cmu 445 poject 3笔记
2022年的任务 https://15445.courses.cs.cmu.edu/fall2022/project3/
task1, 从磁盘读取数据的算子
task2, 聚合和join算子
task3, sort,limit,topn算子,以及sort+limit->TopN优化
leaderboard没做
本文不写代码,只记录遇到的一些思维盲点
Task1
scan
比较简单,参考filter算子的实现即可。
insert和delete
需要根据index对象的keyAttr来将原始的tuple转换为index的entry。
类似下面这样
for (auto it : indexs) {auto key_attrs = (it)->index_->GetKeyAttrs();std::vector<Value> index_cols(key_attrs.size());size_t i = 0;for (auto col_idx : key_attrs) {index_cols[i++] = (child_tuple.GetValue(&child_executor_->GetOutputSchema(), col_idx));}(it)->index_->DeleteEntry(Tuple(index_cols, (it)->index_->GetKeySchema()), child_rid,exec_ctx_->GetTransaction());}
Task 2
Aggregate聚合算子
- 补充hash表的计算函数CombineAggregateValues,这个比较简单,就是根据不同的算子做对应处理即可。
- 需要判断下input的结果是为空,对于count(*)算子,会累加一行,其他的算子都不处理
- 对于计算,需要先执行构建操作,后续调用聚合算子的next时结果都是从构建的结果里取
- 需要特别注意的是,如果是个空表,并且没有group by操作,也是需要返回结果的
第二步大概代码如下
while (true) {auto status = child_->Next(&child_tuple, &child_rid);if (!status) {first_next_ = true;break;}keys.group_bys_.clear();for (const auto &expr : key_exprs) {keys.group_bys_.emplace_back(expr->Evaluate(&child_tuple, child_->GetOutputSchema()));}vals.aggregates_.clear();for (const auto &expr : val_exprs) {vals.aggregates_.emplace_back(expr->Evaluate(&child_tuple, child_->GetOutputSchema()));}aht_.InsertCombine(keys, vals);}
第三步大概代码如下
aht_iterator_ = aht_.Begin();if (aht_iterator_ == aht_.End()) {// empty tableif (key_exprs.empty()) {vals.aggregates_.clear();for (uint32_t i = 0; i < plan_->agg_types_.size(); i++) {vals.aggregates_.emplace_back(ValueFactory::GetNullValueByType(TypeId::BIGINT));}aht_.InsertCombine(keys, vals);aht_iterator_ = aht_.Begin();std::vector<Value> cols;cols.insert(cols.end(), aht_iterator_.Val().aggregates_.begin(), aht_iterator_.Val().aggregates_.end());++aht_iterator_;*tuple = {cols, &GetOutputSchema()};return true;}}
Join算子
也是分为构建阶段和取数据阶段。
构建阶段,主要是把右表(内表)的数据读到一个数组里,用于后续跟左表(外表)的元素进行匹配。
取数据阶段就是读取左表的数据,然后去上面的数组里一行一行匹配。
需要注意的是,一行左表的数据,可能会对应多行右表的数据,因此需要遍历整个数组才行。
- 我的做法是记录一个右表的游标和一个左表的当前记录
- 每次取出左表的数据后,这个游标清零,从头开始匹配右表数据。匹配成功就返回
- 下次取数据时,判断这个游标是否到右表的尾部了,如果不是,那就继续匹配。
- 直到尾部后,再拉取一个左表的数据,从头开始匹配。
Task3
sort 算子
主要是排序算法的实现,需要判断下null的位置。
对于升序,null是最小的。对于降序,null是最大的。
auto comp = [&](Tuple &a, Tuple &b) -> bool {for (const auto &order : orders) {auto left = order.second->Evaluate(&a, GetOutputSchema());auto right = order.second->Evaluate(&b, GetOutputSchema());bool ret = true;if (left.IsNull()) {if (order.first == OrderByType::DESC) {ret = false;}} else if (right.IsNull()) {if (order.first != OrderByType::DESC) {ret = false;}} else {auto val = left.CompareEquals(right);if (val == CmpBool::CmpTrue) {continue;}val = left.CompareLessThan(right);if (val == CmpBool::CmpTrue) {if (order.first == OrderByType::DESC) {ret = false;}} else {if (order.first != OrderByType::DESC) {ret = false;}}}return ret;}return true;};
TopN算子
对于topN算子,使用堆来存limit个元素。
如果是降序的,就构建最小堆。这样,每次淘汰都是淘汰最小的值,最后堆里保存的是最大的limit个元素。
同理,如果是升序的,就构建最大堆。这样,每次淘汰的都是淘汰最大的值,最后堆里保存的是最小的limit个元素。
- std的priority_queue默认是最大堆,因此比较函数就按正常的排序规则就行(同sort的比较方式),它自动的反转构建堆。对于升序,就会构建最大堆;对于降序,就会构建最小堆
- 因为堆里的数据实际上跟最终的结果是相反的,因此在构建阶段,需要把堆里的数据取出来放到一个vector中,取的时候,从尾部到头部取出就行
sort+limit->TopN
需要递归处理, 先处理子算子,然后再处理本节点。
std::vector<AbstractPlanNodeRef> new_child;for (size_t i = 0; i < plan->GetChildren().size(); ++i) {new_child.emplace_back(OptimizeSortLimitAsTopN(plan->children_[i]));}if (plan->GetType() == PlanType::Limit) {if (plan->GetChildren().size() == 1 && new_child[0]->GetType() == PlanType::Sort) {auto sort = std::dynamic_pointer_cast<const SortPlanNode>(new_child[0]);auto limit = dynamic_cast<const LimitPlanNode *>(plan.get());SchemaRef schema = std::make_shared<const Schema>(plan->OutputSchema().GetColumns());auto ret = std::make_shared<TopNPlanNode>(schema, (new_child[0]->GetChildAt(0)), (sort)->GetOrderBy(),limit->GetLimit());return ret;}}return plan->CloneWithChildren(new_child);
相关文章:

cmu 445 poject 3笔记
2022年的任务 https://15445.courses.cs.cmu.edu/fall2022/project3/ task1, 从磁盘读取数据的算子 task2, 聚合和join算子 task3, sort,limit,topn算子,以及sortlimit->TopN优化 leaderboard没做 本文不写代码,只记录遇到的一些思维盲点 Task1 scan…...

CHAPTER 2 Zabbix界面操作
Zabbix界面操作2.1 Zabbix界面操作1.zabbix的web界面安装2.添加监控信息3.查看监控内容4.查看图像2.2 自定义监控与监控报警1.自定义监控1.1 说明1.2 预备知识2.实现自定义监控2.1 自定义语法2.2 agent注册2.3 在server端注册(web操作)2.4 查看监控图形2.3 监控报警1.第三方报警…...

keep-alive的使用-及遇到的问题
被keep-alive包括的的组件,当组件切换是不是走销毁流程,而是缓存起来 keep-alive有三个参数include匹配name名被缓存,exclude匹配name名不会被缓存,max被缓存组件数量 不写,组件默认全部缓存 <keep-alive ><…...
华为OD面试经验分享,尤其注意机试题部分
文章目录招聘流程和背景介绍面试准备机试题目类型和解答技巧在算法部分在操作系统部分面试官提问和答题技巧面试总结和建议推荐一些华为 od 常见的机试题题目:两数之和题目:二叉树的遍历题目:链表反转题目:最大子序和招聘流程和背…...

【Java】String、StringBuffer、StringBuilder的区别
一、String 由 char[] 数组构成,使用了 final 修饰,String的值是不可变的,这就导致每次对String的操作都会生成新的String对象,然后把指针指向新的引用对象,不仅效率低下,而且浪费大量优先的内存空间。 二…...

iOS开发:对Block使用的一次研究总结
在开发中Block是经常使用的,那我们就得知其然,知其所以然。 Block是什么? Block可以封装一个匿名函数为对象,并捕获上下文所需的数据,并传给目标对象在适当的时候回调。我们使用Block的目的其实就是回调传值,那我们去看看Block的底层,再深入了解一下Block。 Block的底…...

Spark 3.1.1 shuffle fetch 导致shuffle错位的问题
背景 最近从数据仓库小组那边反馈了一个问题,一个SQL任务出来的结果不正确,重新运行一次之后就没问题了,具体的SQL如下: select col1,count(1) as cnt from table1 where dt 20230202 group by col1 having count(1) > 1这个问题是偶发…...
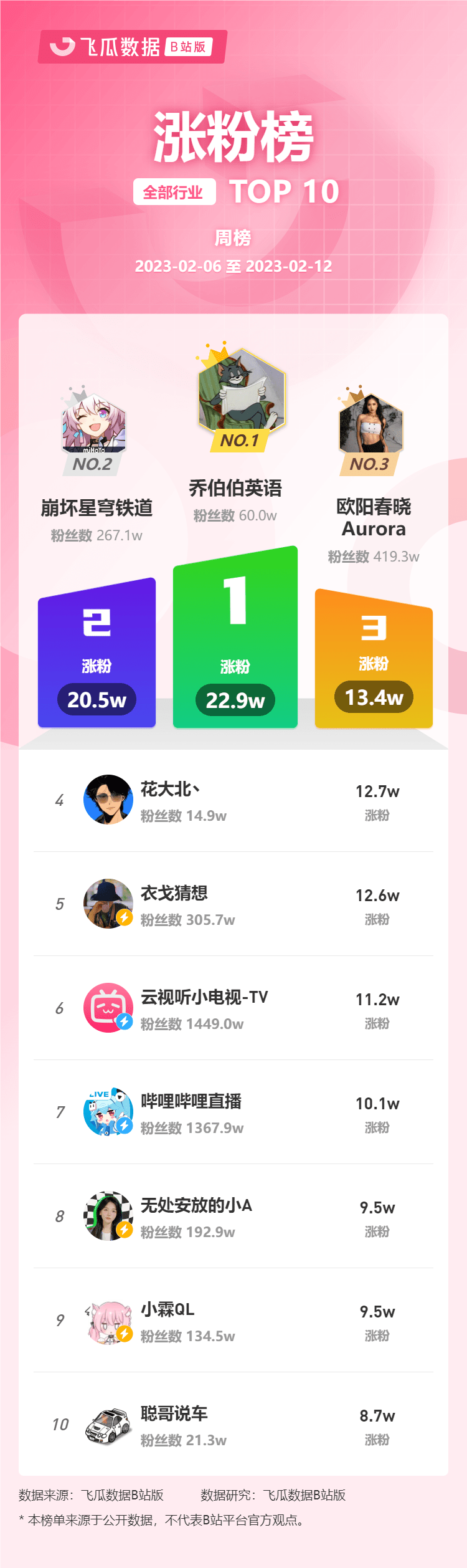
2月第2周榜单丨飞瓜数据B站UP主排行榜(哔哩哔哩平台)发布!
飞瓜轻数发布2023年2月6日-2月12日飞瓜数据UP主排行榜(B站平台),通过充电数、涨粉数、成长指数三个维度来体现UP主账号成长的情况,为用户提供B站号综合价值的数据参考,根据UP主成长情况用户能够快速找到运营能力强的B站…...
Jdk19 动态编译 Java源码为 Class 文件
动态编译 Java 源码为 Class一.背景1.Jdk 版本2.需求二.Java 源码动态编译实现1.Maven 依赖2.源码包装类3.Java 文件对象封装类4.文件管理器封装类5.类加载器6.类编译器三.动态编译测试1.普通测试类2.接口实现类3.测试四.用动态编译 Class 替换 SpringBoot 的 Bean(…...
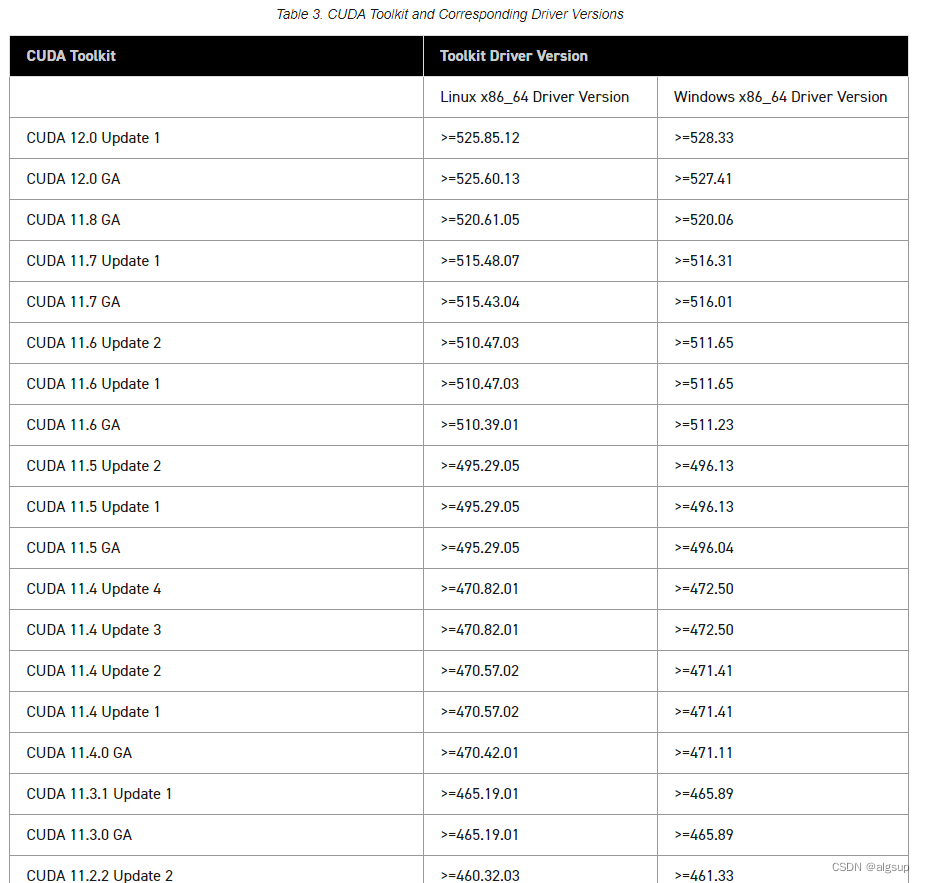
安装 GPU 版本的 tensorflow 完整版本
前言: 之前安装的 CPU 版本的 tensorflow 一直出问题,索性就直接安装 GPU 版本的 tensorflow 了(有了GPU 就不能浪费)。 安装过程: 1)看自己有无 GPU,找到对应 GPU 的版本:任务管理…...

BOM编程-设置地址栏上的URL
<!DOCTYPE html> <html> <head> <meta charset"utf-8"> <title>设置地址栏上的URL</title> </head> <body> <script> function go(){ // 获…...
设计模式之原型模式与建造者模式详解和应用
目录1 原型模式1.1 原型模式定义1.2 原型模式的应用场景1.3 原型模式的通用写法(浅拷贝)1.4 使用序列化实现深度克隆1.5 克隆破坏单例模式1.6 原型模式在源码中的应用1.7 原型模式的优缺点1.8 总结2 建造者模式2.1 建造者模式定义2.2 建造者模式的应用场…...

C语言(函数和递归)
函数是完成特定任务的独立程序代码单元。 目录 一.函数 1.创建一个简单的函数 2.定义带形式参数的函数 3.使用return从函数中返回值 二.递归 一.函数 1.创建一个简单的函数 #include <stdio.h> void print(void); //函数原型 int main(){ print(); //函…...

快乐的shell命令行
快乐的shell命令行 PART1——基础 1.权限 #超级用户权限$普通用户 2.复制粘贴 复制:鼠标左键沿着文本拖动高亮的文本被复制到X管理的缓冲区(或者双击一个单词)粘贴:鼠标中键 3.简单命令 时间和日期date当前月份的日历cal磁…...

大数据面试题flume篇
1.Flume 的Source,Sink,Channel 的作用?你们Source 是什么类型? 1. 作用 (1)Source组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括 avro、thrift、exec、jm…...
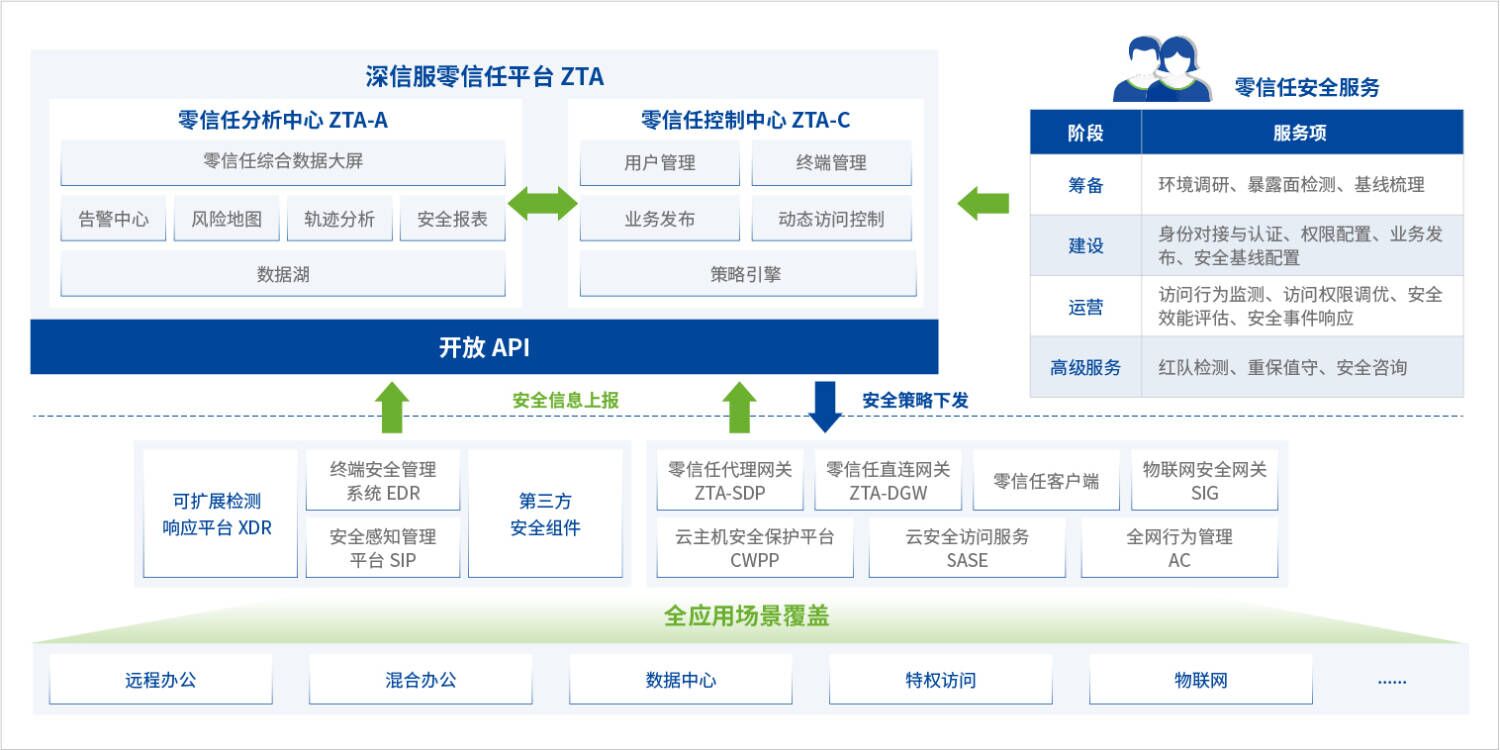
零信任-深信服零信任aTrust介绍(5)
深信服零信任aTrust介绍 深信服是国内领先的互联网信任服务提供商,也是国内首家通过认证的全球信任服务商。深信服零信任是其中一项核心的信任技术,主要针对身份认证、数字签名、数字证书等方面的信任问题。 深信服零信任提供了一种新的安全保护模式…...
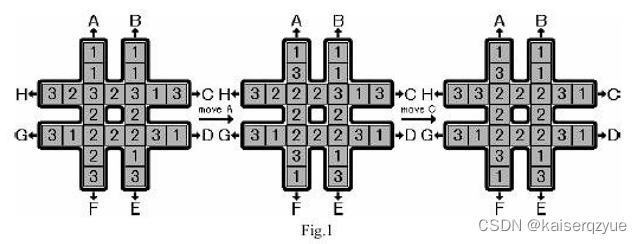
UVa 1343 The Rotation Game 旋转游戏 IDA* BFS 路径还原
题目链接:The Rotation Game 题目描述: 给定二十四个整数,这二十四个整数由八个一,八个二,八个三组成,从左到右,从上到下依次描述下图方格中的数字: 例如上图左边对应的输入就是[1,…...
硬件学习 软件Cadence day02 画原理图的基本操作 (键盘快捷键 , 原理图设计流程 , 从开始到导出网表流程)
1. ORCAD Capture cls 界面的快捷键 键盘 按键对应的操作I放大 (可以滚轮操作)O缩小 (可以滚轮操作)W画线Esc退出现在的状态 (画图界面 右键 End xxx)N放置网络标号J放置节点 (控制…...
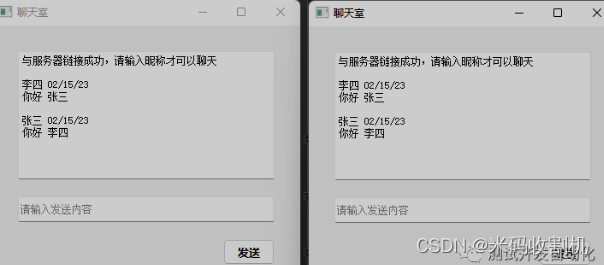
【python】基于Socket的聊天室Python开发
基于Socket的聊天室Python开发一、Socket简述二、创建服务端Server2.1 创建服务端初始化2.2 监听客户端连接2.3 处理客户端消息三、创建客户端Client3.1 创建服务端初始化3.2 发送消息3.3 接收消息3.3 线程工作3.4 线程工作是不是挺好玩的呢?也可以作为课程设计哦&a…...

2023想转行软件测试的看过来,你想要了解的薪资、前景、岗位方向、学习路线都讲明白了
在过去的一年中,软件测试行业发展迅速,随着数字化技术应用的广泛普及,业界对于软件测试的要求也在持续迭代与增加。 同样的,有市场就有需求,软件测试逐渐成为企业中不可或缺的岗位,作为一个高薪又需求广的…...

工业物联网长距离蓝牙环境监测方案解析
1. 项目概述在工业物联网和远程环境监测领域,如何实现低功耗、长距离的数据传输一直是个技术难点。传统蓝牙技术受限于通信距离(通常10米以内),而Wi-Fi方案又面临功耗过高的问题。最近我在一个工厂环境监测项目中,成功…...

Laravel RSS聚合器larafeed:现代化内容聚合后端解决方案
1. 项目概述:一个为Laravel打造的现代化RSS聚合器如果你正在用Laravel构建一个内容聚合平台、新闻阅读器,或者只是想为自己的个人博客添加一个“我最近在读什么”的订阅墙,那么你很可能需要处理RSS或Atom源。手动解析这些XML格式的源、处理缓…...

绩效考核的量化迷思:如何衡量不可直接测量的技术贡献
一、量化绩效考核的困境:软件测试的“隐形”价值在软件行业的绩效考核体系中,量化指标似乎成了“公平”与“高效”的代名词。代码行数、Bug数量、测试用例覆盖率……这些清晰可统计的数字,被当作衡量技术人员贡献的核心标尺。然而,…...

VCF 9.1 新特性:安装器与 Fleet Depot 支持 HTTP 无认证离线软件源
VMware Cloud Foundation(VCF)9.0 推出了统一软件仓库(Software Depot),支持连接博通在线源或企业内部离线源。但在 9.0 中,离线源默认必须使用 HTTPS 基础认证,即使关闭 HTTPS 也依然需要认证,对纯内网环境很不友好。在 VCF 9.1…...

【文件上传绕过】十六—十八:巧用文件幻数与内容伪装突破类型校验
1. 文件幻数:藏在二进制里的身份证 每次上传图片时,你有没有好奇过系统是怎么判断"这张图真的是JPG"的?这就像超市扫码器识别商品条形码一样,计算机其实是通过读取文件开头的几个特殊字节——我们称之为**幻数ÿ…...

ComfyUI-Impact-Pack完整安装指南:为什么你的V8版本功能不全?终极解决方案
ComfyUI-Impact-Pack完整安装指南:为什么你的V8版本功能不全?终极解决方案 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, …...

Chromatic:掌握Chromium/V8的终极通用修改器,开启浏览器调试新纪元
Chromatic:掌握Chromium/V8的终极通用修改器,开启浏览器调试新纪元 【免费下载链接】chromatic Universal modifier for Chromium/V8 | 广谱注入 Chromium/V8 的通用修改器 项目地址: https://gitcode.com/gh_mirrors/be/chromatic 还在为浏览器调…...

Spring Boot + JWT 实现无状态认证
1. JWT JWT(JSON Web Token)是一种开放标准(RFC 7519),用于在网络应用环境间安全地将信息作为 JSON 对象传输。JWT 是目前最流行的跨域认证解决方案,特别适合前后端分离的架构。 1.1 JWT 的结构 JWT 由三…...

Android 14 + Linux 6.1 平台 RTL8822CE Wi‑Fi 适配实战:从 PCI 已枚举到成功扫描热点
摘要 在 Android 14 Linux 6.1 的移植过程中,RTL8822CE Wi‑Fi 很容易出现一种“硬件已经被 PCI 枚举到,但系统就是没有 wlan0”的尴尬状态。本文复盘一次完整的 RTL8822CE 适配过程,最终定位出两个连续阻塞点:第一,目…...

一天怎么完成论文初稿
写论文这件事,从选题到完稿,哪一步都能卡掉你半条命。我身边不少读研读博的同学,白天泡实验室做实验,晚上挤时间写论文,熬了一两个月出初稿,结果格式不对、文献零散,还要和同门改来改去…...