【Python实战】Python采集王者皮肤图片
前言

我们上一篇介绍了,如何采集王者最低战力,本文就来给大家介绍如何采集王者皮肤,买不起皮肤,当个桌面壁纸挺好的。下面,我和大家介绍如何获取数据。
环境使用
- python 3.9
- pycharm
模块使用
- requests
模块介绍
- requests
requests是一个很实用的Python HTTP客户端库,爬虫和测试服务器响应数据时经常会用到,requests是Python语言的第三方的库,专门用于发送HTTP请求,使用起来比urllib简洁很多。
- parsel
parsel是一个python的第三方库,相当于css选择器+xpath+re。
parsel由scrapy团队开发,是将scrapy中的parsel独立抽取出来的,可以轻松解析html,xml内容,获取需要的数据。
相比于BeautifulSoup,xpath,parsel效率更高,使用更简单。
- re
re模块是python独有的匹配字符串的模块,该模块中提供的很多功能是基于正则表达式实现的,而正则表达式是对字符串进行模糊匹配,提取自己需要的字符串部分,他对所有的语言都通用。
- os
os 就是 “operating system” 的缩写,顾名思义,os模块提供的就是各种 Python 程序与操作系统进行交互的接口。通过使用 os 模块,一方面可以方便地与操作系统进行交互,另一方面也可以极大增强代码的可移植性。
- csv
它是一种文件格式,一般也被叫做逗号分隔值文件,可以使用 Excel 软件或者文本文档打开 。其中数据字段用半角逗号间隔(也可以使用其它字符),使用 Excel 打开时,逗号会被转换为分隔符。csv 文件是以纯文本形式存储了表格数据,并且在兼容各个操作系统。
模块安装问题:
- 如果安装python第三方模块:
win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
在pycharm中点击Terminal(终端) 输入安装命令
- 安装失败原因:
- 失败一: pip 不是内部命令
解决方法: 设置环境变量
- 失败二: 出现大量报红 (read time out)
解决方法: 因为是网络链接超时, 需要切换镜像源
清华:https://pypi.tuna.tsinghua.edu.cn/simple阿里云:https://mirrors.aliyun.com/pypi/simple/中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/华中理工大学:https://pypi.hustunique.com/山东理工大学:https://pypi.sdutlinux.org/豆瓣:https://pypi.douban.com/simple/例如:pip3 install -i https://pypi.doubanio.com/simple/ 模块名
- 失败三: cmd里面显示已经安装过了, 或者安装成功了, 但是在pycharm里面还是无法导入
解决方法: 可能安装了多个python版本 (anaconda 或者 python 安装一个即可) 卸载一个就好,或者你pycharm里面python解释器没有设置好。
代码实现
我们上一篇介绍了,如何采集王者最低战力,本文就来给大家介绍如何采集王者皮肤,买不起皮肤,当个桌面壁纸挺好的。下面,我和大家介绍如何获取数据。
确定网址
我们在对王者英雄的主页,进行了分析,我们发现,其网页地址相似,就差一个数字。
https://pvp.qq.com/web201605/herodetail/{ename}.shtml
我们可以把它当作为每个英雄的编号,我们可以从英雄列表获取编号,不过,这里我们直接请求第三方接口数据。
获取英雄编号
html_url ='https://www.sapi.run/hero/getHeroList.php'
datas = requests.get(html_url).json()['data']
for data in datas:ename = data['ename']cname = data['cname']print(ename,cname)
这段代码中,html_url 是一个 URL,指向一个 SAPI 的 Hero 列表页面。requests.get(html_url).json()['data'] 返回一个 JSON 对象,其中包含了 Hero 列表页面的数据。ename 和 cname 是 JSON 对象中的两个键值对,分别表示 Hero 的编号和名字。
在这段代码中,我们使用了一个 for 循环来遍历 JSON 对象中的每一个键值对,并打印出它们的值。这样就可以得到 Hero 列表页面中所有 Hero 的编号和名字。

获取皮肤名称
我们拿到每一个英雄的编号之后,我们就可以访问每一个英雄的主页,我们在其主页可以看到他们的英雄名称和他们的英雄皮肤的地址。我们先获取英雄皮肤的名称。
herodetail_url = f'https://pvp.qq.com/web201605/herodetail/{ename}.shtml'
print(herodetail_url)
res = requests.get(herodetail_url,headers=headers)
res.encoding = 'gbk'
# print(res.text)
pfs = re.findall('data-imgname="(.*?)"',res.text)[0]
pfs=pfs.split('|')
print(pfs)
这段代码中,herodetail_url 是一个 URL,指向一个 Hero 详细页面。requests.get(herodetail_url,headers=headers) 返回一个 JSON 对象,其中包含了 Hero 详细页面的数据。res.encoding = 'gbk' 设置了 JSON 对象的编码方式为 GBK。re.findall('data-imgname="(.*?)"',res.text)[0] 使用正则表达式匹配 Hero 详细页面中的英雄名称,并返回第一个匹配项。pfs 是匹配项的值,它是一个包含英雄名称的列表。

接下来,我们对字段进行处理。
for pf in pfs:pf = pf.split('&')[0]# print(pf)pf_list.append(pf)
print(len(pf_list))
print(pf_list)
我们得到了这样的数据。['正义爆轰', '地狱岩魂', '无尽征程', '寅虎·御盾'],到了这里,我们皮肤名字就获取下来了。
获取皮肤
pages = len(pfs)for page in range(1,pages+1):pf_url = f'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{ename}/{ename}-bigskin-{page}.jpg'pf_url_list.append(pf_url)
这段代码中,我们首先计算出 Hero 详细页面中图片的数量,然后使用 range 函数生成从 1 到 pages 的整数序列。接下来,我们使用一个循环来遍历这个序列,并将每个图片的 URL 添加到 pf_url_list 列表中。
最后,我们将 pf_url_list 列表中的所有 URL 连接起来,并将它们作为参数传递给 requests.get() 函数,以获取 Hero 详细页面的数据。
到这里,我们把所有皮肤的地址获取了下来。
保存数据
for name,url in zip(pf_list,pf_url_list):path = f'.//皮肤//{cname}//'# print(path)if not os.path.exists(path):os.mkdir(path)# print(cname,name,url)pf_save = requests.get(url,headers=headers)print(f"path + '{name}.jpg'")with open(path + f'{name}.jpg', 'wb') as f:f.write(pf_save.content)
这段代码中,我们首先将 pf_list 和 pf_url_list 两个列表进行了 zip 操作,并将结果存储在 pf_list 和 pf_url_list 两个变量中。然后,我们使用 os.path.exists() 函数来检查 path 目录是否存在,如果不存在,则使用 os.mkdir() 函数创建该目录。接下来,我们使用 requests.get() 函数来获取 pf_url_list 列表中的每个 URL,并将它们作为参数传递给 requests.get() 函数,以获取 pf_list 列表中的每个 URL。
最后,我们使用 with open() 语句打开 path + '{name}.jpg' 文件,并将 pf_save.content 写入该文件中。这样就可以将 pf_list 和 pf_url_list 中的每个 URL 保存到 path + '{name}.jpg' 文件中。
全部源码
import re
import os
import requestsf = '皮肤\\'
if not os.path.exists(f):os.mkdir(f)pf_list = []
pf_url_list = []
html_url ='https://www.sapi.run/hero/getHeroList.php'
datas = requests.get(html_url).json()['data']
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
for data in datas:ename = data['ename']cname = data['cname']print(ename,cname)herodetail_url = f'https://pvp.qq.com/web201605/herodetail/{ename}.shtml'# print(herodetail_url)res = requests.get(herodetail_url,headers=headers)res.encoding = 'gbk'pfs = re.findall('data-imgname="(.*?)"',res.text)[0]pfs=pfs.split('|')# 获取英雄皮肤名称。pages = len(pfs) for pf in pfs:pf = pf.split('&')[0]# print(pf)pf_list.append(pf)for page in range(1,pages+1):pf_url = f'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{ename}/{ename}-bigskin-{page}.jpg'pf_url_list.append(pf_url)for name,url in zip(pf_list,pf_url_list):pf_save = requests.get(url,headers=headers)with open(f'皮肤\\{name}.jpg', 'wb') as f:f.write(pf_save.content)
总结
这是一篇关于如何采集王者皮肤的文章,介绍了如何从英雄列表获取编号,并使用正则表达式从网页地址中提取英雄编号和名字。此外,还介绍了如何使用 requests.get() 函数从网页中获取数据,以及如何将数据保存到文件中。

相关文章:
【Python实战】Python采集王者皮肤图片
前言 我们上一篇介绍了,如何采集王者最低战力,本文就来给大家介绍如何采集王者皮肤,买不起皮肤,当个桌面壁纸挺好的。下面,我和大家介绍如何获取数据。 环境使用 python 3.9pycharm 模块使用 requests 模块介绍 re…...

很详细的Django开发入门详解(图文并茂)
1.Django概述 Django是一个开放源代码的Web应用框架,由Python写成。采用了MTV的框架模式,即模型M,视图V和模版T。 Django 框架的核心组件有: 用于创建模型的对象关系映射;为最终用户设计较好的管理界面;…...

Ansible 部署
ansible 自动化运维工具,可以实现批量管理多台(成百上千)主机,应用级别的跨主机编排工具 特性: 无agent的存在,不要在被控制节点上安装客户端应用 通过ssh协议与被控制节点通信 基于模块工作的,…...
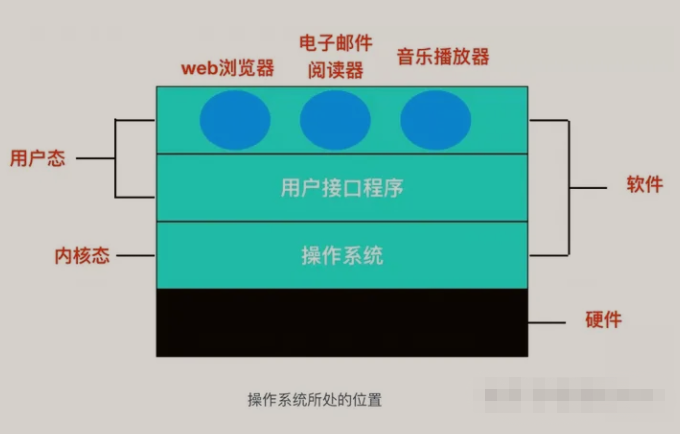
【操作系统】计算机操作系统知识点总结
文章目录 前言一、操作系统的概念与发展二、操作系统的结构与功能1、操作系统的结构2、操作系统的功能 三、进程管理1、进程2、进程的创建3、进程管理的实现4、进程控制块 四、内存管理1、内存2、内存管理3、内存管理的实现 五、文件系统1、文件系统2、文件系统的主要任务3、文…...

springmvc整合thymeleaf
概述 Thymeleaf提供了一组Spring集成,使您可以将其用作Spring MVC应用程序中JSP的全功能替代品。 这些集成将使您能够: Controller像使用JSP一样,将Spring MVC 对象中的映射方法转发到Thymeleaf管理的模板。在模板中使用Spring表达式语言&…...

Redis 内存管理机制
Redis作为一个内存数据库,内存资源非常珍贵。因此,Redis引入了3种内存管理机制来释放不必要的内存,包括定期删除、惰性删除和内存淘汰机制。 定期删除 定期删除是Redis内存管理机制的一种,它用于删除过期的键值对。Redis每隔 10…...
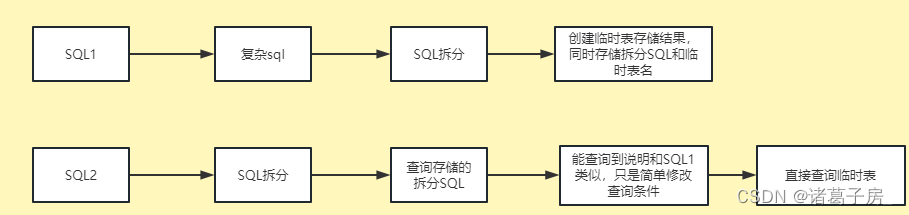
Apache Zeppelin系列教程第九篇——Zeppelin NoteBook数据缓存
背景 在使用Zeppelin JDBC Intercepter 对于Hive 数据进行查询过程中,如果遇到非常复杂的sql,查询效率是非常慢 比如: select dt,count(*) from table group by dt做过数据开发的同学都知道,在hive sql查询过程中,hive…...

用代码实现一个简单计算器
作者主页:paper jie的博客_CSDN博客-C语言,算法详解领域博主 本文作者:大家好,我是paper jie,感谢你阅读本文,欢迎一建三连哦。 本文录入于《C语言》专栏,本专栏是针对于大学生,编程小白精心打造…...

运维圣经:挖矿木马应急响应指南
目录 挖矿木马简介 挖矿流程 挖矿木马应急响应 一. 隔离被感染主机 二. 确定挖矿进程 三. 挖矿木马清除 1、阻断矿池地址的连接 2、清除挖矿定时任务、启动项等 3、禁用可疑用户 4、定位挖矿木马文件的位置并删除 5、全盘杀毒、加固 挖矿木马简介 挖矿:…...
【Flutter】Flutter 如何获取安装来源信息
文章目录 一、 前言二、 安装来源信息的基本概念1. 什么是安装来源信息2. 为什么我们需要获取安装来源信息 三、 如何在 Flutter 中获取安装来源信息1. 准备工作2. 安装必要的依赖库3. 编写代码获取安装来源信息 四、 完整示例代码五、总结 一、 前言 在这篇文章中,…...
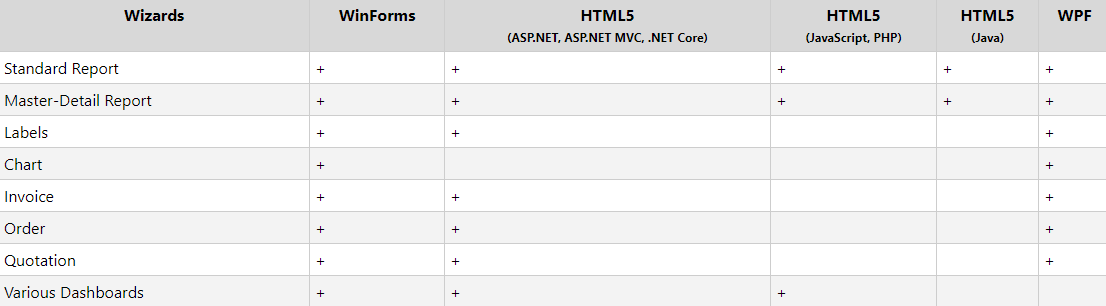
Stimulsoft Reports用户手册:Report Designer介绍
Stimulsoft Reports.Net是一个基于.NET框架的报表生成器,能够帮助你创建结构、功能丰富的报表。StimulReport.Net 的报表设计器不仅界面友好,而且使用便捷,能够让你轻松创建所有报表;该报表设计器在报表设计过程中以及报表运行的过…...
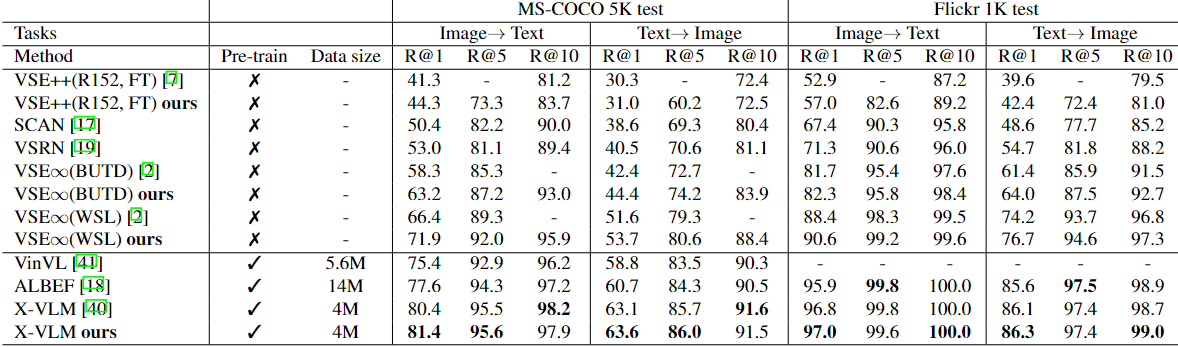
跨模态检索论文阅读:Dissecting Deep Metric Learning Losses for Image-Text Retrieval(GOAL)
Dissecting Deep Metric Learning Losses for Image-Text Retrieval 剖析图像文本检索中的深度度量学习损失 2022.10 视觉语义嵌入(VSE)是图像-文本检索中的一种流行的应用方法,它通过学习图像和语言模式之间的联合嵌入空间来保留语义的相似性…...

贪心算法part5 | ● 435. 无重叠区间 ● 763.划分字母区间 ● 56. 合并区间
文章目录 435. 无重叠区间思路思路代码困难 763.划分字母区间思路官方题解代码困难 56. 合并区间思路思路代码 今日收获 435. 无重叠区间 思路 重叠问题都需要先排好序,再贪心 思路代码 func eraseOverlapIntervals(intervals [][]int) int {sort.Slice(interva…...
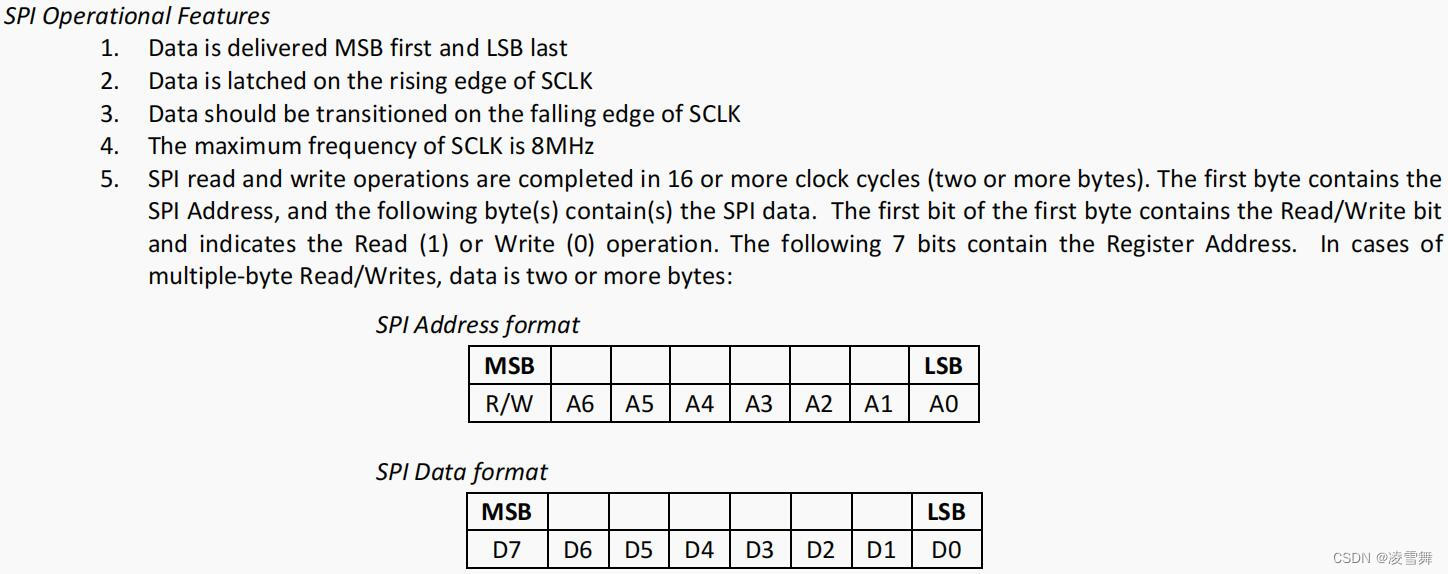
IMX6ULL裸机篇之SPI实验-ICM20608代码实现
一. SPI 实验 SPI实验:学习如何使用 I.MX6U 的 SPI 接口来驱动 ICM-20608,读取 ICM-20608 的六轴数据。 本文学习 SPI通信实验中,涉及从设备的 SPI代码编写。 之前学习了 SPI 主控芯片代码的编写,如下所示: IMX6ULL…...

51单片机读取DS18B20温度传感器
1.首先我们知道DS18B20是单总线协议,只有一根数据线。所以Data数据线即使发送端又是接收端,同时DS18B20内部接了弱上拉电阻(如图一所示),数据线默认为高电平。有了这些概念,我们就能进行下一步。 图一&…...

set/map学习
我们要开始学习map和set的使用,虽然使用更加复杂,但是STL整体的设计,本身就具有很强的前瞻性和延续性,比如说迭代器等,我们顺着文档来看。这也是除了vector之外最重要的容器,当然还有unordered_map 和 unor…...
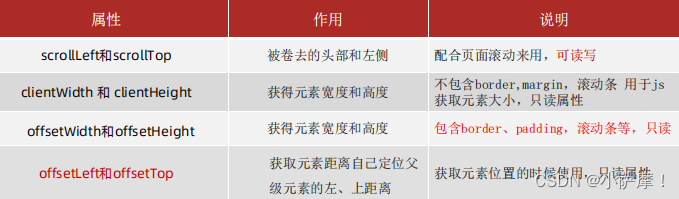
JavaScript Web APIs学习总结
以后声明变量我们有限使用哪一个? const 有了变量先给const,如果发现它后面是要被修改的,再改为let 为什么const声明的对象可以修改里面的属性? 因为对象是引用类型,里面存储的是地址,只要地址不变&…...

萤石摄像头RTSP流获取(黑屏解决)
前言 在获取萤石摄像头RTSP视频流时,视频流获取不成功,黑屏并且一直显示缓冲中。下面对获取过程中查阅的资料和解决方案做一下汇总。 打开RTSP 在萤石云视频APP中打开RTSP,【我的】-【工具】-【局域网设备预览】-【开始扫描】-【选择摄像头…...
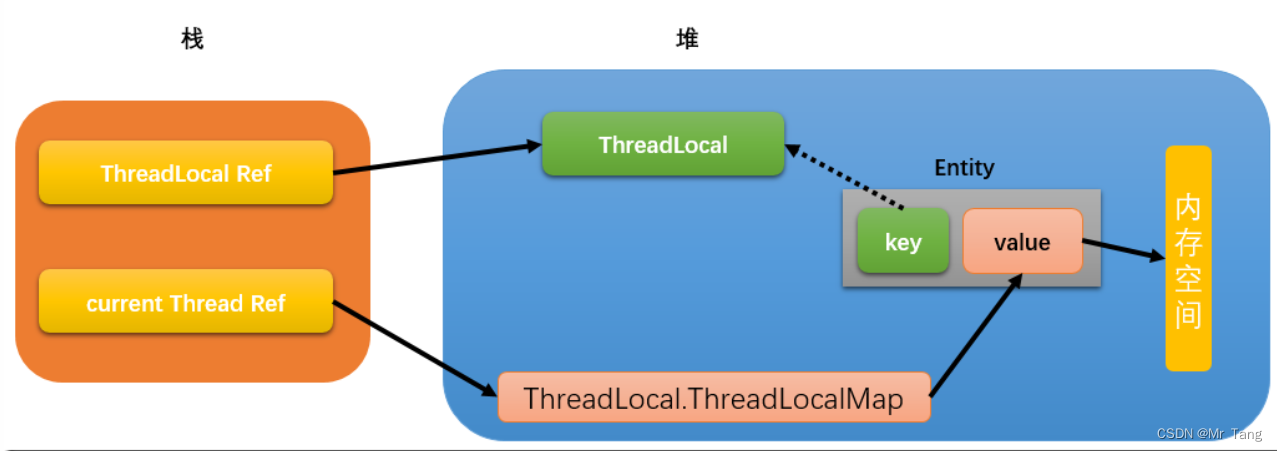
ThreadLocal引发的内存泄漏分析
预备知识(引用) Object o new Object(); 这个o,我们可以称之为对象引用,而new Object()我们可以称之为在内存中产生了一个对象实例。 当写下 onull时,只是表示o不再指向堆中object的对象实例,不代表这个…...

银行数据治理:数据质量管理实践
现代商业银行日常经营活动中积累了大量数据,这些数据除了支持银行前台业务流程运转之外,越来越多地被用于决策支持领域,风险控制、产品定价、绩效考核等管理决策过程也都需要大量高质量数据支持。银行日常经营决策过程的背后,实质…...

手机跑多模态也能快到飞起!面壁MiniCPM-V 4.6开源
大模型技术正快步从云端机房走入普通人的智能手机,让移动设备直接处理复杂的图文与视频任务成为现实。面壁智能最新开源的一款多模态模型,以极低的算力成本,超低的首Token延迟,成功打通当前三大主流手机操作系统。MiniCPM-V 4.6专…...

Axure RP 多版本中文语言包技术解析:从键值对到专业本地化的架构演进
Axure RP 多版本中文语言包技术解析:从键值对到专业本地化的架构演进 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn …...

RAG提示工程失效?NotebookLM上下文压缩机制深度拆解,3类文档结构适配公式即拿即用
更多请点击: https://intelliparadigm.com 第一章:RAG提示工程失效的底层归因与NotebookLM破局逻辑 RAG(Retrieval-Augmented Generation)系统在真实场景中频繁遭遇“提示失焦”现象——检索结果与生成目标语义脱节,导…...

NotebookLM笔记整理实战指南:5步打造自动关联知识图谱的智能笔记系统
更多请点击: https://intelliparadigm.com 第一章:NotebookLM笔记整理实战指南:5步打造自动关联知识图谱的智能笔记系统 NotebookLM 是 Google 推出的面向研究者与开发者的第一方 AI 笔记工具,其核心能力在于基于用户上传文档构建…...

AgentDock:构建可控AI智能体的开源框架与工程实践
1. 项目概述:构建可控的智能体应用框架如果你正在寻找一个既能利用大语言模型(LLM)的创造力,又能确保关键业务流程稳定可靠的开发框架,那么 AgentDock 的出现可能正合你意。我最近深度体验了这个开源项目,它…...

5分钟掌握Windows安装Android应用的终极方案
5分钟掌握Windows安装Android应用的终极方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾想过在Windows电脑上直接运行Android应用,却苦于复杂的…...

建筑消防防火分区专用钢质卷帘门
在现代建筑消防设计体系中,防火分区的科学划分与有效分隔,是控制火灾蔓延、减少人员伤亡与财产损失的核心环节。建筑消防防火分区专用钢质卷帘门,作为固定式防火分隔的重要配套设施,凭借稳定的耐火性能、可靠的启闭功能与强适配性…...

WinMerge过滤器进阶:从基础规则到实战场景配置
1. WinMerge过滤器入门:从零开始理解规则配置 WinMerge作为一款老牌开源文件对比工具,其过滤器功能常常被低估。很多开发者只是用它来排除版本控制目录,但实际上它能做的远不止这些。我第一次接触WinMerge过滤器是在处理一个Java项目时&#…...

龙芯2k0300 - 智能车走马观碑组VL53L0X驱动移植
---------------------------------------------------------------------------------------------------------------------------- 开发板 :久久派开发板eMMC :8GBDDR4 :512MBu-boot :u-boot 2022.04linux :6.12roo…...
)
FreeRTOS移植避坑指南:当你的芯片不在官方支持列表时(以S3C2440/GCC为例)
FreeRTOS移植方法论:非官方支持芯片的通用适配策略 当你在开源社区下载FreeRTOS压缩包时,是否注意到portable目录下那些以芯片型号命名的文件夹?ARM_CM3、ARM_CM4F、MSP430X——这些官方支持的平台享受着"开箱即用"的便利。但当你手…...