linux-2.6.22.6内核网卡驱动框架分析
网络协议分为很多层,而驱动这层对应于实际的物理网卡部分,这也是最底层的部分,以cs89x0.c这个驱动程序为例来分析下网卡驱动程序框架。
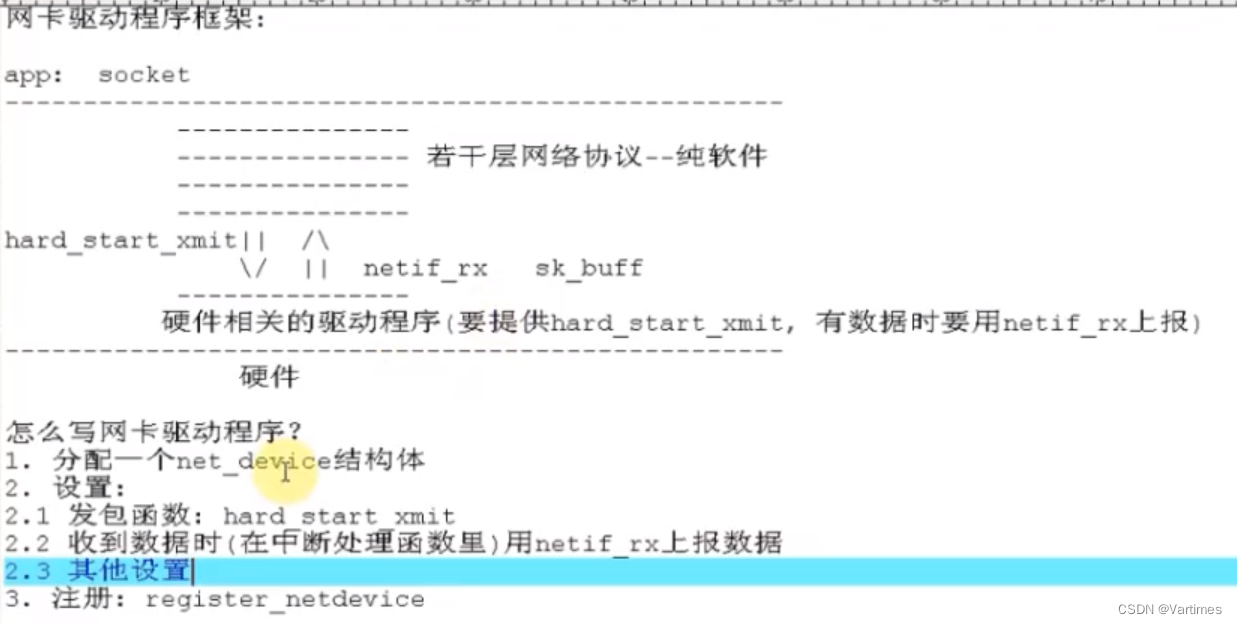
正常开发一个驱动程序时,一般都遵循以下几个步骤:
1.分配某个结构体
2.设置该结构体
3.注册
4.硬件相关操作
首先分析cs89x0.c的入口函数
int __init init_module(void)
{struct net_device *dev = alloc_etherdev(sizeof(struct net_local));struct net_local *lp;int ret = 0;#if defined(CONFIG_ARCH_S3C2410)unsigned int oldval_bwscon; /* 用来保存BWSCON寄存器的值 */unsigned int oldval_bankcon3; /* 用来保存S3C2410_BANKCON3寄存器的值 */
#endif#if DEBUGGINGnet_debug = debug;
#elsedebug = 0;
#endifif (!dev)return -ENOMEM;#if defined(CONFIG_ARCH_S3C2410)// 将CS8900A的物理地址转换为虚拟地址,0x300是CS8900A内部的IO空间的偏移地址dev->base_addr = io = (unsigned int)ioremap(S3C24XX_PA_CS8900, SZ_1M) + 0x300;dev->irq = irq = cs8900_irq_map[0]; /* 中断号 *//* 设置默认MAC地址,* MAC地址可以由CS8900A外接的EEPROM设定(有些单板没接EEPROM),* 或者启动系统后使用ifconfig修改*/dev->dev_addr[0] = 0x08;dev->dev_addr[1] = 0x89;dev->dev_addr[2] = 0x89;dev->dev_addr[3] = 0x89;dev->dev_addr[4] = 0x89;dev->dev_addr[5] = 0x89;/* 设置Bank3: 总线宽度为16, 使能nWAIT, 使能UB/LB。by www.100ask.net */oldval_bwscon = *((volatile unsigned int *)S3C2410_BWSCON);*((volatile unsigned int *)S3C2410_BWSCON) = (oldval_bwscon & ~(3<<12)) \| S3C2410_BWSCON_DW3_16 | S3C2410_BWSCON_WS3 | S3C2410_BWSCON_ST3;/* 设置BANK3的时间参数, by www.100ask.net */oldval_bankcon3 = *((volatile unsigned int *)S3C2410_BANKCON3);*((volatile unsigned int *)S3C2410_BANKCON3) = 0x1f7c;
#elsedev->irq = irq;dev->base_addr = io;
#endiflp = netdev_priv(dev);#if ALLOW_DMAif (use_dma) {lp->use_dma = use_dma;lp->dma = dma;lp->dmasize = dmasize;}
#endifspin_lock_init(&lp->lock);/* boy, they'd better get these right */if (!strcmp(media, "rj45"))lp->adapter_cnf = A_CNF_MEDIA_10B_T | A_CNF_10B_T;else if (!strcmp(media, "aui"))lp->adapter_cnf = A_CNF_MEDIA_AUI | A_CNF_AUI;else if (!strcmp(media, "bnc"))lp->adapter_cnf = A_CNF_MEDIA_10B_2 | A_CNF_10B_2;elselp->adapter_cnf = A_CNF_MEDIA_10B_T | A_CNF_10B_T;if (duplex==-1)lp->auto_neg_cnf = AUTO_NEG_ENABLE;if (io == 0) {printk(KERN_ERR "cs89x0.c: Module autoprobing not allowed.\n");printk(KERN_ERR "cs89x0.c: Append io=0xNNN\n");ret = -EPERM;goto out;} else if (io <= 0x1ff) {ret = -ENXIO;goto out;}#if ALLOW_DMAif (use_dma && dmasize != 16 && dmasize != 64) {printk(KERN_ERR "cs89x0.c: dma size must be either 16K or 64K, not %dK\n", dmasize);ret = -EPERM;goto out;}
#endifret = cs89x0_probe1(dev, io, 1);if (ret)goto out;dev_cs89x0 = dev;return 0;
out:
#if defined(CONFIG_ARCH_S3C2410)iounmap(dev->base_addr);/* 恢复寄存器原来的值 */*((volatile unsigned int *)S3C2410_BWSCON) = oldval_bwscon;*((volatile unsigned int *)S3C2410_BANKCON3) = oldval_bankcon3;
#endif free_netdev(dev);return ret;
}
入口函数里,首先分配了net_device 结构体,然后对该结构体进行进行填充,最后调用cs89x0_probe1进行下一步处理。
cs89x0_probe1(struct net_device *dev, int ioaddr, int modular)
{
.............dev->open = net_open;dev->stop = net_close;dev->tx_timeout = net_timeout;dev->watchdog_timeo = HZ;**dev->hard_start_xmit = net_send_packet;**dev->get_stats = net_get_stats;dev->set_multicast_list = set_multicast_list;dev->set_mac_address = set_mac_address;
.....
.....retval = register_netdev(dev);}
cs89x0_probe1里又进一步对net_device 进行了填充,其中hard_start_xmit 就是发送数据函数,然后通过register_netdev进行注册。
进一步查看net_send_packet
static int net_send_packet(struct sk_buff *skb, struct net_device *dev)
{struct net_local *lp = netdev_priv(dev);if (net_debug > 3) {printk("%s: sent %d byte packet of type %x\n",dev->name, skb->len,(skb->data[ETH_ALEN+ETH_ALEN] << 8) | skb->data[ETH_ALEN+ETH_ALEN+1]);}/* keep the upload from being interrupted, since weask the chip to start transmitting before thewhole packet has been completely uploaded. */spin_lock_irq(&lp->lock);netif_stop_queue(dev);/* initiate a transmit sequence */writeword(dev->base_addr, TX_CMD_PORT, lp->send_cmd);writeword(dev->base_addr, TX_LEN_PORT, skb->len);/* Test to see if the chip has allocated memory for the packet */if ((readreg(dev, PP_BusST) & READY_FOR_TX_NOW) == 0) {/** Gasp! It hasn't. But that shouldn't happen since* we're waiting for TxOk, so return 1 and requeue this packet.*/spin_unlock_irq(&lp->lock);if (net_debug) printk("cs89x0: Tx buffer not free!\n");return 1;}/* Write the contents of the packet */writewords(dev->base_addr, TX_FRAME_PORT,skb->data,(skb->len+1) >>1);spin_unlock_irq(&lp->lock);lp->stats.tx_bytes += skb->len;dev->trans_start = jiffies;dev_kfree_skb (skb);/** We DO NOT call netif_wake_queue() here.* We also DO NOT call netif_start_queue().** Either of these would cause another bottom half run through* net_send_packet() before this packet has fully gone out. That causes* us to hit the "Gasp!" above and the send is rescheduled. it runs like* a dog. We just return and wait for the Tx completion interrupt handler* to restart the netdevice layer*/return 0;
}
net_send_packet里用到了sk_buff 这个结构体,sk_buff 就是数据的载体,net_send_packet里通过sk_buff 发送了数据,那数据又是如何接受的呢,其实是通过中断接受数据的,net_interrupt处理如下:
static irqreturn_t net_interrupt(int irq, void *dev_id)
{struct net_device *dev = dev_id;struct net_local *lp;int ioaddr, status;int handled = 0;ioaddr = dev->base_addr;lp = netdev_priv(dev);/* we MUST read all the events out of the ISQ, otherwise we'll neverget interrupted again. As a consequence, we can't have any limiton the number of times we loop in the interrupt handler. Thehardware guarantees that eventually we'll run out of events. Ofcourse, if you're on a slow machine, and packets are arrivingfaster than you can read them off, you're screwed. Hasta lavista, baby! */while ((status = readword(dev->base_addr, ISQ_PORT))) {if (net_debug > 4)printk("%s: event=%04x\n", dev->name, status);handled = 1;switch(status & ISQ_EVENT_MASK) {case ISQ_RECEIVER_EVENT:/* Got a packet(s). */net_rx(dev);break;case ISQ_TRANSMITTER_EVENT:lp->stats.tx_packets++;netif_wake_queue(dev); /* Inform upper layers. */if ((status & ( TX_OK |TX_LOST_CRS |TX_SQE_ERROR |TX_LATE_COL |TX_16_COL)) != TX_OK) {if ((status & TX_OK) == 0) lp->stats.tx_errors++;if (status & TX_LOST_CRS) lp->stats.tx_carrier_errors++;if (status & TX_SQE_ERROR) lp->stats.tx_heartbeat_errors++;if (status & TX_LATE_COL) lp->stats.tx_window_errors++;if (status & TX_16_COL) lp->stats.tx_aborted_errors++;}break;case ISQ_BUFFER_EVENT:if (status & READY_FOR_TX) {/* we tried to transmit a packet earlier,but inexplicably ran out of buffers.That shouldn't happen since we only everload one packet. Shrug. Do the rightthing anyway. */netif_wake_queue(dev); /* Inform upper layers. */}if (status & TX_UNDERRUN) {if (net_debug > 0) printk("%s: transmit underrun\n", dev->name);lp->send_underrun++;if (lp->send_underrun == 3) lp->send_cmd = TX_AFTER_381;else if (lp->send_underrun == 6) lp->send_cmd = TX_AFTER_ALL;/* transmit cycle is done, althoughframe wasn't transmitted - thisavoids having to wait for the upperlayers to timeout on us, in theevent of a tx underrun */netif_wake_queue(dev); /* Inform upper layers. */}
#if ALLOW_DMAif (lp->use_dma && (status & RX_DMA)) {int count = readreg(dev, PP_DmaFrameCnt);while(count) {if (net_debug > 5)printk("%s: receiving %d DMA frames\n", dev->name, count);if (net_debug > 2 && count >1)printk("%s: receiving %d DMA frames\n", dev->name, count);dma_rx(dev);if (--count == 0)count = readreg(dev, PP_DmaFrameCnt);if (net_debug > 2 && count > 0)printk("%s: continuing with %d DMA frames\n", dev->name, count);}}
#endifbreak;case ISQ_RX_MISS_EVENT:lp->stats.rx_missed_errors += (status >>6);break;case ISQ_TX_COL_EVENT:lp->stats.collisions += (status >>6);break;}}return IRQ_RETVAL(handled);
}
net_interrupt里又调用net_rx(dev);进行处理
net_rx(struct net_device *dev)
{struct net_local *lp = netdev_priv(dev);struct sk_buff *skb;int status, length;int ioaddr = dev->base_addr;status = readword(ioaddr, RX_FRAME_PORT);length = readword(ioaddr, RX_FRAME_PORT);if ((status & RX_OK) == 0) {count_rx_errors(status, lp);return;}/* Malloc up new buffer. */skb = dev_alloc_skb(length + 2);if (skb == NULL) {
#if 0 /* Again, this seems a cruel thing to do */printk(KERN_WARNING "%s: Memory squeeze, dropping packet.\n", dev->name);
#endiflp->stats.rx_dropped++;return;}skb_reserve(skb, 2); /* longword align L3 header */readwords(ioaddr, RX_FRAME_PORT, skb_put(skb, length), length >> 1);if (length & 1)skb->data[length-1] = readword(ioaddr, RX_FRAME_PORT);if (net_debug > 3) {printk( "%s: received %d byte packet of type %x\n",dev->name, length,(skb->data[ETH_ALEN+ETH_ALEN] << 8) | skb->data[ETH_ALEN+ETH_ALEN+1]);}skb->protocol=eth_type_trans(skb,dev);netif_rx(skb);dev->last_rx = jiffies;lp->stats.rx_packets++;lp->stats.rx_bytes += length;
}
net_rx里也会构造一个sk_buff 结构体,然后调用netif_rx(skb);进行发包。
总结:发送数据和接受数据是通过hard_start_xmit 和netif_rx完成的,而数据的载体都是sk_buff 结构体。
相关文章:
linux-2.6.22.6内核网卡驱动框架分析
网络协议分为很多层,而驱动这层对应于实际的物理网卡部分,这也是最底层的部分,以cs89x0.c这个驱动程序为例来分析下网卡驱动程序框架。 正常开发一个驱动程序时,一般都遵循以下几个步骤: 1.分配某个结构体 2.设置该结…...
机器学习7:特征工程
在传统的软件工程中,核心是代码,然而,在机器学习项目中,重点则是特征——也就是说,开发人员优化模型的方法之一是增加和改进其输入特征。很多时候,优化特征比优化模型带来的增益要大得多。 笔者曾经参与过一…...

coverage代码覆盖率测试介绍
coverage代码覆盖率测试介绍 背景知识补充 1、什么是覆盖率 测试过程中提到的覆盖率,指的是已测试的内容,占待测内容的百分比,在一定程度上反应测试的完整程度。 覆盖率有可以根据要衡量的对象细分很多种,比如接口覆盖率、分支…...
使用 Debian、Docker 和 Nginx 部署 Web 应用
前言 本文将介绍基于 Debian 的系统上使用 Docker 和 Nginx 进行 Web 应用部署的过程。着重介绍了 Debian、Docker 和 Nginx 的安装和配置。 第 1 步:更新和升级 Debian 系统 通过 SSH 连接到服务器。更新软件包列表:sudo apt update升级已安装的软件…...
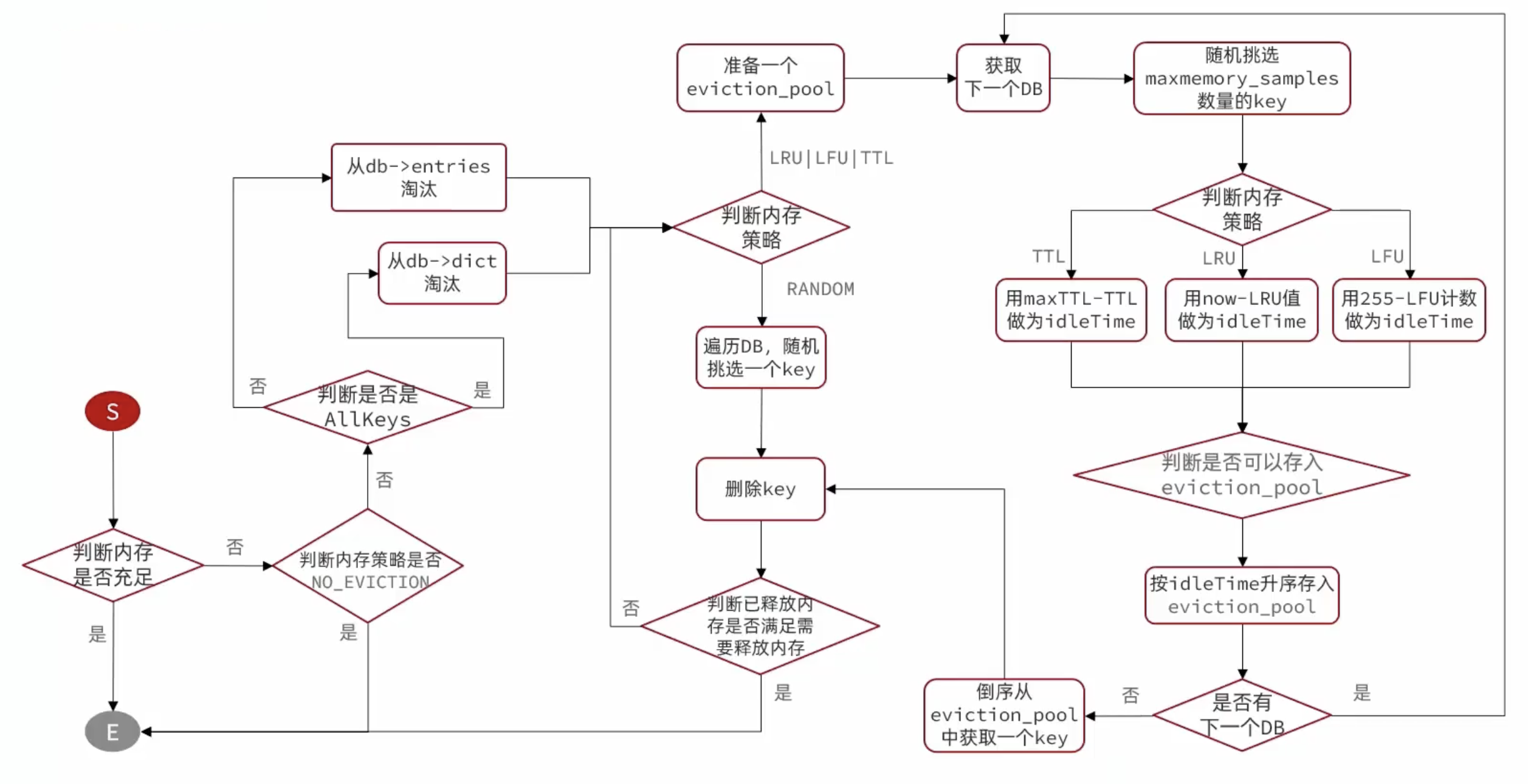
Redis原理 - 内存策略
原文首更地址,阅读效果更佳! Redis原理 - 内存策略 | CoderMast编程桅杆https://www.codermast.com/database/redis/redis-memery-strategy.html Redis 本身是一个典型的 key-value 内存存储数据库,因此所有的 key、value 都保存在之前学习…...
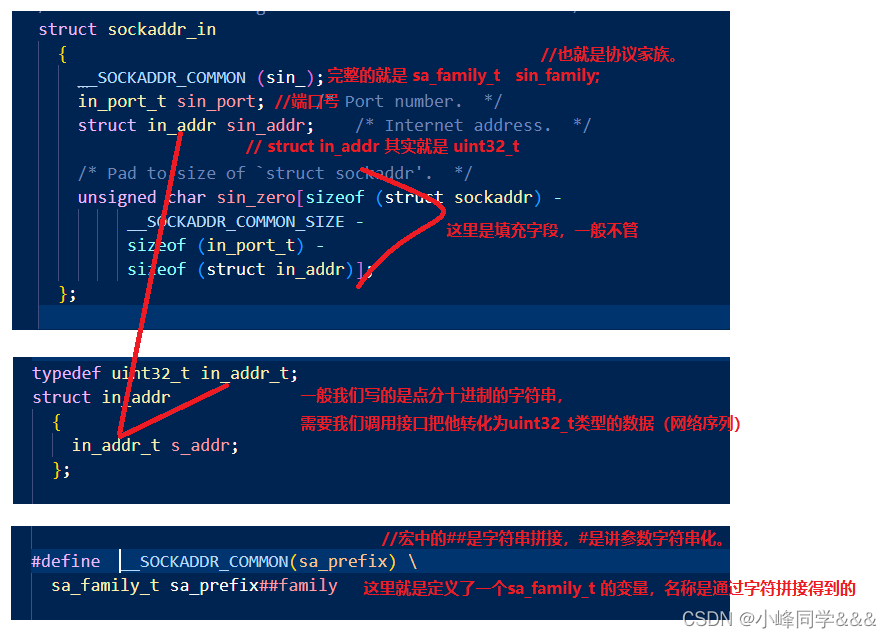
【计算机网络】IP 地址处理函数
目录 1.struct sockaddr_in的结构 2.一般我们写的结构 3.常见的“点分十进制” 到 ” uint32_t 的转化接口 3.1. inet_aton 和 inet_ntoa (ipv4) 3.2. inet_pton 和 inet_ntop (ipv4 和 ipv6) 3.3. inet_addr 和 inet_network 3…...
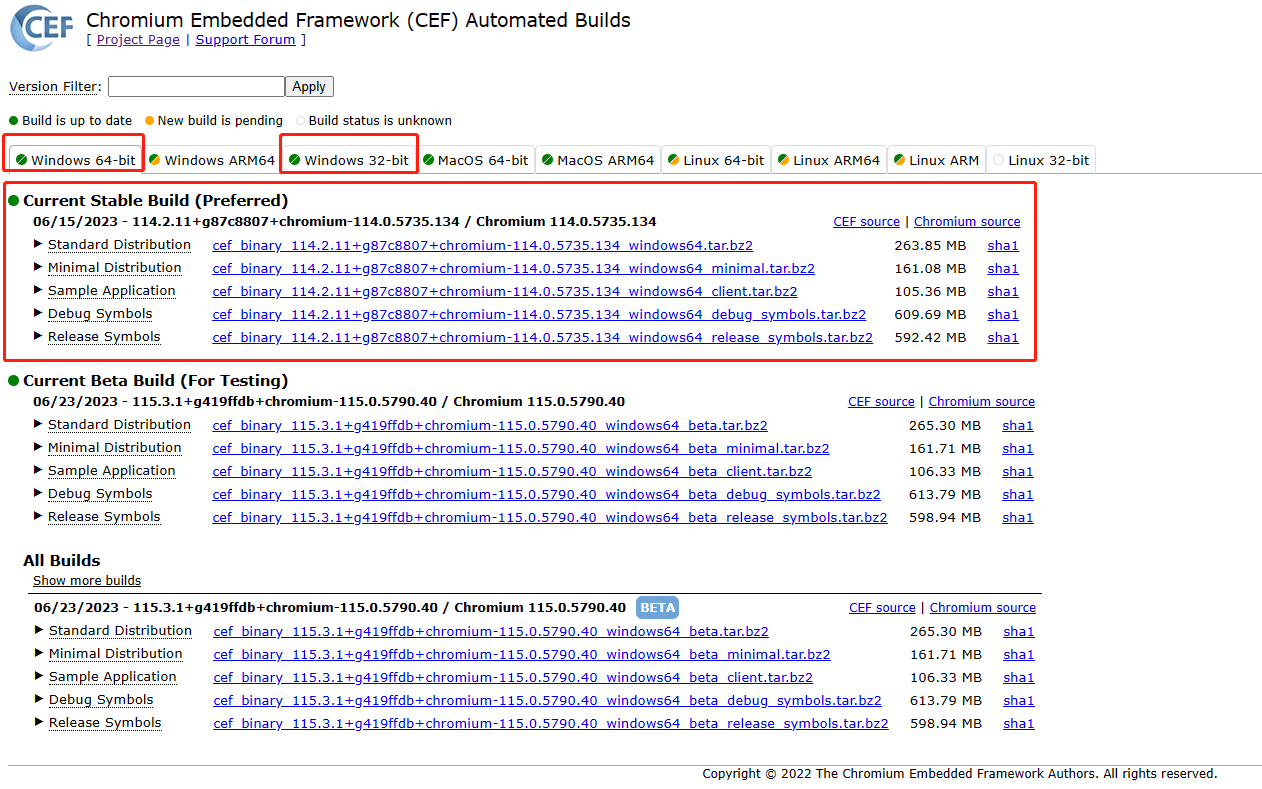
9i物联网浏览器(cef_114.2.110114.2.100支持H264视频)WinForm-CefSharp114(5735)视频版本体验
更新:2023.6.25 版本:Cef_114.2.110和114.2.100+chromium-114.0.5735.134的32位和64位 说明:支持图片,mp3,mp4(H264)多媒体 测试环境:windows server 2019 测试网址:www.html5test.com 1.包下载地址 1.1 https://www.nuget.org/packages/CefSharp.Common/ 1.2 https…...

如何在本地运行一个已关服但具有客户端的游戏
虽然游戏服务器关闭后,我们通常无法再进行在线游戏,但对于一些已经关服但仍保留客户端的游戏来说,我们仍然可以尝试在本地进行游玩。本文将介绍如何在本地运行一个已关服但具有客户端的游戏的方法。 一、获取游戏客户端 要在本地运行一个已关…...

C语言编程—预处理器
预处理器不是编译器的组成部分,但是它是编译过程中一个单独的步骤。简言之,C 预处理器只不过是一个文本替换工具而已,它们会指示编译器在实际编译之前完成所需的预处理。我们将把 C 预处理器(C Preprocessor)简写为 CP…...

使用 Maya Mari 设计 3D 波斯风格道具(p1)
今天瑞云渲染小编给大家带来了Simin Farrokh Ahmadi 分享的Persian Afternoon 项目过程,解释了 Maya 和 Mari 中的建模、纹理和照明过程。 介绍 我的名字是西敏-法罗赫-艾哈迈迪,人们都叫我辛巴 在我十几岁的时候,我就意识到我喜欢艺术和创造…...

Redis分布式问题
Redis实现分布式锁 Redis为单进程单线程模式,采用队列模式将并发访问变成串行访问,且多客户端对Redis的连接并不存在竞争关系Redis中可以使用SETNX命令实现分布式锁。当且仅当 key 不存在,将 key 的值设为 value。 若给定的 key 已经存在&…...
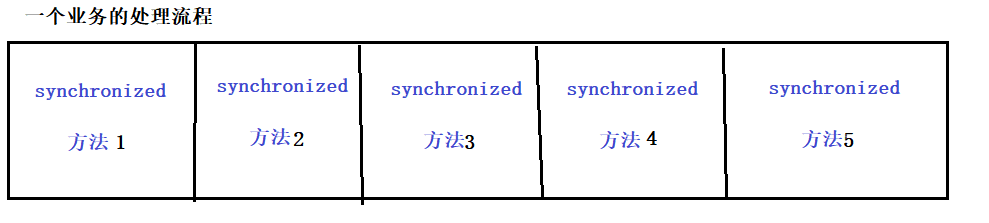
synchronized原理
目录 一、基本特点 二、加锁过程 2.1、偏向锁 2.2、轻量级锁 2.3、重量级锁 三、其它的优化操作 3.1、锁消除 3.2、锁粗化 一、基本特点 synchronized有以下特性: 开始是乐观锁,如果锁冲突频繁,就转换为悲观锁。开始是轻量级锁,…...

10G光模块能兼容千兆光口吗
当涉及到光网络设备和光模块的兼容性时,确保正确的匹配是至关重要的。本期文章内容,我们将探讨10G光模块与千兆光口之间的兼容性。 一、10G光模块和千兆光口的基本概念 首先,我们需要了解10G光模块和千兆光口的基本概念。10G光模块是一种用…...

css 显示省略号 和 动态显示省略号
省略是非常常见的功能。 简单的实现省略号 下面的代码就可以实现省略号,超过宽度的时候就会出现省略号 .text-name{//宽高是一定要设置的不然是会无效延伸的width: 200rpx;overflow: hidden;white-space: nowrap;text-overflow: ellipsis;}稍微复杂点的情况&#…...

LeetCode 1253. 重构 2 行二进制矩阵
【LetMeFly】1253.重构 2 行二进制矩阵 力扣题目链接:https://leetcode.cn/problems/reconstruct-a-2-row-binary-matrix/ 给你一个 2 行 n 列的二进制数组: 矩阵是一个二进制矩阵,这意味着矩阵中的每个元素不是 0 就是 1。第 0 行的元素之…...

【八股】【C++】内存
这里写目录标题 内存空间分配new和delete原理C有几种newmalloc / free 与 new / delete区别malloc和free原理?delete和delete[]区别?C内存泄漏malloc申请的存储空间能用delete释放吗?malloc、calloc函数、realloc函数C中浅拷贝与深拷贝栈和队列的区别C里…...

数据库G等待
> db^Cgbasedbtpc:~$ dbaccess db10 -Database selected.> call insert_t();Routine executed.Elapsed time: 811.630 sec 磁盘逻辑日志,无BUF库> ^Cgbasedbtpc:~$ gbasedbtpc:~$ dbaccess db10 -Database selected.> call insert_t();Routine executed.Elapse…...
基础知识)
PCB封装设计指导(一)基础知识
PCB封装设计指导(一)基础知识 PCB封装是PCB设计的基础,也是PCB最关键的部件之一,尺寸需要非常准确且精确,关系到设计,生产加工,贴片等后续一系列的流程。 下面以Allegro为例介绍封装创建前的一些基础知识 1.各个psm文件代表什么 mechanical symbol 是.bsm Package sy…...

Flask框架之Restful--介绍--下载--基本使用
目录 Restful 概念 架构的主要原则 适用场景 协议 数据传输格式 url链接规则 HTTP请求方式 状态码 Restful的基本使用 介绍 优势 缺点 安装 基本使用 注意 Restful 概念 RESTful(Representational State Transfer)是一种用于设计网络应用…...

2023年上海市浦东新区网络安全管理员决赛理论题样题
目录 一、判断题 二、单选题 三、多选题 一、判断题 1.等保1.0至等保2.0从信息系统拓展为网络和信息系统。 正确 (1)保护对象改变 等保1.0保护的对象是信息系统,等保2.0增加为网络和信息系统,增加了云计算、大数据、工业控制系统、物联网、移动物联技术、网络基础…...

如何免费构建个人游戏串流服务器:Sunshine开源方案完整指南
如何免费构建个人游戏串流服务器:Sunshine开源方案完整指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine是一款开源的自托管游戏串流服务器,让您…...
Pixel Script Temple 效果进阶:YOLOv11目标识别引导的精准构图像素画
Pixel Script Temple 效果进阶:YOLOv11目标识别引导的精准构图像素画 1. 效果亮点预览 当像素艺术遇上目标检测技术,会碰撞出怎样的火花?最新发布的YOLOv11模型与Pixel Script Temple的结合,让像素画创作进入了精准构图的新阶段…...

新手如何借助快马平台AI生成代码,轻松入门蓝桥杯经典题型
作为一个刚接触编程的新手,参加蓝桥杯这样的比赛可能会觉得无从下手。特别是看到题目要求实现算法时,往往不知道如何把问题拆解成代码。最近我发现用InsCode(快马)平台可以很好地解决这个问题,它能根据题目描述直接生成可运行的代码ÿ…...

万物识别镜像高级功能探索:除了基础识别,还能做什么?
万物识别镜像高级功能探索:除了基础识别,还能做什么? 1. 万物识别镜像的隐藏潜力 大多数人使用万物识别镜像时,只停留在基础识别功能上——上传图片,获取识别结果。但这款基于cv_resnest101_general_recognition算法…...

Lychee-rerank-mm在音乐推荐中的创新应用
Lychee-rerank-mm在音乐推荐中的创新应用 1. 引言 你有没有遇到过这样的情况:在音乐平台上听到一首很喜欢的歌,想找类似的音乐,但系统推荐的歌曲却总是差强人意?要么封面风格完全不搭,要么歌词主题南辕北辙ÿ…...

避开这些坑!在PX4 1.14.0上添加自定义串口传感器的完整避坑指南
PX4 1.14.0自定义串口传感器开发实战:从设备注册到数据解析全链路避坑指南 当你在PX4飞控上尝试接入一款新型激光雷达时,是否遇到过这样的场景:按照官方文档一步步操作,编译通过后却发现传感器始终无法输出有效数据?本…...

Phi-4-mini-reasoning入门指南:用Gradio Blocks构建多步解题UI
Phi-4-mini-reasoning入门指南:用Gradio Blocks构建多步解题UI 1. 认识Phi-4-mini-reasoning Phi-4-mini-reasoning是一款3.8B参数的轻量级开源模型,专为数学推理、逻辑推导和多步解题等强逻辑任务设计。这个模型主打"小参数、强推理、长上下文、…...

Openclaw案例之构建《全自动化、高适配、可定制”的AI绘画生产体系》
⚡⚡⚡ 欢迎预览,批评指正⚡⚡⚡ 文章目录一、需求&目标二、搭建基础环境2.1 环境准备2.2 OpenClaw与绘画模型部署启动2.3 核心配置(模型插件联动)三、核心操作3.1 多智能体角色配置(核心步骤)3.2 一键启动自动化…...

7个高效步骤:Meshroom开源三维重建工具从入门到精通
7个高效步骤:Meshroom开源三维重建工具从入门到精通 【免费下载链接】Meshroom 3D Reconstruction Software 项目地址: https://gitcode.com/gh_mirrors/me/Meshroom 技术原理:三维重建的底层逻辑与技术选型 摄影测量技术的数学基础 三维重建技…...

3个步骤实现极致跨平台远程控制:BilldDesk Pro突破性体验
3个步骤实现极致跨平台远程控制:BilldDesk Pro突破性体验 【免费下载链接】billd-desk 基于Vue3 WebRTC Nodejs Flutter搭建的远程桌面控制 项目地址: https://gitcode.com/gh_mirrors/bi/billd-desk 还在为远程协作的种种限制而烦恼吗?当你需…...