HTTP协议——详细讲解
目录
一、HTTP协议
1.http
2.url
url的组成:
url的保留字符:
3.http协议格式编辑
①http request
②http response
4.对request做出响应
5.GET与POST方法
①GET
②POST
7.HTTP常见Header
①Content-Type:: 数据类型(text/html等)在上文我们使用过。
②Content-Length: 正文的长度。
③Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上。
④User-Agent: 声明用户的操作系统和浏览器版本信息。
⑤referer: 表示当前页面是从哪个页面跳转过来的。
⑥Location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问。
⑦Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能。
一、HTTP协议
1.http
上篇文章我们体验了定制协议的繁琐,这次我们来讲述下真正成熟的有很多人使用的协议,例如:http、https、smtp、dns等。
Http协议:超文本传输协议。
客户端通过使用Http协议来向服务端获取资源。
2.url
我们俗称的“网址”就是url。

协议方案名:上例是http://,表示使用http协议。后面我会讲到https,这是http协议的加密版本,现在多数都使用的都是https。
登录信息:我们这次不考虑,一般会省略掉,在正文中携带登录信息。
服务器地址:是资源所在的网站名或服务器的名字,又称为域名。在网络通信中域名必须被转换为IP地址。
端口号:HTTP 协议的默认端口是80,如果省略了这个参数,服务器就会返回80端口的网站。在上上一篇文章中讲到网络之间的通信就是进程之间的通信,通过域名(IP地址)+端口号的方式就可以在全网中确定唯一一个进程。我们发现一些url会缺省port,一般由浏览器自动添加,而这些url对应的port都是公开的,一旦服务上线端口号就已经确定,httpserver->80,httpsserver->443,sshd->22。
文件路径:资源在服务器的位置。
查询字符串:提供给服务器的额外信息。
片段标识符:也叫做锚点,锚点是网页内部的定位点,浏览器加载页面之后,回滚到锚点锁定位的位置。
url的组成:
26个英文字母 10个阿拉伯数字 连词号(-)句典(.) 下划线(_)
url的保留字符:
有10个保留字符,只能在给定位置出现。
如果在其他位置去使用保留字符,就必须使用转义形式。

其中罗列一部分,都是关于特殊符号的转义,那我要在url中体现汉语怎么办?
我们可以现场搜索一下,见见实际情况。 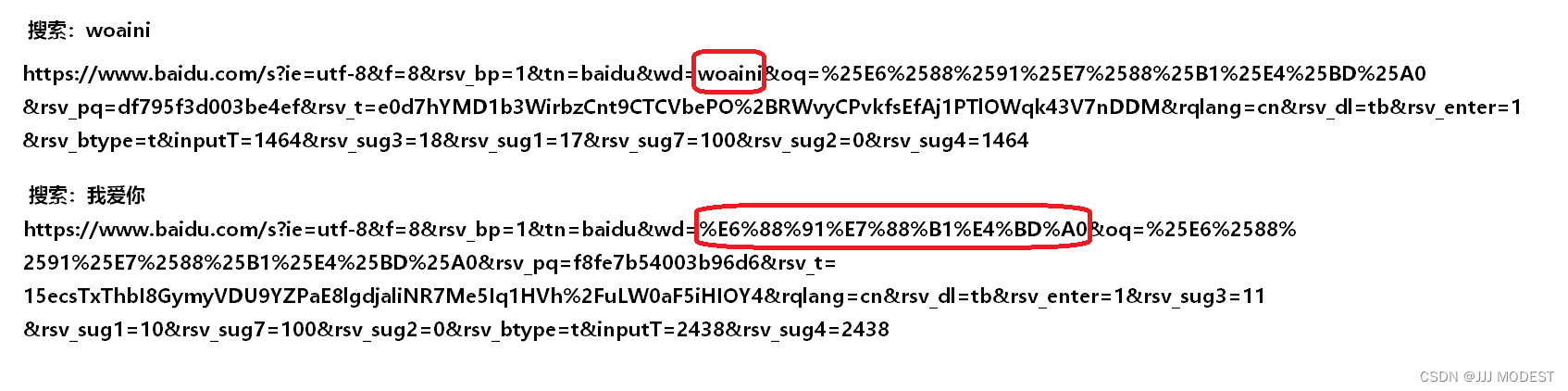
我们会发现汉字也会被转义,转义的规则为:将需要转码的字符转换为16进制,从右到左取四位,每两位做一位,前面加上%,编码成%XY格式。
3.http协议格式
注意:
method为请求方法,常见的get方法、post方法。
key:空格value
http/1.1为当前版本为1.1
现在我们可以通过上节课代码,我们运行server,通过浏览器来访问我们的server,将接收到的东西打印出来,我们就可以真正的见到http request。
①http request
在浏览器中输入你主机的IP地址:你的server绑定的端口号。
 上图中关于服务器版本的信息,当我们换个浏览器使用就会有不同的效果。
上图中关于服务器版本的信息,当我们换个浏览器使用就会有不同的效果。
如图我是用iphone的safari浏览器依据我们的ip与port来访问的。
至于浏览器会表现出如此现象是因为我们做为服务器没有向浏览器响应发送任何东西。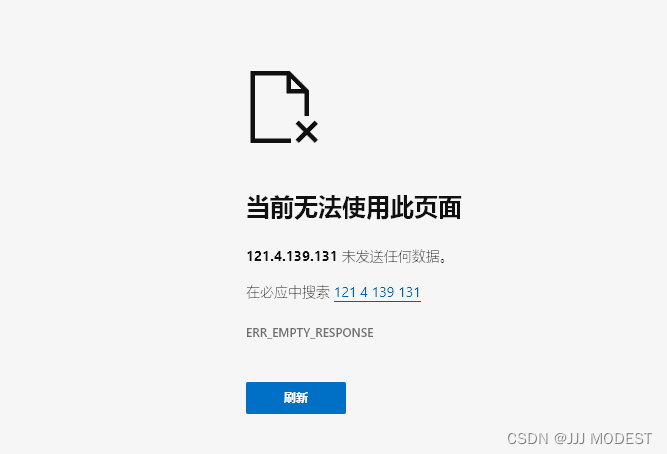
上文的tcpserver的代码是上篇文章写的,很是臃肿,于是我删删减减,得到了simple版本。
void handlerHttpRequest(int sock)
{cout<<"++++++++++++++++++++++++"<<endl;char buffer[1024];ssize_t sz = read(sock, buffer, sizeof(buffer));if (sz > 0){cout << buffer << endl;}
}class Tcpserver
{
public:Tcpserver(uint16_t port, const string &ip = ""): _sock(-1), _port(port), _ip(ip){_quit = false;}~Tcpserver(){if (_sock >= 0)close(_sock);}public:void init(){_sock = socket(AF_INET, SOCK_STREAM, 0);if (_sock < 0){exit(1);}struct sockaddr_in local;memset(&local, 0, sizeof(local));local.sin_family = AF_INET;local.sin_port = htons(_port);_ip.empty() ? INADDR_ANY : (inet_aton(_ip.c_str(), &local.sin_addr));if (bind(_sock, (const sockaddr *)&local, sizeof(local)) < 0){exit(2);}if (listen(_sock, 5) < 0){exit(3);}}void start(){signal(SIGCHLD, SIG_IGN);while (!_quit){struct sockaddr_in peer;socklen_t len = sizeof(peer);int servicesock = accept(_sock, (struct sockaddr *)&peer, &len);if (_quit)break;if (servicesock < 0){cerr << "accept error ..." << endl;continue;}int clientport = ntohs(peer.sin_port);string clientip = inet_ntoa(peer.sin_addr);pid_t pid = fork();assert(pid != -1);if (pid == 0){if (fork() > 0)exit(4);handlerHttpRequest(servicesock);exit(0);}close(servicesock);wait(nullptr);}}void safequit(){_quit = true;}private:int _sock;uint16_t _port;string _ip;// 安全退出bool _quit;
};Tcpserver *svrp = nullptr;
void sighandler(int sig)
{if (sig == 3 && svrp != nullptr)svrp->safequit();cout << "server quit" << endl;
}上文我们可以看到http request的响应代码。接下来我们看一下http response的响应代码。
②http response
接下来,我们可以通过命令行的方式向baidu发送request获得response。
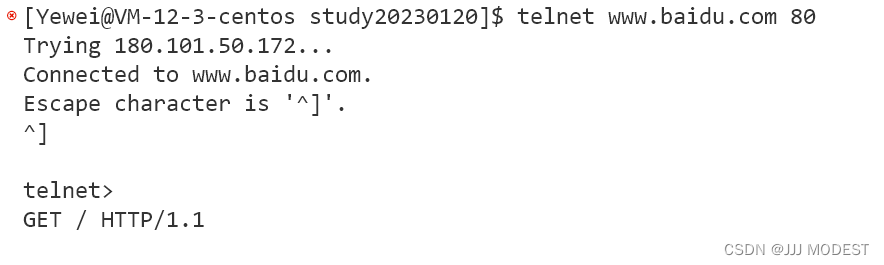
进入telnet后按ctrl+],再按回车输入GET / HTTP/1.1,然后按两下回车。
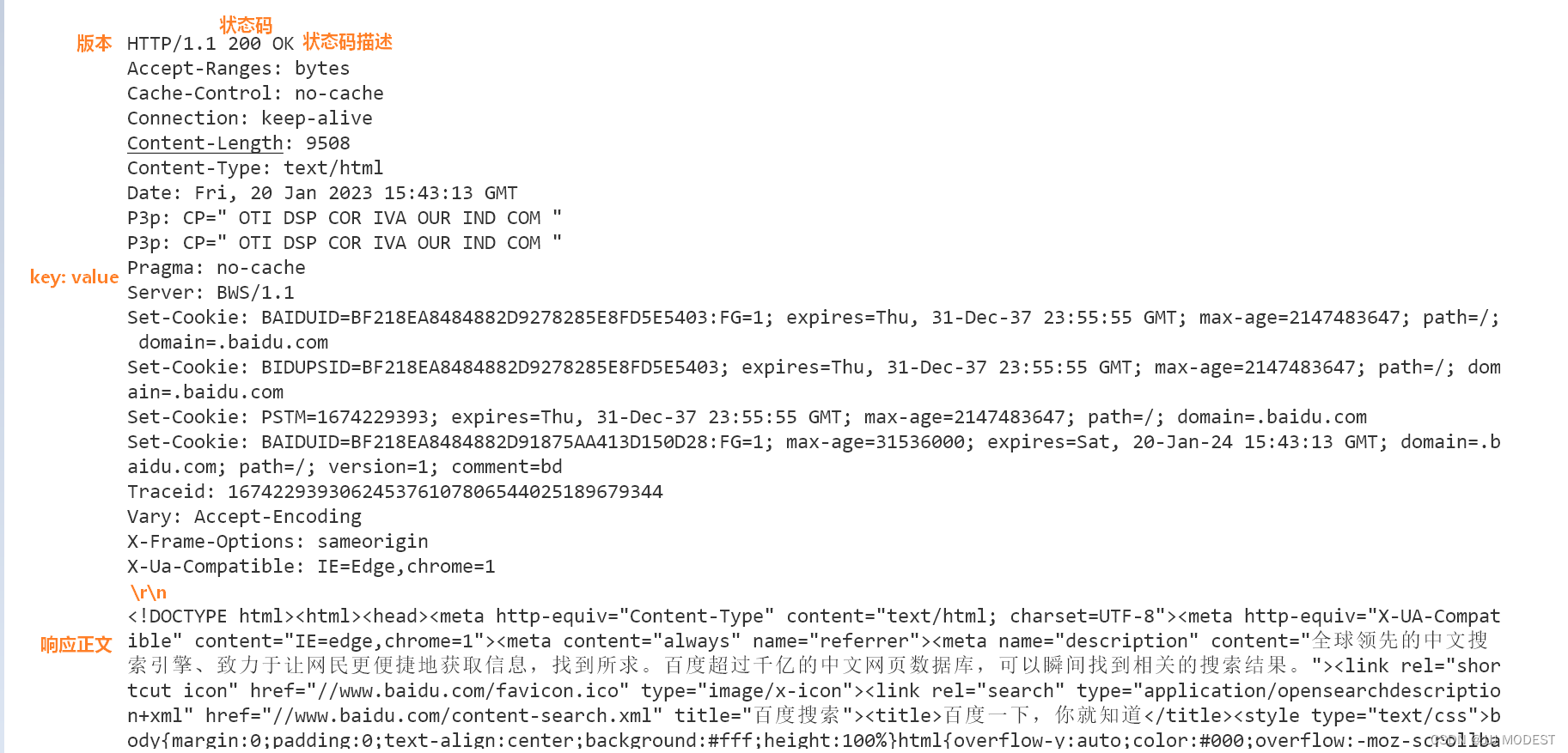
4.对request做出响应
上文我们对浏览器的request并没有做出任何响应,server仅仅是将接收到的http request中的内容,下文我们将对request做出响应。当然不是无所依据的responce,我们可以参照上文百度做出的responce。
这个函数的参数神似我们使用过的write,将flags设置为0,就和write等价。
代码:
void handlerHttpRequest(int sock)
{char buffer[1024];ssize_t sz = read(sock, buffer, sizeof(buffer));if (sz > 0){cout << buffer << endl;}// response string response;response += "HTTP/1.0 200 OK\r\n"; // response请求行response += "\r\n"; // 本行为\r\n为请求报头与正文的分界线 请求报头暂且为空response += "Hello world!"; // 正文send(sock,response.c_str(),response.size(),0);
}结果:

单纯Hello world!有点单一,我们可以让它成为这个网页的大标题,这个工作将由浏览器接收到我们的正文部分然后渲染就可以得到效果了。
代码:
response += "<html><h1>Hello world!</h1></html>"; // 正文
结果:

再次升级,我们将响应报头完善下。
Content-Type 内容类型 指出我们正文所对应的类型。
上文中的正文内容为.html,Content-Type就应该填text/html。
具体的对照类型,可以看这篇博客。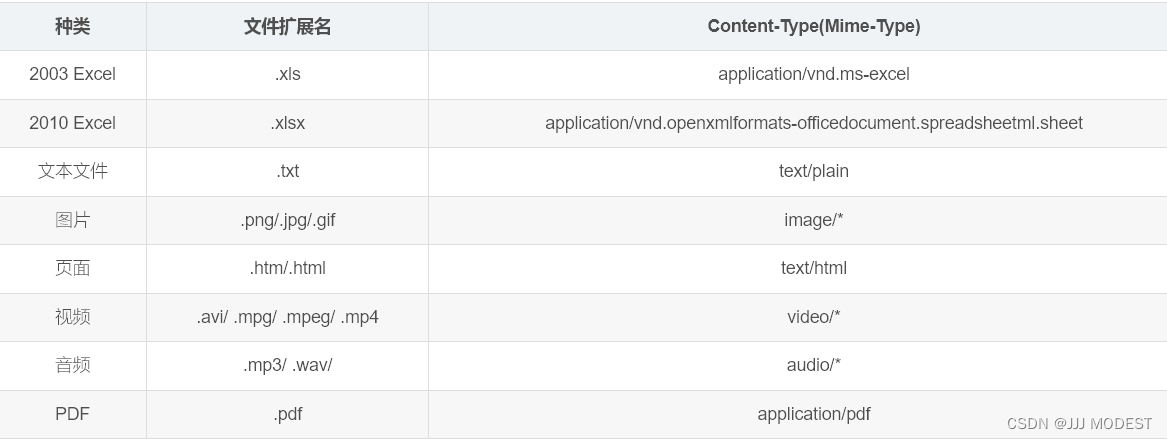
代码:
// response string response;response += "HTTP/1.0 200 OK\r\n"; // response请求行response += "Content-Type: text/html\r\n";response += "\r\n"; // 本行为\r\n为请求报头与正文的分界线 请求报头暂且为空response += "<html><h1>Hello world!</h1></html>"; // 正文
结果跟上文无疑。
如何保证将响应行与响应报头读完整呢?读到空行就可以保证。那如何保证正文读取完整呢?这就是响应报头中的内容来保证的。
Content-Length负责记录正文的长度。
代码:
// responsestring html = "<html><h1>Hello world!</h1></html>";string response;response += "HTTP/1.0 200 OK\r\n"; // response请求行response += "Content-Type: text/html\r\n";response += ("Content-Length: " + to_string(html.size()) + "\r\n");response += "\r\n"; // 本行为\r\n为请求报头与正文的分界线 请求报头暂且为空response += html; // 正文结果:这次通过使用telnet来检验成果,浏览器不会显示。
作为建设服务器的人员将网页构建的代码写到服务器中,是否有点挫,那应该放在什么地方?先前我们在讲url的时候提到过文件路径,由客户端依据文件路径请求资源,服务器依据请求放回资源。所有我们的html等资源都是放在文件里。
至于文件路径是否要从linux根目录中开始写,写到目标文件为止,会写出很长一段文件路径。其实不用,如果客户端要访问a/b/c.html,我们能说a文件就是linux的根目录吗,不能,这是web根目录,具体可以看下方代码。
request = "/a/b/c.html";path = "linux/server/web"; // web根目录path += request; ->linux/server/web/a/b/c.html // 最终的文件路径这次我们将我们的html放在文件中,由客户端申请客户端返回。
我们的主页在当前工作路径下的wwwroot里。
代码:
#define CRLF "\r\n"
#define SPACE " "
#define SPACE_LEN strlen(SPACE)
#define HOME_PAGE "index.html"
#define WEB_ROOT "./wwwroot"// 负责将http_request中的文件路径提取出来
string getPath(string http_request)
{ssize_t pos = http_request.find(CRLF);if (pos == string::npos)return "";string request_line = http_request.substr(0, pos);// GET /a/b/c http/1.1ssize_t firstSpace = request_line.find(SPACE);if (firstSpace == string::npos)return "";ssize_t secondSpace = request_line.rfind(SPACE);if (secondSpace == string::npos)return "";string path = request_line.substr(firstSpace + SPACE_LEN, secondSpace - (firstSpace + SPACE_LEN));if (path.size() == 1 && path[0] == '/')path += HOME_PAGE; // 如果只发了/ ,我们就将我们网址的主页返回过去return path;
}// 负责打开文件将文件的内容读取出来
string readFile(const string &path)
{ifstream in(path, std::ifstream::binary);if (!in.is_open())return "404";string content;string line;while (getline(in, line))content += line;in.close();return content;
}void handlerHttpRequest(int sock)
{char buffer[10240];ssize_t sz = read(sock, buffer, sizeof(buffer));if (sz > 0){cout << buffer;}string path = getPath(buffer);cout << "path->" << path << endl;string resource = WEB_ROOT;resource += path;cout << "resource->" << resource << endl;string html = readFile(resource);string response;response += "HTTP/1.0 200 OK\r\n"; // response请求行response += "Content-Type: text/html\r\n";response += ("Content-Length: " + to_string(html.size()) + "\r\n");response += "\r\n"; // 本行为\r\n为请求报头与正文的分界线 请求报头暂且为空response += html; // 正文send(sock, response.c_str(), response.size(), 0);
}index.html:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>http server</title>
</head>
<body><h3>TEST</h3><p>Hello World!</p>
</body>
</html>telnet中的结果:无论是请求/ 还是/index.html 结果都一样因为我们当前只有一个主页。

web中的结果:

5.GET与POST方法
①GET
下面我们来鉴别POST方法与GET方法的区别。
我们都知道上网的行为一般分两种:
1.从远端获取资源到本地 使用GET方法 //GET / HTTP/1.1
2.将本地的资源上传到远端 可以使用POST方法也可以使用GET方法。
我们这次使用表单将信息填写,然后先用GET方法发送。
代码:
<!DOCTYPE html>
<html><head><meta charset="utf-8"><title>http server</title>
</head><body><h3>TEST</h3><p>Hello World!</p><form action="abc/qwe/index.html" method="get">Username: <input type="text" name="user"><br>Password: <input type="password" name="passwd"><br><input type="submit" value="Submit"></form>
</body></html>
 现象:我们将信息填入点击submit
现象:我们将信息填入点击submit

提交过后会发现会出现404,那是因为网页代码中我们指定将数据提交的网址(abc/qwe/index.html)在服务器中并不存在。

我们主要来分析下当前的url。

我们会发现在HTTP协议中GET方法会以明文的方式 将我们对应的参数信息,拼接到url中。
②POST
下面来看看POST方法。
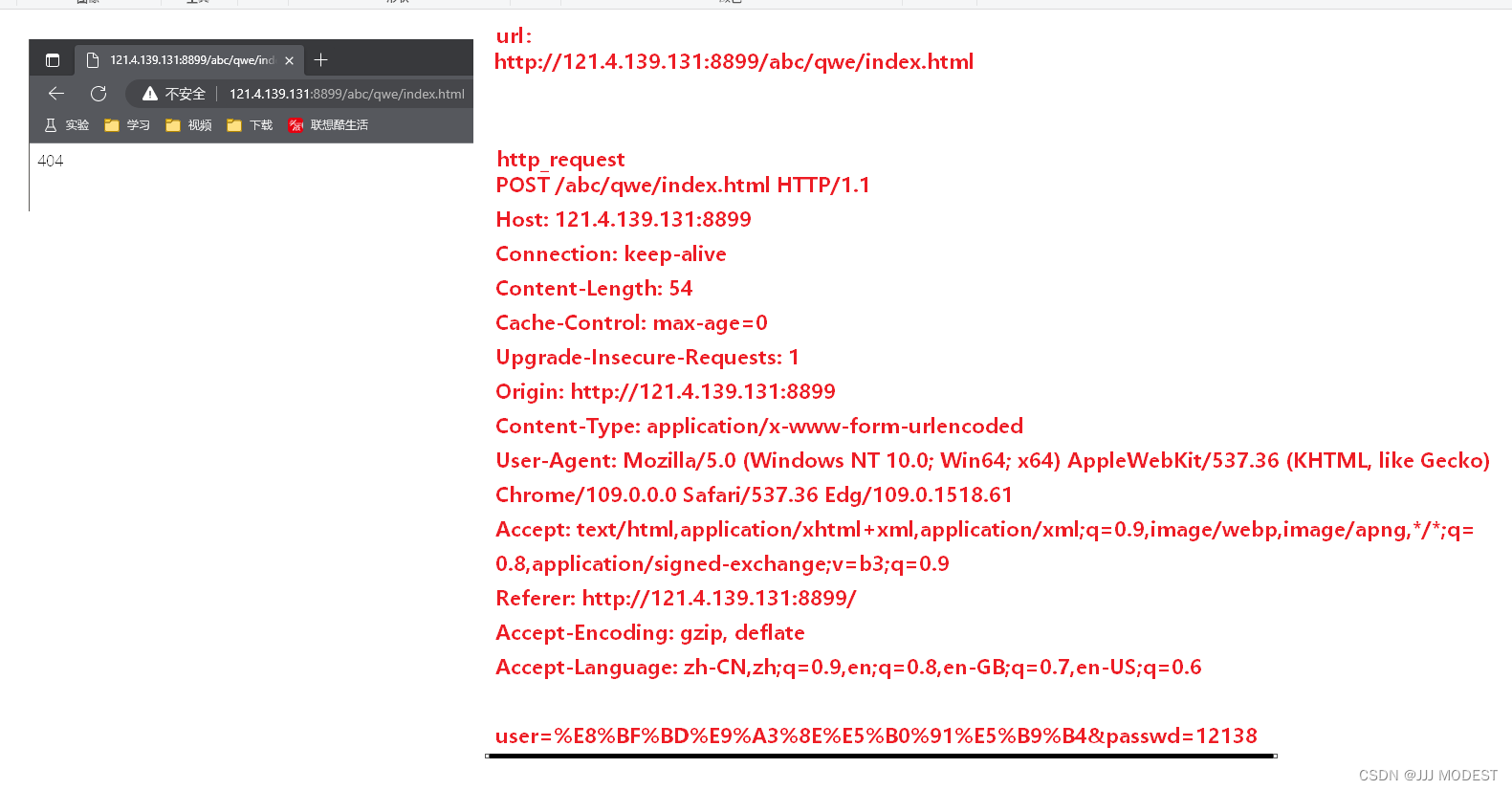
我们会发现GET方法中会将信息拼接在url中,而POST方法不一样,它是将信息拼接到http requset中的正文中。
总结:
1. GET方法通过url传参
2. POST方法通过正文传参
3. GET方法传参不私密
4. POST方法传参通过正文,相对私密。至于为什么不说安全与不安全,HTTP协议在某种角度来说就是不安全的,不管通过GET还是POST方法提交数据都会通过抓包等软件获取到url或者正文,所以说都是不安全的,下面我们会学习HTTPS现在主流安全可靠的协议。
5. 网页中内容较少一般通过GET方法传参,内容较多通过POST方法传参。
6.HTTP状态码
最常见的状态码,比如200(OK),404(Not Found),403(Forbidden),302(Redirect,重定向),504(Bad Gateway)。
我们向服务器申请一个并不存在的资源将会返回什么状态码呢?
会返回4XX,因为客户端申请的资源并不存在,服务器就算穷举也找不到,所以这是客户端出错。
什么时候会返回5XX呢?
客户端申请一些任务,服务器去执行,在其中会申请内存,线程,进程等手段执行任务,当服务器中一些资源到达载荷就会返回5XX。
我们主要研究下3XX。
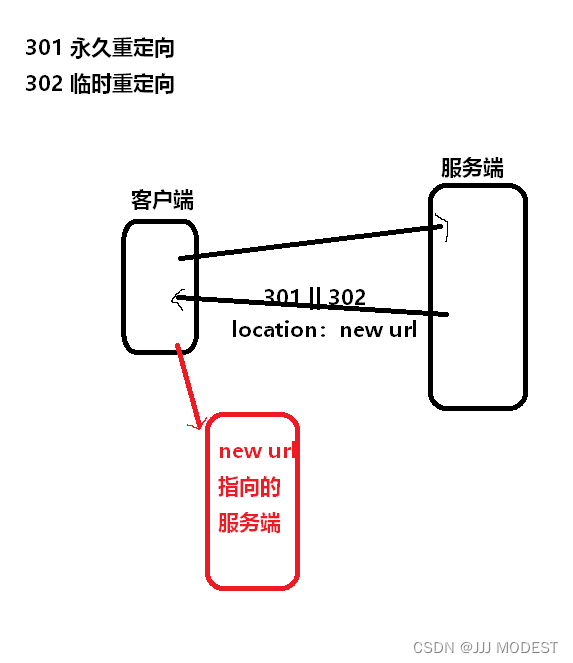
客户端向服务端发起请求,服务端响应中携带301 || 302 和new url,浏览器就会自动跳转到新的服务端去获得资源。
我们通过我们简单的代码,也可以验证下。
代码:
void handlerHttpRequest(int sock)
{char buffer[10240];ssize_t sz = read(sock, buffer, sizeof(buffer));if (sz > 0){cout << buffer;}string response = "HTTP/1.1 302 Moved Temporarily\r\n";response += "Location: www.baidu.com\r\n";response += "\r\n";send(sock, response.c_str(), response.size(), 0);
}现象:
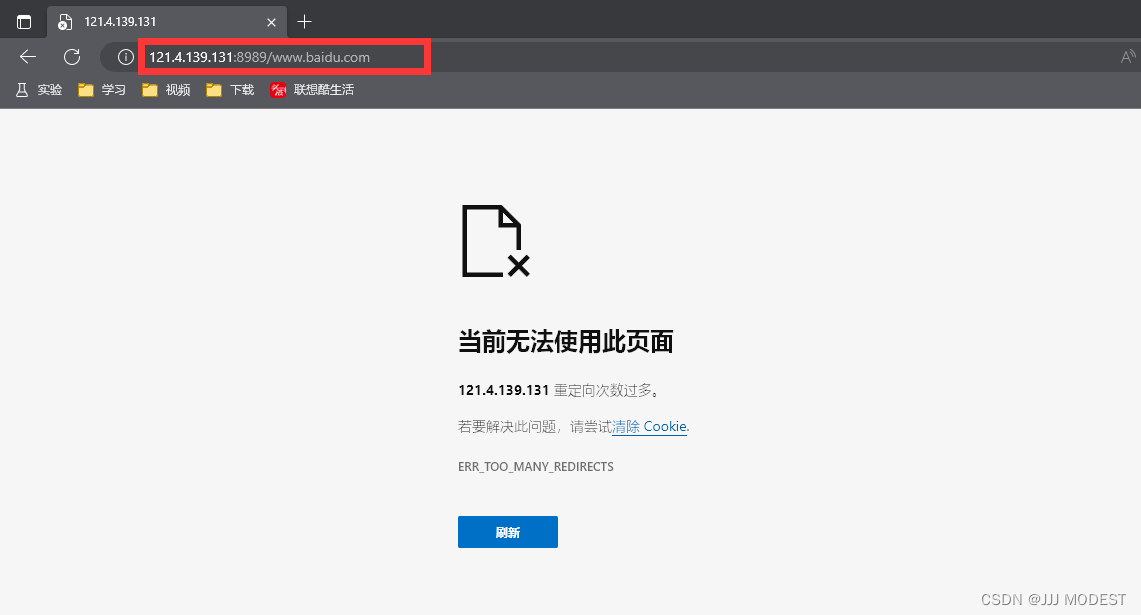
至于为什么没有显示我们重定向之后的页面呢,因为浏览器作为客户端并行的向我们的服务端发送请求,服务端则是向每一个请求都返回重定向,所以会显示出图片中的错误。
当然我们此时也没有完全写对,Location之后一定跟的是网址。写成www.baidu.com只是目前的站内跳转,要实现不同的域也就是服务器跳转,代码要变成:
response += "Location: https://www.baidu.com/\r\n";
现象:将IP地址和端口输入回车之后,就会跳转到我们重定向之后的界面。

什么时候会用到301或者302呢?
301作为永久重定向,一般是在网站更换网址时使用,比如,当时的url取的很随意当想改变跟换一个更好听的时候,会发现当前访问旧网址的人很多,为了避免再换url时损失大量用户,可以在用户访问旧url时,使用永久重定向跳转到新的url。
302作为临时重定向,当该网站临时维护时,不想拒绝访问的用户,可以用到临时重定向使网站跳转到另一个可以提供服务的网站。
7.HTTP常见Header
①Content-Type:: 数据类型(text/html等)在上文我们使用过。
②Content-Length: 正文的长度。
③Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上。
④User-Agent: 声明用户的操作系统和浏览器版本信息。
我们通过Windows环境下的浏览器打开qq的官网观察下载页面,会发现下载页面直接为Windows版本下载。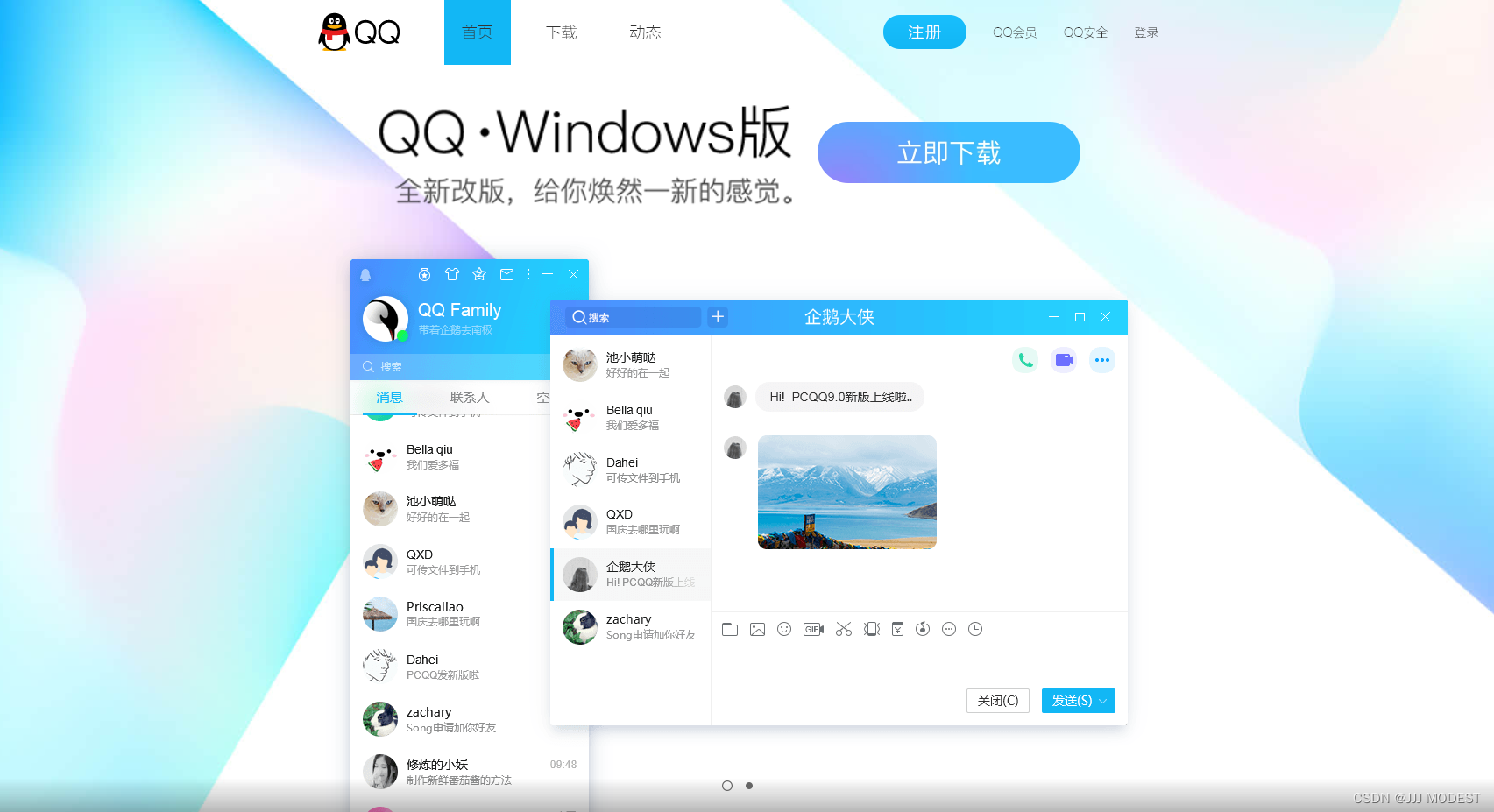
通过手机浏览器打开qq的官网,会发现下载页面会变为qq手机版。

这是依据什么来改变响应界面呢,与User-Agent这个信息密切相关。
⑤referer: 表示当前页面是从哪个页面跳转过来的。
⑥Location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问。
⑦Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能。
在讲Cookie之前我们要知道HTTP协议的特点之一是无状态,什么是无状态呢,简单就是HTTP协议本事并不会记录你请求资源的行为,请求过了再请求HTTP协议本事并不会记录你当前已经请求过了。但是我们当前所知道的浏览记录等信息都是显而易见被记录下来的信息,这些信息都是依靠HTTP周边策略来实现的,比如说Cookie策略。
这个Cookie在哪其作用呢?
像我们每次登入一个常用的网站,关闭之后再次进入,会发现登陆的账号还在保持登陆状态,这就是cookie起了作用,当我们禁止cookie就会发现每次登陆之后关闭再打开,会让你再次登陆,并不会延续你上次登陆的用户。
我们尝试讲Cookie体现在代码中
代码:

现象:

一般流程为我们客户端讲登陆信息输入,登录信息就会被记录到服务器中,当再次访问网站时, 登陆信息就会通过Set-Cookie发送到客户端。
当然Cookie不仅仅是存在于服务端,也有可能存在于浏览器维护的文件中。
我的登录信息这么简单的存储在本地文件中,那木马病毒等不正当手段随便就可以获取我的登陆信息岂不是我的上网安全岌岌可危,所以我们要使用Cookie和Session组合起来的方式来保证安全。
客户端输入登陆信息,然后将登陆信息发给服务端,服务端根据登陆信息形成Session文件,该文件的文件名具有唯一性,该文件名被称为session_id。服务端再将该session_id发给客户端,客户端会将session_id写入本地的cookie中。在cookie中的表现只出现session_id。下次登陆时客户端就会将session_id发送给服务端,服务端依据session_id来判断是否有权利享有对应的资源。
那这个session_id会不会也会被轻易盗取,也是会的,这个问题没有根本解决。但是session_id丢掉之后,你丢掉的只是session_id,你的信息会保存在服务端。大型的服务端有很不错的防护系统。至于更多的知识,感兴趣的同学可以去了解一下更细致的讲解。
关于Cookie和Session的要点:
Cookie的Expires属性指定了cookie的生存期,默认情况下coolie是暂时存在的,他们存储的值只在浏览器会话期间存在,当用户退出浏览器后这些值也会丢失,如果想让cookie存在一段时间,就要为expires属性设置为未来的一个过期日期。现在已经被max-age属性所取代,max-age用秒来设置cookie的生存期。因此当没有设定过期时间时,则退出当前会话时cookie失效。
Session可以存放各种类别的数据,相比只能存储字符串的cookie,能给开发人员存储数据提供很大的便利。
SessionID可以存储每个用户Session的代号,是一个不重复的长整型数字。
单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
目前此篇文章就写到这里,关于HTTPS协议将会在下篇与大家见面,如有错误请指出,感谢观看,我们下次再见。
相关文章:
HTTP协议——详细讲解
目录 一、HTTP协议 1.http 2.url url的组成: url的保留字符: 3.http协议格式编辑 ①http request ②http response 4.对request做出响应 5.GET与POST方法 ①GET ②POST 7.HTTP常见Header ①Content-Type:: 数据类型(text/html等)在上文…...
echonet-dynamic代码解读
1 综述 一共是这些代码,我们主要看echo.py,segmentation.py,video.py,config.py。 2 配置文件config.py 基于配置文件设置路径。 """Sets paths based on configuration files."""import conf…...
大气温室气体浓度不断增加,导致气候变暖加剧,随之会引发一系列气象、生态和环境灾害怎样解决?
大气温室气体浓度不断增加,导致气候变暖加剧,随之会引发一系列气象、生态和环境灾害。如何降低温室气体浓度和应对气候变化已成为全球关注的焦点。海洋是地球上最大的“碳库”,“蓝碳”即海洋活动以及海洋生物(特别是红树林、盐沼和海草&…...
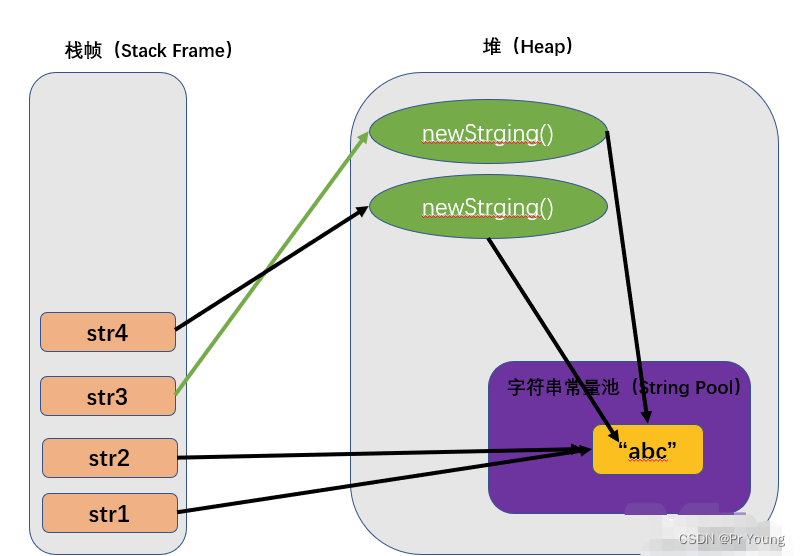
字符串内存分配
涉及三块区域:栈,堆,字符串常量池(jdk1.7之前在方法区,jdk1.7之后在堆中) 关于字符串常量池到底在不在堆中: jdk1.6及以前,方法区独立存在(不在堆里面)&…...

CHI协议通道概念
通道定义为一组结点之间的通信信号。CHI协议定义了四种通道,请求REQ、响应RSP、侦听SNP和数据DAT。 RN结点上CHI协议通道信号组包括: 请求发送端信号,RN结点发送读/写等请求,从不接收请求响应接收端信号,RN结点接收来…...
XQuery 简介
XQuery 简介 解释 XQuery 最佳方式是这样讲:XQuery 相对于 XML 的关系,等同于 SQL 相对于数据库表的关系。 XQuery 被设计用来查询 XML 数据 - 不仅仅限于 XML 文件,还包括任何可以 XML 形态呈现的数据,包括数据库。 您应该具备的…...

Spring的Bean的生命周期与自动注入细节
1. Bean的生命周期 通过一个LifeCycleBean和一个MyBeanPostProcessor来观察Bean的生命周期: 构造(实例化)->依赖注入(前后处理)->初始化(前后处理)->销毁 LifeCycleBean Component public class LifeCycleBean {private static final Logger log LoggerFactory.g…...
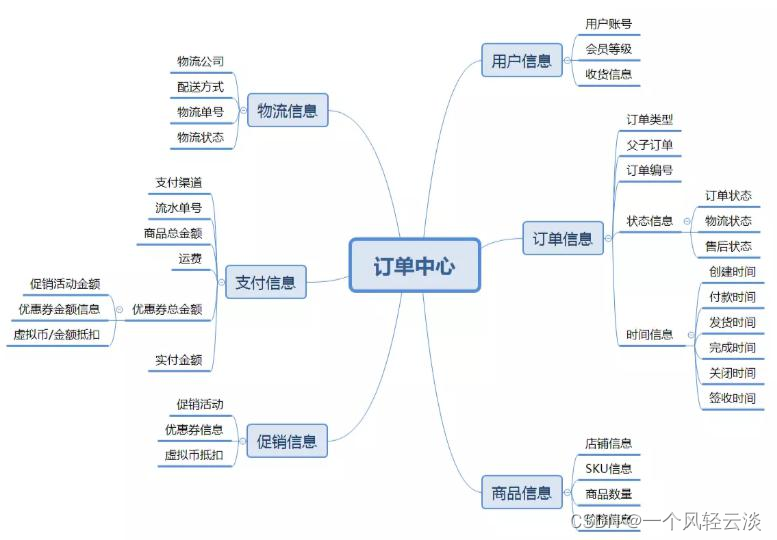
谷粒商城:订单中心概念解析
1、订单中心 电商系统涉及到 3 流,分别时信息流,资金流,物流,而订单系统作为中枢将三者有机的集 合起来。 订单模块是电商系统的枢纽,在订单这个环节上需求获取多个模块的数据和信息,同时对这 些信息进行加…...

快递员配送手机卡,要求当面激活有“猫腻”吗?
咨询:快递员配送手机卡,要求当面激活有“猫腻”吗?有些朋友可能在网上看到了一些关于快递小哥激活会采集信息的文章,所以觉得让快递小哥激活流量卡并不安全,其实,哪有这么多的套路,只要你自己在…...

Sage X3 ERP的称重插件帮助食品和化工企业实现精细化管理
目录 需要称重插件管理的行业客户 Sage X3 ERP称重插件管理的两个关键单位 Sage X3 ERP称重插件的特色 Sage X3 ERP称重插件管理的重要性 需要称重插件管理的行业客户 术语“实际重量”表示在销售和运输时捕获的物品重量。生产销售家禽、肥料、钢材或任何其他需要跟踪实…...
【笔试强训】Day_01
目录 一、选择题 1、 2、 3、 4、 5、 6、 7、 8、 9、 10、 二、编程题 1、组队竞赛 2、删除公共字符 一、选择题 1、 以下for循环的执行次数是() for(int x 0, y 0; (y 123) && (x < 4); x); A 、是无限循环 B 、循环次…...
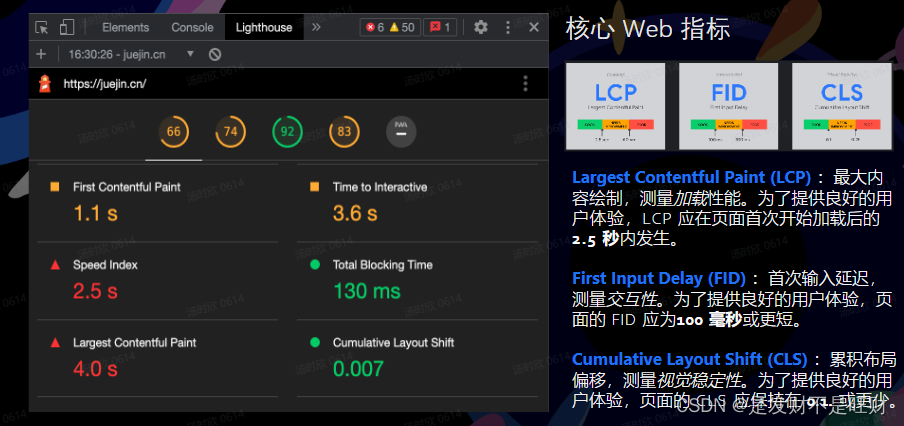
字节跳动青训营--前端day9
文章目录前言PC web端一、 前端Debug的特点二、 前端Debug的方式1. 浏览器动态修改元素和样式2. Console3. Sorce Tab4. NetWork5. Application6. Performancee7. Lighthouse移动端调试IOSAndroid通过代理工具调试前言 仅以此文章记录学习。 PC web端 一、 前端Debug的特点 …...

如何把模糊的照片还原?
在我们工作和学习中,经常需要各种各样的照片,方便我们需要时可以使用。比如写文档就需要添加图片、或者上传文章、视频等都需要使用图片。由于网络上的图片质量都不一样,难免会遇到不能满足自己的需求。如果是遇到了模糊的照片,如…...

29-Golang中的切片
Golang中的切片基本介绍切片在内存中的形式切片使用的三种方式方式一:方式二:方式三:切片使用的区别切片的遍历切片注意事项和细节说明append函数切片的拷贝操作string和slice基本介绍 1.切片是数组的一个引用,因此切片是引用类型…...

闲聊一下开源
今天看了下中国开源开发者报告,感觉收货不少,针对里面的内容,我也加入一些自己的理解,写下来和大家一起闲聊一下。 AI 时至今日,我说一句AI已经在我国几乎各个行业都能找到应用,应该没人反对吧࿱…...

用这4招优雅的实现Spring Boot 异步线程间数据传递
Spring Boot 自定义线程池实现异步开发相信大家都了解,但是在实际开发中需要在父子线程之间传递一些数据,比如用户信息,链路信息等等 比如用户登录信息使用ThreadLocal存放保证线程隔离,代码如下: /*** author 公众号…...

RocketMQ源码分析之NameServer
1、RocketMQ组件概述 NameServer NameServer相当于配置中心,维护Broker集群、Broker信息、Broker存活信息、主题与队列信息等。NameServer彼此之间不通信,每个Broker与集群内所有的Nameserver保持长连接。 2、源码分析NameServer 本文不对 NameServer 与…...

如何优化认知配比
战略可以归结为三种要素的合理配比。我们对战略的一个定义是:在终局处的判断。这其实来自于一个宗教的命题——面死而生。死是终局,生是过程,当你想做一个思想实验,或者是你真的有缘能够直面死亡,你所有关于生的认知就…...

WuThreat身份安全云-TVD每日漏洞情报-2023-02-15
漏洞名称:TOTOLINK A7100RU 安全漏洞 漏洞级别:严重 漏洞编号:CVE-2023-24276,CNNVD-202302-367 相关涉及:TOTOlink A7100RU(V7.4cu.2313_B20191024)路由器 漏洞状态:POC 参考链接:https://tvd.wuthreat.com/#/listDetail?TVD_IDTVD-2023-02977 漏洞名称:Windows NTLM 特权提…...
Unreal Engine角色涌现行为开发教程
在本文中,我将讨论如何使用虚幻引擎、强化学习和免费的机器学习插件 MindMaker 在 AI 角色中生成涌现行为。 目的是感兴趣的读者可以使用它作为在他们自己的游戏项目或具体的 AI 角色中创建涌现行为的指南。 推荐:使用 NSDT场景设计器 快速搭建 3D场景。…...

NotebookLM笔记整理实战指南:5步打造自动关联知识图谱的智能笔记系统
更多请点击: https://intelliparadigm.com 第一章:NotebookLM笔记整理实战指南:5步打造自动关联知识图谱的智能笔记系统 NotebookLM 是 Google 推出的面向研究者与开发者的第一方 AI 笔记工具,其核心能力在于基于用户上传文档构建…...

AgentStack:构建生产级AI智能体应用的一站式平台
1. 项目概述:AgentStack,一个为AI智能体打造的“操作系统”如果你正在开发AI应用,或者想让你的产品具备AI能力,那你一定遇到过这样的困境:大模型能力虽强,但让它稳定、可控、安全地接入你的业务系统&#x…...

开源短剧源码|短剧小程序源码短剧App源码双端适配,即开即用
在当下这个注意力稀缺的时代,短剧以其“爽点密集、节奏明快、情感代入强”的特点,迅速抢占了海量用户的碎片化时间。无论是国内的微信/抖音小程序生态,还是出海的短剧App市场,都呈现出爆发式的增长态势。然而,对于想要…...

深度解析:PC端即时通讯防撤回功能的技术实现
深度解析:PC端即时通讯防撤回功能的技术实现 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitcode.com/GitHub_…...

从夏普IGZO技术授权看显示面板产业的技术转移与战略博弈
1. 从一则旧闻看显示产业的全球棋局:技术、资本与生存的博弈2013年夏天,一则来自日本的消息在科技产业圈,特别是显示面板和半导体供应链领域,激起了不小的涟漪。全球知名的消费电子品牌夏普公司,宣布了一项与中国国有企…...
)
NotebookLM无法识别PDF表格?手把手复现Google Research 2024最新LayoutParser适配方案(附可运行Colab脚本)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM无法识别PDF表格?手把手复现Google Research 2024最新LayoutParser适配方案(附可运行Colab脚本) NotebookLM 默认使用轻量级 PDF 解析器(如 Py…...

使用Node.js在虚拟机后端服务中集成Taotoken多模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Node.js在虚拟机后端服务中集成Taotoken多模型调用 在虚拟机环境中部署Node.js后端服务时,直接对接多个大模型厂商…...

ProxyClaw住宅代理实战:破解反爬虫,赋能AI智能体与数据工程
1. 项目概述:ProxyClaw,一个为AI与数据工程而生的住宅代理网络 如果你正在构建一个需要从互联网上大规模、稳定抓取数据的AI智能体、自动化机器人或者数据管道,那么“被目标网站封禁”这件事,大概率是你最头疼的日常。无论是电商平…...

Swift原生大语言模型推理引擎llmfarm_core.swift集成与优化指南
1. 项目概述:一个为Swift生态打造的本地大语言模型推理引擎 最近在折腾一个iOS上的AI应用,想把一些轻量级的开源大语言模型(LLM)直接跑在手机端。大家都知道,现在主流的LLM推理框架,像llama.cpp、ollama&am…...

基于reflectt-node的WebSocket RPC实践:构建实时协作待办应用
1. 项目概述与核心价值 最近在折腾一个需要实时双向通信的Web应用,传统的轮询和长轮询方案在性能和资源消耗上总感觉差那么点意思。后来把目光投向了WebSocket,但原生WebSocket的API相对底层,自己管理连接、心跳、重连、消息序列化这些琐事&a…...