Elasticsearch原理剖析
一、 Elasticsearch结构
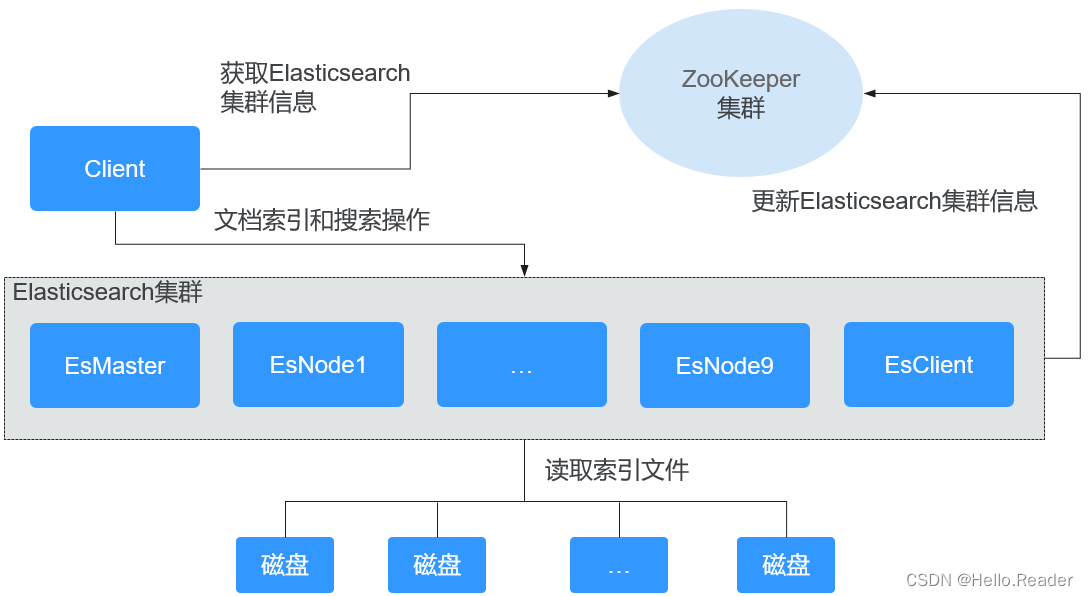
Elasticsearch集群方案由EsMaster、EsClient和EsNode1、EsNode2、EsNode3、EsNode4、EsNode5、EsNode6、EsNode7、EsNode8、EsNode9进程组成,如下图所示,模块说明如表下所示。
说明如表:
| 名称 | 说明 |
|---|---|
| Client | Client使用HTTP或HTTPS协议同Elasticsearch集群中的EsClient以及各EsNode实例进程进行通信,进行分布式索引和分布式搜索操作。 |
| EsMaster | EsMaster为Elasticsearch的主节点,负责集群的管理,主要是集群相关的操作,如决定分片的分配、跟踪集群节点等。 |
| EsNode1-9 | EsNode1-9为Elasticsearch的数据节点,主要是存储索引数据,对文档进行增删改查、聚合等操作。 |
| EsClient | EsClient为Elasticsearch的协调节点,只处理路由请求、搜索,及分发索引等操作。自身不存储数据,也不管理集群。 |
| ZooKeeper集群 | ZooKeeper为Elasticsearch集群中各进程提供心跳感应机制 |
二、Elasticsearch基本概念
-
Index: 即索引,是Elasticsearch中一个逻辑命名空间,指向一个或多个分片,内部Apache Lucene实现索引中数据的读写。索引与关系数据库实例Table相当。一个Elasticsearch实例可以包含多个索引。
-
Document: 文档,是可以被索引的基本单位,特指最顶层结构或根对象序列化成的JSON数据。相当于数据库中的Row。一个索引包含多个文档。
-
Mapping:映射,用来约束字段的类型,可以根据数据自动创建。相当于数据库中的Schema。
-
Field: 字段,组成文档的最小单位。相当于数据库中的Column。每个文档包含多个字段。
-
EsMaster: 主节点,可以临时管理集群级别的一些变更,例如新建或删除索引、增加或移除节点等。主节点不参与文档级别的变更或搜索,也不接收请求。在流量增长时,该主节点不会成为集群的瓶颈。
-
EsNode: Elasticsearch节点,一个节点就是一个Elasticsearch实例。
-
EsClient: Elasticsearch节点,该节点只能路由请求,处理搜索减少阶段和分发批量索引。其自身不进行数据存储,也没有管理集群的能力。
-
Shard: 分片,Elasticsearch中最小级别的工作单元,文档存储在分片中,并且在分片中被索引。
-
Primary Shard: 主分片,索引中的每个文档属于一个单独的主分片,主分片的数量决定了索引最多能存储多少数据。
-
Replica Shard: 复制分片,它是主分片的一个副本,可以防止硬件故障导致的数据丢失,同时可以提供读请求,比如搜索或者从别的shard取回文档。
-
Recovery: 代表数据恢复或叫数据重新分布,Elasticsearch在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,故障的节点重新启动时也会进行数据恢复。
-
Gateway: 代表Elasticsearch索引快照的存储方式,默认是先把索引存放到内存中,当内存满了时再持久化到本地硬盘。Gateway对索引快照进行存储,当这个Elasticsearch集群关闭再重新启动时就会从Gateway中读取索引备份数据。支持多种类型的Gateway,有本地文件系统(默认),分布式文件系统,Hadoop的HDFS。
-
Transport: 代表Elasticsearch内部节点或集群与客户端的交互方式,默认内部是使用TCP协议进行交互,同时它支持HTTP协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)。
-
ZooKeeper集群: 在Elasticsearch是必须的,为其提供安全认证信息的存储等功能。
三、Elasticsearch原理
1.Elasticsearch内部架构
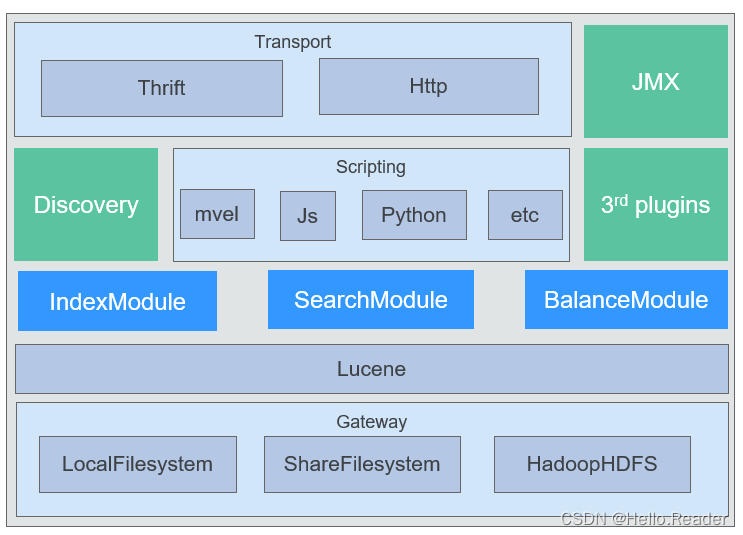
Elasticsearch通过RESTful API或者其他语言(比如Java)API提供丰富访问接口,使用集群发现机制,支持脚本语言,支持丰富的插件。底层基于Lucene,保持Lucene绝对的独立性,通过本地文件、共享文件、HDFS完成索引存储,如下图所示。
2.倒排序索引
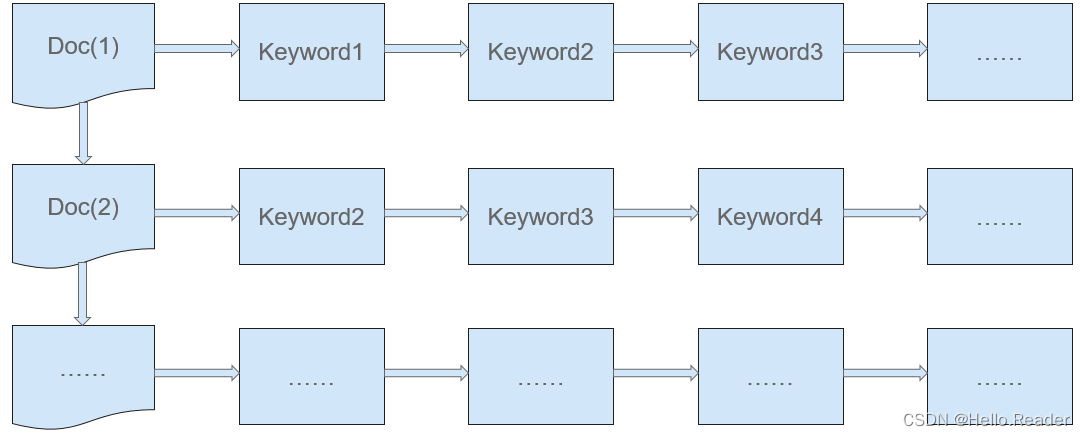
传统的搜索方式(正排序索引,如图3所示)按照文档编号进行搜索,搜索时要扫描每个文档关键字的信息,直到找出所有满足条件的关键字的信息。正排序索引的优点是易于维护,缺点搜索耗时太长。如下图所示:
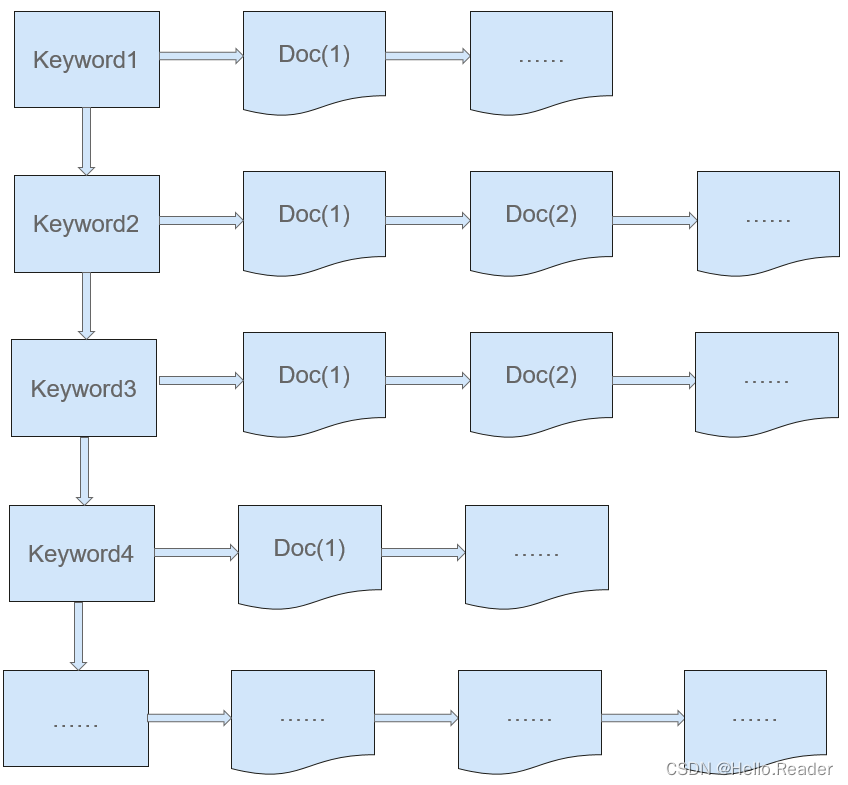
而Elasticsearch(Lucene)的搜索则是采用了倒排序索引(如下图所示)的方式。由不同的关键字组成的表,称为“词典”,其中包含了各种关键字和关键字的统计信息(包含所在文档编号,文档中位置和出现频率等)。通过倒排序索引进行搜索,就是通过关键字查询相对应的文档编号和文档中所在位置,再找到完整文档,类似于查字典,或通过查书目录查指定页码书的内容。倒排在构建索引时较为耗时且维护成本较高,但是搜索耗时短。
2.Elasticsearch分布式索引流程
Elasticsearch分布式索引操作流程如下图所示。
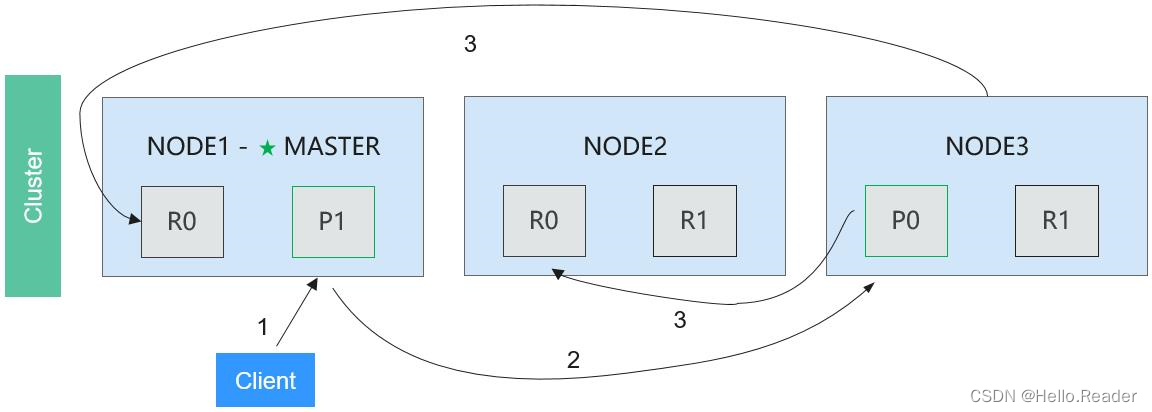
操作流程说明如下:
阶段1: 客户端发送一个索引请求给任意节点,假设是Node 1。
阶段2: Node 1通过请求判断出该文档应该被存储的分片,假设是shard 0这个分片中,因此Node 1会把请求转发到shard 0的primary shard P0存在的Node 3节点上。
阶段3: Node 3在shard 0的primary shard P0上执行请求。如果请求执行成功,Node 3并行地将该请求发给shard 0的所有存在于Node 1和Node 2中的replica shard R0上。如果所有的replica shard都成功地执行了请求,那么将会向Node 3回复一个成功确认,当Node 3收到了所有replica shard的确认信息后,则向用户返回一个Success消息。
3.Elasticsearch分布式搜索流程
Elasticsearch分布式搜索操作流程分为两个阶段,即查询阶段与获取阶段。分布式搜索操作流程之查询阶段如下图所示:
3.1分布式搜索操作流程之查询阶段
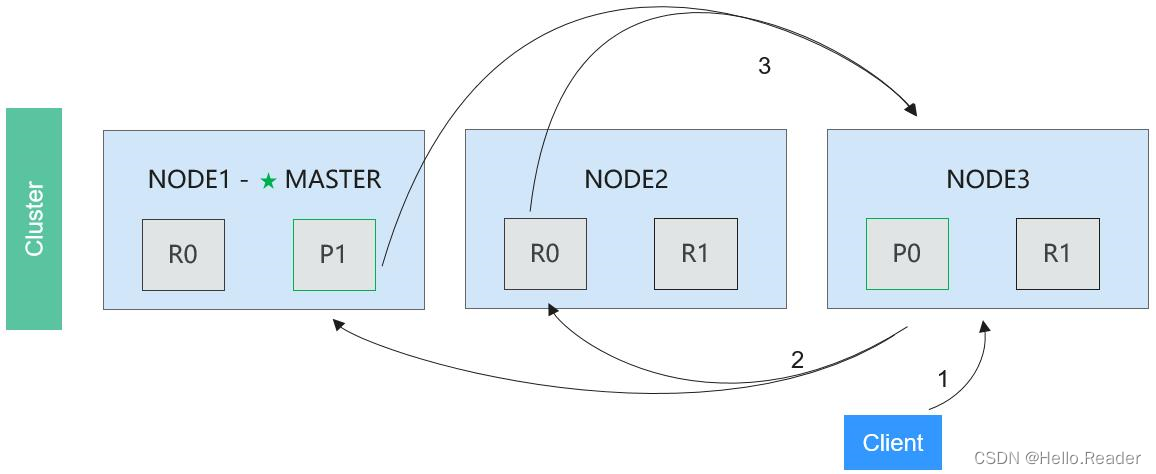 操作流程说明如下:
操作流程说明如下:
阶段1: 客户端发送一个检索请求给任意节点,假设是Node 3。
阶段2: Node 3将检索请求发送给该index中的每一个shard,此时会采取轮询策略,在primary shard及其所有replica shard中随机选择一个,让读请求负载均衡。每个shard在本地执行检索,并将结果排序添加到本地。
阶段3: 每个shard返回本地所记录的结果,发送给Node 3。Node 3将这些值合并,做全局排序。
查询阶段主要定位了所要检索数据的具体位置,而获取阶段的任务就是将这些定位好的数据内容取回并返回给客户端。获取阶段如下图所示:
3.2分布式搜索操作流程之获取阶段
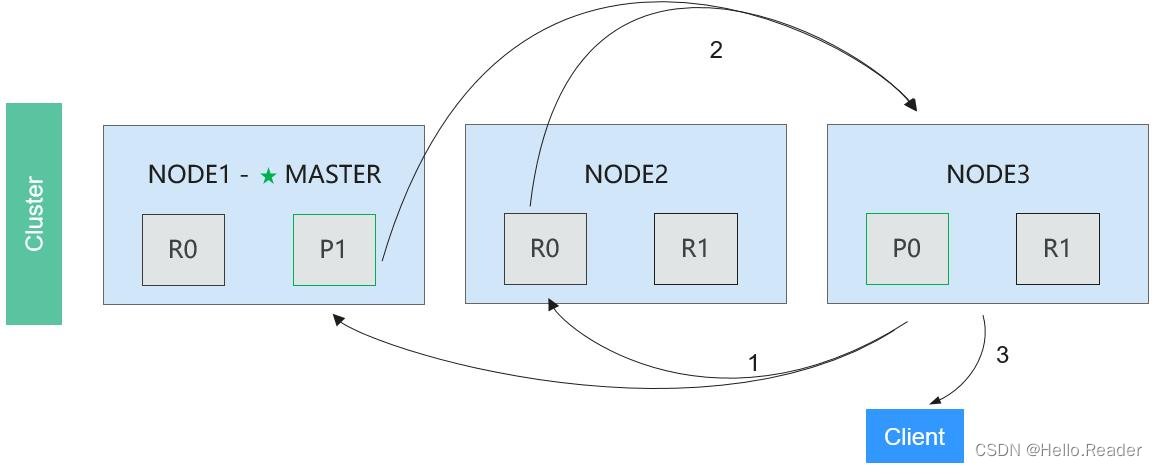 操作流程说明如下:
操作流程说明如下:
阶段1: Node 3获取了所有待检索数据的定位之后,发送请求给与数据相关的shard。
阶段2: 每个收到Node 3请求的shard,将读取相关文档中的内容,并将它们返回给Node 3。
阶段3: 当Node 3获取到了所有shard返回的文档后,Node 3将它们合并成一条汇总结果,返回给客户端。
4.Elasticsearch分布式批量索引流程
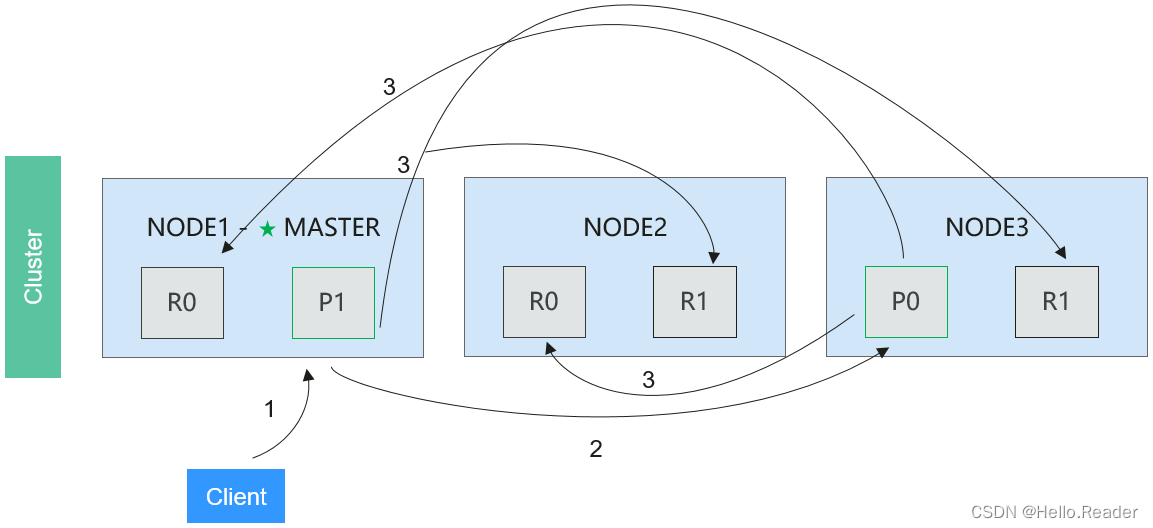
操作流程说明如下:
阶段1: 客户端向Node 1发送bulk请求。
阶段2: Node 1为每个分片构建批量请求,然后转发到这些请求所需的主分片上。
阶段3: 主分片一个接一个的按序执行操作。当一个操作执行完,主分片转发新文档(或者删除部分)给对应的复制节点,然后执行下一个操作。复制节点操作完成后报告给请求节点,请求节点整
5.Elasticsearch分布式批量搜索流程
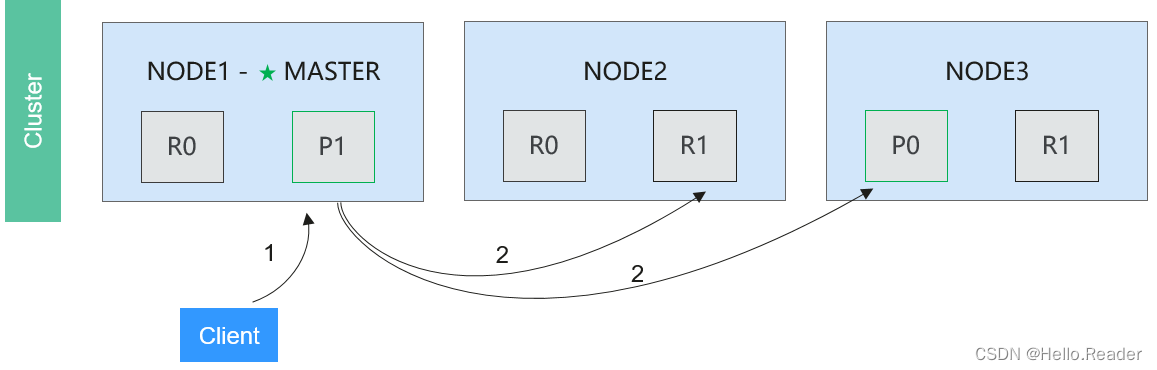 操作流程说明如下:
操作流程说明如下:
阶段1: 客户端向Node 1发送mget请求。
阶段2: Node 1为每个分片构建一个多条数据检索请求,然后转发到这些请求所需的主分片或复制分片上。当所有回复被接收,Node 1构建响应并返回给客户端。
6.Elasticsearch路由算法
Elasticsearch中提供了两种路由算法:
- 默认路由:shard=hash(routing)%number_of_primary_shards
- 自定义路由:该路由方式,通过指定routing的方式,可以影响文档写入到哪个shard,也可以仅仅检索特定的shard。
7.Elasticsearch平衡算法
Elasticsearch中提供了自动平衡功能,适用于扩容、减容、导入数据场景。算法如下:
- weight_index(node, index) = indexBalance * (node.numShards(index) - avgShardsPerNode(index))
- Weight_node(node, index) = shardBalance * (node.numShards() -avgShardsPerNode)
- weight(node, index) = weight_index(node, index) + weight_node(node,index)
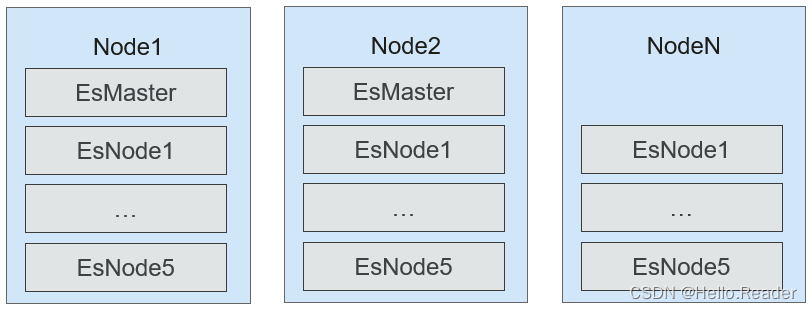
8.Elasticsearch单节点多实例部署
在同一个节点上部署多个Elasticsearch实例,根据IP和不同的端口号来区分不同的Elasticsearch实例。可以提高单节点CPU、内存和磁盘的利用率,同时提高Elasticsearch的索引和搜索能力。具体部署如下图所示:
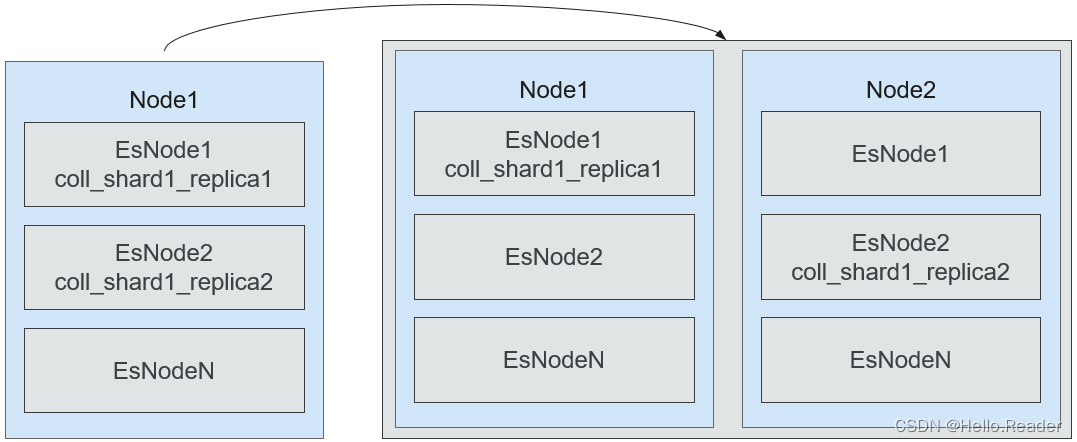
9.Elasticsearch副本自动跨节点分配策略
单节点多实例部署下,多副本时,如果只做到跨实例分配,存在单点故障,增加默认配置cluster.routing.allocation.same_shard.host:true即可。
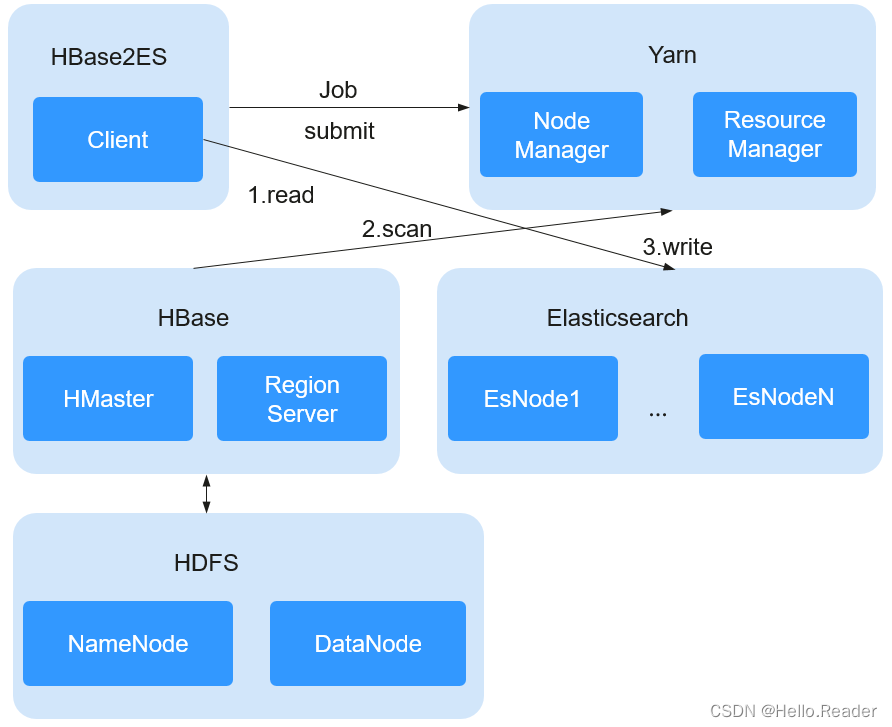
四、Elasticsearch与HBase的关系
Elasticsearch索引HBase数据是将HBase数据写到HDFS的同时,Elasticsearch建立相应的HBase索引数据。其中索引ID与HBase数据的rowkey对应,保证每条索引数据与HBase数据的唯一,实现HBase数据的全文检索。
批量索引: 针对HBase中已有的数据,通过提交MapReduce任务的形式,将HBase中的全部数据读出,然后在Elasticsearch中建立索引,索引过程如下图所示:
相关文章:
Elasticsearch原理剖析
一、 Elasticsearch结构 Elasticsearch集群方案由EsMaster、EsClient和EsNode1、EsNode2、EsNode3、EsNode4、EsNode5、EsNode6、EsNode7、EsNode8、EsNode9进程组成,如下图所示,模块说明如表下所示。 说明如表: 名称说明ClientClient使用H…...

数据在内存中的存储1(C语言进阶)
数据在内存中的存储 1.数据类型介绍1.1类型的基本归类:整形家族浮点数家族构造类型指针类型空类型 2.整形在内存中的存储2.1 原码、反码、补码2.2 大小端介绍为什么有大端和小端: 我们今天来学习数据在内存中的存储 1.数据类型介绍 前面我们已经学习了基…...

Kubernetes API Server 中启用 pprof 接口
要在 Kubernetes API Server 中启用 pprof 接口,你需要在 API Server 的启动参数或配置文件中进行相应的配置。以下是一些常见的方法: 通过启动参数启用 pprof 接口:在运行 API Server 的命令中,添加 -runtime-configapi/alltrue …...
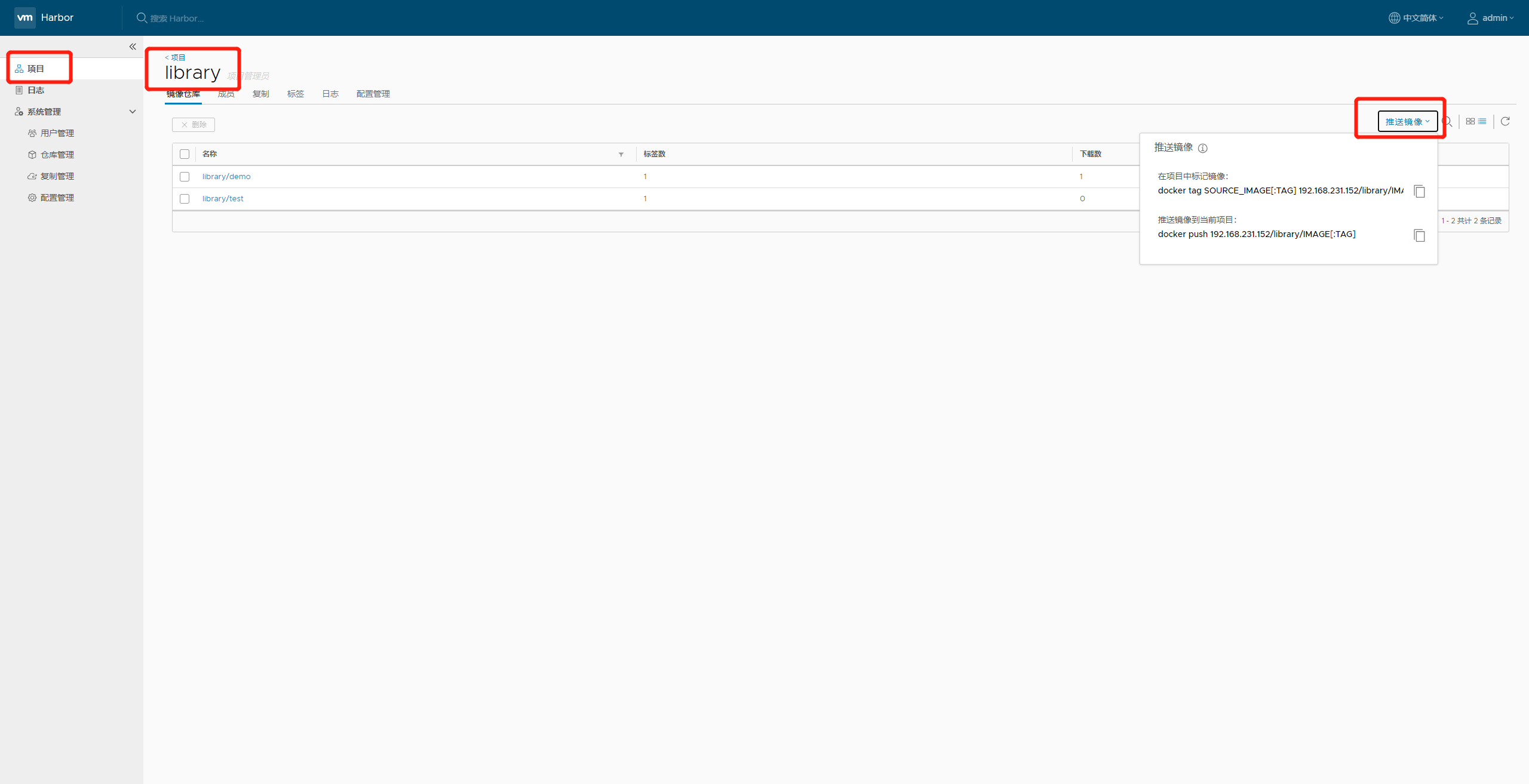
Docker 私有仓库 harbor 搭建
🎈 作者:Linux猿 🎈 简介:CSDN博客专家🏆,华为云享专家🏆,Linux、C/C、云计算、物联网、面试、刷题、算法尽管咨询我,关注我,有问题私聊! &…...
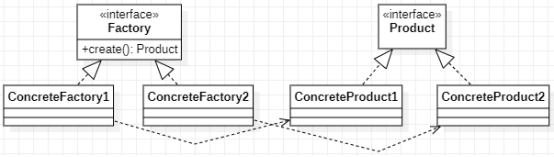
工厂方法模式
在开发组件的时候比如button、text等,需要对这些组件做比较多的初始化工作,比如初始化长度等。传统的开发方案如下: 图 传统开发方案UML 上面的方案组件创建及组件的其他业务操作耦合在一起,违背了单一职责原则;在客户…...

(CentOS 7)nvidia-smi:Failed to initialize NVML: Driver/library version mismatch
[CentOS 7]nvidia-smi:Failed to initialize NVML: Driver/library version mismatch 问题源头: nvidia-smi \text{nvidia-smi} nvidia-smi报错问题 CUDA \text{CUDA} CUDA安装时的问题 这里仅描述自身发现的一种情况,希望对大家有所帮助。 问题源头&…...

呼吸灯——FPGA
文章目录 前言一、呼吸灯是什么?1、介绍2、占空比调节示意图 二、系统设计1、系统框图2、RTL视图 三、源码四、效果五、总结六、参考资料 前言 环境: 1、Quartus18.0 2、vscode 3、板子型号:EP4CE6F17C8 要求: 将四个LED灯实现循环…...
)
群辉用户接入vocechat的方法(附开通GPT机器人)
群辉安装聊天服务器-加入chatgpt vocechat项目简单的使用介绍集成群辉帐号系统登陆vocechat 第二章接入chatgpt这是一个机器人的演示 这是个处于发展中的不错的项目吧,才感觉到好神奇。有意思。 vocechat项目简单的使用介绍 昨天的找群辉文章的时候看到了vocechat&…...

flutter js交互传参
加载网页的webView WebView(initialUrl:http://test/h5atui//#/mobileMaps?lng${CommonConfig.lng}&lat${CommonConfig.lat},javascriptMode: JavascriptMode.unrestricted,onWebViewCreated: (controller) {_webViewController controller;},onProgress: (process){set…...
重磅IntelliJ IDEA 2023.2 新版本即将发布,拥抱 AI
IntelliJ IDEA 近期连续发布多个EAP版本,官方在对用户体验不断优化的同时,也新增了一些不错的功能,尤其是人工智能助手补充,AI Assistant,相信在后续IDEA使用中,会对开发者工作效率带来不错的提升。 以下是…...

JavaWeb_SpringCloud微服务_Day1-eureka, ribbon, nacos
JavaWeb_SpringCloud微服务_Day1-eureka, ribbon, nacos 认识微服务微服务技术对比 分布式服务架构案例远程调用 eureka注册中心原理搭建EurekaServer服务注册服务发现 Ribbon负载均衡修改负载均衡饥饿加载 nacos注册中心快速入门eureka和nacos对比 来源 认识微服务 微服务技术…...

数据科学领域常用python库
pandas Pandas 的名称源自 “ panel data ”,这是一个计量经济学术语,用于表示多维结构化数据集和 “ Python 数据分析”。众所周知,清理和转换数据在数据分析中非常重要,Pandas 提供了丰富的数据结构和功能,使数据处…...

【Android关键字】startActivityForResult/onActivityResult/setResult方法的使用
最近在写一个安卓程序,在程序里需要用到startActivityForResult这个Intent操作关键字,与该关键字有关的还有onActivityResult和setResult。这里对其用法进行一个总结。 三者在API中的形式 //startActivityForResult与startActivity类似,只不…...

PyTorch深度学习实战(5)——计算机视觉
PyTorch深度学习实战(5)——计算机视觉 0. 前言1. 图像表示2. 将图像转换为结构化数组2.1 灰度图像表示2.2 彩色图像表示 3 利用神经网络进行图像分析的优势小结系列链接 0. 前言 计算机视觉是指通过计算机系统对图像和视频进行处理和分析,利…...
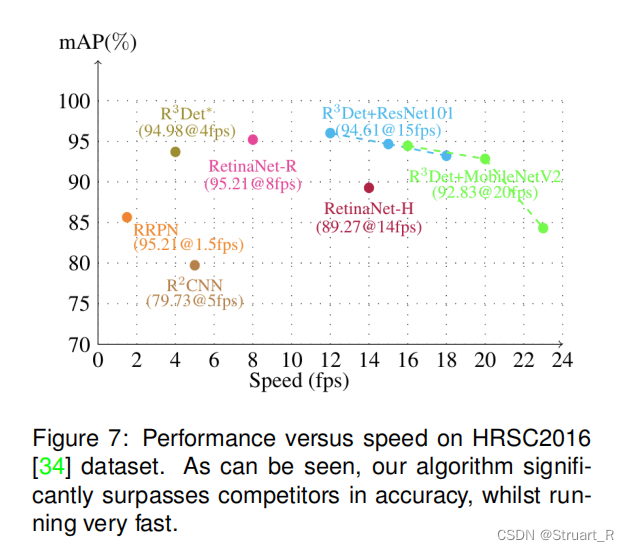
遥感目标检测(1)--R3Det
目录 一、概述 二、三个挑战 三、网络架构编辑 1、旋转RetinaNet 2、精细化旋转RetinaNet 3、与RoIAlign(感兴趣区域插值)进行比较 4、消融实验与对比实验 一、概述 R3Det论文中提到一个端到端的精细化的单级旋转检测器,通过从粗到细…...

使用 vue3-tel-input电话组件时,为什么通过v-model绑定的默认值无效而 通过:value绑定有效?
问题: 使用第三方 vue3-tel-input电话组件时,通过v-model绑定具有初始值的电话变量,但input框内显示的初始值为空? 排查过程: 将 v-model绑定改为 :value绑定后,电话变量初始值竟然能够显示在vue3-tel-inp…...

【运维工程师学习二】OS系统管理
【运维工程师学习二】OS系统管理 1、操作系统管理2、进程管理3、进程的启动4、进程信息的查看4.1、STAT 进程的状态:进程状态使用字符表示的(STAT的状态码),其状态码对应的含义:4.2、ps命令常用用法(方便查看系统进程&…...
)
【前端技巧】CSS常用知识碎片(九)
CSS常用知识碎片(九) mask-image属性 带有半透明的PNG图像的遮罩效果 .mask-image {mask: no-repeat center / contain;mask-image: url(bird.png); }SVG图形遮罩效果 .mask-image {mask-image: url("data:image/svgxml,%3Csvg viewBox0 0 3232…...

SQL 上升的温度
197 上升的温度 SQL架构 表: Weather ---------------------- | Column Name | Type | ---------------------- | id | int | | recordDate | date | | temperature | int | ---------------------- id 是这个表的主键 该表包含特定日期的温度信息 编写一个 SQL …...
)
Matlab实现最优化(附上多个完整仿真源码)
最优化是一种寻找最优解的数学方法,它在各个领域都有广泛的应用。在Matlab中,有多种工具箱和函数库可以用来实现最优化,下面我们来介绍一下如何用Matlab实现最优化。 1. 定义目标函数 在开始最优化之前,需要定义一个目标函数。目…...

Stateflow进阶:巧用‘历史节点’与‘内部转移’,实现带记忆功能的嵌入式状态机
Stateflow进阶:巧用‘历史节点’与‘内部转移’,实现带记忆功能的嵌入式状态机 在嵌入式系统开发中,状态机设计往往面临一个关键挑战:如何在系统重启或断电后恢复之前的工作状态?传统解决方案通常依赖外部存储或默认状…...
)
SAP SD不完整日志配置实战:从字段识别到测试全流程(含避坑指南)
SAP SD不完整日志配置实战:从字段识别到测试全流程(含避坑指南) 在SAP SD模块的实施与运维过程中,确保销售凭证数据的完整性是保障业务流程顺畅运行的基础。不完整日志功能作为数据质量的"守门人",能够有效预…...

开源智能设备开发指南:从技术原理到实战应用
开源智能设备开发指南:从技术原理到实战应用 【免费下载链接】xiaozhi-esp32 Build your own AI friend 项目地址: https://gitcode.com/GitHub_Trending/xia/xiaozhi-esp32 开源智能设备开发正成为物联网创新的核心驱动力,通过边缘计算优化与跨平…...

单细胞测序数据读取实战指南:从CellRanger到Seurat对象
1. 单细胞测序数据读取入门指南 第一次接触单细胞测序数据分析时,最让人头疼的就是数据读取环节。记得我刚入门那会儿,光是理解CellRanger输出的各种文件格式就花了整整一周时间。不过别担心,今天我就把这块硬骨头啃碎了讲给你听。 单细胞测序…...

时光守护者:一键备份QQ空间历史说说的终极解决方案
时光守护者:一键备份QQ空间历史说说的终极解决方案 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 在数字时代,我们的记忆被分散在各个社交平台,QQ空…...

如何突破窗口限制?专业窗口调整工具让桌面管理效率提升300%
如何突破窗口限制?专业窗口调整工具让桌面管理效率提升300% 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 你是否曾遇到过这样的困扰:重要的应用程序窗口无…...

告别格式转换困境:Word-to-Markdown工具的高效智能无缝方案
告别格式转换困境:Word-to-Markdown工具的高效智能无缝方案 【免费下载链接】word-to-markdown A ruby gem to liberate content from Microsoft Word documents 项目地址: https://gitcode.com/gh_mirrors/wo/word-to-markdown 当技术文档作者需要将Word内容…...

WAN2.2文生视频镜像快速部署:NVIDIA驱动适配+ComfyUI插件自动加载教程
WAN2.2文生视频镜像快速部署:NVIDIA驱动适配ComfyUI插件自动加载教程 1. 环境准备与快速部署 WAN2.2是一个强大的文生视频工具,结合了SDXL Prompt风格支持,能够根据中文提示词生成高质量视频内容。这个镜像已经预配置了所有必要的组件&…...

革新性系统安全管理:开源工具重新定义Windows Defender控制范式
革新性系统安全管理:开源工具重新定义Windows Defender控制范式 【免费下载链接】defender-control An open-source windows defender manager. Now you can disable windows defender permanently. 项目地址: https://gitcode.com/gh_mirrors/de/defender-contr…...

ArcGIS Pro 3.0 气象数据处理实战:如何从365天的nc文件中提取单日降水数据
ArcGIS Pro 3.0 气象数据处理实战:从365天nc文件中精准提取单日降水数据 气象数据作为地理信息科学中的重要组成部分,其处理效率直接影响研究进度和成果质量。在众多气象数据格式中,NetCDF(.nc)因其结构化存储和多维数…...