Spark 3:Spark Core RDD持久化
RDD 的数据是过程数据
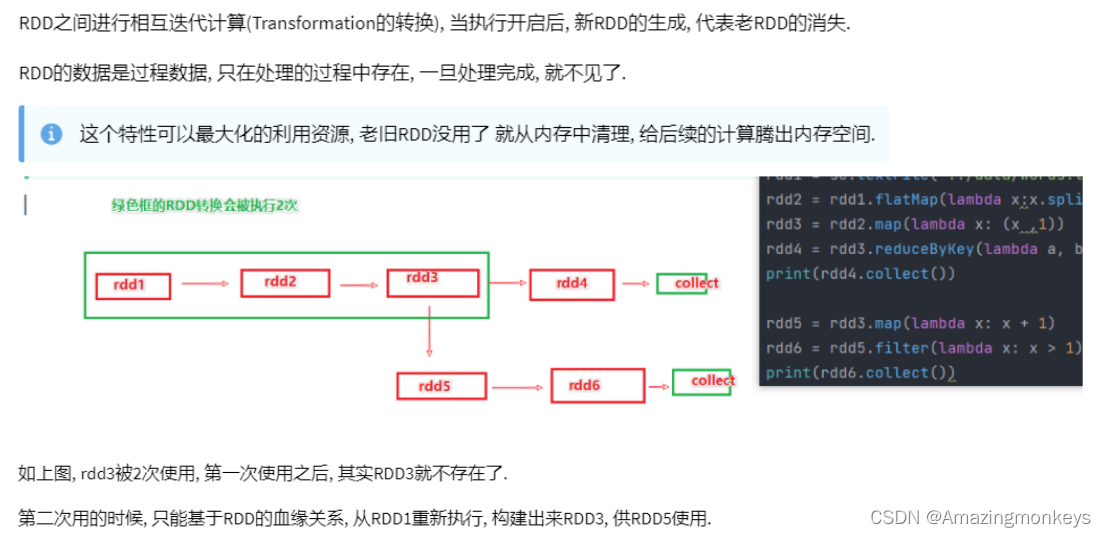
RDD 的缓存

# coding:utf8
import timefrom pyspark import SparkConf, SparkContext
from pyspark.storagelevel import StorageLevelif __name__ == '__main__':conf = SparkConf().setAppName("test").setMaster("local[*]")sc = SparkContext(conf=conf)rdd1 = sc.textFile("../data/input/words.txt")rdd2 = rdd1.flatMap(lambda x: x.split(" "))rdd3 = rdd2.map(lambda x: (x, 1))# 缓存到内存中rdd3.cache()# 先放内存,如果不够则放硬盘,2份副本rdd3.persist(StorageLevel.MEMORY_AND_DISK_2)rdd4 = rdd3.reduceByKey(lambda a, b: a + b)print(rdd4.collect())rdd5 = rdd3.groupByKey()rdd6 = rdd5.mapValues(lambda x: sum(x))print(rdd6.collect())# 清理缓存rdd3.unpersist()time.sleep(100000)

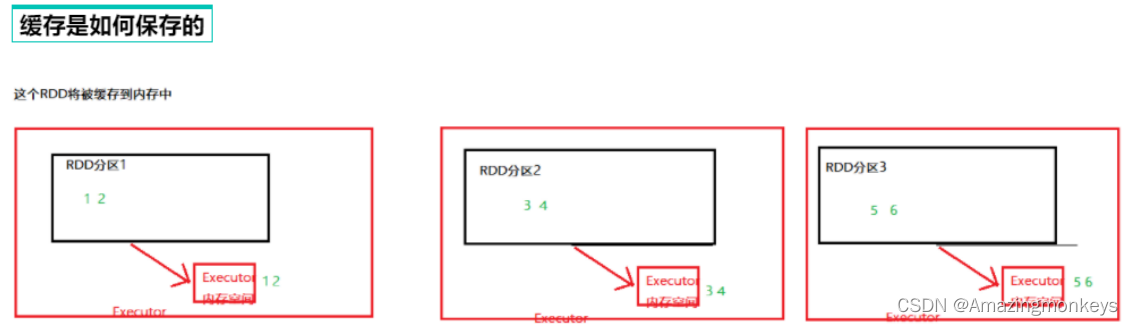
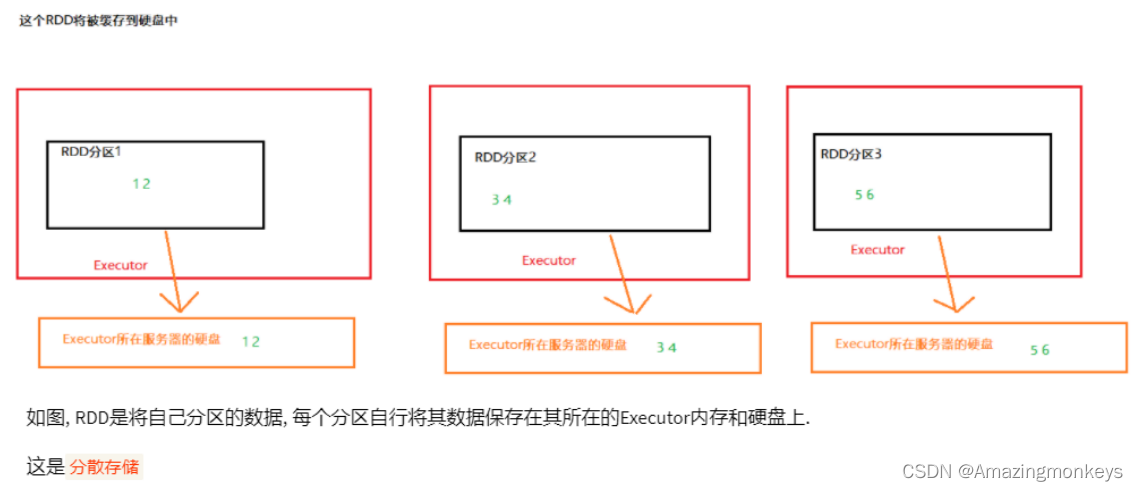
RDD 的CheckPoint

# coding:utf8
import timefrom pyspark import SparkConf, SparkContext
from pyspark.storagelevel import StorageLevelif __name__ == '__main__':conf = SparkConf().setAppName("test").setMaster("local[*]")sc = SparkContext(conf=conf)# 1. 告知spark, 开启CheckPoint功能sc.setCheckpointDir("hdfs://node1:8020/output/ckp")rdd1 = sc.textFile("../data/input/words.txt")rdd2 = rdd1.flatMap(lambda x: x.split(" "))rdd3 = rdd2.map(lambda x: (x, 1))# 调用checkpoint API 保存数据即可rdd3.checkpoint()rdd4 = rdd3.reduceByKey(lambda a, b: a + b)print(rdd4.collect())rdd5 = rdd3.groupByKey()rdd6 = rdd5.mapValues(lambda x: sum(x))print(rdd6.collect())rdd3.unpersist()time.sleep(100000)
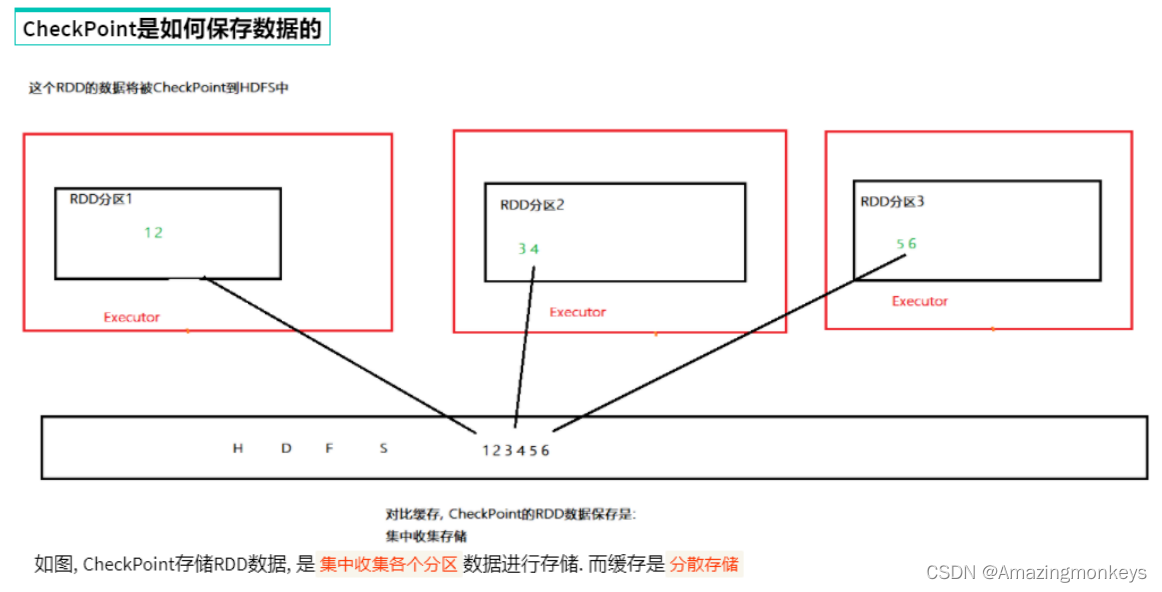
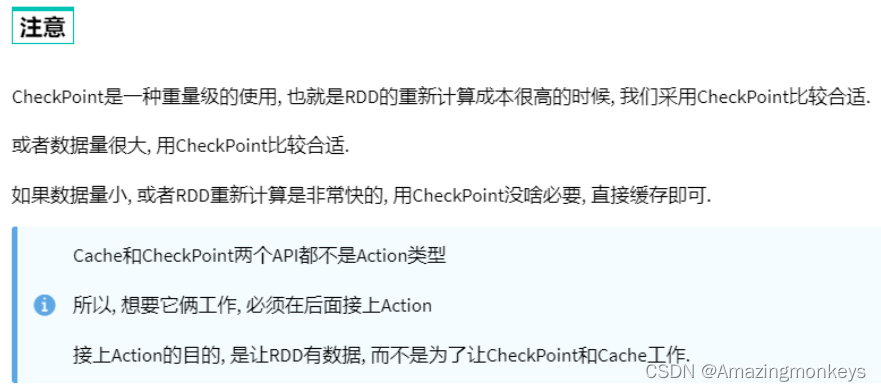
Cache和Checkpoint区别
Cache是轻量化保存RDD数据,可存储在内存和硬盘,是分散存储,设计上数据是不安全的(保留RDD血缘关系)。
CheckPoint是重量级保存RDD数据,是集中存储,只能存储在硬盘(HDFS)上,设计上是安全的(不保留RDD血缘关系)。
Cache 和 CheckPoint的性能对比?
Cache性能更好,因为是分散存储,各个Executor并行执行,效率高,可以保存到内存中(占内存),更快。
CheckPoint比较慢,因为是集中存储,涉及到网络IO,但是存储到HDFS上更加安全(多副本) 。
案例练习:搜索引擎日志分析


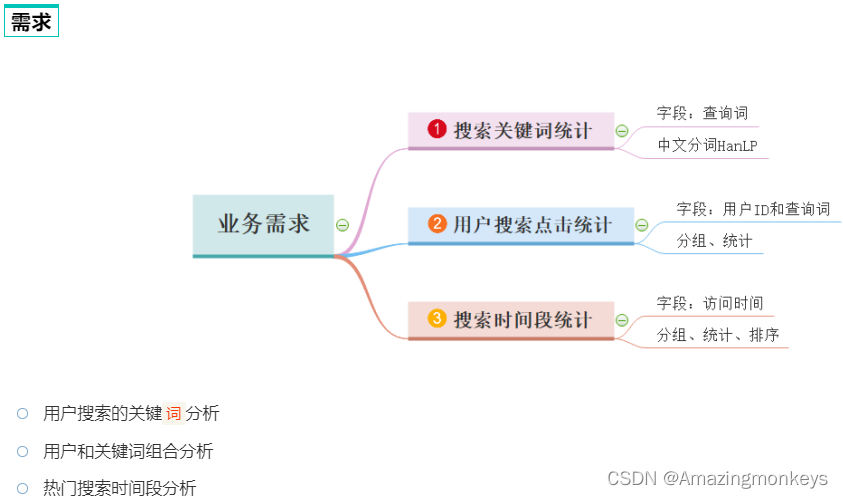
# coding:utf8# 导入Spark的相关包
import timefrom pyspark import SparkConf, SparkContext
from pyspark.storagelevel import StorageLevel
from defs import context_jieba, filter_words, append_words, extract_user_and_word
from operator import addif __name__ == '__main__':# 0. 初始化执行环境 构建SparkContext对象conf = SparkConf().setAppName("test").setMaster("local[*]")sc = SparkContext(conf=conf)# 1. 读取数据文件file_rdd = sc.textFile("hdfs://node1:8020/input/SogouQ.txt")# 2. 对数据进行切分 \tsplit_rdd = file_rdd.map(lambda x: x.split("\t"))# 3. 因为要做多个需求, split_rdd 作为基础的rdd 会被多次使用.split_rdd.persist(StorageLevel.DISK_ONLY)# TODO: 需求1: 用户搜索的关键`词`分析# 主要分析热点词# 将所有的搜索内容取出# print(split_rdd.takeSample(True, 3))context_rdd = split_rdd.map(lambda x: x[2])# 对搜索的内容进行分词分析words_rdd = context_rdd.flatMap(context_jieba)# print(words_rdd.collect())# 院校 帮 -> 院校帮# 博学 谷 -> 博学谷# 传智播 客 -> 传智播客filtered_rdd = words_rdd.filter(filter_words)# 将关键词转换: 传智播 -> 传智播客final_words_rdd = filtered_rdd.map(append_words)# 对单词进行 分组 聚合 排序 求出前5名result1 = final_words_rdd.reduceByKey(lambda a, b: a + b).\sortBy(lambda x: x[1], ascending=False, numPartitions=1).\take(5)print("需求1结果: ", result1)# TODO: 需求2: 用户和关键词组合分析# 1, 我喜欢传智播客# 1+我 1+喜欢 1+传智播客user_content_rdd = split_rdd.map(lambda x: (x[1], x[2]))# 对用户的搜索内容进行分词, 分词后和用户ID再次组合user_word_with_one_rdd = user_content_rdd.flatMap(extract_user_and_word)# 对内容进行 分组 聚合 排序 求前5result2 = user_word_with_one_rdd.reduceByKey(lambda a, b: a + b).\sortBy(lambda x: x[1], ascending=False, numPartitions=1).\take(5)print("需求2结果: ", result2)# TODO: 需求3: 热门搜索时间段分析# 取出来所有的时间time_rdd = split_rdd.map(lambda x: x[0])# 对时间进行处理, 只保留小时精度即可hour_with_one_rdd = time_rdd.map(lambda x: (x.split(":")[0], 1))# 分组 聚合 排序result3 = hour_with_one_rdd.reduceByKey(add).\sortBy(lambda x: x[1], ascending=False, numPartitions=1).\collect()print("需求3结果: ", result3)time.sleep(100000)import jiebadef context_jieba(data):"""通过jieba分词工具 进行分词操作"""seg = jieba.cut_for_search(data)l = list()for word in seg:l.append(word)return ldef filter_words(data):"""过滤不要的 谷 \ 帮 \ 客"""return data not in ['谷', '帮', '客']def append_words(data):"""修订某些关键词的内容"""if data == '传智播': data = '传智播客'if data == '院校': data = '院校帮'if data == '博学': data = '博学谷'return (data, 1)def extract_user_and_word(data):"""传入数据是 元组 (1, 我喜欢传智播客)"""user_id = data[0]content = data[1]# 对content进行分词words = context_jieba(content)return_list = list()for word in words:# 不要忘记过滤 \谷 \ 帮 \ 客if filter_words(word):return_list.append((user_id + "_" + append_words(word)[0], 1))return return_list提交到集群运行
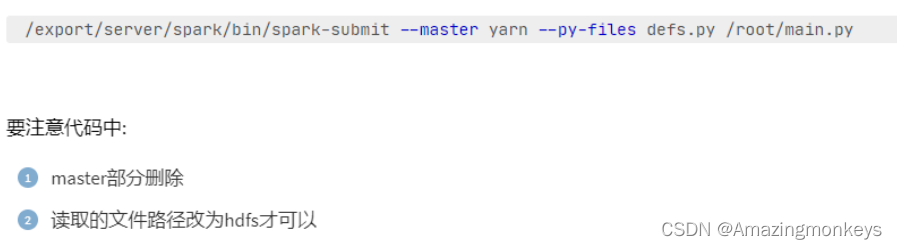
 为什么要在全部的服务器安装jieba库?
为什么要在全部的服务器安装jieba库?
因为YARN是集群运行,Executor可以在所有服务器上执行,所以每个服务器都需要有jieba库提供支撑。
如何尽量提高任务计算的资源?
计算CPU核心和内存量,通过--executor-memory 指定executor内存,通过--executor-cores 指定
executor的核心数,通过--num-executors 指定总executor数量。
相关文章:
Spark 3:Spark Core RDD持久化
RDD 的数据是过程数据 RDD 的缓存 # coding:utf8 import timefrom pyspark import SparkConf, SparkContext from pyspark.storagelevel import StorageLevelif __name__ __main__:conf SparkConf().setAppName("test").setMaster("local[*]")sc SparkC…...

字节跳动五面都过了,结果被刷了,问了hr原因竟说是...
摘要 说在前面,面试时最好不要虚报工资。本来字节跳动是很想去的,几轮面试也通过了,最后没offer,自己只想到几个原因:1、虚报工资,比实际高30%;2、有更好的人选,这个可能性不大&…...
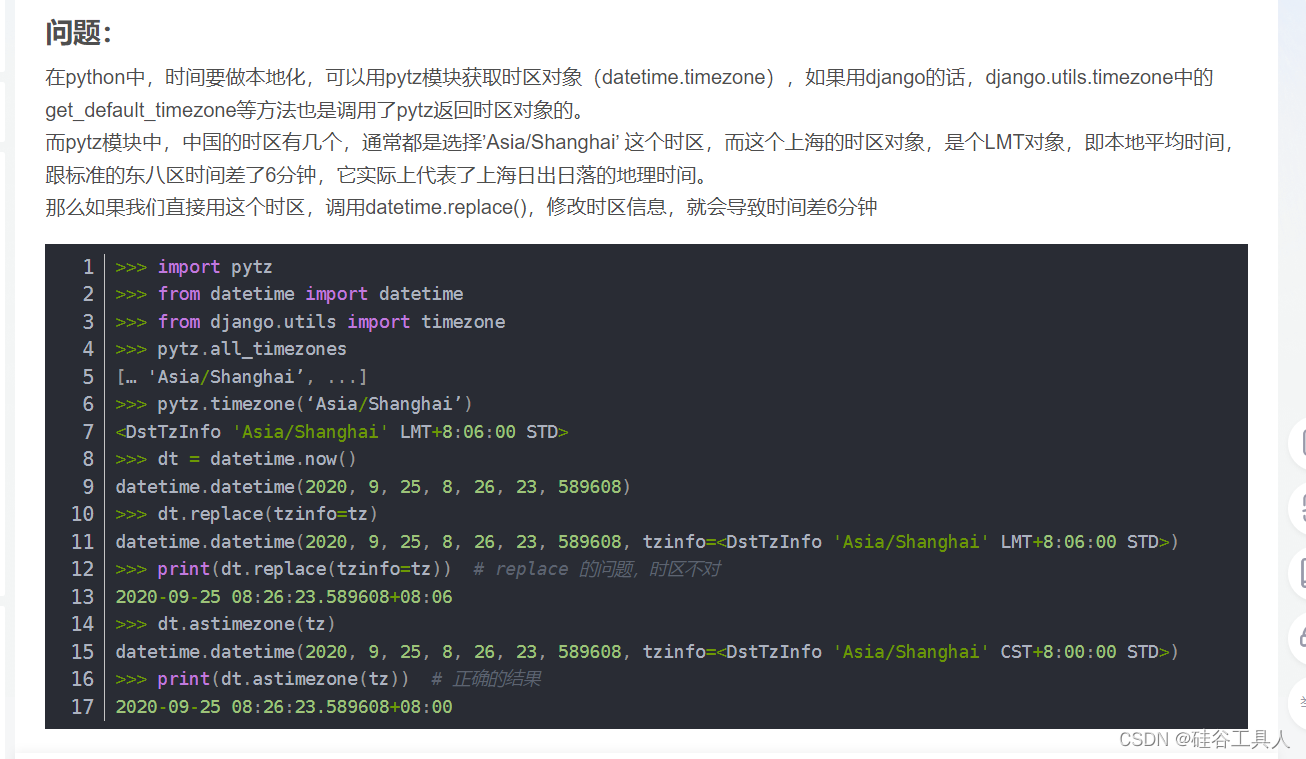
Python日期带时区转换工具类总结
文章目录 1.背景2. 遇到的坑3. 一些小案例3.1 当前日期、日期时间、UTC日期时间3.2 昨天、昨天UTC日期、昨天现在这个时间点的时间戳3.3 日期转时间戳3.4 时间戳转日期3.5 日期加减、小时的加减 4. 总结5. 完整的编码 1.背景 最近项目是国际项目,所以需要经常需要用…...
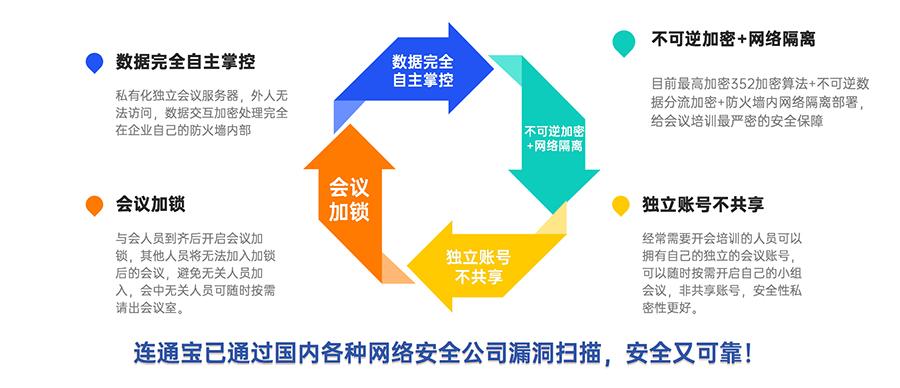
视频会议产品对比分析
内网视频会议系统如何选择?有很多单位为了保密,只能使用内部网络,无法连接互联网,那些SaaS视频会议就无法使用。在内网的优秀视频会议也有很多可供选择,以下是几个常用的: 1. 宝利通:它支持多种…...

每日一练 | 华为认证真题练习Day47
1、某台路由器输出信息如下,下列说法错误的是?(多选) A. 本路由器开启了区域认证 B. 本设备出现故障,配置的Router Id和实际生效的Router ID不一致 C. 本设备生效的Router Id为10.0.12.1 D. 本设备生效的Router Id为…...
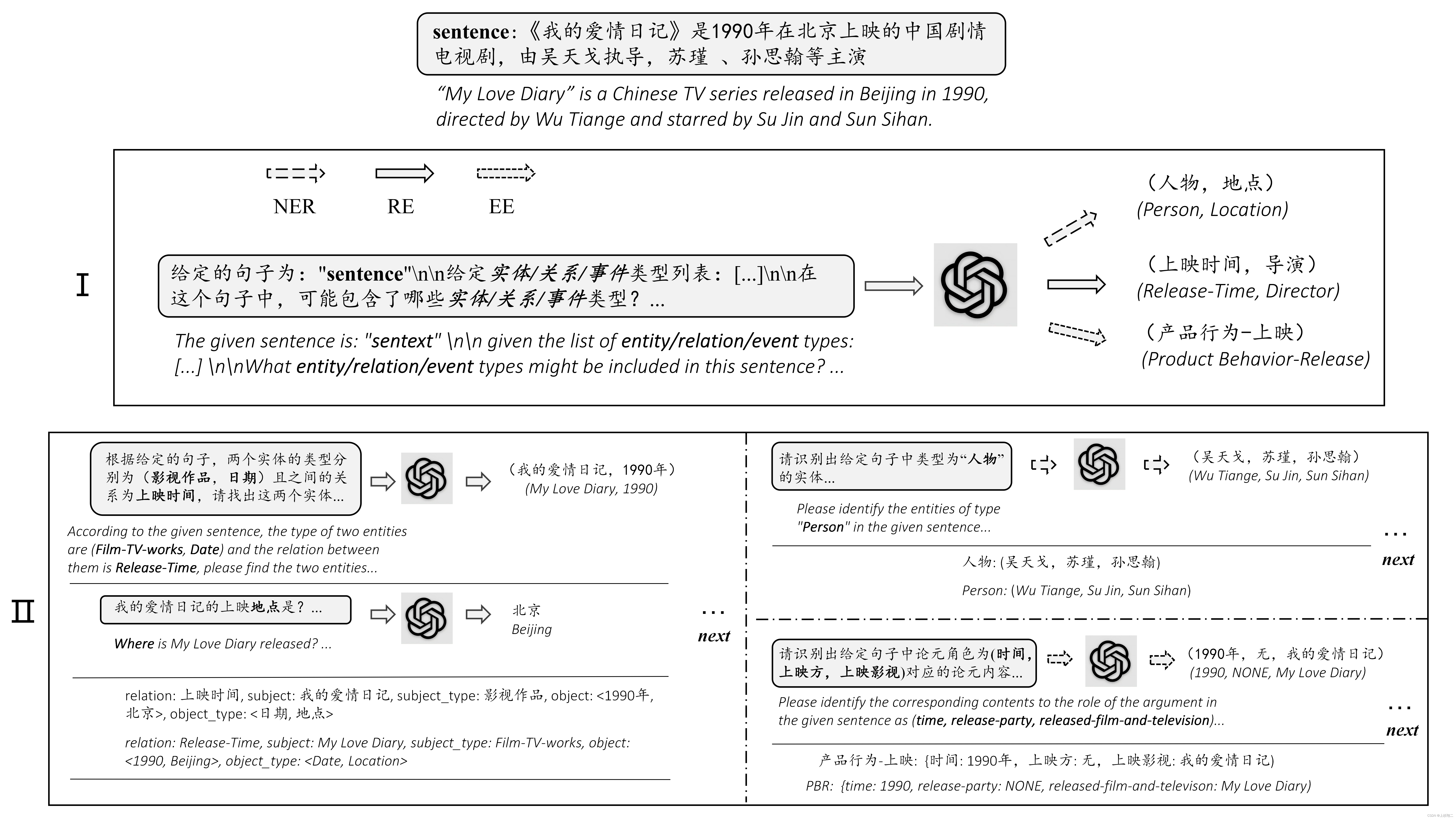
ChatIE(LLM大模型用于信息抽取)
Zero-Shot Information Extraction via Chatting with ChatGPT paper:https://arxiv.org/abs/2302.10205 利用ChatGPT实现零样本信息抽取(Information Extraction,IE),看到零样本就能大概明白这篇文章将以ChatGPT作为…...

提升企业管理效率的利器——ADManager Plus
在当今信息时代,企业的规模和复杂性不断增长,管理各个方面变得愈发具有挑战性。而在企业管理中,活跃目录(Active Directory)起着至关重要的作用。它是一种用于组织内部的用户、计算机、组和其他对象进行集中管理的目录…...

《入侵的艺术》读书心得:第六章:渗透测试中的智慧与愚昧
第六章:渗透测试中的智慧与愚昧 这些想法是愚昧的 1.任何期待渗透测试结果是“毫无破绽”、“无懈可击”…都是极其愚昧的: 第一层含义:测试的不可穷尽性原理(同软件测试) 第二层含义:作为优秀甚至只是合…...
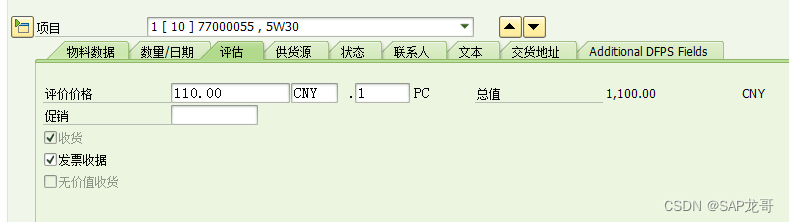
SAP-MM-采购申请-价值特性
采购申请审批在维护价值特性时要注意是抬头价值还是行价值,要确定选择哪个,配置时对应配置。 1、创建价值特性CT04 字段名称:CEBAN-GSWRT,和CEBAN-GFWRT 抬头总价值:CEBAN-GFWRT;如果选择的是抬头审批&am…...
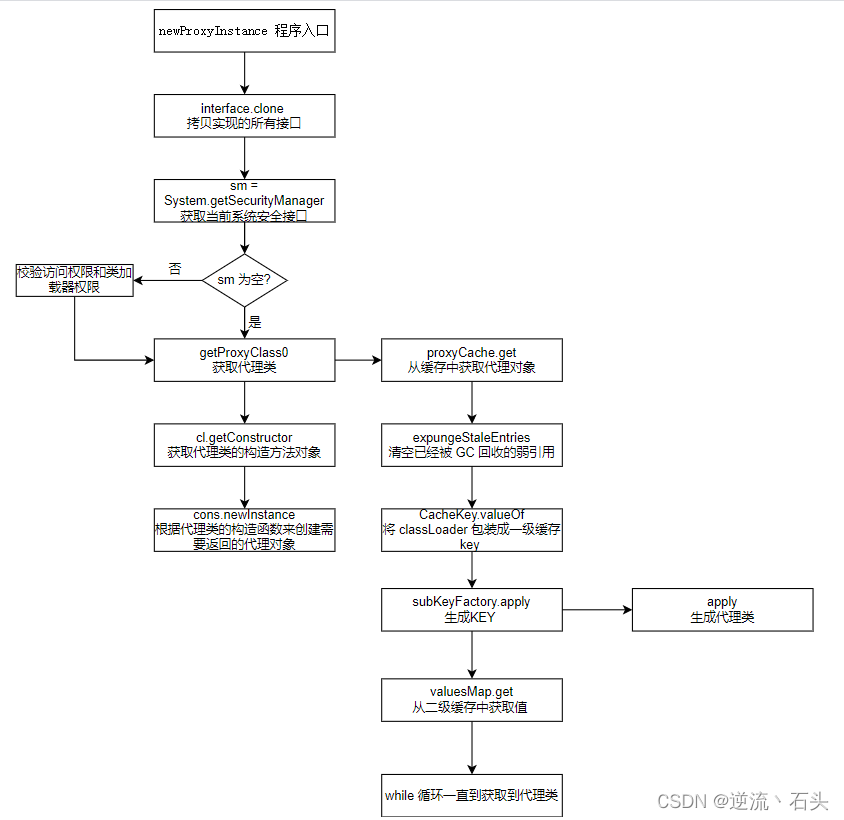
设计模式 - 代理模式
基本介绍: 代理模式:为一个对象提供一个替身,以控制对这个对象的访问。即通过代理 对象访问目标对象.这样做的好处是:可以在目标对象实现的基础上,增强额外的 功能操作,即扩展目标对象的功能。被代理的对象可以是远程对象、创建开销大的对象或需要安全控…...
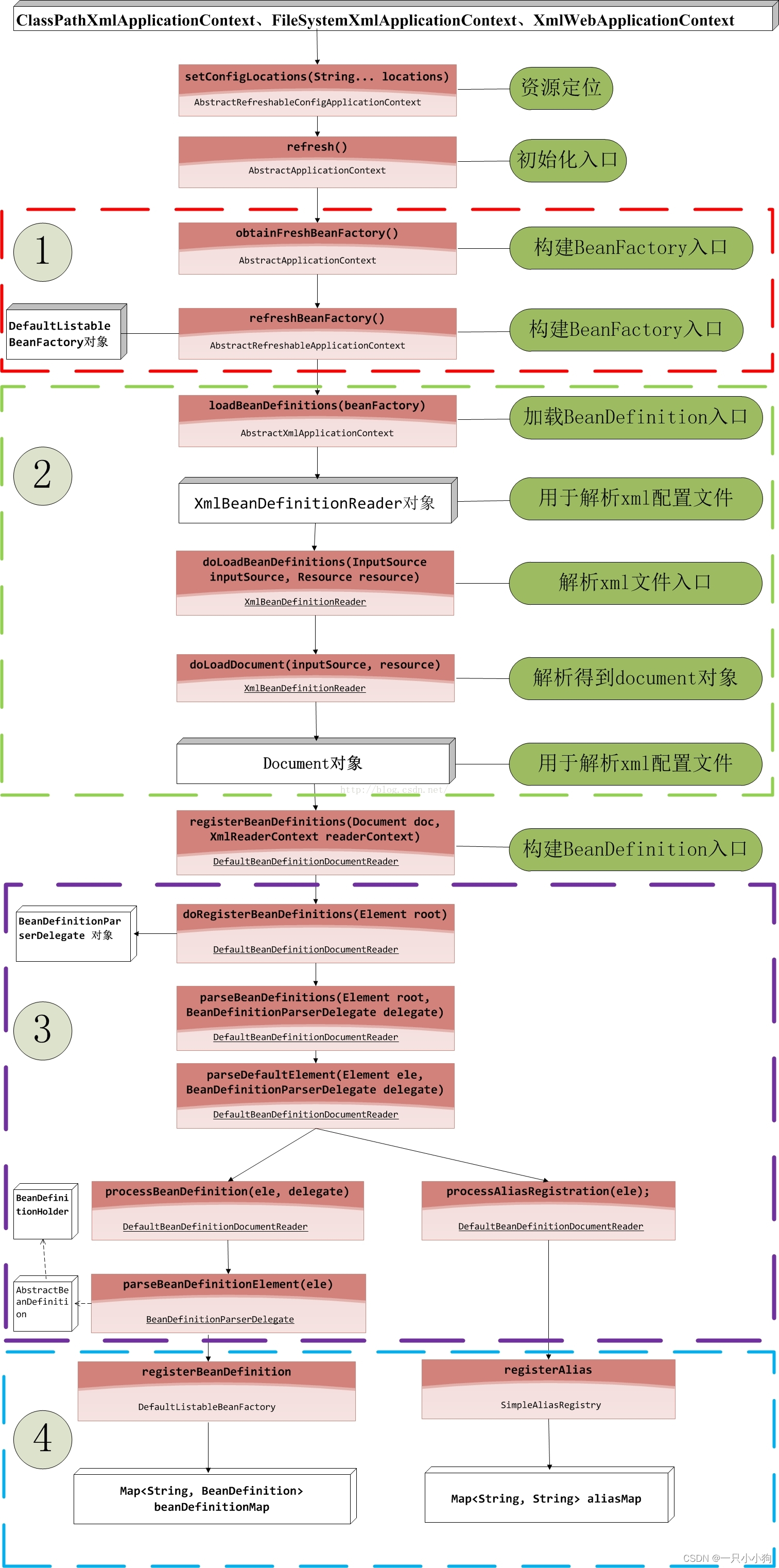
IOC初始化 IOC启动阶段 (Spring容器的启动流程)
[toc](IOC初始化 IOC启动阶段 (Spring容器的启动流程)) IOC初始化 IOC启动阶段 (Spring容器的启动流程) Resource定位过程:这个过程是指定位BeanDefinition的资源,也就是配置文件(如xml)的位置,并将其封装成Resource对…...
)
Java后端入职第四天,就被要求代码回退(Git回退实战)
一、需求背景 初入职场,由于自己的失误或者对git不熟悉,把被人的代码给冲突掉了,然后需要立马回滚,对于新手开发,应该比较常见吧!或者,比较多一种情况,错误把工程add了到了暂存区,比如一些本地配置,本来就不应该提交的,又或者,开发中只提交部分代码,又想最新的提…...

【swing】SplitPanel
当使用Java的Swing库来实现一个左右风格的SplitPanel时,可以使用JSplitPane作为容器,并在左边的面板中放置三个按钮,以及在右边的面板中显示图片。以下是一个示例代码: import javax.swing.*; import java.awt.*; import java.aw…...
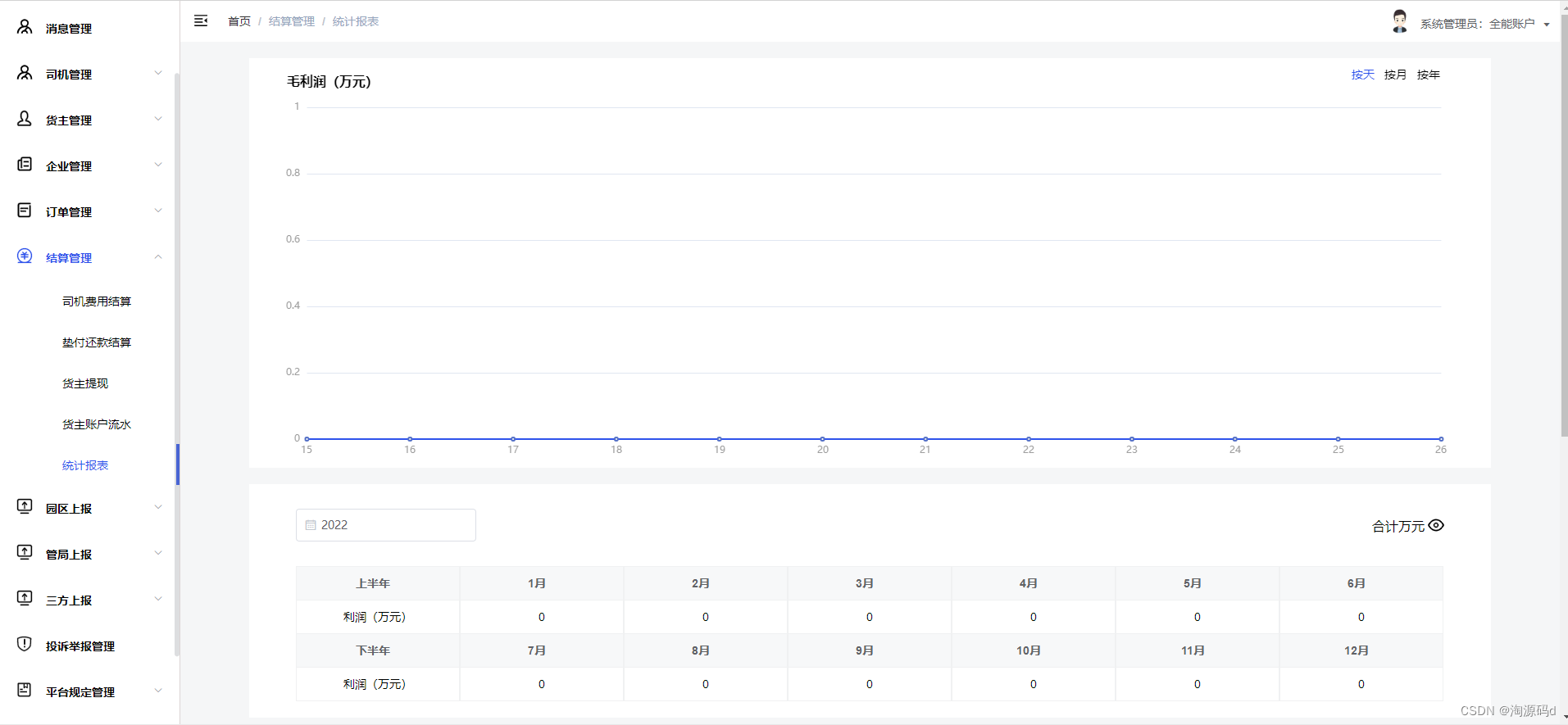
网络货运平台源码 管理平台端+司机端APP+货主端APP源码
网络货运平台系统源码,网络货运平台源码 管理平台端司机端APP货主端APP 遵循政策要求的八项基本功能,结合货主、实际承运人、监管方等多方业务场景,构建人、车、货、企一体的标准化网络货运平台系统。具有信息发布、线上交易、全程监控、金融…...
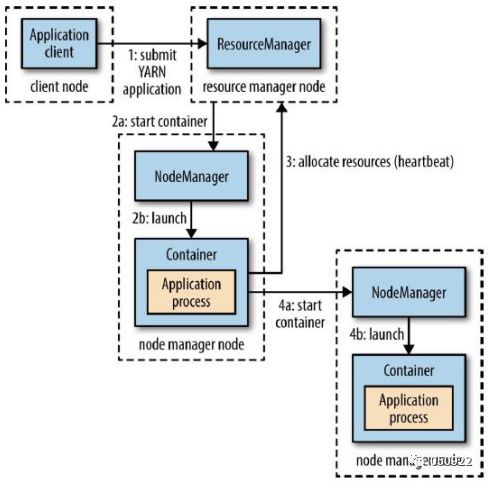
Yarn学习笔记
Apache Hadoop YARN (Yet AnotherResource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一…...
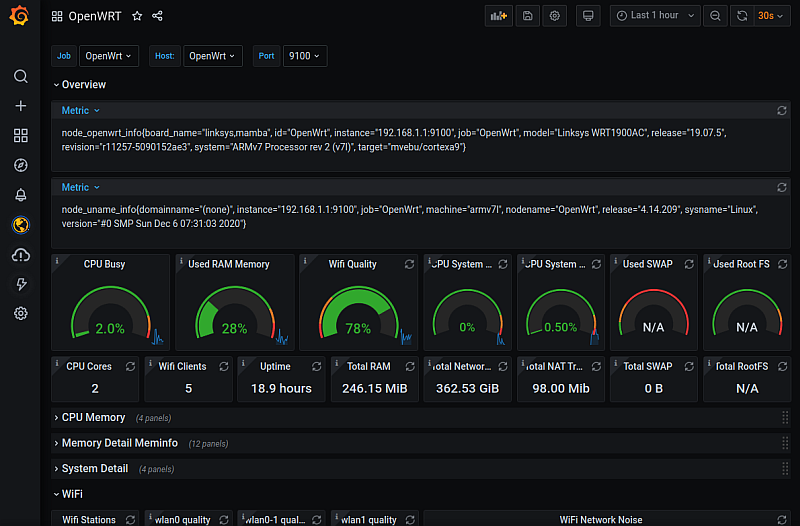
智能路由器开发之OpenWrt简介
智能路由器开发之OpenWrt简介 1. 引言 1.1 智能路由器的重要性和应用场景 智能路由器作为网络通信的核心设备,具有重要的地位和广泛的应用场景。传统的路由器主要提供基本的网络连接功能,但随着智能家居、物联网和大数据应用的快速发展,对于…...
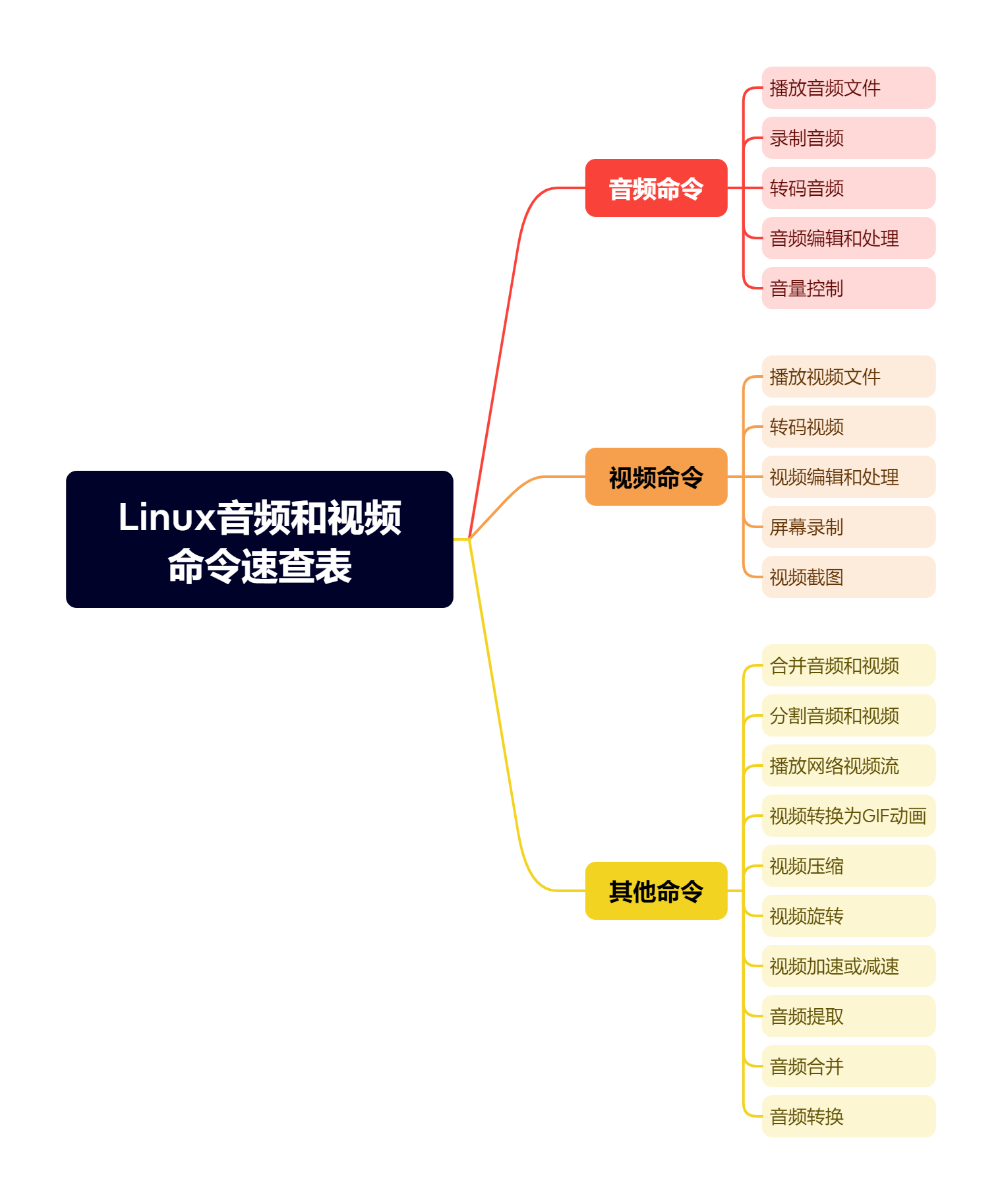
Linux音频和视频命令速查表
在Linux系统中,有许多命令可以帮助我们处理音频和视频文件,从基本的播放和转码,到编辑和处理音频、视频流。 本文将提供一个Linux音频和视频命令速查表,帮助您快速查找并了解各种常用的命令及其用法。 音频命令 播放音频文件 a…...

脉蜂:Django + Flutter 开发的进销存管理系统【已开源】
项目说明 小规模零售(包括电商)跟大规模零售企业的差别在哪里呢? 以我当前的认知来看,小规模零售跟大规模零售企业的差别更多的是在供应链管理、进销存管控上面产生的。如果有一个工具,能够帮他们减少这方面的差异&…...

树的先序,中序,后序递归遍历
//树的先序、中序、后序遍历递归 #include<bits/stdc.h> typedef struct node { char data; struct node *lchild,*rchild; }BTNode; void Greate(BTNode *&T) { char ch; scanf("%c",&ch); if(ch#) TNULL; else { T(BTNode*)malloc(sizeof(BT…...

如何在Linux中更改SSH端口?
SSH(Secure Shell)是一种安全的远程登录协议,它允许您通过网络远程连接到Linux系统并进行管理操作。默认情况下,SSH使用22端口进行通信。然而,为了增强系统的安全性,有时候我们需要更改SSH端口,…...

Java并发工具类CountDownLatch与CyclicBarrier
前言 在现代软件开发中,Java并发工具类CountDownLatch与CyclicBarrier是一个非常重要的技术点。本文将从原理到实践,带你深入理解这一技术,并通过完整的代码示例帮助你快速掌握核心知识点。 核心概念 基本原理 Java并发工具类CountDownLatch与…...

Ubuntu 22.04 LTS下,UE5打包的程序报‘Vulkan设备找不到’?别急着重装驱动,先试试这个库文件修复法
Ubuntu 22.04 LTS下解决UE5 Vulkan设备报错的深度修复指南当你在Ubuntu 22.04 LTS上已经确认NVIDIA驱动安装成功(通过nvidia-smi验证),但Unreal Engine 5打包的程序仍然抛出"Vulkan设备找不到"的错误时,问题往往比表面看…...

用if…elseif…end语句输出成绩等级
Matlab里面的if分支结构语句主要有单分支、双分支和多分支结构语句三种形式,前面两篇博文分别学习了单分支结构语句和双分支结构语句,这篇博文列出三种分支结构语句的特点,并对多分支结构语句进行学习。1、if…end语句if…end语句ÿ…...

CapyMOA:Python流式机器学习框架,高效应对概念漂移与在线持续学习
1. 项目概述:为什么我们需要CapyMOA?在现实世界的机器学习应用中,数据很少是静止不动的。想象一下,你正在构建一个金融欺诈检测系统,攻击者的策略会随时间不断演变;或者是一个工业物联网传感器监控平台&…...

Burp Suite扫描深度配置指南:被动扫描、主动扫描与自定义插入点协同调优
1. 这不是“点一下就扫完”的配置,而是扫描质量的分水岭 很多人把 Burp Suite Scanner 当成一个“自动漏洞探测器”——填个 URL,点下“Active Scan”,等它跑完弹出一堆高危告警,就以为任务完成了。我见过太多这样的场景ÿ…...
别再傻等下载了!手把手教你用wget离线部署sentence-transformers模型(以all-MiniLM-L6-v2为例)
离线部署sentence-transformers模型的终极指南:以all-MiniLM-L6-v2为例你是否曾在下载Hugging Face模型时遭遇网络中断,眼睁睁看着进度条卡在99%却无能为力?本文将彻底解决这一痛点,教你用wget命令行工具实现模型的离线部署。不同…...

遥感因果分析:多尺度表征拼接技术解析与工程实践
1. 项目概述:从“看”到“理解”的遥感因果分析新思路在遥感图像分析领域,我们早已不满足于仅仅“看到”地物。从土地利用分类到灾害评估,核心目标正从“是什么”转向“为什么”和“会怎样”。比如,我们不仅想知道某片区域是农田&…...

Switch大气层系统终极指南:从新手到高手的完整成长路径
Switch大气层系统终极指南:从新手到高手的完整成长路径 【免费下载链接】Atmosphere-stable 大气层整合包系统稳定版 项目地址: https://gitcode.com/gh_mirrors/at/Atmosphere-stable 想要彻底释放你的Switch游戏潜力吗?大气层系统(A…...

当 SonarQube 遇见 Go:从零搭建自动化代码质量检测体系
继 gofmt、golangci-lint、go test -race 之后,SonarQube 成为 Go 工程化质量保障体系的第四块拼图 在上一篇文章中,我们详细梳理了 gofmt + golangci-lint + go test -race 这套原生工具链的审查体系。这套组合拳在代码风格统一、静态分析和数据竞争检测方面表现出色,但细心…...
)
Lindy流程自动化实施倒计时手册:仅剩最后23家企业获赠官方认证治理框架V2.3(含审计就绪检查表)
更多请点击: https://intelliparadigm.com 第一章:Lindy流程自动化实施倒计时手册发布背景与战略意义 在企业数字化转型加速演进的当下,重复性高、规则明确但跨系统耦合度强的业务流程正成为组织效能提升的关键瓶颈。Lindy流程自动化&#x…...