Redis缓存数据库(四)
目录
一、概述
1、Redis Sentinel
1.1、docker配置Redis Sentinel环境
2、Redis存储方案
2.1、哈希链
2.2、哈希环
3、Redis分区(Partitioning)
4、Redis面试题
一、概述
1、Redis Sentinel
Redis Sentinel为Redis提供了高可用解决方案。实际上这意味着使用Sentinel可以部署一套Redis,在没有人为干预的情况下去应付各种各样的失败事件。
Redis Sentinel同时提供了一些其他的功能,例如:监控、通知、并为client提供配置。
下面是Sentinel的功能列表:
- 监控(Monitoring):Sentinel不断的去检查你的主从实例是否按照预期在工作。
- 通知(Notification):Sentinel可以通过一个api来通知系统管理员或者另外的应用程序,被监控的Redis实例有一些问题。
- 自动故障转移(Automatic failover):如果一个主节点没有按照预期工作,Sentinel会开始故障转移过程,把一个从节点提升为主节点,并重新配置其他的从节点使用新的主节点,使用Redis服务的应用程序在连接的时候也被通知新的地址。
- 配置提供者(Configuration provider):Sentinel给客户端的服务发现提供来源:对于一个给定的服务,客户端连接到Sentinels来寻找当前主节点的地址。当故障转移发生的时候,Sentinels将报告新的地址。
1.1、docker配置Redis Sentinel环境
后续补充...
2、Redis存储方案
2.1、哈希链
原文链接:https://blog.csdn.net/Brave_heart4pzj/article/details/126448985
哈希链
原理简介:每个数据存储进来的时候,要根据hash算法,进行算值取余,存入到对应的机器中。取数据的时候,用同样的hash算法对key进行计算,即可取出数据。
应用场景:
Redis集群扩容或宕机缩减,那么就需要进行全库数据的重洗,hash取模的值调整。这样,就比较耗费时间。所以,该方案,要预先估计一下自己公司业务的数据量多大,服务器的存储能力多大,然后,考虑在扩容时,所需的时间多久,只要在允许的时间范围内,能够完成重洗数据,那就可以采取该方案。该方案的一个好处就是,简单。存数据简单,取数据简单,理解容易。
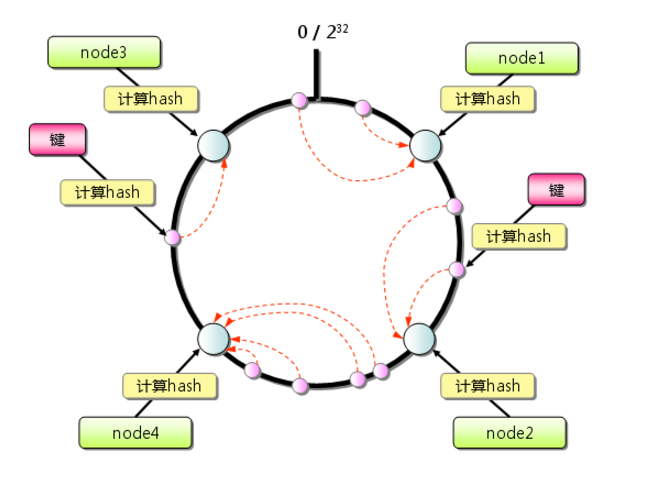
哈希环上面说的Hash链,只经过了1次hash,即把key hash到对应的机器编号。
而Hash环有2次Hash:
(1)把所有机器编号hash到这个环上
(2)把key也hash到这个环上。然后在这个环上进行匹配,看这个key和哪台机器匹配。这样,每个机器负责对应段上的数据。
应用场景
当hash链性能满足不了公司业务数据量的时候,就要采取该方案进行性能提升。
当服务器缩减时,对应段数据向下游转移即可,这样,就不会影响到其他段服务器的数据。
当服务器扩容时,对应服务器下游的服务器数据要进行重洗,把部分数据转移到新扩容的服务器上即可。这样,在查找时,按照最新的hash算法取余,即可取出对应的数据。
这相较于hash链,进行全库冲洗,还是节省了很多
也就是说,hash链和hash环,在新增服务器的时候,都是要冲洗数据的,只是,hash链是全库冲洗(算法复杂度是N),hash环是下游节点冲洗(算法复杂度是1)
那么会有道友问,我直接上第二种方案不就得了。
这显然是不行的。
原因:
hash环是有大小的,它的特点是把hash链首尾相连,那么,假设你公司业务只有百万级数据量,你设置成一个hash环。假设,hash环周长是100,小厂有4台服务器,第一次可以人为均匀分布到环上,但是,如果业务量数据增加,导致需要扩容。这时候,如果你对hash环进行扩周长,如果不重新分配服务器在环上的位置,那就会出现数据倾斜问题,如果,重新均匀分布服务器在环上的位置,那么,就要全库重洗数据。所以,这样就和hash链没什么区别。还多出一个数据倾斜问题。那么有道友就说了,那我把hash环周长设置的超大。这样,不就可以减轻扩容时,数据倾斜问题的严重性了吗?并不是这样,当你保持环周长不变的前提下扩容的时候,数据倾斜和环的周长并没有关系。只是和你扩容的服务器策略有关,就是,假设第一次设置4台服务器,那么,你扩容的服务器必须是2的N次方台,这样才能人为的避免数据倾斜。那么,你小厂有这个实力吗?显然没有,不划算。
另外,你的环周长越大,也就意味着取余的除数越大,那么,计算取余的时间就越久,比如,你对2取余,口算即可。你对2的32次方取余,那就要多用很多时间,这样,随着积累,你浪费的时间就很多了。相对于公司业务,数据量不大,但是,损耗的计算时间却很多,那就很不划算了。所以,环的周长也是要考虑的点。
所以,使用hash环算法,要考虑两点
1、公司自身实力,每次扩容需要的服务器数据量是:a*2^n。其中,a是第一次均匀分布的服务器数据量,n>=0的整数。这个扩容方法,解决数据倾斜问题。
2、hash环周长大小选择。周长越大,计算越耗费时间。所以,要根据公司业务量大小,选择合理的周长大小,不能太小,否则经常扩容,不能太大,浪漫每次的取余时间。
3、数据倾斜问题的本质,就在于服务器节点在环上的分布是否均匀还是密集。分布密集了,那就会出现数据倾斜问题。
2.2、哈希环
原文链接:https://www.cnblogs.com/lpfuture/p/5796398.html
一致性Hash算法背景
一致性哈希算法在1997年由麻省理工学院的Karger等人在解决分布式Cache中提出的,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简单哈希算法带来的问题,使得DHT可以在P2P环境中真正得到应用。
但现在一致性hash算法在分布式系统中也得到了广泛应用,研究过memcached缓存数据库的人都知道,memcached服务器端本身不提供分布式cache的一致性,而是由客户端来提供,具体在计算一致性hash时采用如下步骤:
- 首先求出memcached服务器(节点)的哈希值,并将其配置到0~232的圆(continuum)上。
- 然后采用同样的方法求出存储数据的键的哈希值,并映射到相同的圆上。
- 然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过232仍然找不到服务器,就会保存到第一台memcached服务器上。
从上图的状态中添加一台memcached服务器。余数分布式算法由于保存键的服务器会发生巨大变化而影响缓存的命中率,但Consistent Hashing中,只有在园(continuum)上增加服务器的地点逆时针方向的第一台服务器上的键会受到影响,如下图所示:
一致性Hash性质
考虑到分布式系统每个节点都有可能失效,并且新的节点很可能动态的增加进来,如何保证当系统的节点数目发生变化时仍然能够对外提供良好的服务,这是值得考虑的,尤其实在设计分布式缓存系统时,如果某台服务器失效,对于整个系统来说如果不采用合适的算法来保证一致性,那么缓存于系统中的所有数据都可能会失效(即由于系统节点数目变少,客户端在请求某一对象时需要重新计算其hash值(通常与系统中的节点数目有关),由于hash值已经改变,所以很可能找不到保存该对象的服务器节点),因此一致性hash就显得至关重要,良好的分布式cahce系统中的一致性hash算法应该满足以下几个方面:
- 平衡性(Balance)
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
- 单调性(Monotonicity)
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲区加入到系统中,那么哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲区中去,而不会被映射到旧的缓冲集合中的其他缓冲区。简单的哈希算法往往不能满足单调性的要求,如最简单的线性哈希:x = (ax + b) mod (P),在上式中,P表示全部缓冲的大小。不难看出,当缓冲大小发生变化时(从P1到P2),原来所有的哈希结果均会发生变化,从而不满足单调性的要求。哈希结果的变化意味着当缓冲空间发生变化时,所有的映射关系需要在系统内全部更新。而在P2P系统内,缓冲的变化等价于Peer加入或退出系统,这一情况在P2P系统中会频繁发生,因此会带来极大计算和传输负荷。单调性就是要求哈希算法能够应对这种情况。
- 分散性(Spread)
在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
- 负载(Load)
负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
- 平滑性(Smoothness)
平滑性是指缓存服务器的数目平滑改变和缓存对象的平滑改变是一致的。
原理
基本概念
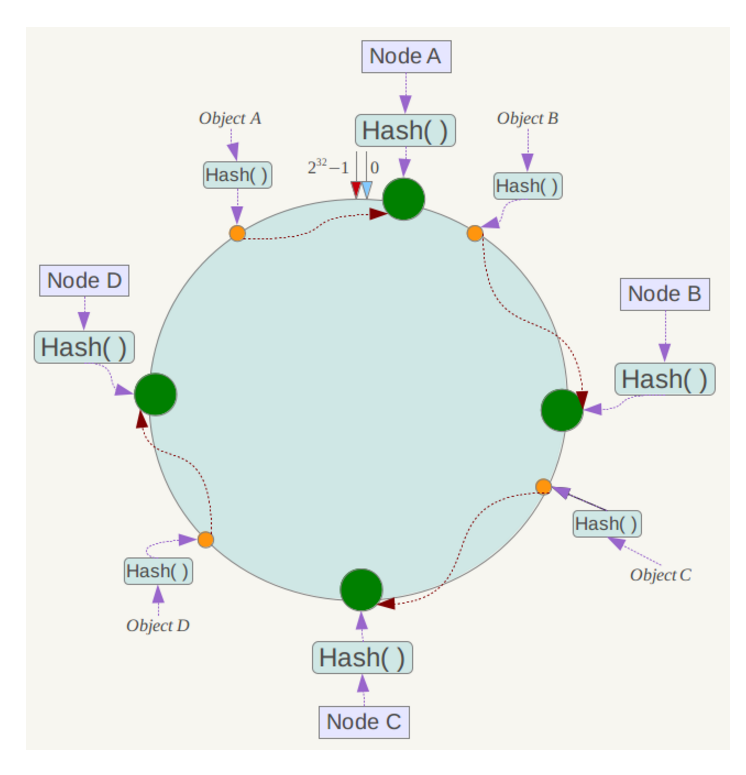
一致性哈希算法(Consistent Hashing)最早在论文《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》中被提出。简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希空间环如下:
整个空间按顺时针方向组织。0和232-1在零点中方向重合。
下一步将各个服务器使用Hash进行一个哈希,具体可以选择服务器的ip或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中四台服务器使用ip地址哈希后在环空间的位置如下:
接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
例如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:
根据一致性哈希算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。
下面分析一致性哈希算法的容错性和可扩展性。现假设Node C不幸宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性哈希算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
下面考虑另外一种情况,如果在系统中增加一台服务器Node X,如下图所示:
此时对象Object A、B、D不受影响,只有对象C需要重定位到新的Node X 。一般的,在一致性哈希算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它数据也不会受到影响。
综上所述,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
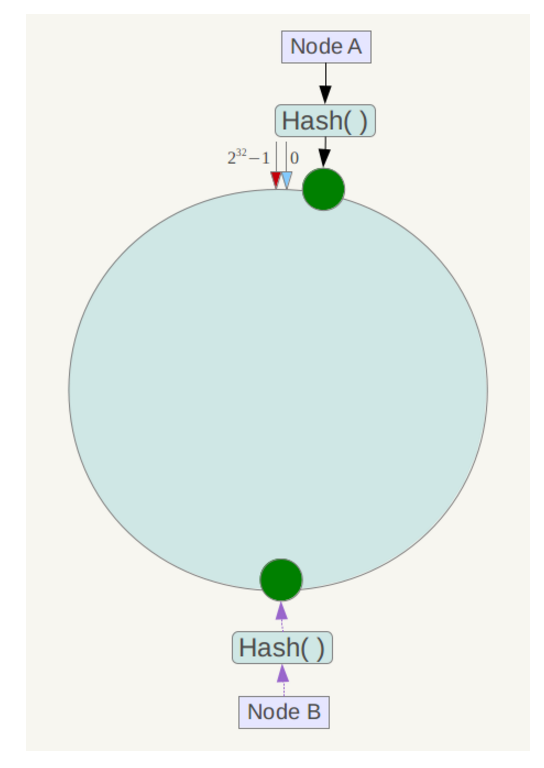
另外,一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。例如系统中只有两台服务器,其环分布如下,
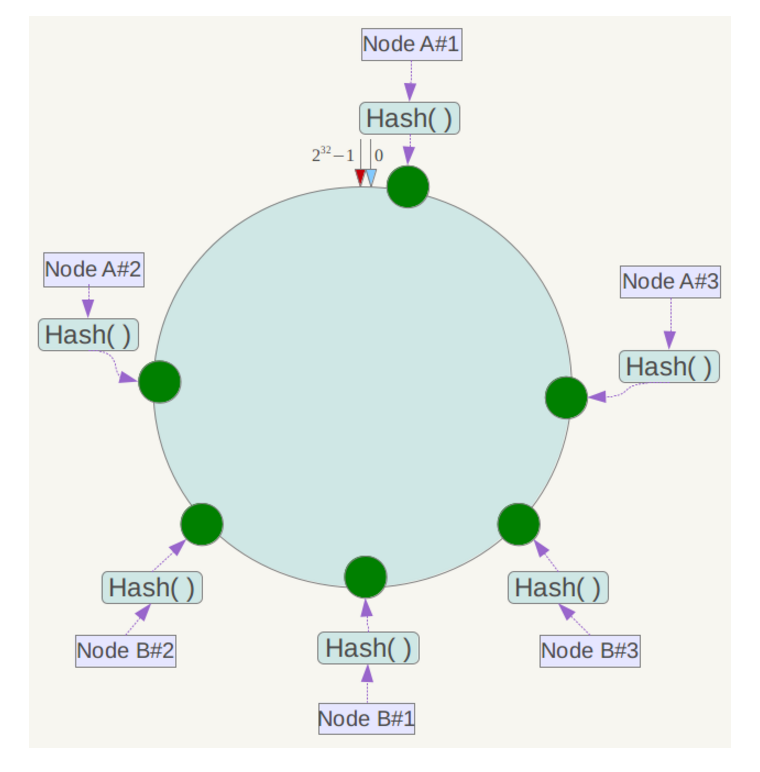
此时必然造成大量数据集中到Node A上,而只有极少量会定位到Node B上。为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器ip或主机名的后面增加编号来实现。例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,于是形成六个虚拟节点:
同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“Node A#1”、“Node A#2”、“Node A#3”三个虚拟节点的数据均定位到Node A上。这样就解决了服务节点少时数据倾斜的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。




3、Redis分区(Partitioning)
分区就是把你的数据分割到多个Redis实例中的一个过程,因此每个实例仅仅包含部分键。
Redis 集群和数据分片
Redis集群不是使用一致性哈希,而是使用哈希槽。整个redis集群有16384个哈希槽,决定一个key应该分配到那个槽的算法是:计算该key的CRC16结果再模16834。
集群中的每个节点负责一部分哈希槽,比如集群中有3个节点,则:
- 节点A存储的哈希槽范围是:0 -- 5500
- 节点B存储的哈希槽范围是:5501 -- 11000
- 节点C存储的哈希槽范围是:11001 -- 16384
这样的分布方式方便节点的添加和删除。比如,需要新增一个节点D,只需要把A、B、C中的部分哈希槽数据移到D节点。同样,如果希望在集群中删除A节点,只需要把A节点的哈希槽的数据移到B和C节点,当A节点的数据全部被移走后,A节点就可以完全从集群中删除。
因为把哈希槽从一个节点移到另一个节点是不需要停机的,所以,增加或删除节点,或更改节点上的哈希槽,也是不需要停机的。
集群支持通过一个命令(或事务, 或lua脚本)同时操作多个key。通过"哈希标签"的概念,用户可以让多个key分配到同一个哈希槽。哈希标签在集群详细文档中有描述,这里做个简单介绍:如果key含有大括号"{}",则只有大括号中的字符串会参与哈希,比如"this{foo}"和"another{foo}"这2个key会分配到同一个哈希槽,所以可以在一个命令中同时操作他们。
4、Redis面试题
4.1、使用过Redis分布式锁么,它是怎么实现的?
先拿setnx来争抢锁,抢到之后,再用expire给锁加一个过期时间防止锁忘记了释放。
4.2、什么是缓存击穿?如何避免?什么是缓存穿透?如何避免?什么是缓存雪崩?何如避免?
缓存击穿
KEY的过期,造成并发访问数据库
如何避免?
先拿setnx来争抢锁,抢到之后,get key setnx ok去DB false,sleep 1。
1、防止死锁:设置锁的过期时间。2、没挂,锁超时:更新锁时间
缓存穿透
一般的缓存系统,都是按照key去缓存查询,如果不存在对应的value,就应该去后端系统查找(比如DB)。一些恶意的请求会故意查询不存在的key,请求量很大,就会对后端系统造成很大的压力。这就叫做缓存穿透。
如何避免?
1:对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该key对应的数据insert了之后清理缓存。
2:对一定不存在的key进行过滤。可以把所有的可能存在的key放到一个大的Bitmap中,查询时通过该bitmap过滤。
布隆过滤器
缓存雪崩
当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,会给后端系统带来很大压力。导致系统崩溃。
如何避免?
1:在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
2:做二级缓存,A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期
3:不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。随机过期时间。
零点:业务层增加零点延迟-->强依赖击穿解决方案。
4.3、解释Redis的复制功能?
Redis 可以使用主从同步,从从同步。第一次同步时,主节点做一次 bgsave,并同时将后续修改操作记录到内存 buffer,待完成后将 rdb 文件全量同步到复制节点,复制节点接受完成后将 rdb 镜像加载到内存。加载完成后,再通知主节点将期间修改的操作记录同步到复制节点进行重放就完成了同步过程。
Redis缓存数据库(一)
干我们这行,啥时候懈怠,就意味着长进的停止,长进的停止就意味着被淘汰,只能往前冲,直到凤凰涅槃的一天!
相关文章:
Redis缓存数据库(四)
目录 一、概述 1、Redis Sentinel 1.1、docker配置Redis Sentinel环境 2、Redis存储方案 2.1、哈希链 2.2、哈希环 3、Redis分区(Partitioning) 4、Redis面试题 一、概述 1、Redis Sentinel Redis Sentinel为Redis提供了高可用解决方案。实际上这意味着使用Sentinel…...

View中的滑动冲突
View中的滑动冲突 1.滑动冲突的种类 滑动冲突一般有3种, 第一种是ViewGroup和子View的滑动方向不一致 比如: 父布局是可以左右滑动,子view可以上下滑动 第二种 ViewGroup和子View的滑动方向一致 第三种 第三种类似于如下图 2.滑动冲突的解决方式 滑动冲突一般情况下有2…...
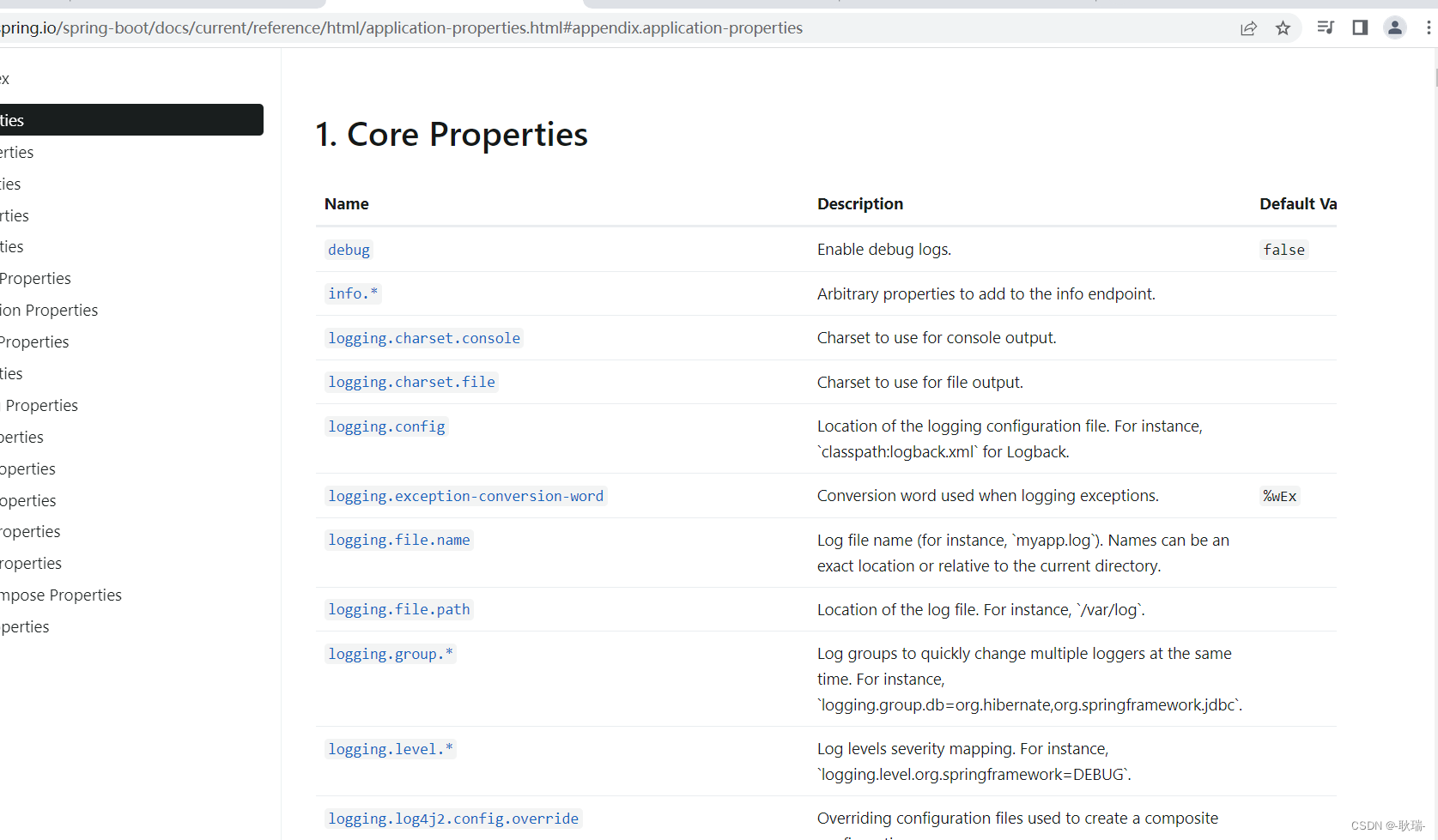
java boot项目基础配置之banner与日志配置演示 并教会你如何使用文档查看配置
上文 我们简单讲了一下 springboot 项目的配置 都是写在resources下的application.properties中 springboot 项目中 配置都写在这一个文件 可以说非常方便 不像之前 写个项目配置这里一个哪里一个 看到是非常费力 我们启动项目 这里有个图案 其实 这叫 banner 我们就用配置来…...
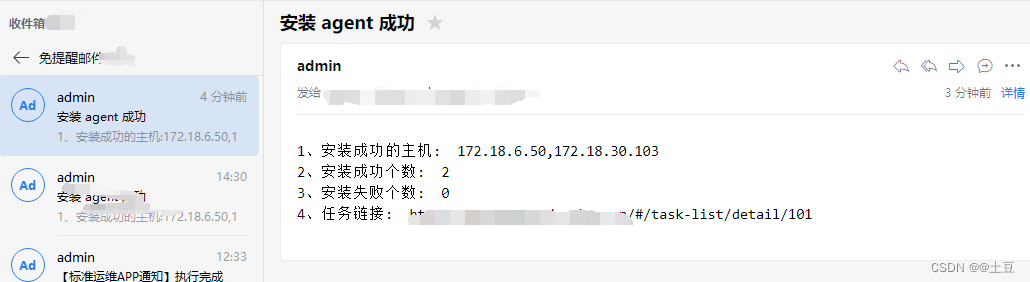
蓝鲸平台通过标准运维 API 安装 Agent
目录 一、背景 二、目的 三、创建安装agent流程 四、通过标准运维 API 安装 Agent 五、总结 一、背景 蓝鲸平台正常情况纳管主机需要在节点管理手工安装agent,不能达到完成自动化安装agent的效果。想通过脚本一键安装agent,而不需要在蓝鲸平台进行过…...

python 图片保存成视频
👨💻个人简介: 深度学习图像领域工作者 🎉工作总结链接:https://blog.csdn.net/qq_28949847/article/details/128552785 链接中主要是个人工作的总结,每个链接都是一些常用demo,…...

uniapp 引入 Less SCSS
✨求关注~ 😀博客:www.protaos.com 本文将介绍如何在 UniApp 中引入 Less 和 SCSS,两种流行的 CSS 预处理器。通过使用 Less 和 SCSS,你可以在 UniApp 项目中更灵活地编写样式,并享受预处理器提供的便利功能。 代码实现…...

Linux程序设计:文件操作
文件操作 系统调用 write //函数定义 #include <unistd.h> size_t write(int fildes, const void *buf, size_t nbytes); //示例程序 #include <unistd.h> #include <stdlib.h> int main() { if ((write(1, “Here is some data\n”, 18)) ! 18)write(2, …...

【自制C++深度学习推理框架】Tensor模板类的设计思路
Tensor模板类的设计思路 为什么要把Armadillo线性代数库arma::fcube封装成Tensor模板类? arma::fcube是Armadillo线性代数库中的一种数据类型,它是一个三维的float类型张量。Armadillo库是一个C科学计算库,提供了高效的线性代数和矩阵运算。…...
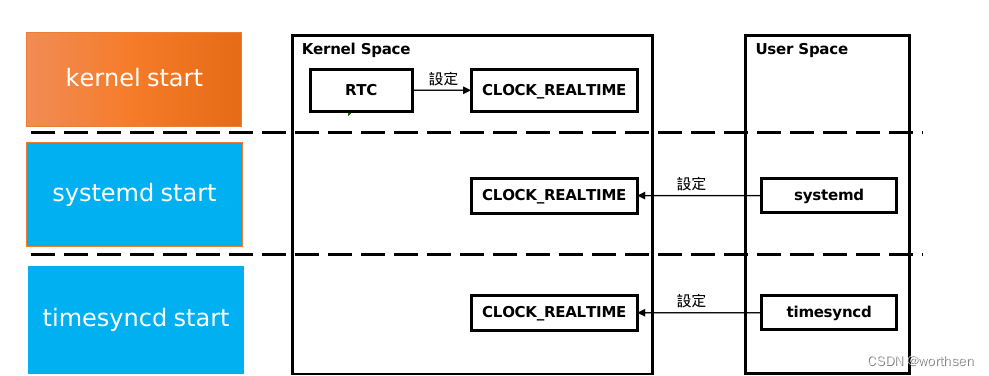
linux--systemd、systemctl
linux--systemd、systemctl 1 介绍1.1 发展sysvinitupstart主角 systemd 登场 1.2 简介 2 优点兼容性启动速度systemd 提供按需启动能力采用 linux 的 cgroups 跟踪和管理进程的生命周期启动挂载点和自动挂载的管理实现事务性依赖关系管理日志服务systemd journal 的优点如下&a…...

加密解密软件VMProtect教程(七):主窗口之控制面板“详情”部分
VMProtect是新一代软件保护实用程序。VMProtect支持德尔菲、Borland C Builder、Visual C/C、Visual Basic(本机)、Virtual Pascal和XCode编译器。 同时,VMProtect有一个内置的反汇编程序,可以与Windows和Mac OS X可执行文件一起…...

国产仪器 4945B/4945C 无线电通信综合测试仪
4945系列无线电通信综合测试仪是多功能、便携式无线电综合测试类仪器,基于软件无线电架构,集成了跳频信号发生与分析、矢量信号发生与解调分析、模拟调制信号发生与解调分析、音频信号发生与分析、音频示波器、自动测试等功能,它可完成无线通…...
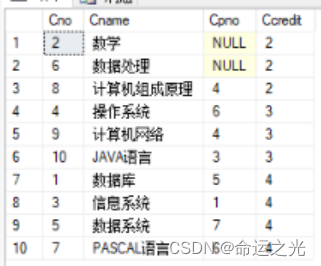
数据库原理及应用上机实验一
✨作者:命运之光 ✨专栏:数据库原理及应用上机实验报告整理 目录 ✨一、实验目的和要求 ✨二、实验内容与步骤 🍓🍓前言: 数据库原理及应用上机实验报告的一个简单整理后期还会不断完善🍓🍓…...

【操作系统】线程常用操作
线程号 就像每个进程都有一个进程号一样,每个线程也有一个线程号。进程号在整个系统中是唯一的,但线程号不同,线程号只在它所属的进程环境中有效。 进程号用 pid_t 数据类型表示,是一个非负整数。线程号则用 pthread_t 数据类型…...

C++编译预处理
目录 一、包含头文件 1)#include包含头文件又两种方式: ①#include<文件名>: ②#include"文件名": 2)C98标准后的头文件: ①C的标准库 ②C的标准库 3)注意 二、宏定义 1…...

Spring IOC 的理解
IoC容器是什么? IoC文英全称Inversion of Control,即控制反转,我么可以这么理解IoC容器: “把某些业务对象的的控制权交给一个平台或者框架来同一管理,这个同一管理的平台可以称为IoC 容器。” 我们刚开始学习…...
:时间片)
Linux 学习笔记(七):时间片
一、时间片概念 时间片(timeslice)又称为 “量子”(quantum)或 “处理器片”(processor slice),是分时操作系统分配给每个正在运行的进程微观上的一段 CPU 时间(在抢占内核中是&…...

java并发-ReentrantLock
当多个线程需要同时对共享资源进行操作时,就需要用到线程同步技术。Java中提供了synchronized关键字用于线程同步,而ReentrantLock就是另外一种用于线程同步的技术,本文将介绍ReentrantLock及其使用方法。 ### 1. 概述 ReentrantLock是Java…...

21.模型的访问器和修改器
学习要点: 1.访问器 2.修改器 本节课我们来开始学习数据库模型的访问器和修改器的使用。 一.访问器 1. 访问器:就是在获取数据列表时,拦截属性并对属性进行修改的过程; 2. 比如,我们在输出性别时࿰…...

72 yaffs文件系统挂载慢 sync不起作用
1 引言 最近在开放过程中遇到了一个问题:Linux在启动挂载根文件系统时很慢很慢!而且每次开机都是这样,一下子让人难以理解。 因为,理论上当机器第一次启动,会扫描完整的rootfs的flash区域,从而建立索引&…...

【无标题】春漫乌海湖!
春漫乌海湖! 杨桂林 黄河流经几字弯内蒙古段的第一段便遇见了镶嵌在大漠中的璀璨明珠乌海湖。 谁也不会相信:这里被乌兰布和、库布其、毛乌素三大沙漠重重包围,矿山林立,煤尘喧嚣飞扬的黑色煤都,如今在金色沙海的映衬下,柔润潋滟周…...

别被忽悠了!2026亲测靠谱的AI论文网站|避坑精选版
2026 年学术写作工具已高度分化,千笔AI与ThouPen为全流程首选,豆包、DeepSeek 为专项强手;避坑关键:拒绝假文献、严控 AIGC 率、优先国内适配、免费试用先行。 一、TOP3 全流程首选(亲测不踩雷) 1. 千笔AI&…...

账务台账数据
银行里说的 “账务台账数据”,本质就是按会计规则把每笔业务逐笔、分户、分科目记下来的完整明细流水 余额 辅助信息,核心是 “可逐笔追溯、可对账、可审计” 的一套明细数据。下面用通俗、具体的方式拆开说:一、银行 “账务台账” 到底是什…...

Spring Security OAuth2 /oauth/token 401原因与Content-Type规范
1. 问题现场还原:一个看似简单却让开发停摆两小时的/oauth/token请求刚接手一个老项目做安全加固,第一件事就是验证OAuth2密码模式的token获取流程。我照着文档写了一条curl命令:curl -X POST http://localhost:8080/oauth/token回车执行&…...

yolo视频识别 车辆速度估计识别 yolo11视频实时速度测量与测速估计
文章目录YOLOv11:视频实时速度测量与测速估计一、YOLOv11概述二、速度测量原理三、距离测量方法四、应用场景五、实践案例以下是关于使用YOLOv11进行视频实时速度测量与测速估计的介绍: YOLOv11:视频实时速度测量与测速估计 随着计算机视觉…...

2026论文顶级降AI率工具大曝光:一键把AIGC率降至安全线!
步入2026年,学术圈的规则已经彻底变了味。过去那种只盯着查重率的“降重焦虑”早就被更可怕的“降AI焦虑”取代了。AI检测算法越来越聪明,高校审核标准也越来越严苛,光是把重复率压下去已经完全不够用了。现在摆在学生和科研人员面前的难题是…...

XZ6128A工作电压5-100V 输出电流5A 升压型大功率LED灯恒流驱动控制芯片
概述 XZ6128A是一款高效率、高精度的升压型大功率LED灯恒流驱动控制芯片。 XZ6128A内置高精度误差放大器,固定关断时间控制电路,恒流驱动电路等,特别适合大功率、多个高亮度LED灯串的恒流驱动。 XZ6128A采用固定关断时间的控制方式࿰…...

DIY智能USB充电器:基于电流检测与双稳态继电器的零功耗节能方案
1. 项目概述:打造一款智能、节能的USB手机充电器作为一名电子爱好者,我经常折腾各种电源项目。市面上很多手机充电器,包括一些原装货,都存在一个通病:手机充满电后,充电器依然插在插座上,内部电…...

观察Taotoken在多模型聚合调用下的路由与失败重试效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型聚合调用下的路由与失败重试效果 在构建依赖大模型能力的应用时,服务的稳定性是开发者关注的核心…...

基于ESP32与MQTT的智能时钟:从硬件驱动到物联网系统集成实战
1. 项目概述:一个基于ESP32和MQTT的智能卧室时钟几年前,我在一个旧货市场淘到了四块巨大的SA40-19SRWA七段数码管,它们一直躺在我的零件箱里吃灰。直到ESP32这颗功能强大的物联网芯片变得唾手可得,我才终于为它们找到了完美的归宿…...

终极指南:5步精通开源网页版三国杀无名杀
终极指南:5步精通开源网页版三国杀无名杀 【免费下载链接】noname 项目地址: https://gitcode.com/GitHub_Trending/no/noname 想要随时随地畅玩经典的三国杀卡牌游戏吗?无名杀作为当前最受欢迎的开源网页版三国杀,让你无需下载客户端…...