【Netty】字节缓冲区 ByteBuf (六)(上)
文章目录
- 前言
- 一、ByteBuf类
- 二、ByteBuffer 实现原理
- 2.1 ByteBuffer 写入模式
- 2.2 ByteBuffer 读取模式
- 2.3 ByteBuffer 写入模式切换为读取模式
- 2.4 clear() 与 compact() 方法
- 2.5 ByteBuffer 使用案例
- 总结
前言
回顾Netty系列文章:
- Netty 概述(一)
- Netty 架构设计(二)
- Netty Channel 概述(三)
- Netty ChannelHandler(四)
- ChannelPipeline源码分析(五)
网络数据传输的基本单位是字节,缓冲区就是存储字节的容器。在存取字节时,会先把字节放入缓冲区,再在操作缓冲区实现字节的批量存储以提升性能。
Java NIO 提供了ByteBuffer 作为它的缓冲区,但是这个类用起来过于复杂,而且也有些繁琐。因此,Netty 自己实现了 ByteBuf 以替代 ByteBuffer 。
本篇文章就来介绍Netty自己缓冲区的作用。
一、ByteBuf类
缓冲区可以简单理解为一段内存区域,某些情况下,如果程序频繁的操作一个资源(如文件或数据库),则性能会很低,此时为了提升性能,就可以将一部分数据暂时读入内存的一块区域之中,以后直接从此区域中读取数据即可。因为读取内存速度会很快,这样就可以提升程序的性能。
因此,缓冲区决定了网络数据处理的性能。
ByteBuf 被设计为一个可从底层解决 ByteBuffer 问题,并可满足日常网络应用开发需要的缓冲类型,其特点如下:
- 允许使用自定义的缓冲区类型。
- 通过内置的复合缓冲区类型实现了透明的零拷贝。
- 容量可以按需增长(类似于 JDK 的 StringBuilder)。
- 在读和写这两种模式之间切换不需要调用 ByteBuffer 的 flip()方法;
- 正常情况下具有比 ByteBuffer 更快的响应速度。
二、ByteBuffer 实现原理
使用 ByteBuffer 读写数据一般遵循以下4个步骤。
- 写入数据到 ByteBuffer 。
- 调用 flip()方法。
- 从 ByteBuffer 中读取数据。
- 调用clear()方法或者compact()方法。
当向 ByteBuffer 写入数据时, ByteBuffer 会记录下写了多少数据。一旦读取数据时,需要通过flip()方法将 ByteBuffer 从写入模式切换到读取模式。在读取模式下,可以读取之前写入 ByteBuffer 的所有数据。
一旦读完了所有数据,就需要清空缓冲区,让它可以再次被写入。有两种方式能清空缓冲区:调用clear()方法或者compact()方法。clear()方法会清空整个缓冲区。compact()方法只会清空已经读取过的数据,任何未读的数据都被移到缓冲区的起初处,新写入的数据将放到缓冲区未读数据的后面。
下面是一个 Java NIO 实现 服务器端实例中使用ByteBuffe的例子:
// 可写
if (key.isWritable()) {SocketChannel client = (SocketChannel) key.channel();ByteBuffer output = (ByteBuffer) key.attachment();output.flip();client.write(output);System.out.println("NonBlokingEchoServer -> " + client.getRemoteAddress() + ":" + output.toString());output.compact();key.interestOps(SelectionKey.OP_READ);
}
对于ByteBuffer,其主要有五个属性:mark,position,limit,capacity和array。这五个属性的作用如下:
- mark:记录了当前所标记的索引下标。
- position:对于写入模式,表示当前可写入数据的下标,对于读取模式,表示接下来可以读取的数据的下标。
- limit:对于写入模式,表示当前可以写入的数组大小,默认为数组的最大长度,对于读取模式,表示当前最多可以读取的数据的位置下标。
- capacity:表示当前数组的容量大小。
- array:保存了当前写入的数据。
上述变量存在以下关系:
0 <= mark <= position <=limit <= capacity
这几个数据中,除了 array 是用于保存数据的以外,这里最需要关注的是position,limit和capacity三个属性,因为对于写入和读取模式,这三个属性的表示的含义大不一样。
2.1 ByteBuffer 写入模式
如下图所示为初始状态和写入3个字节之后position,limit和capacity三个属性的状态:
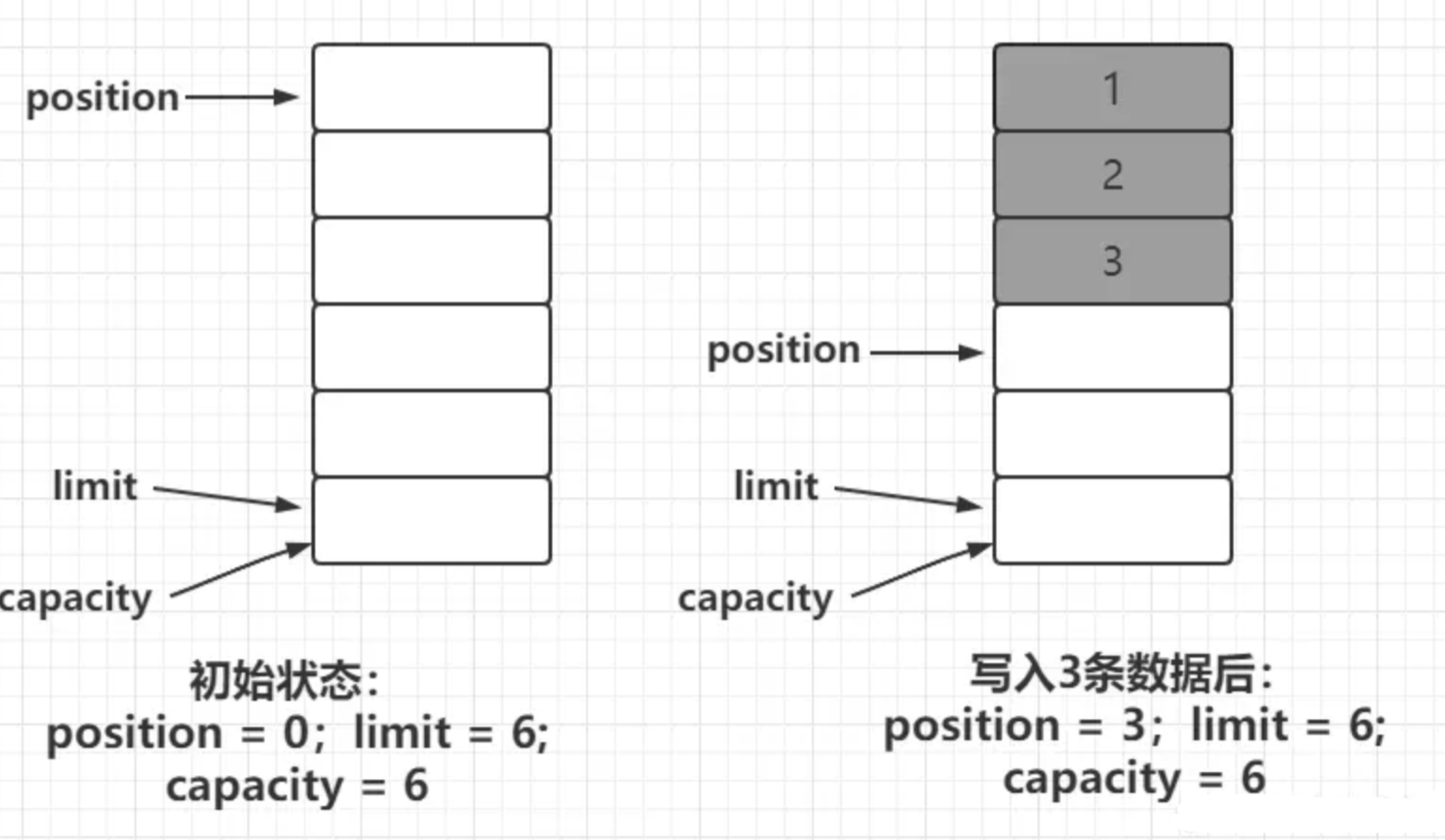
从图中可以看出,在写入模式下:
- limit指向的始终是当前可最多写入的数组索引下标。
- position指向的则是下一个可以写入的数据的索引位置。
- capacity则始终不会变化,即为数组大小。
2.2 ByteBuffer 读取模式
假设我们按照上述方式在初始长度为6的 ByteBuffer 中写入了三个字节的数据,此时我们将模式切换为读取模式,那么这里的position,limit和capacity则变为如下形式:
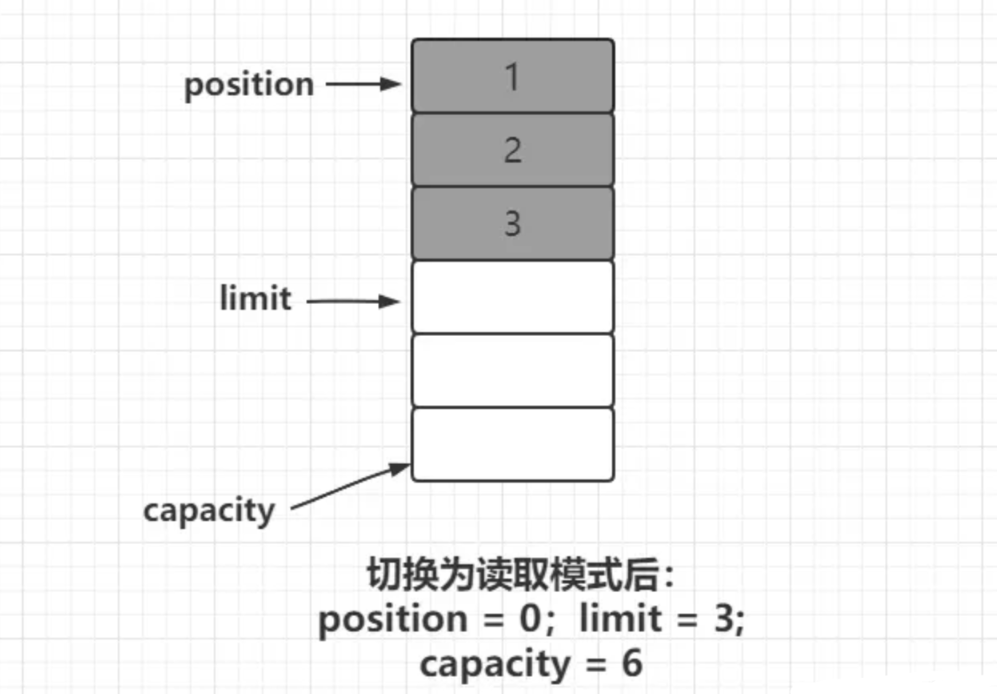
可以看到,当切换为读取模式之后:
-
limit则指向了最后一个可读取数据的下一个位置,表示最多可读取的数据。
-
position则指向了数组的初始位置,表示下一个可读取的数据的位置。
-
capacity还是表示数组的最大容量。
这里当我们一个一个读取数据的时候,position就会依次往下切换,当与limit重合时,就表示当前ByteBuffer中已没有可读取的数据了。
2.3 ByteBuffer 写入模式切换为读取模式
读写切换时要调用flip()方法。flip()方法的核心源码如下:
public final Buffer flip() {limit = position;position = 0;mark = -1;return this;
}
从上述源码可以看出,执行flip()后,将limit设置为position,然后将该position设置为0。
2.4 clear() 与 compact() 方法
一旦读取完 ByteBuffer 中的数据,需要让 ByteBuffer 准备好再次被写入。可以通过clear()或compact()方法来完成。
如果调用的是clear()方法,position将被设置为0,limit将被设置为capacity的值。换句话说,ByteBuffer 被清空了。ByteBuffer 中的数据并未清除,只是这些标记告诉我们可以从哪里开始往 ByteBuffer 里写数据。
如果 ByteBuffer 中有一些未读的数据,调用clear()方法,数据将被遗忘,意味着不再有任何标记标注哪些数据被读过,哪些还没有。
clear()方法的核心源码如下:
public final Buffer clear() {position = 0;limit = capacity;mark = -1;return this;
}
如果 ByteBuffer 中仍有未读的数据,且后续还需要这些数据,但是此时想要先写些数据,那么使用compact()方法。
compact()方法将所有的未读的数据复制到 ByteBuffer 起始处。然后将 position 设置到最后一个未读元素的后面。limit属性依然像clear()方法一样设置成capacity。现在 ByteBuffer 准备好写数据了,但是不会覆盖未读的数据。
compact()方法核心源码如下:
public ByteBuffer compact() {int pos = position();int lim = limit();assert (pos <= lim);int rem = (pos <= lim ? lim - pos : 0);unsafe.copyMemory(ix(pos), ix(0), (long)rem << 0);position(rem);limit(capacity());discardMark();return this;}
2.5 ByteBuffer 使用案例
为了更好的理解 ByteBuffer ,我们来看一些示例:
public class ByteBufferDemo {public static void main(String[] args) {// 创建一个缓冲区ByteBuffer buffer = ByteBuffer.allocate(10);System.out.println("------------初始时缓冲区------------");printBuffer(buffer);// 添加一些数据到缓冲区中System.out.println("------------添加数据到缓冲区------------");String s = "love";buffer.put(s.getBytes());printBuffer(buffer);// 切换成读模式System.out.println("------------执行flip切换到读取模式------------");buffer.flip();printBuffer(buffer);// 读取数据System.out.println("------------读取数据------------");// 创建一个limit()大小的字节数组(因为就只有limit这么多个数据可读)byte[] bytes = new byte[buffer.limit()];// 将读取的数据装进我们的字节数组中buffer.get(bytes);printBuffer(buffer);// 执行compactSystem.out.println("------------执行compact------------");buffer.compact();printBuffer(buffer);// 执行clearSystem.out.println("------------执行clear清空缓冲区------------");buffer.clear();printBuffer(buffer);}/*** 打印出ByteBuffer的信息* * @param buffer*/private static void printBuffer(ByteBuffer buffer) {System.out.println("mark:" + buffer.mark());System.out.println("position:" + buffer.position());System.out.println("limit:" + buffer.limit());System.out.println("capacity:" + buffer.capacity());}
}
输出结果:
------------初始时缓冲区------------
mark:java.nio.HeapByteBuffer[pos=0 lim=10 cap=10]
position:0
limit:10
capacity:10
------------添加数据到缓冲区------------
mark:java.nio.HeapByteBuffer[pos=4 lim=10 cap=10]
position:4
limit:10
capacity:10
------------执行flip切换到读取模式------------
mark:java.nio.HeapByteBuffer[pos=0 lim=4 cap=10]
position:0
limit:4
capacity:10
------------读取数据------------
mark:java.nio.HeapByteBuffer[pos=4 lim=4 cap=10]
position:4
limit:4
capacity:10
------------执行compact------------
mark:java.nio.HeapByteBuffer[pos=0 lim=10 cap=10]
position:0
limit:10
capacity:10
------------执行clear清空缓冲区------------
mark:java.nio.HeapByteBuffer[pos=0 lim=10 cap=10]
position:0
limit:10
capacity:10Process finished with exit code 0
总结
本文首先展示了ByteBuffer在写入模式和读取模式下内部的一个状态,然后分析了clear() 与 compact() 方法的源码,最后讲解了ByteBuffer的使用案例。
下节我们再来分析ByteBuf实现原理。
相关文章:
【Netty】字节缓冲区 ByteBuf (六)(上)
文章目录 前言一、ByteBuf类二、ByteBuffer 实现原理2.1 ByteBuffer 写入模式2.2 ByteBuffer 读取模式2.3 ByteBuffer 写入模式切换为读取模式2.4 clear() 与 compact() 方法2.5 ByteBuffer 使用案例 总结 前言 回顾Netty系列文章: Netty 概述(一&…...
Python - 面向对象编程 - 实例方法、静态方法、类方法
实例方法 在类中定义的方法默认都是实例方法,前面几篇文章已经大量使用到实例方法 实例方法栗子 class PoloBlog:def __init__(self, name, age):print("自动调用构造方法")self.name nameself.age agedef test(self):print("一个实例方法&…...
性能测试——基本性能监控系统使用
这里写目录标题 一、基本性能监控系统组成二、环境搭建1、准备数据文件 type.db collectd.conf2、启动InfluxDB3、启动grafana4、启动collectd5、Grafana中配置数据源 一、基本性能监控系统组成 Collectd InfluxdDB Grafana Collectd 是一个守护(daemon)进程,用来…...

JavaCollection集合
5 Collection集合 5.1 Collection集合概述 是单列集合的顶层接口,它表示一组对象,这些对象也称Collection元素JDK不提供此接口的直接实现,它提供更具体的子接口(Set 和 List)实现package ceshi;import java.util.AbstractCollection; import java.util.ArrayList; import…...

C++中string的用法
博主简介:Hello大家好呀,我是陈童学,一个与你一样正在慢慢前行的人。 博主主页:陈童学哦 所属专栏:CSTL 前言:Hello各位小伙伴们好!欢迎来到本专栏CSTL的学习,本专栏旨在帮助大家了解…...

目标检测YOLO实战应用案例100讲-基于深度学习的交通场景多尺度目标检测算法研究与应用
目录 基于深度学习的交通目标检测算法研究 传统的目标检测算法 基于深度学习的目标检测算法 </...

面试:vue事件绑定修饰符
stop - 调用 event.stopPropagation()。 prevent - 调用 event.preventDefault()。 trim 自动过滤用户输入的首尾空格 number 将输出字符串转为Number类型 enter 回车键 capture - 添加事件侦听器时使用 capture 模式。 self - 只当事件是从侦听器绑定的元素本身触发时才触发…...

优思学院|从0到1,认识精益生产管理
精益生产是一种系统性的生产管理方法,旨在最大化价值,最小化浪费,以及提高产品质量和客户满意度。它源于丰田生产系统(TPS),是一种基于流程优化、以人为本的管理方法,强调优化生产流程、减少浪费…...

HashSet创建String类型的数据
package com.test.Test07;import java.util.HashSet;public class TestString {//这是一个main方法,是程序的入口public static void main(String[] args) {//创建一个HashSet集合HashSet<String> hs new HashSet<>();hs.add("hello");Syste…...

真会玩:莫言用ChatGPT为余华写了一篇获奖词
5月16日,《收获》杂志65周年庆典暨新书发布活动在上海舞蹈中心举行。 典礼现场,余华凭借《文城》获得收获文学榜2021年长篇小说榜榜首。 作为老友,莫言在颁奖时故意卖了个关子:“这次获奖的是一个了不起的人物,当然了&…...
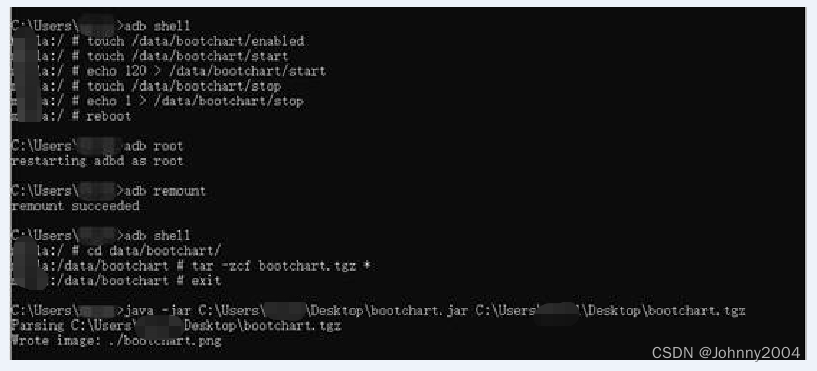
10 工具Bootchart的使用(windows)
Bootchart的使用方法(windows) 下载bootchart.jar并拷贝到windows, 然后保证windows也安装了open jdk 1.8; 下载地址:https://download.csdn.net/download/Johnny2004/87807973 打开设备开机启动bootchart的开关: adb shell touch /data/boo…...

电磁频谱异常监测论文阅读 | 《战场电磁环境下的电磁频谱管控指标体系研究》
文章目录 1.《战场电磁环境下的电磁频谱管控指标体系研究》1.1 电磁频谱管控的基本概念:1.2 电磁频谱管控的主要内容:1.3 指标体系1.3.1 技术指标体系1.3.2 战术指标体系1.《战场电磁环境下的电磁频谱管控指标体系研究》 1.1 电磁频谱管控的基本概念: 频谱管控是指军队领导…...

掌握好linkedin的这些技巧,你就已经超越了80%的跨境人
领英作为一款目前市面上最多人使用的在线职场社交媒体软件,是我们这些跨境电商人拓展客户的好渠道,并且很容易找到相应的外贸客户。但是领英的玩法并不像其他社交媒体平台一样简单,规则比较多,很多国内的用户都是胡乱操作…...

Linux——网络套接字1|socket编程
IP地址(公网IP),标定了主机的唯一性。 通常情况,把数据送到对方的机器是目的吗? 不是的,真正的网络通信过程其实是进程间通信,如客户端进程和服务器进程,我们把数据在主机间转发仅仅是手段,机器收到数据之后,需要将数据交付给指定的进程,当客户端有多个进程在运行时…...
)
stable-diffusion-webui服务器centos部署实践(成功)
之前关注stable-diffusion仅仅是因为stable-diffusion模型,但实践证明,stable-diffusion如果么有那么好的提示词功力,恐怕生成的图就是“畸形的,缺胳膊少腿的,多一块,少一块的”,如V1实践,V2实践,纸糊效果。 如果做不到其他人那样“美女自给自足”,那么我这个“大佬…...
北京筑龙作为软件服务商出席《国企阳光采购标准》研讨会
近日,由中国企业国有产权交易机构协会市场创新专业委员会主办、青岛产权交易所有限公司承办的《国企阳光采购标准》研讨会在青岛召开,该会议共有19家已开展采购业务的各地产权交易机构参加,北京筑龙作为软件服务商出席会议。 《国企阳光采购标…...
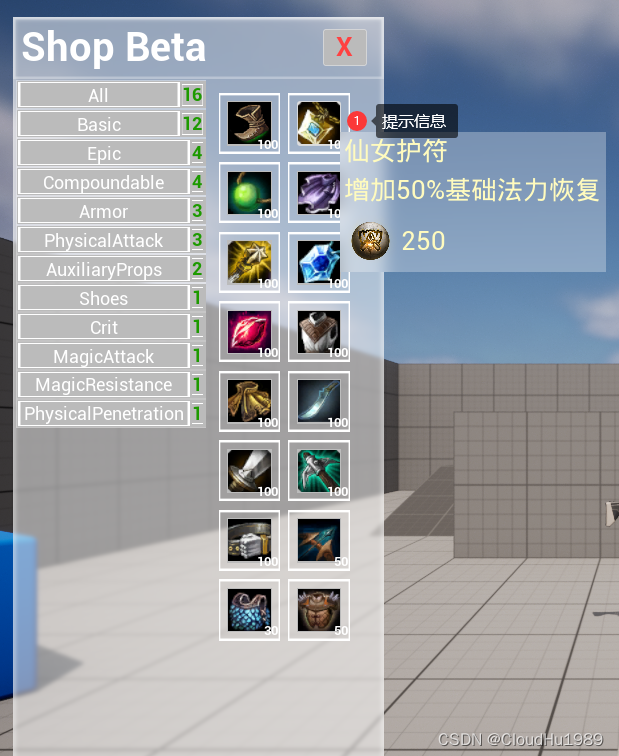
如何动态显示物品提示?
UE5 插件开发指南 前言0 提示信息窗口类前言 为了使物品的排列简洁,各种游戏里的物品信息都是以提示的形式展示出来,而不是整个铺排陈列,只需要玩家鼠标悬停在物品上就自动显示出提示窗口,如下图所示: 这些提示信息在物品定义数据资产中已经定义了,所以这里要做的只是将…...

推荐试试这个简单好用的手机技巧
技巧一:一键锁屏 除了按住手机电源键进行锁屏外,还有其他一些快捷方法可以实现锁屏操作。 对于苹果手机用户,可以按照以下步骤进行设置: 1.打开手机的设置应用,通常可以在主屏幕或应用列表中找到该图标。 2.在设置…...

传染病学模型 | Matlab实现SIS传染病学模型 (SIS Epidemic Model)
文章目录 效果一览基本描述模型介绍程序设计参考资料效果一览 基本描述 传染病学模型 | Matlab实现SIS传染病学模型 (SIS Epidemic Model) 模型介绍 SIS模型是一种基本的传染病学模型,用于描述一个人群中某种传染病的传播情况。SIS模型假设每个人都可以被感染,即没有免疫力,…...

s2020gc56收集数据
作答区域: #include<bits/stdc.h> using namespace std; int n,k,s1,s2,h1,h2,he,ans,r2,r1,l2,l11,f[1000009]; int main() {cin>>n>>k;for(int i1;i<n;i)cin>>f[i];for(int i1;;i){s1;if(s1>k)break;h1h1f[i];}for(int in;;i--){…...

Video2X完整指南:用AI免费无损放大视频到4K的终极解决方案
Video2X完整指南:用AI免费无损放大视频到4K的终极解决方案 【免费下载链接】video2x A machine learning-based video super resolution and frame interpolation framework. Est. Hack the Valley II, 2018. 项目地址: https://gitcode.com/GitHub_Trending/vi/v…...

怎样轻松突破微信网页版限制:wechat-need-web开源插件实用指南
怎样轻松突破微信网页版限制:wechat-need-web开源插件实用指南 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 微信作为日常沟通的重要工具…...

NCMDump工具:3步轻松解密网易云音乐NCM加密文件
NCMDump工具:3步轻松解密网易云音乐NCM加密文件 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经在网易云音乐下载了喜欢的歌曲,却发现只能在官方客户端播放?NCM加密格式的限制让你无法在…...

图像做 DCT:揭秘那个让像素“开口说话“的数学魔法
一、一个让我"开窍"的乐谱解读故事 我有一个学钢琴的表妹,从小就有一种让我惊叹的能力——她听任何一段陌生的旋律,都能立刻在钢琴上准确弹出来。我一直觉得她有"绝对音感"这种天赋。有一次我好奇地问她:“你怎么做到的&…...

Applite:3分钟搞定macOS应用管理的终极图形化解决方案
Applite:3分钟搞定macOS应用管理的终极图形化解决方案 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为macOS上的软件安装和管理头疼吗?每次都要打…...

终极iOS越狱实战指南:解锁iPhone隐藏功能与深度定制方案
终极iOS越狱实战指南:解锁iPhone隐藏功能与深度定制方案 【免费下载链接】Jailbreak iOS 26.4 - 26, 17 - 17.7.5 & iOS 18 - 18.7.3 Jailbreak Tools, Cydia/Sileo/Zebra Tweaks & Jailbreak News Updates || AI Jailbreak Finder 👇 项目地址…...

从Python课设到CTF利器:JWT_GUI工具开发复盘与使用避坑全指南
从Python课设到CTF利器:JWT_GUI工具开发复盘与使用避坑全指南在CTF竞赛和渗透测试中,JWT(JSON Web Token)的安全问题一直是个高频考点。作为一个原本只是应付Python课程设计的工具,JWT_GUI却意外成为了解决这类问题的利…...

子黎曼几何与庞特里亚金原理:约束系统时间最优控制
1. 从黎曼到子黎曼:当几何遇见约束 在物理和工程的世界里,我们常常需要为系统寻找一条“最优”的路径。无论是让量子比特以最快的速度演化到目标态,还是规划机器人在复杂地形中的最短时间轨迹,其背后都隐藏着一个深刻的几何问题&a…...

可解释AI在宏基因组学中的应用:从黑箱预测到透明洞察
1. 项目概述:当宏基因组学遇见可解释AI如果你在生物信息学或精准医疗领域工作,最近几年一定被两个词刷屏了:一个是“宏基因组学”,另一个是“可解释AI”。前者让我们得以窥见人体内万亿微生物构成的复杂宇宙,后者则试图…...
)
告别双系统!用WSL2+Ubuntu20.04+ROS Noetic,在Windows上丝滑运行AirSim仿真(保姆级避坑指南)
在Windows上构建WSL2ROSAirSim一体化仿真环境:从零避坑到实战 对于机器人开发者而言,跨平台仿真环境的搭建往往意味着无尽的配置噩梦。当我在研究生课题中首次尝试将AirSim与ROS联调时,经历了整整两周的黑暗时期——双系统切换导致工作流断裂…...