【数据结构】线性表之栈、队列

前言
前面两篇文章讲述了关于线性表中的顺序表与链表,这篇文章继续讲述线性表中的栈和队列。
这里讲述的两种线性表与前面的线性表不同,只允许在一端入数据,一段出数据,详细内容请看下面的文章。
顺序表与链表两篇文章的链接:
线性表之顺序表
线性表之链表
注意: 本文提到的效率全部为空间复杂度!!!!
一、栈
1. 栈的概念
栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO (Last ln FirstOut)的原则.
入栈:栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。
出栈:栈的删除操作叫做出栈。出数据也在栈顶。
2. 栈的结构
栈的结构决定了栈只能在栈顶入数据,栈顶出数据,并且遵循着后进先出的原则。
2.1 选择数据结构完成栈(数组 or 链表)
2.1.1 数组
前面学习过顺序表就能知道,数组只有尾插和尾删的效率高为 O(1) , 而靠近头的位置的插入删除的效率比较低为O(N)。
而对于栈这种只能在栈顶插入、删除的数据结构可谓是完美契合数组的优点。
2.1.2 链表
前面学习过链表就可以知道,对于单链表的头插、头删的效率非常高为 O(1) , 而它的尾插、尾删需要找尾,效率比较低为 O(N)。
若以单链表的头为栈底,尾为栈顶,则入栈、出栈相当于单链表的尾插、尾删效率并不高。
显然这不是我们的最佳选项,但是若用一个变量记录尾的情况下,尾插、尾删的效率也可以达到O(1)。
若以单链表的头为栈顶,尾为栈底,则入栈、出栈相当于单链表的头插、头删效率非常高为O(1)。
这里与前面的数组差不多,也是栈的操作完全契合单链表的优点。
栈能够使用单链表实现,当然也可以用带头双向循环链表实现,但是我认为这里使用带头双向循环链表有点大炮打蚊子,大材小用的感觉。
2.1.3 我选择用数组完成栈
为什么这里选择数组完成栈呢?
明明数组容量不足时扩容需要消耗,而链表没有这个消耗,为什么不用链表?
原因有以下几点:
- 由于数组物理结构上是连续的,缓存命中率高,访问效率高。
- 相比链表,数组只需要存储数据,而链表每一个节点还需要存下一个节点的地址。
- 虽然数组扩容有消耗,但是链表每次申请节点的时候也会有消耗。
2.2 栈的操作
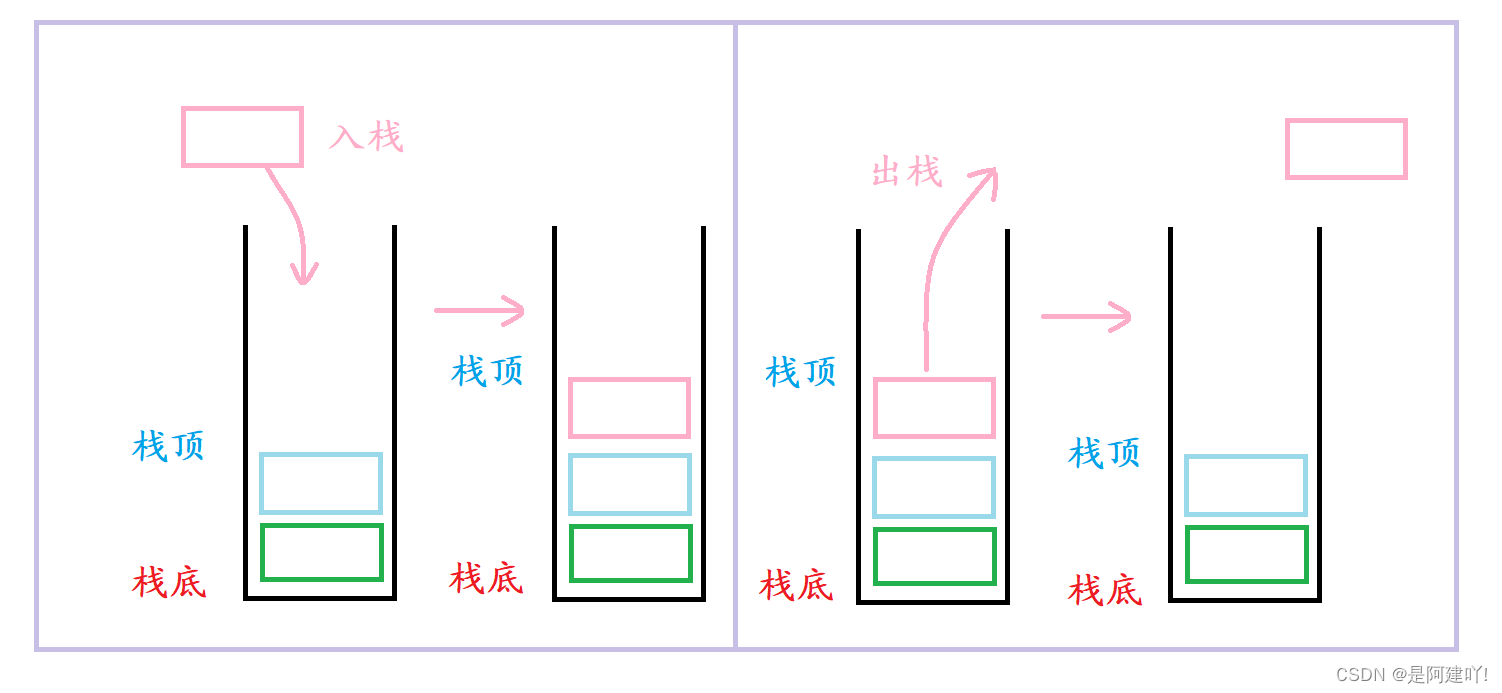
3. 栈的实现
Stack.h头文件的实现
#pragma once#include <stdio.h>
#include <stdlib.h>
#include <assert.h>// 支持动态增长的栈
typedef int STDataType;
typedef struct Stack
{STDataType* a;int top; // 栈顶int capacity; // 容量
}Stack;
// 初始化栈
void StackInit(Stack* ps);
// 入栈
void StackPush(Stack* ps, STDataType data);
// 出栈
void StackPop(Stack* ps);
// 获取栈顶元素
STDataType StackTop(Stack* ps);
// 获取栈中有效元素个数
int StackSize(Stack* ps);
// 检测栈是否为空,如果为空返回非零结果,如果不为空返回0
int StackEmpty(Stack* ps);
// 销毁栈
void StackDestroy(Stack* ps);
Stack.c文件的实现
3.1 初始化栈
栈的初始化将传入函数的结构体进行初始化:
a. 栈顶初始化的时候注意有两种情况:
1. top指向栈顶元素
2. top指向栈顶元素的后面一个位置
当然都可以,我选择 1 仅仅方便我自己理解
b. 是否在初始化的时候给栈申请部分空间
当然都可以,我这里选择不申请空间,在后面用realloc函数申请和扩容空间。
// 初始化栈
void StackInit(Stack* ps)
{assert(ps);ps->capacity = 0;//ps->top = -1; //top指向栈顶ps->top = 0; //top指向栈顶的后面一个元素ps->a = NULL;
}
3.2 入栈
当数据入栈时需要判断栈是否为满,若为满则需要扩容,这里的StackFull函数其实并没有必要,由于栈只有尾插这一个插入操作不需要复用扩容操作,所以可以直接写在入栈操作中。
注意:
当realloc()函数的参数为NULL时,其作用与malloc()函数的作用一样。
void StackFull(Stack* ps)
{assert(ps);int newcapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;STDataType* tmp = (STDataType*)realloc(ps->a, sizeof(STDataType) * newcapacity);if (tmp == NULL){perror("realloc");return;}ps->a = tmp;ps->capacity = newcapacity;
}// 入栈
void StackPush(Stack* ps, STDataType data)
{assert(ps);if (ps->capacity == ps->top)StackFull(ps);ps->a[ps->top] = data;ps->top++;
}
3.3 判空
前面假设了top是指向栈顶元素后面一个位置,所以当 top 指向 0 的时候栈是空的。
// 检测栈是否为空,如果为空返回非零结果,如果不为空返回0
int StackEmpty(Stack* ps)
{assert(ps);return ps->top == 0;
}
3.4 出栈
执行出栈操作时,栈不能为空,且只需要 top-- , 不需要将其数据抹除。
// 出栈
void StackPop(Stack* ps)
{assert(ps);assert(!StackEmpty(ps));//栈为空,则不能继续出栈ps->top--;
}
3.5 取栈顶元素
与出栈操作一样,取栈顶元素时,栈不能为空。
且top是指向栈顶元素后面一个位置,所以取栈顶元素时取的是 top - 1 指向的元素。
// 获取栈顶元素
STDataType StackTop(Stack* ps)
{assert(ps);assert(!StackEmpty(ps));//栈为空,则无栈顶元素return ps->a[ps->top - 1];
}3.6 获取栈中有效元素个数
由于top是指向栈顶元素的下一个位置,而元素个数正好是下标 + 1 ,也就是top。
// 获取栈中有效元素个数
int StackSize(Stack* ps)
{assert(ps);return ps->top; //由于top是指向栈顶元素的下一个位置 //而元素个数正好是下标 + 1 ,也就是top
}
3.7 销毁栈
// 销毁栈
void StackDestroy(Stack* ps)
{assert(ps);free(ps->a);ps->a = NULL;ps->capacity = 0;ps->top = 0;
}
4. 整体代码的实现
#include "Stack.h"
// 初始化栈
void StackInit(Stack* ps)
{assert(ps);ps->capacity = 0;ps->top = 0; //top指向栈顶的后面一个元素ps->a = NULL;
}void StackFull(Stack* ps)
{assert(ps);int newcapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;STDataType* tmp = (STDataType*)realloc(ps->a, sizeof(STDataType) * newcapacity);if (tmp == NULL){perror("realloc");return;}ps->a = tmp;ps->capacity = newcapacity;
}// 入栈
void StackPush(Stack* ps, STDataType data)
{assert(ps);if (ps->capacity == ps->top)StackFull(ps);ps->a[ps->top] = data;ps->top++;
}// 检测栈是否为空,如果为空返回非零结果,如果不为空返回0
int StackEmpty(Stack* ps)
{assert(ps);return ps->top == 0;
}// 出栈
void StackPop(Stack* ps)
{assert(ps);assert(!StackEmpty(ps));//栈为空,则不能继续出栈ps->top--;
}// 获取栈顶元素
STDataType StackTop(Stack* ps)
{assert(ps);assert(!StackEmpty(ps));//栈为空,则无栈顶元素return ps->a[ps->top - 1];
}// 获取栈中有效元素个数
int StackSize(Stack* ps)
{assert(ps);return ps->top; //由于top是指向栈顶元素的下一个位置 //而元素个数正好是下标 + 1 ,也就是top
}// 销毁栈
void StackDestroy(Stack* ps)
{assert(ps);free(ps->a);ps->a = NULL;ps->capacity = 0;ps->top = 0;
}
二、队列
1. 队列的概念
队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有 先进先出 FIFO(First In First Out) 的原则。
入队列:进行插入操作的一端称为队尾
出队列:进行删除操作的一端称为队头
2. 队列的结构
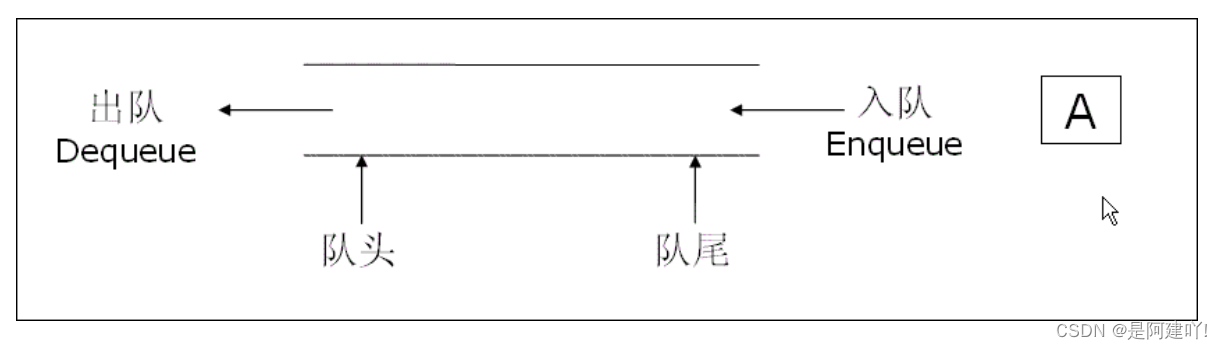
2.1 选择数据结构完成队列(数组 or 链表)
2.1.1 数组
前面学习过顺序表就能知道,数组只有尾插和尾删的效率高为 O(1) , 而靠近头的位置的插入删除的效率比较低为O(N)。
而对于队列这种只能在队尾插入、对头删除的数据结构,无论队头和队尾定义在哪,使用数组完成必定会有头删或头插,会使得队列的效率降低,所以不建议使用数组完成。
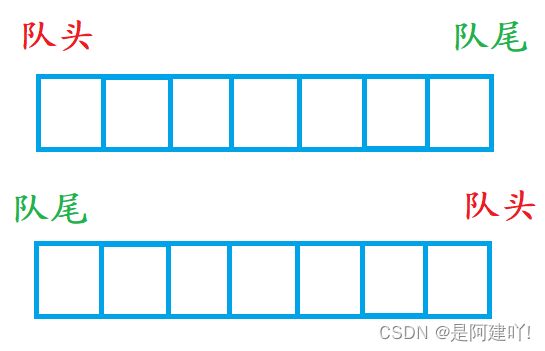
2.1.2 链表
前面学习过链表就可以知道,对于单链表的头插、头删的效率非常高为 O(1) , 而它的尾插、尾删需要找尾,效率比较低为 O(N)。
(1)若以单链表的头为队头,尾为队尾,则入队列、出队列相当于单链表的尾插、头删效率并不高。
(2)若以单链表的头为队尾,尾为队头,则入队列、出队列相当于单链表的头插、尾删效率并不高。
虽然两种情况都有一种操作效率为O(N) , 但是这两种情况都是与尾有关的操作,
所以只要在结构体中定一个记录尾的成员,那么尾插、尾删的效率就能达到O(1).
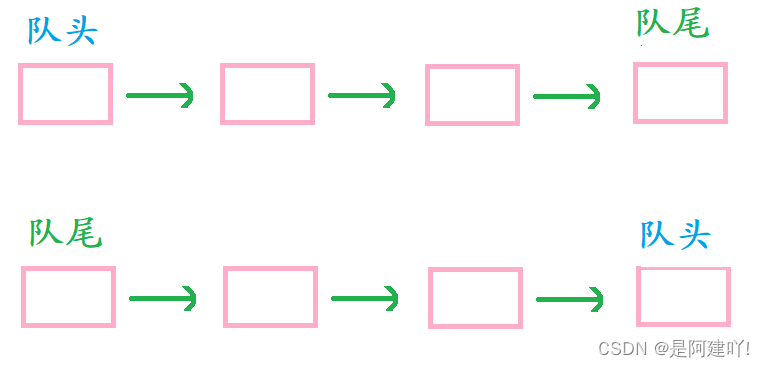
2.1.3 我选择用链表完成队列
为什么这里选择链表完成队列?
通过上面的讲述原因已经显而易见了。
原因如下:
由于无论怎么改造数组都会有一个操作效率为 O(N),而链表只需要改变结构体,使其多一个指向尾的成员,就能使队列的插入、删除的操作效率为O(1).
3. 队列的实现
Queue.h头文件的实现
#pragma once#include <stdio.h>
#include <stdlib.h>
#include <assert.h>typedef int QDataType;// 链式结构:表示队列
typedef struct QListNode
{struct QListNode* next;QDataType data;
}QNode;// 队列的结构
typedef struct Queue
{QNode* front;QNode* rear; //指向队列最后一个元素的后面int size;
}Queue;// 初始化队列
void QueueInit(Queue* q);
// 队尾入队列
void QueuePush(Queue* q, QDataType data);
// 队头出队列
void QueuePop(Queue* q);
// 获取队列头部元素
QDataType QueueFront(Queue* q);
// 获取队列队尾元素
QDataType QueueBack(Queue* q);
// 获取队列中有效元素个数
int QueueSize(Queue* q);
// 检测队列是否为空,如果为空返回非零结果,如果非空返回0
int QueueEmpty(Queue* q);
// 销毁队列
void QueueDestroy(Queue* q);
Queue.c文件的实现
3.1 初始化队列
这里队列的front指向队头,rear指向队尾。
当队列为空的时候,那么front和rear 都是指向 NULL。
// 初始化队列
void QueueInit(Queue* q)
{q->front = NULL;q->rear = NULL;q->size = 0;
}

3.2 队尾入队列
由于使用链表实现队列,插入时需要申请一个节点。
入队列分为两种情况:
- 队列为空时,需要改变队头、队尾的指针。
- 队列不为空时,只需要将新节点接到队尾,并将尾指针向后移动即可。
// 队尾入队列
void QueuePush(Queue* q, QDataType data)
{assert(q);QNode* newnode = (QNode*)malloc(sizeof(QNode));if (newnode == NULL){perror("malloc");return;}newnode->next = NULL;newnode->data = data;if (q->front == NULL) //分队列是否有元素两种情况{ //队列为空assert(q->rear == NULL);q->front = newnode;q->rear = newnode;}else{ //队列不为空q->rear->next = newnode;q->rear = newnode;}q->size++;//入队列,队列长度加一
}
3.3 判空
当队列中的头、尾指针都指向NULL的时候为队列为空。
// 检测队列是否为空,如果为空返回非零结果,如果非空返回0
int QueueEmpty(Queue* q)
{assert(q);return q->front == NULL && q->rear == NULL;
}
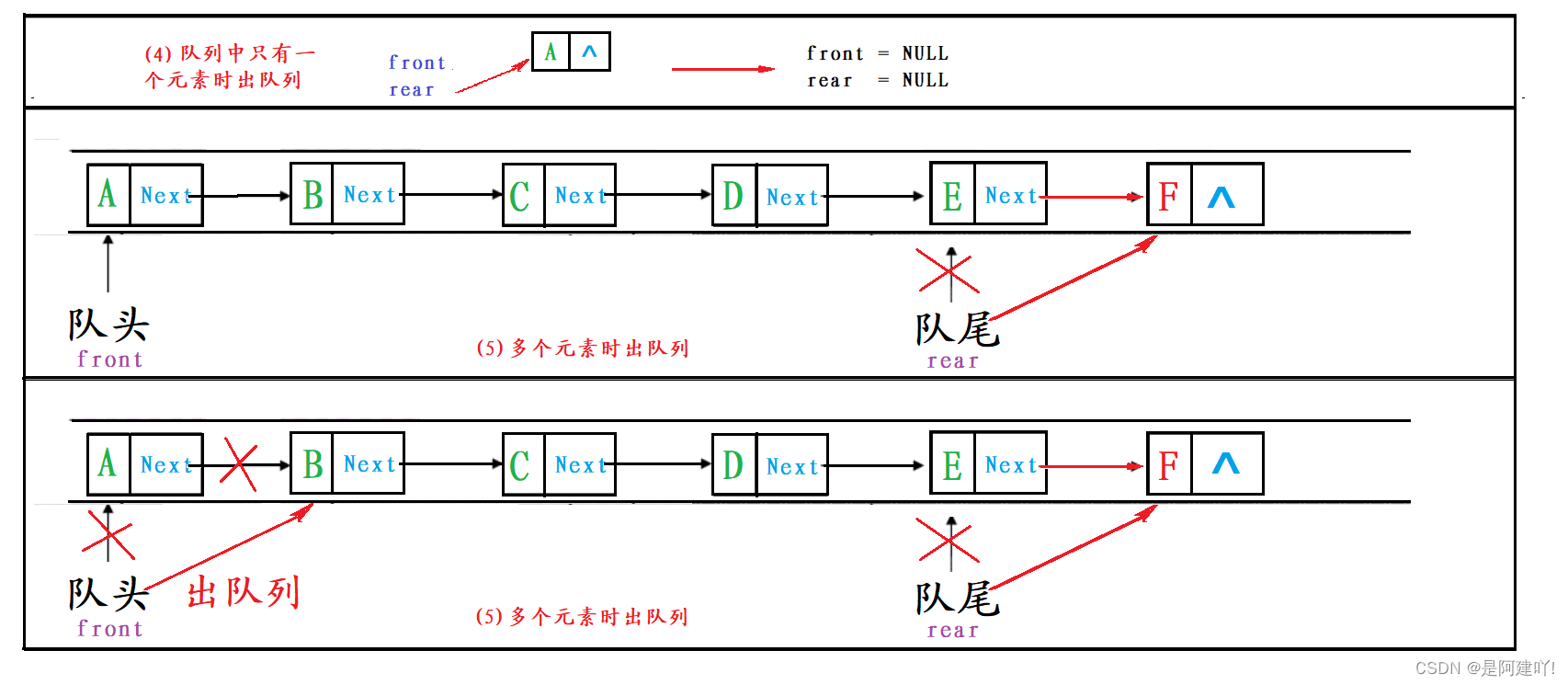
3.4 队头出队列
出队列分为两种情况:
- 队列中只有一个元素时:删除最后一个节点,并将
front和rear指向NULL。 - 队列中有多个元素时:删除
front指向的节点,并将front向后移动。
// 队头出队列
void QueuePop(Queue* q)
{assert(q);//出队列时,队列不能为空assert(!QueueEmpty(q));//当队列中只有一个元素的时候,不仅仅头指针需要改变,尾指针也需要改变//因为当删除最后一个元素时,首指针释放当前节点,并向后移动,而尾指针并没有移动//当释放后若在插入元素时,尾指针会造成野指针的情况if (q->front->next == NULL){QNode* del = q->front;q->front = NULL;q->rear = NULL;free(del);}else{QNode* del = q->front;q->front = q->front->next;free(del);}q->size--;
}
3.5 获取队列头部元素
front 指向的节点存储着头部元素。
// 获取队列头部元素
QDataType QueueFront(Queue* q)
{assert(q);//获取队列头部元素时,队列不能为空assert(!QueueEmpty(q));return q->front->data;
}
3.6 获取队列队尾元素
rear 指向的节点存储着尾元素。
// 获取队列队尾元素
QDataType QueueBack(Queue* q)
{assert(q);//获取队列头部元素时,队列不能为空assert(!QueueEmpty(q));return q->rear->data;
}
3.7 获取队列中有效元素个数
结构体中的 size 存储着队列中的有效元素个数
// 获取队列中有效元素个数
int QueueSize(Queue* q)
{assert(q);//结构体中定义了一个size//而这里遍历链表得到个数,效率低O(N)/*int size = 0; 不要用QNode* cur = q->front;while (cur != q->rear){size++;q->front = q->front->next;}*/return q->size;
}
3.8 销毁队列
销毁队列与前面销毁单链表相同,需要将每一个节点都释放。
// 销毁队列
void QueueDestroy(Queue* q)
{assert(q);QNode* cur = q->front;while (cur){QNode* next = cur->next;free(cur);cur = next;}
}
4. 整体代码的实现
// 初始化队列
void QueueInit(Queue* q)
{q->front = NULL;q->rear = NULL;q->size = 0;
}// 队尾入队列
void QueuePush(Queue* q, QDataType data)
{assert(q);QNode* newnode = (QNode*)malloc(sizeof(QNode));if (newnode == NULL){perror("malloc");return;}newnode->next = NULL;newnode->data = data;if (q->front == NULL) //分队列是否有元素两种情况{assert(q->rear == NULL);q->front = newnode;q->rear = newnode;}else{q->rear->next = newnode;q->rear = newnode;}q->size++;//入队列,队列长度加一
}// 检测队列是否为空,如果为空返回非零结果,如果非空返回0
int QueueEmpty(Queue* q)
{assert(q);return q->front == NULL && q->rear == NULL;
}// 队头出队列
void QueuePop(Queue* q)
{assert(q);//出队列时,队列不能为空assert(!QueueEmpty(q));//当队列中只有一个元素的时候,不仅仅头指针需要改变,尾指针也需要改变//因为当删除最后一个元素时,首指针释放当前节点,并向后移动,而尾指针并没有移动//当释放后若在插入元素时,尾指针会造成野指针的情况if (q->front->next == NULL){QNode* del = q->front;q->front = NULL;q->rear = NULL;free(del);}else{QNode* del = q->front;q->front = q->front->next;free(del);}q->size--;
}// 获取队列头部元素
QDataType QueueFront(Queue* q)
{assert(q);//获取队列头部元素时,队列不能为空assert(!QueueEmpty(q));return q->front->data;
}// 获取队列队尾元素
QDataType QueueBack(Queue* q)
{assert(q);//获取队列头部元素时,队列不能为空assert(!QueueEmpty(q));return q->rear->data;
}// 获取队列中有效元素个数
int QueueSize(Queue* q)
{assert(q);//结构体中定义了一个size//而这里遍历链表得到个数,效率低/*int size = 0; 不要用QNode* cur = q->front;while (cur != q->rear){size++;q->front = q->front->next;}*/return q->size;
}// 销毁队列
void QueueDestroy(Queue* q)
{assert(q);QNode* cur = q->front;while (cur){QNode* next = cur->next;free(cur);cur = next;}
}
结尾
注意: 本文提到的效率全部为空间复杂度!!!!
如果有什么建议和疑问,或是有什么错误,大家可以在评论区中提出。
希望大家以后也能和我一起进步!!🌹🌹
如果这篇文章对你有用的话,希望大家给一个三连!!🌹🌹

相关文章:
【数据结构】线性表之栈、队列
前言 前面两篇文章讲述了关于线性表中的顺序表与链表,这篇文章继续讲述线性表中的栈和队列。 这里讲述的两种线性表与前面的线性表不同,只允许在一端入数据,一段出数据,详细内容请看下面的文章。 顺序表与链表两篇文章的链接&…...
字符串截取方法总结)
StringUtils.substring\[XX]()字符串截取方法总结
StringUtils.substring[XX]()字符串截取方法总结 StringUtils (Apache Commons Lang 3.12.0 API) 文章目录 StringUtils.substring\[XX]()字符串截取方法总结导入依赖方法介绍substring(String str, int start)substring(String str, int start, int end)substringAfter(String…...
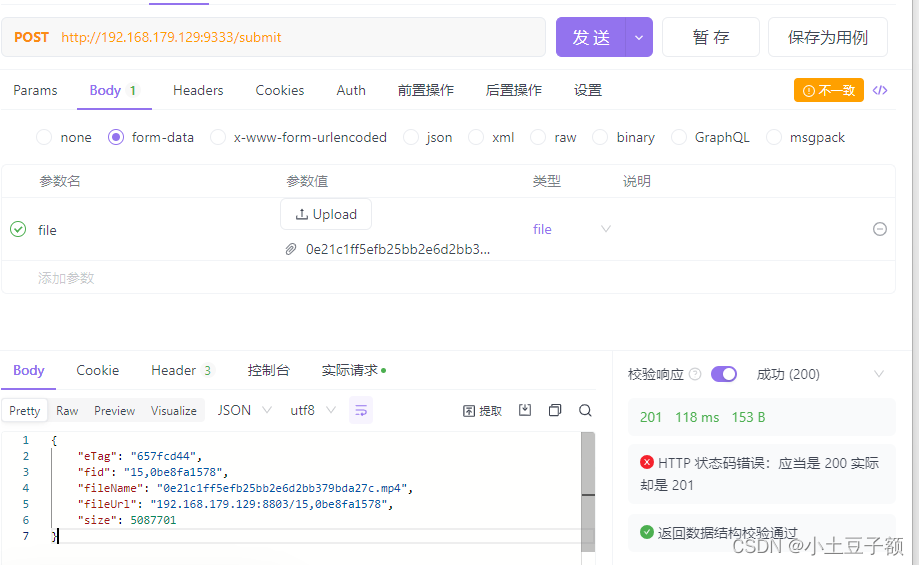
SeaweedFs使用-通过http接口实现文件操作
通过http接口实现文件操作 SeaweedFs可通过filer的http接口/master中的http接口来进行文件上传 1.通过master的接口进行上传文件 通过各种方式进行请求接口:http://localhost:9333/submit, ip和端口号是master服务的信息。此接口通过post请求方式将文件的二进制流…...

成绩管理系统
系列文章 任务28 成绩管理系统 文章目录 系列文章一、实践目的与要求1、目的2、要求 二、课题任务三、总体设计1.存储结构及数据类型定义2.程序结构3.所实现的功能函数4、程序流程图 四、小组成员及分工五、 测试读入数据浏览全部信息增加学生信息保存数据删除学生信息修改学生…...

【MYSQL】事务的4大属性,对隔离级别的详细讲解
目录 1.原子性和持久性 1.1.手动提交事务 1.2.自动提交事务 1.3.事务的原理: 2.隔离性 1.读未提交(Read Uncommitted) 2.读提交(Read Committed) 3.可重复读 4.串行化 3.一致性 4.理解读提交和可重复读的实现…...

如何在宝塔面板后的阿里云服务器运行Flask项目并公网可以访问?
在你的服务器安装宝塔面板 宝塔面板是服务器运维管理系统 使用宝塔前: 手工输入命令安装各类软件,操作起来费时费力并且容易出错,而且需要记住很多Linux的命令,非常复杂。 使用宝塔后: 2分钟装好面板,一键…...
-- response对象 -- 向页面响应数据)
HTTP(九)-- response对象 -- 向页面响应数据
目录 1. 服务器输出字符数据到浏览器 1.1 获取字符输出流 1.2 实例演示:...

音视频windows安装ffmpeg6.0并使用vs调试源码笔记
建立在上一步,vs已经能够正常调试qt项目,可以实现: 1:qt可以使用mvsc (使用cdb)进行调试。 2:vs已经可以加载qt项目,借助vs进行调试。 本文目标:编译ffmpeg库…...

Midjourney|文心一格prompt教程[进阶篇]:Midjourney Prompt 高级参数、各版本差异、官方提供常见问题
Midjourney|文心一格prompt教程[进阶篇]:Midjourney Prompt 高级参数、各版本差异、官方提供常见问题 1.Midjourney Prompt 高级参数 Quality 图片质量是另一个我比较常用的属性,首先需要注意这个参数并不影响分辨率,并不改变分辨率&#x…...
?)
什么是Java虚拟机(JVM)?
Java虚拟机(Java Virtual Machine,JVM)是Java平台的关键组成部分之一。它是一种虚拟的计算机,可以在计算机上运行Java字节码(即编译后的Java程序)。 JVM具有以下主要功能: 字节码执行ÿ…...

【HISI IC萌新虚拟项目】Package Process Unit模块整体方案·PART3
5. 模块方案说明 5.1CRG 模块方案说明 5.1.1简介 CRG 模块实现复位信号的滤抖功能,可滤除小于100ns的低电平复位毛刺,并对复位信号进行同步化处理。同时,对100MHz的输入时钟信号进行2分频,作为 CPU_IF模块和TEST_CORE模块的工作时钟。 5.1.2接口信号 信号位宽I/O描述...
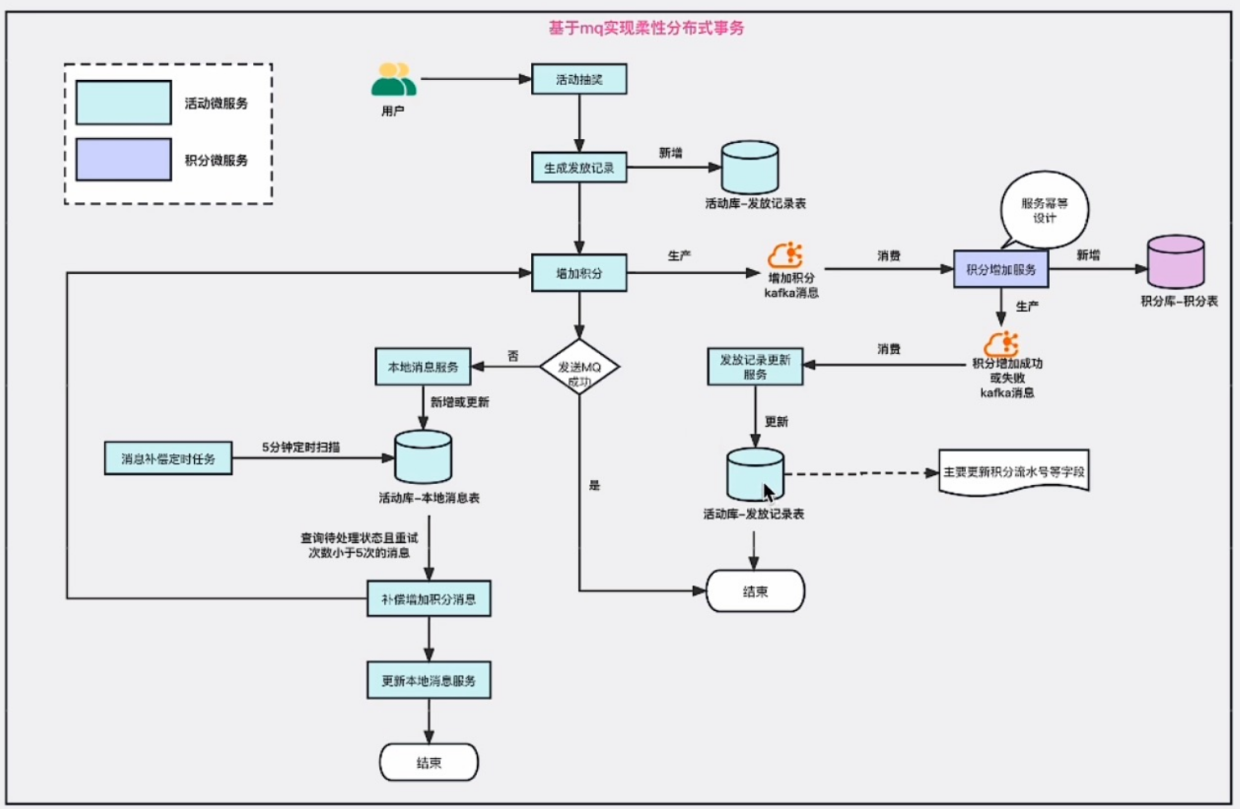
分布式事务常见解决方案
分布式事务常见解决方案 一、事务介绍 事务是一系列的动作,它们综合在一起才是一个完的工作单元,这些动作必须全部完成,如果有一个失败的话,那么事务就会回滚到最开始的状态,仿佛什么都没发生过一样。 1、单事务概念…...
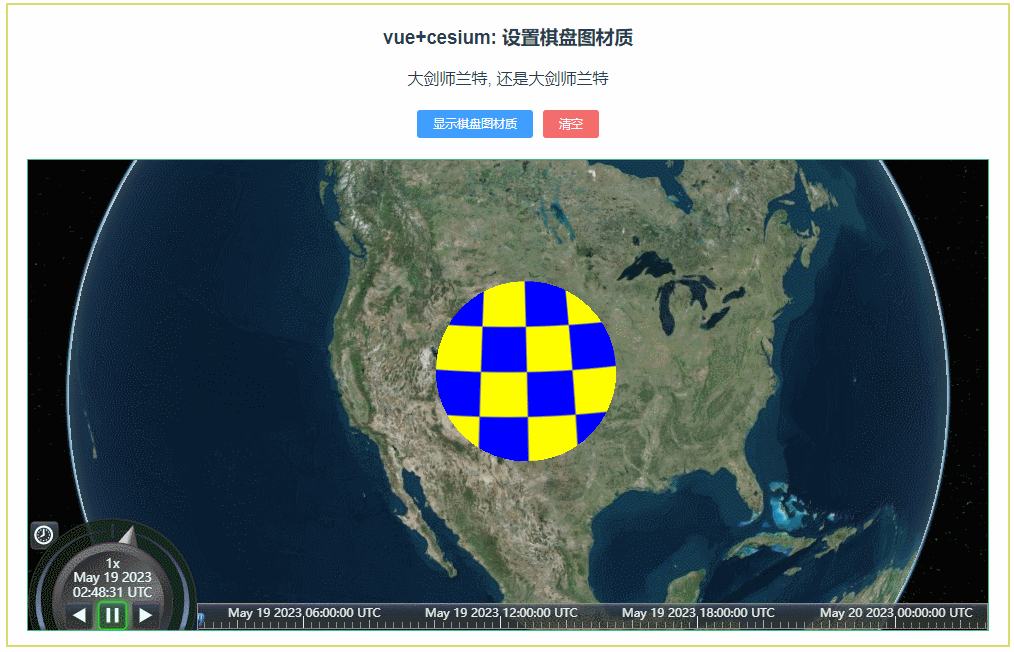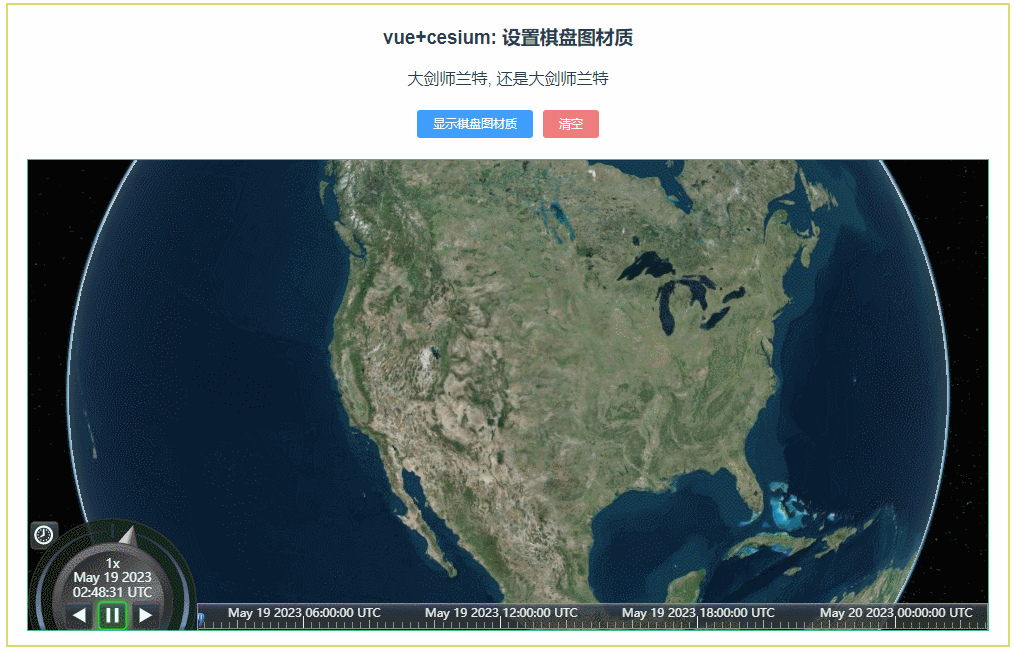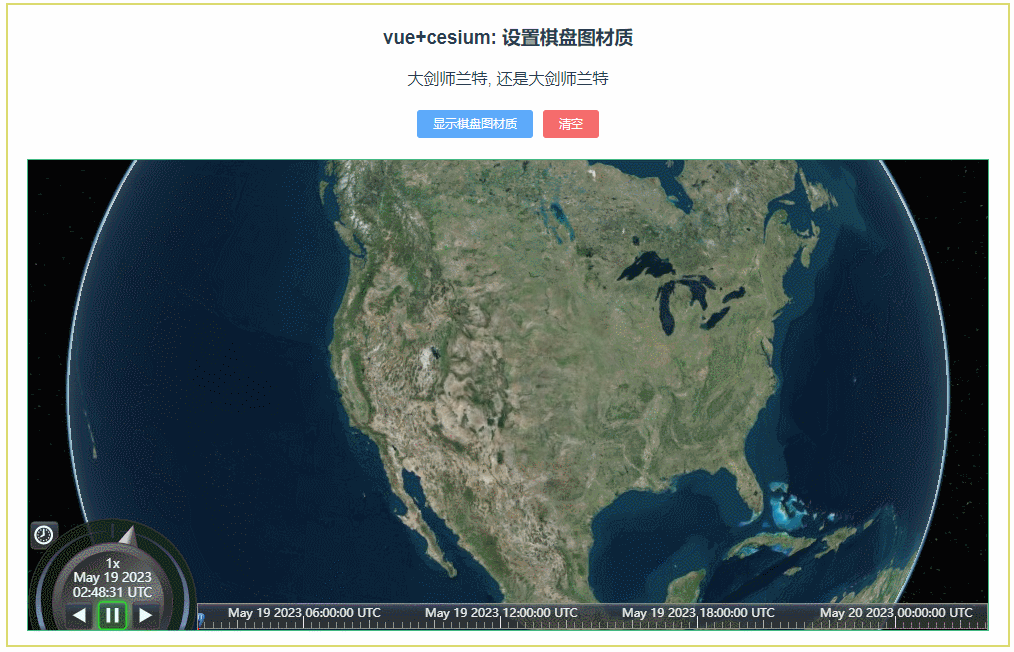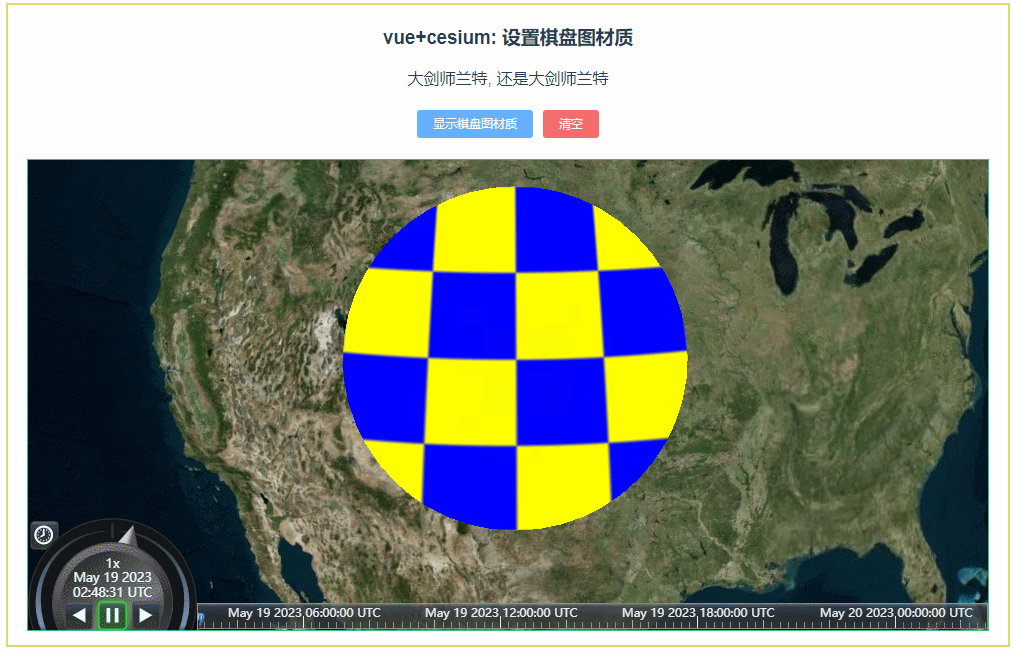
061:cesium设置棋盘图材质(material-5)
第061个 点击查看专栏目录 本示例的目的是介绍如何在vue+cesium中设置棋盘材质,请参考源代码,了解CheckerboardMaterialProperty的应用。 直接复制下面的 vue+cesium源代码,操作2分钟即可运行实现效果. 文章目录 示例效果配置方式示例源代码(共89行)相关API参考:专栏目标…...

【AI Earth试玩】权限配置与openAPI调用工具库
前言 AI earth是阿里达摩院出的遥感云计算平台,我简单体验下来感觉像是GEE的python版本遥感深度学习计算平台,整体体验还是挺不错的,尤其是多分类的结果还是挺惊艳的。 平台提供工具箱和notebook两种模式,工具箱整个交互简单易用…...
Tomcat安装与使用
Tomcat 是HTTP服务器,用于使用HTTP协议。 1、下载Tomcat 下载链接:https://tomcat.apache.org/ 进入官网后,根据自己想要下载的版本进行下载,我这里选择下载的版本是Tomcat 8. 点击选择自己想要下载的对应版本,下载Z…...

大数据课程-学习二十四周总结
6.Hive函数 Hive的函数分为三类: 聚合函数、内置函数,表生成函数,聚合函数之前已经学习过了,接下来学习内置函数和表生成函数. 6.1.Hive的内置函数 6.1.1.数学函数 6.1.1.1. 取整函数: round 语法: round(double a) 返回值: BIG…...
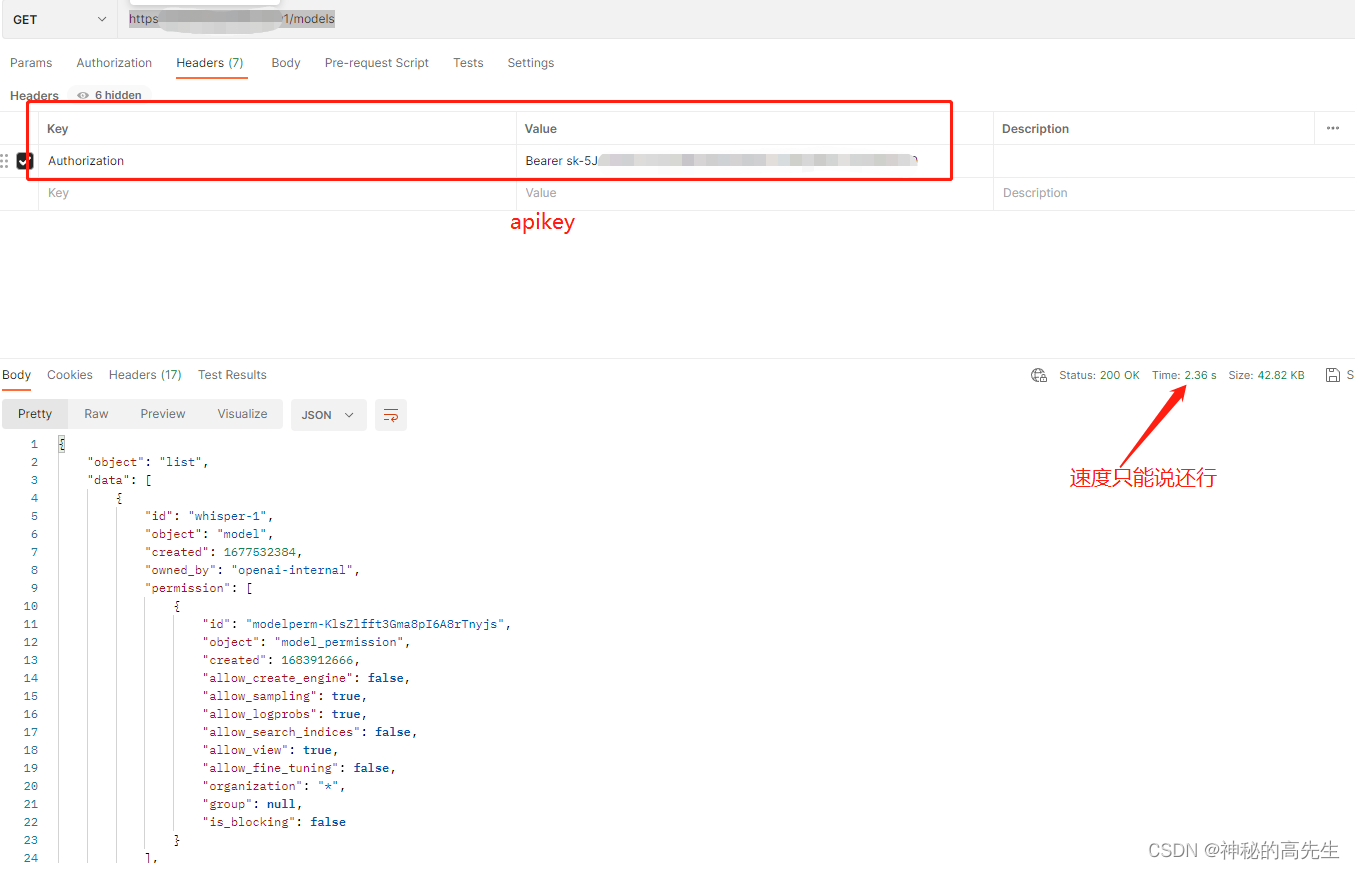
【GPT科技系列】国内开发者调用openAI-API科技方法
1. 前言 openAI上线7个月了,但是随着openAI的约束越来越多,国内开发者想要使用openai的接口实现开发简直就是难上加难。那真的就没有办法了吗?no no no,CF解决一切不开心~ 2.准备工作 我们需要一个国际域名 注册cloudflare账号 …...
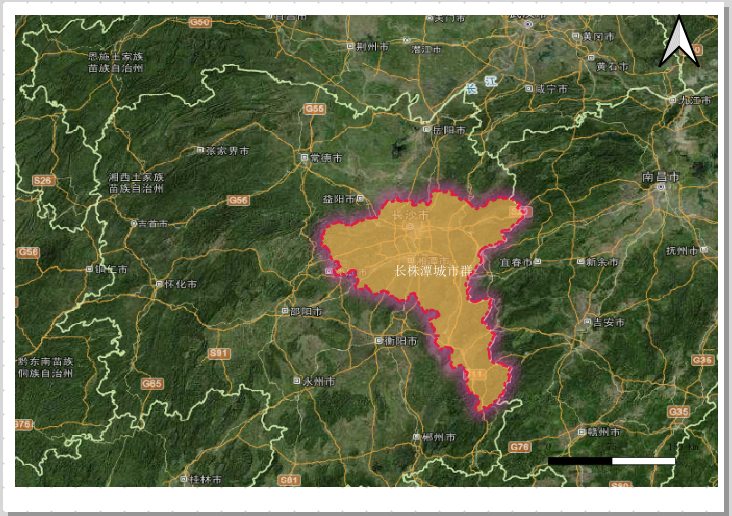
基于QGIS的长株潭城市群边界范围融合实战
背景 在面向区域的研究过程中,比如一些研究区域,如果是具体的行政区划,比如具体的某省或者某市或者县,可以直接从国家官方的地理数据中直接下载就可以。但如果并没有直接的空间数据那怎么办呢?比如之前遇到的一个场景&…...
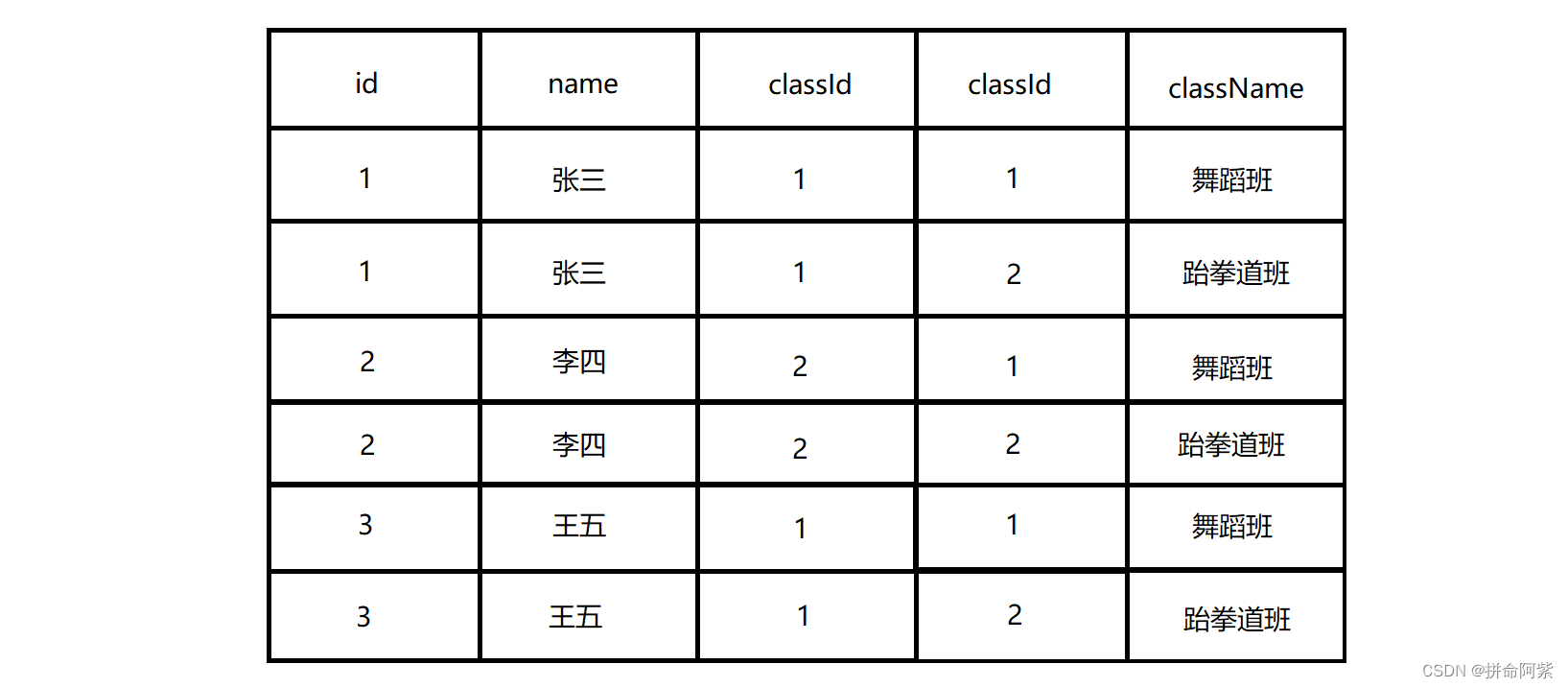
【MySQL联合查询】轻松实现数据关联
1、联合查询 联合查询又称为多表查询,它的基本执行过程就是笛卡尔积 1.1 认识笛卡尔积 那么什么是笛卡尔积呢? 答:笛卡尔积就是将两张表放在一起进行计算,把第一张表的每一行分别取出来和第二张表的每一行进行连接,得到…...

Windows安装Ubuntu双系统
Windows安装Ubuntu双系统 1.下载Ubuntu 16.04,地址https://releases.ubuntu.com/16.04/ 2.下载Rufus,地址https://rufus.ie/zh/ 3.准备U盘,烧录系统 4.磁盘分区 5.重启,按住shift键 本人电脑是联想小新 Windows11系统࿰…...

Gazebo Sim多旋翼控制:四轴飞行器动力学建模与PID调参
Gazebo Sim多旋翼控制:四轴飞行器动力学建模与PID调参 【免费下载链接】gz-sim Open source robotics simulator. The latest version of Gazebo. 项目地址: https://gitcode.com/gh_mirrors/gz/gz-sim Gazebo Sim是一款功能强大的开源机器人模拟器ÿ…...

万星easy-vibe:描述需求即发布 零基础无需学语法
开源Easy-Vibe是一套开源AI编程学习方案,把学习顺序从先学语法再做项目翻转为直接做项目。文章拆解了项目驱动、提示词编写、AI编辑器和多Agent协作的完整流程,解释了为什么想法比语法更重要。 github上datawhalechina/easy-vibe:它在GitHub…...

Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式 对于技术管理者或项目负责人而言,清晰了解团队的AI…...

Unity Spine换装系统:骨骼映射与Skin动态管理实战
1. 为什么Spine换装不能只靠“替换贴图”——一个被低估的骨骼绑定难题 在Unity里做Spine换装,很多人第一反应是:把新衣服的Atlas和SkeletonData拖进去,用 SkeletonRenderer 的 skeletonDataAsset 字段一换,完事。我去年接手一…...

如何免费解锁AMD Ryzen处理器隐藏性能?SMUDebugTool完整使用指南
如何免费解锁AMD Ryzen处理器隐藏性能?SMUDebugTool完整使用指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: …...
的三维量化体系)
别再用BLEU和ROUGE了!2024最前沿的DeepSeek评估范式:基于认知对齐度(CA-Score)的三维量化体系
更多请点击: https://intelliparadigm.com 第一章:别再用BLEU和ROUGE了!2024最前沿的DeepSeek评估范式:基于认知对齐度(CA-Score)的三维量化体系 传统自动评估指标如BLEU、ROUGE长期受限于n-gram表面匹配&…...

荣耀出征离线挂机深度攻略:吃透隐性机制,告别无效挂机碾压同级
作为混迹游戏圈二十余年、从街机厅搓摇杆到网吧通宵刷端游,日均稳坐游戏6小时以上的老玩家,实测过无数网游的挂机体系。《荣耀出征》的离线挂机看似门槛极低、操作简单,但全网九成攻略都只停留在“开自动、挂地图”的基础层面,完全…...

IwaraDownloadTool:3种突破性技术实现的专业级Iwara视频批量下载方案
IwaraDownloadTool:3种突破性技术实现的专业级Iwara视频批量下载方案 【免费下载链接】IwaraDownloadTool Iwara 下载工具 | Iwara Downloader 项目地址: https://gitcode.com/gh_mirrors/iw/IwaraDownloadTool 在数字内容创作日益丰富的今天,Iwa…...

茅台自动预约终极指南:告别手动抢购的智能解决方案
茅台自动预约终极指南:告别手动抢购的智能解决方案 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://git…...

告别瞎猜!用DBSCAN和K-means搞定毫米波雷达点云聚类,附完整Matlab代码与数据集
毫米波雷达点云聚类实战:DBSCAN与K-means算法深度对比与Matlab实现在自动驾驶和智能感知领域,毫米波雷达因其全天候工作能力和稳定的性能表现,成为环境感知系统中不可或缺的传感器。然而,原始雷达点云数据往往呈现出稀疏、噪声多且…...