csv文件完整操作总结
csv文件完整操作总结
1.概述
csv 模块主要用于处理从电子数据表格Excel或数据库中导入到文本文件的数据,通常简称为 comma-separated value (CSV)格式因为逗号用于分离每条记录的各个字段。
2.读写操作
2.1.测试数据
创建一个test.csv文件,复制下面内容到文件中
"Title 1","Title 2","Title 3","Title 4"
1,"a",08/18/07,"å"
2,"b",08/19/07,"∫"
3,"c",08/20/07,"ç"
2.2.读取
从 CSV 文件中读取数据,可以使用 reader() 函数来创建一个读取对象。 这个读取对象顺序处理文件的每一行,可以把它当成迭代器使用, 例如:
import csvwith open('test.csv', 'rt') as f:reader = csv.reader(f)for row in reader:print(row)
reader() 的第一个参数指源文本,在这个例子中,是一个文件,但它可以是任何可迭代对象( StringIO 实例,list 等)。第二个参数是可选的,可用于控制输入的数据如何被解析。
['Title 1', 'Title 2', 'Title 3', 'Title 4']
['1', 'a', '08/18/07', 'å']
['2', 'b', '08/19/07', '∫']
['3', 'c', '08/20/07', 'ç']
2.3.写入
写入 CSV 文件和读取它们一样简单。使用 writer() 方法创建一个写入对象,然后使用 writerow() 去输出每一行。
import csvunicode_chars = 'å∫ç'with open('testout.csv', 'wt') as f:writer = csv.writer(f)writer.writerow(('Title 1', 'Title 2', 'Title 3', 'Title 4'))for i in range(3):row = (i + 1,chr(ord('a') + i),'08/{:02d}/07'.format(i + 1),unicode_chars[i],)writer.writerow(row)print(open('testout.csv', 'rt').read())
这个例子的输出和上面读取的例子看起来有些不同,是因为这里有的值没有加引号
Title 1,Title 2,Title 3,Title 4
1,a,08/01/07,å
2,b,08/02/07,∫
3,c,08/03/07,ç2.4.引号
写入时,默认的引用行为不同,所以之前示例中的第二和第三个字段未被引用。 要添加引号,请将 quoting 参数设置为其他引用模式。
writer = csv.writer(f, quoting=csv.QUOTE_NONNUMERIC)
在这个例子中, QUOTE_NONNUMERIC 会给所有字段值不是数字的值添加引号
"Title 1","Title 2","Title 3","Title 4"
1,"a","08/01/07","å"
2,"b","08/02/07","∫"
3,"c","08/03/07","ç"
有四种不同的引用选项,在 csv 模块中被定义为常量。
- QUOTE_ALL :无论什么类型的字段都会被引用。
- QUOTE_MINIMAL:这是默认的选项,使用指定的字符引用各字段(如果解析器被配置为相同的 dialect 和选项时,可能会让解析器在解析时产生混淆)。
- QUOTE_NONNUMERIC:引用那些不是整数或浮点数的字段。当使用读取对象时,如果输入的字段是没有引号的,那么它们会被转换成浮点数。
- QUOTE_NONE:对所有的输出内容都不加引用,当使用读取对象时,引用字符看作是包含在每个字段的值里(但在正常情况下,它们被当成定界符而被去掉)。
3.编码风格
其实没有一个标准定义这类逗号分隔值的文件,所以解析器需要很灵活,通过很多参数去控制如何解析 csv 或给其写入数据。但这并不是每个参数在写入或读取 csv 时分别传入,而是统一分组为一个 编码风格 对象。
3.1.查看编码风格
Dialect 类可以通过名字注册,因此 csv 模块调用它时不必预先知道相关的参数设置。所有注册过的编码风格列表可以通过 list_dialects() 方法查看。
import csvprint(csv.list_dialects())
标准库提供了三种编码风格,分别为: excel, excel-tabs 和 unix。 excel 编码风格用来处理默认来自 Microsoft Excel 格式的数据的,同样可用于处理来自 LibreOffice 格式的。 unix 编码风格将所有字段通过双引号引用,并用 \n 做为每条记录的分隔符。
['excel', 'excel-tab', 'unix']
3.2.创建一个编码风格
如果不使用逗号分隔字段,输入文件使用竖杠( | ),新建一个testdata.pipes文件,复制下面内容到文件中作为测试数据。
"Title 1"|"Title 2"|"Title 3"
1|"first line
second line"|08/18/07
使用「竖杠」的编码风格,可以像使用逗号一样读取文件
import csvcsv.register_dialect('pipes', delimiter='|')with open('testdata.pipes', 'rt') as f:reader = csv.reader(f, dialect='pipes')for row in reader:print(row)
运行结果
['Title 1', 'Title 2', 'Title 3']
['1', 'first line\nsecond line', '08/18/07']
3.3.编码风格参数
编码风格指定解析或写入数据文件时使用的所有标记。下表列出了可以设定的属性,从字段的分隔方式到用于转义标记的字符。
| 属性 | 默认 | 含义 |
|---|---|---|
| delimiter | , | 字段分隔符(单字符) |
| doublequote | True | 控制 quotechar 实例是否翻倍 |
| escapechar | None | 用于表示转义序列的字符 |
| lineterminator | \r\n | 写入时用来换行的字符 |
| quotechar | " | 引用含特殊值字段的字符(一个字符) |
| quoting | QUOTE_MINIMAL | 控制前面表述的引用行为 |
| skipinitialspace | False | 是否在字段分隔符后忽略空格 |
这段程序演示了当使用几种不同的编码风格格式化时,相同的数据如何展示。
import csv
import syscsv.register_dialect('escaped',escapechar='\\',doublequote=False,quoting=csv.QUOTE_NONE,)
csv.register_dialect('singlequote',quotechar="'",quoting=csv.QUOTE_ALL,)quoting_modes = {getattr(csv, n): nfor n in dir(csv)if n.startswith('QUOTE_')
}TEMPLATE = '''\
Dialect: "{name}"delimiter = {dl!r:<6} skipinitialspace = {si!r}doublequote = {dq!r:<6} quoting = {qu}quotechar = {qc!r:<6} lineterminator = {lt!r}escapechar = {ec!r:<6}
'''for name in sorted(csv.list_dialects()):dialect = csv.get_dialect(name)print(TEMPLATE.format(name=name,dl=dialect.delimiter,si=dialect.skipinitialspace,dq=dialect.doublequote,qu=quoting_modes[dialect.quoting],qc=dialect.quotechar,lt=dialect.lineterminator,ec=dialect.escapechar,))writer = csv.writer(sys.stdout, dialect=dialect)writer.writerow(('col1', 1, '10/01/2010','Special chars: " \' {} to parse'.format(dialect.delimiter)))print()
运行结果
Dialect: "escaped"delimiter = ',' skipinitialspace = 0doublequote = 0 quoting = QUOTE_NONEquotechar = '"' lineterminator = '\r\n'escapechar = '\\'col1,1,10/01/2010,Special chars: \" ' \, to parseDialect: "excel"delimiter = ',' skipinitialspace = 0doublequote = 1 quoting = QUOTE_MINIMALquotechar = '"' lineterminator = '\r\n'escapechar = Nonecol1,1,10/01/2010,"Special chars: "" ' , to parse"Dialect: "excel-tab"delimiter = '\t' skipinitialspace = 0doublequote = 1 quoting = QUOTE_MINIMALquotechar = '"' lineterminator = '\r\n'escapechar = Nonecol1 1 10/01/2010 "Special chars: "" ' to parse"Dialect: "singlequote"delimiter = ',' skipinitialspace = 0doublequote = 1 quoting = QUOTE_ALLquotechar = "'" lineterminator = '\r\n'escapechar = None'col1','1','10/01/2010','Special chars: " '' , to parse'Dialect: "unix"delimiter = ',' skipinitialspace = 0doublequote = 1 quoting = QUOTE_ALLquotechar = '"' lineterminator = '\n'escapechar = None"col1","1","10/01/2010","Special chars: "" ' , to parse"
3.4.自动检测编码风格
配置一个输入文件的编码风格的最好的办法是提前知道哪种编码风格是正确的。对于那些编码风格未知的参数, Sniffer 类可用于做有效的猜测。 sniff() 方法会获取输入数据的一个样本和一个可选参数,给出可能的分隔符。
import csv
from io import StringIO
import textwrapcsv.register_dialect('escaped',escapechar='\\',doublequote=False,quoting=csv.QUOTE_NONE)
csv.register_dialect('singlequote',quotechar="'",quoting=csv.QUOTE_ALL)# 为所有已知的编码风格生成样本数据
samples = []
for name in sorted(csv.list_dialects()):buffer = StringIO()dialect = csv.get_dialect(name)writer = csv.writer(buffer, dialect=dialect)writer.writerow(('col1', 1, '10/01/2010','Special chars " \' {} to parse'.format(dialect.delimiter)))samples.append((name, dialect, buffer.getvalue()))# 猜测样本的编码风格,然后用猜测结果来解析数据。
sniffer = csv.Sniffer()
for name, expected, sample in samples:print('Dialect: "{}"'.format(name))print('In: {}'.format(sample.rstrip()))dialect = sniffer.sniff(sample, delimiters=',\t')reader = csv.reader(StringIO(sample), dialect=dialect)print('Parsed:\n {}\n'.format('\n '.join(repr(r) for r in next(reader))))
sniff() 方法返回一个包含了解析数据的参数的 Dialect 实例。结果并不一定是正确的,例如这个例子中的「escaped」。
python3 csv_dialect_sniffer.pyDialect: "escaped"
In: col1,1,10/01/2010,Special chars \" ' \, to parse
Parsed:'col1''1''10/01/2010''Special chars \\" \' \\'' to parse'Dialect: "excel"
In: col1,1,10/01/2010,"Special chars "" ' , to parse"
Parsed:'col1''1''10/01/2010''Special chars " \' , to parse'Dialect: "excel-tab"
In: col1 1 10/01/2010 "Special chars "" ' to parse"
Parsed:'col1''1''10/01/2010''Special chars " \' \t to parse'Dialect: "singlequote"
In: 'col1','1','10/01/2010','Special chars " '' , to parse'
Parsed:'col1''1''10/01/2010''Special chars " \' , to parse'Dialect: "unix"
In: "col1","1","10/01/2010","Special chars "" ' , to parse"
Parsed:'col1''1''10/01/2010''Special chars " \' , to parse'
相关文章:

csv文件完整操作总结
csv文件完整操作总结 1.概述 csv 模块主要用于处理从电子数据表格Excel或数据库中导入到文本文件的数据,通常简称为 comma-separated value (CSV)格式因为逗号用于分离每条记录的各个字段。 2.读写操作 2.1.测试数据 创建一个test.csv文…...
时间序列预测--基于CNN的股价预测(Matlab代码实现)
目录 💥1 概述 📚2 运行结果 🎉3 参考文献 👨💻4 Matlab代码 💥1 概述 时间序列预测有很多方法,如传统的时序建模方法ARIMA、周期因子法、深度学习网络等,本次实验采用最简单的…...
Dubbo与Spring Cloud优缺点分析(文档学习个人理解)
文章目录核心部件1、总体框架1.1 Dubbo 核心部件如下1.2 Spring Cloud 总体架构2、微服务架构核心要素3、通讯协议3.1 Dubbo3.2 Spring Cloud3.3 性能比较4、服务依赖方式4.1 Dubbo4.2 Spring Cloud5、组件运行流程5.1 Dubbo5.2 Dubbo 运行组件5.3 Spring Cloud5.4 Spring Clou…...

单元测试工具——JUnit的使用
⭐️前言⭐️ 本篇文章主要介绍单元测试工具JUnit的使用。 🍉欢迎点赞 👍 收藏 ⭐留言评论 📝私信必回哟😁 🍉博主将持续更新学习记录收获,友友们有任何问题可以在评论区留言 🍉博客中涉及源码…...

Linux_基本权限
Linux入门第二篇已送达! Linux_基本权限shell外壳权限Linux的用户分类角色划分Linux的文件文件类型查看权限目录的权限默认权限粘滞位shell外壳 为了保护操作系统,用户的指令不能由操作系统直接进行执行,需要一个中间者,比如Linu…...

3、JavaScript面试题
1, Js数据类型有哪些?数值、字符串、布尔、undefined、null、数组、对象、函数2, 引用类型和值类型的区别- 值类型存在于栈中, 存取速度快 引用类型存在于堆,存取速度慢- 值类型复制的是值本身 引用类型复制的是指向对象的指针- 值类型结构简单只包含基本数据, 引用…...

YUV图像
YUV的存储方式UV格式有两大类:planar和packed。对于planar的YUV格式,先连续存储所有像素点的Y,紧接着存储所有像素点的U,随后是所有像素点的V。对于packed的YUV格式,每个像素点的Y,U,V是连续交替存储的。YUV的采样主流…...
.net6API使用AutoMapper和DTO
AutoMapper,是一个转换工具,说到AutoMapper时,就不得不先说DTO,它叫做数据传输对象(Data Transfer Object)。 通俗的来说,DTO就是前端界面需要用的数据结构和类型,而我们经常使用的数据实体,是数…...
IO知识整理
IO 面向系统IO page cache 程序虚拟内存到物理内存的转换依靠cpu中的mmu映射 物理内存以page(4k)为单位做分配 多个程序访问磁盘上同一个文件,步骤 kernel将文件内容加载到pagecache多个程序读取同一份文件指向的同一个pagecache多个程…...
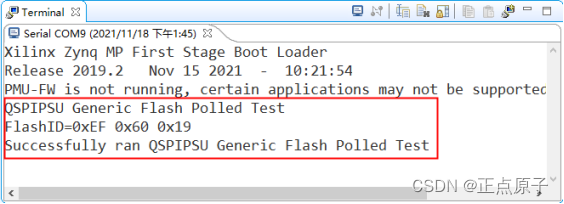
【正点原子FPGA连载】第十三章QSPI Flash读写测试实验 摘自【正点原子】DFZU2EG_4EV MPSoC之嵌入式Vitis开发指南
1)实验平台:正点原子MPSoC开发板 2)平台购买地址:https://detail.tmall.com/item.htm?id692450874670 3)全套实验源码手册视频下载地址: http://www.openedv.com/thread-340252-1-1.html 第十三章QSPI Fl…...
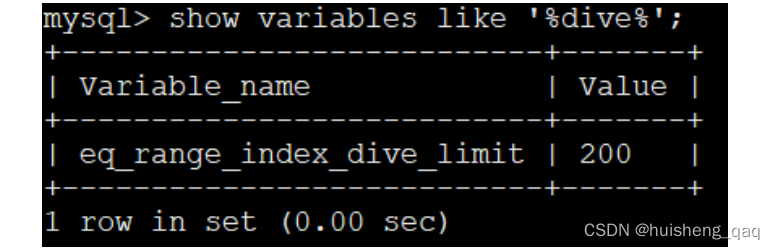
深入理解mysql的内核查询成本计算
MySql系列整体栏目 内容链接地址【一】深入理解mysql索引本质https://blog.csdn.net/zhenghuishengq/article/details/121027025【二】深入理解mysql索引优化以及explain关键字https://blog.csdn.net/zhenghuishengq/article/details/124552080【三】深入理解mysql的索引分类&a…...

LeetCode 141. 环形链表
原题链接 难度:easy\color{Green}{easy}easy 题目描述 给你一个链表的头节点 headheadhead ,判断链表中是否有环。 如果链表中有某个节点,可以通过连续跟踪 nextnextnext 指针再次到达,则链表中存在环。 为了表示给定链表中的…...
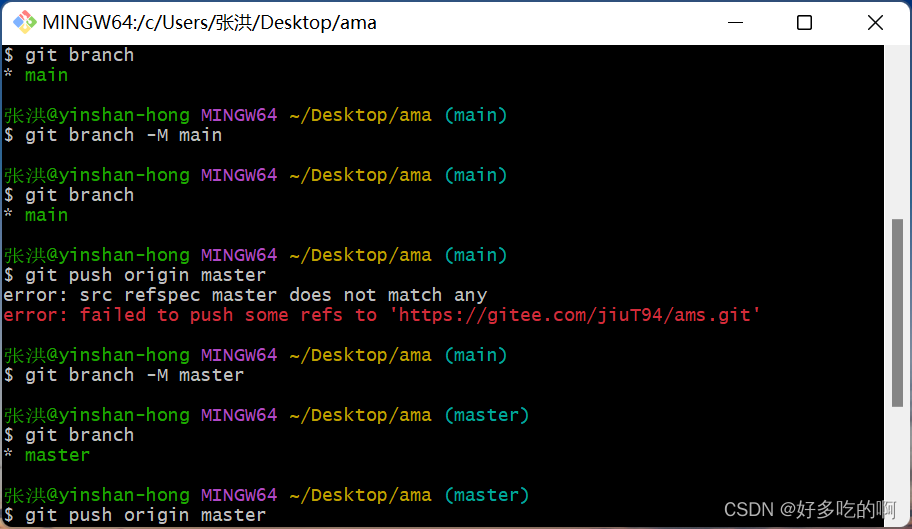
git提交
文章目录关于数据库:桌面/vue-admin/vue_shop_api 的 git 输入 打开 phpStudy ->mySQL管理器 导入文件同时输入密码,和文件名 node app.js 错误区: $ git branch // git branch 查看分支 只有一个main分支不见master解决: gi…...

Java中常见的编码集问题
收录于热门专栏Java基础教程系列(进阶篇) 一、遇到一个问题 1、读取CSV文件 package com.guor.demo.charset;import java.io.BufferedReader; import java.io.FileReader; import java.util.ArrayList; import java.util.HashMap; import java.util.L…...

数据结构与算法(Java版) | 就让我们来看看几个实际编程中遇到的问题吧!
上一讲,我给大家简单介绍了一下数据结构,以及数据结构与算法之间的关系,照理来说,接下来我就应该要给大家详细介绍线性结构和非线性结构了,但是在此之前,我决定还是先带着大家看几个实际编程中遇到的问题&a…...
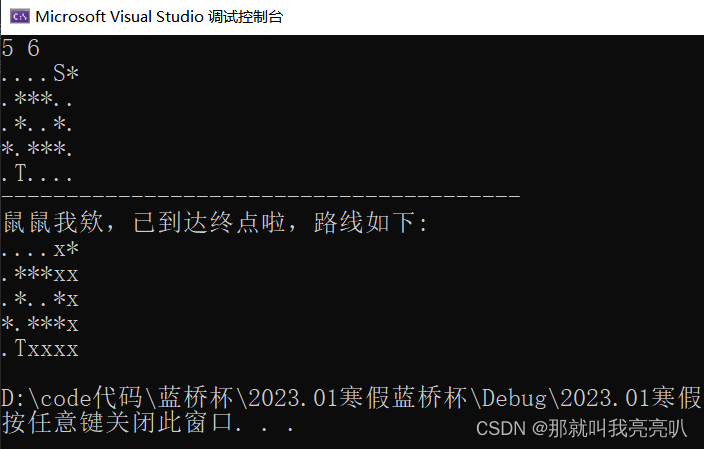
【C++算法】dfs深度优先搜索(上) ——【全面深度剖析+经典例题展示】
💃🏼 本人简介:男 👶🏼 年龄:18 📕 ps:七八天没更新了欸,这几天刚搞完元宇宙,上午一直练🚗,下午背四级单词和刷题来着,还在忙一些学弟…...
总结高频率Vue面试题
目录 什么是三次握手? 什么是四次挥手?(close触发) 什么是VUEX? 什么是同源----跨域? 什么是Promise? 什么是fexl布局? 数据类型 什么是深浅拷贝? 什么是懒加载&…...
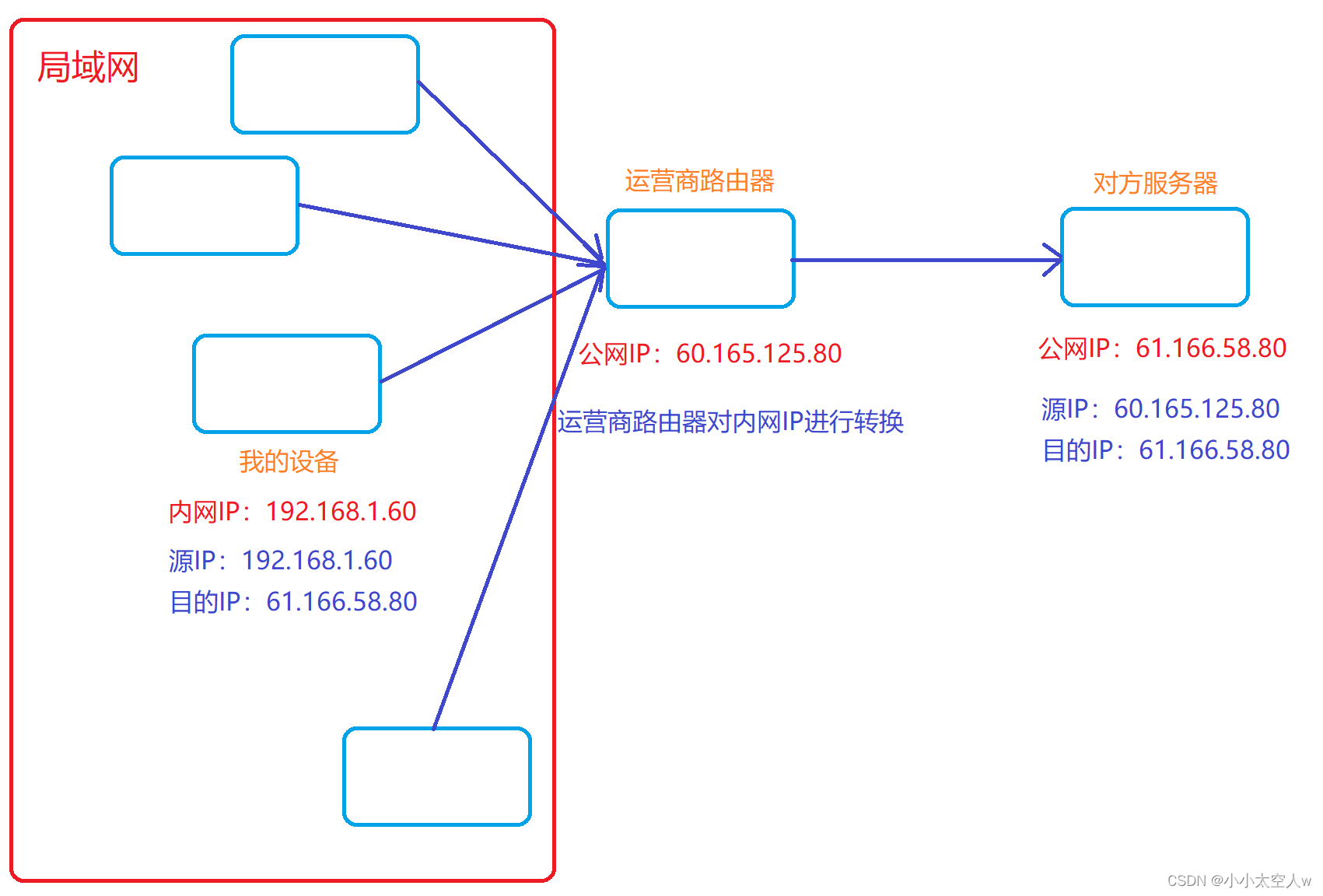
IP协议详解
目录 前言: IP协议 提出问题 解决方案 地址管理 子网掩码 路由选择 小结: 前言: IP协议作为网络层知名协议。当数据经过传输层使用TCP或者UDP对数据进行封装,然后当数据到达网络层,基于TCP或UDP数据包继续进行…...
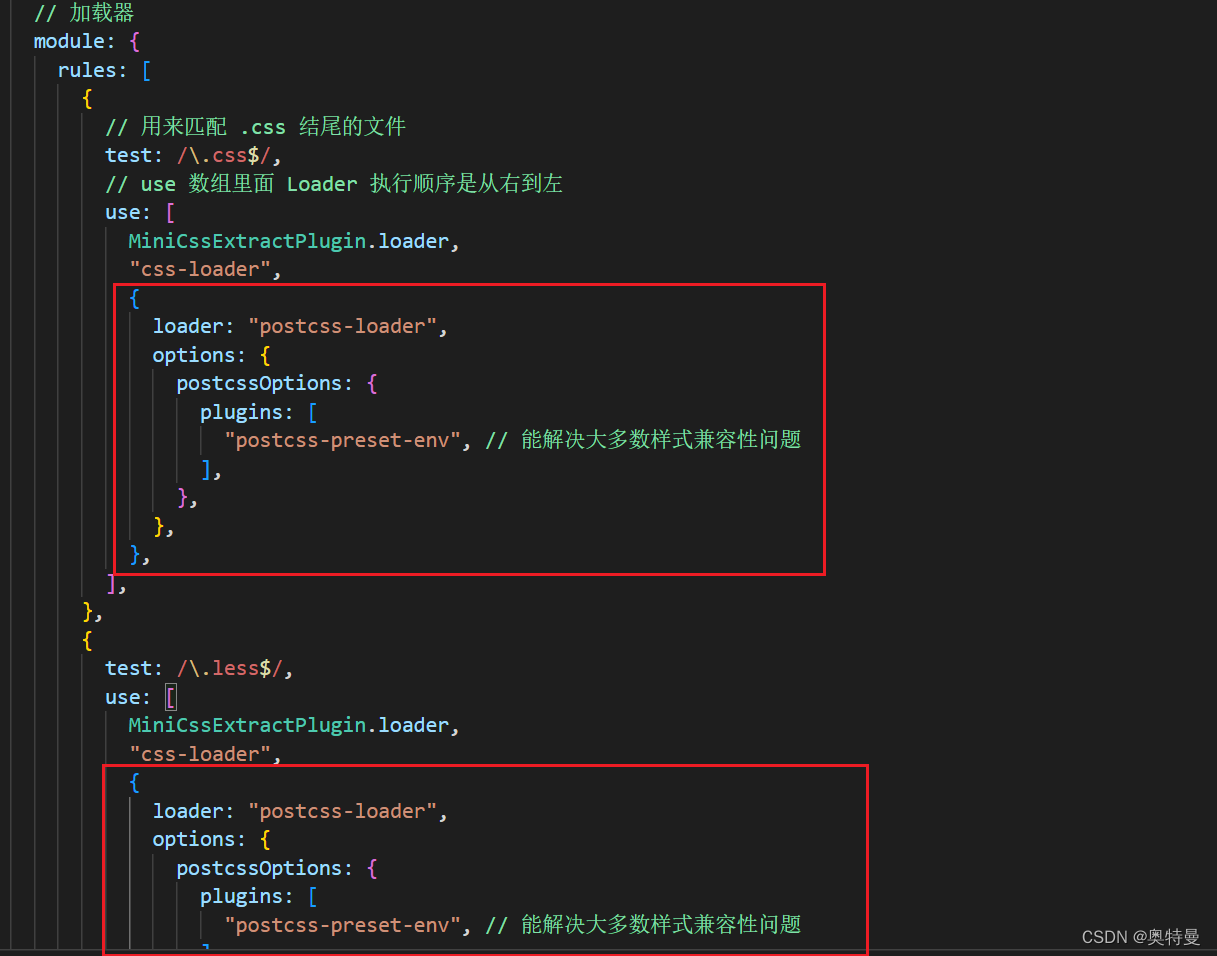
webpack5 基础配置
在开发中,我们会使用 vue、react、less、scss等语法进行开发项目,但是浏览器只能识别 js、css,或者说在js中使用了es6中的import 导入 这时候也需要打包工具去转换成浏览器可以识别的语句。 一、使用webpack 1.初始化package.json npm i…...
IDEA入门安装使用教程
一、背景 作为一个Java开发者,有非常多编辑工具供我们选择,比如Eclipse、IntelliJ IDEA、NetBeans、Visual Studio Code、Sublime Text等等,这些有免费也有收费的,但是就目前市场占比来说普遍使用Eclipse和IntelliJ IDEA这两款主…...
)
FPGA状态机实战:用Verilog实现自动售卖机(附三段式完整代码)
FPGA状态机实战:用Verilog实现自动售卖机(附三段式完整代码) 在数字电路设计中,状态机是最核心的设计思想之一。它能够将复杂的控制逻辑分解为有限的状态和状态之间的转换,使得设计更加清晰、可维护。自动售卖机作为一…...

【实战解析】PVE无显卡启动后网络失联:从硬件自检到系统绑定的完整排障指南
1. 无显卡启动的硬件准备与BIOS调试 当你准备在Proxmox VE(PVE)环境下实现无显卡启动时,首先要确保硬件层面支持这个特性。我遇到过不少用户直接拔掉显卡就期待系统能正常启动,结果发现连最基本的网络连接都失效了。这其实是个典型…...

利用OFA-Image-Caption自动生成Latex论文图表标题与描述
利用OFA-Image-Caption自动生成Latex论文图表标题与描述 写论文最烦人的步骤是什么?对我而言,除了反复修改格式,就是给那一大堆图表想标题和写描述了。一张图,你得想个既准确又简洁的标题,还得在正文里引用它…...

OpenClaw与nanobot镜像结合:打造个人AI研究助手全流程
OpenClaw与nanobot镜像结合:打造个人AI研究助手全流程 1. 为什么需要个人AI研究助手? 作为一名经常需要阅读大量论文的研究者,我发现自己每天要重复处理许多机械性工作:在多个学术平台检索最新文献、下载PDF并分类存储、提取关键…...

GTE文本向量助力智能写作:文本分类与情感倾向双重把关
GTE文本向量助力智能写作:文本分类与情感倾向双重把关 1. 智能写作的核心挑战:内容质量的多维评估 在内容创作领域,我们常常面临一个基本矛盾:如何同时保证文本的专业性和情感表达?传统写作辅助工具往往只能解决单一…...

AnythingtoRealCharacters2511应用案例:为小说角色生成真人参考形象
AnythingtoRealCharacters2511应用案例:为小说角色生成真人参考形象 1. 引言:从动漫到真人的魔法转换 想象一下,当你阅读一本精彩的小说时,脑海中浮现的角色形象突然变得栩栩如生。这正是AnythingtoRealCharacters2511能够实现的…...

深入OpenBMC散热控制:从IPMI命令到D-Bus,揭秘手动与自动模式切换
深入OpenBMC散热控制:从IPMI命令到D-Bus,揭秘手动与自动模式切换 在数据中心和服务器运维领域,散热控制一直是系统稳定性的关键因素。OpenBMC作为开源基板管理控制器,其散热管理机制直接影响到服务器的可靠性和能效比。本文将带您…...

用Logisim搞定六进制计数器:从真值表到同步置数/异步清零的保姆级布线教程
用Logisim搞定六进制计数器:从真值表到同步置数/异步清零的保姆级布线教程 第一次在Logisim里搭建计数器电路时,看着那些密密麻麻的逻辑门和跳线,我盯着屏幕发呆了半小时——明明按照课本上的真值表连接,仿真时却总是卡在某个状态…...

如何5分钟快速安装Ghidra:新手逆向工程终极指南
如何5分钟快速安装Ghidra:新手逆向工程终极指南 【免费下载链接】ghidra_installer Helper scripts to set up OpenJDK 11 and scale Ghidra for 4K on Ubuntu 18.04 / 18.10 项目地址: https://gitcode.com/gh_mirrors/gh/ghidra_installer Ghidra作为美国国…...
避坑指南:从FindService到SubscribeACK,一次讲透所有配置参数与常见故障)
SOME/IP服务发现(SD)避坑指南:从FindService到SubscribeACK,一次讲透所有配置参数与常见故障
SOME/IP服务发现实战手册:从参数配置到故障排查的完整指南 在车载以太网开发中,服务发现(Service Discovery)机制如同交通信号灯,协调着各个ECU节点之间的通信秩序。想象一下,当一辆智能汽车启动时…...