4.将图神经网络应用于大规模图数据(Cluster-GCN)
到目前为止,我们已经为节点分类任务单独以全批方式训练了图神经网络。特别是,这意味着每个节点的隐藏表示都是并行计算的,并且可以在下一层中重复使用。
然而,一旦我们想在更大的图上操作,由于内存消耗爆炸,这种方案就不再可行。例如,一个具有大约1000万个节点和128个隐藏特征维度的图已经为每层消耗了大约5GB的GPU内存。
因此,最近有一些努力让图神经网络扩展到更大的图。其中一种方法被称为Cluster-GCN (Chiang et al. (2019),它基于将图预先划分为子图,可以在子图上以小批量的方式进行操作。
为了展示,让我们从 Planetoid 节点分类基准套件(Yang et al. (2016))中加载PubMed 图:
import torch
from torch_geometric.datasets import Planetoid
from torch_geometric.transforms import NormalizeFeaturesdataset = Planetoid(root='data/Planetoid', name='PubMed', transform=NormalizeFeatures())print()
print(f'Dataset: {dataset}:')
print('==================')
print(f'Number of graphs: {len(dataset)}')
print(f'Number of features: {dataset.num_features}')
print(f'Number of classes: {dataset.num_classes}')data = dataset[0] # Get the first graph object.print()
print(data)
print('===============================================================================================================')# Gather some statistics about the graph.
print(f'Number of nodes: {data.num_nodes}')
print(f'Number of edges: {data.num_edges}')
print(f'Average node degree: {data.num_edges / data.num_nodes:.2f}')
print(f'Number of training nodes: {data.train_mask.sum()}')
print(f'Training node label rate: {int(data.train_mask.sum()) / data.num_nodes:.3f}')
print(f'Has isolated nodes: {data.has_isolated_nodes()}')
print(f'Has self-loops: {data.has_self_loops()}')
print(f'Is undirected: {data.is_undirected()}')

可以看出,该图大约有19717个节点。虽然这个数量的节点应该可以轻松地放入GPU内存,但它仍然是一个很好的例子,可以展示如何在PyTorch Geometric中扩展GNN。
Cluster-GCN的工作原理是首先基于图划分算法将图划分为子图。因此,GNN被限制为仅在其特定子图内进行卷积,从而省略了邻域爆炸的问题。

然而,在对图进行分区后,会删除一些链接,这可能会由于有偏差的估计而限制模型的性能。为了解决这个问题,Cluster-GCN还将类别之间的连接合并到一个小批量中,这导致了以下随机划分方案:

这里,颜色表示每批维护的邻接信息(对于每个epoch可能不同)。PyTorch Geometric提供了Cluster-GCN算法的两阶段实现:
ClusterData将一个Data对象转换为包含num_parts分区的子图的数据集。- 给定一个用户定义的
batch_size,ClusterLoader实现随机划分方案以创建小批量。
然后,制作小批量的程序如下:
from torch_geometric.loader import ClusterData, ClusterLoadertorch.manual_seed(12345)
cluster_data = ClusterData(data, num_parts=128) # 1. Create subgraphs.
train_loader = ClusterLoader(cluster_data, batch_size=32, shuffle=True) # 2. Stochastic partioning scheme.print()
total_num_nodes = 0
for step, sub_data in enumerate(train_loader):print(f'Step {step + 1}:')print('=======')print(f'Number of nodes in the current batch: {sub_data.num_nodes}')print(sub_data)print()total_num_nodes += sub_data.num_nodesprint(f'Iterated over {total_num_nodes} of {data.num_nodes} nodes!')

在这里,我们将初始图划分为128个分区,并使用32个子图的batch_size来形成mini-batches(每个epoch4批)。正如我们所看到的,在一个epoch之后,每个节点都被精确地看到了一次。
Cluster-GCN的伟大之处在于它不会使GNN模型的实现复杂化。我们构造如下一个简单模型:

这种图神经网络的训练与用于图分类任务的图神经网络训练非常相似。我们现在不再以全批处理的方式对图进行操作,而是对每个小批进行迭代,并相互独立地优化每个批:
model = GCN(hidden_channels=16)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
criterion = torch.nn.CrossEntropyLoss()def train():model.train()for sub_data in train_loader: # Iterate over each mini-batch.out = model(sub_data.x, sub_data.edge_index) # Perform a single forward pass.loss = criterion(out[sub_data.train_mask], sub_data.y[sub_data.train_mask]) # Compute the loss solely based on the training nodes.loss.backward() # Derive gradients.optimizer.step() # Update parameters based on gradients.optimizer.zero_grad() # Clear gradients.def test():model.eval()out = model(data.x, data.edge_index)pred = out.argmax(dim=1) # Use the class with highest probability.accs = []for mask in [data.train_mask, data.val_mask, data.test_mask]:correct = pred[mask] == data.y[mask] # Check against ground-truth labels.accs.append(int(correct.sum()) / int(mask.sum())) # Derive ratio of correct predictions.return accsfor epoch in range(1, 51):loss = train()train_acc, val_acc, test_acc = test()print(f'Epoch: {epoch:03d}, Train: {train_acc:.4f}, Val Acc: {val_acc:.4f}, Test Acc: {test_acc:.4f}')

在本文中,我们向您介绍了一种将 scale GNNs to large graphs的方法,否则这些图将不适合GPU内存。
本文内容参考:PyG官网
相关文章:
4.将图神经网络应用于大规模图数据(Cluster-GCN)
到目前为止,我们已经为节点分类任务单独以全批方式训练了图神经网络。特别是,这意味着每个节点的隐藏表示都是并行计算的,并且可以在下一层中重复使用。 然而,一旦我们想在更大的图上操作,由于内存消耗爆炸,…...

pymongo更新数据
使用 PyMongo,可以通过以下步骤将查询到的记录进行更新: 下面是一个简单的示例代码片段,展示如何向名为users的集合中的所有文档添加一个新字段age。 import pymongo # 连接 MongoDB client pymongo.MongoClient("mongodb://localh…...
)
手机软件测试规范(含具体用例)
菜单基本功能测试规范一、短消息功能测试规范测试选项操作方法观察与判断结果创建、编辑短消息并发送书写短消息1、分别使用菜单或快捷方式进入书写短消息是否有异常; 2、输入0个字符,选择、输入号码发送,应成功; 3、输入1个中文…...

mysql having的用法
having的用法 having字句可以让我们筛选成组后的各种数据,where字句在聚合前先筛选记录,也就是说作用在group by和having字句前。而 having子句在聚合后对组记录进行筛选。我的理解就是真实表中没有此数据,这些数据是通过一些函数生存。 SQ…...
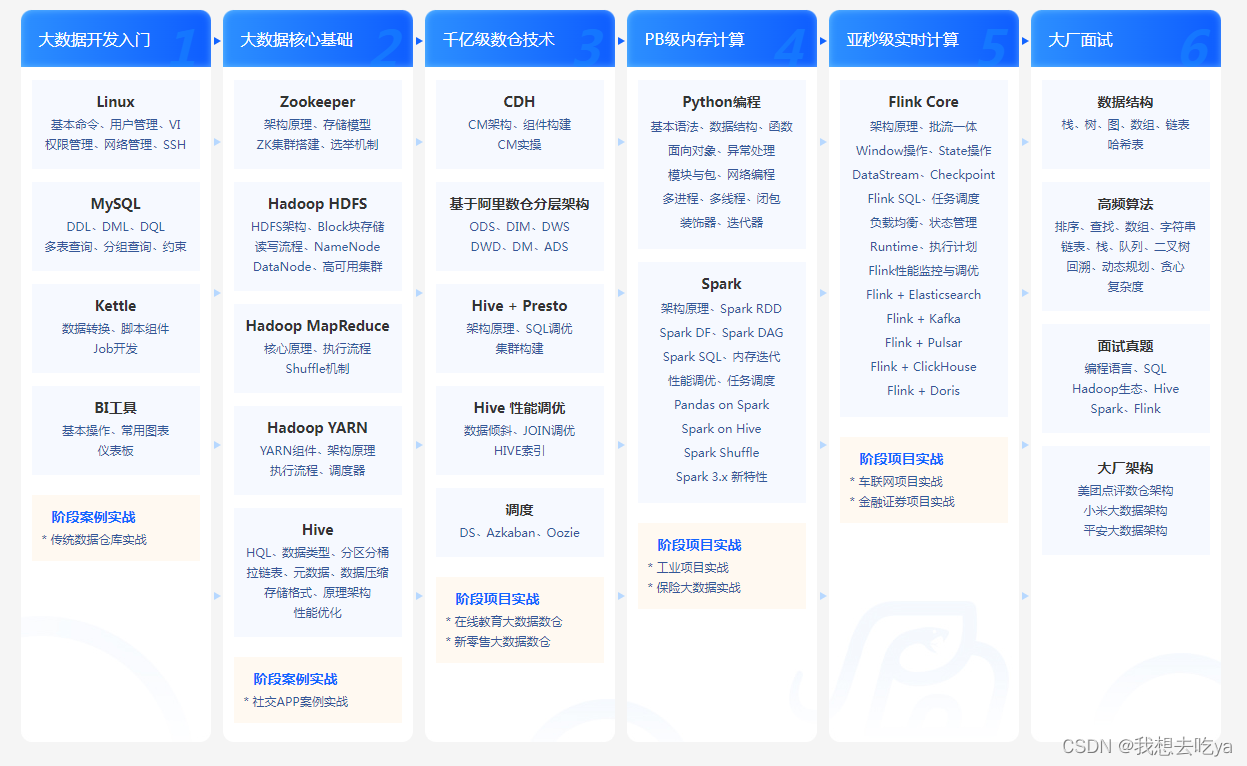
大数据需要学习哪些内容?
大数据技术的体系庞大且复杂,每年都会涌现出大量新的技术,目前大数据行业所涉及到的核心技术主要就是:数据采集、数据存储、数据清洗、数据查询分析和数据可视化。 Python 已成利器 在大数据领域中大放异彩 Python,成为职场人追求…...
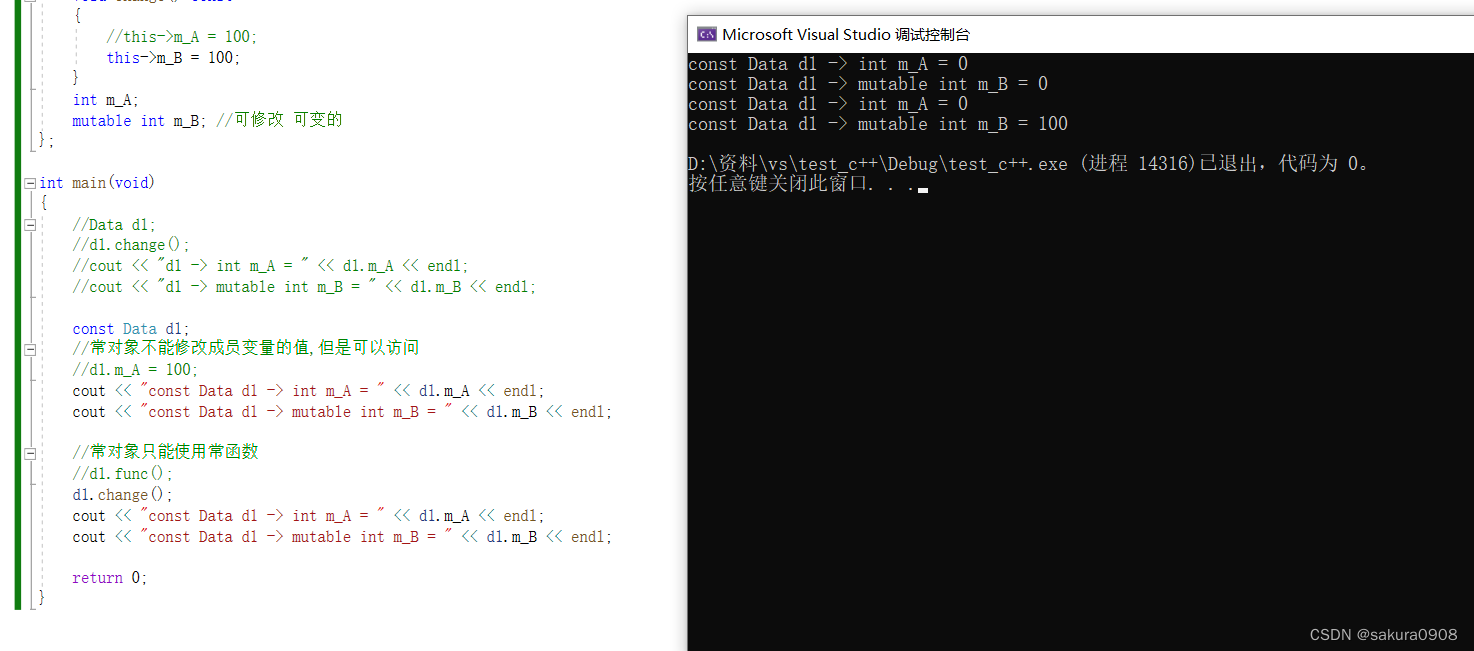
【c++】static和const修饰类的成员变量或成员函数
目录 1、静态成员变量 2、静态成员函数 3、常函数 4、常对象 当我们使用c的关键字static修饰类中的成员变量和成员函数的时候,此时的成员变量和成员函数被称为静态成员。 静态成员包含: 静态成员变量静态成员函数 1、静态成员变量 静态成员变量有…...
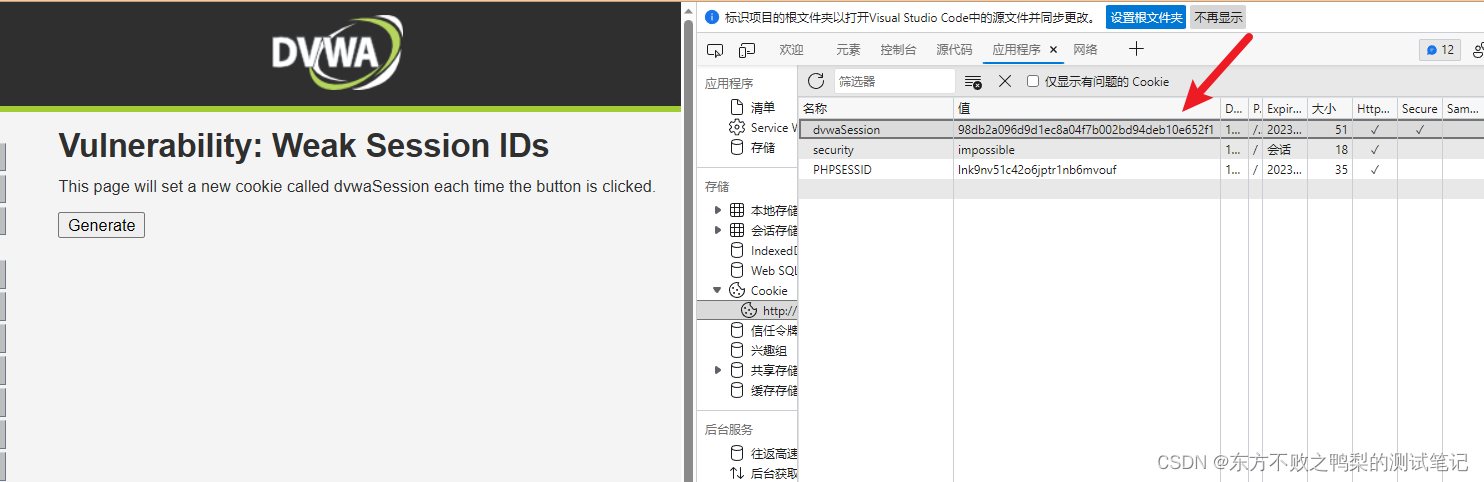
DVWA-9.Weak Session IDs
大约 了解会话 ID 通常是在登录后以特定用户身份访问站点所需的唯一内容,如果能够计算或轻松猜测该会话 ID,则攻击者将有一种简单的方法来访问用户帐户,而无需暴力破解密码或查找其他漏洞,例如跨站点脚本。 目的 该模块使用四种…...
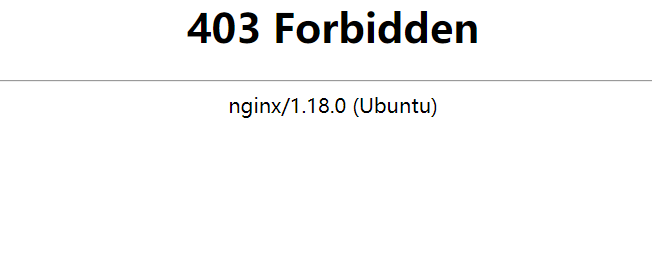
Bug序列——容器内给/root目录777权限后无法使用ssh免密登录
Linux——创建容器并将本地调试完全的前后端分离项目打包上传docker运行_北岭山脚鼠鼠的博客-CSDN博客 接着上一篇文章结尾出现403错误时通过赋予/root目录以777权限解决403错误。 chmod 777 /root 现在又出现新的问题,远程ssh无法免密登录了,即使通过…...

华为OD机试真题 JavaScript 实现【服务中心选址】【2023Q1 100分 】
一、题目描述 一个快递公司希望在一条街道建立新的服务中心。公司统计了该街道中所有区域在地图上的位置,并希望能够以此为依据为新的服务中心选址,使服务中心到所有区域的距离的总和最小。 给你一个数组 positions,其中 positions[i] [le…...

<Linux>《OpenSSH 客户端配置文件ssh_config详解》
《OpenSSH 客户端配置文件ssh_config详解》 1、 ssh获取配置数据顺序2、关键字2.1 Host2.2 Match2.3 AddKeysToAgent2.4 AddressFamily2.5 BatchMode2.6 BindAddress2.7 BindInterface2.8 CanonicalDomains2.9 CanonicalizeFallbackLocal2.10 CanonicalizeHostname2.11 Canonic…...

Linux内核中内存管理相关配置项的详细解析8
接前一篇文章:Linux内核中内存管理相关配置项的详细解析7 十一、Enable KSM for page merging 对应配置变量为:CONFIG_KSM。 此项只有选中和不选中两种状态,默认为选中。 内核源码详细解释为: Enable Kernel Samepage Merging:…...

深入浅出Vite:Vite打包与拆分
一、背景 在生产环境下,为了提高页面加载性能,构建工具一般将项目的代码打包(bundle)到一起,这样上线之后只需要请求少量的 JS 文件,大大减少 HTTP 请求。当然,Vite 也不例外,默认情况下 Vite 利用底层打包引擎 Rollup 来完成项目的模块打包。 某种意义上来说,对线上环…...
大数据ETL工具Kettle
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言最近公司在搞大数据数字化,有MES,CIM,WorkFlow等等N多的系统,不同的数据源DB,需要将这些不同的数据源DB里的数据进行整治统一…...
大学物理(上)-期末知识点结合习题复习(4)——质点运动学-动能定理 力做功 保守力与非保守力 势能 机械能守恒定律 完全弹性碰撞
目录 1.力做功 恒力作用下的功 变力的功 2.动能定理 3.保守力与非保守力 4.势能 引力的功与弹力的功 引力势能与弹性势能 5.保守力做功与势能的关系 6.机械能守恒定律 7.完全弹性碰撞 题1 题目描述 题解 题2 题目描述 题解 1.力做功 物体在力作用下移动做功…...
这两个小众的资源搜索工具其实很好用
01 小不点搜索是一个中国网络技术公司开发的网盘搜索引擎,该网站通过与多个主流网盘进行整合,为用户提供一种快速查找和下载文件的方式。小不点搜索因其高效性、便利性和实用性受到了广大用户的喜爱。 在技术实现上,小不点搜索拥有先进的搜…...
— 单例模式1)
Java设计模式(六)— 单例模式1
系列文章目录 单例模式介绍 单例模式之静态常量饿汉式 单例模式之静态代码饿汉式 单例模式之线程不安全懒汉式 文章目录 系列文章目录前言一、单例设计模式介绍二、单例设计模式八种方式三、单例—静态常量饿汉式1.静态常量饿汉式介绍2.静态常量饿汉式案例3.静态常量饿汉式优缺…...
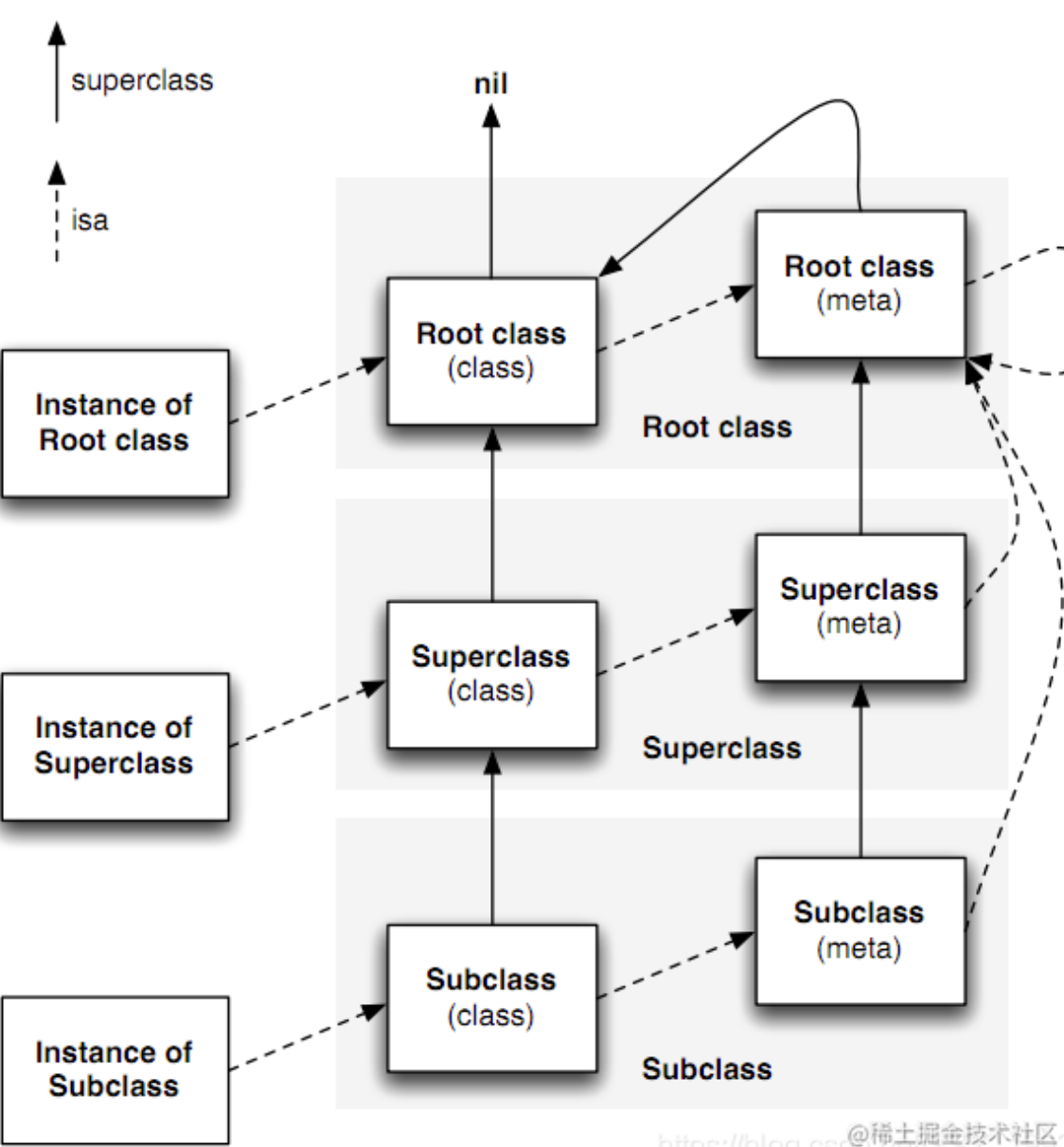
iOS -- isa指针
isa指针:isa指针是一个指向对象所属类或元类的指针。它决定了对象可以调用的方法和属性。isa指针在对象的结构中存在,并且在运行时会被自动设置。isa 指针,表示这个对象是一个什么类。而 Class 类型, 也就是 struct objc_class * …...

【SA8295P 源码分析】14 - Passthrough配置文件 /mnt/vm/images/linux-la.config 内容分析
系列文章汇总见:《【SA8295P 源码分析】00 - 系列文章链接汇总》 本文链接:《【SA8295P 源码分析】14 - Passthrough配置文件 /mnt/vm/images/linux-la.config 内容分析》 透传配置文件位于:qnx.git\apps\qnx_ap\target\hypervisor\gvm\ivi\la\linux-la.config 它是在QNX Ho…...
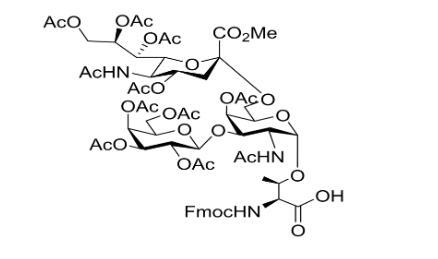
新型糖基化氨基酸:Fmoc-Thr((Ac4Galβ1-3)Me,Ac4Neu5Acα2-6AcGalNAcα)-OH,化学CAS号174783-92-7
●英文名:Fmoc-Thr((Ac4Galβ1-3)Me,Ac4Neu5Acα2-6AcGalNAcα)-OH ●外观以及性质: Fmoc-Thr((Ac4Galβ1-3)Me,Ac4Neu5Acα2-6AcGalNAcα)-OH中通过对蛋白进行复杂蛋白糖基化修饰,细胞产生了极大丰度的蛋白质类型;通过对各类糖基…...

网络安全(黑客)怎么自学?
最近看到很多问题,都是小白想要转行网络安全行业咨询学习路线和学习资料的,作为一个培训机构,学习路线和免费学习资料肯定是很多的。机构里面的不是顶级的黑阔大佬就是正在学习的同学,也用不上这些内容,每天都在某云盘…...

Windows安装安卓APK的终极指南:APK Installer免费工具完整教程
Windows安装安卓APK的终极指南:APK Installer免费工具完整教程 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为Windows电脑无法直接运行安卓应用而烦…...

AI和大模型——拟合
一、拟合 Fitting,中文翻译成拟合,这个翻译还是比较贴切的。怎么理解拟合呢?其实非常好理解,如果接受过九年义务教育,基本都有极限或微积分的概念。有没有想起过积分中用高低不等的小矩形来拼凑出曲线面的面积,那个过程…...

面试官追问LDA与PCA区别?用这张对比图+3个核心公式轻松讲明白
LDA与PCA本质区别:3个核心公式实战对比解析 当面试官要求你解释LDA和PCA的区别时,他们真正想考察的是什么?不是简单的概念复述,而是对两种降维技术底层逻辑的深刻理解。本文将用几何直觉、数学本质和代码实例,带你穿透…...

从习题到实战:掌握随机变量及其分布的5个核心场景
1. 从杯子分球看离散型随机变量 想象你面前有4个空杯子和3个乒乓球,随手把球扔进杯子里会发生什么?这个看似简单的游戏,其实是理解离散型随机变量的绝佳案例。X代表"杯子中球的最大个数",它可能取值为1、2、3——这就是…...
)
从B站视频到跑通代码:手把手复现大疆C板控制M2006电机的完整流程(STM32CubeMX + C610电调)
大疆C板驱动M2006电机全流程解析:从CubeMX配置到CAN通信实战 第一次拿到大疆RoboMaster C板时,看着官方文档和一堆外设确实有点无从下手。特别是当需要控制M2006这种高性能电机时,文档中的信息分散在不同章节,而社区里的完整教程又…...

从 ROS 到 Cognitive OS、Agentic OS:机器人操作系统与具身智能新时代
一、先搞懂:我们常说的机器人操作系统,到底是什么?在机器人领域,“操作系统” 从来不是单一概念,而是一套功能分层、各司其职的完整软件体系。不同层级定位不同、职责分明,实际项目中可组合部署、按需协作&…...

高校食堂学生信息录入系统开发实战|从0到1搭建简易Web系统
大家好~ 最近完成了一个适合高校课程作业、小型食堂管理使用的「大学食堂学生信息录入系统」,全程用纯前端技术实现,无需复杂后端环境,双击即可运行,今天就来分享一下开发全过程、功能细节和使用技巧,适合刚…...

PetaLinux下为ZynqMP配置GMII2RGMII驱动:从设备树修改到内核编译的完整指南
PetaLinux下为ZynqMP配置GMII2RGMII驱动的实战指南 在嵌入式Linux开发中,以太网驱动的配置往往是系统集成的关键环节。对于使用Xilinx ZynqMP芯片的开发者来说,当硬件设计采用GMII2RGMII IP核实现PL端以太网功能时,如何在PetaLinux环境下正确…...
)
用Python+CCA算法搞定SSVEP脑电信号识别:从理论到代码实战(附GitHub源码)
PythonCCA算法实现SSVEP脑电信号识别实战指南 在脑机接口研究领域,稳态视觉诱发电位(SSVEP)因其高信噪比和稳定特性成为热门研究方向。典型相关分析(CCA)作为SSVEP信号处理的经典算法,以其数学优雅和实现简…...

APK Installer技术解析与实践指南:Windows平台安卓应用部署的革命性方案
APK Installer技术解析与实践指南:Windows平台安卓应用部署的革命性方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在Windows系统上运行安卓应用一直是…...