【C++】 STL(上)STL简述、STL容器
文章目录
- 简述
- STL容器
- list链表
- vector向量
- deque双端队列
- map映射表
- set集合
- hash_map哈希表
简述
STL是“Standard Template Library”的缩写,中文译为“标准模板库”。STL是C++标准库的一部分,位与各个C++的头文件中,即他并非以二进制代码的形式提供,而是以源码的形式提供。STL体现了泛型编程的思想,大部分基本算法被抽象,被泛化,独立于与之对应的数据结构,用于以相同或近似的方式处理各种不同情形,为我们提供了一个可扩展的应用框架,高度体现了程序的可复用性。STL的一个重要特点是数据结构和算法的分离。
STL的头文件都不加扩展名,且打开std命名空间。
包含了六大组件:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CmEqUrg0-1686553741440)(C++.assets/image-20230530214549154.png)]](https://img-blog.csdnimg.cn/9dab92ad6b6449b0b5cf5d9dbef732d1.png)
STL容器
主要分为两大类:
序列性容器:序列容器保持插入元素的原始顺序。允许指定在容器中插入元素的位置。每个元素都有固定位置,取决于插入时机和地点,和元素值无关,如:链表(list),向量(vector),双端队列(deque)。
关联性容器:元素位置取决于特定的排序规则和插入顺序无关,map、hash-map、set。容器类自动申请和释放内存,无需new和delete操作。
list链表
STL链表是序列性容器的模板类,它将其元素保持在线性排列中,链式结构,并允许在队列中的任何位置进行有效的插入和删除。
特点:list在任何指定位置动态的添加删除效率不变,时间复杂度为O(1),操作相比于vector比较方便。但其查找效率为O(n),若想访问、查看、读取数据使用vector。
双向循环链表:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oZyyPPwM-1686553741440)(C++.assets/image-20230530215305514.png)]](https://img-blog.csdnimg.cn/ad25b4efb1064a528156136a196cdc54.png)
require:#include using namespace std;
构造链表的几种方式
空链表:
list<int> lst;
构建指定长度的链表,且有默认的初始值
list<int> lst(3);
构建了指定长度的链表,手动指定初始值
list<int> lst(3, 4);
使用初始化列表进行构建 类似new int[3]{1,2,3};
list<int> lst{ 2,3,4 };
链表中的一些方法
- begin():获取头节点的迭代器。end():获取尾节点的迭代器。
- front():返回头节点里的值。back():返回尾节点里的值。
- clear():清空链表。
- size():返回链表的长度、元素的数量。
- bool empty(),链表是否为空。
- erase():删除指定迭代器位置的节点,返回的是删除节点的下一个节点的迭代器。insert():指定迭代器位置插入一个元素,返回的是插入的元素的迭代器。
insert():
list<int>::iterator ite = lst.insert(lst.begin(), 1); //在指定位置之前for (int v : lst) {cout << v << " ";}cout << endl;cout << "ite = " << *ite << endl; //返回的是增加的
erase():
ite++;ite = lst.erase(ite);//返回的是删除的下一个for (int v : lst) {cout << v << " ";}cout << endl;if (ite != lst.end()) { cout << "ite = " << *ite << endl; //ite=3}
注意:如果我们删除的是最后一个值,那么ite返回的就是尾节点,但是尾节点中没有元素,强行获取元素就会崩,所以要加一个判断
- push_back()、push_front()、pop_back()、pop_front():链表头尾添加、删除。
- remove(const Type&_Val):将值为val的所有节点删除。
将值为4的所有节点移除:
lst.remove(4);
- unique():对连续而相同的节点移除只剩一个。
lst.push_back(0);lst.push_back(0);lst.push_back(1);lst.push_back(2);lst.push_back(0);lst.unique(); //连续且相同,移除只剩一个for (int v : lst) {cout << v << " ";}cout << endl;
- sort():对链表元素进行排序,默认升序。如果要指定排序规则,需要指定排序规则函数。bool func(Type,Type);或greater()降序,less()升序。
默认:
lst2.sort(); //默认升序for (ite = lst2.begin(); ite != lst2.end(); ite++) {cout << *ite << " ";}cout << endl;
指定规则:
bool rule(int a, int b) {return a > b;
}lst2.sort(&rule); //指定规则for (ite = lst2.begin(); ite != lst2.end(); ite++) {cout << *ite << " ";}cout << endl;
greater/less(降序/升序)
lst2.sort(less<int>()/*greater<int>()*/); for (ite = lst2.begin(); ite != lst2.end(); ite++) {cout << *ite << " ";}cout << endl;
- reverse():链表进行翻转。
lst2.reverse(); //翻转链表for (ite = lst2.begin(); ite != lst2.end(); ite++) {cout << *ite << " ";}cout << endl;
- **剪切拷贝整个链表:**splice(iterator Where,list& Right):将Right链表整个结合到另一个链表Where位置之前,这是一个剪切操作,Right链表将为空。
list<int> lst3{ 1,10,5 };ite = lst2.begin();::advance(ite, 3); //ite+=3lst2.splice(ite, lst3); //将lst3 整个链表放到 3位置之前 ,剪切操作for (ite = lst2.begin(); ite != lst2.end(); ite++) {cout << *ite << " ";}cout << endl;cout << "size = " << lst3.size() << endl; //size = 0
这里我们了解到了一个函数:advance();它可以用来偏移迭代器,正常我们只能通过++来偏移,如果想偏移多个就要用循环,而不能用+=,那么我们就可以用这个方法
**剪切拷贝链表某个节点:**splice(iterator Where,list& Right,iterator First):将Right链表的First位置节点结合到this链表的Where位置之前,这是一个剪切操作。this和Right可以为同一个链表。
lst2.splice(ite, lst3, lst3.begin());for (ite = lst2.begin(); ite != lst2.end(); ite++) {cout << *ite << " ";}cout << endl;for (ite = lst3.begin(); ite != lst3.end(); ite++) {cout << *ite << " ";}cout << endl;
**剪切拷贝链表的某一段节点:**splice(iterator Where,list& Right,iterator First,iterator Last):将Right链表的First位置到Last位置的一段元素[First,Last),不包含Last,结合到this链表的Where位置之前,这是一个剪切操作。this和Right可以为同一个链表,但Where不能位于[First,Last)内。
lst2.splice(ite, lst3, lst3.begin(), --lst3.end());for (ite = lst2.begin(); ite != lst2.end(); ite++) {cout << *ite << " ";}cout << endl;for (ite = lst3.begin(); ite != lst3.end(); ite++) {cout << *ite << " ";}cout << endl;
- merge(list& Right,Traits Comp):将Right链表合并到this链表上,this和Right必须经过排序,两者或都为递增、或都为递减,Comp描述了递增合并还是递减合并,bool func(Type,Type);或greater()降序,less()升序。这是一个剪切操作,Right将为空链表。
升序:
lst2.sort();lst3.sort();lst2.merge(lst3); //合并 剪切操作for (ite = lst2.begin(); ite != lst2.end(); ite++) {cout << *ite << " ";}cout << endl;cout << "size = " << lst3.size() << endl;
降序:
lst2.sort(greater<int>());lst3.sort(greater<int>());lst2.merge(lst3,greater<int>());for (ite = lst2.begin(); ite != lst2.end(); ite++) {cout << *ite << " ";}cout << endl;cout << "size = " << lst3.size() << endl;
- swap(list& Rigth):交换两个链表。
lst2.swap(lst3);for (ite = lst2.begin(); ite != lst2.end(); ite++) {cout << *ite << " ";}cout << endl;for (ite = lst3.begin(); ite != lst3.end(); ite++) {cout << *ite << " ";}cout << endl;
vector向量
vector的行为类似于数组(array),但是其容量会随着需求自动增长(动态数组)向量在尾部的push和pop操作时间是恒定的.在向量的中间insert或erase元素需要线性时间在序列结尾插入、删除操作比开始位置性能要优越。
当向量元素增加超过当前的存储容量时,会发生重新分配操作。重载了[]操作符,就意味着它可以像数组一样使用[下标]访问元素。
特点:数据的存储访问比较方便,可以像数组一样使用[index]访问或修改值,适用于对元素修改和查看比较多的情况,对于insert或erase比较多的操作,很影响效率,不建议使用vector。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rvRp2O5x-1686553741441)(C++.assets/image-20230611224520275.png)]](https://img-blog.csdnimg.cn/19cbe5f8af7440a88985d0441ea1b558.png)
构造向量
require:#include using namespace std;
vector(size_type Count)。vector(size_type Count,const Type& Val)。构造函数,构造指定长度的向量并设定初始值。有默认值。
空向量:
vector<int> vec;
指定向量的容量,默认值为0:
vector<int> vec(3);
指定向量的容量,并且指定默认值:
vector<int> vec(3, 1);
初始化列表初始化向量:
vector<int> vec{ 1,2,3 };
向量中的方法:
- begin(),end(),返回向量头尾元素的迭代器。
- front(),back(),返回头尾元素中的值。
- size(),返回向量的使用量,capacity(),返回向量的容量。
- push_back(),pop_back(),在向量尾部添加删除,当用push_back向vector尾部加元素的时候,如果当前的空间不足,会重新申请一块更大的空间。pop_back删除时,使用量减少,但容量不会减少。不同于list,并没有提供push_front()和pop_front()。
- insert(const_iterator Where,const Type& Val),向量的某个位置之前插入指定值。insert(const_iterator Where,size_type Count,const Type& Val)。向量的某个位置之前插入count个指定值。 返回插入元素的迭代器,size会增加。
ite = vec.insert(vec.begin(), 0);
- erase(count_iterator Where),删除迭代器指向的元素,返回的是删除元素的下一个元素的迭代器。size减少,capacity不变。
ite = vec.begin() + 3;//ite += 3;ite = vec.erase(ite);
向量中的迭代器可以有+,+=操作
- clear(),清空向量元素,size使用量为0,capacity不变。
- empty(),向量是否为空,描述的是使用量(size)。
- resize(size_type Newsize),resize(size_type _Newsoze,Type _Val)。为向量指定新的使用量,如果使用量减少,元素按顺序截取,但容量不变;如果使用量增加,则会有默认值0;如果使用量增加大于原容量,则扩展容量,有默认值,也可以指定新的扩展元素的值。
- swap(vector& Right),交换两个向量的元素。
vector<int> v1(3);vec.swap(v1);
可以利用交换将向量中的使用量和容量都清零
vector<int>().swap(vec);
对比 list 和 vector :
- vector是连续性空间,是顺序存储,list是链式结构体,链式存储。
- vector在非尾部插入、删除节点会导致其他元素的拷贝移动,list则不会影响其他节点元素。
- vector一次性分配好内存,使用量不够时,申请内存重新分配。list每次插入新节点时都会申请内存。
- vector随机访问性能好,插入删除性能差;list随机访问性能差,插入删除性能好。
- vector具有容量和使用量的概念,而list只有使用量(即长度)概念。
deque双端队列
deque没有容量的观念。它是动态以分段连续空间组合而成,一旦有必要在deque的前端和尾端增加新空间,串接在整个deque的头端或尾端,deque的迭代器不是普通的指针,其复杂度比vector复杂的多。除非必要,我们应该尽量选择使用vector而非deque。
deque是一种双向开口的连续性空间,可在头尾两端分别做元素的插入和删除操作。
deque模型图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-P1gn5EWD-1686553741441)(C++.assets/image-20230611233419099.png)]](https://img-blog.csdnimg.cn/61ed7ffb08ec4d63b549be45ae21284b.png)
构造双端队列:
require:#include using namespace std;
deque(size_type Count),deque(size_type_Count,const Type& Val),构造函数,构造指定长度的向量并设定初始值。有默认值。
同样也是有三种构造方法(指定元素个数给定默认值,手动给值,初始化参数列表)。
deque<int> de{ 1,2,3,4 };
方法:
- push_back()、push_front()、pop_back()、pop_front()。
- begin()、end()、back()、front()、erase()、insert()。
- size()、empty()、clear(),支持[]下标访问,所以可以使用下标遍历。
双端队列的几种遍历方法:
下标:
for (int i = 0; i < de.size(); i++) {cout << de[i] << " ";}cout << endl;
增强的范围for:
for (int v : de) {cout << v << " ";}cout << endl;
迭代器遍历:
deque<int>::iterator ite = de.begin();while (ite != de.end()) {cout << *ite << " ";ite++;}
map映射表
Map的特性是,所有元素都会根据元素的键值自动被排序,map的所有元素都是pair,同时拥有键值(key)和实值(value)。pair的第一元素被视为键值,第二元素被视为实值。Map不允许两个元素拥有相同的键值,Map的键值关系到Map的元素排列规则,任意改变Map的元素键值将严重破坏Map的组织。所以不可以通过Map的迭代器来改变Map的键值。但可以通过迭代器来修改元素的实值。
查找效率:O(log2(n)),内部实现红黑树。
map模型图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bwJCq73e-1686553741441)(C++.assets/image-20230612121457200.png)]](https://img-blog.csdnimg.cn/46ebd1552f004810a9f05b0af11d8902.png)
构造:
require:#include
map<char, int> mm{ {'d',1},{'f',2},{'b',3} };
可以直接使用key值增加元素:
mm['c'] = 4;
方法:
- begin()、end(),支持迭代器遍历。
map<char, int> ::iterator ite = mm.begin();while (ite != mm.end()) {cout << ite->first << "-" << ite->second << " ";ite++;}cout << endl;
- pair<iterator,bool>insert(value_type& Val),插入一个元素,如果key值重复,则插入失败。iterator erase(iterator Where),返回删除的下一个。(没有push和pop的插入删除)。
插入:
pair<map<char, int> ::iterator,bool> pr = mm.insert(pair<char, int>('a', 5)); //插入成功,返回true,迭代器指向新增的元素if (pr.second) {cout << "插入成功" << endl; //插入成功}else {cout << "插入失败" << endl;}cout << pr.first->first << "--" << pr.first->second << endl; pr = mm.insert(pair<char, int>('a', 6)); //插入失败,返回false,迭代器指向的是已存在的元素if (pr.second) {cout << "插入成功" << endl;}else {cout << "插入失败" << endl; //插入失败}cout << pr.first->first << "--" << pr.first->second << endl;
删除:
ite = ++mm.begin();ite = mm.erase(ite);for (pair<char, int> pr : mm) {cout << pr.first << "-" << pr.second << " ";}cout << endl;if (ite != mm.end()) {cout << ite->first << "-" << ite->second << endl;}
- clear()、size()、empty()
- iterator find(const Key& Key)、按键值查找,未匹配到返回end(),count(const Key& Key),按键值统计元素,返回1或0。
通过键值查找删除元素:
ite = mm.find('d');if (ite != mm.end()) { //如果找到了元素,则删除ite = mm.erase(ite);}for (pair<char, int> pr : mm) {cout << pr.first << "-" << pr.second << " ";}cout << endl;
- upper_bound(const Key& Key)、返回大于该键值的map的迭代器。lower_bound(const Key& Key),返回该键值或者大于该键值的map的迭代器。
map<char,int>::iterator ite = mm.upper_bound('b');cout << ite->first << "-" << ite->second << endl; //c-4
ite = mm.lower_bound('b');cout << ite->first << "-" << ite->second << endl; //b-3
如果upper_bound和lower_bound返回的迭代器相同,那么代表元素不存在
char e = 'e';if (mm.upper_bound(e) == mm.lower_bound(e)) { //元素不存在cout << e << "不存在" << endl;}else {cout << e << "存在" << endl;}
set集合
所有元素都会根据元素的键值自动被排序,Set的元素Map那样可以同时拥有实值和键值,Set元素的简直就是实值,实值就是键值。Set不允许两个元素有相同的键值,因为Set元素值就是其键值,关系到Set元素的排列规则。如果任意改变Set的元素值,会严重的破坏Set组织。
查找效率:O(log2(n)),内部实现红黑树。
构造:
require:#include using namespace std;
set<int> st{ 4,1,6,3 };
因为没有实值键值的区分了,所以不能像map一样用[]去添加了
方法:
- begin()、end(),支持迭代器遍历。
set<int>::iterator ite = st.begin();while (ite != st.end()) {cout << *ite << " ";ite++;}cout << endl;
- pair<iterator,bool>insert(const value_type& Val),插入一个元素,如果key值重复,则插入失败。iterator erase(iterator Where),返回删除的下一个。
pair<set<int>::iterator,bool> pr = st.insert(6);if (!pr.second) {cout << "插入失败" << endl;}cout << *pr.first << endl;
- clear()、size()、empty()。
- iterator find(const Key& Key)、按键值查找,未匹配到返回end(),count(const Key& Key),按键值统计元素,返回1或0。
ite = st.find(44);if (ite == st.end()) {cout << "没找到" << endl;}
- upper_bound(const Key& Key)、返回大于该键值的set的迭代器。lower_bound(const Key& Key),返回该键值或者大于该键值的set的迭代器。
hash_map哈希表
基于hash table(哈希表),数据的存储和查找效率非常高,几乎可以看作常量时间,相应的代价是消耗更多的内存。使用一个较大的数组来存储元素,经过算法,使得每个元素与数组下标有唯一的对应关系,查找时直接定位。
查找效率O(1)。
构造:
require:#include<hash_map> using namespace std;
若高版本需要 #define _SILENCE_STDEXT_HASH_DEPRECATION_WARNINGS 来去除error,或使用<unordered_map>
#include<unordered_map>
using namespace std;
unordered_map<string, int> mm;mm["aa"] = 1;mm["ff"] = 2;mm["oo"] = 3;mm["cc"] = 4;
方法:
- begin()、end(),返回头、尾节点的迭代器。支持迭代器遍历。
unordered_map<string, int>::iterator ite = mm.begin();while (ite != mm.end()) {cout << ite->first << "-" << ite->second << " ";ite++;}cout << endl;
遍历结果为无序的
- pair<iterator,bool> insert(const value_type& Val),插入一个元素,如果key值重复,则插入失败。iterator erase(iterator Where),返回删除的下一个。
- iterator find(const Key& _Key),按照key值进行查找, 注意:查找速度,数据量,内存使用。
ite = mm.find("cc");ite = mm.erase(ite);for (pair<string, int> pr : mm) {cout << pr.first << "-" << pr.second << " ";}cout << endl;cout << ite->first << "-" << ite->second << endl;
相关文章:
【C++】 STL(上)STL简述、STL容器
文章目录 简述STL容器list链表vector向量deque双端队列map映射表set集合hash_map哈希表 简述 STL是“Standard Template Library”的缩写,中文译为“标准模板库”。STL是C标准库的一部分,位与各个C的头文件中,即他并非以二进制代码的形式提供…...

【002 基础知识】什么是原子操作?
一、原子操作 原子操作就是指不能再进一步分割的操作。 二、为了实现一个互斥,自己定义一个变量作为标记来作为一个资源只有一个使用者行不行? 不行。如果在一个线程正持有锁时(2处),线程上下文发生切换,…...

English Learning - L3 作业打卡 Lesson5 Day32 2023.6.5 周一
English Learning - L3 作业打卡 Lesson5 Day32 2023.6.5 周一 引言🍉句1: What do you read when you are travelling by train or bus?成分划分弱读爆破语调 🍉句2: What are other passengers reading?成分划分弱读连读语调 🍉句3: Perh…...

深度学习应用篇-自然语言处理-命名实体识别[9]:BiLSTM+CRF实现命名实体识别、实体、关系、属性抽取实战项目合集(含智能标注)【上篇】
【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化算法、卷积模型、序列模型、预训练模型、对抗神经网络等 专栏详细介绍:【深度学习入门到进阶】必看系列,含激活函数、优化策略、损失函数、模型调优、归一化…...
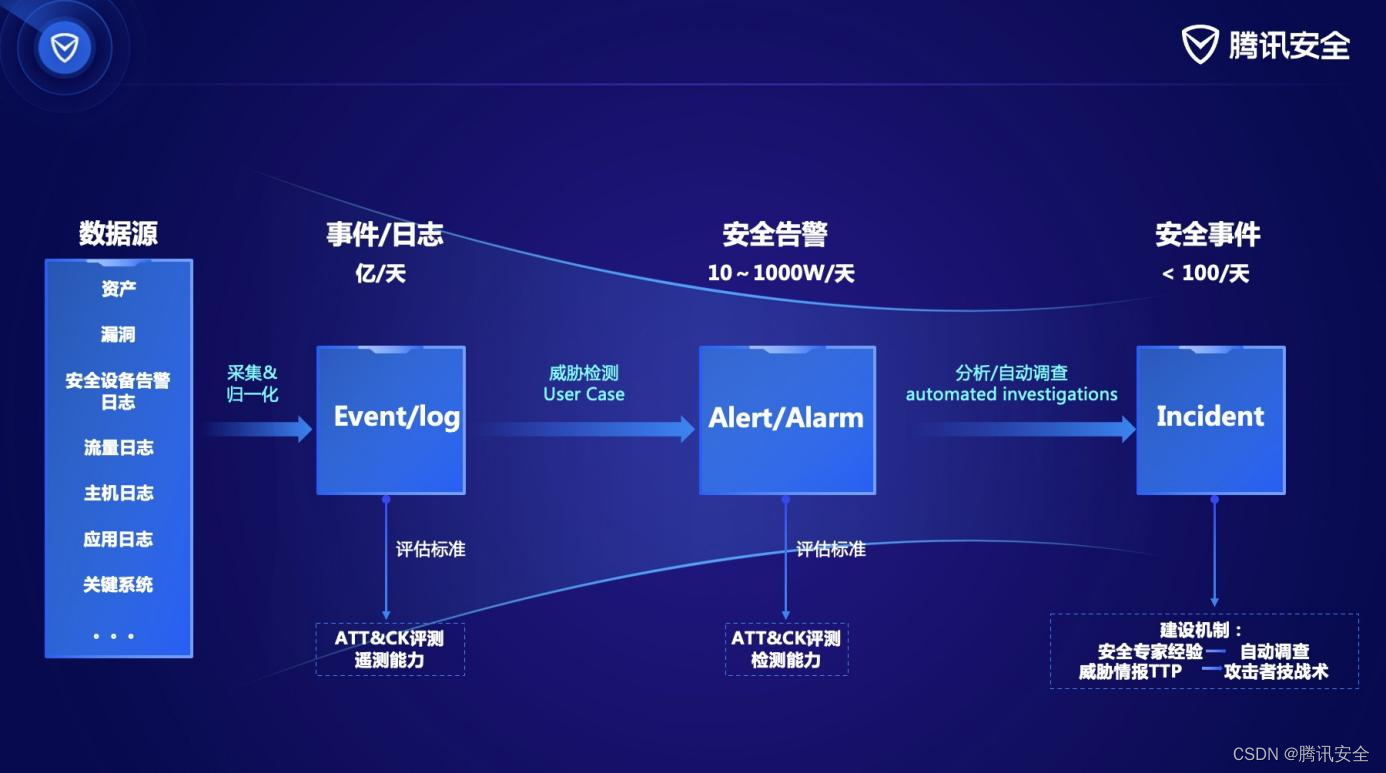
腾讯安全SOC+荣获“鑫智奖”,助力金融业数智化转型
近日,由金科创新社主办,全球金融专业人士协会支持的“2023鑫智奖第五届金融数据智能优秀解决方案评选”榜单正式发布。腾讯安全申报的“SOC基于新一代安全日志大数据平台架构的高级威胁安全治理解决方案”获评“鑫智奖网络信息安全创新优秀解决方案”。 …...

Python绘制气泡图示例
部分数据来源:ChatGPT 引言 在数据可视化领域中,气泡图是一种能够同时展示三维信息的图表类型,常用于表示数据集中的两个变量之间的关系。Python中提供了许多用于绘制气泡图的可视化库,比如pyecharts。在本篇文章中,我们将介绍如何使用pyecharts库绘制一个简单的气泡图,…...

数学建模经历-程序人生
引言 即将大四毕业(现在大三末),闲来无事(为了冲粽子)就写一篇记录数学建模经历的博客吧。其实经常看到一些大佬的博客里会有什么"程序人生"、"人生感想"之类的专栏,但是由于我只是一个小趴菜没什么阅历因此也就没有写过类似的博客…...

数字电子电路绪论
博主介绍:一个爱打游戏的计算机专业学生 博主主页:夏驰和徐策 所属专栏:程序猿之数字电路 1.科技革命促生互联网时代 科技革命对互联网时代的兴起产生了巨大的推动作用。以下是一些科技革命对互联网时代的促进因素: 1. 计算机技…...

电脑丢失dll文件一键修复需要什么软件?快速修复dll文件的方法
在使用电脑的过程中,我们经常会遇到程序无法正常运行的情况,提示“XXX.dll文件丢失”的错误。这时候,很多人会感到困惑,不知道该如何解决。本文将详细介绍dll文件丢失的各种原因、如何使用dll修复工具进行一键修复dll丢失问题以及…...
你知道微信的转账是可以退回的吗
微信作为当今最受欢迎的即时通讯软件之一,其转账功能得到了广泛的应用。在使用微信转账时,我们可能会遇到一些问题,例如误操作、支付失败或者需要退款等等。 首先需要注意的是,微信转账退回的操作只能在“一天内未确认”时进行。如…...
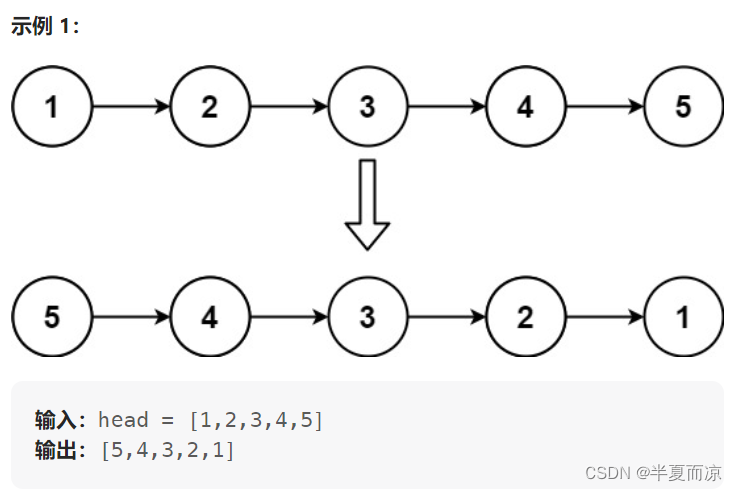
【链表Part01】| 203.移除链表元素、707.设计链表、206.反转链表
目录 ✿LeetCode203.移除链表元素❀ ✿LeetCode707.设计链表❀ ✿LeetCode206.反转链表❀ ✿LeetCode203.移除链表元素❀ 链接:203.移除链表元素 给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val val 的节点ÿ…...

如何使用Postman生成curl?
生成在Lunix系统调接口的curl 直接看图操作 点击</>即可!...

CSS灯光效果,背景黑金效果
先看效果 再看代码: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>灯光效果</title><link href"https://fonts.googleapis.com/css2?familyCinzel:wght700&dis…...
这里推荐几个前端icon网站(动图网站)
1. Loading.ioLoading.io 是一个免费的加载动效(Loading animations)图标库。它提供了多种风格的加载动效图标,包括 SVG、CSS 和 Lottie 动画格式。这些加载图标可以增强用户体验,为网站和应用程序添加更佳的视觉效果。 网站地址:loading.io - Your SVG GIF PNG Ajax Loading…...

【图神经网络】用PyG实现图机器学习的可解释性
Graph Machine Learning Explainability with PyG 框架总览示例:解释器The Explanation ClassThe Explainer Class and Explanation SettingsExplanation评估基准数据集Explainability Visualisation实现自己的ExplainerAlgorithm对于异质图的扩展解释链路预测 总结…...

HarmonyOS ArkTS Ability内页面的跳转和数据传递
HarmonyOS ArkTS Ability的数据传递包括有Ability内页面的跳转和数据传递、Ability间的数据跳转和数据传递。本节主要讲解Ability内页面的跳转和数据传递。 打开DevEco Studio,选择一个Empty Ability工程模板,创建一个名为“ArkUIPagesRouter”的工程为…...

MySQL 8.0.29 instant DDL 数据腐化问题分析
前言Instant add or drop column的主线逻辑表定义的列顺序与row 存储列顺序阐述引入row版本的必要性数据腐化问题原因分析Bug重现与解析MySQL8.0.30修复方案 前言 DDL 相对于数据库的 DML 之类的其他操作,相对来说是比较耗时、相对重型的操作; 因此对业务的影比较严…...
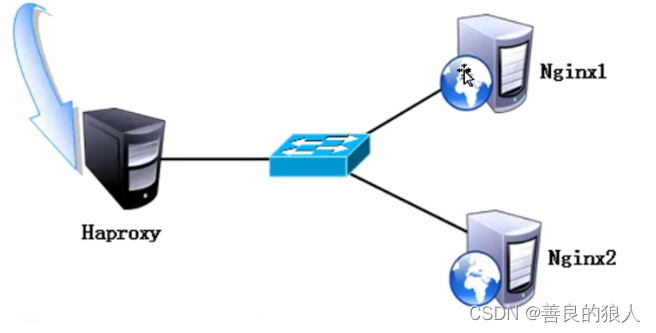
Haproxy搭建负载均衡
Haproxy搭建负载均衡 一、常见的Web集群调度器二、Haproxy介绍1、Haproxy应用分析2、Haproxy的主要特性3、Haproxy负载均衡策略 三、LVS、Nginx、Haproxy之间的区别四、Haproxy搭建Web群集1、Haproxy服务器部署2、节点服务器部署3、测试Web群集 五、日志定义1、方法一2、方法二…...

SpringBoot:SpringBoot启动加载过程 ④
一、思想 我们看到技术上高效简单的使用,其实背后除了奇思妙想的开创性设计,另一点是别人帮你做了复杂繁琐的事情。 二、从官网Demo入手 官网就一行代码。这个就是它的启动代码。 1、SpringBootApplication注解 ①. 三个核心注解的整合。 SpringBootCon…...

抽象轻松JavaScript
真真假假,鬼鬼,谁知道什么是真什么是假 疑点二:什么是真,什么是假 核心:确定一个清晰的目的,可以达到目的就是真,达不到就是假 知道了核心开始举例 考大学,考上大学就是满足目的…...

2026金铲铲之战电脑版模拟器实测:选对模拟器轻松上分
一、实测前提说明作为拥有三年游玩经验的金铲铲之战老弈士,从手机端切换到电脑端游玩后,大屏在阵容运营、棋子对位、选秀博弈上的优势十分突出:手机小屏不仅看不清棋子星级、装备细节,频繁触屏操作还容易误触卖错棋子、放错站位&a…...

3分钟完成Windows和Office永久激活:KMS智能激活脚本终极指南
3分钟完成Windows和Office永久激活:KMS智能激活脚本终极指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活烦恼吗?Office突然变成只读模式让你工…...

避坑指南:SciencePlots安装后样式不生效?手把手教你排查Matplotlib的stylelib路径问题
科学绘图样式失效?彻底解决Matplotlib样式库路径配置难题 当你第一次尝试用SciencePlats的science样式美化科研图表时,却发现Python报出KeyError: science is not a valid style的错误提示——这种挫败感我深有体会。作为每天与数据可视化打交道的从业者…...
)
Midjourney v7新功能全维度压测报告(v6 vs v7实测对比:提示词容错率↑47%,构图理解准确率突破92.6%)
更多请点击: https://intelliparadigm.com 第一章:Midjourney v7新功能全面解析 Midjourney v7 于2024年第三季度正式发布,标志着AI图像生成在语义理解、构图控制与跨模态一致性方面迈入新阶段。本次升级不再仅依赖提示词(prompt…...
)
Simulink仿真避坑指南:PWM控制48V直流电机时,轻载和重载下的参数设置与波形分析(附2018a源文件)
Simulink仿真避坑指南:PWM控制48V直流电机时,轻载和重载下的参数设置与波形分析 在工程实践中,直流电机的仿真建模是验证控制算法和预测系统性能的关键环节。特别是当面对不同负载条件时,如何准确设置电机参数并解读仿真波形&…...

如何用DdddOcr在3分钟内构建离线验证码识别系统
如何用DdddOcr在3分钟内构建离线验证码识别系统 【免费下载链接】ddddocr 带带弟弟 通用验证码识别OCR pypi版 项目地址: https://gitcode.com/gh_mirrors/dd/ddddocr 在当今的自动化测试、数据采集和网络安全领域,验证码识别是绕不开的技术难题。传统的在线…...

粒子群灰狼优化算法稀疏码设计【附代码】
✨ 长期致力于稀疏码多址接入、星型正交振幅调制、功率不平衡码本、粒子群算法、混合粒子群灰狼优化算法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1ÿ…...

构建自我进化的AI家园:基于多智能体与GitOps的工程实践
1. 项目概述:构建一个能自我进化的AI家园如果你和我一样,对那种“一问一答”式的AI聊天机器人感到厌倦,总想着能不能让AI更“主动”一点,甚至能帮你打理整个技术栈,那么这个项目绝对值得你花时间研究。ai-homebase不是…...

小白程序员必看:收藏这份AI黑话指南,轻松入门大模型世界!
本文用大白话解释了AI领域几个核心概念:AI是总称,LLM是推理模型,Agent能独立执行任务,MCP是标准化接口,Skills是技能包。文章通过生活化比喻和实例,帮助读者理解这些概念如何协同工作,实现高效自…...

Unity3D游戏马赛克清除终极指南:7种高效技术深度解析
Unity3D游戏马赛克清除终极指南:7种高效技术深度解析 【免费下载链接】UniversalUnityDemosaics A collection of universal demosaic BepInEx plugins for games made in Unity3D engine 项目地址: https://gitcode.com/gh_mirrors/un/UniversalUnityDemosaics …...