SpringBoot开发实用篇2---与数据层技术有关的替换和整合
四、数据层解决方案
1.SQL
现有数据层解决方案技术选型:Druid+MyBatis-plus+MySQL
数据源:DruidDataSource
持久化技术:MyBatis-plus/MyBatis
数据库:MySql
内置数据源:
SpringBoot提供了3种内嵌的数据源对象供开发者选择:
HikariCP:默认内置数据源对象;
Tomcat提供DataSource:HikariCP不可用的情况下,且在web环境中,将使用tomcat服务器配置的数据源对象;
Commons DBCP:Hikari不可用,tomcat数据源也不可用,将使用dbcp数据源。
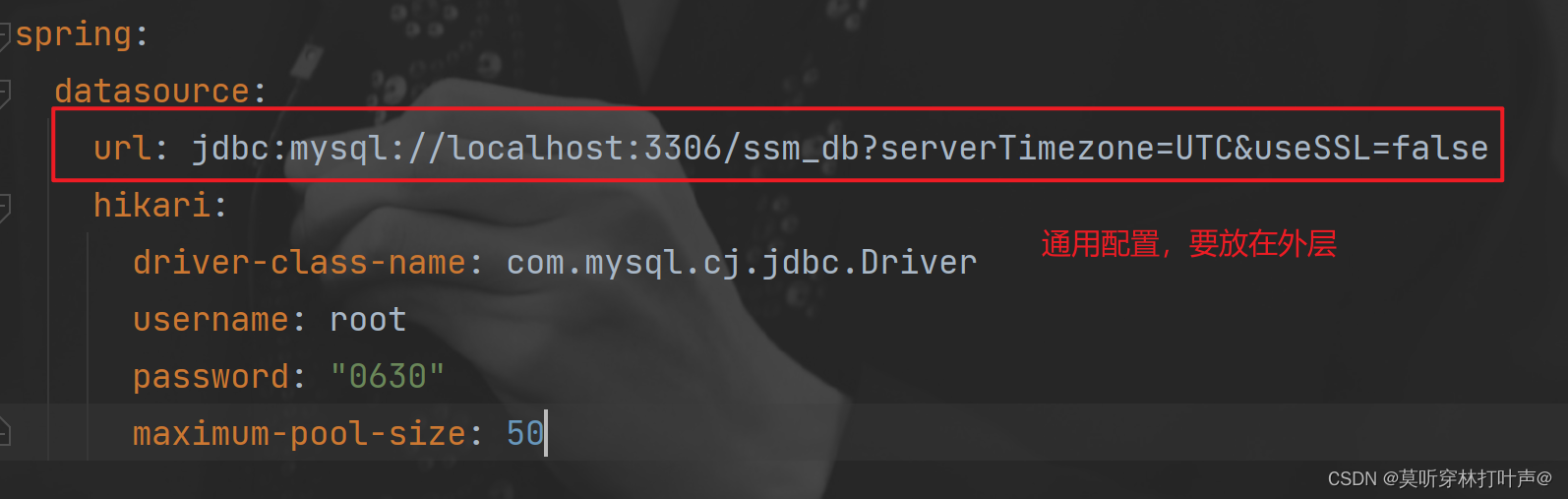
使用方式:先使用默认配置,再使用个性化配置。
通用配置无法设置具体的数据源配置信息,仅提供基本的连接相关配置,如需配置,在下一级配置中设置具体设定。
JdbcTemplate:Spring提供的默认的持久化技术(几乎没人用)
操作数据库的模板技术。
pom.xml:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
@Autowiredprivate JdbcTemplate jdbcTemplate;@Testvoid testJdbcTemplate(){String sql="select * from tbl_book";RowMapper<Book> rm=new RowMapper<Book>() {@Overridepublic Book mapRow(ResultSet rs, int rowNum) throws SQLException {Book temp=new Book();//查出来的放到结果集中,从结果集中得到,在set到对象中temp.setId(rs.getInt("id"));temp.setName(rs.getString("name"));temp.setType(rs.getString("type"));temp.setDescription(rs.getString("description"));return temp;}};List<Book> list = jdbcTemplate.query(sql, rm);System.out.println(list);}@Testvoid testJdbcTemplateSave(){String sql="insert into tbl_book values(null,'springboot','springboot','springboot')";jdbcTemplate.update(sql);}H2数据库:
SpringBoot提供了3种内嵌数据库供开发者选择,提高开发测试效率:
H2
HSQL
Derby
伴随着内存启动而启动的数据库,比较小巧。
pom.xml中:
<!--演示H2数据库--><dependency><groupId>com.h2database</groupId><artifactId>h2</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency>
配置文件中:
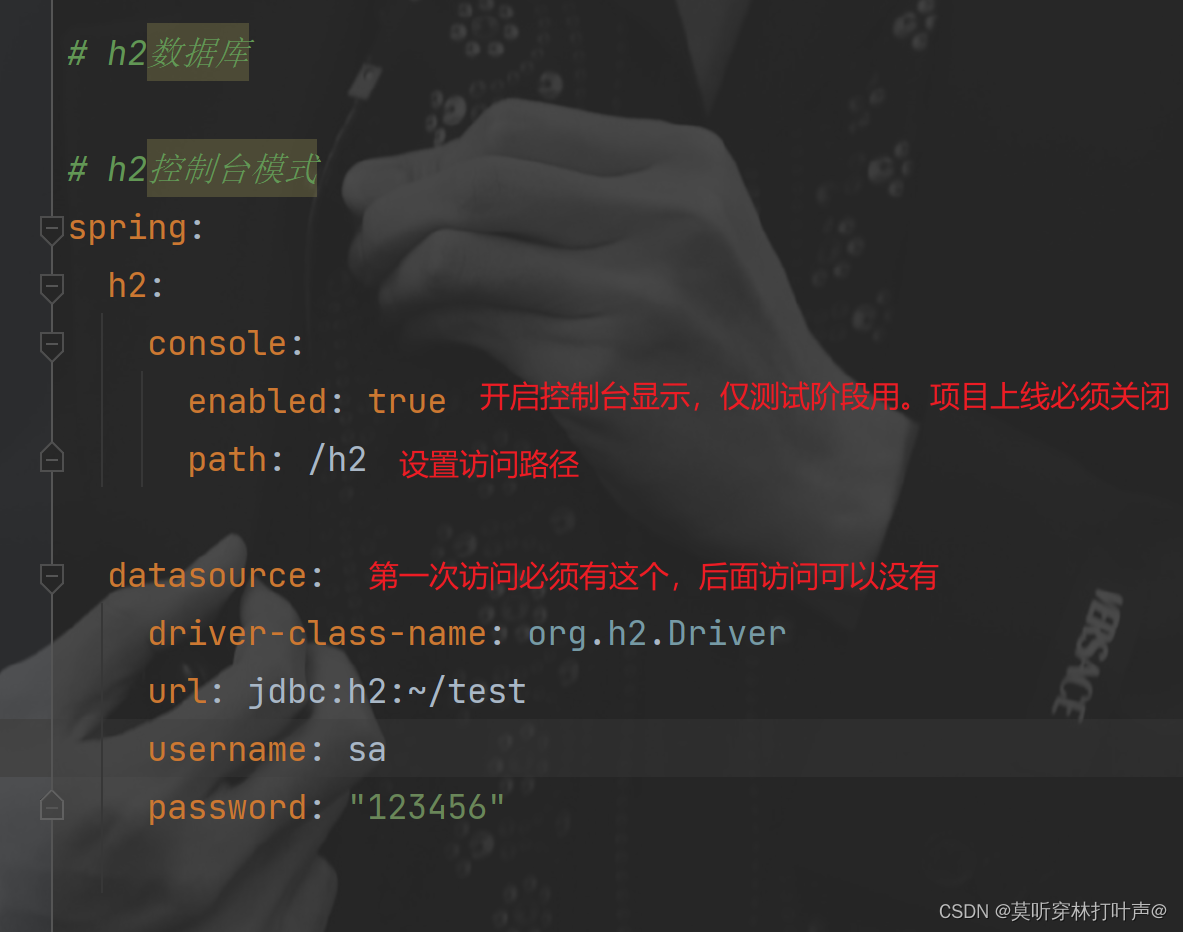
开启服务后,在浏览器中就可以访问:
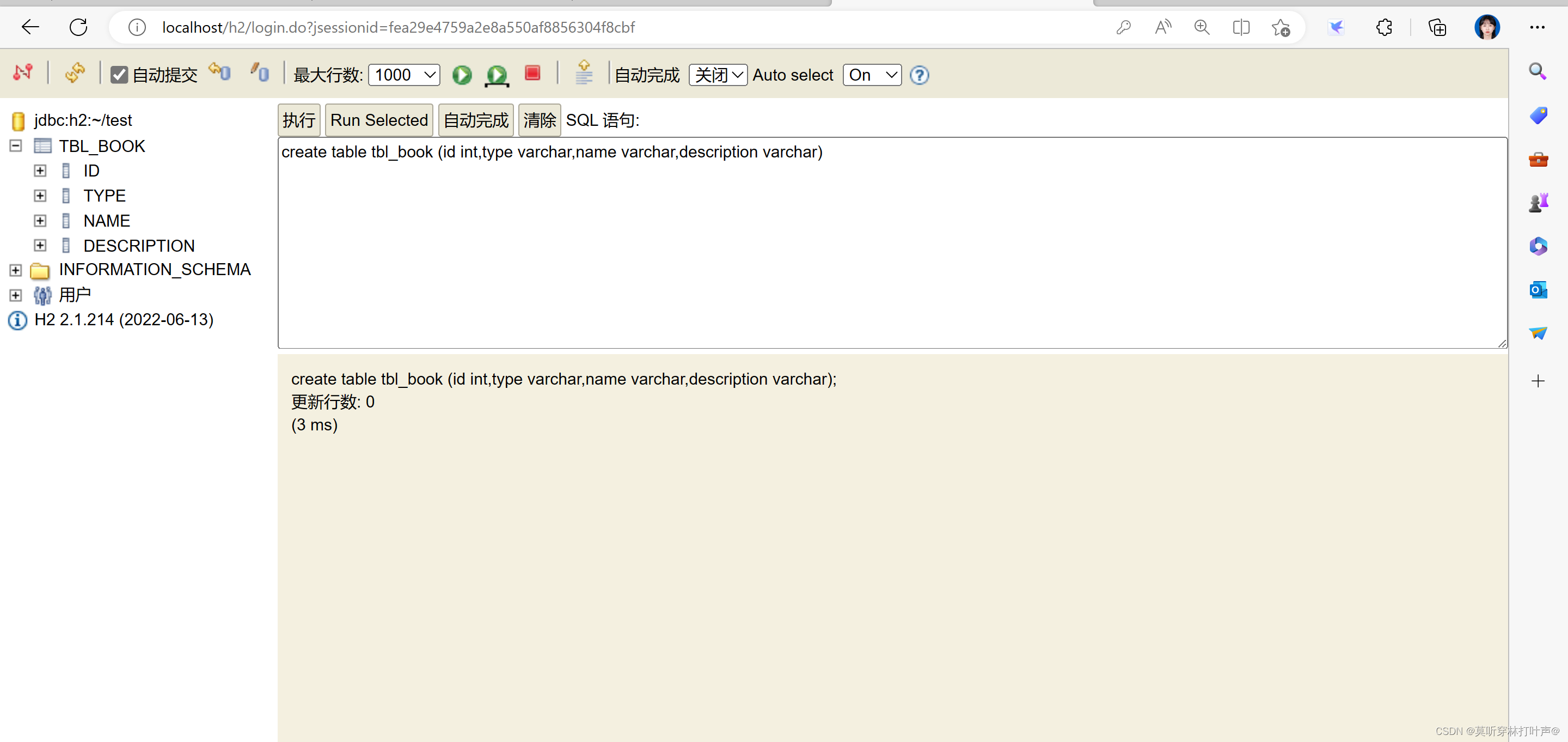
可以和持久层框架Mybatis-plus、JdbcTemplate搭配使用。
2.NoSQL
(1)Redis
市面上常见的NoSQL解决方案:
Redis
MongoDB
ES
上述技术通常在Linux系统中安装部署。
在Windows安装,方便整合(整合都是一样的)。
Redis是一款key-value存储结构的内存级NoSQL数据库:
支持多种数据存储格式
支持持久化
支持集群
Redis的安装与启动(Windows版)
Windows解压安装或一键式安装
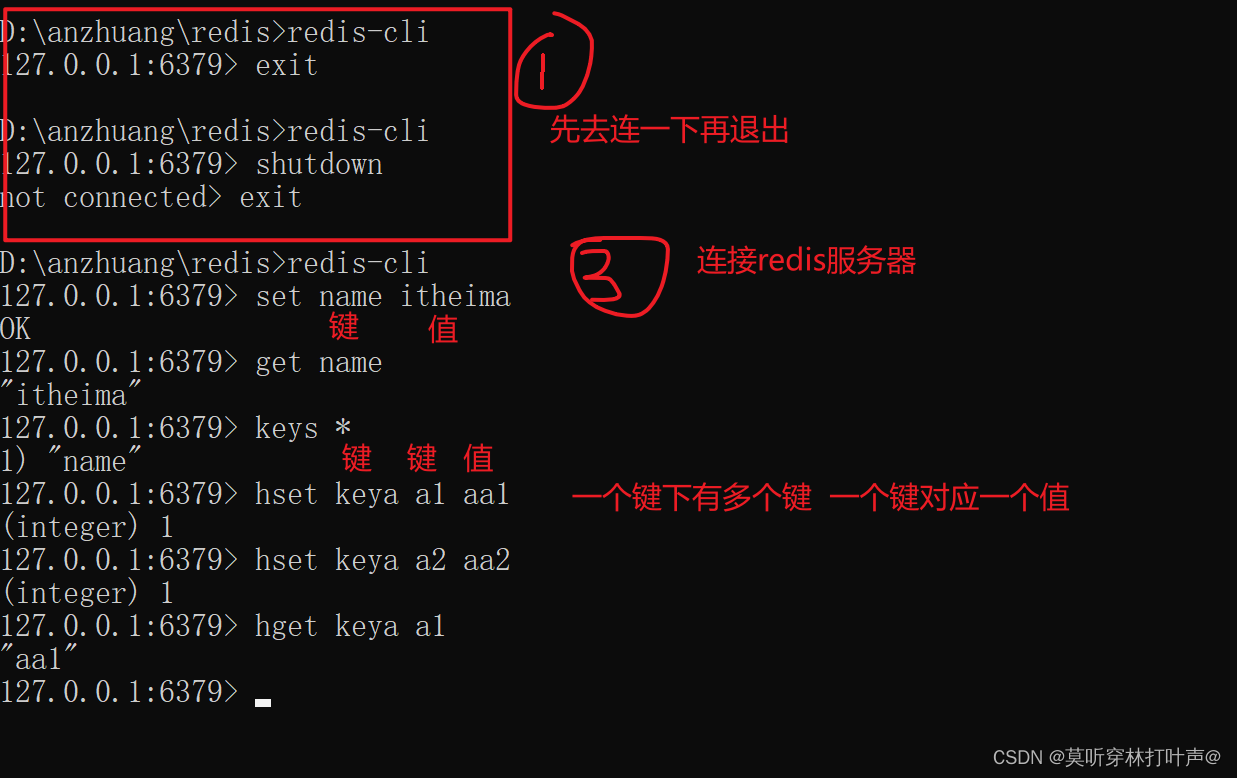
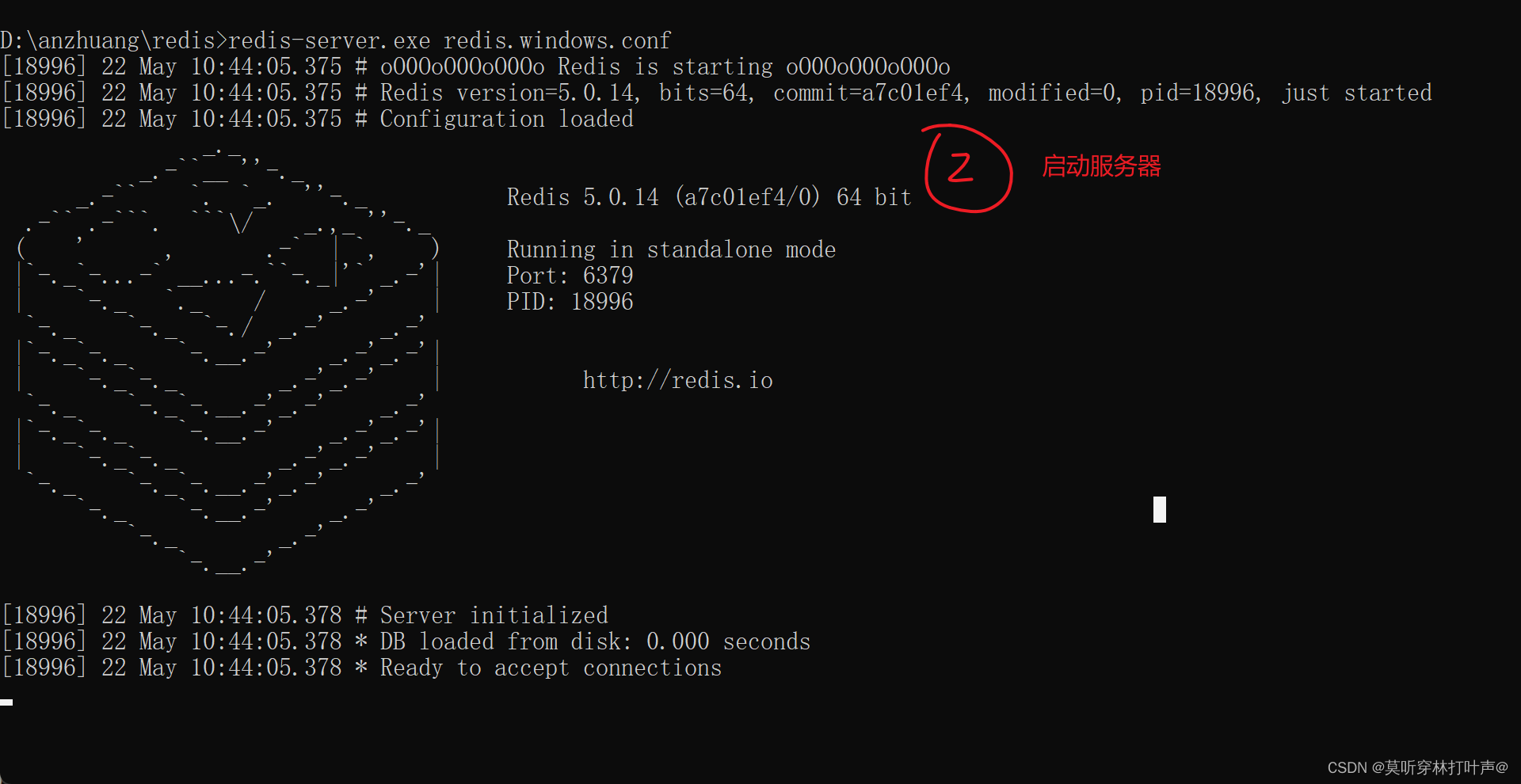
服务端启动命令
redis-server.exe redis.windows.conf
客户端启动命令
redis-cli.exe
具体操作:先打开服务器,再用客户端去连接。
SpringBoot整合Redis:
导入redis对应的starter,在创建工程的时候勾选。
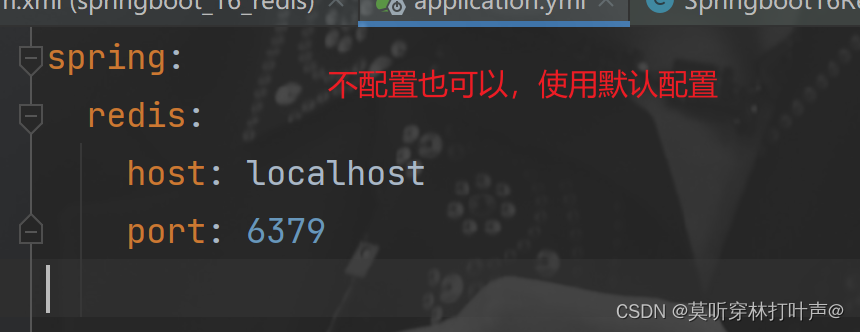
配置Redis(采用默认配置)
提供操作Redis接口对象RedisTemplate:
@SpringBootTest
class Springboot16RedisApplicationTests {@Resourceprivate RedisTemplate redisTemplate;@Testvoid set() {ValueOperations ops = redisTemplate.opsForValue();ops.set("age",41);}@Testvoid get(){ValueOperations ops = redisTemplate.opsForValue();Object age = ops.get("age");System.out.println(age);}@Testvoid hset() {HashOperations ops = redisTemplate.opsForHash();ops.put("info","a","aa");}@Testvoid hget(){HashOperations ops = redisTemplate.opsForHash();Object val = ops.get("info", "a");System.out.println(val);}
}客户端:RedisTemplate以对象作为key和value,内部对数据进行序列化。
StringRedisTemplate以字符串作为key和value,与Redis客户端操作等效。
@SpringBootTest
public class StringRedisTemplateTest {@Autowiredprivate StringRedisTemplate stringRedisTemplate;@Testvoid get(){ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();String name = ops.get("name");System.out.println(name);}
}
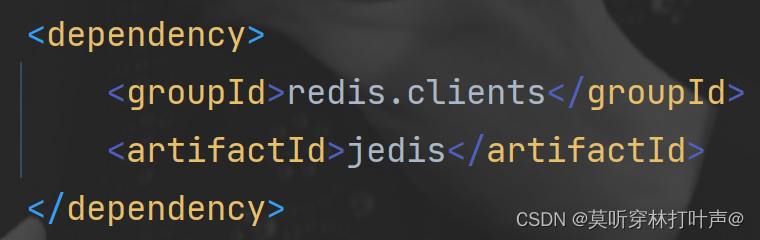
客户端使用jedis,加坐标,改配置文件。
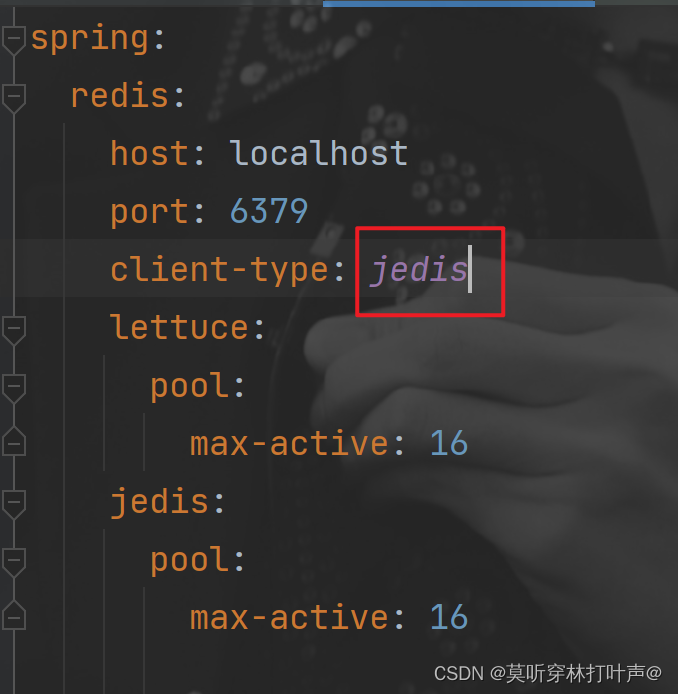
lettcus和jedis的区别:
jedis连接Redis服务器是直连模式,当多线程模式下使用jedis会存在线程安全问题,解决方案可以通过配置连接池使每个连接专用,这样整体性能就会大受影响。
lettcus基于Netty框架进行与Redis服务器连接,底层设计中采用StatefulRedisConnection。StatefulRedisConnection自身是线程安全的,可以保障并发访问安全问题,所以一个连接可以被多线程复用。当然lettcus也支持多连接实例一起工作。
(2)MongoDB
需求:既能存储结构化数据,又高性能。数据有着很高的修改需求
MongoDB是一个开源、高性能、无模式的文档型数据库。NoSQL数据库产品的一种,是最像关系型数据库的非关系型数据库。
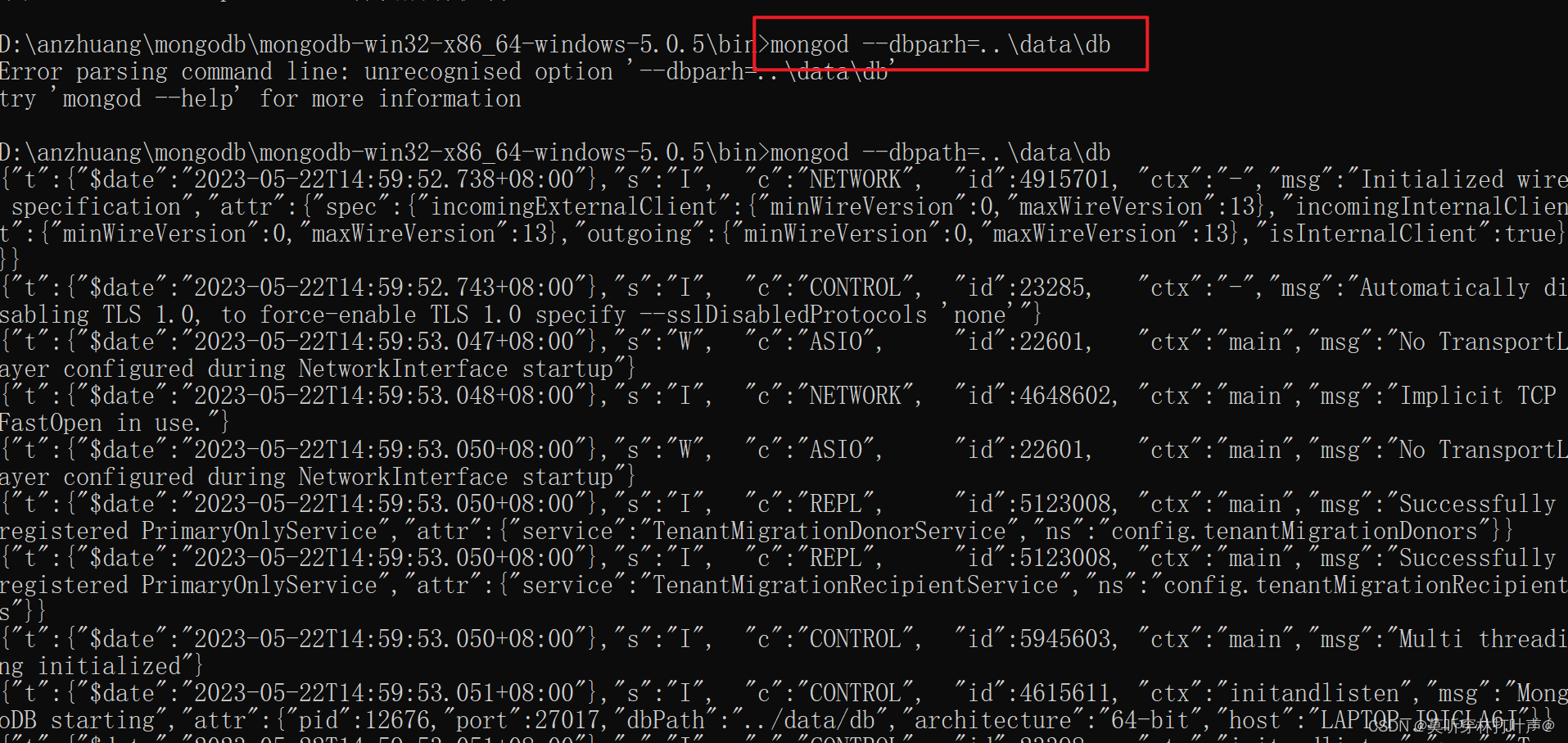
启动mongoDB服务:
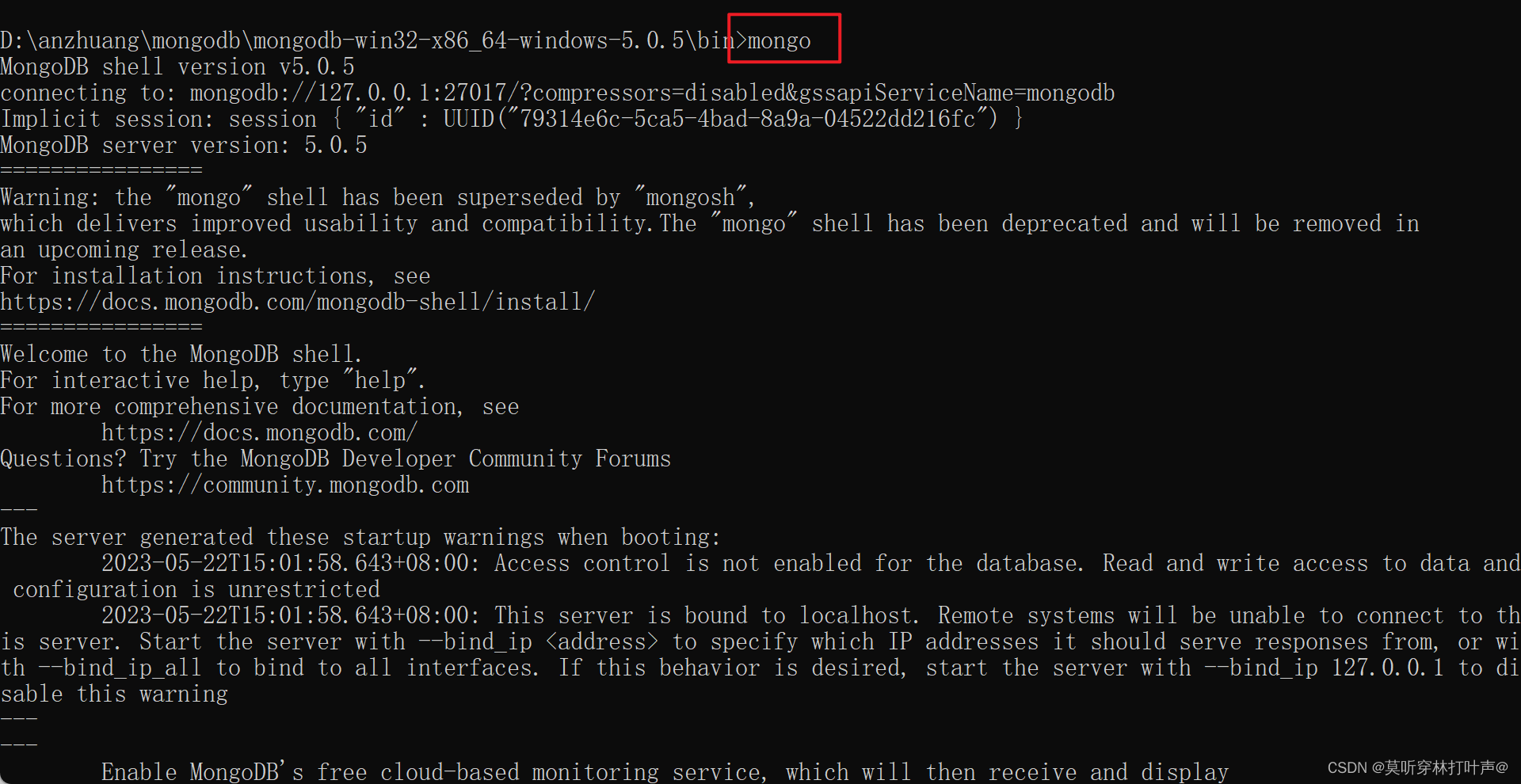
在客户端连接MongoDB服务:
mongo --host=127.0.0.1 --port=27017
或者使用可视化客户端:
基础CRUD操作:
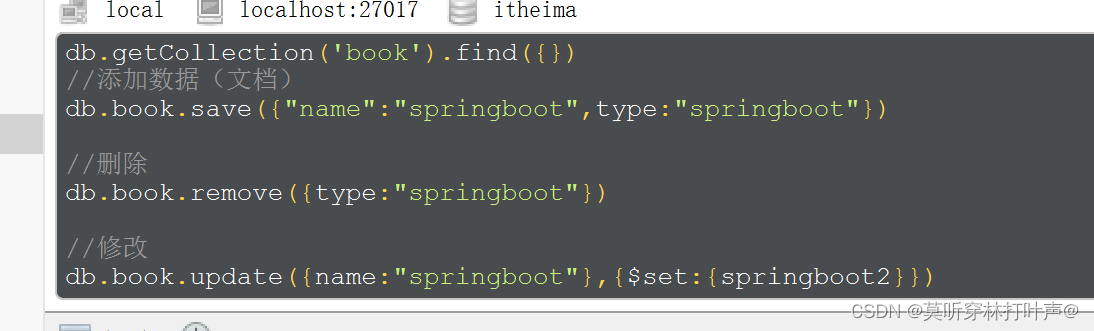

SpringBoot整合MongoDB:
1.导入Mongodb对应的starter:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
2.配置mongodb访问uri:
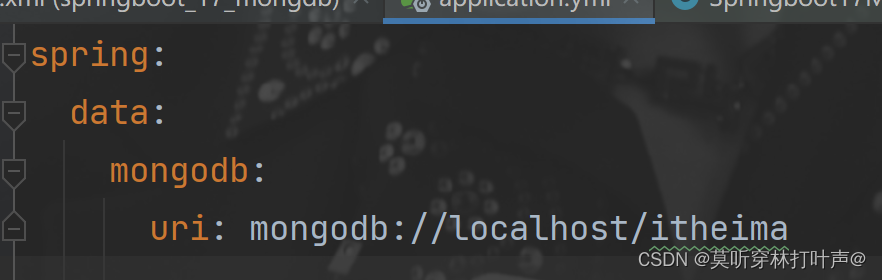
3.提供操作Mongodb接口对象MongoTemplate
@SpringBootTest
class Springboot17MongdbApplicationTests {@Autowiredprivate MongoTemplate mongoTemplate;@Testvoid contextLoads() {Book book=new Book();book.setId(1);book.setName("springboot");book.setType("springboot");book.setDescription("springboot");mongoTemplate.save(book);}/*** 类型转换的问题 把数据库中不是int的删了*/@Testvoid find(){List<Book> all = mongoTemplate.findAll(Book.class);System.out.println(all);}}(3)ES Elasticsearch
相关概念:
Elasticsearch是一个分布式全文搜索引擎。(分布式:架构可以做成分布式的)
要想做全文搜索:
1.通过所提供的数据进行分词,将关联数据保存起来。就有了一个一个的id对应一个一个的简要数据。
2.分词查出来先匹配一个一个的id,id再得到数据。(实际上查询的时候,是将输入这个id的数据展示出来)。
这种方式大幅度的提高了查询速度。
传统的索引:根据id查数据。
ES的索引(倒排索引):根据关键字(数据)查id,再根据id查数据。
一条:关键字—>1—>数据 对应的是一个文档,每一条都需要提前建立起来。当使用关键字后,就能找到对应的数据了。
基础操作:
打开ES服务:双击这个批处理文件:
启动后,可以在浏览器直接创建。
创建/查询/删除索引:
PUT:http://localhost:9200/books
GET:http://localhost:9200/books
DELETE:http://localhost:9200/books
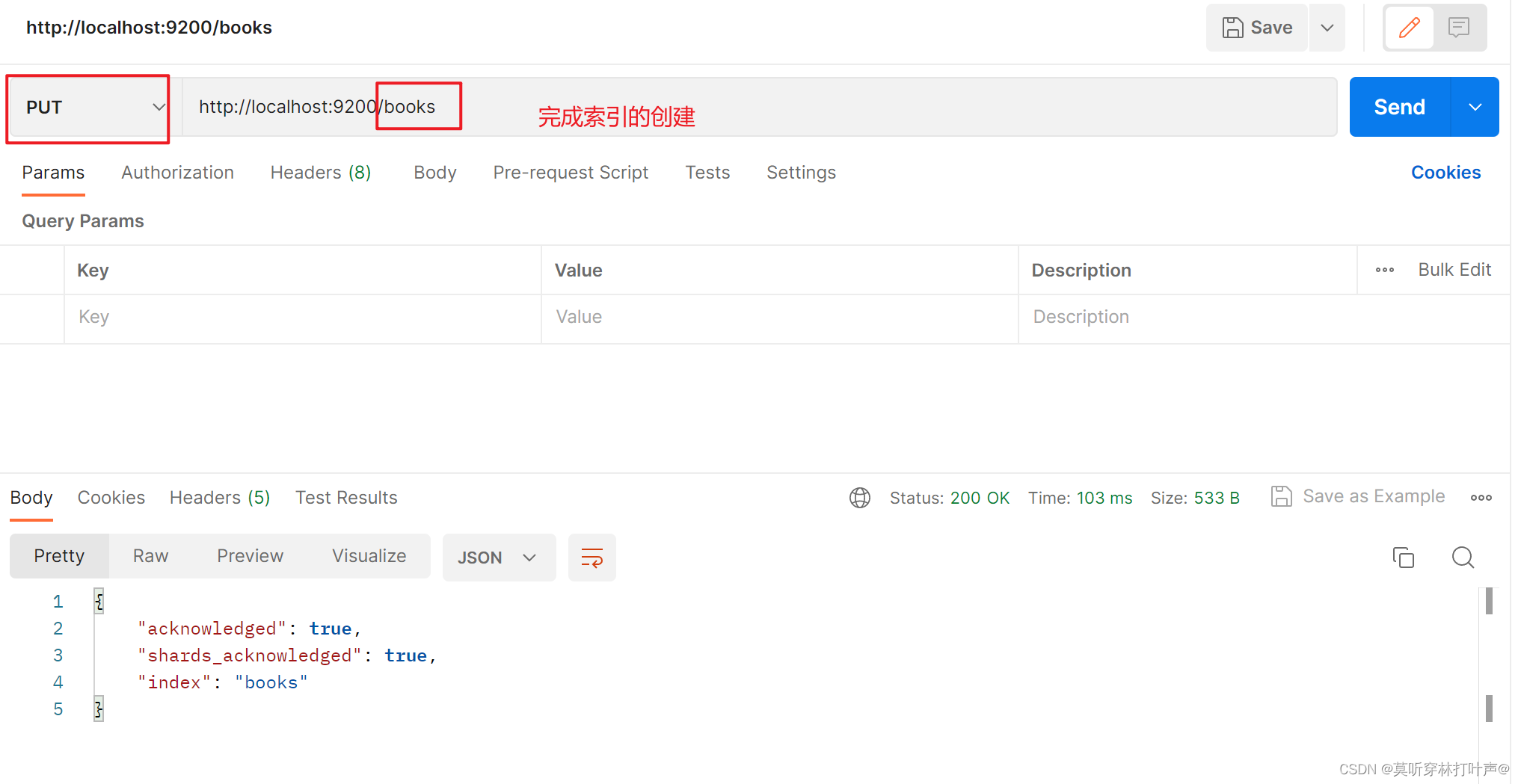
目前创建的这个索引是不支持分词的。要支持分词添加IK插件。再重启服务。
创建一个有分词功能的索引:
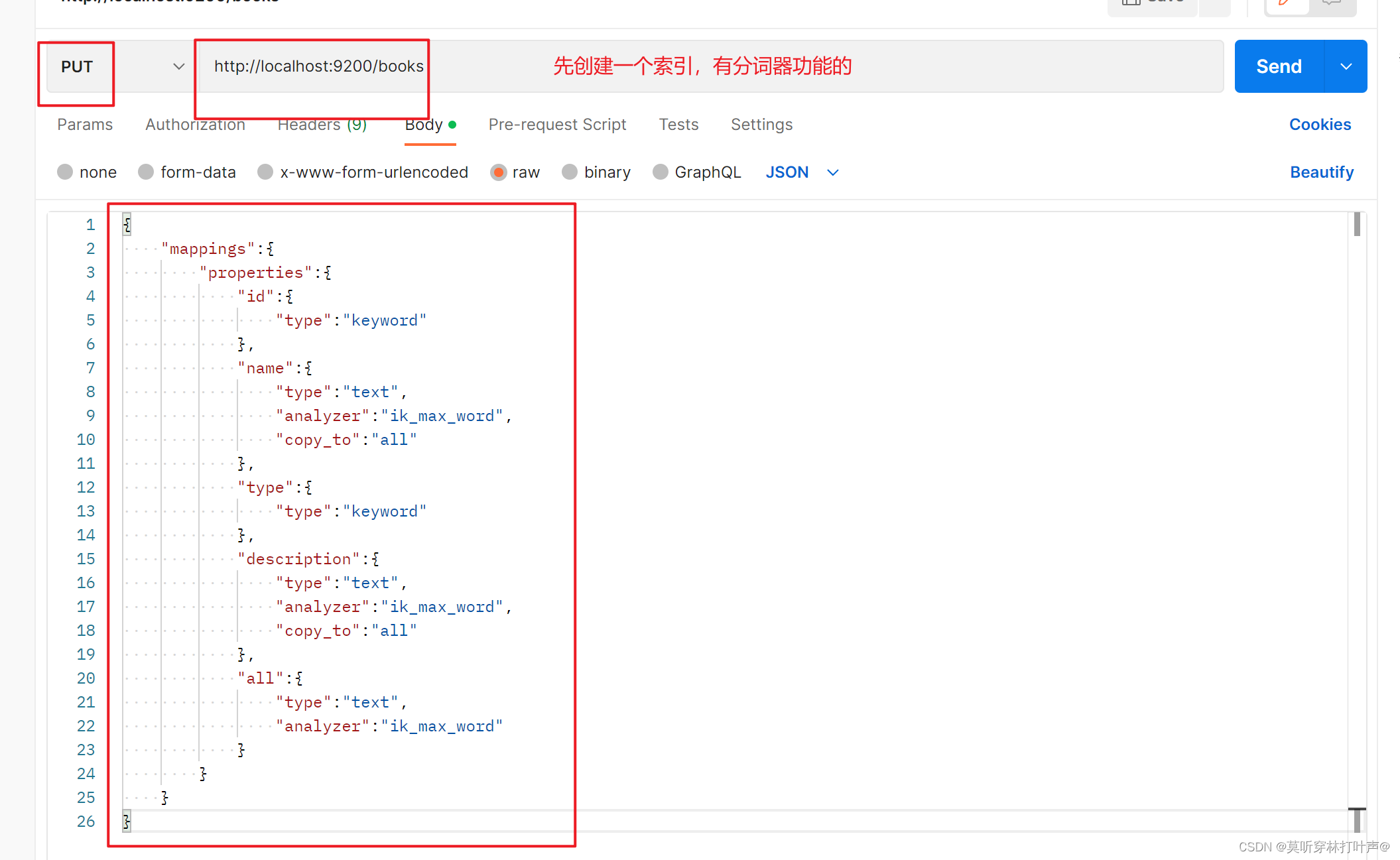
查看这个索引:
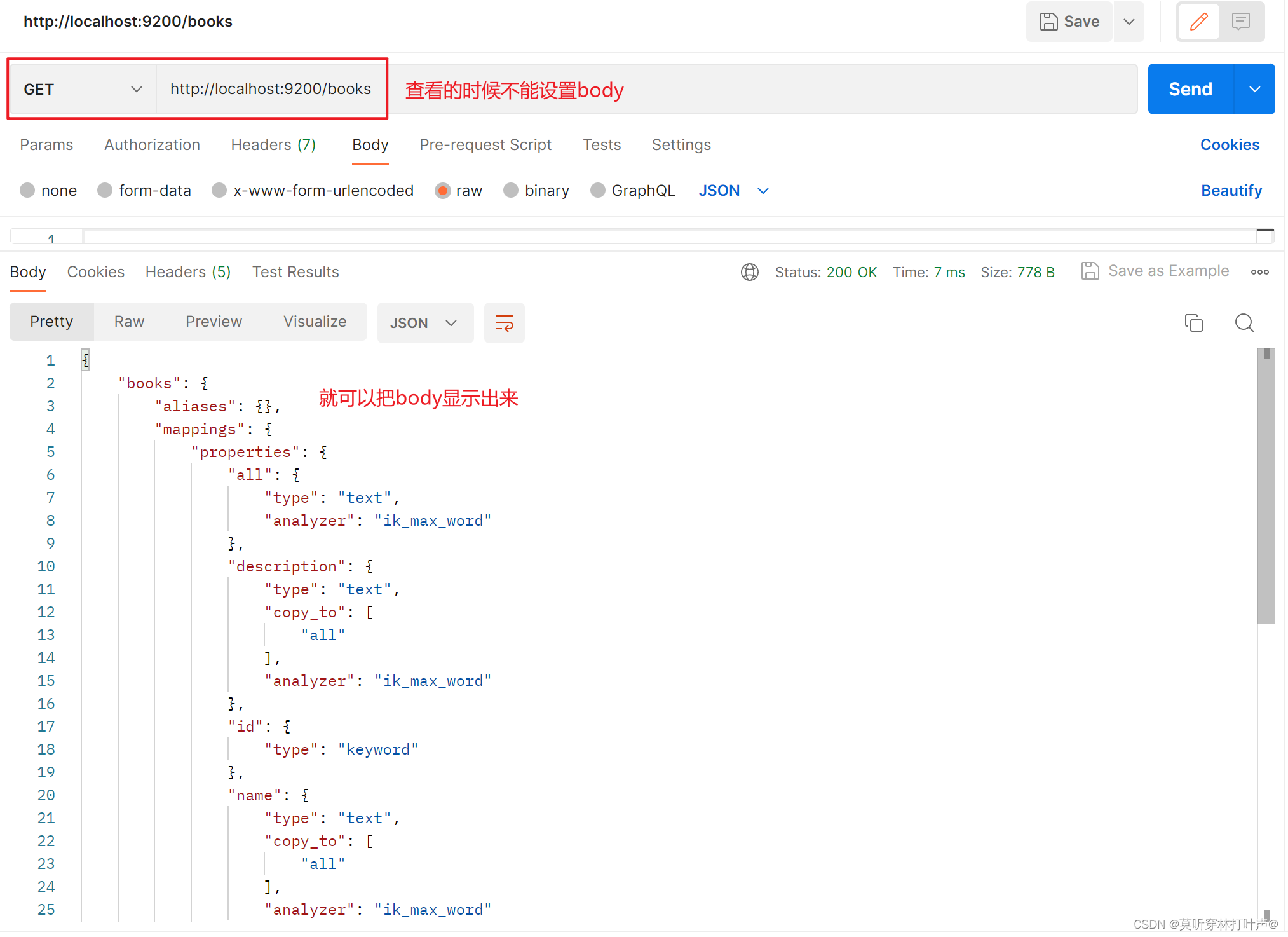
ES文档操作:
添加一条文档,相当于给数据库中添加一条数据,不需要指定表结构。文档结构是无模式的。
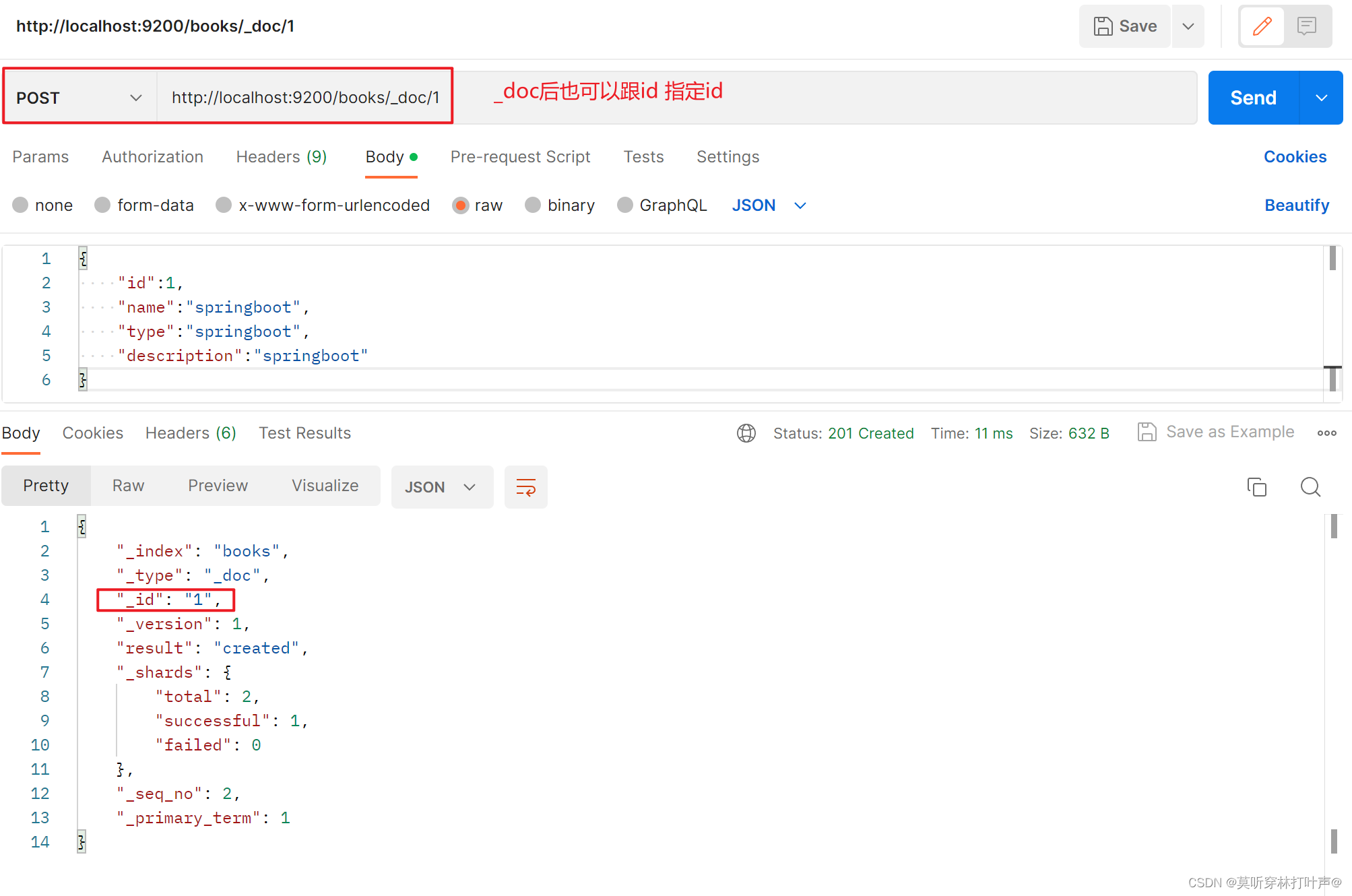
使用_doc添加一个文档信息,id是自动生成的。
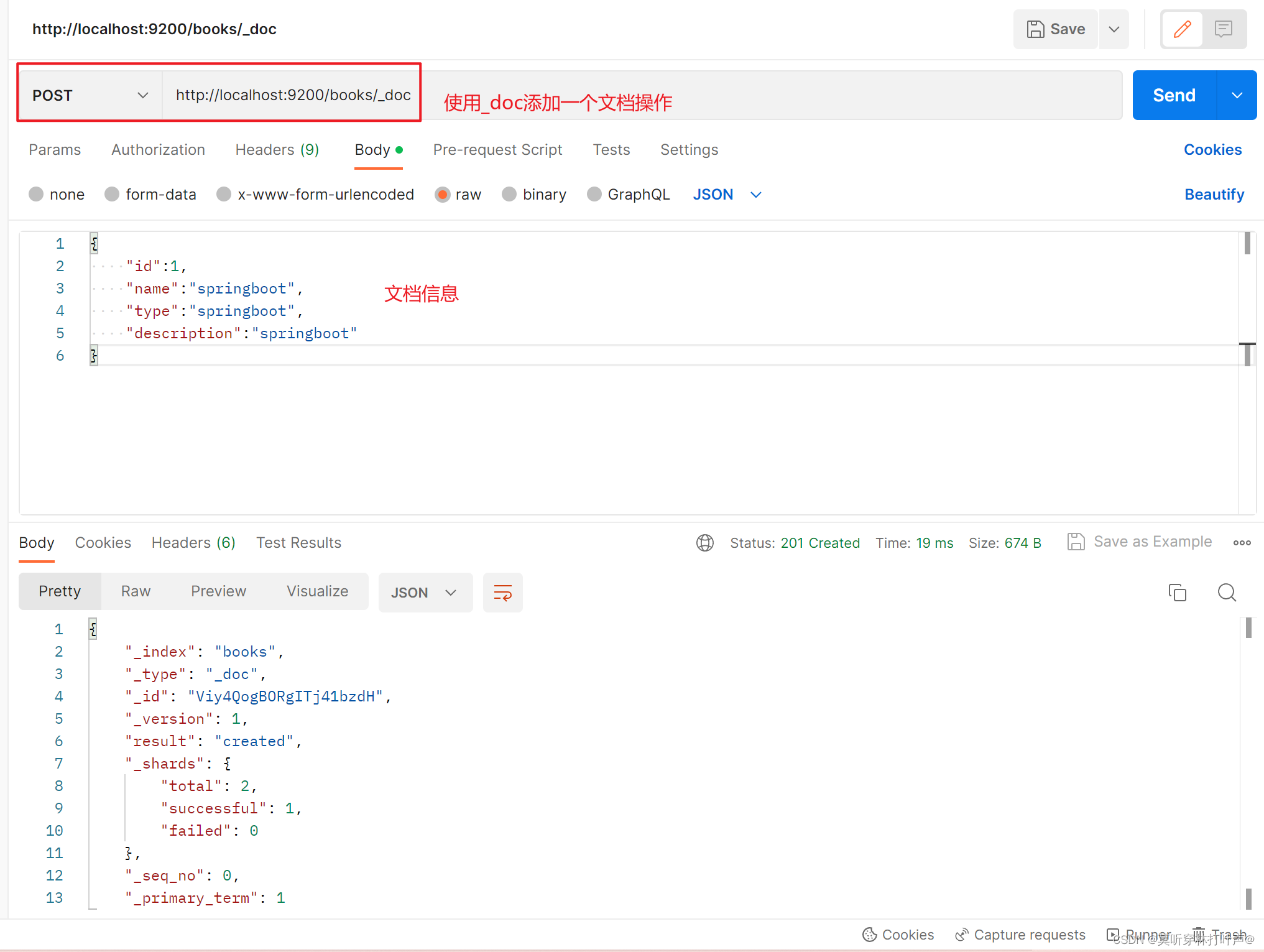
使用_create添加文档信息,后面需要加id号。
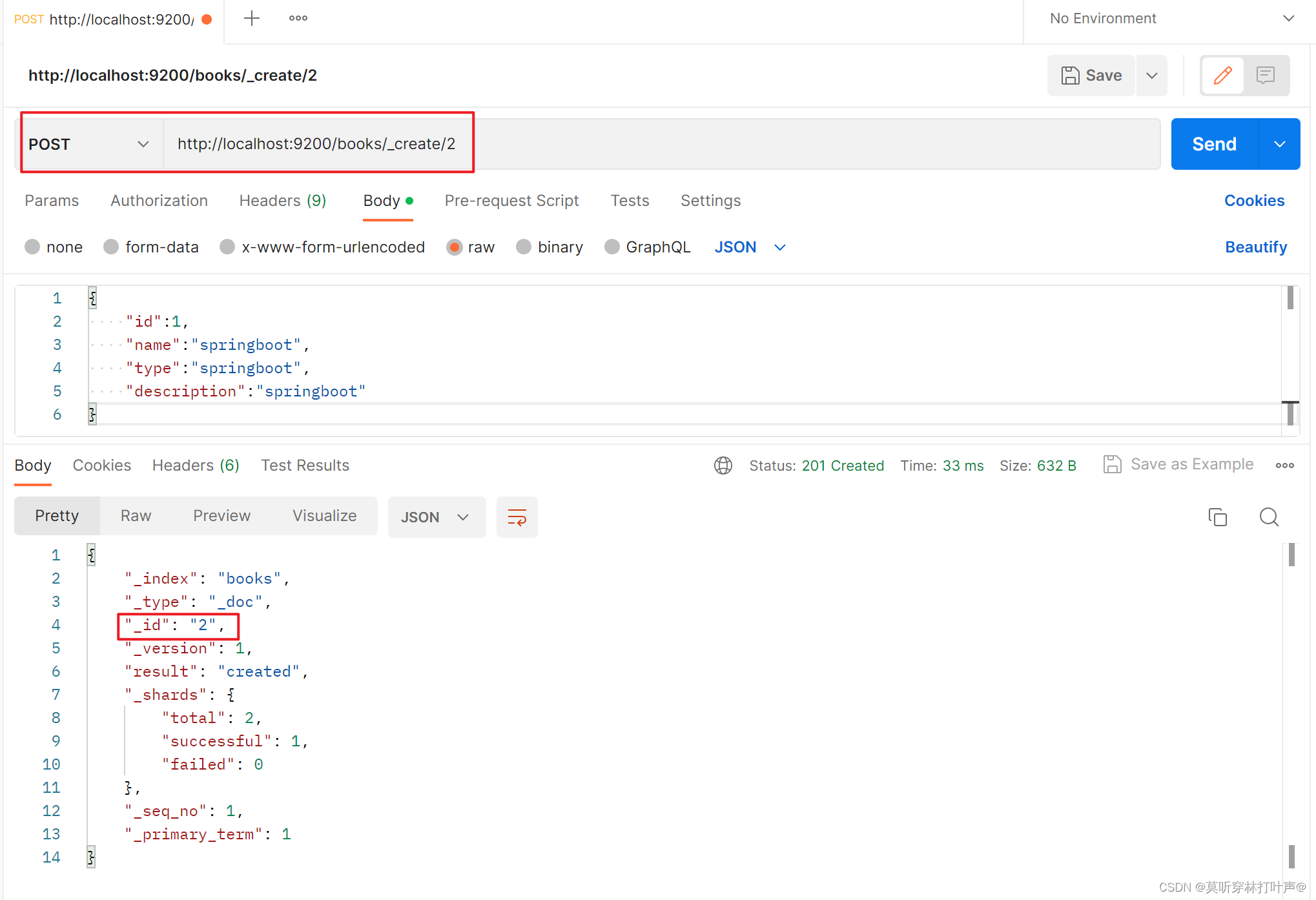
_doc后也可以加id号。
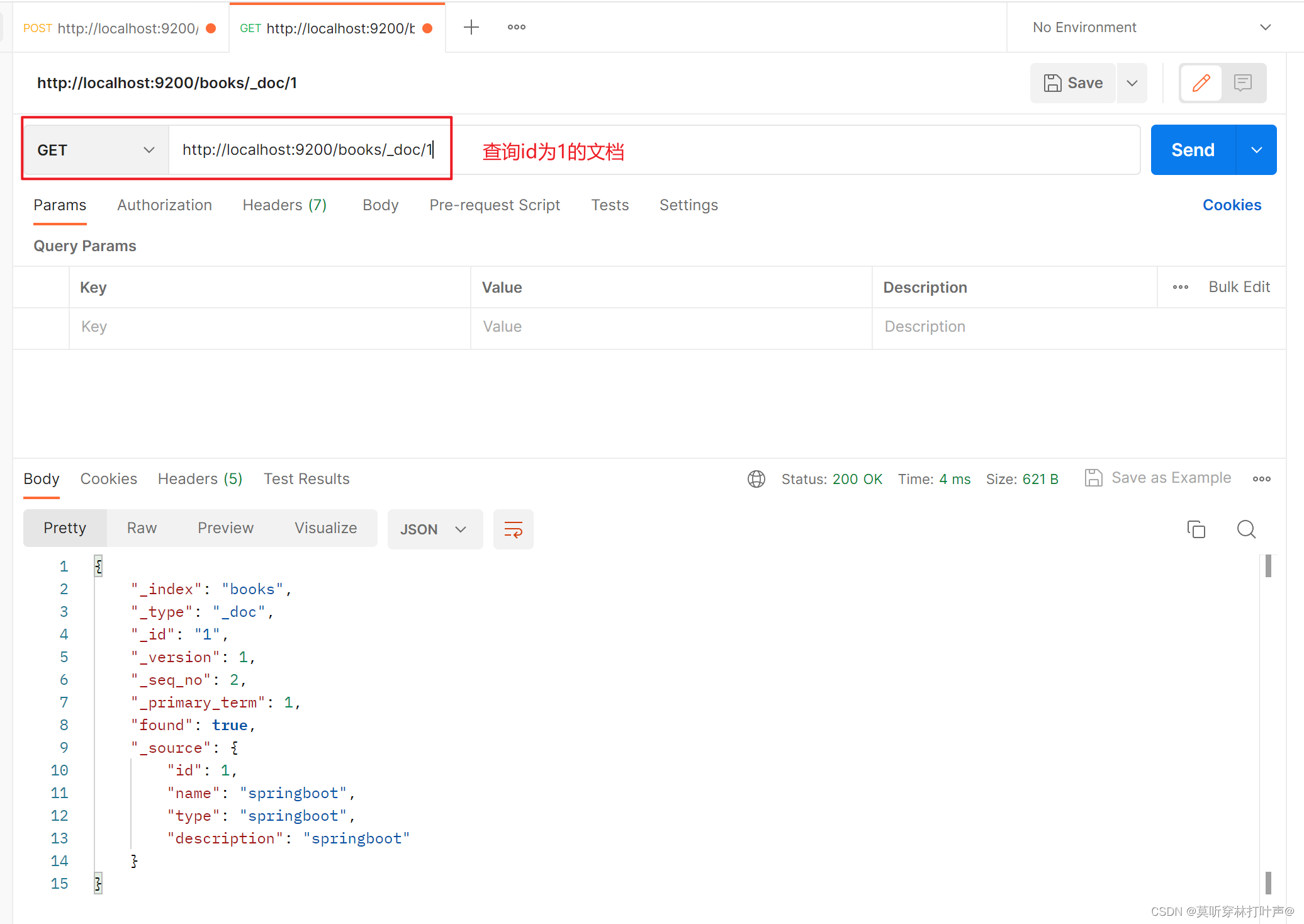
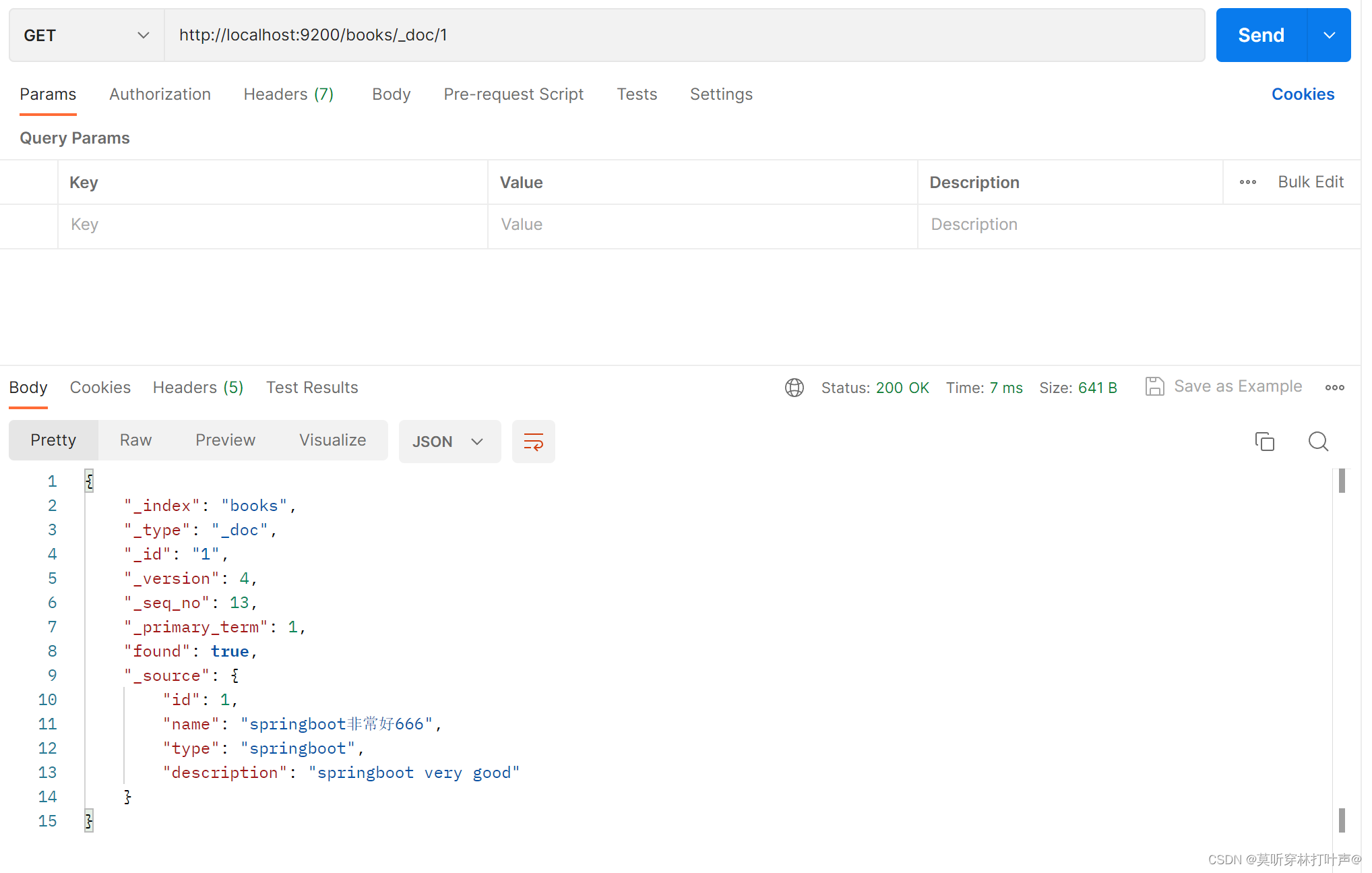
 查询文档:查询id为1的文档
查询文档:查询id为1的文档
查询所有文档:
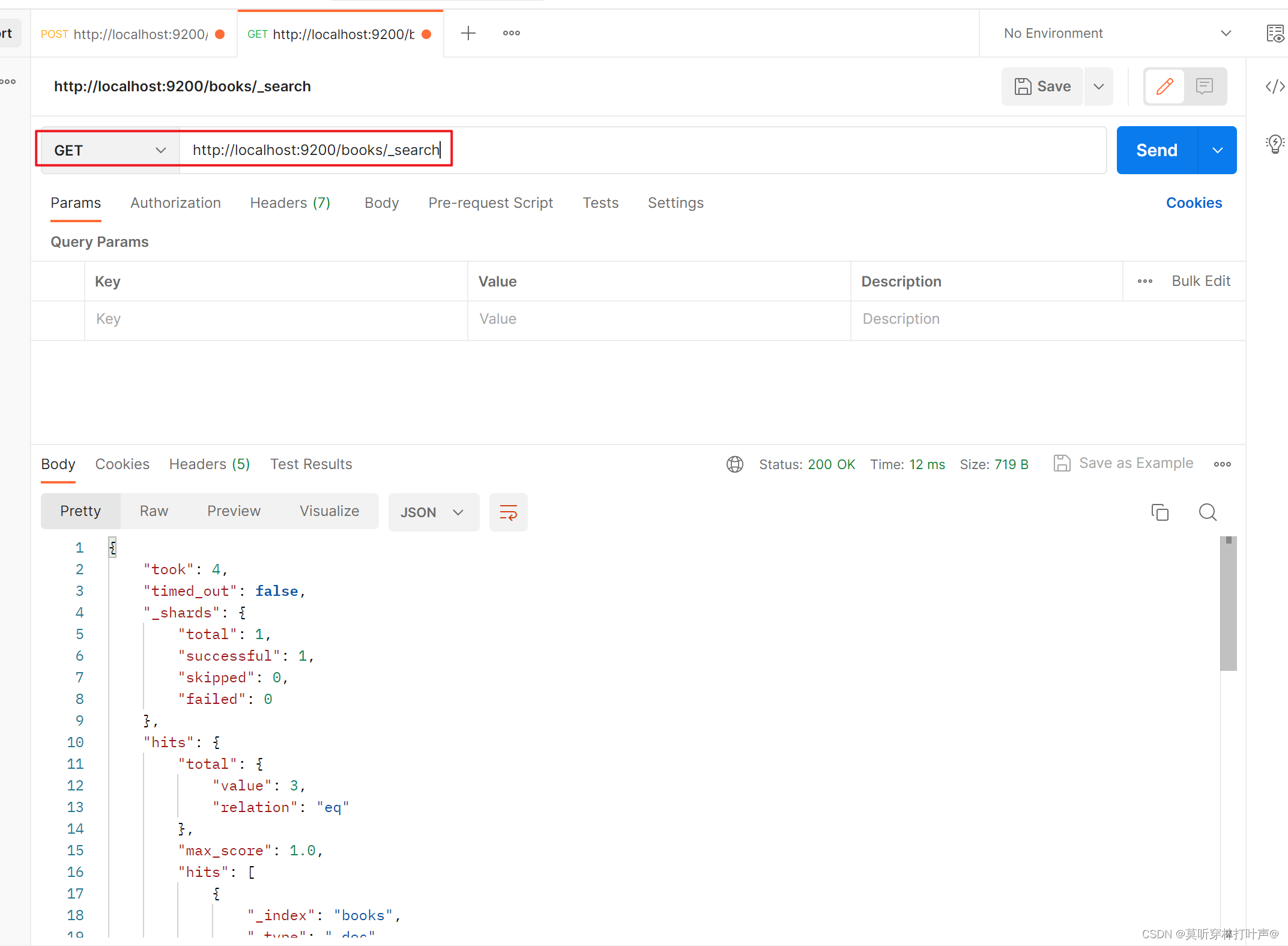
使用条件查询:
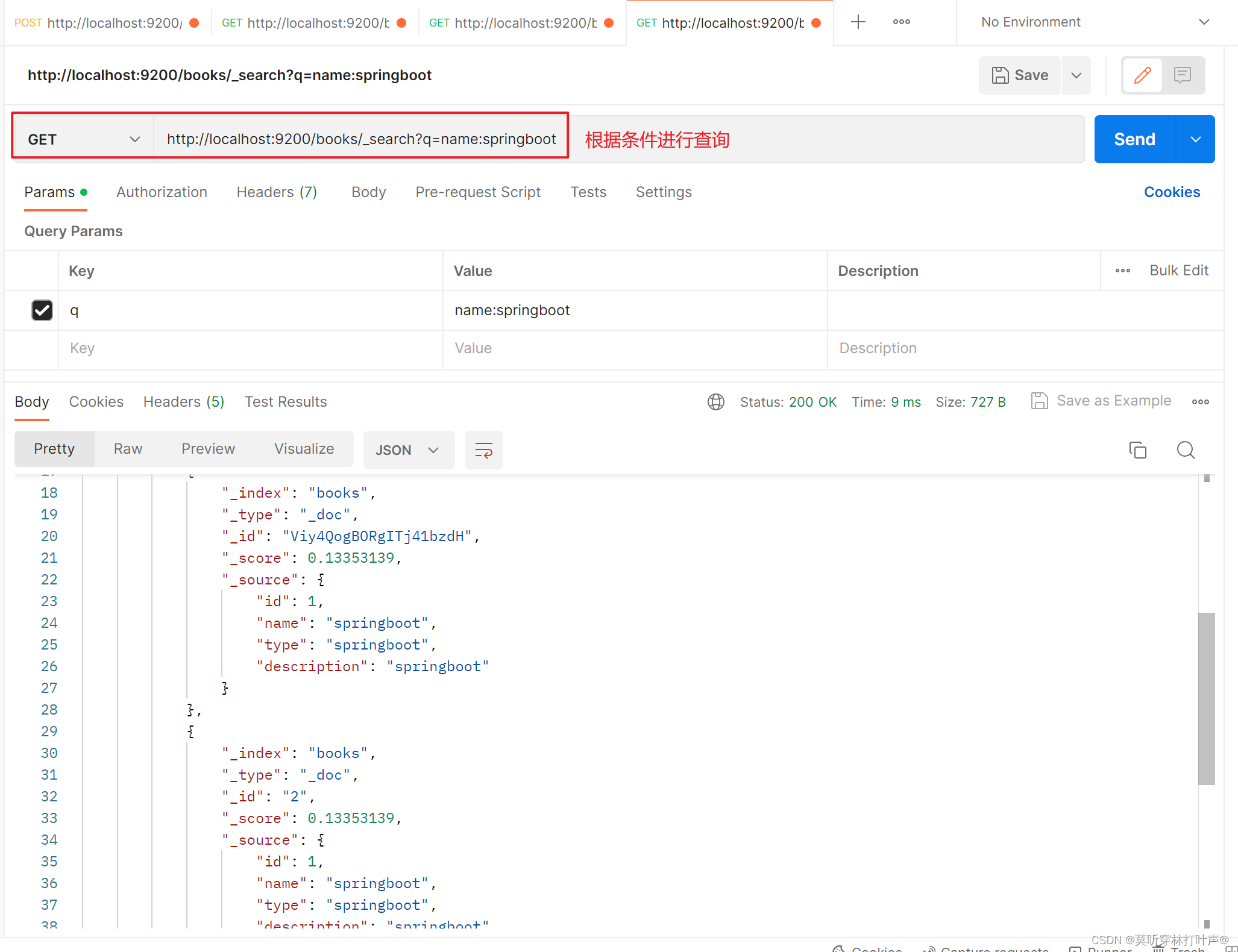
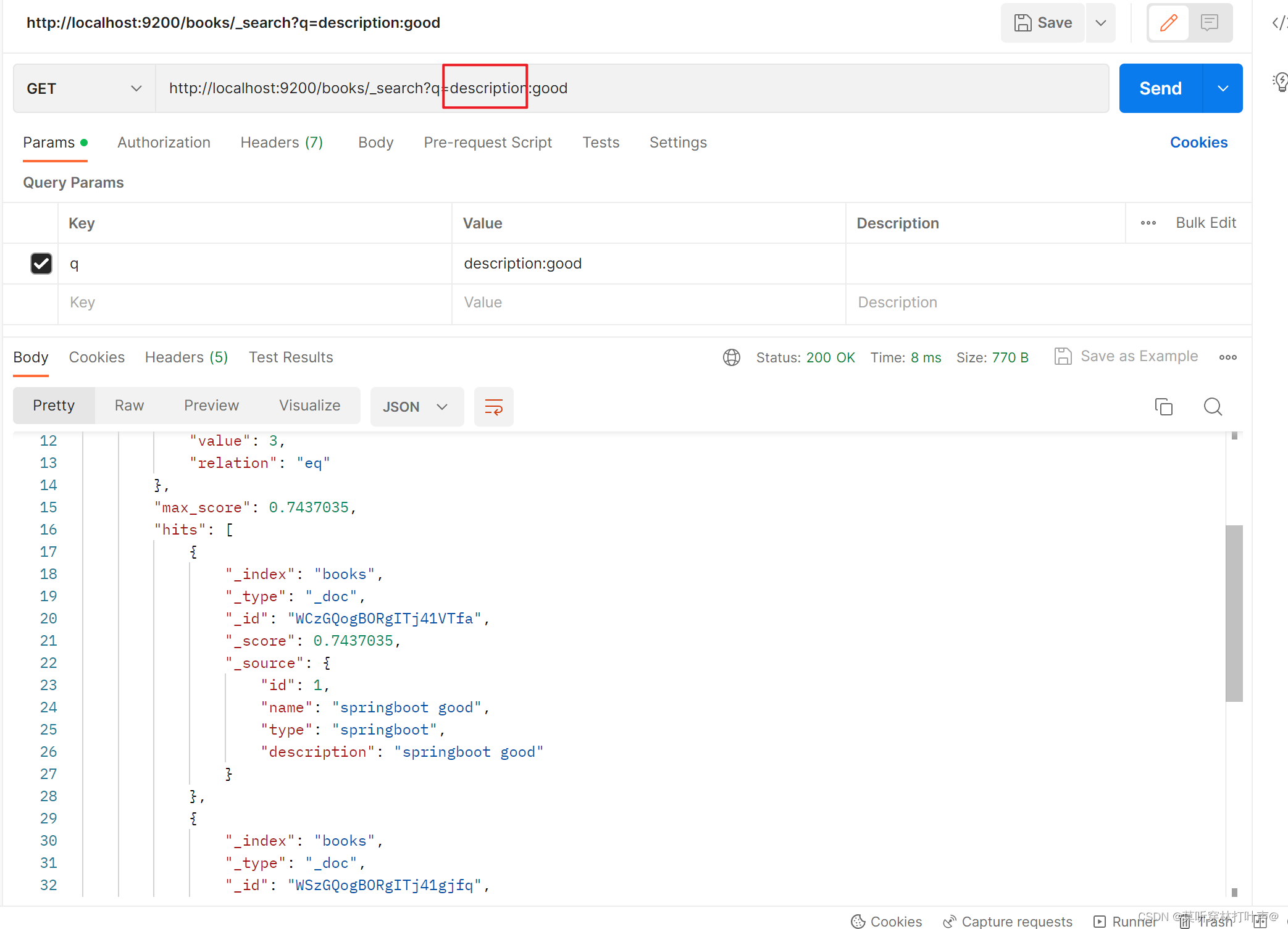
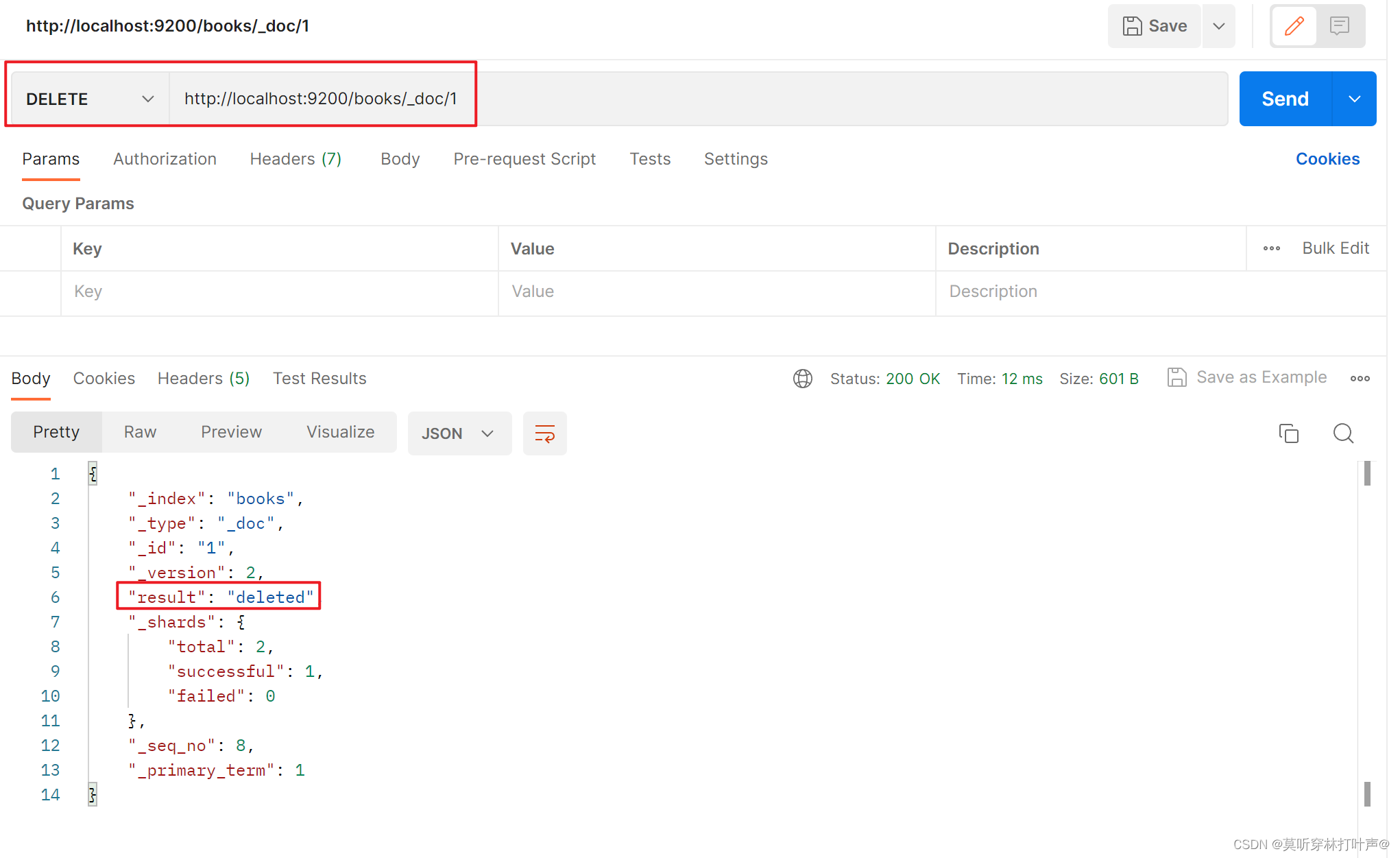
删除文档:
删除一个已经存在的:
删除一个不存在的:
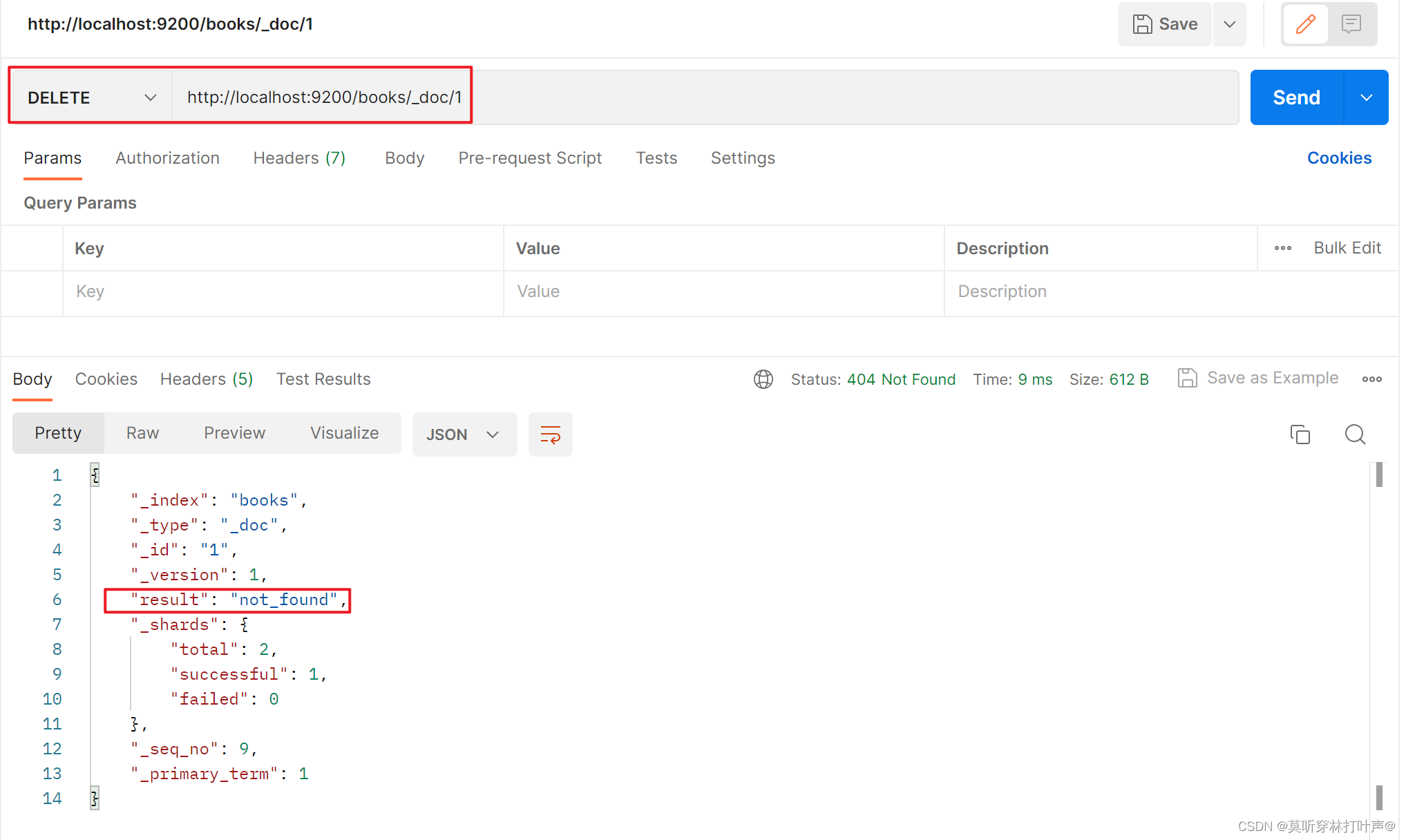
修改一个文档:
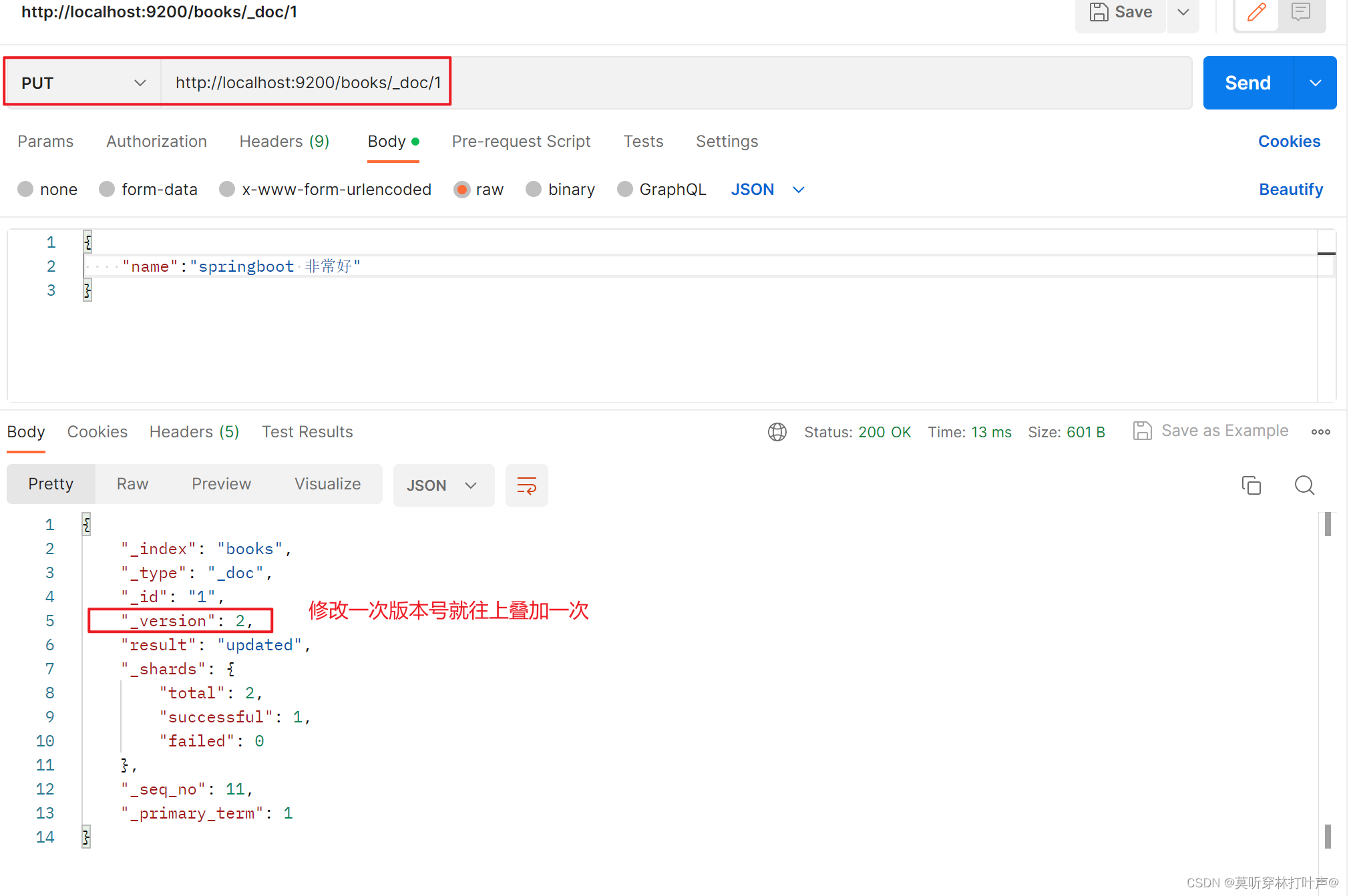
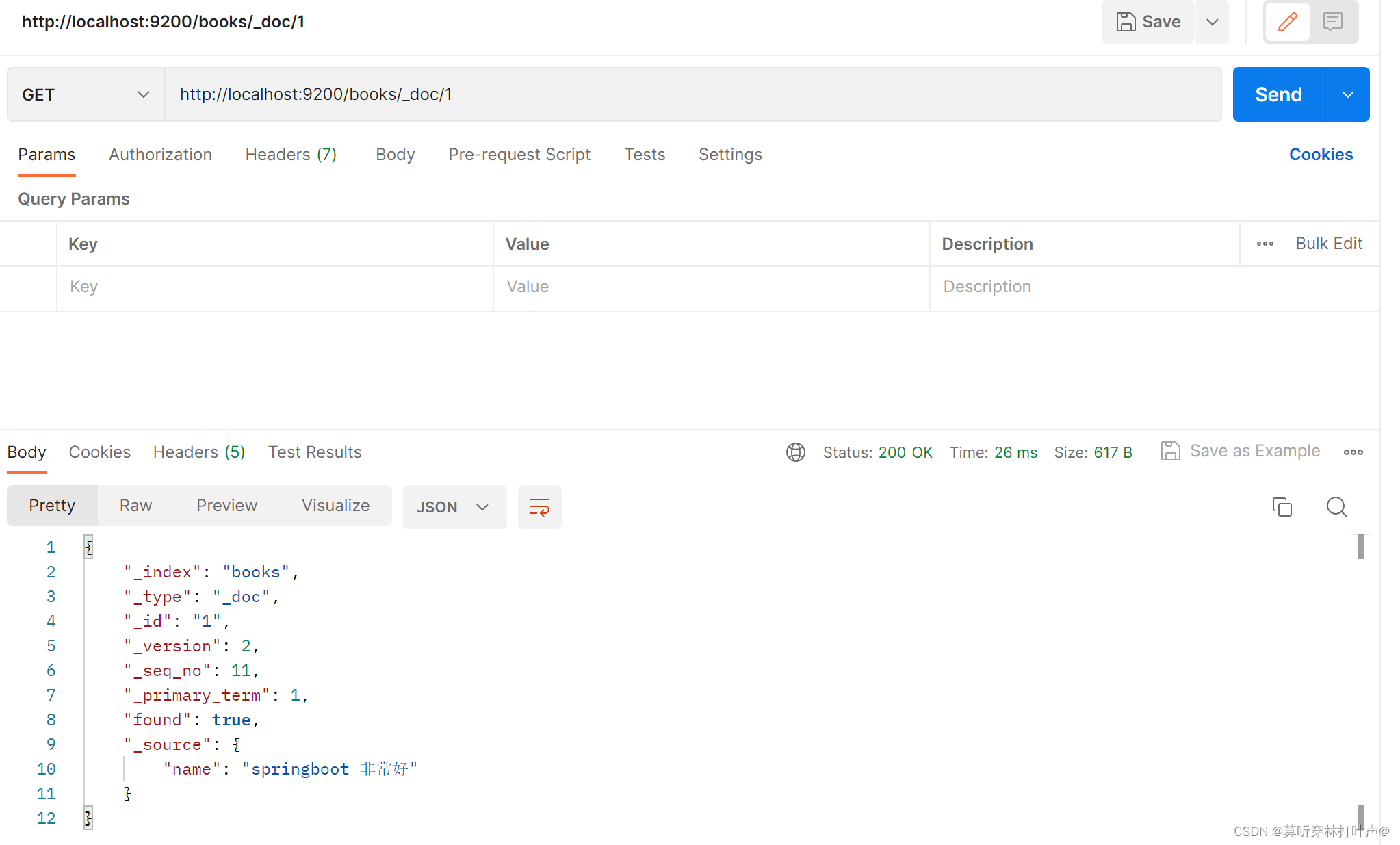
查询一下刚才修改的文档,发现只有name,是全覆盖。
如果不想全部修改,只想修改某一条属性信息:使用文档属性进行修改的。就不会覆盖其他的属性。
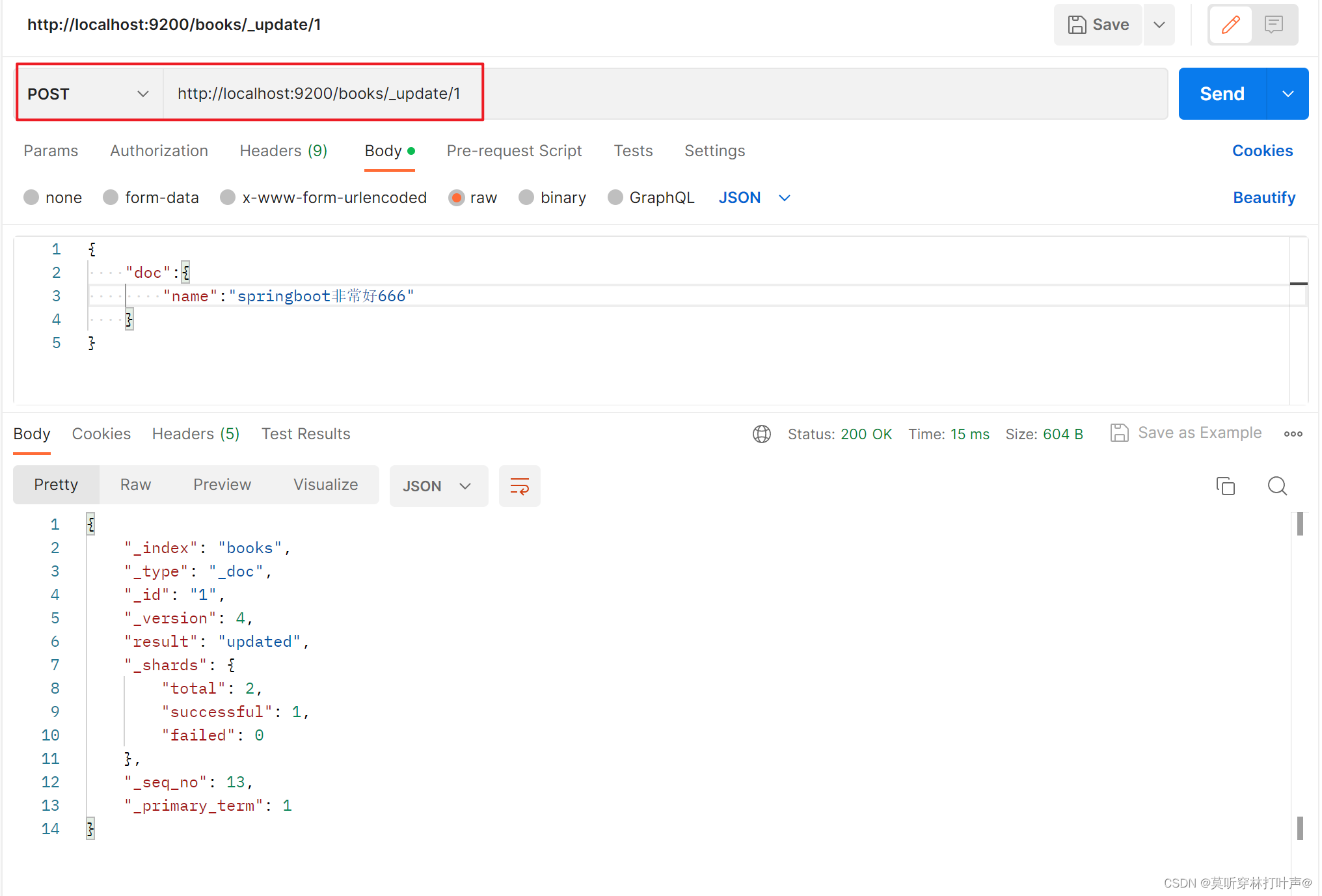
再次查询一下,只有修改的变了。
ElasticSearch(ES)总结:
创建文档:有三种方式。
POST http://localhost:9200/books/_doc #使用系统生成id
POST http://localhost:9200/books/_create/1 #使用指定id
POST http://localhost:9200/books/_doc/1 #使用指定id,不存在创建,存在更新(版本递增)
查询文档:
GET http://localhost:9200/books/_doc/1 #查询单个文档
GET http://localhost:9200/books/_search #查询全部文档
条件查询:
GET http://localhost:9200/books/_search?q=name:springboot
删除文档:
DELETE http://localhost:9200/books/_doc/1
修改文档(全量修改)
PUT http://localhost:9200/books/_doc/1
修改文档(部分修改):对文档中的某个属性,不是对整个文档进行操作(其余都是对一整个文档进行操作的)。
POST http://localhost:9200/books/_update/1
SpringBoot整合ES客户端:
直接整合高级别的客户端:
先导入starter
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
再写配置文件:配置文件不用写,采用的是硬编码的方式。
在SpringBoot里创建ES客户端:
@Testvoid testCreateIndex() throws IOException {//创建客户端HttpHost host=HttpHost.create("http://localhost:9200");RestClientBuilder builder=RestClient.builder(host);client= new RestHighLevelClient(builder);//使用客户端发送了一个请求,创建了一个名称为books的索引CreateIndexRequest request=new CreateIndexRequest("books");client.indices().create(request, RequestOptions.DEFAULT);//关闭客户端client.close();}
在SpringBoot中创建索引:
@Testvoid testCreateIndexByIk() throws IOException {//创建客户端HttpHost host=HttpHost.create("http://localhost:9200");RestClientBuilder builder=RestClient.builder(host);client= new RestHighLevelClient(builder);//使用客户端发送了一个请求,创建了一个名称为books的索引CreateIndexRequest request=new CreateIndexRequest("books");String json="{\n" +" \"mappings\":{\n" +" \"properties\":{\n" +" \"id\":{\n" +" \"type\":\"keyword\"\n" +" },\n" +" \"name\":{\n" +" \"type\":\"text\",\n" +" \"analyzer\":\"ik_max_word\",\n" +" \"copy_to\":\"all\"\n" +" },\n" +" \"type\":{\n" +" \"type\":\"keyword\"\n" +" },\n" +" \"description\":{\n" +" \"type\":\"text\",\n" +" \"analyzer\":\"ik_max_word\",\n" +" \"copy_to\":\"all\"\n" +" },\n" +" \"all\":{\n" +" \"type\":\"text\",\n" +" \"analyzer\":\"ik_max_word\"\n" +" }\n" +" }\n" +" }\n" +"}";//设置请求中的参数request.source(json, XContentType.JSON);client.indices().create(request, RequestOptions.DEFAULT);//关闭客户端client.close();}
添加单个文档:
//添加文档@Testvoid testCreateDoc() throws IOException {//创建客户端HttpHost host=HttpHost.create("http://localhost:9200");RestClientBuilder builder=RestClient.builder(host);client= new RestHighLevelClient(builder);Book book = bookDao.selectById(1);IndexRequest request=new IndexRequest("books").id(book.getId().toString());String json= JSON.toJSONString(book);request.source(json,XContentType.JSON);client.index(request,RequestOptions.DEFAULT);//关闭客户端client.close();}添加多个文档:
//添加全部文档@Testvoid testCreateDocAll() throws IOException {//创建客户端HttpHost host=HttpHost.create("http://localhost:9200");RestClientBuilder builder=RestClient.builder(host);client= new RestHighLevelClient(builder);//把所有东西都查出来,造一个批处理请求的容器List<Book> bookList = bookDao.selectList(null);BulkRequest bulk=new BulkRequest();for (Book book : bookList) {IndexRequest request=new IndexRequest("books").id(book.getId().toString());String json= JSON.toJSONString(book);request.source(json,XContentType.JSON);bulk.add(request);}client.bulk(bulk,RequestOptions.DEFAULT);//关闭客户端client.close();}
查询文档:
//按id查询@Testvoid testGet() throws IOException {//创建客户端HttpHost host=HttpHost.create("http://localhost:9200");RestClientBuilder builder=RestClient.builder(host);client= new RestHighLevelClient(builder);GetRequest request=new GetRequest("books","1");GetResponse response = client.get(request, RequestOptions.DEFAULT);String json = response.getSourceAsString();System.out.println(json);//关闭客户端client.close();}//按条件查询@Testvoid testSearch() throws IOException {//创建客户端HttpHost host=HttpHost.create("http://localhost:9200");RestClientBuilder builder=RestClient.builder(host);client= new RestHighLevelClient(builder);//查books索引SearchRequest request=new SearchRequest("books");//设置条件 如果还有条件继续往里排就行SearchSourceBuilder builder1=new SearchSourceBuilder();builder1.query(QueryBuilders.termQuery("all","1"));request.source(builder1);SearchResponse response = client.search(request, RequestOptions.DEFAULT);//查询到的结果如何显示出来SearchHits hits = response.getHits();for (SearchHit hit : hits) {String source = hit.getSourceAsString();
// System.out.println(source);Book book = JSON.parseObject(source, Book.class);System.out.println(book);}//关闭客户端client.close();}相关文章:
SpringBoot开发实用篇2---与数据层技术有关的替换和整合
四、数据层解决方案 1.SQL 现有数据层解决方案技术选型:DruidMyBatis-plusMySQL 数据源:DruidDataSource 持久化技术:MyBatis-plus/MyBatis 数据库:MySql 内置数据源: SpringBoot提供了3种内嵌的数据源对象供开发者选…...

科普ChatGPT
ChatGPT是什么? ChatGPT是一款基于人工智能技术的聊天机器人,可以进行自然语言的交互。它是由OpenAI公司开发的,其名称中的GPT是“Generative Pre-trained Transformer”的缩写,即基于预训练的转换器。ChatGPT使用预训练的神经网络模型来理…...
Spring MVC的核心类和注解
DispatcherServlet DispatcherServlet作用 DispatcherServlet是Spring MVC的核心类,也是Spring MVC的流程控制中心,也称为Spring MVC的前端控制器,它可以拦截客户端的请求。拦截客户端请求之后,DispatcherServlet会根据具体规则…...

Java 创建一个大文件
有时候,我们在对文件进行测试的时候,可能需要创建一个临时的大文件。 那么问题来了,在 Java 中如何创建大文件呢? 问题和解决 有些人想到的办法就是定义一个随机的字符串,然后重复很多次,然后将这个字符…...

董小姐大意了
阅读本文大概需要 1.17 分钟。 董小姐跟孟羽童的事情,想必大家或多或少都听说了。 事情的经过我就不多做赘述了,实际上并不复杂。 董小姐不是善茬,孟年轻做不来事,不能给格力带来价值,那可以归为双方没缘分,…...
Java高并发核心编程—内置锁原理篇
注:本笔记是阅读《Java高并发核心编程卷2》整理的笔记! 导致并发修改的原因 基本概念 synchronized 关键字 方法声明synchronized synchronized 同步块 消费者生产者问题 Java对象结构与内置锁 四种内置锁 偏向锁原理 偏向锁的撤销 偏向锁的膨胀 全局安全…...

opencv文字识别
OpenCV(开源计算机视觉库)是一个用于实现计算机视觉和机器学习的开源库。它包含了许多预先训练的模型和算法,可以帮助开发者快速实现图像处理、对象检测和识别等功能。在文字识别方面,OpenCV也有一些实用的工具和方法。 要在OpenC…...

bool、python集合
目录 1、使用bool判断某一数据类型是否为空 2、Python集合(数组) 1、列表 2、元组 3、集合 4、字典 1、使用bool判断某一数据类型是否为空 如果有某种内容,则几乎所有值都将评估为 True。 除空字符串外,任何字符串均为 Tr…...
从零开始学架构——可扩展架构模式
可扩展架构模式的基本思想和模式 软件系统与硬件和建筑系统最大的差异在于软件是可扩展的,一个硬件生产出来后就不会再进行改变、一个建筑完工后也不会再改变其整体结构 例如,一颗 CPU 生产出来后装到一台 PC 机上,不会再返回工厂进行加工以…...

Day03 01-MySQL数据完整性详解
文章目录 第七章 数据完整性7.1 完整性约束7.2 实体完整性7.2.1 唯一约束7.2.2 主键约束7.2.3 自增约束 7.3 域完整性7.3.1 非空约束7.3.2 默认值约束7.3.3 检查约束 7.4 引用完整性 第七章 数据完整性 7.1 完整性约束 我们已经知道了如何创建数据库、如何创建表、如何在表中…...
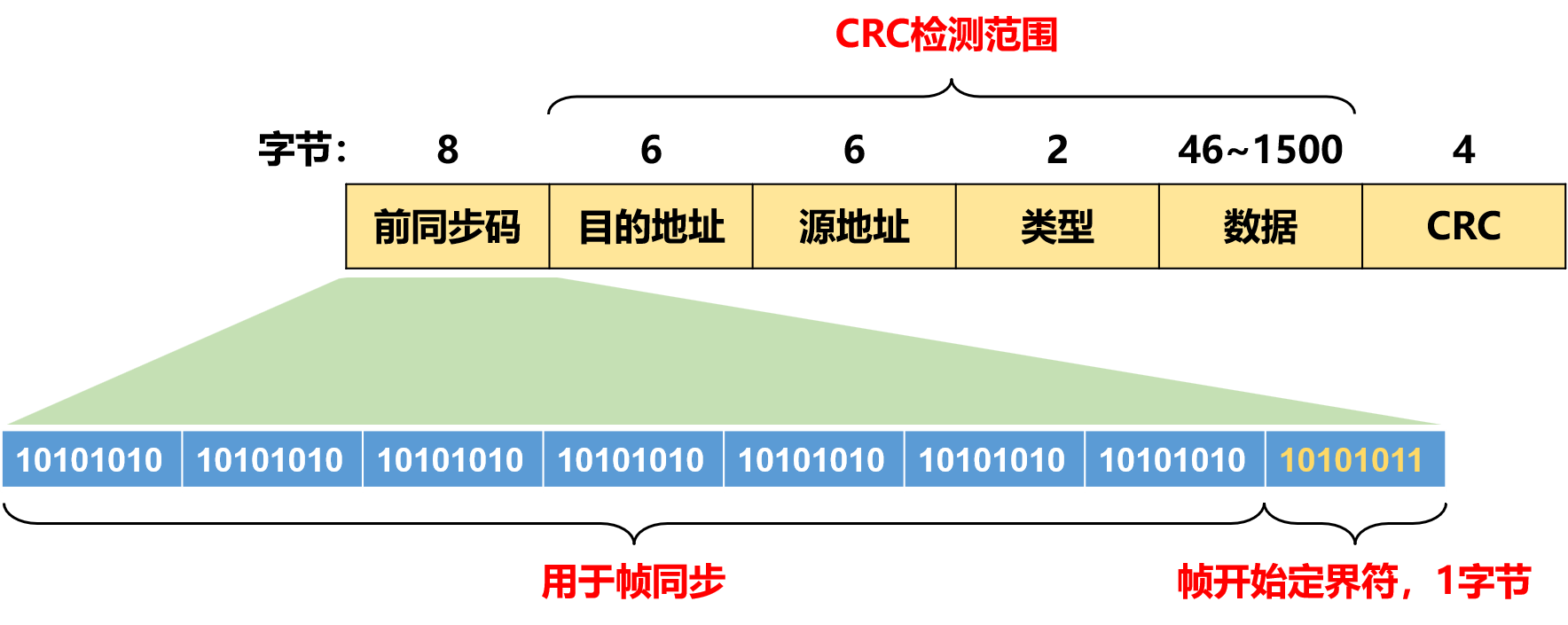
DJ 5-4 以太网 Ethernet
目录 一、以太网的物理拓扑结构 二、以太网物理层标准 1、以太网技术:10Base-T 和 100Base-T 2、以太网技术:1000Base 系列 3、曼彻斯特编码* 4、差分曼彻斯特编码机制* 三、以太网链路层控制技术 四、以太网的帧结构 1、前同步码 2、MAC 地址…...

华为OD机试真题 Java 实现【区块链文件转储系统】【2023Q2 200分】
一、题目描述 区块链底层存储是一个链式文件系统,由顺序的N个文件组成,每个文件的大小不一,依次为F1,F2…Fn。 随着时间的推移,所占存储会越来越大。 云平台考虑将区块链按文件转储到廉价的SATA盘,只有连续的区块链…...

Java 实现 二叉树的 后序遍历
1、定义节点类 class Node {int val;Node left;Node right;Node(int val) {this.val val;} }public class BinaryTree {/*** 后序遍历* param root 节点*/public void postorderTraversal(Node root) {if (root ! null) {postorderTraversal(root.left);postorderTraversal(r…...

rk3588安装qt虚拟键盘
qt是默认安装的,版本号为5.12.8,但是没有虚拟键盘模块,项目中需要,就采用源码编译的方法执行 下载源码 源码地址为Index of /archive/qt/5.12/5.12.1/submodules,下载后放到3588中解压cd到src路径,运行一下命令 …...
HCIP-RIP双向重发布综合实验
拓扑结构: 要求: 1、两个协议间进行多点双向重发布 2、R7的环回没有宣告在OSPF协议中,而是在后期重发布进入的 3、解决环路,所有路径选择最优,且存在备份 4、R2的环回要在RIP中宣告,R3的环回要在OSPF中宣…...

Flask的使用例子
以下是一个简单的使用Flask创建Web应用程序的示例: from flask import Flask, render_template, requestapp Flask(__name__)app.route(/) def home():return Hello, World!app.route(/about) def about():return render_template(about.html)app.route(/submit, …...

【基础6】存储过程的 创建与调用
目录 什么是存储过程 用户自定义存储过程 练习 什么是存储过程 什么是存储过程 类似于C语言中的函数。用来执行管理任务或应用复杂的业务规则存储过程可以带参数,也可以返回结果存储过程可以包含数据操纵等语句、变量、逻辑控制语句等。(单个select语…...

如何快速实现接口自动化测试,常规接口断言封装实践
目录 前言: 一、框架设计思路 1. 封装请求方法 2. 断言封装 3. 接口封装 4. 接口统一管理 二、框架使用 三、总结 前言: 在当今互联网行业中,接口自动化测试已经成为了非常重要的测试手段之一。而在这个过程中,接口自动化…...
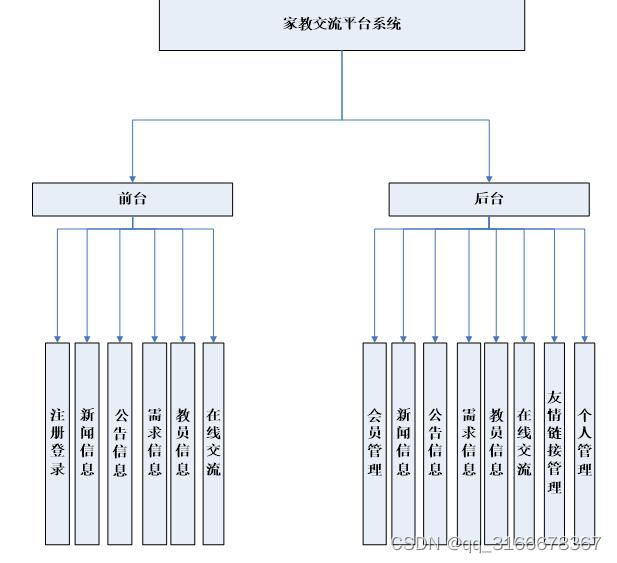
java+nodejs+vue+python+php家教信息管理系统
任何网友都可以自由地查看、搜索、发布该家教信息平台的信息。该平台是区别于传统的家教中介的服务平台。学生可以免费查看网站上的家教信息,挑选适合自己的家教;教师可以免费查看网站上的需求信息,挑选适合自己的学生;学生可以发…...

课程分享:鸿蒙HarmonyOS系统及物联网开发实战课程(附课程视频及源码下载)
课程名称: 鸿蒙HarmonyOS系统及物联网开发实战课程 课程介绍: HarmonyOS 是一款面向万物互联时代的、全新的分布式操作系统。在传统的单设备系统能力基础上,HarmonyOS 提出了基于同一套系统能力、适配多种终端形态的分布式理念,…...

终极指南:5步快速掌握免费的3D点云标注工具labelCloud
终极指南:5步快速掌握免费的3D点云标注工具labelCloud 【免费下载链接】labelCloud A lightweight tool for labeling 3D bounding boxes in point clouds. 项目地址: https://gitcode.com/gh_mirrors/la/labelCloud 想要为自动驾驶、机器人视觉或3D目标检测…...

终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词
终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 你是否厌倦了在听歌时手动搜索歌词…...

Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式 对于技术管理者或项目负责人而言,清晰了解团队的AI…...

如何快速定制Office界面:终极开源工具使用指南
如何快速定制Office界面:终极开源工具使用指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-editor O…...

基于Atmega 1284P的16位复古计算器:硬件设计与软件实现全解析
1. 项目概述与核心思路最近在整理工作室时,翻出了一堆老旧的7段数码管和矩阵键盘,看着这些充满复古气息的元件,一个想法冒了出来:为什么不自己动手做一台复古风格的计算器呢?不是那种用液晶屏显示的现代计算器…...

别再只会用--nogpgcheck了!手把手教你安全修复PostgreSQL yum源的GPG密钥问题
企业级PostgreSQL部署:安全解决GPG密钥验证的完整方案 当你在生产环境中部署PostgreSQL时,遇到GPG签名验证错误直接使用--nogpgcheck绕过检查,就像因为门锁打不开就直接把门拆掉一样危险。本文将带你深入理解GPG验证机制,并提供一…...

5步完美解决Windows 10 PL2303驱动兼容性问题:完整实施方案指南
5步完美解决Windows 10 PL2303驱动兼容性问题:完整实施方案指南 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 在Windows 10系统中使用PL2303 USB转串口设…...

MySQL全局ID生成实战:从自增主键到自定义Sequence的平滑升级方案与避坑指南
MySQL全局ID生成实战:从自增主键到自定义Sequence的平滑升级方案与避坑指南 当电商平台的日订单量突破百万时,技术团队突然发现系统开始频繁出现"Duplicate entry"错误——那些原本可靠的自增主键,在分库分表的环境下变成了数据一致…...

5个高效技巧:重新定义你的Chrome书签管理体验
5个高效技巧:重新定义你的Chrome书签管理体验 【免费下载链接】neat-bookmarks A neat bookmarks tree popup extension for Chrome [DISCONTINUED] 项目地址: https://gitcode.com/gh_mirrors/ne/neat-bookmarks 你是否曾花费数分钟在混乱的书签海洋中寻找那…...
)
【仅限首批200家认证用户】DeepSeek v3.2.1重复检测私有化部署补丁包(含GPU内存泄漏热修复+增量扫描加速模块)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力…...