从0开始,手写MySQL事务
说在前面:从0开始,手写MySQL的学习价值
尼恩曾经指导过的一个7年经验小伙,凭借精通Mysql, 搞定月薪40K。
从0开始,手写一个MySQL的学习价值在于:
- 可以深入地理解MySQL的内部机制和原理,Mysql可谓是面试的绝对重点和难点
- 从而更好地掌握MySQL的使用和优化。
- 帮助你提高编程能力和解决问题的能力。
- 作为一个优质的简历轮子项目,注意,这是高质量的简历轮子项目
很多小伙伴的项目都很low,极度缺乏轮子项目,so,轮子项目这就来了。
文章目录
- 说在前面:从0开始,手写MySQL的学习价值
- 手写DB架构设计:
- 从0开始,手写Mysql事务
- 事务5种状态
- 事务5种状态之间的转换
- 如何管理事务的状态?
- 创建xid文件
- 定义常量
- 校验XID文件是否合法
- 开启事务
- 改变事务状态
- 更新xid Header
- 判断事务状态
- 关闭TM
- 两阶段锁实现事务操作
- 两阶段锁(2PL)功能介绍
- 两阶段锁(2PL)事务实现
- 手写两阶段锁(2PL)事务
- 事务存储
- 开启事务
- 提交事务
- 回滚事务
- 删除事务
- 插入数据
- 读取事务
- 事务的ACID特性
- 原子性(Atomicity)
- 一致性(consistency)
- 隔离性(isolation)
- 持久性(durability)
- 死锁
- 死锁检测
- 判断死锁
- 高并发场景如何做事务隔离
- 事务的隔离级别功能分析
- 读未提交(READ UNCOMMITTED)
- 读已提交(READ COMMITTED)
- 可重复读(REPEATABLE READ)
- 可串行化(SERIALIZABLE)
- MVCC
- 并发事务带来的问题
- 读-读
- 写-写
- 写-读或读-写
- mvcc 的实现原理
- 隐藏字段
- ReadView
- 版本链
- 手写事务隔离级别
- 已提交读
- 可重复读
- 版本跳跃
- 作者介绍:
- 说在后面:
- 技术自由的实现路径 PDF:
- 实现你的 架构自由:
- 实现你的 响应式 自由:
- 实现你的 spring cloud 自由:
- 实现你的 linux 自由:
- 实现你的 网络 自由:
- 实现你的 分布式锁 自由:
- 实现你的 王者组件 自由:
- 实现你的 面试题 自由:
手写DB架构设计:
尼恩的风格: 开始写代码前,先做架构
从功能上来说,一个手写DB系统架构分为以下几个模块:
- 数据管理器DM
- 事务管理器TM
- 版本管理器(VM)
- 表管理器(TBM)
- 索引管理器(IM)、
手写DB架构设计设计图,具体如下:

从0开始,手写Mysql事务
事务是应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤消。
也就是事务具有原子性,一个事务中的一系列的操作要么全部成功,要么一个都不做。
事务的结束有两种,当事务中的所有步骤全部成功执行时,事务提交。
如果其中一个步骤失败,将发生回滚操作,撤消事务开始时的所有操作。
事务定义的语句如下
(1) BEGIN TRANSACTION:事务开始。
(2) END TRANSACTION:事务结束。
(3) COMMIT:事务提交。该操作表示事务成功地结束,它将通知事务管理器该事务的所有更新操作现在可以被提交或永久地保留。
(4) ROLLBACK:事务回滚。该操作表示事务非成功地结束,它将通知事务管理器出故障了,数据库可能处于不一致状态,该事务的所有更新操作必须回滚或撤销。
事务5种状态
事务是数据库的基本执行单元,如果事务成功执行,则数据库从一个一致状态进入另一个一致状态。
事务状态 的状态有以下5种
- 活动状态:事务的初始状态,事务执行时处于这个状态。
- 部分提交状态:当操作序列的最后一条语句执行后,事务就处于部分提交状态。这时,事务虽然已经完全执行,但由于实际输出可能还临时驻留在内存中,在事务成功完成前还有可能出现硬件故障,因此,部分提交状态并不等于事务成功执行。
- 失败状态:由于硬件或逻辑错误,使得事务不能继续正常执行,事务就进入了失败状态,处于失败状态的事务必须回滚。这样,事务就进入了中止状态。
- 中止状态:事务回滚并且数据库恢复到事务开始执行前的状态。
- 提交状态:当事务成功完成后,称事务处于提交状态。只有事务处于提交状态后,才能说事务已经提交。
如果因为某种原因事务没能成功执行,但其已经对数据库进行了修改,这时候可能会导致数据库处于不一致的状态,需要对事务已经造成的变更进行撤销(回滚)。
事务5种状态之间的转换

- BEGIN TRANSACTION:开始运行事务,使事务进入活动状态
- END TRANSACTION:说明事物中的所有读写操作都已完成,使事务进入部分提交状态,把事务的所有操作对数据库的影响存入数据库。
- COMMIT:标志事务已经成功地完成,事务中的所有操作对数据库的影响已经安全地存入数据库,事务进入提交状态,结束事务的运行。
- ABORT:标志事务进入失败状态,系统撤销事务中所有操作对数据库和其他事务的影响,结束事务的运行。
如何管理事务的状态?
在手写数据库 MYDB 中,每一个事务都有一个 XID,这个 ID 唯一标识了这个事务。
事务的 XID 从 1 开始标号,并自增,不可重复。
事务管理器TM通过维护XID文件来维护事务的状态,并提供接口供其他模块来查询某个事务的状态。
规定 XID 0 是一个超级事务(Super Transaction)。
当一些操作想在没有申请事务的情况下进行,那么可以将操作的 XID 设置为 0。XID 为 0 的事务的状态永远是 committed。
每个事务有三种状态:
- active,正在进行,尚未结束,即活动状态
- committed,已提交状态
- aborted,回滚状态
定义如下:
// 事务的三种状态
//活动状态
private static final byte FIELD_TRAN_ACTIVE = 0;
//已提交状态
private static final byte FIELD_TRAN_COMMITTED = 1;
//回滚状态
private static final byte FIELD_TRAN_ABORTED = 2;
XID 文件给每个事务分配了一个字节的空间,用来保存其状态。
同时,在 XID 文件的头部,还保存了一个 8 字节的数字,记录了这个 XID 文件管理的事务的个数。
于是,事务 xid 在文件中的状态就存储在 (xid-1)+8 字节处,xid-1 是因为 xid 0(Super XID) 的状态不需要记录。
在TransactionManager中提供了一些接口供其他模块调用,用来创建事务和查询事务状态,其接口方法如下:
//开启事务
long begin();
//提交事务
void commit(long xid);
//撤销事务
void abort(long xid);
// 判断事务状态-活动状态
boolean isActive(long xid);
// 是否提交状态
boolean isCommitted(long xid);
// 是否失败状态
boolean isAborted(long xid);
// 关闭事务管理TM
void close();
创建xid文件
我们需要创建一个xid文件并创建TM对象,其具体实现如下:
public static TransactionManagerImpl create(String path) {File f = new File(path+TransactionManagerImpl.XID_SUFFIX);try {if(!f.createNewFile()) {Panic.panic(Error.FileExistsException);}} catch (Exception e) {Panic.panic(e);}if(!f.canRead() || !f.canWrite()) {Panic.panic(Error.FileCannotRWException);}FileChannel fc = null;RandomAccessFile raf = null;try {raf = new RandomAccessFile(f, "rw");fc = raf.getChannel();} catch (FileNotFoundException e) {Panic.panic(e);}// 写空XID文件头ByteBuffer buf = ByteBuffer.wrap(new byte[TransactionManagerImpl.LEN_XID_HEADER_LENGTH]);try {//从零创建 XID 文件时需要写一个空的 XID 文件头,即设置 xidCounter 为 0,// 否则后续在校验时会不合法:fc.position(0);fc.write(buf);} catch (IOException e) {Panic.panic(e);}return new TransactionManagerImpl(raf, fc);
}//从一个已有的 xid 文件来创建 TM
public static TransactionManagerImpl open(String path) {File f = new File(path+TransactionManagerImpl.XID_SUFFIX);if(!f.exists()) {Panic.panic(Error.FileNotExistsException);}if(!f.canRead() || !f.canWrite()) {Panic.panic(Error.FileCannotRWException);}FileChannel fc = null;RandomAccessFile raf = null;try {//用来访问那些保存数据记录的文件raf = new RandomAccessFile(f, "rw");//返回与这个文件有关的唯一FileChannel对象fc = raf.getChannel();} catch (FileNotFoundException e) {Panic.panic(e);}return new TransactionManagerImpl(raf, fc);
}
定义常量
我们看下TransactionManager接口的实现类TransactionManagerImpl.首先定义一些必要的常量
// XID文件头长度
static final int LEN_XID_HEADER_LENGTH = 8;
// 每个事务的占用长度
private static final int XID_FIELD_SIZE = 1;// 事务的三种状态
//活动状态
private static final byte FIELD_TRAN_ACTIVE = 0;
//已提交状态
private static final byte FIELD_TRAN_COMMITTED = 1;
//回滚状态
private static final byte FIELD_TRAN_ABORTED = 2;// 超级事务,永远为commited状态
public static final long SUPER_XID =1;// XID 文件后缀
static final String XID_SUFFIX = ".xid";private RandomAccessFile file;
private FileChannel fc;
private long xidCounter;
//显示锁
private Lock counterLock;
文件读写都采用了 NIO 方式的 FileChannel,FileChannel 提供了一种通过通道来访问文件的方式,它可以通过带参数 position(int) 方法定位到文件的任意位置开始进行操作,还能够将文件映射到直接内存,提高大文件的访问效率。关于java的NIO 请参考<<java 高并发核心编程(卷1)>>.
校验XID文件是否合法
构造函数创建了一个 TransactionManager 之后,首先要对 XID 文件进行校验,以保证这是一个合法的 XID 文件。
校验的方式也很简单,通过文件头的 8 字节数字反推文件的理论长度,与文件的实际长度做对比。如果不同则认为 XID 文件不合法。
TransactionManagerImpl(RandomAccessFile raf, FileChannel fc) {this.file = raf;this.fc = fc;//显式锁counterLock = new ReentrantLock();checkXIDCounter();
}/*** 检查XID文件是否合法* 读取XID_FILE_HEADER中的xidcounter,根据它计算文件的理论长度,对比实际长度*/
private void checkXIDCounter() {long fileLen = 0;try {fileLen = file.length();} catch (IOException e1) {Panic.panic(Error.BadXIDFileException);}if(fileLen < LEN_XID_HEADER_LENGTH) {//对于校验没有通过的,会直接通过 panic 方法,强制停机。// 在一些基础模块中出现错误都会如此处理,// 无法恢复的错误只能直接停机。Panic.panic(Error.BadXIDFileException);}// java NIO中的Buffer的array()方法在能够读和写之前,必须有一个缓冲区,// 用静态方法 allocate() 来分配缓冲区ByteBuffer buf = ByteBuffer.allocate(LEN_XID_HEADER_LENGTH);try {fc.position(0);fc.read(buf);} catch (IOException e) {Panic.panic(e);}//从文件开头8个字节得到事务的个数this.xidCounter = Parser.parseLong(buf.array());// 根据事务xid取得其在xid文件中对应的位置long end = getXidPosition(this.xidCounter + 1);if(end != fileLen) {//对于校验没有通过的,会直接通过 panic 方法,强制停机Panic.panic(Error.BadXIDFileException);}
}
锁用的是可重入锁ReentrantLock,ReentrantLock是JUC包提供的显式锁的一个基础实现类,ReentrantLock类实现了Lock接口,它拥有与synchronized相同的并发性和内存语义,但是拥有了限时抢占、可中断抢占等一些高级锁特性。关于ReenttrantLock 内容可参考<<java高并发核心编程(卷2)>>.
文件的理论长度:开头的8个字节+一个事务状态所占用的字节*事务的个数;
通过xid文件开头的 8 个字节(记录了事务的个数)反推文件的理论长度与文件的实际长度做对比。如果不等则认为 XID 文件不合法。每次创建xid对象都会检查一次.
对于校验没有通过的,会直接通过 panic 方法,强制停机。在一些基础模块中出现错误都会如此处理,无法恢复的错误只能直接停机。
来获取 xid 的状态在文件中的偏移getXidPosition()方法实现如下:
// 根据事务xid取得其在xid文件中对应的位置
private long getXidPosition(long xid) {return LEN_XID_HEADER_LENGTH + (xid-1)*XID_FIELD_SIZE;
}
开启事务
begin() 开启一个事务,并初始化事务的结构,将其存放在 activeTransaction 中,用于检查和快照使用:
/***begin() 每开启一个事务,并计算当前活跃的事务的结构,将其存放在 activeTransaction 中,* 用于检查和快照使用:* @param level* @return*/
@Override
public long begin(int level) {lock.lock();try {long xid = tm.begin();//activeTransaction 当前事务创建时活跃的事务,,如果level!=0,放入t的快照中Transaction t = Transaction.newTransaction(xid, level, activeTransaction);activeTransaction.put(xid, t);return xid;} finally {lock.unlock();}
}
改变事务状态
事务xid的偏移量=开头的8个字节+一个事务状态所占用的字节*事务的xid;
通过事务xid计算出记录该事务状态的偏移量,再更改状态。
具体实现如下:
// 更新xid事务的状态为status
private void updateXID(long xid, byte status) {long offset = getXidPosition(xid);//每个事务占用长度byte[] tmp = new byte[XID_FIELD_SIZE];tmp[0] = status;ByteBuffer buf = ByteBuffer.wrap(tmp);try {fc.position(offset);fc.write(buf);} catch (IOException e) {Panic.panic(e);}try {//将数据刷出到磁盘,但不包括元数据fc.force(false);} catch (IOException e) {Panic.panic(e);}
}
其中abort()和commit()这是调用了这个方法,
// 提交XID事务
public void commit(long xid) {updateXID(xid, FIELD_TRAN_COMMITTED);
}// 回滚XID事务
public void abort(long xid) {updateXID(xid, FIELD_TRAN_ABORTED);
}更新xid Header
每次创建一个事务时,都需要将文件头记录的事务个数+1;
// 将XID加一,并更新XID Header
private void incrXIDCounter() {xidCounter ++;ByteBuffer buf = ByteBuffer.wrap(Parser.long2Byte(xidCounter));//游标pos, 限制为lim, 容量为captry {fc.position(0);fc.write(buf);} catch (IOException e) {Panic.panic(e);}try {fc.force(false);} catch (IOException e) {Panic.panic(e);}
}
判断事务状态
根据xid-》获取记录事务xid的状态的offset-》读取事务xid的状态-》是否等于status.
// 检测XID事务是否处于status状态
private boolean checkXID(long xid, byte status) {long offset = getXidPosition(xid);ByteBuffer buf = ByteBuffer.wrap(new byte[XID_FIELD_SIZE]);try {fc.position(offset);fc.read(buf);} catch (IOException e) {Panic.panic(e);}return buf.array()[0] == status;
}// 活动状态判断
public boolean isActive(long xid) {if(xid == SUPER_XID) return false;return checkXID(xid, FIELD_TRAN_ACTIVE);
}// 已提交状态判断
public boolean isCommitted(long xid) {if(xid == SUPER_XID) return true;return checkXID(xid, FIELD_TRAN_COMMITTED);
}//回滚状态判断
public boolean isAborted(long xid) {if(xid == SUPER_XID) return false;return checkXID(xid, FIELD_TRAN_ABORTED);
}
关闭TM
//TM关闭
public void close() {try {fc.close();file.close();} catch (IOException e) {Panic.panic(e);}
}
两阶段锁实现事务操作
两阶段锁(2PL)功能介绍
事务调度一般有串行调度和并行调度;首先我们来了解以下几个概念:
- 并发控制:指多用户共享的系统中,许多用户可能同时对同一数据进行操作
- 调度:事务的执行次序
- 串行调度:多个事务依次串行执行,且只有当一个事务的所有操作都执行完后才执行另一个事务的所有操作。只要是串行调度,执行的结果都是正确的。

- 并行调度:利用分时的方法同时处理多个事务。但是并行调度的调度结果可能是错误的,可能产生不一致的状态,包括有:丢失修改,不可重复读和读脏数据.

在一个事务里面,分为加锁(lock)阶段和解锁(unlock)阶段,也即所有的lock操作都在unlock操作之前,如下图所示:

在实际情况下,SQL是千变万化、条数不定的,数据库很难在事务中判定什么是加锁阶段,什么是解锁阶段。于是引入了S2PL(Strict-2PL),即:在事务中只有提交(commit)或者回滚(rollback)时才是解锁阶段, 其余时间为加锁阶段。引入2PL是为了保证事务的隔离性,即多个事务在并发的情况下等同于串行的执行。

第一阶段是获得封锁的阶段,称为扩展阶段:其实也就是该阶段可以进入加锁操作,在对任何数据进行读操作之前要申请获得S锁,在进行写操作之前要申请并获得X锁,加锁不成功,则事务进入等待状态,直到加锁成功才继续执行。就是加锁后就不能解锁了。
第二阶段是释放封锁的阶段,称为收缩阶段:当事务释放一个封锁后,事务进入封锁阶段,在该阶段只能进行解锁而不能再进行加锁操作。
两阶段锁(2PL)事务实现
mysql中事务默认是隐式事务,执行insert、update、delete操作的时候,数据库自动开启事务、提交或回滚事务。
是否开启隐式事务是由变量autocommit控制的。
所以事务分为隐式事务和显式事务。
隐式事务是由事务自动开启、提交或回滚,比如insert、update、delete语句,事务的开启、提交或回滚由mysql内部自动控制的。
显式事务是需要手动开启、提交或回滚,由开发者自己控制。
手写两阶段锁(2PL)事务
在实现事务隔离级别之前, 我们需要先来讨论一下 Version Manager(VM).
VM是基于两阶段锁协议实现了调度序列的可串行化,并实现了MVCC 以消除读写阻塞。
同时实现了两种隔离级别.VM 是手写数据库 MYDB的事务和数据版本管理核心.
事务存储
对于一条记录来说,MYDB 使用 Entry 类维护了其结构。
虽然理论上,MVCC 实现了多版本,但是在实现中,VM 并没有提供 Update 操作,对于字段的更新操作由后面的表和字段管理(TBM)实现。
所以在 VM 的实现中,一条记录只有一个版本。
一条记录存储在一条 Data Item 中,所以 Entry 中保存一个 DataItem 的引用即可:
public class Entry {private static final int OF_XMIN = 0;private static final int OF_XMAX = OF_XMIN+8;private static final int OF_DATA = OF_XMAX+8;private long uid;private DataItem dataItem;private VersionManager vm;public static Entry newEntry(VersionManager vm, DataItem dataItem, long uid) {Entry entry = new Entry();entry.uid = uid;entry.dataItem = dataItem;entry.vm = vm;return entry;}public static Entry loadEntry(VersionManager vm, long uid) throws Exception {DataItem di = ((VersionManagerImpl)vm).dm.read(uid);return newEntry(vm, di, uid);}public void release() {((VersionManagerImpl)vm).releaseEntry(this);}public void remove() {dataItem.release();}
}
规定一条Entry中存储的数据格式如下:
[XMIN] [XMAX] [DATA]
8个字节 8个字节
XMIN 是创建该条记录(版本)的事务编号,而 XMAX 则是删除该条记录(版本)的事务编号。DATA 就是这条记录持有的数据。
根据这个结构,在创建记录时调用的 wrapEntryRaw()方法如下:
public static byte[] wrapEntryRaw(long xid, byte[] data) {byte[] xmin = Parser.long2Byte(xid);byte[] xmax = new byte[8];return Bytes.concat(xmin, xmax, data);
}
同样,如果要获取记录中持有的数据,也就需要按照这个结构来解析:
// 以拷贝的形式返回内容
public byte[] data() {dataItem.rLock();try {SubArray sa = dataItem.data();byte[] data = new byte[sa.end - sa.start - OF_DATA];System.arraycopy(sa.raw, sa.start+OF_DATA, data, 0, data.length);return data;} finally {dataItem.rUnLock();}
}
这里以拷贝的形式返回数据,如果需要修改的话,需要遵循一定的流程:在修改之前需要调用 before() 方法,想要撤销修改时,调用 unBefore() 方法,在修改完成后,调用 after() 方法。
整个流程,主要是为了保存前相数据,并及时落日志。DM 会保证对 DataItem 的修改是原子性的。
@Override
public void before() {wLock.lock();pg.setDirty(true);System.arraycopy(raw.raw, raw.start, oldRaw, 0, oldRaw.length);
}@Override
public void unBefore() {System.arraycopy(oldRaw, 0, raw.raw, raw.start, oldRaw.length);wLock.unlock();
}@Override
public void after(long xid) {dm.logDataItem(xid, this);wLock.unlock();
}
在设置 XMAX 的值中体现了如果需要修改的话,要遵循一定的规则, 而且这个版本对每一个XMAX之后的事务都是不可见的,等价于删除了. setXmax代码如下:
public void setXmax(long xid) {dataItem.before();try {SubArray sa = dataItem.data();System.arraycopy(Parser.long2Byte(xid), 0, sa.raw, sa.start+OF_XMAX, 8);} finally {dataItem.after(xid);}
}
开启事务
begin() 每开启一个事务,计算当前活跃的事务的结构,将其存放在 activeTransaction 中,
@Override
public long begin(int level) {lock.lock();try {long xid = tm.begin();Transaction t = Transaction.newTransaction(xid, level, activeTransaction);activeTransaction.put(xid, t);return xid;} finally {lock.unlock();}
}
提交事务
commit() 方法提交一个事务,主要就是 free 掉相关的结构,并且释放持有的锁,并修改 TM 状态,并把该事务从activeTransaction中移除。
@Override
public void commit(long xid) throws Exception {lock.lock();Transaction t = activeTransaction.get(xid);lock.unlock();try {if(t.err != null) {throw t.err;}} catch(NullPointerException n) {System.out.println(xid);System.out.println(activeTransaction.keySet());Panic.panic(n);}lock.lock();activeTransaction.remove(xid);lock.unlock();lt.remove(xid);tm.commit(xid);
}
回滚事务
abort 事务的方法则有两种,手动和自动。
手动指的是调用 abort() 方法,而自动,则是在事务被检测出出现死锁时,会自动撤销回滚事务;或者出现版本跳跃时,也会自动回滚:
/*** 回滚事务* @param xid*/
@Override
public void abort(long xid) {internAbort(xid, false);
}private void internAbort(long xid, boolean autoAborted) {lock.lock();Transaction t = activeTransaction.get(xid);//手动回滚if(!autoAborted) {activeTransaction.remove(xid);}lock.unlock();//自动回滚if(t.autoAborted) return;lt.remove(xid);tm.abort(xid);
}
删除事务
在一个事务 commit 或者 abort 时,就可以释放所有它持有的锁,并将自身从等待图中删除。
并从等待队列中选择一个xid来占用uid.
解锁时,将该 Lock 对象 unlock 即可,这样其他业务线程就获取到了锁,就可以继续执行了。
public void remove(long xid) {lock.lock();try {List<Long> l = x2u.get(xid);if(l != null) {while(l.size() > 0) {Long uid = l.remove(0);selectNewXID(uid);}}waitU.remove(xid);x2u.remove(xid);waitLock.remove(xid);} finally {lock.unlock();}
}// 从等待队列中选择一个xid来占用uid
private void selectNewXID(long uid) {u2x.remove(uid);List<Long> l = wait.get(uid);if(l == null) return;assert l.size() > 0;while(l.size() > 0) {long xid = l.remove(0);if(!waitLock.containsKey(xid)) {continue;} else {u2x.put(uid, xid);Lock lo = waitLock.remove(xid);waitU.remove(xid);lo.unlock();break;}}if(l.size() == 0) wait.remove(uid);
}
插入数据
insert() 则是将数据包裹成 Entry,交给 DM 插入即可:
@Override
public long insert(long xid, byte[] data) throws Exception {lock.lock();Transaction t = activeTransaction.get(xid);lock.unlock();if(t.err != null) {throw t.err;}byte[] raw = Entry.wrapEntryRaw(xid, data);return dm.insert(xid, raw);
}
读取事务
read() 方法读取一个 entry,根据隔离级别判断下可见性即可.
@Override
public byte[] read(long xid, long uid) throws Exception {lock.lock();//当前事务xid读取时的快照数据Transaction t = activeTransaction.get(xid);lock.unlock();if(t.err != null) {throw t.err;}Entry entry = null;try {//通过uid找要读取的事务dataItementry = super.get(uid);} catch(Exception e) {if(e == Error.NullEntryException) {return null;} else {throw e;}}try {if(Visibility.isVisible(tm, t, entry)) {return entry.data();} else {return null;}} finally {entry.release();}
}
事务的ACID特性
事务是访问并更新数据库中各种数据项的一个程序执行单元。事务的目的是要么都修改,要么都不做。
大多数场景下, 应用都只需要操作单一的数据库,这种情况下的事务称之为本地事务(Local Transaction)。
本地事务的ACID特性是数据库直接提供支持。
为了达成本地事务,Mysql 做了很多工作,比如回滚日志、重做日志、MVCC 、读写锁等。
对于InnoDB存储引擎而言,其默认的事务隔离级别是Repeatable read,完全遵循和满足事务的ACID特性。
ACID是原子性(Atomicity)、一致性(consistency)、隔离性(isolation)、持久性(durability) 4个单词的缩写。
InnoDB是通过日志和锁来保证事务的ACID特性:
- 通过数据库锁的机制,保证事务的隔离性;
- 通过Redo Log(重做日志)来保证事务的隔离性;
- 通过Undo Log(撤销日志)来保证事务的原子性和一致性;
原子性(Atomicity)
事务必须是一个原子的操作序列单元, 事务中包含的各项操作在一次执行过程中,要么全部成功,要么全部不执行,任何一项失败,整个事务回滚,只有全部都执行成功,整个事务才算成功。
在操作任何数据之前, 首先将数据备份到Undo Log,然后进行数据的修改。如果出现了错误或者用户执行了了Rollback 语句,系统可以利用Undo Log 中的备份将数据恢复到事务开始之前的状态,以此保证数据的原子性。
一致性(consistency)
事务的执行不能破坏数据库数据的完整性和一致性,事务在执行之前和之后,数据库都必须处于一致性状态。
一致性包括两方面的内容,分别是约束一致性和数据一致性;
- 约束一致性: 创建表结构时所指定的外键、check(mysql不支持)、唯一索引等约束。
- 数据一致性: 是一个综合性的规定,因为它是由原子性、持久性、隔离性共同保证的结果,而不是单单依赖于某一种技术。
隔离性(isolation)
在并发情况中,并发的事务是相互隔离的,一个事务的执行不能被其他事务干扰。
即不同的事务并发操作相同的数据时,每个事务都有各自完整的数据空间,即一个事务内部的操作及使用的数据对其他并发事务是个隔离的,并发执行的各个事务之间不能相互干扰。
持久性(durability)
持久性也称为永久性(permanence),指一个事务一旦提交,它对数据库中对应数据的状态变更就应该是永久性的。 即使发生系统崩溃或者机器宕机,只要数据库能够重启,那么一定能够将其恢复到事务成功结束时的状态。
Redo Log记录的是新数据的备份,在事务提交前,只要将Redo Log 持久化即可,不需要将数据持久化,当系统崩溃时,虽然数据咩有持久化,但是Redo Log 已经持久化。系统可以根据Redo Log的内容,将所有数据恢复到崩溃之前的状态,这就是使用Redo Log 保障数据的持久化的过程。
总结
数据的完整性主要体现的是一致性特性,数据的完整性是通过原子性、隔离性、持久性来保证的,这三个特性又是通过redo Log 和Undo Log 来保证的。ACID 特性的关系下图所示:

死锁
在mysql中,两阶段锁协议(2PL)通常包括扩张和收缩两个阶段。在扩张阶段,事务将获取锁,但不能释放任何锁。在收缩阶段,可以释放现有的锁但不能获取新的锁,这种规定存在着死锁的风险。
例如:当T1’在扩张阶段,获取了Y的读锁,并读取了Y,此时想要去获取X的写锁,却发现T2’的读锁锁定了X,而T2’也想要获取Y的写锁。简而言之,T1’不得到X是不会释放Y的,T2’不得到Y也是不会释放X的,这便陷入了循环,便形成了死锁。
2PL 会阻塞事务,直至持有锁的线程释放锁。可以将这种等待关系抽象成有向边,例如:Tj 在等待 Ti,就可以表示为 Tj --> Ti。这样,无数有向边就可以形成一个图。检测死锁只需要查看这个图中是否有环即可。
死锁检测
创建一个LockTable对象,在内存中维护这张图,维护结构如下:
public class LockTable {private Map<Long, List<Long>> x2u; // 某个XID已经获得的资源的UID列表private Map<Long, Long> u2x; // UID被某个XID持有private Map<Long, List<Long>> wait; // 正在等待UID的XID列表private Map<Long, Lock> waitLock; // 正在等待资源的XID的锁private Map<Long, Long> waitU; // XID正在等待的UID......
}
在每次出现等待的情况时,就尝试向图中增加一条边,并进行死锁检测。如果检测到死锁,就撤销这条边,不允许添加,并撤销该事务。
// 不需要等待则返回null,否则返回锁对象
// 会造成死锁则抛出异常
public Lock add(long xid, long uid) throws Exception {lock.lock();try {//某个xid已经获得的资源的UID列表,如果在这个列表里面,则不造成死锁,也不需要等待if(isInList(x2u, xid, uid)) {return null;}//表示有了一个新的uid,则把uid加入到u2x和x2u里面,不死锁,不等待// u2x uid被某个xid占有if(!u2x.containsKey(uid)) {u2x.put(uid, xid);putIntoList(x2u, xid, uid);return null;}//以下就是需要等待的情况//多个事务等待一个uid的释放waitU.put(xid, uid);//putIntoList(wait, xid, uid);putIntoList(wait, uid, xid);//造成死锁if(hasDeadLock()) {//从等待列表里面删除waitU.remove(xid);removeFromList(wait, uid, xid);throw Error.DeadlockException;}//从等待列表里面删除Lock l = new ReentrantLock();l.lock();waitLock.put(xid, l);return l;} finally {lock.unlock();}
}
调用 add,如果不需要等待则进行下一步,如果需要等待的话,会返回一个上了锁的 Lock 对象。调用方在获取到该对象时,需要尝试获取该对象的锁,由此实现阻塞线程的目的,
try {l = lt.add(xid, uid);
} catch(Exception e) {t.err = Error.ConcurrentUpdateException;internAbort(xid, true);t.autoAborted = true;throw t.err;
}
if(l != null) {l.lock();l.unlock();
}
判断死锁
查找图中是否有环的算法实际上就是一个深搜,需要注意的是这个图不一定是连通图。具体的思路就是为每个节点设置一个访问戳,都初始化为 1,随后遍历所有节点,以每个非 1 的节点作为根进行深搜,并将深搜该连通图中遇到的所有节点都设置为同一个数字,不同的连通图数字不同。这样,如果在遍历某个图时,遇到了之前遍历过的节点,说明出现了环。
判断死锁的具体实现如下:
private boolean hasDeadLock() {xidStamp = new HashMap<>();stamp = 1;System.out.println("xid已经持有哪些uid x2u="+x2u);//xid已经持有哪些uidSystem.out.println("uid正在被哪个xid占用 u2x="+u2x);//uid正在被哪个xid占用//已经拿到锁的xidfor(long xid : x2u.keySet()) {Integer s = xidStamp.get(xid);if(s != null && s > 0) {continue;}stamp ++;System.out.println("xid"+xid+"的stamp是"+s);System.out.println("进入深搜");if(dfs(xid)) {return true;}}return false;
}private boolean dfs(long xid) {Integer stp = xidStamp.get(xid);//遍历某个图时,遇到了之前遍历过的节点,说明出现了环if(stp != null && stp == stamp) {return true;}if(stp != null && stp < stamp) {return false;}//每个已获得资源的事务一个独特的stampxidStamp.put(xid, stamp);System.out.println("xidStamp找不到该xid,加入后xidStamp变为"+xidStamp);//已获得资源的事务xid正在等待的uidLong uid = waitU.get(xid);System.out.println("xid"+xid+"正在等待的uid是"+uid);if(uid == null){System.out.println("未成环,退出深搜");//xid没有需要等待的uid,无死锁return false;}//xid需要等待的uid被哪个xid占用了Long x = u2x.get(uid);System.out.println("xid"+xid+"需要的uid被"+"xid"+x+"占用了");System.out.println("=====再次进入深搜"+"xid"+x+"====");assert x != null;return dfs(x);
}
在一个事务 commit 或者 abort 时,就可以释放所有它持有的锁,并将自身从等待图中删除。
public void remove(long xid) {lock.lock();try {List<Long> l = x2u.get(xid);if(l != null) {while(l.size() > 0) {Long uid = l.remove(0);selectNewXID(uid);}}waitU.remove(xid);x2u.remove(xid);waitLock.remove(xid);} finally {lock.unlock();}
}
while 循环释放掉了这个线程所有持有的资源的锁,这些资源可以被等待的线程所获取:
// 从等待队列中选择一个xid来占用uid
private void selectNewXID(long uid) {u2x.remove(uid);List<Long> l = wait.get(uid);if(l == null) return;assert l.size() > 0;while(l.size() > 0) {long xid = l.remove(0);if(!waitLock.containsKey(xid)) {continue;} else {u2x.put(uid, xid);Lock lo = waitLock.remove(xid);waitU.remove(xid);lo.unlock();break;}}if(l.size() == 0) wait.remove(uid);
}
从 List 开头开始尝试解锁,还是个公平锁。解锁时,将该 Lock 对象 unlock 即可,这样业务线程就获取到了锁,就可以继续执行了。
测试代码如下:
public static void main(String[] args) throws Exception {LockTable lock = new LockTable();lock.add(1L,3L);lock.add(2L,4L);lock.add(3L,5L);lock.add(1L,4L);System.out.println("+++++++++++++++++++++++");lock.add(2L,5L);System.out.println("++++++++++++++++");lock.add(3L,3L);System.out.println(lock.hasDeadLock());
}
执行结果如下:
xid已经持有哪些uid x2u={1=[3], 2=[4], 3=[5]}
uid正在被哪个xid占用 u2x={3=1, 4=2, 5=3}
xid1的stamp是null
进入深搜
xidStamp找不到该xid,加入后xidStamp变为{1=2}
xid1正在等待的uid是4
xid1需要的uid被xid2占用了
=====再次进入深搜xid2====
xidStamp找不到该xid,加入后xidStamp变为{1=2, 2=2}
xid2正在等待的uid是null
未成环,退出深搜
xid3的stamp是null
进入深搜
xidStamp找不到该xid,加入后xidStamp变为{1=2, 2=2, 3=3}
xid3正在等待的uid是null
未成环,退出深搜
+++++++++++++++++++++++
xid已经持有哪些uid x2u={1=[3], 2=[4], 3=[5]}
uid正在被哪个xid占用 u2x={3=1, 4=2, 5=3}
xid1的stamp是null
进入深搜
xidStamp找不到该xid,加入后xidStamp变为{1=2}
xid1正在等待的uid是4
xid1需要的uid被xid2占用了
=====再次进入深搜xid2====
xidStamp找不到该xid,加入后xidStamp变为{1=2, 2=2}
xid2正在等待的uid是5
xid2需要的uid被xid3占用了
=====再次进入深搜xid3====
xidStamp找不到该xid,加入后xidStamp变为{1=2, 2=2, 3=2}
xid3正在等待的uid是null
未成环,退出深搜
++++++++++++++++
xid已经持有哪些uid x2u={1=[3], 2=[4], 3=[5]}
uid正在被哪个xid占用 u2x={3=1, 4=2, 5=3}
xid1的stamp是null
进入深搜
xidStamp找不到该xid,加入后xidStamp变为{1=2}
xid1正在等待的uid是4
xid1需要的uid被xid2占用了
=====再次进入深搜xid2====
xidStamp找不到该xid,加入后xidStamp变为{1=2, 2=2}
xid2正在等待的uid是5
xid2需要的uid被xid3占用了
=====再次进入深搜xid3====
xidStamp找不到该xid,加入后xidStamp变为{1=2, 2=2, 3=2}
xid3正在等待的uid是3
xid3需要的uid被xid1占用了
=====再次进入深搜xid1====
高并发场景如何做事务隔离
事务的隔离级别功能分析
锁和多版本控制(MVCC)技术就是用于保障隔离性的, InnoDB支持的隔离性有4种,从低到高分别是
- 读未提交(READ UNCOMMITTED)
- 读已提交(READ COMMITTED)
- 可重复读(REPEATABLE READ)
- 可串行化(SERIALIZABLE)。
读未提交(READ UNCOMMITTED)
在读未提交隔离级别下,允许脏读的情况发生。未提交意味着这些数据可能会回滚,读到了不一定最终存在的数据。读未提交隔离级别容易出现脏读问题;
脏读指的就是在不同的事务下,当前事务可以读到另外事务未提交的数据,简单说就是读到脏数据。 而所谓的脏数据是指事务对缓冲池中行记录的修改,并且还没有被提交。
如果读到了脏数据,即一个事务可以读到另一个事务中未提交的数据,显然违反了数据库的隔离性。

脏读发生的条件是需要事务的隔离级别为Read uncommitted, 在生产环境中,绝大部分数据库至少会设置成Read Committed ,所以在生产环境下发送的概率很小。
读已提交(READ COMMITTED)
只允许读到已提交的数据, 即事务A在将n从0累加到10的过程中, B无法看到n的中国值,只能看到10.
在已提交隔离级别下,禁止了脏读, 但是运行不可重复读的情况发生。
读已提交满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变.
oracle 、sql server 默认的隔离级别是读已提交。
读已提交隔离级别容易出现不可重复读问题.不可重复读是指一个事务内多次读取同一数据集合的数据不一样的情况。

事务A 多次读取同一数据,但事务B在事务A多次读取的过程中,对数据作了更新并比较,导致事务A多次读取同一数据时,结果不一致了。
脏读和不可重复读的区别是:脏读读到的是未提交的数据,而不可重复读读到的确实已提交的数据,但是违反了数据库事务一致性原则。
在一般情况下,不可重复读的问题是可以接受的,因为其读到的是已经提交的数据, 本身不会带来很大的问题。Oracle、SQL server 数据库事务的默认隔离级别设置为Read Committed,RC 隔离级别是允许不可重复读的现象。Mysql 默认的隔离级别是RR, 通过使用Next-Key Lock 算法来避免不可重复读的现象。
不可重复读和幻读的区别是:
- 不可重复读的重点在修改: 同样的条件,第一次读取过的数据,再次读取出来发现值不一样了。
- 幻读的重点在新增或删除:同样的条件,第一次和第二次读取出来的记录数不一样。
可重复读(REPEATABLE READ)
保证在事务过程中,多次读取同一数据时,其值都和事务开始时刻时是一致的。
在可重复读隔离级别下,禁止脏读和不可重复读,但是存在幻读。
幻读是指一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。
mysql 默认的隔离级别是 可重复读,查看mysql 当前数据库的事务隔离级别命令如下
show variables like 'tx_isolation';
或
select @@tx_isolation;
设置事务隔离级别:
set tx_isolation='READ-UNCOMMITTED';
set tx_isolation='READ-COMMITTED';
set tx_isolation='REPEATABLE-READ';
set tx_isolation='SERIALIZABLE';
可重复读在理论上,会导致另一个棘手的问题:幻读. 幻读至当前用户读取某一范围的数据行时 ,另一个事务又在该范围内插入新行,当用户再读取该范围的数据行时 ,会发现有新的"幻影"行. InnoDB存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。
可串行化(SERIALIZABLE)
最严格的事务,要求所有事务被串行执行,并不能并发执行.
它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题.
换句话说就是在每个读的数据行上加上共享锁.
可串行可能导致大量的超时现象和锁竞争.
总结:
| 隔离级别 | 脏读(Dirty Read) | 不可重复读(NoRepeatable Read) | 幻读(Phantom Read) |
|---|---|---|---|
| 读未提交(Read uncommitted) | 可能 | 可能 | 可能 |
| 读已提交(Read committed | 不可能 | 可能 | 可能 |
| 可重复读(Repeatable read) | 不可能 | 不可能 | 可能 |
| 可串行化(Serializable) | 不可能 | 不可能 | 不可能 |
MVCC
MVCC全称是Multi-Version Concurrent Control,即多版本并发控制,其原理与copyonwrite类似。
并发事务带来的问题
读-读
即并发事务相继读取同一记录.
因为读取记录并不会对记录造成任何影响,所以同个事务并发读取同一记录也就不存在任何安全问题,所以允许这种操作。不存在任何问题,也不需要并发控制.
写-写
即并发事务相继对同一记录做出修改.
如果允许并发事务都读取同一记录,并相继基于旧估对这一记录做出修改,那么就会出现前一个事务所做的修改被后面事务的修改覆盖,即出现提交覆盖的问题。
另外一种情况,并发事务相继对同一记录做出修改,其中一个事务提交之后之后另一个事务发生回滚,这样就会出现已提交的修改因为回滚而丢失的问题,即回滚覆盖问题.
所以是存在线程安全问题的,两种情况都可能存在更新丢失问题.
写-读或读-写
即两个并发事务对同一记录分别进行读操作和写操作。
如果一个事务读取了另一个事务尚未提交的修政记录,那么就出现了脏读的问题;
如果我们加以控制使得一个事务只能读取其他已提交事务的修改的数据,那么这个事务在另一个事务提交修改前后读取到的数据是不一样的,这就意味看发生了不可重复读;
如果一个事务根据一些条件查询到一些记录,之后另一事物向表中插入了一些记录,原先的事务以相同条件再次查询时发现得到的结果跟第一次查词得到的结果不一致,这就意味着发生了幻读。
针对写-读或读-写出现的问题,MySQL的InnoDB实现了MVCC来更好地处理读写冲突,可以做到即使存在并发读写,也可以不用加锁,实现"非阻塞并发读"。
那么,总结一下,需要MVCC的原因是由于数据库通常使用锁来实现隔离性,最原生的锁,锁住一个资源后会禁止其他任何线程访问统一资源。但是很多应用的一个特点是读多写少的场景,很多数据的读取次数远大于修改的次数,而读取数据间互相排斥显得不是很必要.所以就使用了一种读写锁的方法,读锁和读锁之间不互斥,而写锁和写锁、读锁都互斥。这样就很大提升了系统的并发能力。
之后人们发现并发读还是不够,又提出了能不能让读写之间也不冲突的方法,就是读取数据时通过一种类似快照的方式将数据保存下来,这样读锁就和写锁不冲突了,不同的事务session会看到自己特定版本的数据。当然快照是一种概念模型,不同的数据库可能用不同的方式来实现这种功能。
在MVCC协议下,每个读操作, 会看到一个一致性的snapshot 快照,并且可以实现非阻塞的读。读这个snapshot 快照,不用加锁。除了snapshot 快照版本之外, MVCC允许数据具有多个版本,版本编号可以是时间戳,或者是全局递
增的事务ID,在同一个时间点,不同的事务看到的数据是不同的。
首先,了解MVCC 之前,我们需要明确两个定义
- 当前读:读取的数据是最新版本,读取数据时还要保证其他并发事务不会修改当前的数据,当前读会对读取的记录加锁。比如:select …… lock in share mode(共享锁)、select …… for update | update | insert | delete(排他锁)
- 快照读:每一次修改数据,都会在 undo log 中存有快照记录,这里的快照,就是读取undo log中的某一版本的快照。这种方式的优点是可以不用加锁就可以读取到数据,缺点是读取到的数据可能不是最新的版本。一般的查询都是快照读,比如:select * from t_user where id=1; 在MVCC中的查询都是快照度。
mvcc 的实现原理
MySQL中MVCC主要是通过行记录中的隐藏字段(隐藏主键 row_id、事务ID trx_id、回滚指针 roll_pointer)、undo log(版本链)、ReadView(一致性读视图)来实现的。
隐藏字段
MySQL中,在每一行记录中除了自定义的字段,还有一些隐藏字段:
- row_id:当数据库表没定义主键时,InnoDB会以row_id为主键生成一个聚集索引。
- trx_id:事务ID记录了新增/最近修改这条记录的事务id,事务id是自增的。
- roll_pointer:回滚指针指向当前记录的上一个版本(在 undo log 中)。
ReadView
ReadView一致性视图主要是由两部分组成:所有未提交事务的ID数组和已经创建的最大事务ID组成。比如:[100,200],300。事务100和200是当前未提交的事务,而事务300是当前创建的最大事务(已经提交了)。当执行SELECT语句的时候会创建ReadView,但是在读取已提交和可重复读两个事务级别下,生成ReadView的策略是不一样的:读取已提交级别是每执行一次SELECT语句就会重新生成一份ReadView,而可重复读级别是只会在第一次SELECT语句执行的时候会生成一份,后续的SELECT语句会沿用之前生成的ReadView(即使后面有更新语句的话,也会继续沿用)。
ReadView 就是MVCC在对数据进行快照读时,会产生的一个"读视图"。ReadView中有4个比较重要的变量:
- m_ids:活跃事务id列表,当前系统中所有活跃的(也就是没提交的)事务的事务id列表。
- min_trx_id:m_ids 中最小的事务id。
- max_trx_id:生成 ReadView 时,系统应该分配给下一个事务的id(注意不是 m_ids 中最大的事务id),也就是m_ids 中的最大事务id + 1 。
- creator_trx_id:生成该 ReadView 的事务的事务id。
版本链
修改数据的时候,会向 redo log 中记录修改的页内容(为了在数据库宕机重启后恢复对数据库的操作),也会向 undo log 记录数据原来的快照(用于回滚事务)。undo log有两个作用,除了用于回滚事务,还用于实现MVCC。
用一个简单的例子来画一下MVCC中用到的undo log版本链的逻辑图:
当事务100(trx_id=100)执行了 insert into t_user values(1,‘弯弯’,30); 之后:

当事务102(trx_id=102)执行了 update t_user set name=‘李四’ where id=1; 之后:

当事务102(trx_id=102)执行了 update t_user set name=‘王五’ where id=1; 之后:

而具体版本链的比对规则如下,首先从版本链中拿出最上面第一个版本的事务ID开始逐个往下进行比对:

(其中min_id指向ReadView中未提交事务数组中的最小事务ID,而max_id指向ReadView中的已经创建的最大事务ID)
某个事务进行快照读时可以读到哪个版本的数据,ReadView 的规则如下:
(1)当版本链中记录的 trx_id 等于当前事务id(trx_id = creator_trx_id)时,说明版本链中的这个版本是当前事务修改的,所以该快照记录对当前事务可见。
(2)当版本链中记录的 trx_id 小于活跃事务的最小id(trx_id < min_trx_id)时,说明版本链中的这条记录已经提交了,所以该快照记录对当前事务可见。
(3)当版本链中记录的 trx_id 大于下一个要分配的事务id(trx_id > max_trx_id)时,该快照记录对当前事务不可见。
(4)当版本链中记录的 trx_id 大于等于最小活跃事务id且版本链中记录的trx_id小于下一个要分配的事务id(min_trx_id<= trx_id < max_trx_id)时,如果版本链中记录的 trx_id 在活跃事务id列表 m_ids 中,说明生成 ReadView 时,修改记录的事务还没提交,所以该快照记录对当前事务不可见;否则该快照记录对当前事务可见。
当事务对 id=1 的记录进行快照读时select * from t_user where id=1,在版本链的快照中,从最新的一条记录开始,依次判断这4个条件,直到某一版本的快照对当前事务可见,否则继续比较上一个版本的记录。
MVCC主要是用来解决RU隔离级别下的脏读和RC隔离级别下的不可重复读的问题,所以MVCC只在RC(解决脏读)和RR(解决不可重复读)隔离级别下生效,也就是MySQL只会在RC和RR隔离级别下的快照读时才会生成ReadView。
区别就是,在RC隔离级别下,每一次快照读都会生成一个最新的ReadView;在RR隔离级别下,只有事务中第一次快照读会生成ReadView,之后的快照读都使用第一次生成的ReadView。
MySQL 通过 MVCC,降低了事务的阻塞概率。
例如:T1 想要更新记录 X 的值,于是 T1 需要首先获取 X 的锁,接着更新,也就是创建了一个新的 X 的版本,假设为 x3。
假设 T1 还没有释放 X 的锁时,T2 想要读取 X 的值,这时候就不会阻塞,MYDB 会返回一个较老版本的 X,例如 x2。这样最后执行的结果,就等价于,T2 先执行,T1 后执行,调度序列依然是可串行化的。如果 X 没有一个更老的版本,那只能等待 T1 释放锁了。
所以只是降低了概率。
手写事务隔离级别
如果一个记录的最新版本被加锁,当另一个事务想要修改或读取这条记录时,MYDB 就会返回一个较旧的版本的数据。
这时就可以认为,最新的被加锁的版本,对于另一个事务来说,是不可见的。
已提交读
即事务在读取数据时, 只能读取已经提交事务产生的数据。
版本的可见性与事务的隔离度是相关的。
MYDB 支持的最低的事务隔离程度,是“读提交”(Read Committed),即事务在读取数据时, 只能读取已经提交事务产生的数据。保证最低的读提交的好处,第四章中已经说明(防止级联回滚与 commit 语义冲突)。
MYDB 实现读提交,为每个版本维护了两个变量,就是前面提到的 XMIN 和 XMAX:
- XMIN:创建该版本的事务编号
- XMAX:删除该版本的事务编号
XMIN 应当在版本创建时填写,而 XMAX 则在版本被删除,或者有新版本出现时填写。
XMAX 这个变量,也就解释了为什么 DM 层不提供删除操作,当想删除一个版本时,只需要设置其 XMAX,这样,这个版本对每一个 XMAX 之后的事务都是不可见的,也就等价于删除了。
在读提交下,版本对事务的可见性逻辑如下:
(XMIN == Ti and // 由Ti创建且XMAX == NULL // 还未被删除
)
or // 或
(XMIN is commited and // 由一个已提交的事务创建且(XMAX == NULL or // 尚未删除或(XMAX != Ti and XMAX is not commited) // 由一个未提交的事务删除
))
若条件为 true,则版本对 Ti 可见。那么获取 Ti 适合的版本,只需要从最新版本开始,依次向前检查可见性,如果为 true,就可以直接返回。
以下方法判断某个记录对事务 t 是否可见:
private static boolean readCommitted(TransactionManager tm, Transaction t, Entry e) {long xid = t.xid;long xmin = e.getXmin();long xmax = e.getXmax();if(xmin == xid && xmax == 0) return true;if(tm.isCommitted(xmin)) {if(xmax == 0) return true;if(xmax != xid) {if(!tm.isCommitted(xmax)) {return true;}}}return false;
}
可重复读
不可重复度,会导致一个事务在执行期间对同一个数据项的读取得到不同结果。如下面的结果,加入 X 初始值为 0:
T1 begin
R1(X) // T1 读得 0
T2 begin
U2(X) // 将 X 修改为 1
T2 commit
R1(X) // T1 读的
可以看到,T1 两次读 X,读到的结果不一样。如果想要避免这个情况,就需要引入更严格的隔离级别,即可重复读.
T1 在第二次读取的时候,读到了已经提交的 T2 修改的值(这个修改事务为原版本的XMAX,为新版本的XMIN),导致了这个问题。于是我们可以规定:事务只能读取它开始时,就已经结束的那些事务产生的数据版本.
这条规定,事务需要忽略2点:
(1) 在本事务后开始的事务的数据;
(2) 本事务开始时还是active状态的事务的数据.
对于第一条,只需要比较事务 ID,即可确定。而对于第二条,则需要在事务 Ti 开始时,记录下当前活跃的所有事务 SP(Ti),如果记录的某个版本,XMIN 在 SP(Ti) 中,也应当对 Ti 不可见。
于是,可重复读的判断逻辑如下:
(XMIN == Ti and // 由Ti创建且(XMAX == NULL or // 尚未被删除
))
or // 或
(XMIN is commited and // 由一个已提交的事务创建且XMIN < XID and // 这个事务小于Ti且XMIN is not in SP(Ti) and // 这个事务在Ti开始前提交且(XMAX == NULL or // 尚未被删除或(XMAX != Ti and // 由其他事务删除但是(XMAX is not commited or // 这个事务尚未提交或
XMAX > Ti or // 这个事务在Ti开始之后才开始或
XMAX is in SP(Ti) // 这个事务在Ti开始前还未提交
))))
于是,需要提供一个结构,来抽象一个事务,以保存快照数据(该事务创建时还活跃着的事务):
// vm对一个事务的抽象
public class Transaction {public long xid;public int level;public Map<Long, Boolean> snapshot;public Exception err;public boolean autoAborted;//事务id 隔离级别 快照public static Transaction newTransaction(long xid, int level, Map<Long, Transaction> active) {Transaction t = new Transaction();t.xid = xid;t.level = level;if(level != 0) {//隔离级别为可重复读,读已提交不需要快照信息t.snapshot = new HashMap<>();for(Long x : active.keySet()) {t.snapshot.put(x, true);}}return t;}public boolean isInSnapshot(long xid) {if(xid == TransactionManagerImpl.SUPER_XID) {return false;}return snapshot.containsKey(xid);}
}
构造方法中的 active,保存着当前所有 active 的事务。
于是,可重复读的隔离级别下,一个版本是否对事务可见的判断如下:
private static boolean repeatableRead(TransactionManager tm, Transaction t, Entry e) {long xid = t.xid;long xmin = e.getXmin();long xmax = e.getXmax();if(xmin == xid && xmax == 0) return true;if(tm.isCommitted(xmin) && xmin < xid && !t.isInSnapshot(xmin)) {if(xmax == 0) return true;if(xmax != xid) {if(!tm.isCommitted(xmax) || xmax > xid || t.isInSnapshot(xmax)) {return true;}}}return false;
}
版本跳跃
版本跳跃问题,考虑如下的情况,假设 X 最初只有 x0 版本,T1 和 T2 都是可重复读的隔离级别:
T1 begin
T2 begin
R1(X) // T1读取x0
R2(X) // T2读取x0
U1(X) // T1将X更新到x1
T1 commit
U2(X) // T2将X更新到x2
T2 commit
这种情况实际运行起来是没问题的,但是逻辑上不太正确。
T1 将 X 从 x0 更新为了 x1,这是没错的。但是 T2 则是将 X 从 x0 更新成了 x2,跳过了 x1 版本。
读提交是允许版本跳跃的,而可重复读则是不允许版本跳跃的。
解决版本跳跃的思路:如果 Ti 需要修改 X,而 X 已经被 Ti 不可见的事务 Tj 修改了,那么要求 Ti 回滚。
MVCC 的实现,使得撤销或是回滚事务时:只需要将这个事务标记为 aborted 即可。
根据前一章提到的可见性,每个事务都只能看到其他 committed 的事务所产生的数据,一个 aborted 事务产生的数据,就不会对其他事务产生任何影响了,也就相当于,这个事务不曾存在过
if(Visibility.isVersionSkip(tm, t, entry)) {System.out.println("检查到版本跳跃,自动回滚");t.err = Error.ConcurrentUpdateException;internAbort(xid, true);t.autoAborted = true;throw t.err;
}
前面我们总结了,Ti 不可见的Tj,有两种情况:
(1) XID(Tj) > XID(Ti) 修改版本在Ti之后创建
(2) Tj in SP(Ti) Ti创建时修改版本已经创建但是还未提交
版本跳跃的检查首先取出要修改数据X的最新提交版本,并检查该最新版本的创建者对当前事务是否可见.具体实现如下:
public static boolean isVersionSkip(TransactionManager tm, Transaction t, Entry e) {long xmax = e.getXmax();if(t.level == 0) {return false;} else {return tm.isCommitted(xmax) && (xmax > t.xid || t.isInSnapshot(xmax));}
}
作者介绍:
一作:Mark, 资深大数据架构师、Java架构师,近20年Java、大数据架构和开发经验。资深架构导师,成功指导了多个中级Java、高级Java转型架构师岗位。
二作:尼恩,资深系统架构师、IT领域资深作家、著名博主。近20年高性能Web平台、高性能通信、高性能搜索、数据挖掘等领域的3高架构研究、系统架构、系统分析、核心代码开发工作。资深架构导师,成功指导了多个中级Java、高级Java转型架构师岗位。
说在后面:
持续迭代、持续升级 是 尼恩团队的宗旨,
持续迭代、持续升级 也是 《从0开始,手写MySQL》的灵魂。
后面会收集更多的面试真题,同时,遇到面试难题,可以来尼恩的社区《技术自由圈(原疯狂创客圈)》中交流和求助。
咱们的目标,打造宇宙最牛的《手写MySQL》面试宝典。
技术自由的实现路径 PDF:
实现你的 架构自由:
《吃透8图1模板,人人可以做架构》
《10Wqps评论中台,如何架构?B站是这么做的!!!》
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
《100亿级订单怎么调度,来一个大厂的极品方案》
《2个大厂 100亿级 超大流量 红包 架构方案》
… 更多架构文章,正在添加中
实现你的 响应式 自由:
《响应式圣经:10W字,实现Spring响应式编程自由》
这是老版本 《Flux、Mono、Reactor 实战(史上最全)》
实现你的 spring cloud 自由:
《Spring cloud Alibaba 学习圣经》
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
实现你的 linux 自由:
《Linux命令大全:2W多字,一次实现Linux自由》
实现你的 网络 自由:
《TCP协议详解 (史上最全)》
《网络三张表:ARP表, MAC表, 路由表,实现你的网络自由!!》
实现你的 分布式锁 自由:
《Redis分布式锁(图解 - 秒懂 - 史上最全)》
《Zookeeper 分布式锁 - 图解 - 秒懂》
实现你的 王者组件 自由:
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《缓存之王:Caffeine 的使用(史上最全)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
实现你的 面试题 自由:
4000页《尼恩Java面试宝典 》 40个专题
尼恩 架构笔记、面试题 的PDF文件更新,请到下面《技术自由圈》公号取↓↓↓
相关文章:
从0开始,手写MySQL事务
说在前面:从0开始,手写MySQL的学习价值 尼恩曾经指导过的一个7年经验小伙,凭借精通Mysql, 搞定月薪40K。 从0开始,手写一个MySQL的学习价值在于: 可以深入地理解MySQL的内部机制和原理,Mysql可谓是面试的…...
React中useState的setState方法请求了好多次
1、问题描述 最近在写react的时候碰到了一个很奇怪的问题。 可以看到那个getXXX()的方法一直不断的被调用,网页一直请求,根本停不下来了。 2、产生原因 要弄明白这个原因,首先要先了解一下react生命周期。 react是组件式的编程,一…...

【MYSQL基础】基础命令介绍
基础命令 MYSQL注释方式 -- 单行注释/* 多行注释 哈哈哈哈哈 哈哈哈哈 */连接数据库 mysql -u root -p12345678退出数据库连接 使用exit;命令可以退出连接 查询MYSQL版本 mysql> select version(); ----------- | version() | ----------- | 8.0.27 | ----------- 1…...

多元回归预测 | Matlab基于灰狼算法优化深度置信网络(GWO-DBN)的数据回归预测,matlab代码回归预测,多变量输入模型
文章目录 效果一览文章概述部分源码参考资料效果一览 文章概述 多元回归预测 | Matlab基于灰狼算法优化深度置信网络(GWO-DBN)的数据回归预测,matlab代码回归预测,多变量输入模型,matlab代码回归预测,多变量输入模型,多变量输入模型 评价指标包括:MAE、RMSE和R2等,代码质…...
校园wifi网页认证登录入口
很多校园wifi网页认证登录入口是1.1.1.1 连上校园网在浏览器写上http://1.1.1.1就进入了校园网 使 用 说 明 一、帐户余额 < 0.00元时,帐号被禁用,需追加网费。 二、在计算中心机房上机的用户,登录时请选择新建帐号时给您指定的NT域&…...
[SpringBoot]Spring Security框架
目录 关于Spring Security框架 Spring Security框架的依赖项 Spring Security框架的典型特征 关于Spring Security的配置 关于默认的登录页 关于请求的授权访问(访问控制) 使用自定义的账号登录 使用数据库中的账号登录 关于密码编码器 使用BCry…...

Unity 之 抖音小游戏本地数据最新存储方法分享
Unity 之 抖音小游戏本地数据最新存储方法分享 一、抖音小游戏文件存储系统背景二、文件存储系统的使用方法2.1 初始化2.1 创建目录2.3 存储数据2.4 删除目录/文件2.5 其他相关操作 三,小结 抖音小游戏是一种基于抖音平台开发的小型游戏,与传统的 APP 不…...

逍遥自在学C语言 | 函数初级到高级解析
前言 函数是C语言中的基本构建块之一,它允许我们将代码组织成可重用、模块化的单元。 本文将逐步介绍C语言函数的基础概念、参数传递、返回值、递归以及内联函数和匿名函数。 一、人物简介 第一位闪亮登场,有请今后会一直教我们C语言的老师 —— 自在…...

Elastic 推出 Elastic AI 助手
作者:Mike Nichols Elastic 推出了 Elastic AI Assistant,这是一款由 ESRE 提供支持的开放式、生成式 AI 助手,旨在使网络安全民主化并支持各种技能水平的用户。 最近发布的 Elasticsearch Relevance Engine™ (ESRE™) 提供了用于创建高度相…...
【数据库】MySQL安装(最新图文保姆级别超详细版本介绍)
1.总共两部分(第二部可省略) 安装mysql体验mysql环境变量配置 1.1安装mysql 1.输入官网地址https://www.mysql.com/ 下载完成后,我们双击打开我们的下载文件 打开后的界面,如图所示 我们选择custom,点击nex…...

前端使用pdf-lib库实现pdf合并,window.open预览合并后的pdf
最近出差开了好多发票,写了一个pdf合并网站,用于把多张发票pdf合并成一张,方便打印 使用pdf-lib这个库实现的pdf合并功能,预览使用的是浏览器自身查看pdf功能 源码 网页地址 https://zqy233.github.io/PDF-merge/ <!DOCTYPE h…...
)
计算机网络相关知识点总结(二)
比特bit是计算机中数据量的最小单位,可简记为b。字节Byte也是计算机中数据量的单位,可简记为B,1B8bit。常用的数据量单位还有kB、MB、GB、TB等,其中k、M、G、T的数值分别为 2 10 2^{10} 210, 2 20 2^{20} 220, 2 30 2^{30} 230, 2 40 2^{40} 240。 K, M, G, T 分别对应以下…...
)
Redmine与Gitlab整合(实战版)
网上查了很多文章,总结一下。 安装过程略。可参考:(84条消息) Redmine与Gitlab功能集成_redmine gitlab_羽之大公公的博客-CSDN博客 配置集成的方法,参考: Redmine与GitLab集成 (ngui.cc) 修改ssh-key密码的方法,参…...
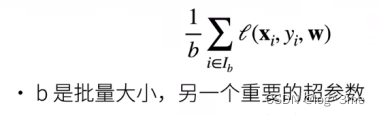
(3)深度学习学习笔记-简单线性模型
文章目录 一、线性模型二、实例1.pytorch求导功能2.简单线性模型(人工数据集) 来源 一、线性模型 一个简单模型:假设一个房子的价格由卧室、卫生间、居住面积决定,用x1,x2,x3表示。 那么房价y就可以认为yw…...
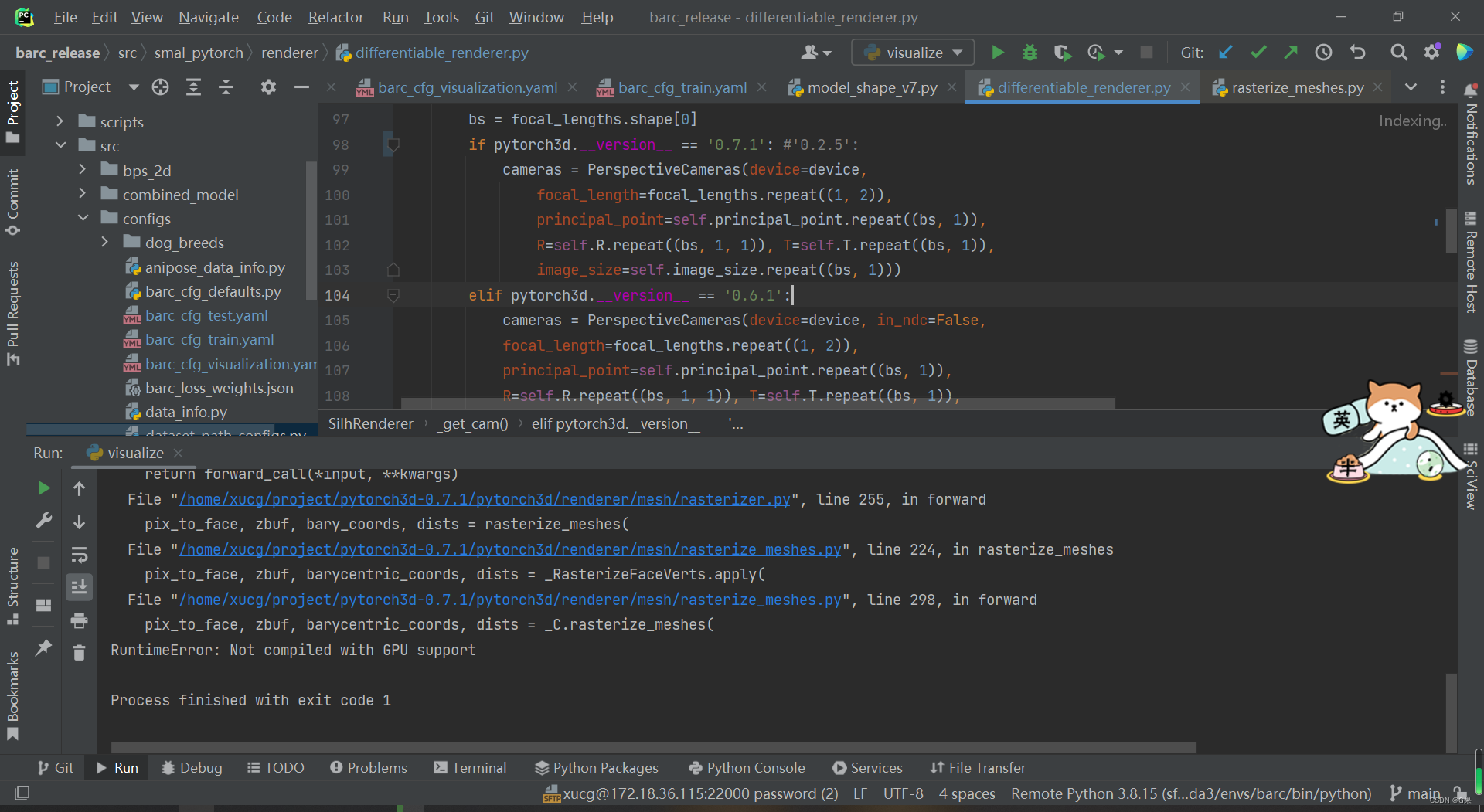
pytorch3d 安装报错 RuntimeError: Not compiled with GPU support pytorch3d
安装环境 NVIDIA GeForce RTX 3090 cuda 11.3 python 3.8.5 torch 1.11.0 torchvision 0.12.0 环境安装命令 conda install pytorch1.11.0 torchvision0.12.0 torchaudio0.11.0 cudatoolkit11.3 -c pytorch安装pytorch3d参考官网链接 https://github.com/facebookresearch/p…...

spring工程的启动流程?bean的生命周期?提供哪些扩展点?管理事务?解决循环依赖问题的?事务传播行为有哪些?
1.Spring工程的启动流程: Spring工程的启动流程主要包括以下几个步骤: 加载配置文件:Spring会读取配置文件(如XML配置文件或注解配置)来获取应用程序的配置信息。实例化并初始化IoC容器:Spring会创建并初…...

使用 Zabbix 监控 RocketMQ列举监控项和触发器
在使用 Zabbix 监控 RocketMQ 的过程中,以下是一些可能的监控项和触发器: 监控项 集群总体健康状况生产者和消费者的连接数量Broker 的状态消息的生产和消费速度队列深度(即队列中的消息数量)磁盘空间使用内存使用CPU使用网络流…...

uniApp:路由与页面跳转及传参
方式一:声明式导航 声明式导航,通过组件进行跳转。官方文档:详情 使用 navigator 组件进行页面跳转。 属性类型默认值说明urlString应用内的跳转链接,值为相对路径或绝对路径,如:“…/first/first”&#x…...
Java中操作文件(二)
目录 一、什么是数据流 二、InputStream概述 2.1、方法 2.2、说明 三、FileInputStream概述 3.1、构造方法 3.2、利用Scanner进行字符串读取,简化操作 四、OutputStream概述 4.1、方法 4.2、PrinterWriter简化写操作 五、小程序练习 示例1 示例…...

springboot+vue在线考试系统(java项目源码+文档)
风定落花生,歌声逐流水,大家好我是风歌,混迹在java圈的辛苦码农。今天要和大家聊的是一款基于springboot的在线考试系统。项目源码以及部署相关请联系风歌,文末附上联系信息 。 💕💕作者:风歌&a…...

挑战复杂功能,让快马AI成为你微信小程序开发的智能编程搭档
最近在开发一个微信小程序时,遇到了一个比较复杂的自定义组件需求:一个可以左右滑动切换日期、并显示对应日程的周视图日历。这个功能看似简单,但实际开发中涉及到日期计算、滑动事件处理、数据绑定等多个难点。好在发现了InsCode(快马)平台&…...
Translumo完全指南:5分钟掌握实时屏幕翻译,打破语言障碍
Translumo完全指南:5分钟掌握实时屏幕翻译,打破语言障碍 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo…...

颠覆式图像分层黑科技:layerdivider让设计效率提升95%的秘密
颠覆式图像分层黑科技:layerdivider让设计效率提升95%的秘密 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 设计效率的革命性突破࿱…...

Blueman:Linux系统蓝牙管理的高效解决方案
Blueman:Linux系统蓝牙管理的高效解决方案 【免费下载链接】blueman Blueman is a GTK Bluetooth Manager 项目地址: https://gitcode.com/gh_mirrors/bl/blueman 在Linux桌面环境中,蓝牙设备管理长期面临着易用性与功能性难以兼顾的挑战。Bluema…...

BMC监控实战:用Python+IPMI打造服务器硬件健康巡检系统
BMC监控实战:用PythonIPMI打造服务器硬件健康巡检系统 当服务器机房的报警铃声在深夜响起,运维团队最需要的是快速定位问题根源——是CPU过热触发了保护机制?还是某个风扇模块突然停转?传统的人工巡检方式在现代化数据中心早已力不…...

FastAPI 2.0流式响应性能翻倍的4个隐藏配置:uvloop优化、httpx异步客户端复用、response_model_exclude_unset调优、asyncpg连接池预热
第一章:FastAPI 2.0流式响应性能翻倍的全景认知FastAPI 2.0 引入了原生异步流式响应(StreamingResponse)的底层重构,通过移除中间层缓冲、直接对接 ASGI 服务器的 send 协议,并支持零拷贝字节流分块推送,显…...

Oracle错误代码实战指南:从ORA-00001到ORA-02899的快速排查手册
Oracle数据库错误代码实战排查指南:从原理到解决方案 1. 理解Oracle错误代码体系 Oracle数据库的错误代码体系采用"ORA-XXXXX"的格式,其中前五位数字代表特定错误类型。这些错误代码并非随机排列,而是按照功能模块进行了系统分类…...

突破语言壁垒:FigmaCN开源插件让设计界面全中文呈现
突破语言壁垒:FigmaCN开源插件让设计界面全中文呈现 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 作为一名设计师,你是否也曾在使用Figma时因全英文界面而频繁…...

Ubuntu 20.04 下 LVI-SAM 复现全记录:从 gtsam 版本踩坑到 OpenCV 头文件修改
Ubuntu 20.04 下 LVI-SAM 复现实战:从 gtsam 版本适配到 OpenCV 接口升级全解析 在机器人感知与定位领域,LVI-SAM 作为融合激光雷达与视觉信息的 SLAM 系统,因其优异的实时性和鲁棒性备受关注。然而其复杂的依赖环境配置常常让开发者陷入&quo…...
)
RabbitMQ 3.13.0实战:5分钟搞定MQTT 5.0协议配置与特性测试(附Docker命令)
RabbitMQ 3.13.0实战:5分钟搞定MQTT 5.0协议配置与特性测试(附Docker命令) 物联网开发者们,好消息!RabbitMQ 3.13.0正式支持MQTT 5.0协议了。作为消息中间件的标杆产品,这次更新让RabbitMQ在物联网领域的竞…...