装Docker3.3 拉取一个pytorch的镜像3.4 部署自己的项目3.5 导出配置好项目的新镜像 4. 分享新镜像4.1 将镜像导出为tar分享给…...

c#中slice,substr,substring区别
1. 都使用一个参数: //栗子数据 var arr [1,2,3,4,5,6,7], str "helloworld!"; //防止空格干扰,不用带空格的,注意这里有个!号也算一位 console.log(str.slice(1)); //elloworld! console.log(str.substring(1)); //…...

java语言里redis在项目中使用场景,每个场景的样例代码
Redis是一款高性能的NoSQL数据库,常被用于缓存、消息队列、计数器、分布式锁等场景。以下是50个Redis在项目中使用的场景以及对应的样例代码和详细说明: ##1、缓存:将查询结果缓存在Redis中,下次查询时直接从缓存中获取ÿ…...

Mongo集合操作
2、创建切换数据库 2.1 默认数据库 mongo数据库和其他类型的数据库一样,可以创建数据库,且可以创建多个数据库。 mongo数据库默认会有四个数据库,分别是 admin:主要存储MongoDB的用户、角色等信息 config:主要存储…...

ConvTranspose2d 的简单例子理解
文章目录 参考基础概念output_padding 简单例子: stride2step1step2step3 参考 逆卷积的详细解释ConvTranspose2d(fractionally-strided convolutions)nn.ConvTranspose2d的参数output_padding的作用torch.nn.ConvTranspose2d Explained 基础概念 逆卷…...

酒精和肠内外健康:有帮助还是有害?
谷禾健康 酒精与健康 饮酒作为一种特殊的文化形式,在我们国家有其独特的地位,在几千年的发展中,酒几乎渗透到日常生活、社会经济、文化活动之中。 据2018年发表的《中国饮酒人群适量饮酒状况》白皮书数据显示,中国饮酒人群高达6亿…...

SylixOS Shell下操作环境变量方法
系统启动后会在内核中生成一份默认的环境变量,环境变量名和默认值由源程序决定。系统启动后如果文件系统中存在有效的/etc/profile文件,则还会自动读取文件中的内容,并导入到Shell环境中,覆盖对应变量或增加新的变量。程序运行时&…...
【dfs解决分组问题-两道例题——供佬学会!】(A元素是放在已经存在的组别中,还是再创建一个更好?--小孩子才做选择,dfs直接两种情况都试试)
问题关键就是: 一个点,可能 新开一个组 比 放到已经存在的组 更划算 因为后面的数据,我们遍历之前的点时,并不知道 所以我们应该针对每个点,都应该做出一个选择就是 新开一个元组或者放到之前的元组中,都尝…...
使用Hexo在Github上搭建个人博客
使用Hexo在Github上搭建个人博客 1. 安装Node和git2. 安装Hexo3. Git与Github的准备工作4. 将Hexo部署到Github5. 开始写作 1. 安装Node和git 在Mac上安装Node.js可以使用Homebrew,使用以下命令安装: brew install node使用以下命令安装Git: …...

【面试题】面试官:说说你对 CSS 盒模型的理解
前言 CSS 盒模型是 CSS 基础的重点难点,因此常被面试官们拿来考察候选人对前端基础的掌握程度,这篇文章将对 CSS 盒模型知识点进行全面的梳理。 我们先看个例子:下面的 div 元素的总宽度是多少呢? js <!DOCTYPE html> &…...

【ROS2】学习笔记
1. 基础概念 1.1 执行单元 1.1.1 executable——执行程序 executable表示针对某个目标的程序执行流程,一个executable可以启动多个node; 1.1.2 node——“进程” node其实就是进程的意思; ROS2允许同时启动两个相同的node,&a…...
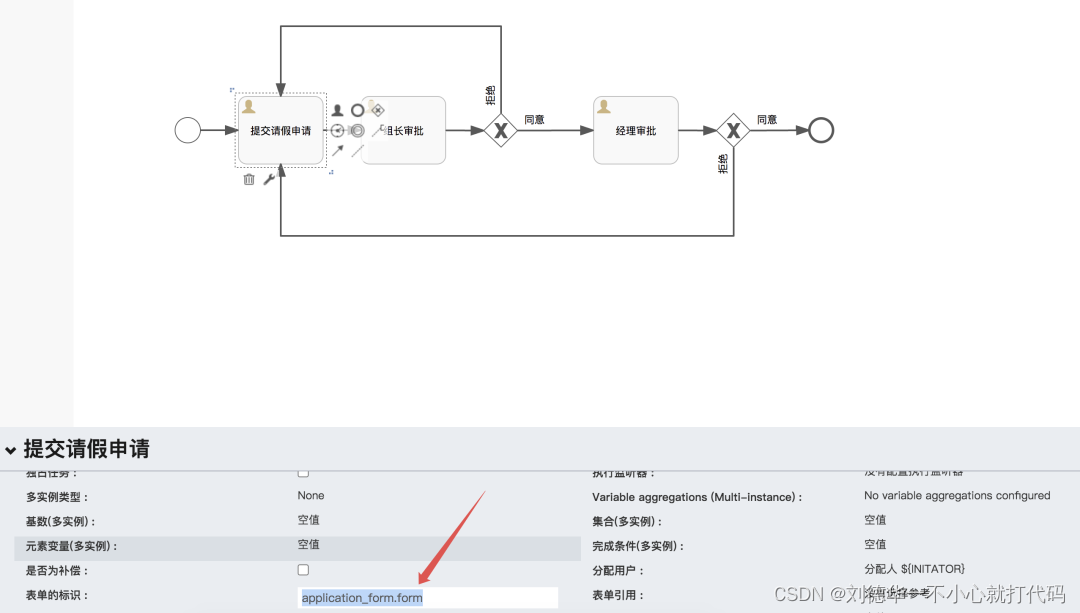
Springboot +Flowable,流程表单应用之外置表单(JSON形式)(二)
一.简介 整体上来说,我们可以将Flowable 的表单分为三种不同的类型: 动态表单 这种表单定义方式我们可以配置表单中每一个字段的可读性、可写性、是否必填等信息,不过不能定义完整的表单页面。外置表单 外置表单我们只需要定义一下表单的 k…...

告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点
告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点每次在终端敲入docker ps、docker stop、docker rm时,你是否想过——当容器数量超过两位数,这种重复劳动是否在消耗你的生命?去年我们团队在迁移微服务架…...

③ AI副业第一步:如何找到适合自己的AI赚钱赛道
③ AI副业第一步:如何找到适合自己的AI赚钱赛道选对赛道,努力才有意义。选错赛道,越努力离钱越远。前言:为什么大多数人AI副业做不起来? 我观察了100想做AI副业的人,失败的原因高度一致: 失败路…...

别再手动改路径了!用LabVIEW + MATLAB Script做自动化测试,这份环境配置指南让你效率翻倍
LabVIEW与MATLAB深度整合:构建自动化测试系统的工程实践指南在工业自动化与测试测量领域,LabVIEW和MATLAB的组合堪称黄金搭档。LabVIEW擅长硬件接口和实时控制,而MATLAB在算法开发和数据分析方面具有无可比拟的优势。本文将深入探讨如何将两者…...

51单片机驱动ST7735S彩屏避坑指南:从5秒刷屏到流畅贪吃蛇的优化实战
51单片机驱动ST7735S彩屏性能优化实战:从卡顿到流畅游戏的蜕变之路当一块128x160分辨率的ST7735S彩屏遇上传统的51单片机,这种组合看似矛盾却又充满挑战。许多开发者初次尝试时会发现,原本在STM32等平台上运行流畅的显示驱动,移植…...

SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能
SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...
)
Postgresql基础实践教程(九)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 七十二、WITH查询(公用表表达式CTE) 1. SELECT 中的 WITH 2. 递归查询 3. 公用表表达式的物化 4. WITH中的数据修改语句 WITH提供了一种在主查询中写辅助语句的方法。这些语…...

2026 文章代码高亮方案选型
将基于 Prism.js 或 Highlight.js 的传统高亮方案与基于 Shiki 的现代化高亮方案进行对比,其核心区别在于底层解析原理的不同(正则表达式 vs. TextMate 语法树)。 以下是两种方案的底层原理、各自优缺点、核心对比矩阵以及适用场景的详细分析…...

交流电机驱动器的三种控制模式:前沿切相、后沿切相与同步模式详解
1. 项目概述:一个能玩出花的交流电机驱动器在汽车改装、工业控制或者一些创客项目里,驱动一个交流电机听起来简单,但想让它听话地变速、正反转,甚至实现软启动和精确同步,往往就得搬出笨重又昂贵的工业变频器。今天分享…...
)
为什么你的DeepSeek微调loss震荡不止?(Meta/DeepSeek联合团队未公开的梯度裁剪+LoRA初始化双校准协议)
更多请点击: https://codechina.net 第一章:DeepSeek微调loss震荡的根本归因剖析 DeepSeek系列模型在微调过程中频繁出现loss剧烈震荡现象,其本质并非单一因素所致,而是数据、优化器、梯度动态与模型结构四者耦合失稳的系统性表现…...

别再死记硬背了!用UE材质里的点积、叉积,5分钟搞定模型表面动态光效
用UE材质玩转动态光效:点积、叉积实战指南第一次接触UE材质编辑器时,看到那些密密麻麻的数学节点总让人头皮发麻。特别是"点积"、"叉积"这些听起来就很高深的术语,很容易让美术背景的创作者望而却步。但你知道吗…...