Caffeine 本地高速缓存工具类
目录
Caffeine工具类方式
SpringBoot 整合 Caffeine 缓存 (SpringCache模式)
驱逐策略
开发使用
Caffeine是一种高性能的缓存库,是基于Java 8的最佳(最优)缓存框架,性能各方面优于guava。
Caffeine工具类方式
原文链接:https://www.cnblogs.com/wudiffs/p/11585757.html
代码仓库如下:
<dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId><version>2.4.0</version>
</dependency>代码详细示例如下:
public class CaffeineCacheManagerService {private static LoadingCache<String, CacheVO> cache;private static AsyncLoadingCache<String, CacheVO> asyncCache;private static AsyncLoadingCache<String, CacheVO> asyncCache1;private static ExecutorService executorService = new ThreadPoolExecutor(8, 8, 8, TimeUnit.SECONDS, newLinkedBlockingQueue<Runnable>(1204));static {cache = Caffeine.newBuilder()// 初始化缓存长度.initialCapacity(1024 * 10)// 最大长度.maximumSize(1024 * 10)// 更新策略.refreshAfterWrite(10, TimeUnit.SECONDS)// 设置缓存的过期时间.expireAfterWrite(10, TimeUnit.SECONDS).build(new CacheLoader<String, CacheVO>() {// 同步加载@CheckForNull@Overridepublic CacheVO load(@Nonnull String key) throws Exception {return createCacheVO(key);}// getAll将会对缓存中没有值的key分别调用CacheLoader.load方法来构建缓存的值。// 我们可以重写CacheLoader.loadAll方法来提高getAll的效率。@Nonnull@Overridepublic Map<String, CacheVO> loadAll(@Nonnull Iterable<? extends String> keys) throws Exception {return createBatchCacheVOs(keys);}});// 异步加载 同步load写法,最后也会转异步asyncCache = Caffeine.newBuilder().maximumSize(1024 * 10).expireAfterWrite(10, TimeUnit.SECONDS).buildAsync(new CacheLoader<String, CacheVO>() {@CheckForNull@Overridepublic CacheVO load(@Nonnull String key) throws Exception {return createCacheVO(key);}@Nonnull@Overridepublic Map<String, CacheVO> loadAll(@Nonnull Iterable<? extends String> keys) {return createBatchCacheVOs(keys);}});// 异步加载 异步load写法asyncCache1 = Caffeine.newBuilder().maximumSize(1024 * 10).expireAfterWrite(10, TimeUnit.SECONDS).buildAsync(new AsyncCacheLoader<String, CacheVO>() {@Nonnull@Overridepublic CompletableFuture<CacheVO> asyncLoad(@Nonnull String key, @Nonnull Executor executor) {return asyncCreateCacheVO(key, executor);}@Nonnull@Overridepublic CompletableFuture<Map<String, CacheVO>> asyncLoadAll(@Nonnull Iterable<? extends String> keys, @Nonnull Executor executor) {return asyncCreateBatchCacheVOs(keys, executor);}});}public static CompletableFuture<CacheVO> asyncCreateCacheVO(String key, Executor executor) {return CompletableFuture.supplyAsync(() -> createCacheVO(key), executor);}public static CompletableFuture<Map<String, CacheVO>> asyncCreateBatchCacheVOs(Iterable<? extends String> keys, Executor executor) {return CompletableFuture.supplyAsync(() -> createBatchCacheVOs(keys), executor);}public static CacheVO createCacheVO(String key) {return new CacheVO(key);}public static Map<String, CacheVO> createBatchCacheVOs(Iterable<? extends String> keys) {Map<String, CacheVO> result = new HashMap<>();for (String key : keys) {result.put(key, new CacheVO(key));}return result;}public static void main(String[] args) throws Exception {CacheVO cacheVO1 = cache.get("AA");List<String> list = new ArrayList<>();list.add("BB");list.add("CC");Map<String, CacheVO> map = cache.getAll(list);// 如果有缓存则返回;否则运算、缓存、然后返回,整个过程是阻塞的// 即使多个线程同时请求该值也只会调用一次Function方法CacheVO cacheVO2 = cache.get("DD", (k) -> createCacheVO(k));System.out.println(JSON.toJSONString(cacheVO2));// 单个清除cache.invalidate("AA");// 批量清除cache.invalidateAll(list);// 全部清除cache.invalidateAll();// 返回一个CompletableFutureCompletableFuture<CacheVO> future = asyncCache.get("EE");CacheVO asyncCacheVO = future.get();System.out.println(JSON.toJSONString(asyncCacheVO));// 返回一个CompletableFuture<MAP<>>CompletableFuture<Map<String, CacheVO>> allFuture = asyncCache.getAll(list);Map<String, CacheVO> asyncMap = allFuture.get();System.out.println(JSON.toJSONString(asyncMap));CompletableFuture<CacheVO> future1 = asyncCache1.get("FF");CacheVO asyncCacheVO1 = future1.get();System.out.println(JSON.toJSONString(asyncCacheVO1));CompletableFuture<Map<String, CacheVO>> allFuture1 = asyncCache1.getAll(list);Map<String, CacheVO> asyncMap1 = allFuture.get();System.out.println(JSON.toJSONString(asyncMap1));}}
或者使用下发方式实现Caffeine 工具类
支持同步、异步读写缓存实现
import com.github.benmanes.caffeine.cache.AsyncCache;
import com.github.benmanes.caffeine.cache.Caffeine;import java.util.concurrent.CompletableFuture;
import java.util.concurrent.Executor;
import java.util.concurrent.TimeUnit;public class CaffeineCacheUtils {private static com.github.benmanes.caffeine.cache.Cache<Object, Object> syncCache;private static AsyncCache<Object, Object> asyncCache;private CaffeineCacheUtils() {}public static void initCache() {syncCache = Caffeine.newBuilder().initialCapacity(100).maximumSize(1000).expireAfterWrite(30, TimeUnit.MINUTES).build();asyncCache = Caffeine.newBuilder().initialCapacity(100).maximumSize(1000).expireAfterWrite(30, TimeUnit.MINUTES).buildAsync();}public static void putSync(Object key, Object value) {syncCache.put(key, value);}public static Object getSync(Object key) {return syncCache.getIfPresent(key);}public static CompletableFuture<Object> getAsync(Object key, Executor executor) {return asyncCache.get(key, k -> CompletableFuture.supplyAsync(() -> fetchDataFromDataSource(k), executor));}public static CompletableFuture<Void> putAsync(Object key, Object value, Executor executor) {return asyncCache.put(key, CompletableFuture.completedFuture(value), executor);}public static void removeSync(Object key) {syncCache.invalidate(key);}public static void clearSync() {syncCache.invalidateAll();}private static Object fetchDataFromDataSource(Object key) {// 模拟从数据源获取数据的操作// 这里可以根据具体业务需求进行实现return null;}
}
SpringBoot 整合 Caffeine 缓存 (SpringCache模式)
原文链接:https://blog.csdn.net/Listening_Wind/article/details/110085228
添加依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId><version>2.6.2</version>
</dependency>缓存配置:
如果使用了多个cahce,比如redis、caffeine等,必须指定某一个CacheManage为@primary
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.assertj.core.util.Lists;
import org.springframework.cache.CacheManager;
import org.springframework.cache.caffeine.CaffeineCache;
import org.springframework.cache.support.SimpleCacheManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;import java.util.ArrayList;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.TimeUnit;/*** @Author: Wxy* @Date: 2020/11/7 16:56* @Description*/
@Configuration
@EnableCaching // 开启缓存,否则无效
public class CaffeineConfig {/*** 创建基于Caffeine的Cache Manager** @return*/@Bean@Primarypublic CacheManager caffeineCacheManager() {SimpleCacheManager cacheManager = new SimpleCacheManager();ArrayList<CaffeineCache> caches = Lists.newArrayList();Map<String, Object> map = getCacheType();for (String name : map.keySet()) {caches.add(new CaffeineCache(name, (Cache<Object, Object>) map.get(name)));}cacheManager.setCaches(caches);return cacheManager;}/*** 初始化自定义缓存策略** @return*/private static Map<String, Object> getCacheType() {Map<String, Object> map = new ConcurrentHashMap<>();map.put("name1", Caffeine.newBuilder().recordStats().expireAfterWrite(10, TimeUnit.SECONDS).maximumSize(100).build());map.put("name2", Caffeine.newBuilder().recordStats().expireAfterWrite(50, TimeUnit.SECONDS).maximumSize(50).build());return map;}
}驱逐策略
基于大小的回收策略有两种方式:基于缓存大小,基于权重,基于时间。
maximumSize : 根据缓存的计数进行驱逐 同一缓存策略 缓存的数据量,以访问先后顺序,以最大100为例,超出100驱逐最晚访问的数据缓存。
maximumWeight : 根据缓存的权重来进行驱逐(权重只是用于确定缓存大小,不会用于决定该缓存是否被驱逐)。
maximumWeight与maximumSize不可以同时使用。
Caffeine提供了三种定时驱逐策略:
expireAfterAccess(long, TimeUnit):在最后一次访问或者写入后开始计时,在指定的时间后过期。假如一直有请求访问该key,那么这个缓存将一直不会过期。
expireAfterWrite(long, TimeUnit): 在最后一次写入缓存后开始计时,在指定的时间后过期。
expireAfter(Expiry): 自定义策略,过期时间由Expiry实现独自计算。
缓存的删除策略使用的是惰性删除和定时删除。这两个删除策略的时间复杂度都是O(1)
开发使用
主要基于Spring缓存注解@Cacheable、@CacheEvict、@CachePut的方式使用
- @Cacheable :改注解修饰的方法,若不存在缓存,则执行方法并将结果写入缓存;若存在缓存,则不执行方法,直接返回缓存结果。
- @CachePut :执行方法,更新缓存;该注解下的方法始终会被执行。
- @CacheEvict :删除缓存
- @Caching 将多个缓存组合在一个方法上(该注解可以允许一个方法同时设置多个注解)
- @CacheConfig 在类级别设置一些缓存相关的共同配置(与其它缓存配合使用)
注意 :@Cacheable 默认使用标@primary 注释的CacheManage
/*** 先查缓存,如果查不到,执行方法体并将结果写入缓存,若查到,不执行方法体,直接返回缓存结果* @param id*/
@Cacheable(value = "name1", key = "#id", sync = true)
public void getUser(long id){//TODO 查找数据库
}/*** 更新缓存,每次都会执行方法体* @param user*/
@CachePut(value = "name1", key = "#user.id")
public void saveUser(User user){//todo 保存数据库
}/*** 删除* @param user*/
@CacheEvict(value = "name1",key = "#user.id")
public void delUser(User user){//todo 保存数据库
}
参考博客:https://www.cnblogs.com/wudiffs/p/11585757.html
(23条消息) SpringBoot 集成 Caffeine(咖啡因)最优秀的本地缓存_springboot caffeine_Listening_Wind的博客-CSDN博客![]() https://blog.csdn.net/Listening_Wind/article/details/110085228
https://blog.csdn.net/Listening_Wind/article/details/110085228
相关文章:
Caffeine 本地高速缓存工具类
目录 Caffeine工具类方式 SpringBoot 整合 Caffeine 缓存 (SpringCache模式) 驱逐策略 开发使用 Caffeine是一种高性能的缓存库,是基于Java 8的最佳(最优)缓存框架,性能各方面优于guava。 Caffeine工具…...
许可制度之序列号生成器)
加密解密软件VMProtect教程(八)许可制度之序列号生成器
VMProtect是新一代软件保护实用程序。VMProtect支持德尔菲、Borland C Builder、Visual C/C、Visual Basic(本机)、Virtual Pascal和XCode编译器。 同时,VMProtect有一个内置的反汇编程序,可以与Windows和Mac OS X可执行文件一起…...
单源最短路的建图
1.热浪 信息学奥赛一本通(C版)在线评测系统 (ssoier.cn)http://ybt.ssoier.cn:8088/problem_show.php?pid1379 很裸的单源最短路问题,n2500,可以用dijksta或者spfa都能过,下面展示spfa的做法 #include<bits/stdc.h> usi…...
MyBatis基本操作及SpringBoot单元测试
目录 一、什么是单元测试? 1.1 单元测试的好处 1.2 单元测试的实现步骤 1.2.1 生成单元测试类: 1.2.2 SpringBootTest注解 1.2.3 检验方法结果: 二、利用MyBatis实现查询操作 2.1单表查询 2.2 参数占位符 #{} 和 ${} 2.2.1 ${} 字符…...
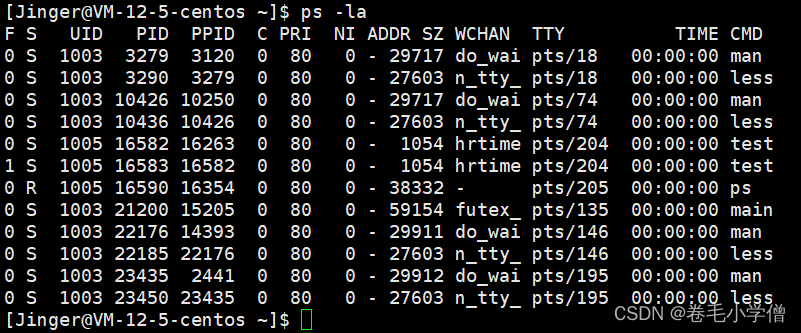
Linux之创建进程、查看进程、进程的状态以及进程的优先级
文章目录 前言一、初识fork1.演示2.介绍3.将子进程与父进程执行的任务分离4.多进程并行 二、进程的状态1.进程的状态都有哪些?2.查看进程的状态2.运行(R)3.阻塞4.僵尸进程(Z)1.僵尸状态概念2.为什么要有僵尸状态&#…...

k8s部署rabbitmq
docker pull rabbitmq:3.9.28-management 1.部署模板 apiVersion: v1 kind: Service metadata:name: rabbitmq spec:ports:- name: amqpport: 5672targetPort: 5672- name: managementport: 15672targetPort: 15672selector:app: rabbitmq---apiVersion: apps/v1 kind: Statef…...

关于QGroundControl的软件架构的理解
首先QGC是基于QT平台开发,个人理解软件架构即为项目前后端结构,以及前后端数据交互的逻辑。下面是对QGroundControl源码的一些个人理解,写这个博客只是为了记录下来,防止时间久了忘记,过程中看了一些大佬的博客来帮助理…...
Android 文本识别:MLKIT + PreviewView
随着移动设备的普及和摄像头的高像素化,利用相机进行文本识别成为了一种流行的方式。MLKit 是 Google 提供的一款机器学习工具包,其中包含了丰富的图像和语言处理功能,包括文本识别。PreviewView 是 Android Jetpack 的一部分,它提…...

刮泥机的分类有哪些及组成部分
刮泥机的分类有哪些及组成部分 刮泥机的分类: 刮泥机主要包括:周边传动刮泥机、中心传动浓缩刮泥机。 1、中心传动浓缩刮泥机:主要由溢流装置、大梁及拦杆、进口管、传动装置、电器箱、稳流筒、主轴、浮渣耙板、刮集装置、水下轴承、小刮刀、…...
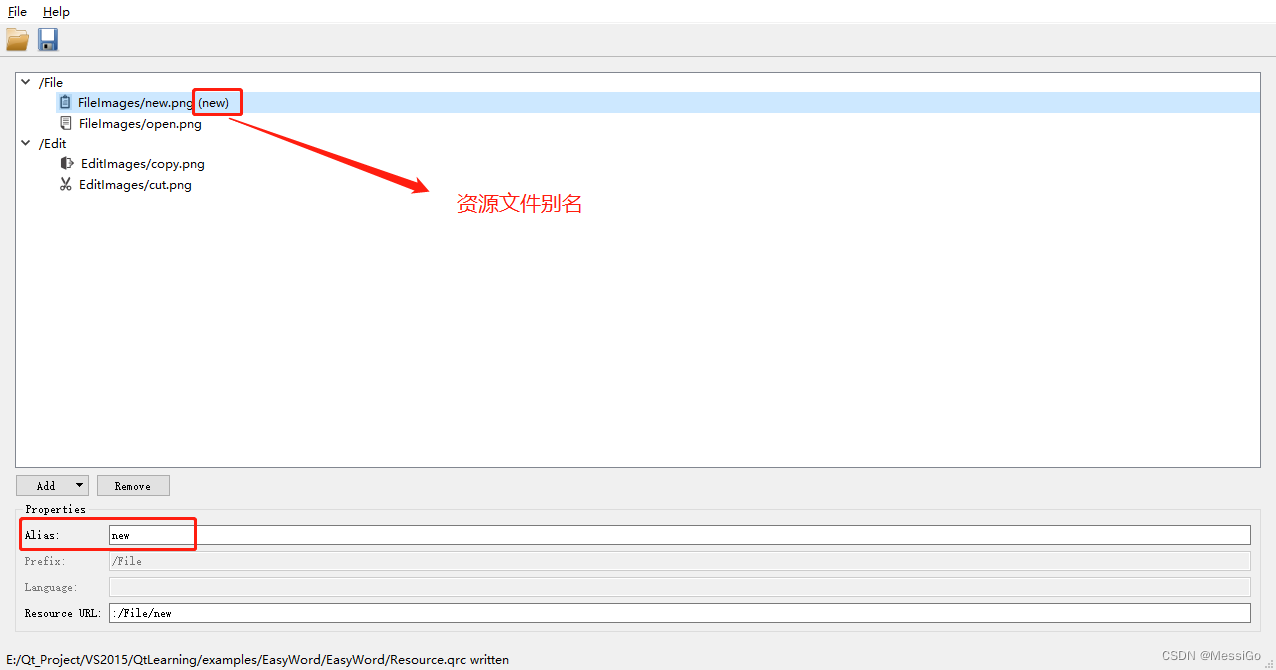
Qt编程基础 | 第六章-窗体 | 6.2、VS导入资源文件
一、VS导入资源文件 1.1、导入资源文件 步骤一: 将所有图片放到各自文件夹下,并将文件夹拷贝到资源文件(.qrc文件)的同级目录下,如下: 步骤二: 新建VS项目的时候,系统会自动建好一…...

NET框架程序设计-第4章类型基础
4.1 所有类型的基类型:System.Object CLR 要求每个类型最终都要继承自 System.Object 类型。 两种类型定义: 1)隐式继承 //隐式继承 Object class Employee{}2)显式继承 class Employee:System.Object{}System.Object 主要的公…...

Java设计模式-备忘录模式
简介 在软件开发中,设计模式是为了解决常见问题而提出的一种经过验证的解决方案。备忘录模式(Memento Pattern)是一种行为型设计模式,它允许我们在不破坏封装性的前提下,捕获和恢复对象的内部状态。 备忘录模式是一种…...

Zookeeper集群 + Kafka集群
Zookeeper 概述 Zookeeper 定义 Zookeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目。 Zookeeper 工作机制 Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数…...

“邮件营销新趋势,这个平台让你收获颇丰!
随着各媒体平台的迅速发展,2023年大家更专注于视频营销、网红营销、直播营销等营销方式。可以见得,数字媒介手段的发展,对于营销方式也产生了巨大的影响。但是,企业在拥抱新兴的营销方式的同时,也不要忽视传统的营销方…...

Python列表推导
列表推导式 列表推导式创建列表的方式更简洁。常见的用法为,对序列或可迭代对象中的每个元素应用某种操作,用生成的结果创建新的列表;或用满足特定条件的元素创建子序列。 例如,创建平方值的列表: squares [] for …...

git使用查看分支、创建分支、合并分支
一、查看分支 查看的git命令如下: git branch 列出本地已经存在的分支,并且当前分支会用*标记 git branch -r 查看远程版本库的分支列表 git branch -a 查看所有分支列表(包括本地和远程,remotes/开头的表示远程分支)…...
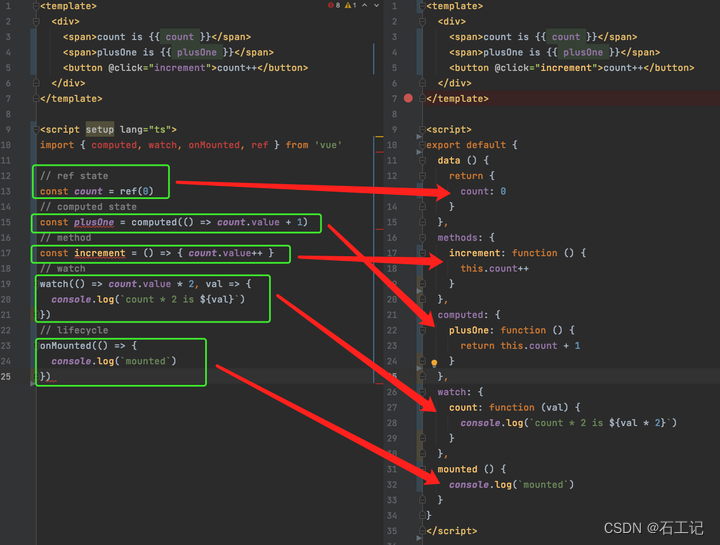
vue3.0与vue2.0
一、生命周期的变化 1.vue2.响应式架构 2.vue3.0 响应式架构图 Vue3.0响应式框架在设计上,将视图渲染和数据响应式完全分离开来。将响应式核心方法effect从原有的Watcher中抽离。这样,当我们只需要监听数据响应某种逻辑回调(例如监听某个text属性的变化…...

HTML 中的常用标签用法
HTML是构建Web页面的基础语言,其中包含许多不同类型的标签。这些标签由尖括号包围,以指示浏览器如何呈现文本。下面是HTML中的一些常用标签以及它们的使用方法: 标题标签(h1-h6) 标题标签用于标识页面内容的标题&…...
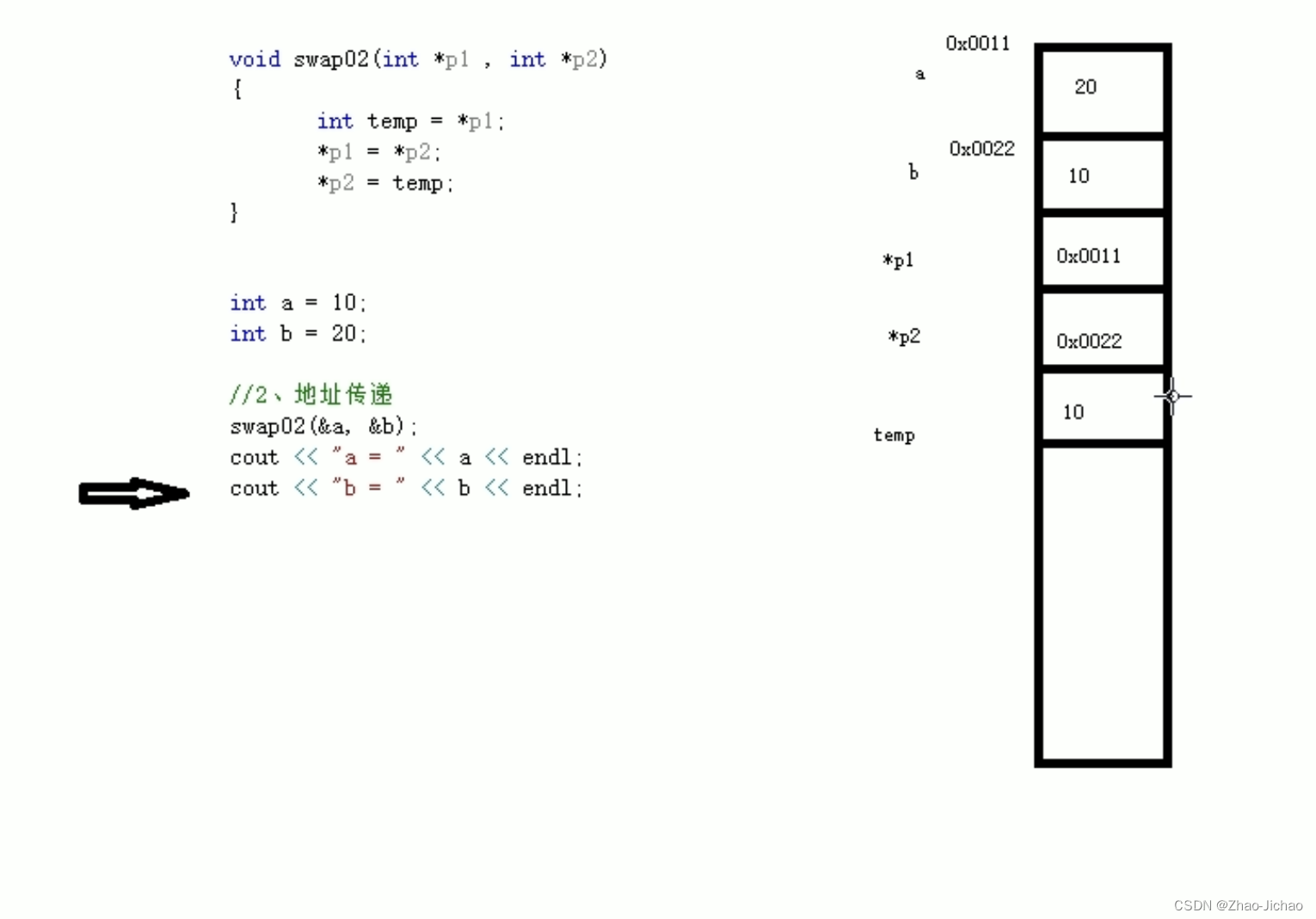
【C++】指针 - 定义和使用,所占内存空间,空指针,野指针,const 修饰指针,指针和数组,指针和函数
文章目录 1. 定义和使用2. 所占内存空间3. 空指针4. 野指针5. const 修饰指针6. 指针和数组7. 指针和函数 1. 定义和使用 数据类型 * 变量名; 指针的作用是,可以通过指针间接访问内存。 内存编号是从 0 开始记录的,一般用十六进制数字表示。可以利用指…...

新规之下产业园区如何合理收费水电费用
一、政策背景 2018年3月30日,国家发改委发布《国家发展改革委关于降低一般工商业电价有关事项的通知》。明确提出进一步规范和降低电网环节收费,一是提高两部制电价的灵活性;二是全面清理规范电网企业在输配电价之外的收费项目,重…...

如何5分钟搞定全网资源下载:res-downloader智能嗅探实战指南
如何5分钟搞定全网资源下载:res-downloader智能嗅探实战指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 还在…...

SSH协议深度解析:从加密隧道到生产级安全加固
1. 这不是“连服务器”的工具,而是现代数字信任的底层地基很多人第一次听说SSH,是在运维同事敲下ssh user192.168.1.100那刻——屏幕一闪,就进了另一台机器的命令行。于是顺理成章把它理解成“远程登录工具”。但这种认知,就像把高…...

飞书文档批量导出技术解决方案:企业知识库迁移的工程化实践
飞书文档批量导出技术解决方案:企业知识库迁移的工程化实践 【免费下载链接】feishu-doc-export 飞书文档导出服务 项目地址: https://gitcode.com/gh_mirrors/fe/feishu-doc-export 在数字化转型浪潮中,企业知识库的管理和迁移成为技术团队面临的…...

iOS砸壳与反编译实战:从FairPlay解密到Swift逆向分析
1. 砸壳不是“破解”,而是理解iOS应用分发机制的第一道门很多人第一次听说“砸壳”,脑子里立刻浮现出“绕过App Store审核”“盗取商业逻辑”“窃取用户数据”这类词。这其实是个根深蒂固的误解。在我过去八年做iOS底层工具链开发、参与多个企业级MDM方案…...

2026年降AI工具处理速度横评:五款主流工具一万字论文处理时长完整数据报告
2026年降AI工具处理速度横评:五款主流工具一万字论文处理时长完整数据报告 拿同一篇论文,用三款工具分别处理,记录了完整检测数据。 结论先说:嘎嘎降AI(www.aigcleaner.com)效果最稳,价格也最…...

3.RAG
一、RAG初识: RAG(Retrieval-Augmented Generation,检索增强生成)是一种将 信息检索与文本生成 相结合的技术框架。它通过以下流程解决大模型(LLM)的“知识盲区”问题: 用户问题->从知识库检索相关文档->将文档作为上下文输入LLM->生成精准答…...
)
Windows 11账户密码管理避坑指南:从默认42天到永久有效,完整配置流程(含ChatGPT答案验证)
Windows 11密码策略深度解析:从42天默认值到永久有效的终极配置手册 每次系统提示"您的密码即将过期"时,那种被打断工作的烦躁感想必大家都不陌生。Windows 11默认的42天密码有效期策略,实际上源自微软早期安全框架的设计哲学——通…...

深度学习解码星际湍流:从光谱图估计MHD模式能量分数
1. 项目概述与核心价值在星际介质(ISM)的研究中,磁流体动力学(MHD)湍流扮演着能量传输、物质混合和结构形成的“发动机”角色。它并非一团混沌,而是可以分解为三种具有不同物理特性的基本模式:阿…...

吉利银河星耀7 MAX上市:零百加速5.4秒 指导价9.88万起
雷递网 乐天 5月24日吉利银河旗下全新中级豪华电混轿车——吉利银河星耀7 MAX正式上市。新车全系标配四驱,有220km四驱星耀版、220km四驱探索版、220km四驱领航版、220km四驱远航版4个版本,同时,官方还提供四驱远航版两驱反选权益,…...
)
手把手教你用Powergui的FFT Tool分析Simulink示波器数据(从记录到出图)
从仿真到频谱:Powergui FFT工具在Simulink中的完整应用指南当你在Simulink中完成电力系统或信号处理的仿真后,如何从时域波形中提取有价值的频域信息?许多工程师在第一次接触FFT分析时,往往会被各种参数设置和数据格式问题困扰。本…...