学C的第二十二天【深度剖析数据在内存中的存储:1. 数据类型介绍;2. 整型在内存中的存储】
=========================================================================
相关代码gitee自取:C语言学习日记: 加油努力 (gitee.com)
=========================================================================
接上期:学C的第二十一天【初阶测评讲解:1. 计算递归了几次;2. 判断 do while 循环执行了几次;3. 求输入的两个数的最小公倍数;4. 将一句话的单词进行倒置,标点不倒置;补充知识点】_高高的胖子的博客-CSDN博客
=========================================================================
1. 数据类型介绍
(1). 基本的内置类型(C语言自带类型):
char -- 字符数据类型 -- 1字节
short -- 短整型 -- 2字节
int -- 整型 -- 4字节
long -- 长整型 -- 4字节 或 8字节
sizeof(long) >= sizeof(int)
long long -- 更长的整型 -- 8字节
float -- 单精度浮点数 -- 4字节
double -- 双精度浮点数 -- 8字节
类型的意义:
1. 使用这个类型开辟内存空间的大小(大小决定了使用范围)
2. C语言规定了:sizeof(long) >= sizeof(int),所以long的大小可以是4字节或8字节
3. 把整型分为短整型、整型和长整型的原因:有些整型数据可能比较小,使用short就够了,如:年龄。short的范围:-32768 ~ 32767。
4. 对于整型类型,还分为 有符号(signed) 和 无符号(unsigned)
(2). 类型的基本归类:
整型类型:(只有整型分有符号和无符号)
char:
unsigned char
signed char
(字符存储时,存储的是ASCII码值,是整型,所以归类时把char放在整型类型中)
(直接写成 char 是 signed char 还是 unsigned char 是不确定的,取决于编译器)
short:
unsigned short [int]
signed short [int] == short [int]
( [int]通常会省略掉 )
int:
unsigned int
signed int == int
long
unsigned long [int]
signed long [int] == long [int]
( [int]通常会省略掉 )
long long
unsigned long long [int]
signed long long [int] == long long [int]
( [int]通常会省略掉 )
signed:二进制位的最高位是 符号位,其它位都是 数值位
unsigned:二进制位的最高位也是 数值位,即所有位都是 数值位
例如(其它整型类型以此类推):
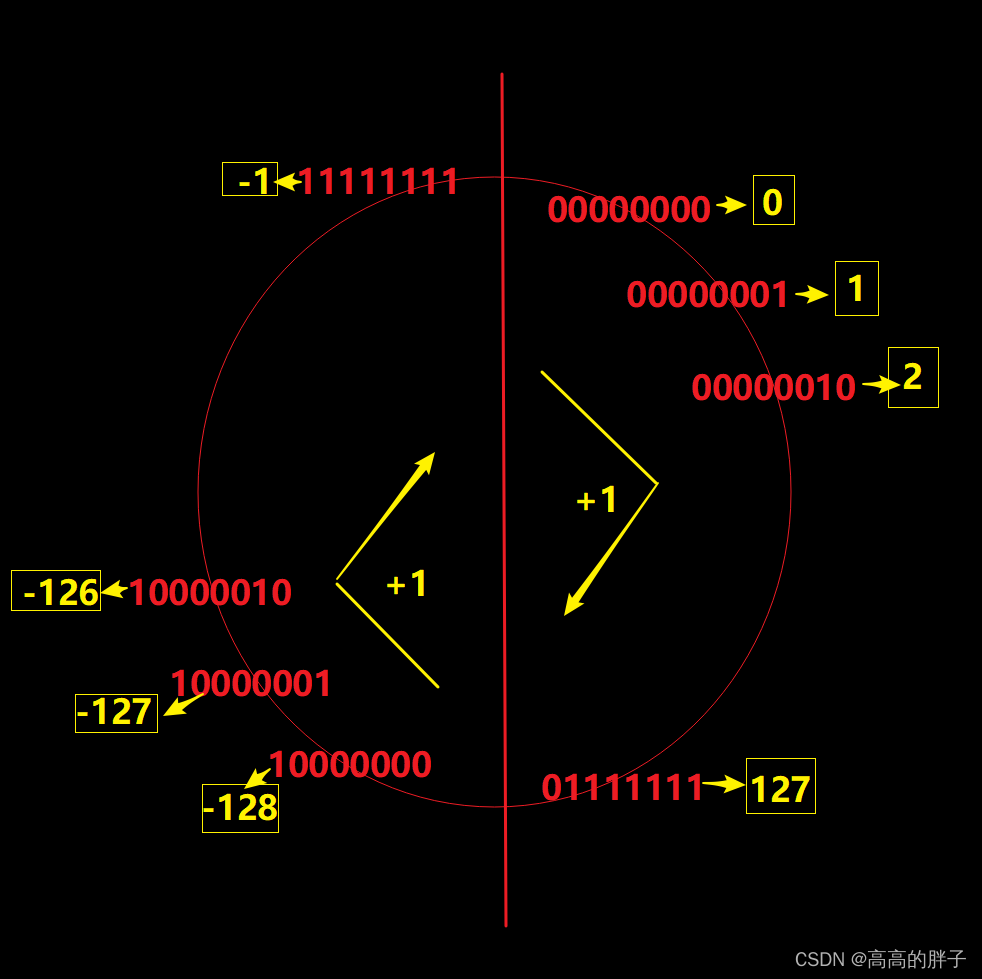
(signed char 范围是:-128~127,补码:10000000无法转换为原码,被直接当成-128)
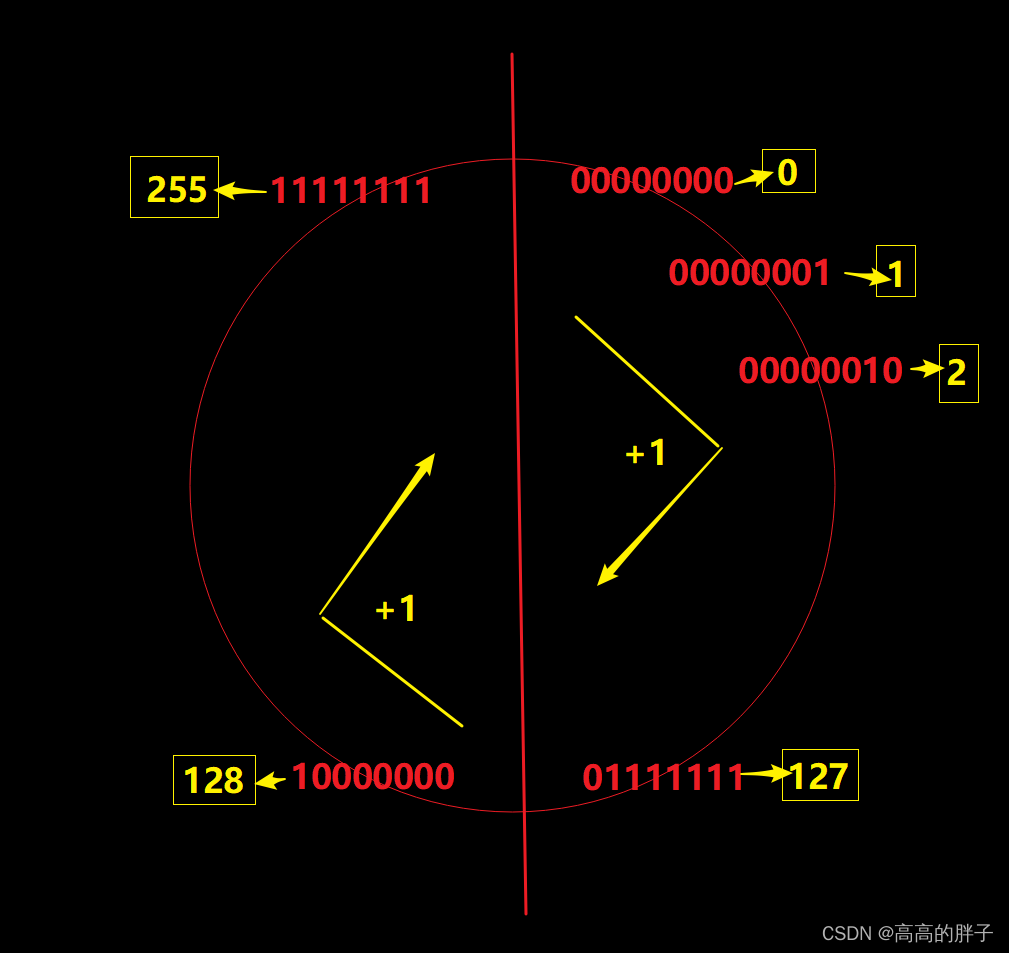
(unsigned char 范围是:0~255,8位全是数值位,无负数)
浮点数类型:
float
double
long double
构造类型(自定义类型):
数组类型:
(数组的元素个数 和 数组的类型 发生变化时,数组类型就不一样了:)
int arr1[10]; 类型是 int [10]
int arr2[5]; 类型是 int [5]
char arr3[5]; 类型是 char [5]
(这是三个不同的数组类型)
结构体类型 struct
枚举类型 enum
联合类型 union
指针类型:
int* pi;
char* pc;
float* pf;
void* pv;
空类型:
void 表示 空类型(无类型):通常应用于函数的返回类型、函数的参数、指针类型。
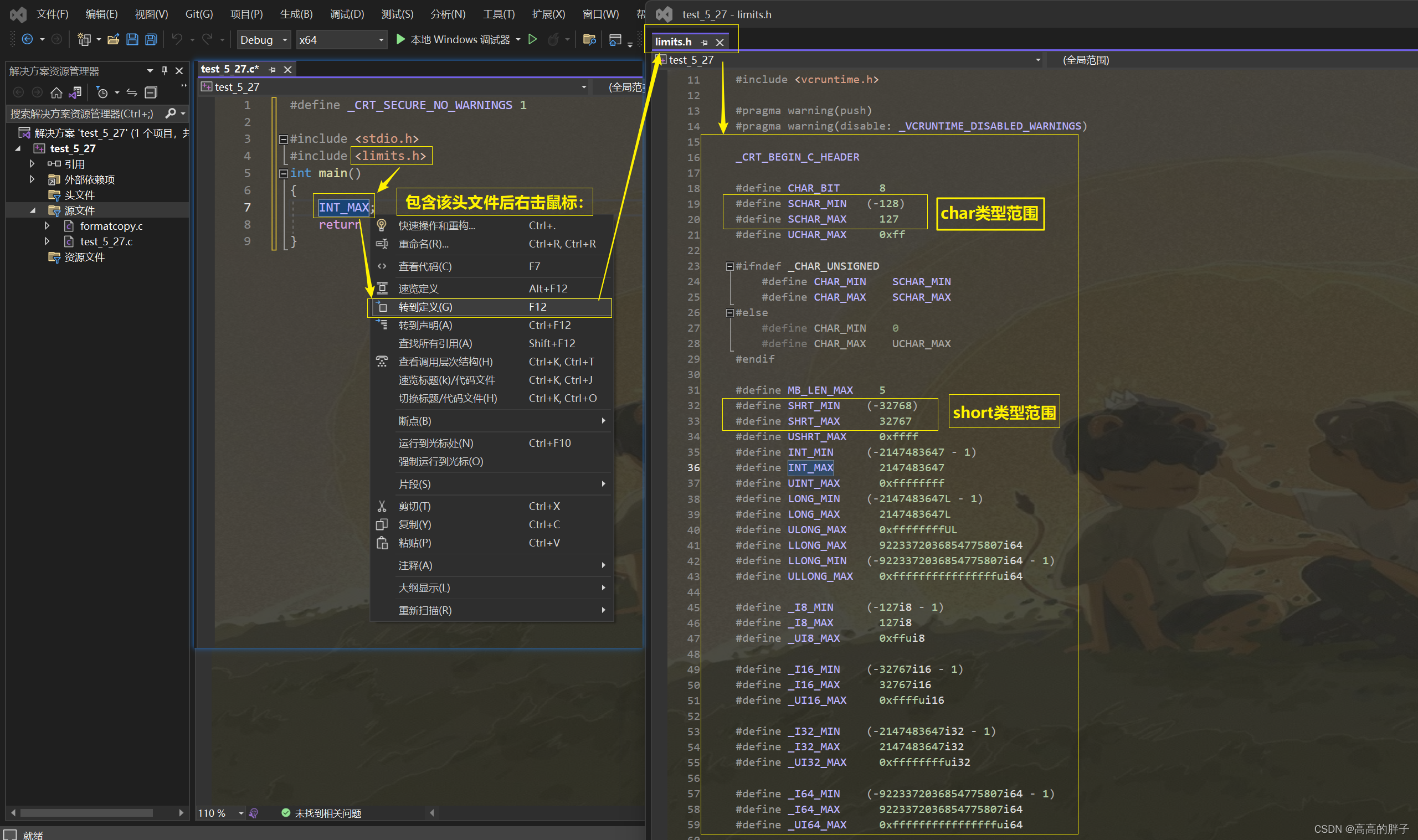
2. 整型在内存中的存储
变量的创建时要在内存中开辟空间的,空间的大小是根据不同的类型而决定的
而开辟空间后,数据在所开辟内存中是如何存储的呢?
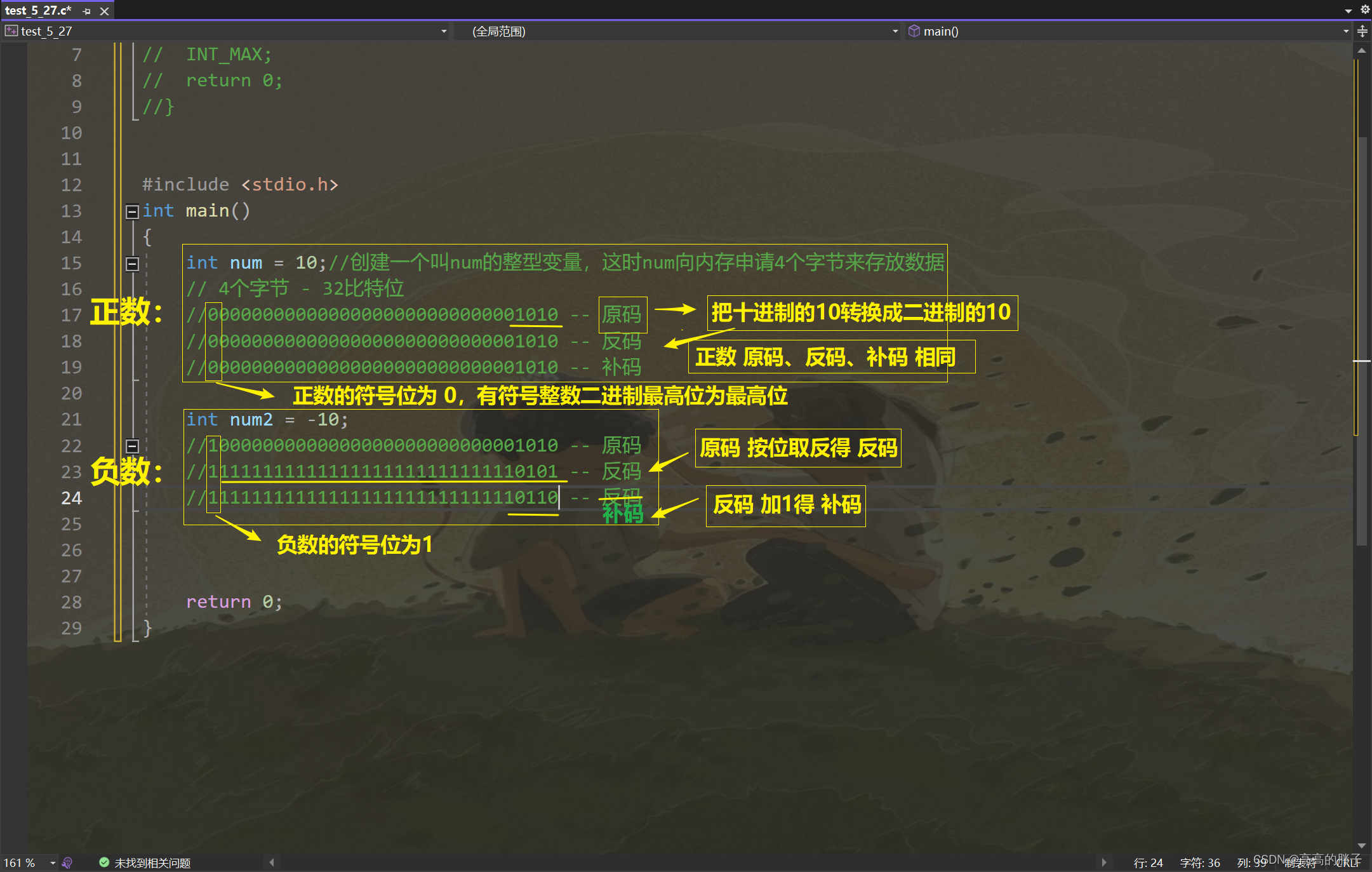
(1). 整数用二进制表示的三种表示形式:原码、反码、补码
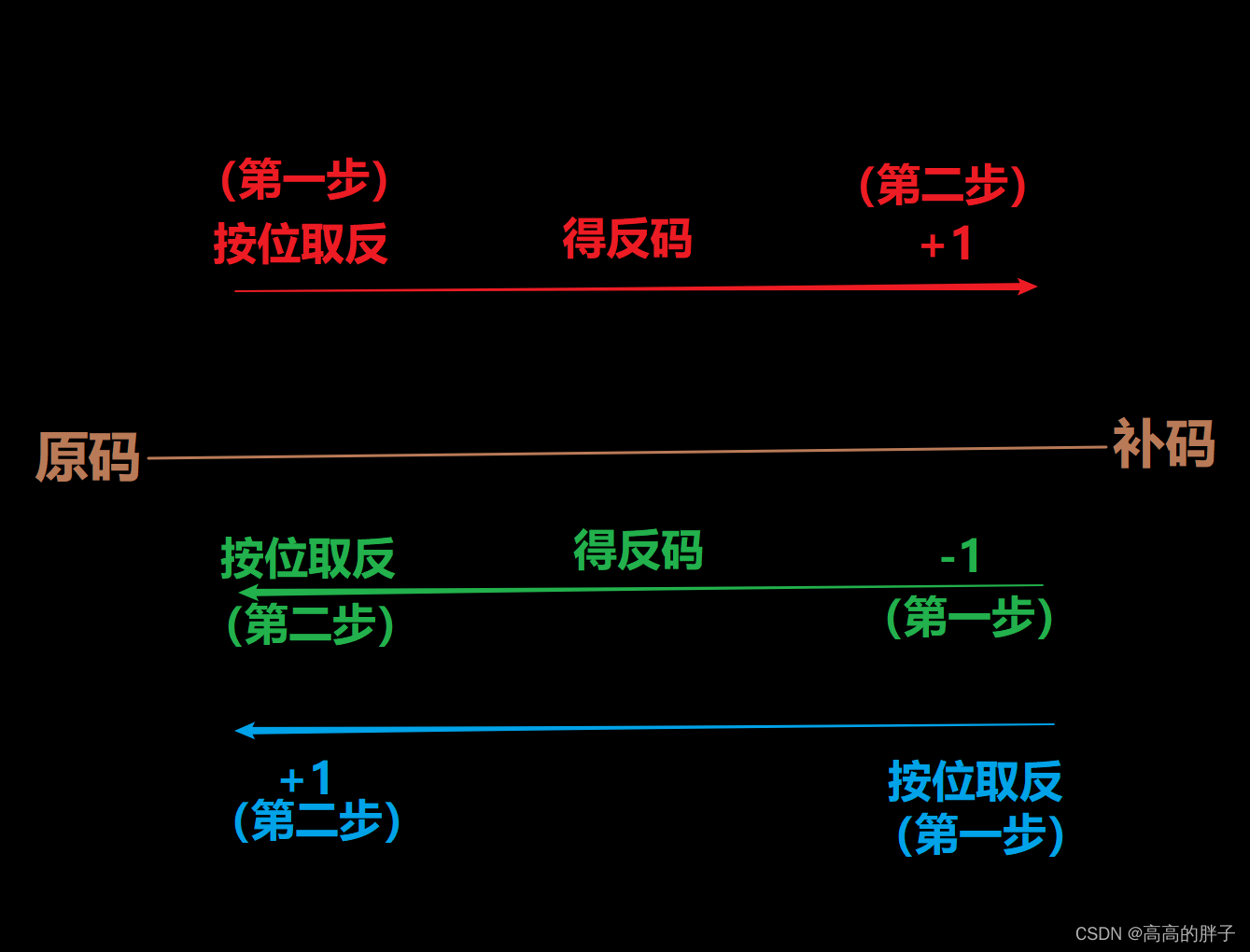
原码:
正数:直接将数值按照正负数的形式翻译成二进制得到原码
负数:直接将数值按照正负数的形式翻译成二进制得到原码
或者
反码按位取反得到原码
再或者
补码按位取反,再+1得到原码
反码:
正数:原码、反码、补码 都相同
负数:原码的符号位不变,将其它位依次按位取反得到反码
或者
补码-1得到反码
补码:
正数:原码、反码、补码 都相同
负数:反码+1得到补码
(2). 符号位 和 数值位(整数)
上面三种表示形式都有 符号位 和 数值位 两部分:
符号位:
二进制最高位的一位叫做符号位,
符号位 用 0 表示 “正”;
符号位 用 1 表示 “负”。
数值位:
除了符号位,其它位都是数值位
对于正数:原码、反码、补码 都相同
对于负数:三种表示方法各不相同(参考上面)
(演示代码:)
#include <stdio.h> int main() {int num = 10;//创建一个叫num的整型变量,这时num向内存申请4个字节来存放数据// 4个字节 - 32比特位//00000000000000000000000000001010 -- 原码//00000000000000000000000000001010 -- 反码//00000000000000000000000000001010 -- 补码int num2 = -10;//10000000000000000000000000001010 -- 原码//11111111111111111111111111110101 -- 反码//11111111111111111111111111110110 -- 补码return 0; }
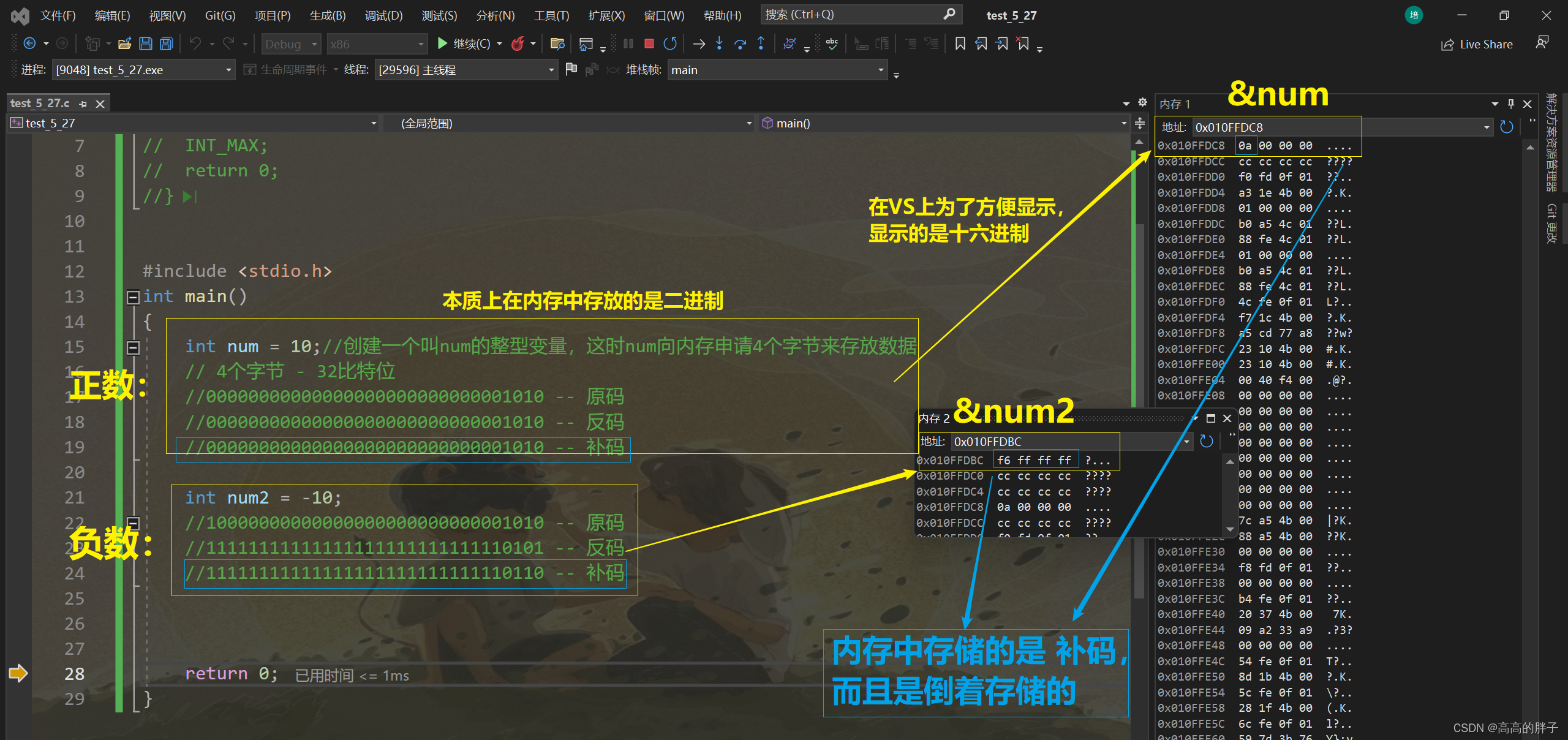
对于整型来说:数据存放在内存中其实存放的是补码
在计算机系统中,数值一律用 补码 来表示和存储。
原因在于:使用补码,可以将符号位和数值位统一处理(把符号位也看成数值位来计算);
同时,加法和减法也可以统一处理(CPU只有加法器),
此为,补码和原码相互转换,其运算过程是相同的
(原码转换为补码按位取反再+1,补码转换为原码也可以按位取反再+1),
不需要额外的硬件电路。
只有加法器,计算减法时:1 - 1 --> 1 + (-1) ,
假设计算用的是原码,算出来的是 -2,是错误的
而用补码进行计算后,再用原码表示,结果则是对的
(为什么会倒着存储呢?)
(3). 大小端介绍
字节序:
以字节为单位,讨论存储顺序(大端字节序存储 / 小端字节序存储)
低位 / 高位:
十进制:数字123,1是百位,2是十位,3是个位。这里的1就是高位,3就是低位。
十六进制:0x 11 22 33 44,这里 11 就是高位,44就是低位。
大端字节序存储:
大端(存储)模式:指数据的低位字节内容保存在内存的高地址中,而数据的高位字节内容,保存在内存的低地址中;
(低位高地址,高位低地址)
小端字节序存储:
小段(存储)模式:指数据的低位字节内容保存在内存的低地址中,而数据的高位字节内容,保存在内存的高地址中;
(低位低地址,高位高地址)
为什么有大端和小段:
一个数据只要超过一个字节,在内存中存储的时候就必然涉及到顺序的问题,所以要有大端和小端的存储模式对该数据进行排序。
为什么会有大小端模式之分,是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为 8bit 。但是在C语言中除了 8bit 的 char 之外,还有 16bit 的 short 类型,32位的 long 类型(具体要看编译器),另外,对于位数大于8位的处理器,例如 16位 或者 32位 的处理器,由于寄存器宽度大于一个字节,那么就存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式 。
例如:一个 16bit 的 short 类型 x ,在内存中的地址为 0x0010,x 的值为 0x1122,那么 0x11 为高字节,0x22 为低字节。对于大端模式,就将 0x11 放在低地址中,即地址 0x0010 中, 0x22 放在高地址中,即地址 0x0011 中。小端模式则相反。
我们常用的 x86 结构是小端模式,所以上面的图数据会“倒着放”,低位字节放在了低地址,高位字节放在了高地址。而 KEIL C51 则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择为大端模式还是小端模式。
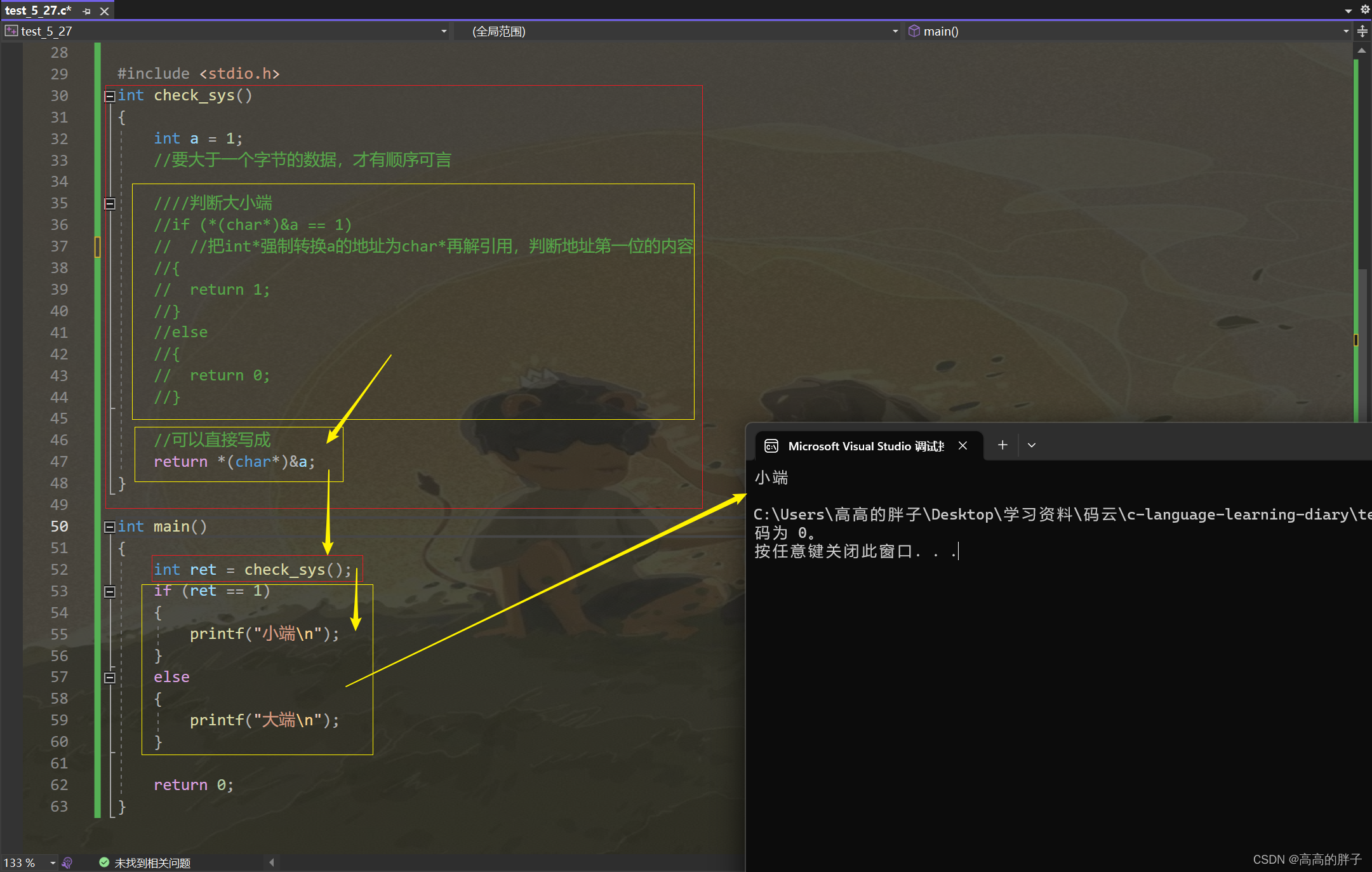
(4). 写个程序判断大小端:
思路:
有变量a,存放在内存中的十六进制数为:01 00 00 00(小端存储),地址第一位是1,
如果是大端存储:则应该是:00 00 00 01,地址第一位是0,
可以把 a 的地址取出第一位,如果
第一位地址 == 1,说明是小端存储,
第一位地址 == 0,说明是大端存储,
取出 int类型a 的 地址 第一位方法:
*(char*)&a
把 int* 强制转换为 char*,再解引用,即可取出一位地址的内容。
实现代码:
#include <stdio.h> int check_sys() {int a = 1;//要大于一个字节的数据,才有顺序可言判断大小端//if (*(char*)&a == 1)// //把int*强制转换a的地址为char*再解引用,判断地址第一位的内容//{// return 1;//}//else//{// return 0;//}//可以直接写成return *(char*)&a; }int main() {int ret = check_sys();if (ret == 1){printf("小端\n");}else{printf("大端\n");}return 0; }
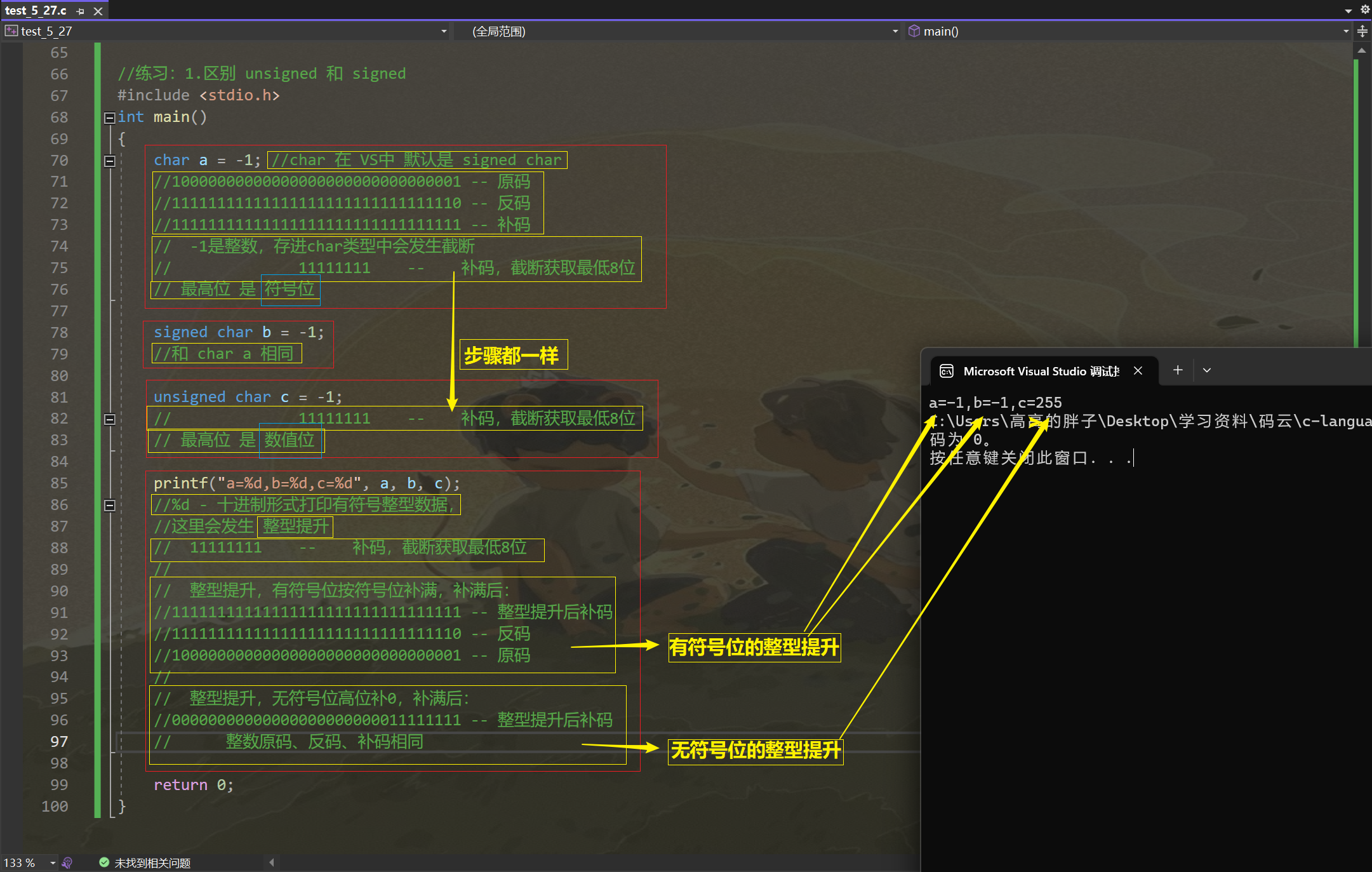
(5). 练习:(重点在注释)
1. 区别 unsigned 和 signed :
//练习:1.区别 unsigned 和 signed #include <stdio.h> int main() {char a = -1; //char 在 VS中 默认是 signed char//10000000000000000000000000000001 -- 原码//11111111111111111111111111111110 -- 反码//11111111111111111111111111111111 -- 补码// -1是整数,存进char类型中会发生截断// 11111111 -- 补码,截断获取最低8位// 最高位 是 符号位signed char b = -1;//和 char a 相同unsigned char c = -1;// 11111111 -- 补码,截断获取最低8位// 最高位 是 数值位printf("a=%d,b=%d,c=%d", a, b, c);//%d - 十进制形式打印有符号整型数据,//这里会发生 整型提升// 11111111 -- 补码,截断获取最低8位// // 整型提升,有符号位按符号位补满,补满后://11111111111111111111111111111111 -- 整型提升后补码//11111111111111111111111111111110 -- 反码//10000000000000000000000000000001 -- 原码// // 整型提升,无符号位高位补0,补满后://00000000000000000000000011111111 -- 整型提升后补码// 整数原码、反码、补码相同return 0; }
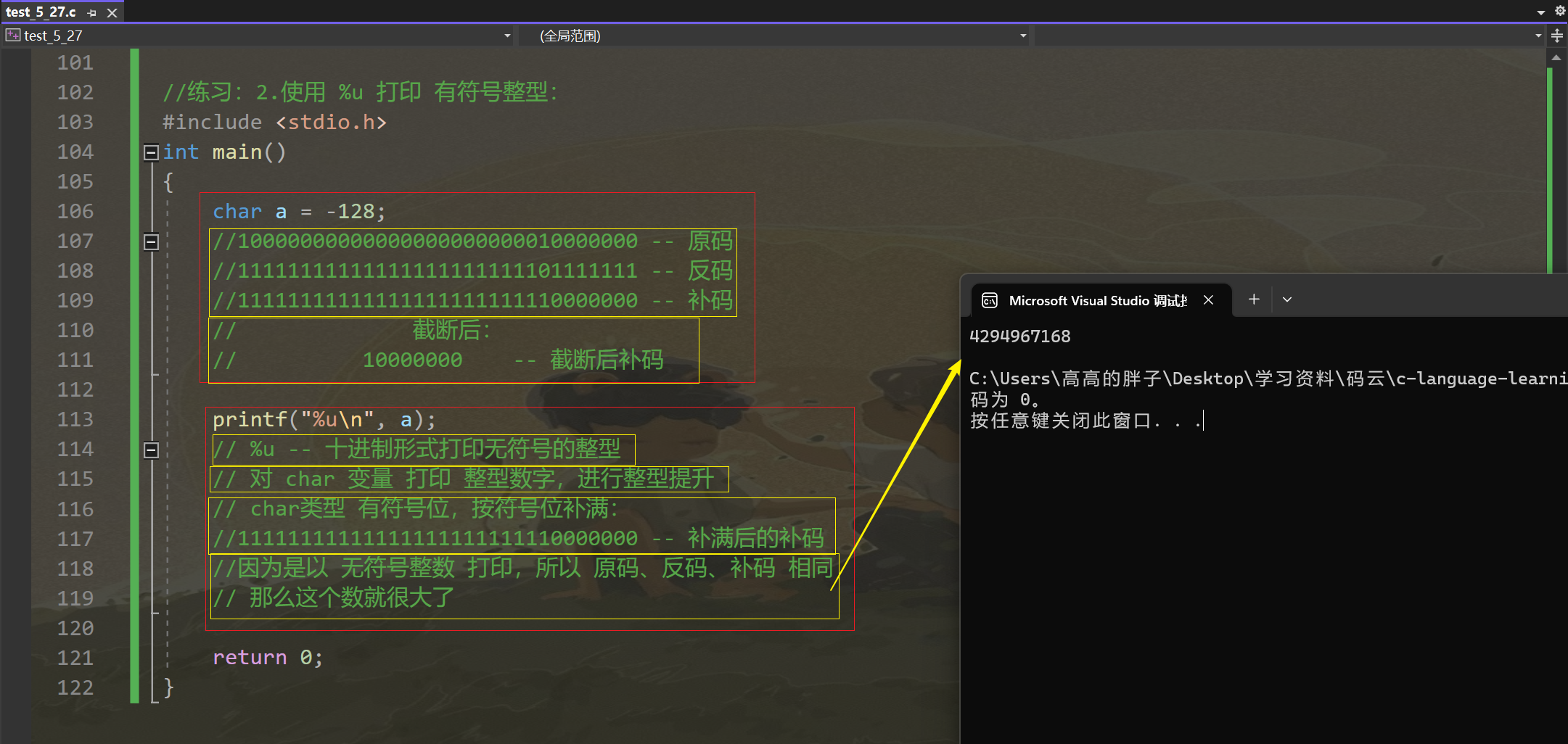
2. 使用 %u 打印 有符号整型:
(补充:%u -- 十进制形式打印无符号的整型)
(1). 打印 -128:
//练习:2.使用 %u 打印 有符号整型: #include <stdio.h> int main() {char a = -128;//10000000000000000000000010000000 -- 原码//11111111111111111111111101111111 -- 反码//11111111111111111111111110000000 -- 补码// 截断后:// 10000000 -- 截断后补码printf("%u\n", a);// %u -- 十进制形式打印无符号的整型// 对 char 变量 打印 整型数字,进行整型提升// char类型 有符号位,按符号位补满://11111111111111111111111110000000 -- 补满后的补码//因为是以 无符号整数 打印,所以 原码、反码、补码 相同// 那么这个数就很大了return 0; }
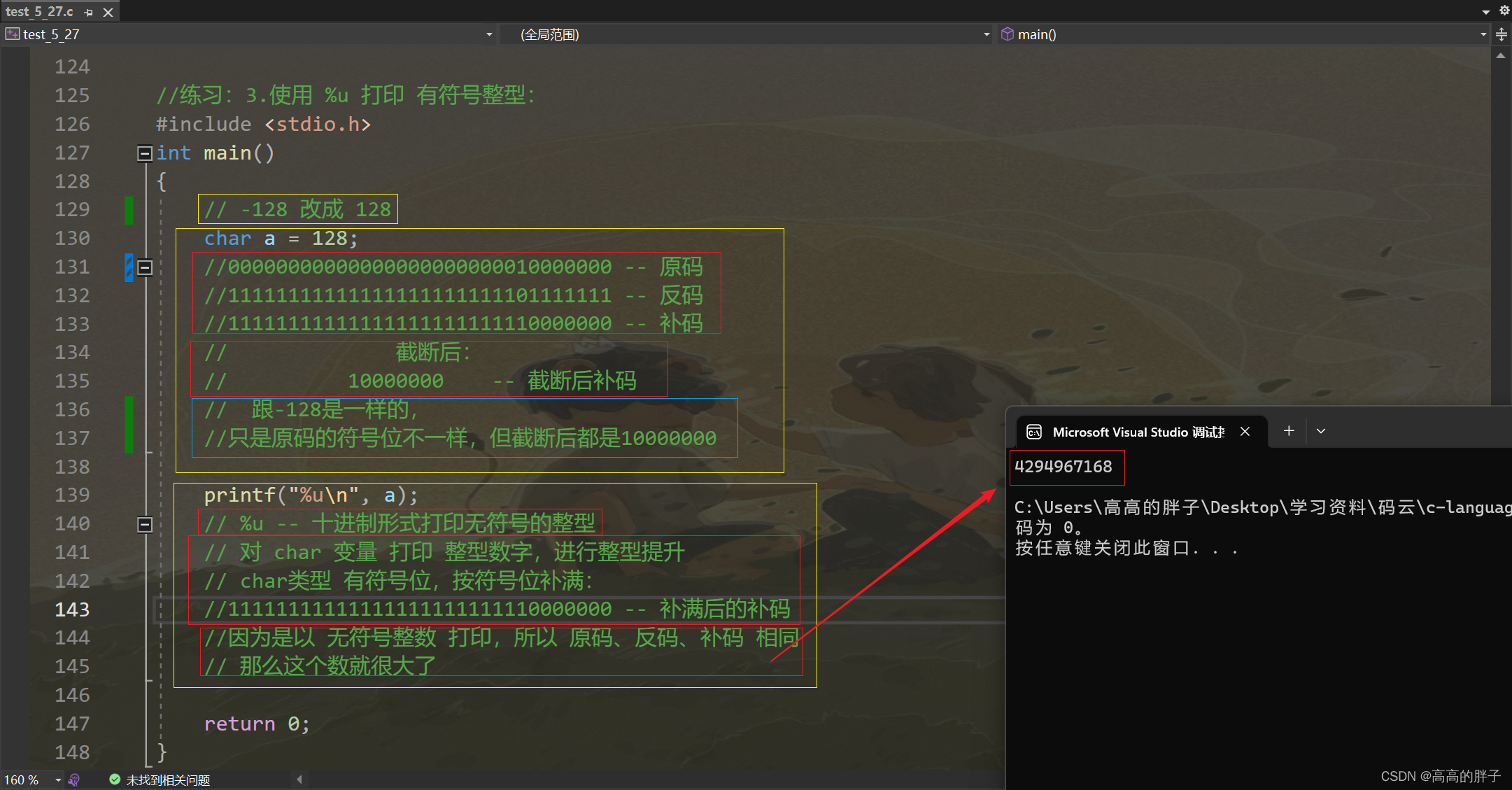
(2). 打印 128:
//练习:3.使用 %u 打印 有符号整型: #include <stdio.h> int main() {// -128 改成 128char a = 128;//00000000000000000000000010000000 -- 原码//11111111111111111111111101111111 -- 反码//11111111111111111111111110000000 -- 补码// 截断后:// 10000000 -- 截断后补码// 跟-128是一样的,//只是原码的符号位不一样,但截断后都是10000000printf("%u\n", a);// %u -- 十进制形式打印无符号的整型// 对 char 变量 打印 整型数字,进行整型提升// char类型 有符号位,按符号位补满://11111111111111111111111110000000 -- 补满后的补码//因为是以 无符号整数 打印,所以 原码、反码、补码 相同// 那么这个数就很大了return 0; }
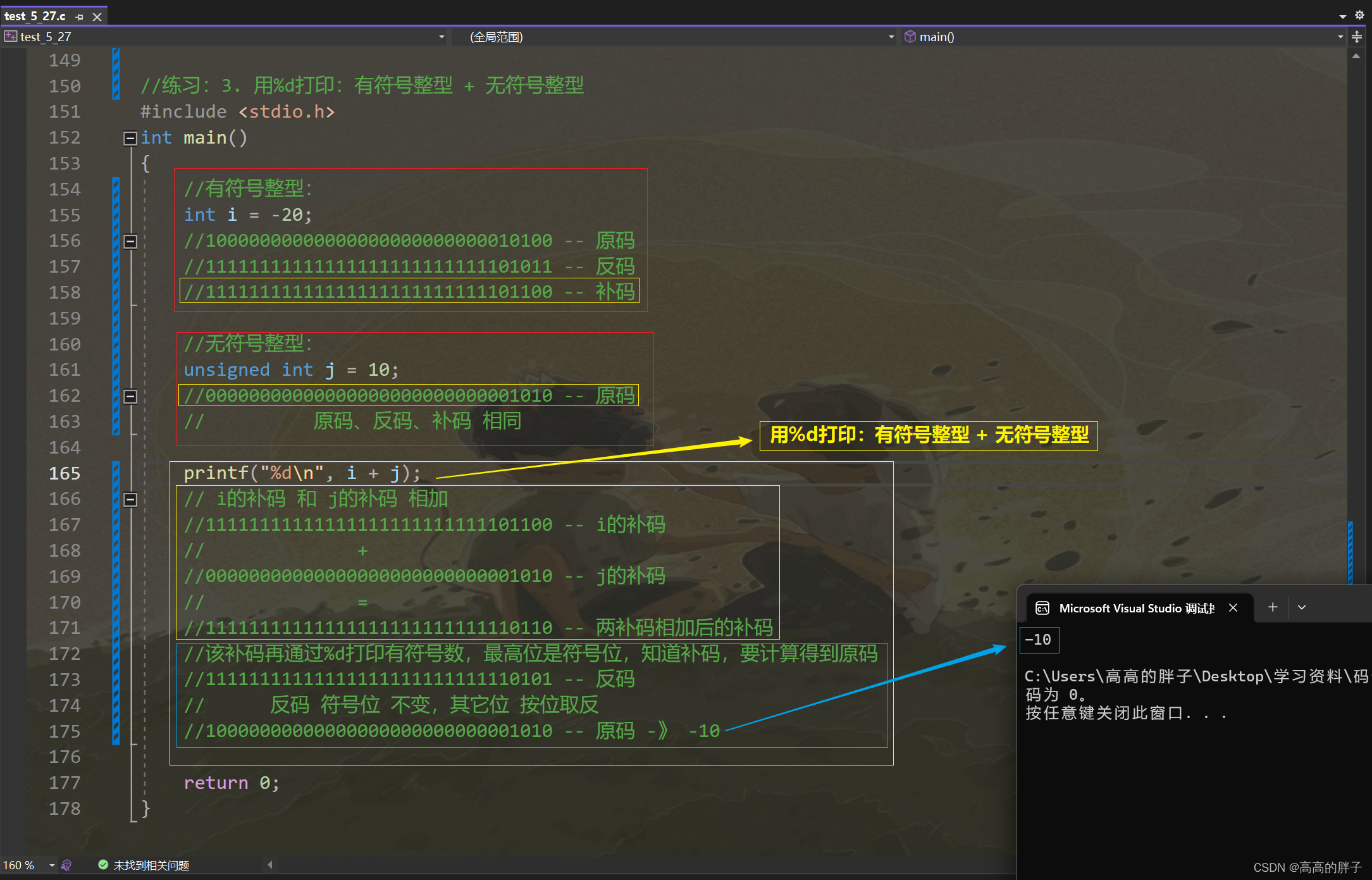
3. 用%d打印:有符号整型 + 无符号整型
//练习:3. 用%d打印:有符号整型 + 无符号整型 #include <stdio.h> int main() {//有符号整型:int i = -20;//10000000000000000000000000010100 -- 原码//11111111111111111111111111101011 -- 反码//11111111111111111111111111101100 -- 补码//无符号整型:unsigned int j = 10;//00000000000000000000000000001010 -- 原码// 原码、反码、补码 相同printf("%d\n", i + j);// i的补码 和 j的补码 相加//11111111111111111111111111101100 -- i的补码// +//00000000000000000000000000001010 -- j的补码// =//11111111111111111111111111110110 -- 两补码相加后的补码//该补码再通过%d打印有符号数,最高位是符号位,知道补码,要计算得到原码//11111111111111111111111111110101 -- 反码// 反码 符号位 不变,其它位 按位取反//10000000000000000000000000001010 -- 原码 -》 -10return 0; }
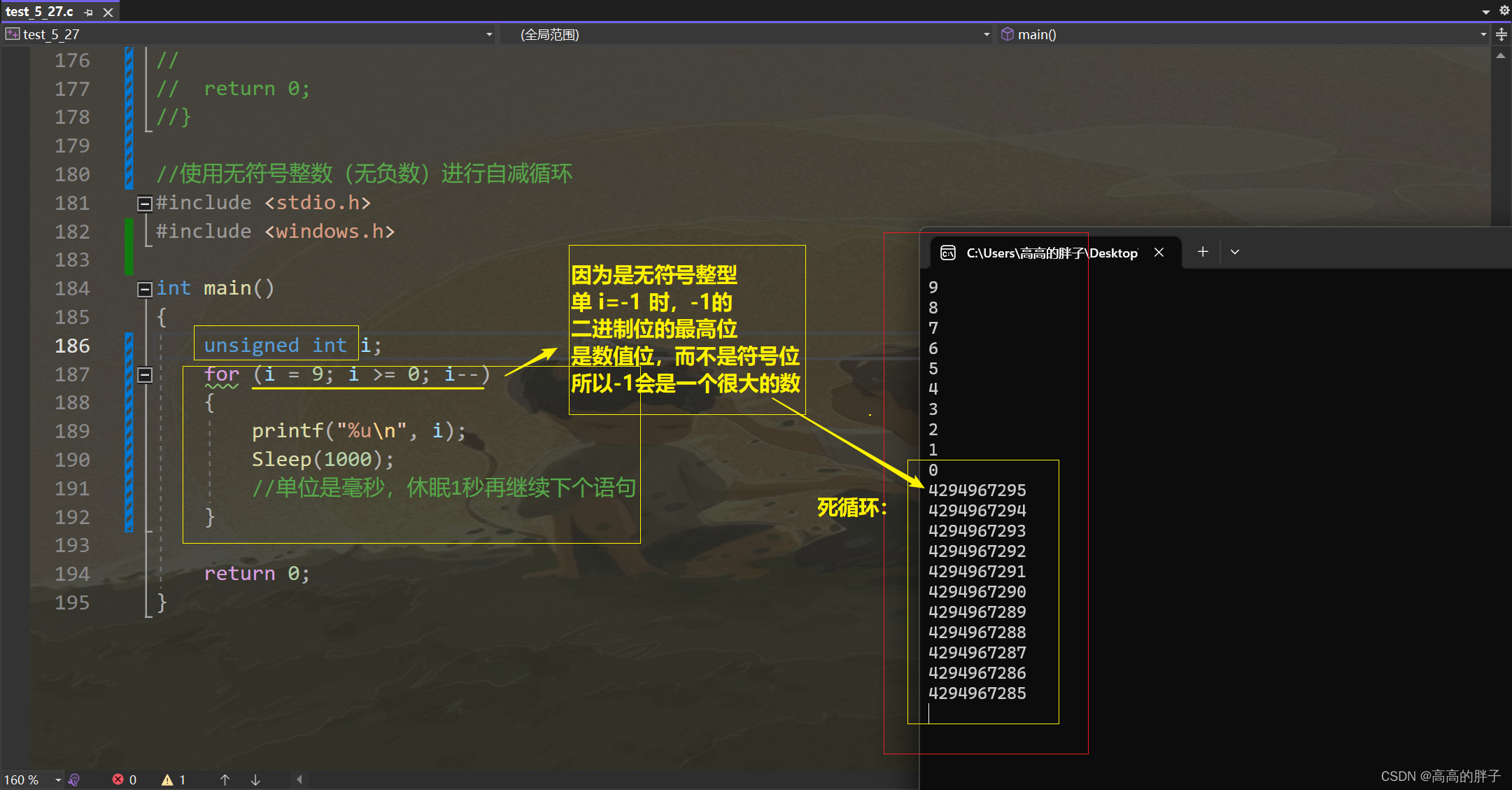
4. 使用无符号整数(无负数)进行自减循环
//使用无符号整数(无负数)进行自减循环 #include <stdio.h> #include <windows.h>int main() {unsigned int i;for (i = 9; i >= 0; i--){printf("%u\n", i);Sleep(1000);//单位是毫秒,休眠1秒再继续下个语句}return 0; }
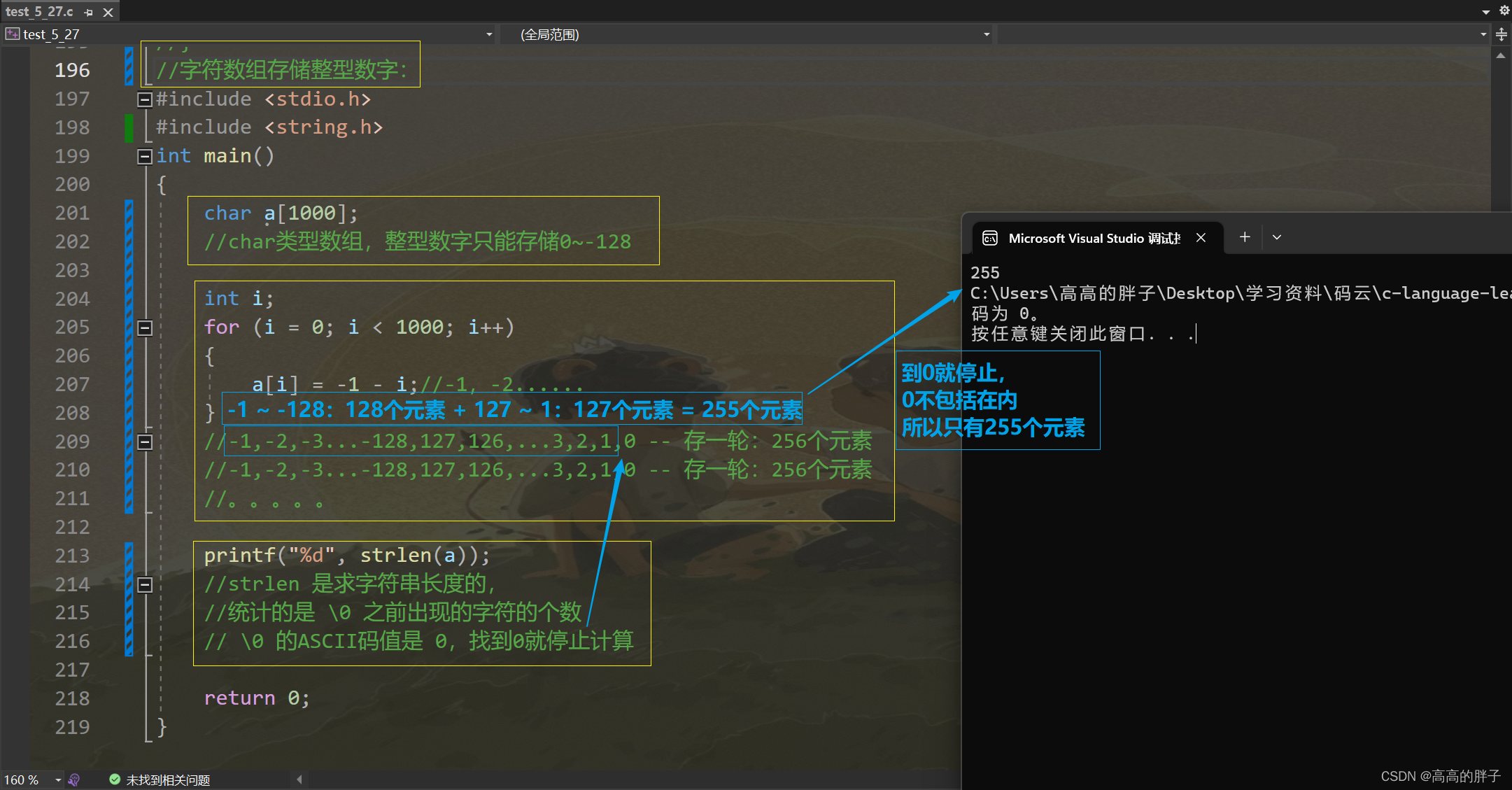
5. 字符数组存储整型数字:
//字符数组存储整型数字: #include <stdio.h> #include <string.h> int main() {char a[1000];//char类型数组,整型数字只能存储0~-128int i;for (i = 0; i < 1000; i++){a[i] = -1 - i;//-1,-2......}//-1,-2,-3...-128,127,126,...3,2,1,0 -- 存一轮:256个元素//-1,-2,-3...-128,127,126,...3,2,1,0 -- 存一轮:256个元素//。。。。。printf("%d", strlen(a));//strlen 是求字符串长度的,//统计的是 \0 之前出现的字符的个数// \0 的ASCII码值是 0,找到0就停止计算return 0; }
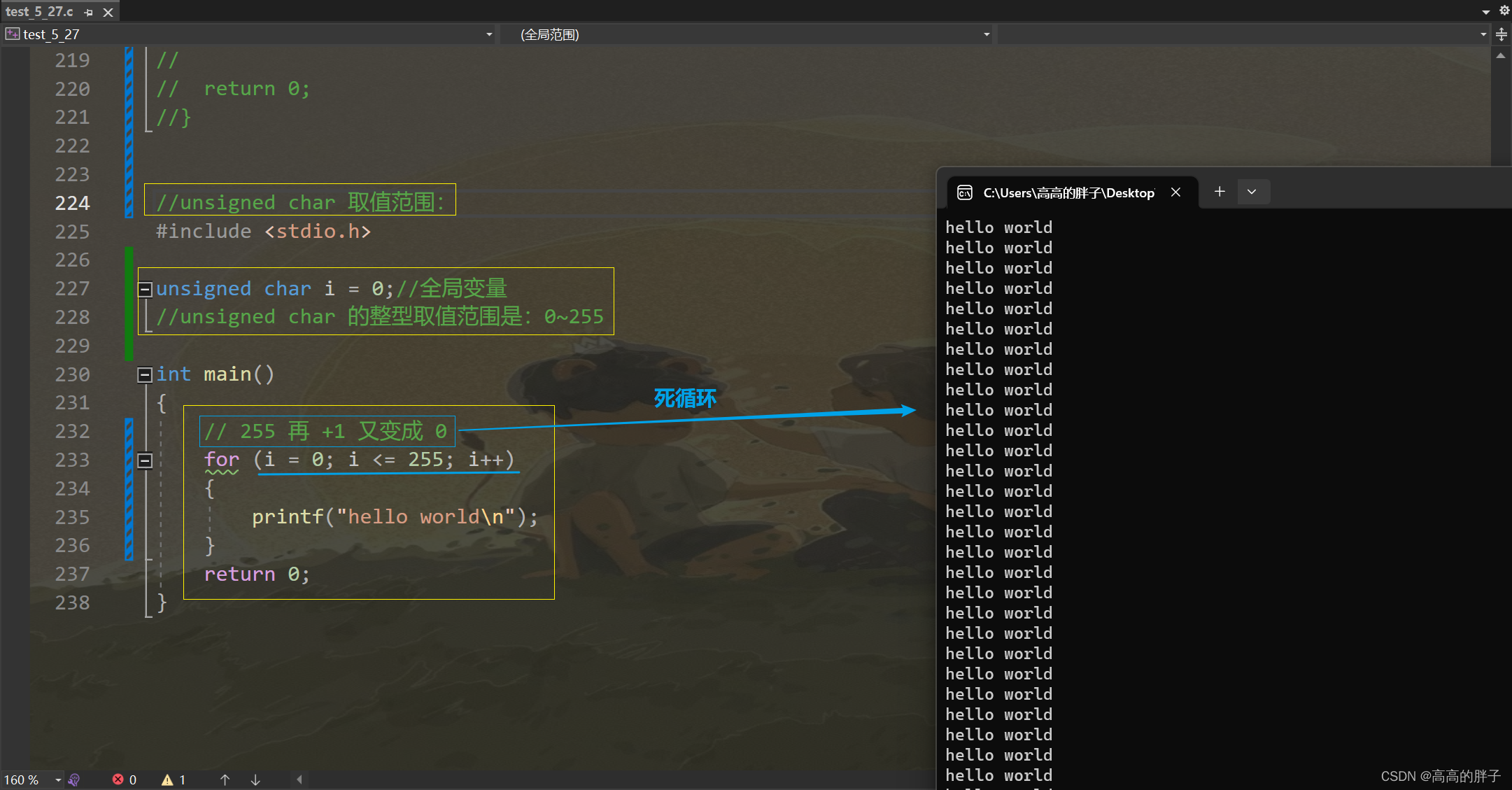
6. unsigned char 取值范围:
//unsigned char 取值范围: #include <stdio.h>unsigned char i = 0;//全局变量 //unsigned char 的整型取值范围是:0~255int main() {// 255 再 +1 又变成 0for (i = 0; i <= 255; i++){printf("hello world\n");}return 0; }
相关文章:
学C的第二十二天【深度剖析数据在内存中的存储:1. 数据类型介绍;2. 整型在内存中的存储】
相关代码gitee自取:C语言学习日记: 加油努力 (gitee.com) 接上期:学C的第二十一天【初阶测评讲解:1. 计算递归了几次;2. 判断 do while 循环执行了几次;3. 求输入的两个数的最小公倍数;4. 将一句话的单词进…...

测试计划模板一
测试计划 修订历史记录 版本 日期 AMD 修订者 说明 1.0 XXXX年XX月XX (A-添加,M-修改,D-删除) 目录 1. 简介.. 4 1. 1目的... 4 1. 2背景... 4...

【利用AI让知识体系化】5种创建型模式
文章目录 创建型模式简介工厂模式抽象工厂模式单例模式建造者模式原型模式 创建型模式 简介 创建型模式,顾名思义,是用来创建对象的模式。在软件开发中,对象的创建往往比一般的编程任务更为复杂,可能涉及到一些琐碎、复杂的过程…...

Unity的UnityStats: 属性详解与实用案例
UnityStats 属性详解 UnityStats 是 Unity 引擎提供的一个用于监测游戏性能的工具,它提供了一系列的属性值,可以帮助开发者解游戏的运行情况,从而进行优化。本文将详细介绍 UnityStats 的每个属性值,并提供多个使用例子帮助开发者…...

TDengine集群搭建
我这里用三台服务器搭建集群 1、如果搭建集群的物理节点上之前安装过TDengine先卸载清空,直接执行以下4条命令 rmtaos rm -rf /var/lib/taos rm -rf /var/log/taos rm -rf /etc/taos2、确保集群中所有主机开放端口 6030-6043/tcp,6060/tcp,…...

Android 12.0无源码apk设置默认启动Launcher的相关属性
1.概述 在12.0的系统产品开发中,对于一些产品的需求,需要将一些无源码app的某个MainActivity作为启动Launcher页面的功能实现,由于没有源码,所以需要 利用PMS的安装解析apk的AndroidManifest.xml的时候,在判断是某个Activity的时候,设置Lancher属性来实现某些功能 2.无源…...

js深拷贝和浅拷贝
👉十分钟学会 前端面试题 js 深拷贝与浅拷贝_前端深拷贝和浅拷贝面试题_Mar-30的博客-CSDN博客 目录 背景: 概念:核心是创建新地址 方法: 浅拷贝: Object.assign() 方法:Object.assign(拷贝的对象&am…...
CANopenNode Master 配置
文章目录 CANopenNode 简介CANopenNode 主栈SDO ClientPDO 通讯参数RPDO 通讯参数RPDO 通信参数设置实例TPDO 通讯参数TPDO 通信参数设置实例 PDO 映射参数RPDO 映射参数设置实例TPDO 映射参数设置实例 CANopenNode 简介 CANopenNode 是一个开源的免费的开源 CANopen 协议栈。…...
HW之轻量级内网资产探测漏洞扫描工具
简介 RGPScan是一款支持弱口令爆破的内网资产探测漏洞扫描工具,集成了Xray与Nuclei的Poc 工具定位 内网资产探测、通用漏洞扫描、弱口令爆破、端口转发、内网穿透、SOCK5 主机[IP&域名]存活检测,支持PING/ICMP模式 端口[IP&域名]服务扫描 网…...
算法练习-2:送外卖
n 个小区排成一列,编号为从 0 到 n-1 。一开始,美团外卖员在第0号小区,目标为位于第 n-1 个小区的配送站。 给定两个整数数列 a[0]~a[n-1] 和 b[0]~b[n-1] ,在每个小区 i 里你有两种选择: 1) 选择a:向前 a[…...
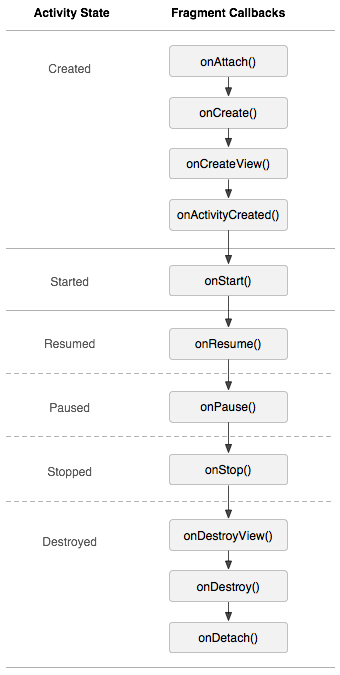
八股总结(六):Android基础:四大组件与UI控件
文章目录 Activity一个APP的启动过程基本概念总图zygote是什么?有什么作用?SystemServer是什么?有什么用,与zygote的关系是什么?为什么称为服务端对象?APP、AMS、zygote是三个独立的进程,他们之…...

【P46】JMeter 响应断言(Response Assertion)
文章目录 一、响应断言(Response Assertion) 参数说明二、准备工作三、测试计划设计3.1、包括3.2、匹配3.3、相等3.4、字符串3.5、字符串3.6、或者 一、响应断言(Response Assertion) 参数说明 可以对 Jmeter 取样器的响应消息进…...
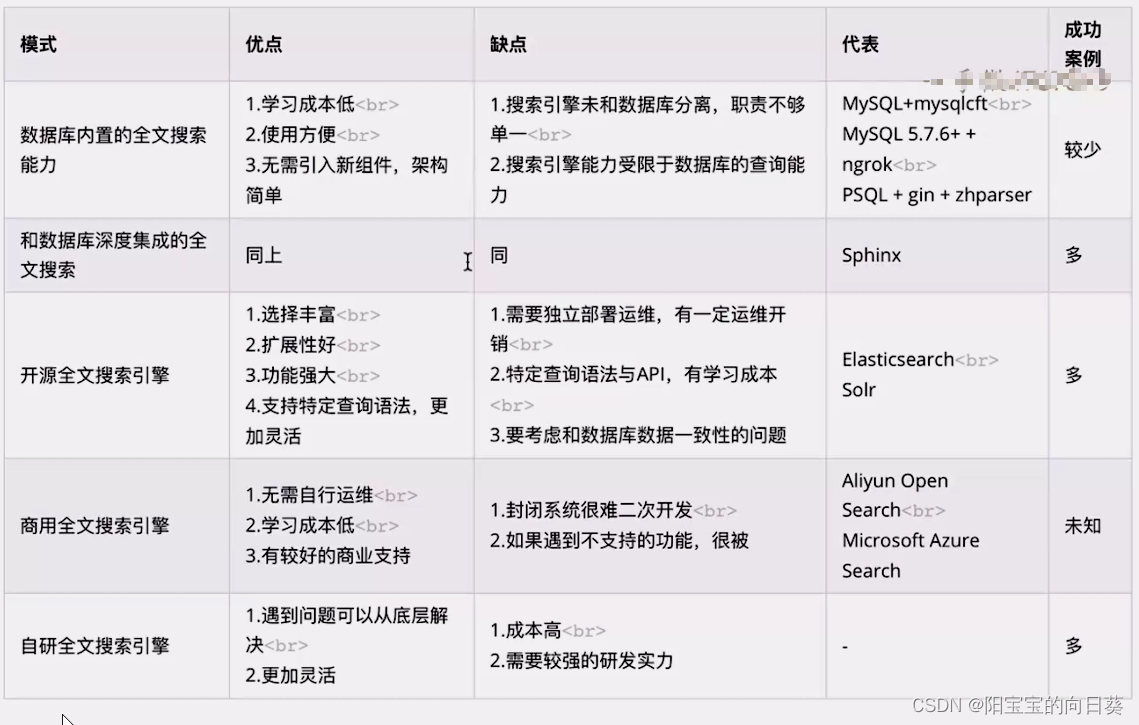
19-02 基于业务量级的架构技术选型演进
从零开始——单服务应用 单体应用技术选型 (GitHub、Gitee…)搜索是否有线程的产品用最熟悉的技术,最快的速度上线如果有经费:考虑商业化解决方案 个人小程序怎么做技术选型的 搜索是否有快速搭建下程序的软件技术选型 后端技…...

Server - 高性能的 PyTorch 训练环境配置 (PyTorch3D 和 FairScale)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://blog.csdn.net/caroline_wendy/article/details/130863537 PyTorch3D 是基于 PyTorch 的 3D 数据深度学习库,提供了高效、模块化和可微分的组件,以简化 3D 深度学…...
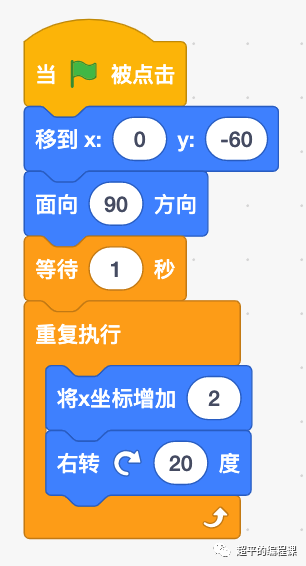
小猫踩球-第14届蓝桥杯省赛Scratch中级组真题第2题
[导读]:超平老师的《Scratch蓝桥杯真题解析100讲》已经全部完成,后续会不定期解读蓝桥杯真题,这是Scratch蓝桥杯真题解析第137讲。 小猫踩球,本题是2023年5月7日举行的第14届蓝桥杯省赛Scratch图形化编程中级组真题第2题…...
)
嵌入式开发从入门到精通之第二十一节:三轴加速度传感器(BMA250E)
目录 1、工作模式 2、中断支持的模式 2.1 新数据的产生 2.2 任何斜率的变化的监测...

代码随想录算法训练营第三十六天|435. 无重叠区间 763.划分字母区间 56. 合并区间
目录 LeeCode 435. 无重叠区间 LeeCode 763.划分字母区间 LeeCode 56. 合并区间 LeeCode 435. 无重叠区间 435. 无重叠区间 - 力扣(LeetCode) 思路1:按照右边界排序,从左向右记录非交叉区间的个数。最后用区间总数减去非交叉…...

shell 脚本
Shell概述 shell是一个命令行解释器,它接收应用程序/用户命令,然后调用操作系统内核 脚本入门 脚本格式 脚本以#!/bin/bash开头(指定解析器) helloworld # 创建脚本 [linuxlocalhost datas]$ cat helloworld.sh #!/bin/bas…...
:(4)】::用户切换)
Linux :: 【基础指令篇 :: 用户管理(补充):(4)】::用户切换
前言:本篇是 Linux 基本操作篇章的内容! 笔者使用的环境是基于腾讯云服务器:CentOS 7.6 64bit。 学习集: C 入门到入土!!!学习合集Linux 从命令到网络再到内核!学习合集 目录索引&am…...

打印机无法扫描的原因及解决方法
在家庭和办公环境中,打印机已成为不可或缺的设备。它不仅可以打印文件,还可以扫描文档并将它们转换为数字数据。但有时,打印机可能无法扫描文档或图片。以下是可能导致这些问题的原因和解决方法。 出现打印机无法扫描的原因: 1.…...
)
DeepSeek代码风格检查避坑指南(内部审计报告首次披露:37个被忽略的合规红线)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek代码风格检查的合规性本质与审计背景 DeepSeek代码风格检查并非单纯的技术偏好约束,而是嵌入研发治理链条中的合规性控制节点。其本质是将编程实践与组织级安全策略、行业监管要求&…...

【大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型?】
大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型? 随着大模型技术的快速发展,越来越多的企业开始将 AI 能力融入到业务流程中。然而,面对市场上众多的大模型产品,企业往往面临着 “选择困难…...

如何通过Joy-Con Toolkit实现专业级Switch手柄控制与硬件逆向工程
如何通过Joy-Con Toolkit实现专业级Switch手柄控制与硬件逆向工程 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit 在游戏开发、硬件调试和嵌入式系统研究中,与游戏手柄等专业输入设备进行深度交互一直…...

【2026实测】怎么提高论文原创度?盘点8款主流降AI工具,附结构级优化指南
写文章最怕碰到什么,是辛辛苦苦自己码出来的字,却被标了极高的AI值。目前很多文本审核机制对内容的原创度要求极高,纯手写的初稿也可能因为句式太工整被判定为机器生成的。 为了帮几个快被这事折腾疯了的学弟学妹找条出路,我花了…...

Redis 客户端连接详解
Redis 客户端连接详解 引言 Redis 是一款高性能的内存数据结构存储系统,常用于缓存、会话管理、实时排行榜等功能。客户端连接是 Redis 生态系统中的重要组成部分,本文将详细介绍 Redis 客户端连接的相关知识,包括连接方式、连接配置、连接管理等方面。 Redis 客户端连接…...
)
告别KITTI!用TartanAir数据集在Unreal Engine仿真环境里“虐”你的VSLAM算法(附保姆级下载与使用指南)
用TartanAir数据集在Unreal Engine中打造VSLAM算法的"极限考场"当你的视觉SLAM算法在KITTI数据集上跑出98%的准确率时,是否意味着它已经准备好应对真实世界的复杂场景?现实往往会给乐观的开发者当头一棒——实验室里的"优等生"在遇到…...

为什么你明明很努力,领导却总看不到?问题出在这
许多测试同行在深夜加班排查Bug时,在凌晨赶写自动化脚本时,在对着海量数据做性能分析时,内心都会浮现一个共同的困惑:我明明已经这么拼了,为什么在领导眼里,我依然是个“找茬的”,而不是“创造价…...

Charles弱网测试六维参数实战:从丢包率到DNS延迟的精准复现
1. 为什么弱网测试不能只靠“模拟3G”按钮点一下就完事做移动端或Web前端的同学,大概率都听过这句话:“上线前跑一遍Charles,切个2G网络测下加载。”——听起来很专业,实际一查日志,发现90%的团队连Charles的Throttlin…...

ABS+神经网络:端到端宇宙学参数推断新范式解析
1. 项目概述:当ABS遇上神经网络,一个端到端宇宙学参数推断新范式的诞生 在宇宙学研究的核心地带,有一项任务既令人着迷又充满挑战:如何从宇宙微波背景(CMB)这张宇宙婴儿时期的“照片”中,精准地…...

Pearcleaner:让Mac告别臃肿的3大清理秘籍
Pearcleaner:让Mac告别臃肿的3大清理秘籍 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 还在为Mac存储空间不足而烦恼吗?每次删除应…...