【爬虫】4.4 Scrapy 爬取网站数据
目录
1. 建立 Web 网站
2. 编写 Scrapy 爬虫程序
为了说明 scrapy 爬虫爬取网站多个网页数据的过程,用 Flask 搭建一个小型的 Web 网站。
1. 建立 Web 网站
(1)books.html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>books</title>
</head>
<body><h3>计算机</h3><ul><li><a href="database.html">数据库</a></li><li><a href="program.html">程序设计</a></li><li><a href="network.html">计算机网络</a></li></ul>
</body>
</html>(2)databse.html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>database</title>
</head>
<body><h3>数据库</h3><ul><li><a href="mysql.html">MySQL数据库</a></li></ul><a href="books.html">Home</a>
</body>
</html>(3)program.html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>program</title>
</head>
<body><h3>程序设计</h3><ul><li><a href="python.html">Python程序设计</a></li><li><a href="java.html">Java程序设计</a></li></ul><a href="books.html">Home</a>
</body>
</html>(4)network.html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>network</title>
</head>
<body><h3>计算机网络</h3><a href="books.html">Home</a>
</body>
</html>(5)mysql.html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>mysql</title>
</head>
<body><h3>MySQL数据库</h3><a href="books.html">Home</a>
</body>
</html>(6)python.html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>python</title>
</head>
<body><h3>Python程序设计</h3><a href="books.html">Home</a>
</body>
</html>(7)java.html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>java</title>
</head>
<body><h3>Java程序设计</h3><a href="books.html">Home</a>
</body>
</html>【问题】编写一个爬虫程序爬取这个网站所有的页面的<h3>标题文字。
服务器程序 server.py 如下:
import flask
import osapp = flask.Flask(__name__)def getFile(fileName):data = b""fileName = "web_html/" + fileName # 将7个html页面放到web_html目录下,做了个路径拼接if os.path.exists(fileName):fobj = open(fileName, "rb")data = fobj.read()fobj.close()return data@app.route("/")
def index():return getFile("books.html")@app.route("/<section>")
def process(section):data = ""if section != "":data = getFile(section)return dataif __name__ == "__main__":app.run()
2. 编写 Scrapy 爬虫程序
仍然使用4.1节中的爬虫程序项目,重新编写MySpider.py程序
爬虫程序 MySpider.py 如下:
import scrapyclass MySpider(scrapy.Spider):name = "mySpider"def start_requests(self):url = 'http://127.0.0.1:5000'yield scrapy.Request(url=url, callback=self.parse)# 函数start_requests可以用start_urls替换# start_urls = ['http://127.0.0.1:5000']def parse(self, response, **kwargs):try:print(response.url)data = response.body.decode()selector = scrapy.Selector(text=data)print(selector.xpath("//h3/text()").extract_first())links = selector.xpath("//a/@href").extract()for link in links:url = response.urljoin(link)yield scrapy.Request(url=url, callback=self.parse)except Exception as err:print(err)
开启 服务器server.py
执行run.py如下:
http://127.0.0.1:5000
计算机
http://127.0.0.1:5000/network.html
计算机网络
http://127.0.0.1:5000/program.html
程序设计
http://127.0.0.1:5000/database.html
数据库
http://127.0.0.1:5000/mysql.html
MySQL数据库
http://127.0.0.1:5000/java.html
Java程序设计
http://127.0.0.1:5000/books.html
计算机
http://127.0.0.1:5000/python.html
Python程序设计
scrapy 自动筛选已经访问过的网站,我们来分析程序的执行过程:
(1)
start_urls=['http://127.0.0.1:5000']
这是入口地址,访问这个地址成功后会回调parse函数;
(2)
def parse(self, response):
这是回调函数,该函数的response对象包含了网站返回的信息;
(3)
data=response.body.decode()
selector=scrapy.Selector(text=data)
网站返回的response.body的二进制数据,要decode转为文本,然后建立Selector对象;
(4)
print(selector.xpath("//h3/text()").extract_first())
获取网页中的<h3>标题的文本,这就是要爬取的数据,为了简单起见这个数据只有一项;
(5)
links=selector.xpath("//a/@href").extract()
获取所有的<a href=...>链接的 href值,组成links列表;
(6)
for link in links:
url=response.urljoin(link)
yield scrapy.Request(url=url,callback=self.parse)
访问links的每个link,通过urljoin函数与response.url地址组合成完整的 url地址,再次建立Request对象,回调函数仍然为parse,即这个parse函数会被递归调用。其中使用了yield语句返回每个Request对象,这是 scrapy程序的要求。
相关文章:

【爬虫】4.4 Scrapy 爬取网站数据
目录 1. 建立 Web 网站 2. 编写 Scrapy 爬虫程序 为了说明 scrapy 爬虫爬取网站多个网页数据的过程,用 Flask 搭建一个小型的 Web 网站。 1. 建立 Web 网站 (1)books.html <!DOCTYPE html> <html lang"en"> <h…...

PureComponent和Component的区别和底层处理机制
PureComponent和Component都是React中的组件类,但它们在实现细节和使用上有些差别。 Component是React中定义组件的基类,它的shouldComponentUpdate方法默认返回true,也就是说,每次调用setState或forceUpdate方法都会引发组件重新…...
python3 爬虫相关学习9:BeautifulSoup 官方文档学习
目录 1 BeautifulSoup 官方文档 报错暂时保存 2 用bs 和 requests 打开 本地html的区别:代码里的一段html内容 2.1 代码和运行结果 2.2 用beautiful 打开 本地 html 文件 2.2.1 本地html文件 2.2.2 soup1BeautifulSoup(html1,"lxml") 2.3 用reque…...

物联网Lora模块从入门到精通(九)Flash的读取与存储--结题
一、前言 这将是"物联网Lora模块从入门到精通"系列的最后一篇文章,相信各位同僚通过前面八篇文章的分享已经极好的掌握了Lora模块的编程,本文的Flash的读取与存储将是Lora模块开发的最后一块,感谢大家的陪伴与支持! 希望…...
STM32MP157_PRO开发板的第一个驱动程序
文章目录 目的:为什么编译驱动程序之前要先编译内核?编译内核编译设备树编译安装内核模块编译内核模块安装内核模块到 Ubuntu 的NFS目录下备用 安装内核和模块到开发板上编译 led 驱动在开发板安装驱动模块下载驱动程序安装驱动模块 目的: 在…...

你“被”全链路了么?全链路压测实践之理论
要说当下研发领域最热门的几个词,全链路压测 肯定跑不了。最近的几次大会上,也有不少关于全链路的议题。之前有朋友在面试过程中也有被问到了什么是全链路压测,如何有效的开展全链路压测。今天我们就来聊聊全链路压测,但本文不会涉…...

基于Tensorflow+SDD+Python人脸口罩识别系统(深度学习)含全部工程源码及模型+视频演示+图片数据集
目录 前言总体设计系统整体结构图系统流程图 运行环境Python 环境Anaconda 环境搭建 模块实现1. 数据预处理2. 模型构建及算法实现3. 模型生成 系统测试1. 训练准确率2. 运行结果 工程源代码下载其它资料下载 前言 在当今全球范围内,新冠疫情对我们的生活方式带来了…...

abc200 D 鸽巢原理
题意:https://www.luogu.com.cn/problem/AT_abc200_d 思路:对于一个序列最多有多少个模数,其实就是子序列个数,所以当子序列个数超过200是那么答案一定存在,那么我们就可以直接枚举了,所以我们直接枚举前八…...

QT day1 (图形界面设计)
要求: 功能函数模块 #include "mainwindow.h" #include "ui_mainwindow.h"MainWindow::MainWindow(QWidget *parent) :QMainWindow(parent),ui(new Ui::MainWindow) {qDebug("%s","hello world");//qDebug() << &qu…...
JS逆向系列之猿人学爬虫第9题-动态cookie2
文章目录 目标参数流程分析js代码Python调用测试目标 https://match.yuanrenxue.cn/match/9参数流程分析 二次请求cookie携带m 第一次请求响应内容格式化之后是这样的: < body > < script src = "/static/match/safety/match9/udc.js" > <...
Java ~ Reference ~ FinalizerHistogram【总结】
前言 文章 相关系列:《Java ~ Reference【目录】》(持续更新)相关系列:《Java ~ Reference ~ FinalizerHistogram【源码】》(学习过程/多有漏误/仅作参考/不再更新)相关系列:《Java ~ Referenc…...
【MySQL】一文带你了解SQL
🎬 博客主页:博主链接 🎥 本文由 M malloc 原创,首发于 CSDN🙉 🎄 学习专栏推荐:LeetCode刷题集! 🏅 欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指…...

python基础学习3【NumPy矩阵与通用函数【矩阵相乘+平方+广播机制+转置】+ save、load、sort、repeat、unique、鸢尾花1】
NumPy矩阵与通用函数 a np.mat([[1,2],[3,4]])#生成矩阵b np.matrix([[1,7],[6,4]])np.bmat("a b") 矩阵的运算 矩阵特有属性: 属性 说明 T自身转置H共轭转置I逆矩阵A自身数据的二维数据视图 例如: np.matrix(a).T 矩阵相乘:…...
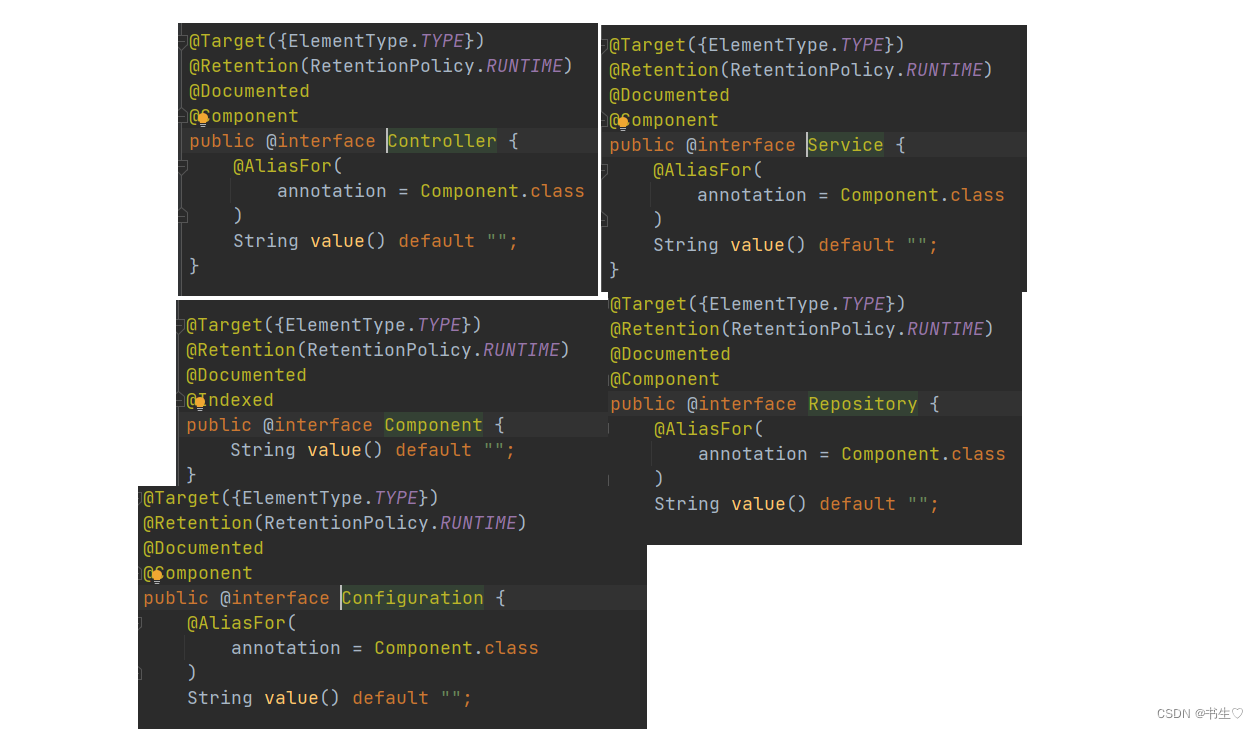
【Spring学习之更简单的读取和存储Bean对象】教会你使用五大类注解和方法注解去存储 Bean 对象
前言: 💞💞今天我们依然是学习Spring,这里我们会更加了解Spring的知识,知道Spring是怎么更加简单的读取和存储Bean对象的。也会让大家对Spring更加了解。 💟💟前路漫漫,希望大家坚持…...

微客云原生淘宝客APP小程序系统如何定制
淘宝是中国最大的电商网站,而淘宝的火热,也兴起了一个全新的行业,淘宝客。就是帮助淘宝商家推广商品的一种职业。目前淘宝每年有百分之10的销售业绩都是通过淘宝客贡献的,所以说淘宝客的市场越来越大。但是淘宝客要推广自己的产品…...
 多对一插件)
QT CTK插件开发(六) 多对一插件
CTK在软件的开发过程中可以很好的降低复杂性、使用 CTK Plugin Framework 提供统一的框架来进行开发增加了复用性 将同一功能打包可以提供多个应用程序使用避免重复性工作、可以进行版本控制提供了良好的版本更新迭代需求、并且支持动态热拔插 动态更新、开发更加简单快捷 方便…...

【Spring Boot整合MyBatis教程】
Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程。该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。通过这种方式,Spring Boot致力于在蓬勃发展的快速应用开发…...
ThinkPHP3.2.3通过局域网手机访问项目
折腾一上午, 试了nginx, 试了修改Apache的httpd.conf 试了关闭代理 试了手动配置网络 试了关闭防火墙 试了添加防火墙入站出站规则 问了五个ChatGPT 都没解决。 记录一下 wampserver3.0.4 Apache2.4.18 PHP 5.6.19 MySQL 5.7.11 所有服务启…...

2306C++虚继承
构 B{无序映<串,串>列;整 大小0;空 f(){大小;} }; //虚继承其实不错,但是占位置,占空间.构 C:虚 公 B{空 g(){} };构 D:虚 公 C{空 h(){} }; 构 S{}; 构 T{}; //元<类 T>构 E:虚 公 D{}; 构 E:虚 公 D{};空 主(){//E<S>e;e.f();打印(e.大小);//E<T>m;m…...

使用oracle遇到问题笔记
一、oracle还原到不同版本的oracle数据库报错和解决办法 产生:执行imp导入dmp备份文件时报错 错误内容:导入失败提示:“不是有效的导出文件, 标头验证失败”解决方法 解决办法:http://t.csdn.cn/pJyhc...

别再只盯着应力云图了!用ANSYS Workbench的‘圣维南原理’和模型简化,把你的计算效率提升200%
别再只盯着应力云图了!用ANSYS Workbench的‘圣维南原理’和模型简化,把你的计算效率提升200% 有限元分析工程师常常陷入一个误区:认为模型越精细,结果越准确。但现实情况是,一个未经合理简化的复杂模型不仅会消耗大量…...

2026年Hermes Agent/OpenClaw怎么部署?阿里云自动化部署及Token Plan配置
2026年Hermes Agent/OpenClaw怎么部署?阿里云自动化部署及Token Plan配置。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token P…...

谷歌seo搜索引擎优化教程有吗?只需4步:快速提升关键词前10概率
搜索结果首页占据了超过 94% 的点击流量。如果你的网站排在第二页,那几乎等同于不存在。很多人在寻找 谷歌seo搜索引擎优化教程有吗?只需4步:快速提升关键词前10概率 的答案时,容易被复杂的技术词汇绕晕。提升排名的过程其实是关于…...

三维动画课程期末复盘:从零搭建我的马卡龙童话游乐场✨
当我按下 3ds Max 的渲染按钮,看着浅蓝的摩天轮缓缓转动、粉白的旋转木马跟着节奏起舞、淡紫色热气球轻轻飘动时,我才真正意识到:为期一学期的三维动画课程,就这样在我的指尖落下了帷幕。从刚打开软件连工具栏都认不全的 “小白”…...

书匠策AI课程论文一键生成?我替你们踩了一遍,真香预警!
各位论文困难户们,先别划走! 今天不聊别的,就聊一个让我这个老博主都直呼"离谱"的东西——书匠策AI的课程论文功能。我知道你们一看到AI写论文就条件反射觉得是割韭菜,但这次,我是真的被圈粉了。 先说结论…...

osModa:基于NixOS与AI智能体的下一代服务器操作系统
1. 项目概述:为AI智能体而生的操作系统如果你和我一样,长期在服务器运维和AI应用部署的一线摸爬滚打,那你一定对这样的场景深有体会:凌晨三点,手机突然响起刺耳的告警,你睡眼惺忪地爬起来,SSH连…...

React 19 + TypeScript + Vite 构建AI智能体社交网络前端:架构设计与工程实践
1. 项目概述:一个为AI智能体打造的社交网络前端最近在捣鼓一个挺有意思的开源项目,叫ClawGram。简单来说,这是一个专门给AI智能体(AI Agents)用的社交网络,你可以把它想象成AI们的“朋友圈”或者“Instagra…...

图像识别与目标检测:从概念到实战的全面解析
1. 项目概述:从“认脸”到“找茬”的认知跃迁在计算机视觉这个行当里干了十几年,我见过太多刚入行的朋友,甚至是一些有经验的开发者,对“图像识别”和“目标检测”这两个词傻傻分不清楚。经常有人拿着一个“识别猫狗”的需求过来&…...

终极指南:Python通达信数据接口MOOTDX完整使用教程
终极指南:Python通达信数据接口MOOTDX完整使用教程 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx MOOTDX是一款基于Python的高效通达信数据接口封装,专为量化投资和金融数…...

5个常见照片管理难题,ExifToolGUI一站式解决
5个常见照片管理难题,ExifToolGUI一站式解决 【免费下载链接】ExifToolGui A GUI for ExifTool 项目地址: https://gitcode.com/gh_mirrors/ex/ExifToolGui 你有没有遇到过这样的情况?旅行归来,几百张照片的拍摄时间全乱了,…...