基于BP神经网络对MNIST数据集检测识别(numpy版本)
基于BP神经网络对MNIST数据集检测识别
- 1.作者介绍
- 2.BP神经网络介绍
- 2.1 BP神经网络
- 3.BP神经网络对MNIST数据集检测实验
- 3.1 读取数据集
- 3.2 前向传播
- 3.3 损失函数
- 3.4 构建神经网络
- 3.5 训练
- 3.6 模型推理
- 4.完整代码
1.作者介绍
王凯,男,西安工程大学电子信息学院,2022级研究生
研究方向:机器视觉与人工智能
电子邮件:1794240761@qq.com
张思怡,女,西安工程大学电子信息学院,2022级研究生,张宏伟人工智能课题组
研究方向:机器视觉与人工智能
电子邮件:981664791@qq.com
2.BP神经网络介绍
2.1 BP神经网络
搭建一个两层(两个权重矩阵,一个隐藏层)的神经网络,其中输入节点和输出节点的个数是确定的,分别为 784 和 10。而隐藏层节点的个数还未确定,并没有明确要求隐藏层的节点个数,所以在这里取50个。现在神经网络的结构已经确定了,再看一下里面是怎么样的,这里画出了对一个数据的运算过程:
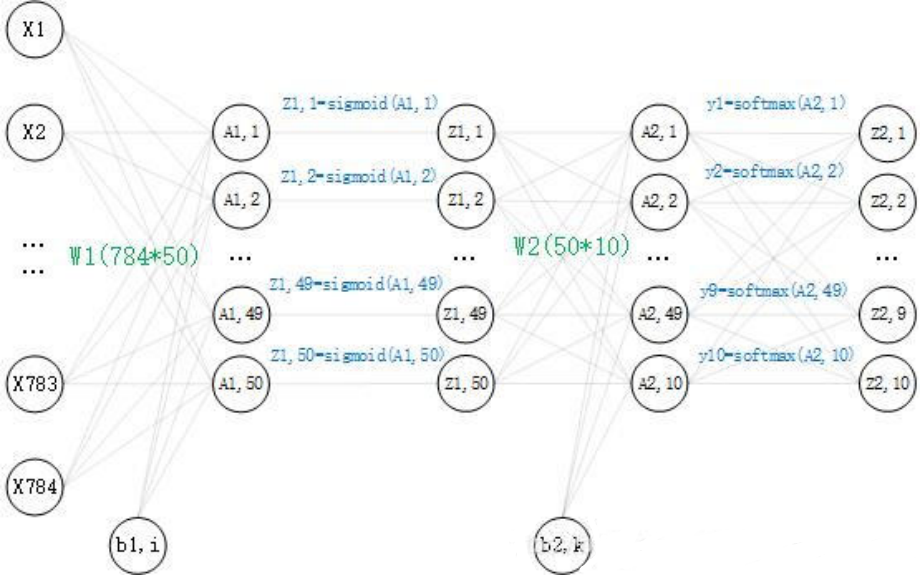
数学公式:

3.BP神经网络对MNIST数据集检测实验
3.1 读取数据集
安装numpy :pip install numpy
安装matplotlib pip install matplotlib
mnist是一个包含各种手写数字图片的数据集:其中有60000个训练数据和10000个测试时局,即60000个 train_img 和与之对应的 train_label,10000个 test_img 和 与之对应的test_label。

其中的 train_img 和 test_img 就是这种图片的形式,train_img 是为了训练神经网络算法的训练数据,test_img 是为了测试神经网络算法的测试数据,每一张图片为2828,将图片转换为2828=784个像素点,每个像素点的值为0到255,像素点值的大小代表灰度,从而构成一个1784的矩阵,作为神经网络的输入,而神经网络的输出形式为110的矩阵,个:eg:[0.01,0.01,0.01,0.04,0.8,0.01,0.1,0.01,0.01,0.01],矩阵里的数字代表神经网络预测值的概率,比如0.8代表第五个数的预测值概率。
其中 train_label 和 test_label 是 对应训练数据和测试数据的标签,可以理解为一个1*10的矩阵,用one-hot-vectors(只有正确解表示为1)表示,one_hot_label为True的情况下,标签作为one-hot数组返回,one-hot数组 例:[0,0,0,0,1,0,0,0,0,0],即矩阵里的数字1代表第五个数为True,也就是这个标签代表数字5。
数据集的读取:
load_mnist(normalize=True, flatten=True, one_hot_label=False):中,
normalize : 是否将图像的像素值正规化为0.0~1.0(将像素值正规化有利于提高精度)。flatten : 是否将图像展开为一维数组。 one_hot_label:是否采用one-hot表示。
完整代码及数据集下载:https://gitee.com/wang-kai-ya/bp.git
3.2 前向传播
前向传播时,我们可以构造一个函数,输入数据,输出预测。
def predict(self, x):w1, w2 = self.dict['w1'], self.dict['w2']b1, b2 = self.dict['b1'], self.dict['b2']a1 = np.dot(x, w1) + b1z1 = sigmoid(a1)a2 = np.dot(z1, w2) + b2y = softmax(a2)
3.3 损失函数
求出神经网络对一组数据的预测值,是一个1*10的矩阵。
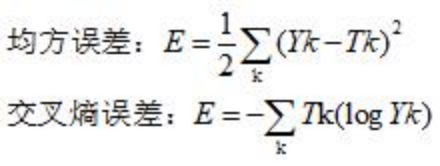
其中,Yk表示的是第k个节点的预测值,Tk表示标签中第k个节点的one-hot值,举前面的eg:(手写数字5的图片预测值和5的标签)
Yk=[0.01,0.01,0.01,0.04,0.8,0.01,0.1,0.01,0.01,0.01]
Tk=[0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
值得一提的是,在交叉熵误差函数中,Tk的值只有一个1,其余为0,所以对于这个数据的交叉熵误差就为 E = -1(log0.8)。
在这里选用交叉熵误差作为损失函数,代码实现如下:
def loss(self, y, t):t = t.argmax(axis=1)num = y.shape[0]s = y[np.arange(num), t]return -np.sum(np.log(s)) / num
3.4 构建神经网络
前面我们定义了预测值predict, 损失函数loss, 识别精度accuracy, 梯度grad,下面构建一个神经网络的类,把这些方法添加到神经网络的类中:
for i in range(epoch):batch_mask = np.random.choice(train_size, batch_size) # 从0到60000 随机选100个数x_batch = x_train[batch_mask]y_batch = net.predict(x_batch)t_batch = t_train[batch_mask]grad = net.gradient(x_batch, t_batch)for key in ('w1', 'b1', 'w2', 'b2'):net.dict[key] -= lr * grad[key]loss = net.loss(y_batch, t_batch)train_loss_list.append(loss)# 每批数据记录一次精度和当前的损失值if i % iter_per_epoch == 0:train_acc = net.accuracy(x_train, t_train)test_acc = net.accuracy(x_test, t_test)train_acc_list.append(train_acc)test_acc_list.append(test_acc)print('第' + str(i/600) + '次迭代''train_acc, test_acc, loss :| ' + str(train_acc) + ", " + str(test_acc) + ',' + str(loss))
3.5 训练
import numpy as np
import matplotlib.pyplot as plt
from TwoLayerNet import TwoLayerNet
from mnist import load_mnist(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
net = TwoLayerNet(input_size=784, hidden_size=50, output_size=10, weight_init_std=0.01)epoch = 20400
batch_size = 100
lr = 0.1train_size = x_train.shape[0] # 60000
iter_per_epoch = max(train_size / batch_size, 1) # 600train_loss_list = []
train_acc_list = []
test_acc_list = []
保存权重:
np.save('w1.npy', net.dict['w1'])
np.save('b1.npy', net.dict['b1'])
np.save('w2.npy', net.dict['w2'])
np.save('b2.npy', net.dict['b2'])
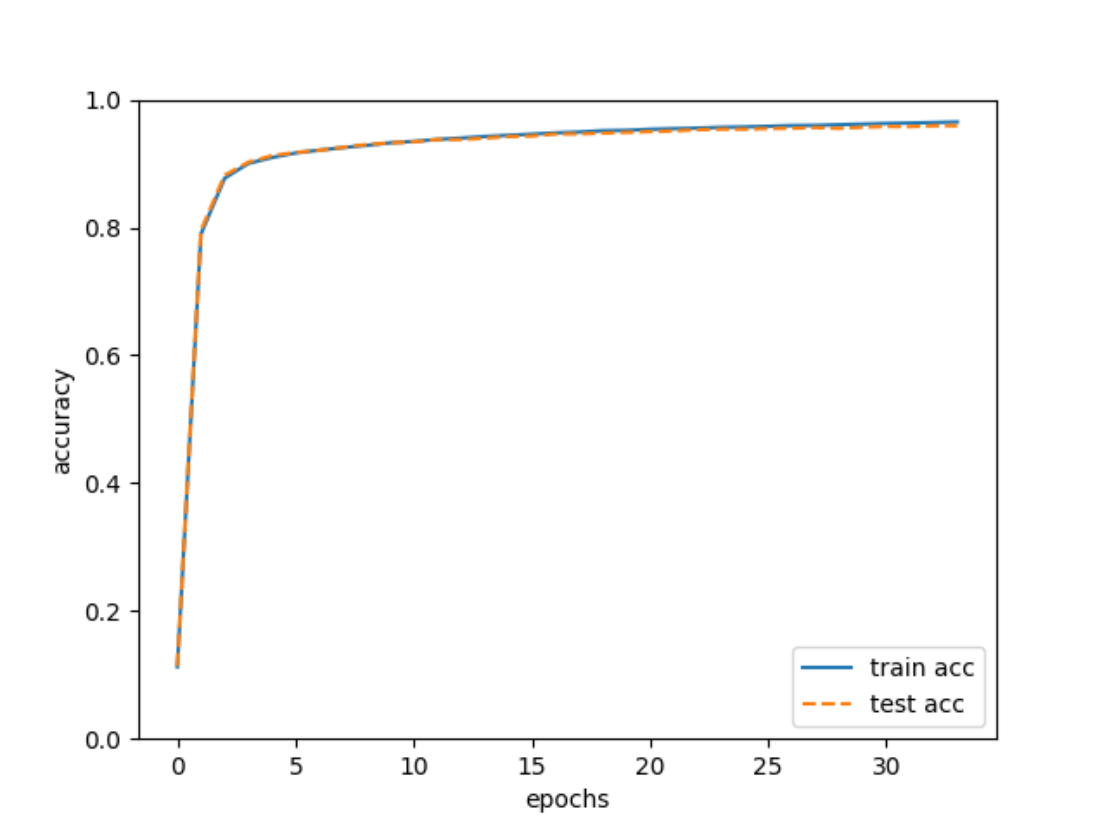
结果可视化:
3.6 模型推理
import numpy as np
from mnist import load_mnist
from functions import sigmoid, softmax
import cv2
######################################数据的预处理
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
batch_mask = np.random.choice(100,1) # 从0到60000 随机选100个数
#print(batch_mask)
x_batch = x_train[batch_mask]#####################################转成图片
arr = x_batch.reshape(28,28)
cv2.imshow('wk',arr)
key = cv2.waitKey(10000)
#np.savetxt('batch_mask.txt',arr)
#print(x_batch)
#train_size = x_batch.shape[0]
#print(train_size)
########################################进入模型预测
w1 = np.load('w1.npy')
b1 = np.load('b1.npy')
w2 = np.load('w2.npy')
b2 = np.load('b2.npy')a1 = np.dot(x_batch,w1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1,w2) + b2
y = softmax(a2)
p = np.argmax(y, axis=1)print(p)
运行python reasoning.py
可以看到模型拥有较高的准确率。
4.完整代码
训练
import numpy as np
import matplotlib.pyplot as plt
from TwoLayerNet import TwoLayerNet
from mnist import load_mnist(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
net = TwoLayerNet(input_size=784, hidden_size=50, output_size=10, weight_init_std=0.01)epoch = 20400
batch_size = 100
lr = 0.1train_size = x_train.shape[0] # 60000
iter_per_epoch = max(train_size / batch_size, 1) # 600train_loss_list = []
train_acc_list = []
test_acc_list = []for i in range(epoch):batch_mask = np.random.choice(train_size, batch_size) # 从0到60000 随机选100个数x_batch = x_train[batch_mask]y_batch = net.predict(x_batch)t_batch = t_train[batch_mask]grad = net.gradient(x_batch, t_batch)for key in ('w1', 'b1', 'w2', 'b2'):net.dict[key] -= lr * grad[key]loss = net.loss(y_batch, t_batch)train_loss_list.append(loss)# 每批数据记录一次精度和当前的损失值if i % iter_per_epoch == 0:train_acc = net.accuracy(x_train, t_train)test_acc = net.accuracy(x_test, t_test)train_acc_list.append(train_acc)test_acc_list.append(test_acc)print('第' + str(i/600) + '次迭代''train_acc, test_acc, loss :| ' + str(train_acc) + ", " + str(test_acc) + ',' + str(loss))np.save('w1.npy', net.dict['w1'])
np.save('b1.npy', net.dict['b1'])
np.save('w2.npy', net.dict['w2'])
np.save('b2.npy', net.dict['b2'])markers = {'train': 'o', 'test': 's'}
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, label='train acc')
plt.plot(x, test_acc_list, label='test acc', linestyle='--')
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
测试
import numpy as np
from mnist import load_mnist
from functions import sigmoid, softmax
import cv2
######################################数据的预处理
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
batch_mask = np.random.choice(100,1) # 从0到60000 随机选100个数
#print(batch_mask)
x_batch = x_train[batch_mask]#####################################转成图片
arr = x_batch.reshape(28,28)
cv2.imshow('wk',arr)
key = cv2.waitKey(10000)
#np.savetxt('batch_mask.txt',arr)
#print(x_batch)
#train_size = x_batch.shape[0]
#print(train_size)
########################################进入模型预测
w1 = np.load('w1.npy')
b1 = np.load('b1.npy')
w2 = np.load('w2.npy')
b2 = np.load('b2.npy')a1 = np.dot(x_batch,w1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1,w2) + b2
y = softmax(a2)
p = np.argmax(y, axis=1)print(p)
相关文章:
基于BP神经网络对MNIST数据集检测识别(numpy版本)
基于BP神经网络对MNIST数据集检测识别 1.作者介绍2.BP神经网络介绍2.1 BP神经网络 3.BP神经网络对MNIST数据集检测实验3.1 读取数据集3.2 前向传播3.3 损失函数3.4 构建神经网络3.5 训练3.6 模型推理 4.完整代码 1.作者…...
HTML5-创建HTML文档
HTML5中的一个主要变化是:将元素的语义与元素对其内容呈现结果的影响分开。从原理上讲这合乎情理。HTML元素负责文档内容的结构和含义,内容的呈现则由应用于元素上的CSS样式控制。下面介绍最基础的HTML元素:文档元素和元数据元素。 一、构建…...

Vue中Axios的封装和API接口的管理
一、axios的封装 在vue项目中,和后台交互获取数据这块,我们通常使用的是axios库,它是基于promise的http库,可运行在浏览器端和node.js中。他有很多优秀的特性,例如拦截请求和响应、取消请求、转换json、客户端防御XSR…...

MLIR面试题
1、请简要解释MLIR的概念和用途,并说明MLIR在编译器领域中的重要性。 MLIR(Multi-Level Intermediate Representation)是一种多级中间表示语言,提供灵活、可扩展和可优化的编译器基础设施。MLIR的主要目标是为不同的编程语言、领域专用语言(DSL)和编译器…...
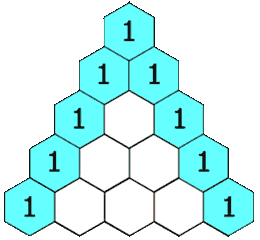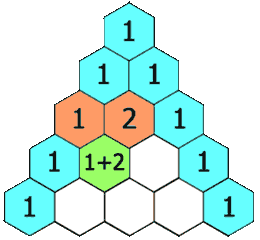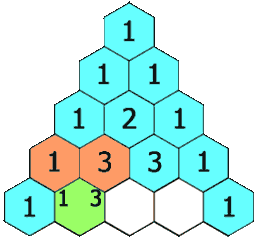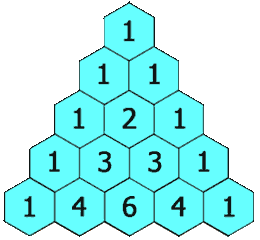
***杨辉三角_yyds_LeetCode_python***
1.题目描述: 给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。 在「杨辉三角」中,每个数是它左上方和右上方的数的和。 示例 1: 输入: numRows 5 输出: [[1],[1,1],[1,2,1],[1,3,3,1],[1,4,6,4,1]] 示例 2: 输入: numRows …...
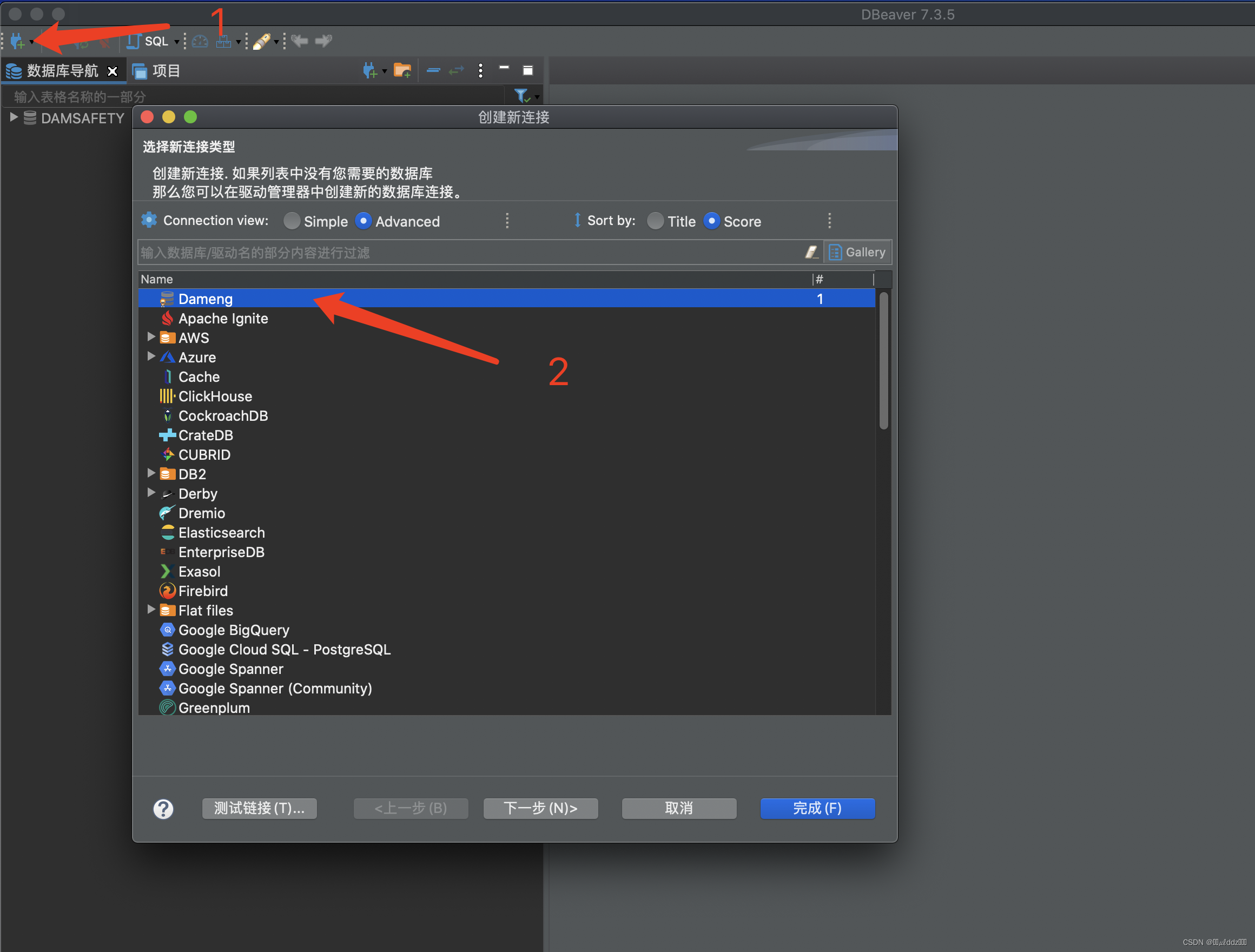
Mac使用DBeaver连接达梦数据库
Mac使用DBeaver连接达梦数据库 下载达梦驱动包 达梦数据库 在下载页面随便选择一个系统并下载下来。 下载下来的是zip的压缩包解压出来就是一个ISO文件,然后我们打开ISO文件进入目录:/dameng/source/drivers/jdbc 进入目录后找到这几个驱动包&#x…...

spring.expression 随笔0 概述
0. 我只是个普通码农,不值得挽留 Spring SpEL表达式的使用 常见的应用场景:分布式锁的切面借助SpEL来构建key 比较另类的的应用场景:动态校验 个人感觉可以用作控制程序的走向,除此之外,spring的一些模块的自动配置类,也会在Cond…...

从Cookie到Session: Servlet API中的会话管理详解
文章目录 一. Cookie与Session1. Cookie与Session2. Servlet会话管理操作 二. 登录逻辑的实现 一. Cookie与Session 1. Cookie与Session 首先, 在学习过 HTTP 协议的基础上, 我们需要知道 Cookie 是 HTTP 请求报头中的一个关键字段, 本质上是浏览器在本地存储数据的一种机制,…...
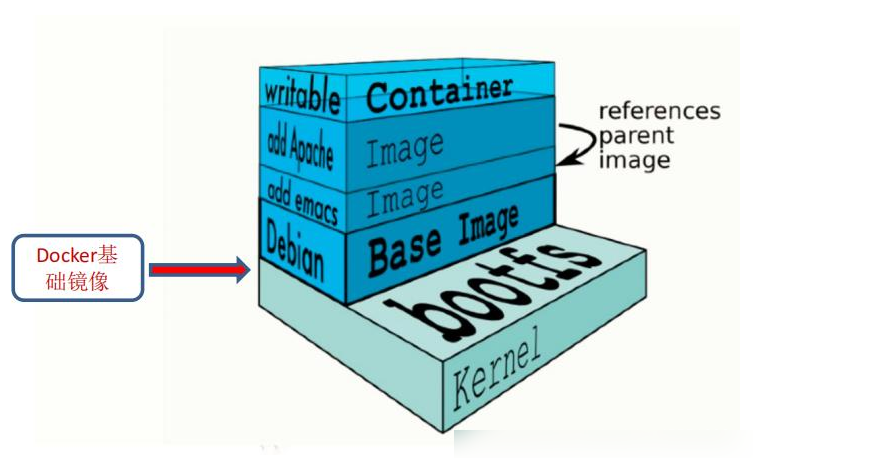
docker数据管理与网络通信
一、管理docker容器中数据 管理Docker 容器中数据主要有两种方式:数据卷(Data Volumes)和数据卷容器( DataVolumes Containers) 。 1、 数据卷 数据卷是一个供容器使用的特殊目录,位于容器中。可将宿主机的目录挂载到数据卷上,对数据卷的修改操作立刻…...
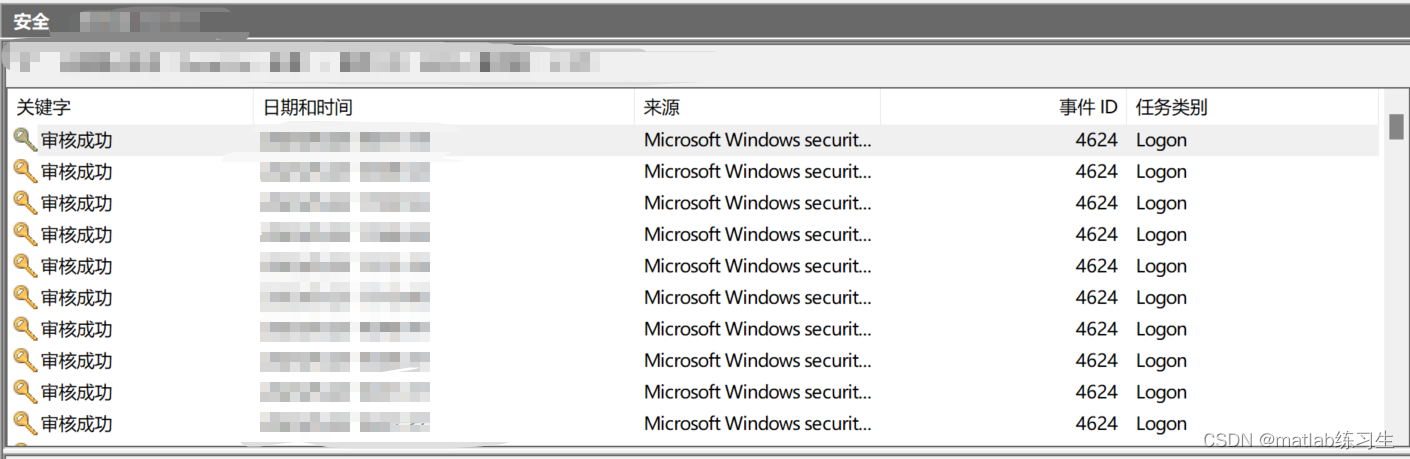
怎么查询电脑的登录记录及密码更改情况?
源头是办公室公用的电脑莫名其妙打不开了,问别人也都不知道密码是多少 因为本来就没设密码啊!(躺倒) 甚至已经想好了如果是50万想攻破电脑,被po抓住要怎么花这笔钱了 是我想太多 当然最后也没解决,莫名…...
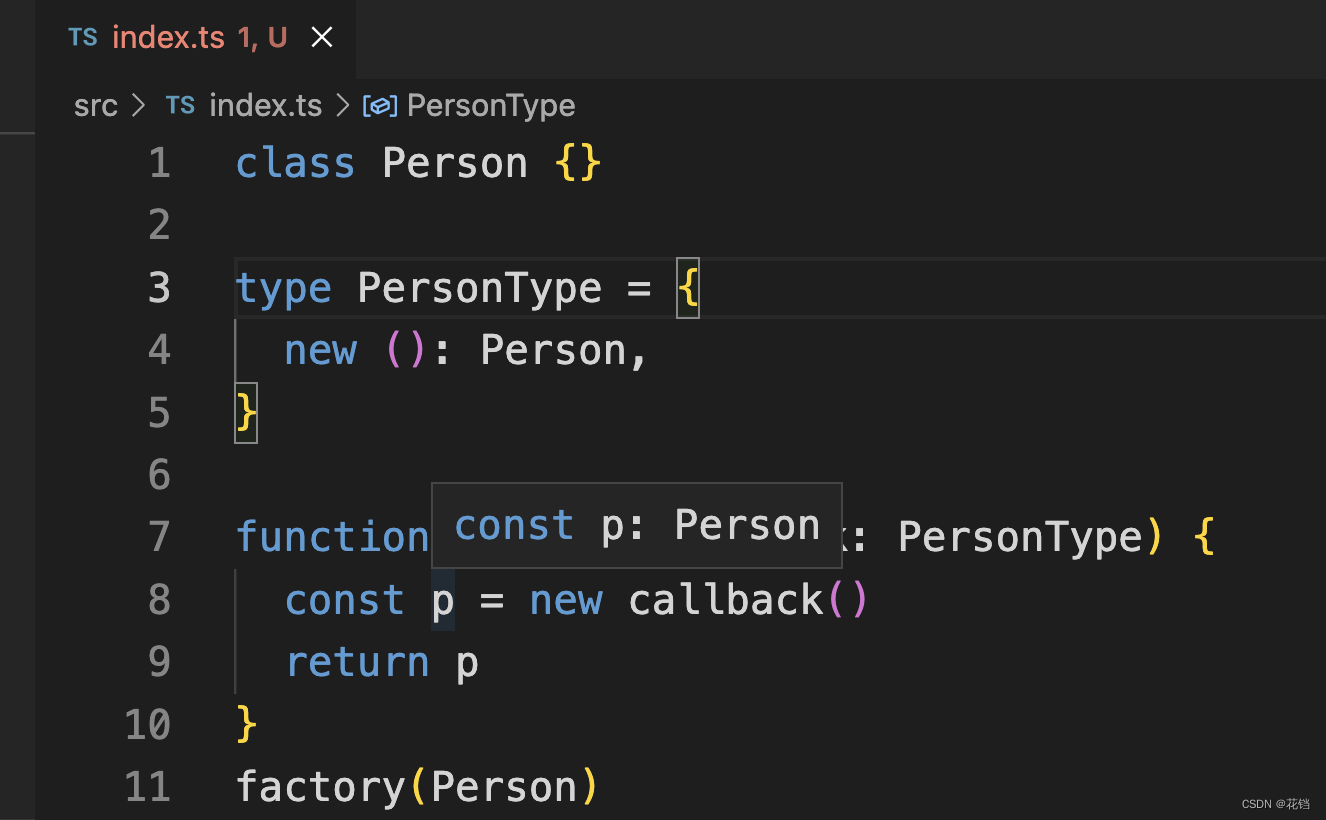
《三》TypeScript 中函数的类型
TypeScript 允许指定函数的参数和返回值的类型。 函数声明的类型定义:function 函数名(形参: 形参类型, 形参: 形参类型, ...): 返回值类型 {} function sum(x: number, y: number): number {return x y } sum(1, 2) // 正确 sum(1, 2, 3) // 错误。输入多余的或者…...
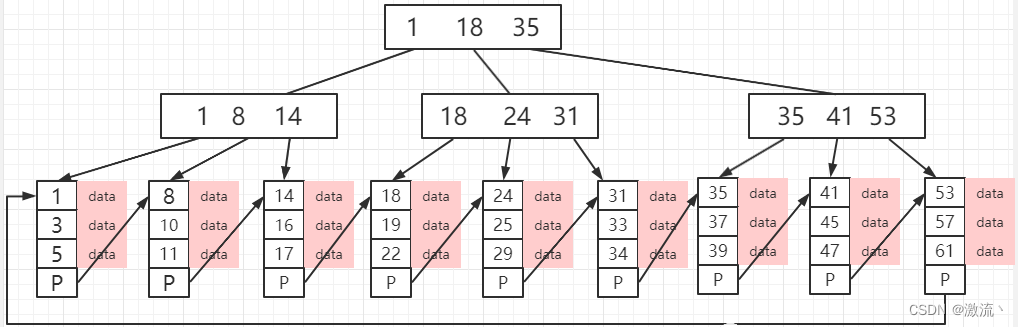
深入学习 Mysql 引擎 InnoDB、MyISAM
tip:作为程序员一定学习编程之道,一定要对代码的编写有追求,不能实现就完事了。我们应该让自己写的代码更加优雅,即使这会费时费力。 💕💕 推荐:体系化学习Java(Java面试专题&#…...
(C++ Java JavaScript Python))
【华为OD统一考试B卷 | 100分】阿里巴巴找黄金宝箱(V)(C++ Java JavaScript Python)
题目描述 一贫如洗的樵夫阿里巴巴在去砍柴的路上,无意中发现了强盗集团的藏宝地,藏宝地有编号从0~N的箱子,每个箱子上面贴有一个数字。 阿里巴巴念出一个咒语数字k(k<N),找出连续k个宝箱数字和的最大值,并输出该最大值。 输入描述 第一行输入一个数字字串,数字之间…...

六步快速搭建个人网站
目录 第一步、选择搭建平台WordPress 第二步、选域名 1)域名在哪买? 2)域名怎么选? 3)以阿里云为例,讲解怎么买域名 第三步、选择服务器 第四步、申请主机、安装WordPress 第五步、选择WordPress模…...

TypeScript 中的 type 关键字有什么用?
创建类型别名 在 TypeScript 中,type 关键字用于创建类型别名(Type Alias)。类型别名可以给一个类型起一个新的名字,使代码更具可读性和可维护性。 类型别名可以用于定义各种类型,包括基本类型、复合类型和自定义类型…...
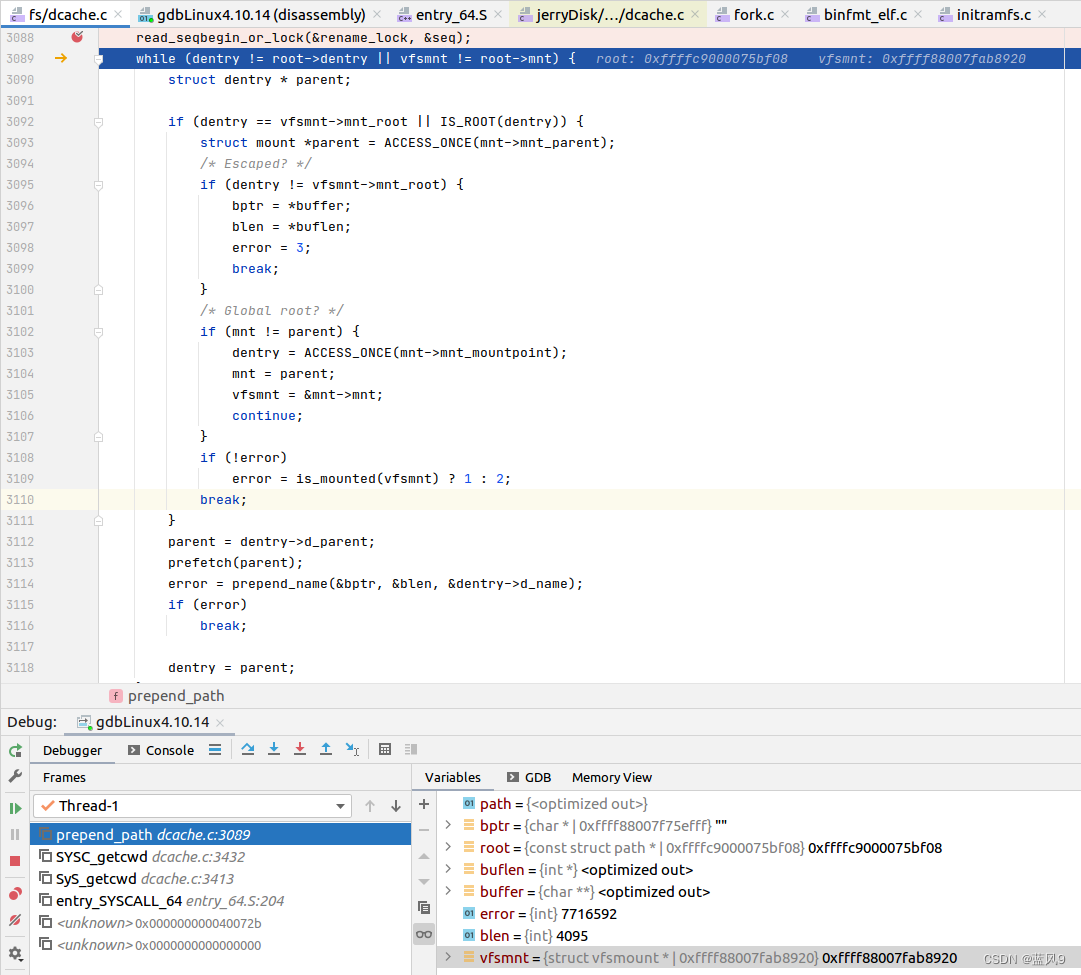
27 getcwd 的调试
前言 同样是一个 很常用的 glibc 库函数 不管是 用户业务代码 还是 很多类库的代码, 基本上都会用到 获取当前路径 不过 我们这里是从 具体的实现 来看一下 测试用例 就是简单的使用了一下 getcwd rootubuntu:~/Desktop/linux/HelloWorld# cat Test04Getcwd.c #inc…...

使用IDEA使用Git:Git使用指北——实际操作篇
Git使用指北——实际操作 🤖:使用IDEA Git插件实际工作流程 💡 本文从实际使用的角度出发,以IDEA Git插件为基座讲述了如果使用IDEA的Git插件来解决实际开发中的协作开发问题。本文从 远程仓库中拉取项目,在本地分支进行开发&…...
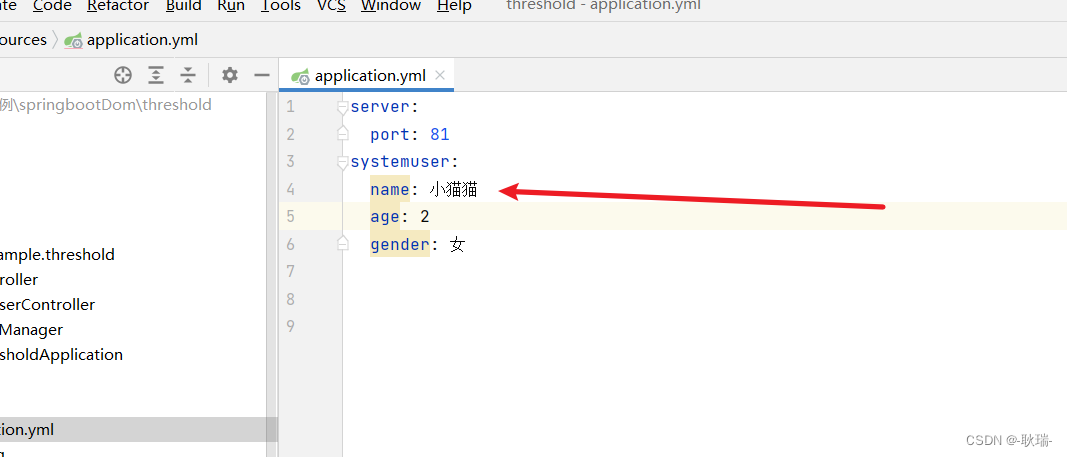
java boot将一组yml配置信息装配在一个对象中
其实将一组yml数据封进一个对象中才是以后的主流开发方式 我们创建一个springboot项目 找到项目中的启动类所在目录 在同目录下创建一个类 名字你们可以随便取 我这里直接叫 dataManager 然后 在yml中定义这样一组数据信息 然后 我们在类中定义三个和这个配置信息相同的字段…...

【裸机开发】链接脚本(.lds文件)的基本语法
目录 一、什么是链接脚本? 二、链接脚本的基本语法格式 1、常用命令 2、内置变量 三、链接脚本的简单案例 一、什么是链接脚本? 一段程序的编译需要经历四个阶段(预处理—编译—汇编—链接),而链接脚本管理的就是…...

Java 进阶 -- 集合(三)
4、实现 实现是用于存储集合的数据对象,它实现了接口部分中描述的接口。本课描述了以下类型的实现: 通用实现是最常用的实现,是为日常使用而设计的。它们在标题为“通用实现”的表格中进行了总结。特殊目的实现是为在特殊情况下使用而设计的࿰…...

Agent设计模式全景图——从ReAct到Multi-Agent的完整知识体系
Agent概念在2023年就已出现,2024年是框架快速迭代的一年。到了2026年,Agent设计模式逐渐成熟,成为工程实践的关键。 GitHub上关于Agent的开源项目突破10万个,LangChain、LangGraph、AutoGen、CrewAI……框架层出不穷。但翻遍这些文…...

别再为Modbus RTU超时头疼了!STM32CubeMX+FreeModbus从站移植,搞定串口与定时器配置的黄金法则
STM32CubeMXFreeModbus从站移植实战:破解RTU超时难题的工程化思维 当你在深夜调试Modbus RTU从站设备,串口调试助手反复弹出"Timeout"错误提示时,那种挫败感每个嵌入式工程师都深有体会。超时问题就像幽灵般难以捉摸——代码编译通…...

IL-8 Inhibitor ;Ac-RRWWCR-NH₂
一、基础信息多肽名称:IL-8 Inhibitor(白介素 8 抑制剂肽) 修饰:N 端乙酰化 Ac-,C 端酰胺化 -NH₂ 三字母序列:Ac-Arg-Arg-Trp-Trp-Cys-Arg-NH₂ 单字母序列:Ac-RRWWCR-NH₂ 氨基酸数量…...

5分钟掌握HunterPie:解决《怪物猎人:世界》战斗信息盲区的终极指南
5分钟掌握HunterPie:解决《怪物猎人:世界》战斗信息盲区的终极指南 【免费下载链接】HunterPie-legacy A complete, modern and clean overlay with Discord Rich Presence integration for Monster Hunter: World. 项目地址: https://gitcode.com/gh_…...

从入门到精通:摄影测量学核心概念与应用全景解析
1. 摄影测量学入门指南:从零开始理解核心概念 第一次接触摄影测量学时,我被那些专业术语搞得晕头转向。直到有一次在公园用手机拍摄了一组树木照片,尝试用免费软件生成3D模型后,才真正理解了这门技术的魅力。摄影测量学本质上就是…...
)
树莓派4B + MPU9250:从零到一搭建你的第一个姿态传感器(附完整代码与避坑指南)
树莓派4B与MPU9250实战:从硬件连接到姿态解算的全流程指南 1. 准备工作与环境搭建 1.1 硬件清单与连接指南 在开始之前,我们需要准备以下硬件组件: 树莓派4B(建议4GB内存版本)MPU9250九轴传感器模块杜邦线(…...

Bebas Neue字体技术深度解析:开源无衬线显示字体的现代排版解决方案
Bebas Neue字体技术深度解析:开源无衬线显示字体的现代排版解决方案 【免费下载链接】Bebas-Neue Bebas Neue font 项目地址: https://gitcode.com/gh_mirrors/be/Bebas-Neue Bebas Neue作为一款采用SIL Open Font License 1.1许可证的开源显示字体ÿ…...

编译原理实战:手把手教你化简DFA
1. 从零开始理解DFA化简 第一次接触DFA化简这个概念时,我盯着课本上那些复杂的箭头和状态图发了好一会儿呆。作为一个编译原理的初学者,最让我困惑的是:为什么已经有了能工作的DFA,还要费劲去化简它?直到在实际项目中遇…...

反射式红外光电管ITR9909:从基础测试到智能车竞赛应用实战
1. ITR9909反射式红外光电管基础入门 第一次拿到ITR9909这个小家伙时,我差点被它朴素的外表骗了。这个直径不到5mm的黑色塑料封装器件,看起来就像普通的三极管,但它的能力可不容小觑。作为智能车竞赛的老玩家,我发现它在信标检测…...

Java开发者收藏必看:转型AI领域,解锁高薪职业新机遇!
本文探讨了Java开发者向AI领域转型的可行性、优势及所需知识。文章指出,Java开发者具备转型AI的独特优势,AI领域岗位需求旺盛且薪资高于Java开发。转型者需补充数学、Python等知识,并通过实践项目积累经验。掌握AI技术能显著提升个人竞争力&a…...