分布式应用之zookeeper集群+消息队列Kafka
一、zookeeper集群的相关知识
1.zookeeper的概念
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。为分布式框架提供协调服务的Apache项目。
Zookeeper 数据结构:
ZooKeeper数据模型的结构与Linux文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode。每一个ZNode默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标识。
2.Zookeeper 工作机制
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。也就是说 Zookeeper = 文件系统 + 通知机制。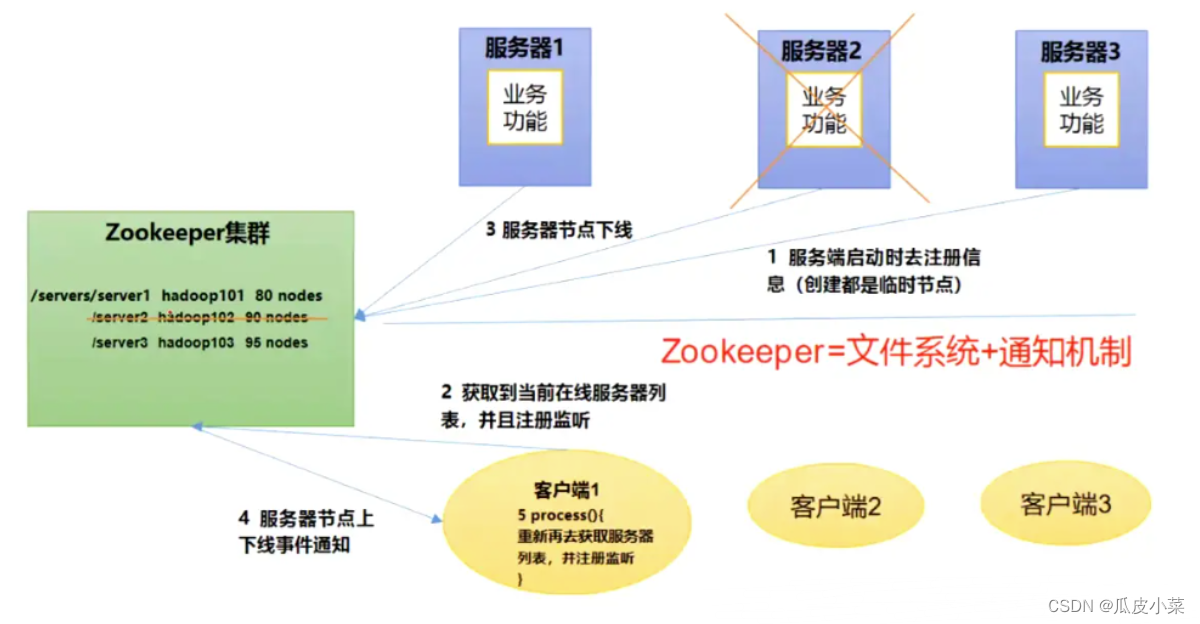
3.Zookeeper 特点
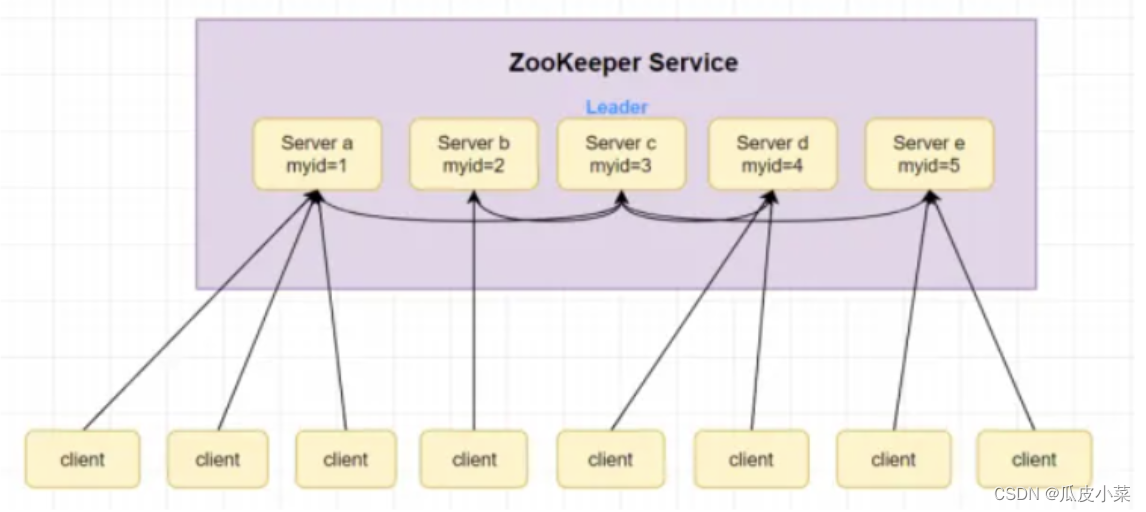
(1)Zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群。
(2)Zookeepe集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。所以Zookeeper适合安装奇数台服务器。
(3)全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
(4)更新请求顺序执行,来自同一个Client的更新请求按其发送顺序依次执行,即先进先出。
(5)数据更新原子性,一次数据更新要么成功,要么失败。
(6)实时性,在一定时间范围内,Client能读到最新数据。
4. Zookeeper 应用场景
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。
●统一命名服务
在分布式环境下,经常需要对应用/服务进行统一命名,便于识别。例如:IP不容易记住,而域名容易记住。
●统一配置管理
(1)分布式环境下,配置文件同步非常常见。一般要求一个集群中,所有节点的配置信息是一致的,比如Kafka集群。对配置文件修改后,希望能够快速同步到各个节点上。
(2)配置管理可交由ZooKeeper实现。可将配置信息写入ZooKeeper上的一个Znode。各个客户端服务器监听这个Znode。一旦 Znode中的数据被修改,ZooKeeper将通知各个客户端服务器。
●统一集群管理
(1)分布式环境中,实时掌握每个节点的状态是必要的。可根据节点实时状态做出一些调整。
(2)ZooKeeper可以实现实时监控节点状态变化。可将节点信息写入ZooKeeper上的一个ZNode。监听这个ZNode可获取它的实时状态变化。
●服务器动态上下线
客户端能实时洞察到服务器上下线的变化。
●软负载均衡
在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端请求。
5.Zookeeper 选举机制
●第一次启动选举机制
(1)服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的myid比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
(4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;(5)服务器5启动,同4一样当小弟。
●非第一次启动选举机制
(1)当ZooKeeper 集群中的一台服务器出现以下两种情况之一时,就会开始进入Leader选举:
1)服务器初始化启动。
2)服务器运行期间无法和Leader保持连接。
(2)而当一台机器进入Leader选举流程时,当前集群也可能会处于以下两种状态:
1)集群中本来就已经存在一个Leader。
对于已经存在Leader的情况,机器试图去选举Leader时,会被告知当前服务器的Leader信息,对于该机器来说,仅仅需要和 Leader机器建立连接,并进行状态同步即可。
2)集群中确实不存在Leader。
假设ZooKeeper由5台服务器组成,SID分别为1、2、3、4、5,ZXID分别为8、8、8、7、7,并且此时SID为3的服务器是Leader。某一时刻,3和5服务器出现故障,因此开始进行Leader选举。
选举Leader规则:
1.EPOCH大的直接胜出
2.EPOCH相同,事务id大的胜出
3.事务id相同,服务器id大的胜出
SID:服务器ID。用来唯一标识一台ZooKeeper集群中的机器,每台机器不能重复,和myid一致。
ZXID:事务ID。ZXID是一个事务ID,用来标识一次服务器状态的变更。在某一时刻,集群中的每台机器的ZXID值不一定完全一致,这和ZooKeeper服务器对于客户端“更新请求”的处理逻辑速度有关。
Epoch:每个Leader任期的代号。没有Leader时同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加二、 部署 Zookeeper 集群
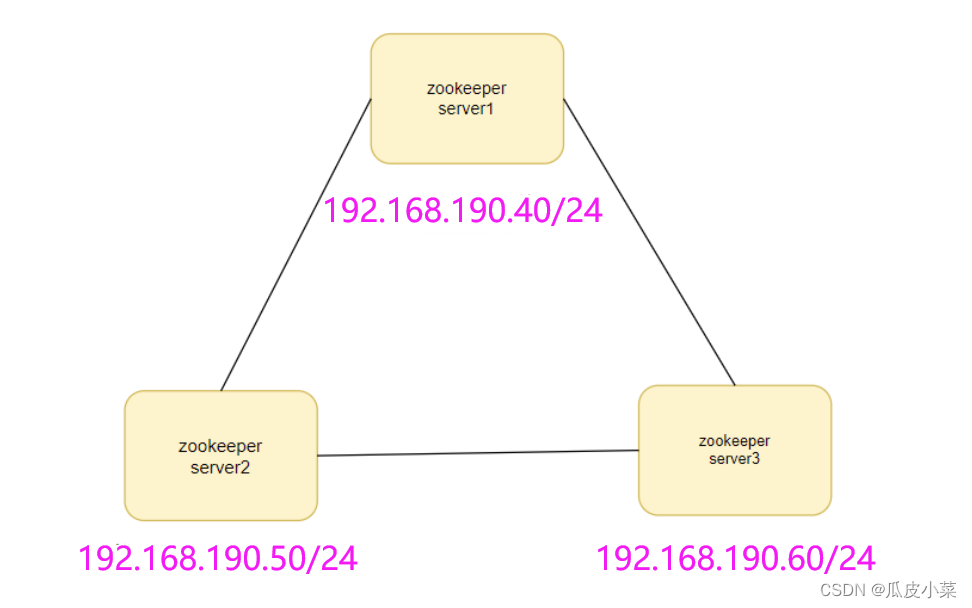
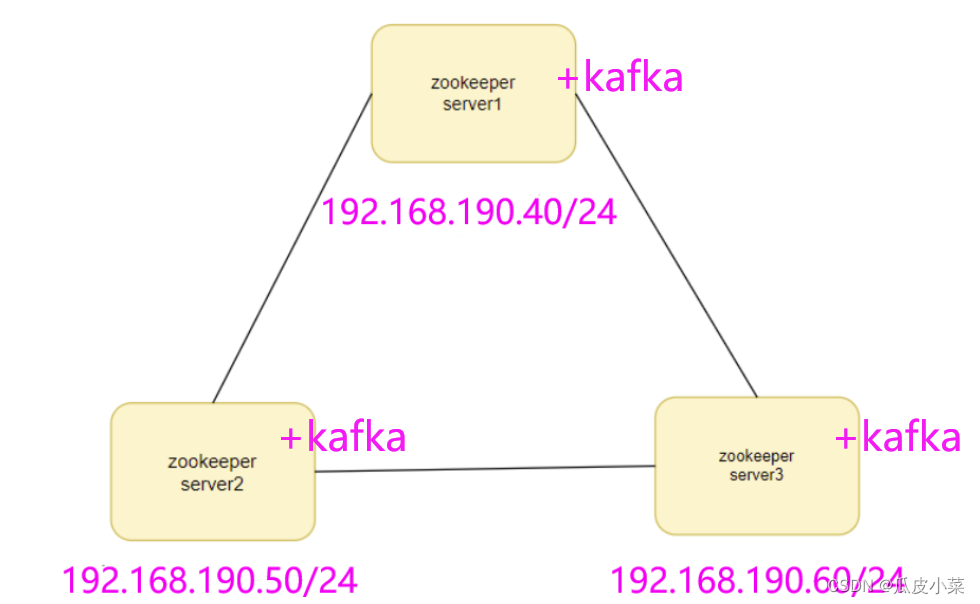
实验设计
准备 3 台服务器做 Zookeeper 集群
192.168.190.40
192.168.190.50
192.168.190.60
1.安装前准备(三台服务器均操作)
//关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
setenforce 0//安装 JDK
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
java -version//下载安装包
官方下载地址:https://archive.apache.org/dist/zookeeper/cd /opt
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/apache-zookeeper-3.5.7-bin.tar.gz2.安装 Zookeeper 服务
2.安装 Zookeeper
cd /opt
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
mv apache-zookeeper-3.5.7-bin /usr/local/zookeeper-3.5.7//修改配置文件
cd /usr/local/zookeeper-3.5.7/conf/
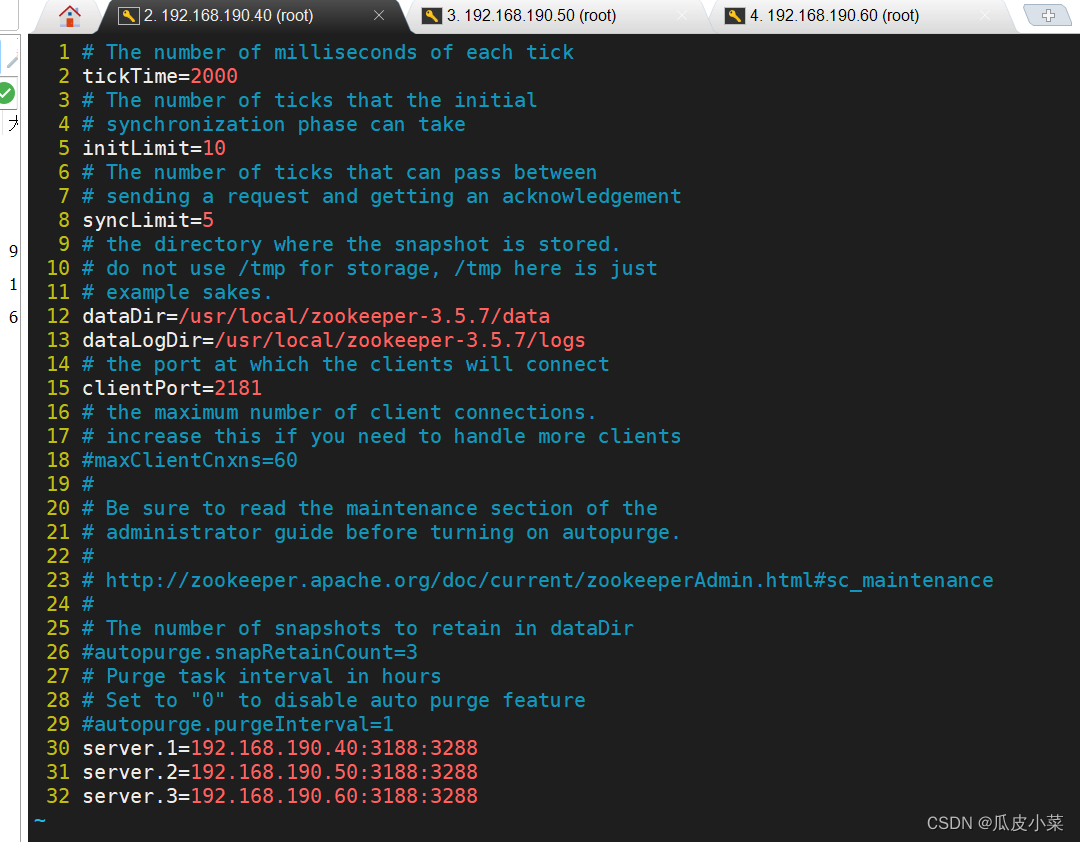
cp zoo_sample.cfg zoo.cfgvim zoo.cfg
tickTime=2000 #通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
initLimit=10 #Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量),这里表示为10*2s
syncLimit=5 #Leader和Follower之间同步通信的超时时间,这里表示如果超过5*2s,Leader认为Follwer死掉,并从服务器列表中删除Follwer
dataDir=/usr/local/zookeeper-3.5.7/data ●修改,指定保存Zookeeper中的数据的目录,目录需要单独创建
dataLogDir=/usr/local/zookeeper-3.5.7/logs ●添加,指定存放日志的目录,目录需要单独创建
clientPort=2181 #客户端连接端口
#添加集群信息
server.1=192.168.190.40:3188:3288
server.2=192.168.190.50:3188:3288
server.3=192.168.190.60:3188:3288
//拷贝配置好的 Zookeeper 配置文件到其他机器上
scp /usr/local/zookeeper-3.5.7/conf/zoo.cfg 192.168.190.50:/usr/local/zookeeper-3.5.7/conf/
scp /usr/local/zookeeper-3.5.7/conf/zoo.cfg 192.168.190.60:/usr/local/zookeeper-3.5.7/conf///在每个节点上创建数据目录和日志目录
mkdir /usr/local/zookeeper-3.5.7/data
mkdir /usr/local/zookeeper-3.5.7/logs//在每个节点的dataDir指定的目录下创建一个 myid 的文件
echo 1 > /usr/local/zookeeper-3.5.7/data/myid
echo 2 > /usr/local/zookeeper-3.5.7/data/myid
echo 3 > /usr/local/zookeeper-3.5.7/data/myid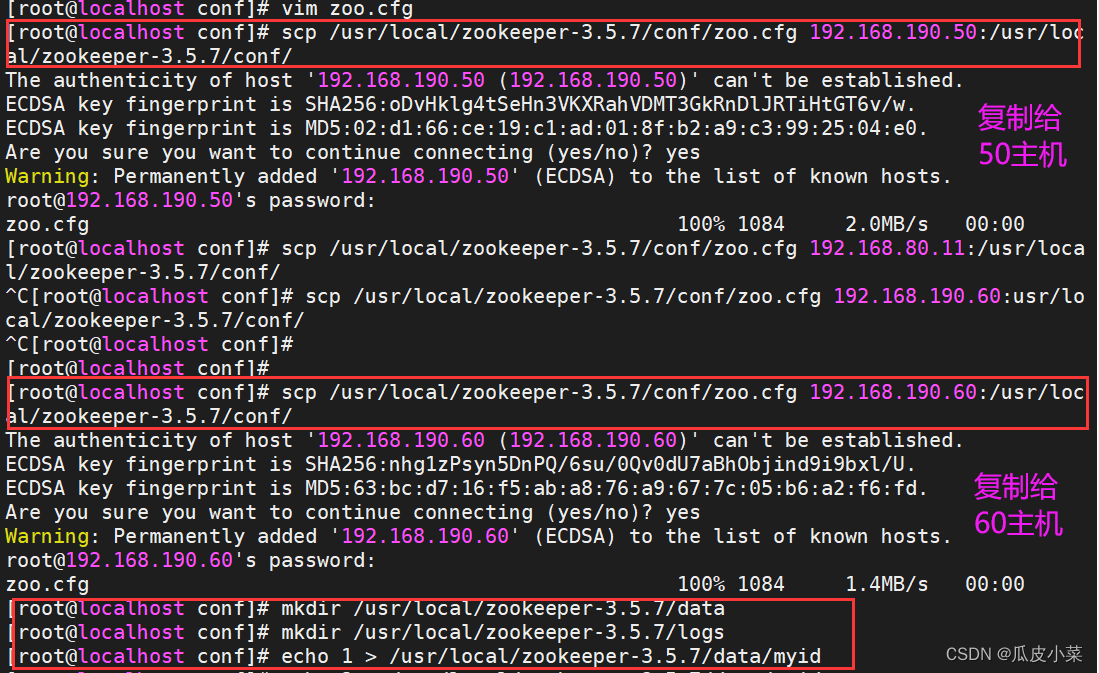
-------------------------------------------------------------------------------------
server.A=B:C:D
●A是一个数字,表示这个是第几号服务器。集群模式下需要在zoo.cfg中dataDir指定的目录下创建一个文件myid,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
●B是这个服务器的地址。
●C是这个服务器Follower与集群中的Leader服务器交换信息的端口。
●D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。3.配置 Zookeeper 启动脚本
//配置 Zookeeper 启动脚本
vim /etc/init.d/zookeeper
#!/bin/bash
#chkconfig: 2345 20 90
#description:Zookeeper Service Control Script
ZK_HOME='/usr/local/zookeeper-3.5.7'
case $1 in
start)echo "---------- zookeeper 启动 ------------"$ZK_HOME/bin/zkServer.sh start
;;
stop)echo "---------- zookeeper 停止 ------------"$ZK_HOME/bin/zkServer.sh stop
;;
restart)echo "---------- zookeeper 重启 ------------"$ZK_HOME/bin/zkServer.sh restart
;;
status)echo "---------- zookeeper 状态 ------------"$ZK_HOME/bin/zkServer.sh status
;;
*)echo "Usage: $0 {start|stop|restart|status}"
esac// 设置开机自启
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper//分别启动 Zookeeper
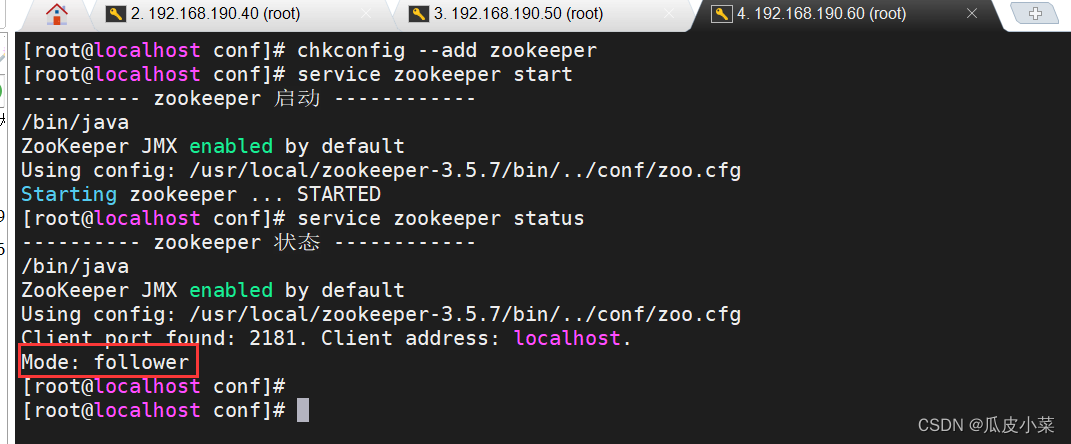
service zookeeper start//查看当前状态
service zookeeper status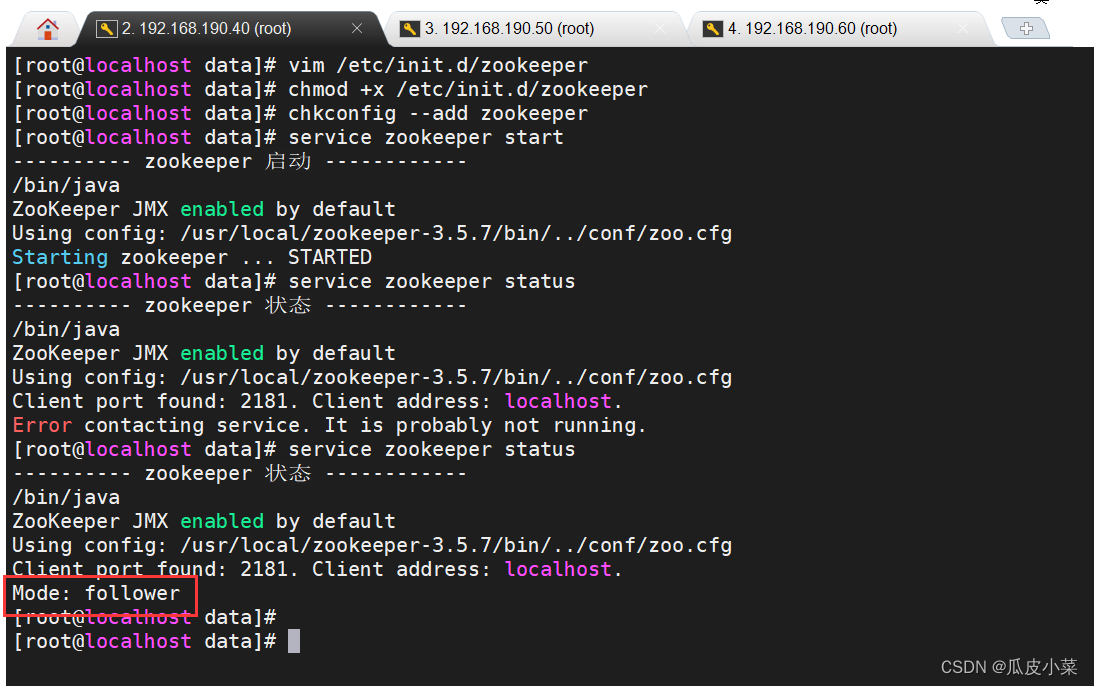
选举出leader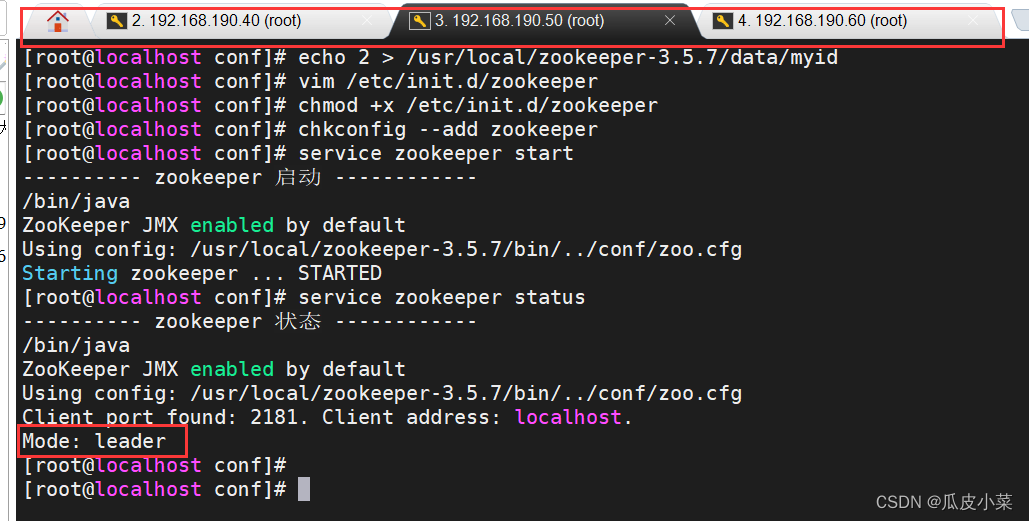
三、消息队列的相关知识
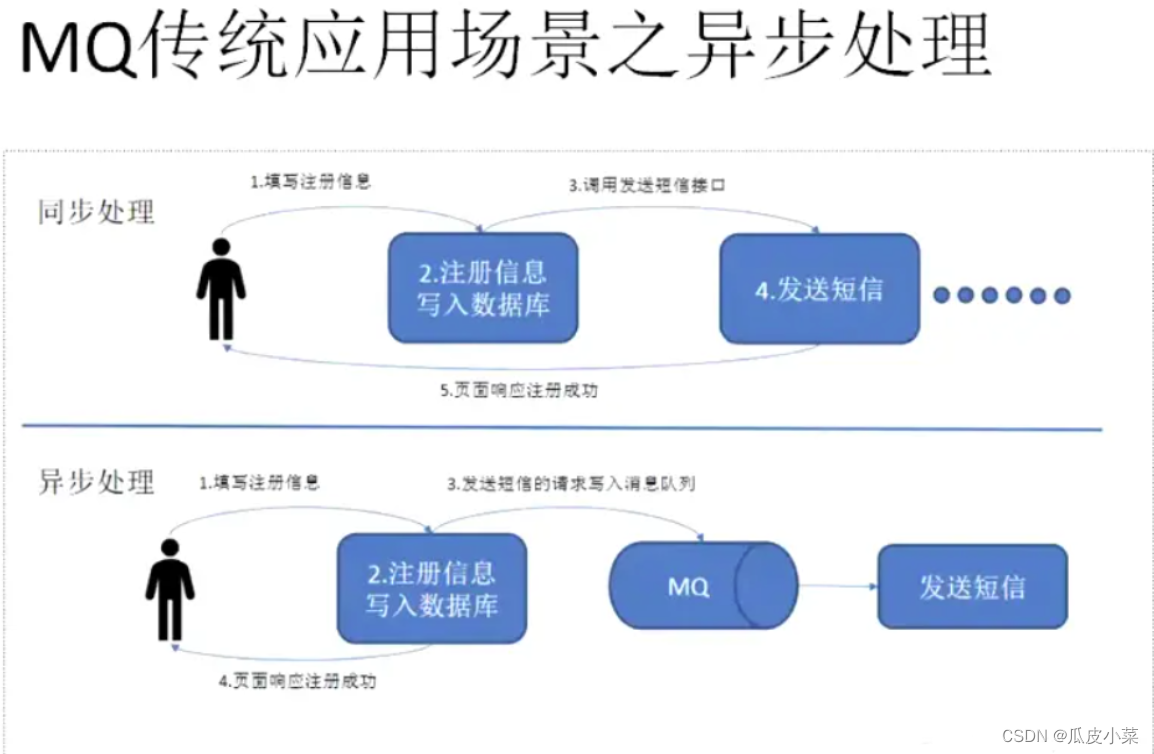
1.为什么需要消息队列(MQ)?
主要原因是由于在高并发环境下,同步请求来不及处理,请求往往会发生阻塞。比如大量的请求并发访问数据库,导致行锁表锁,最后请求线程会堆积过多,从而触发 too many connection 错误,引发雪崩效应。
我们使用消息队列,通过异步处理请求,从而缓解系统的压力。消息队列常应用于异步处理,流量削峰,应用解耦,消息通讯等场景。
当前比较常见的 MQ 中间件有 ActiveMQ、RabbitMQ、RocketMQ、Kafka 等。

2.使用消息队列的好处
(1)解耦
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
(2)可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
(3)缓冲
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
(4)灵活性 & 峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
(5)异步通信
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
3.消息队列的两种模式
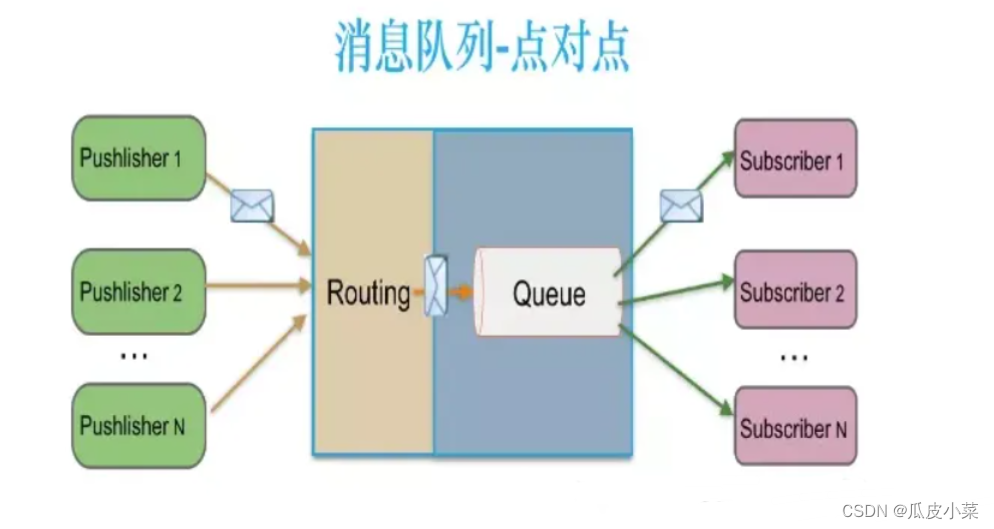
(1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
消息生产者生产消息发送到消息队列中,然后消息消费者从消息队列中取出并且消费消息。消息被消费以后,消息队列中不再有存储,所以消息消费者不可能消费到已经被消费的消息。消息队列支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
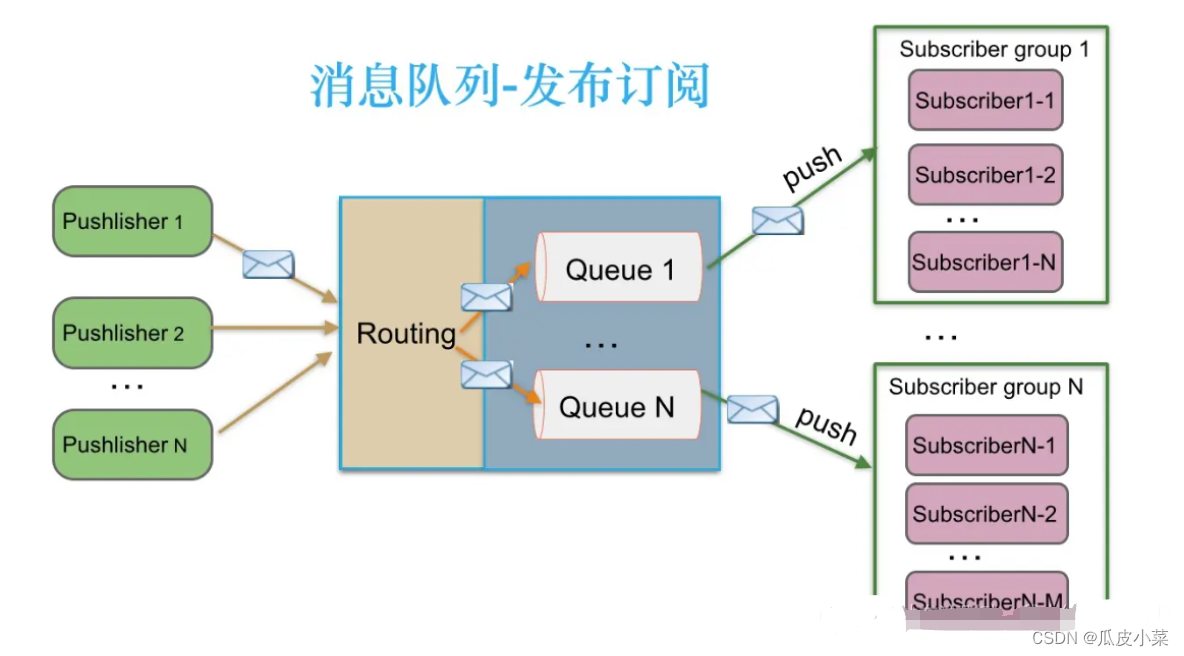
(2)发布/订阅模式(一对多,又叫观察者模式,消费者消费数据之后不会清除消息)
消息生产者(发布)将消息发布到 topic 中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到 topic 的消息会被所有订阅者消费。
发布/订阅模式是定义对象间一种一对多的依赖关系,使得每当一个对象(目标对象)的状态发生改变,则所有依赖于它的对象(观察者对象)都会得到通知并自动更新。
四、Kafka 消息队列工具
1.kafka的定义与简介
Kafka 是一个分布式的基于发布/订阅模式的消息队列(MQ,Message Queue),主要应用于大数据领域的实时计算以及日志收集。
Kafka 是最初由 Linkedin 公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于 Zookeeper 协调的分布式消息中间件系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景,比如基于 hadoop 的批处理系统、低延迟的实时系统、Spark/Flink 流式处理引擎,nginx 访问日志,消息服务等等,用 scala 语言编写,
Linkedin 于 2010 年贡献给了 Apache 基金会并成为顶级开源项目。
2.Kafka 的特性
●高吞吐量、低延迟
Kafka 每秒可以处理几十万条消息,它的延迟最低只有几毫秒。每个 topic 可以分多个 Partition,Consumer Group 对 Partition 进行消费操作,提高负载均衡能力和消费能力。
●可扩展性
kafka 集群支持热扩展
●持久性、可靠性
消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
●容错性
允许集群中节点失败(多副本情况下,若副本数量为 n,则允许 n-1 个节点失败)
●高并发
支持数千个客户端同时读写
3. Kafka 系统架构
(1)Broker
一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。
(2)Topic
可以理解为一个队列,生产者和消费者面向的都是一个 topic。
类似于数据库的表名或者 ES 的 index
物理上不同 topic 的消息分开存储
(3)Partition
为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分割为一个或多个 partition,每个 partition 是一个有序的队列。Kafka 只保证 partition 内的记录是有序的,而不保证 topic 中不同 partition 的顺序。
每个 topic 至少有一个 partition,当生产者产生数据的时候,会根据分配策略选择分区,然后将消息追加到指定的分区的队列末尾。
##Partation 数据路由规则:
1.指定了 patition,则直接使用;
2.未指定 patition 但指定 key(相当于消息中某个属性),通过对 key 的 value 进行 hash 取模,选出一个 patition;
3.patition 和 key 都未指定,使用轮询选出一个 patition。每条消息都会有一个自增的编号,用于标识消息的偏移量,标识顺序从 0 开始。每个 partition 中的数据使用多个 segment 文件存储。如果 topic 有多个 partition,消费数据时就不能保证数据的顺序。严格保证消息的消费顺序的场景下(例如商品秒杀、 抢红包),需要将 partition 数目设为 1。●broker 存储 topic 的数据。如果某 topic 有 N 个 partition,集群有 N 个 broker,那么每个 broker 存储该 topic 的一个 partition。
●如果某 topic 有 N 个 partition,集群有 (N+M) 个 broker,那么其中有 N 个 broker 存储 topic 的一个 partition, 剩下的 M 个 broker 不存储该 topic 的 partition 数据。
●如果某 topic 有 N 个 partition,集群中 broker 数目少于 N 个,那么一个 broker 存储该 topic 的一个或多个 partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致 Kafka 集群数据不均衡。分区的原因
●方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了;
●可以提高并发,因为可以以Partition为单位读写了。(4)Replica
副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower。
(5)Leader
每个 partition 有多个副本,其中有且仅有一个作为 Leader,Leader 是当前负责数据的读写的 partition。
(6)Follower
Follower 跟随 Leader,所有写请求都通过 Leader 路由,数据变更会广播给所有 Follower,Follower 与 Leader 保持数据同步。Follower 只负责备份,不负责数据的读写。
如果 Leader 故障,则从 Follower 中选举出一个新的 Leader。
当 Follower 挂掉、卡住或者同步太慢,Leader 会把这个 Follower 从 ISR(Leader 维护的一个和 Leader 保持同步的 Follower 集合) 列表中删除,重新创建一个 Follower。
(7)Producer
生产者即数据的发布者,该角色将消息 push 发布到 Kafka 的 topic 中。
broker 接收到生产者发送的消息后,broker 将该消息追加到当前用于追加数据的 segment 文件中。
生产者发送的消息,存储到一个 partition 中,生产者也可以指定数据存储的 partition。
(8)Consumer
消费者可以从 broker 中 pull 拉取数据。消费者可以消费多个 topic 中的数据。
(9)Consumer Group(CG)
消费者组,由多个 consumer 组成。
所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。可为每个消费者指定组名,若不指定组名则属于默认的组。
将多个消费者集中到一起去处理某一个 Topic 的数据,可以更快的提高数据的消费能力。
消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费,防止数据被重复读取。
消费者组之间互不影响。
(10)offset 偏移量
可以唯一的标识一条消息。
偏移量决定读取数据的位置,不会有线程安全的问题,消费者通过偏移量来决定下次读取的消息(即消费位置)。
消息被消费之后,并不被马上删除,这样多个业务就可以重复使用 Kafka 的消息。
某一个业务也可以通过修改偏移量达到重新读取消息的目的,偏移量由用户控制。
消息最终还是会被删除的,默认生命周期为 1 周(7*24小时)。
(11)Zookeeper
Kafka 通过 Zookeeper 来存储集群的 meta 信息。
由于 consumer 在消费过程中可能会出现断电宕机等故障,consumer 恢复后,需要从故障前的位置的继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。
Kafka 0.9 版本之前,consumer 默认将 offset 保存在 Zookeeper 中;从 0.9 版本开始,consumer 默认将 offset 保存在 Kafka 一个内置的 topic 中,该 topic 为 __consumer_offsets。
也就是说,zookeeper的作用就是,生产者push数据到kafka集群,就必须要找到kafka集群的节点在哪里,这些都是通过zookeeper去寻找的。消费者消费哪一条数据,也需要zookeeper的支持,从zookeeper获得offset,offset记录上一次消费的数据消费到哪里,这样就可以接着下一条数据进行消费。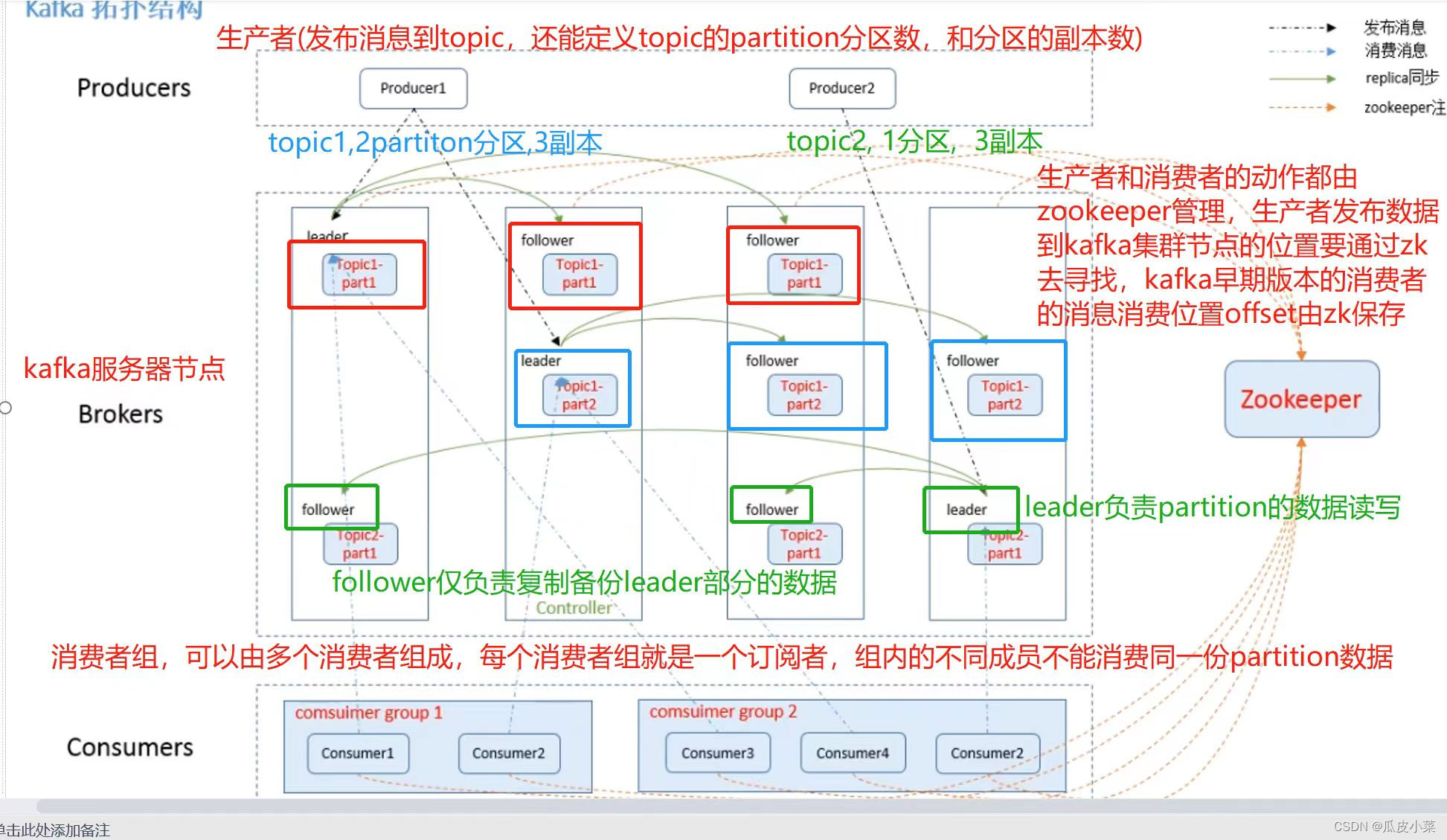
五、 部署 kafka 集群
注:kafka从3.0版本之后,不再依赖zookeeper。但是为了业务的稳定,大部分企业还是采用zookeeper+Kafka的架构
1.安装的包的下载
1.下载安装包
官方下载地址:http://kafka.apache.org/downloads.htmlcd /opt
wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.7.1/kafka_2.13-2.7.1.tgz2.安装 Kafka
cd /opt/
tar zxvf kafka_2.13-2.7.1.tgz
mv kafka_2.13-2.7.1 /usr/local/kafka
2.修改配置文件和环境变量
//修改配置文件
cd /usr/local/kafka/config/
cp server.properties{,.bak}vim server.properties
broker.id=0 ●21行,broker的全局唯一编号,每个broker不能重复,因此要在其他机器上配置 broker.id=1、broker.id=2
listeners=PLAINTEXT://192.168.190.40:9092 ●31行,指定监听的IP和端口,如果修改每个broker的IP需区分开来,也可保持默认配置不用修改
num.network.threads=3 #42行,broker 处理网络请求的线程数量,一般情况下不需要去修改
num.io.threads=8 #45行,用来处理磁盘IO的线程数量,数值应该大于硬盘数
socket.send.buffer.bytes=102400 #48行,发送套接字的缓冲区大小
socket.receive.buffer.bytes=102400 #51行,接收套接字的缓冲区大小
socket.request.max.bytes=104857600 #54行,请求套接字的缓冲区大小
log.dirs=/usr/local/kafka/logs #60行,kafka运行日志存放的路径,也是数据存放的路径
num.partitions=1 #65行,topic在当前broker上的默认分区个数,会被topic创建时的指定参数覆盖
num.recovery.threads.per.data.dir=1 #69行,用来恢复和清理data下数据的线程数量
log.retention.hours=168 #103行,segment文件(数据文件)保留的最长时间,单位为小时,默认为7天,超时将被删除
log.segment.bytes=1073741824 #110行,一个segment文件最大的大小,默认为 1G,超出将新建一个新的segment文件
zookeeper.connect=192.168.190.40:2181,192.168.190.50:2181,192.168.190.60:2181 ●123行,配置连接Zookeeper集群地址//修改环境变量
vim /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/binsource /etc/profile



3.配置zookeeper的启动脚本
配置 Zookeeper 启动脚本
vim /etc/init.d/kafka
#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/usr/local/kafka'
case $1 in
start)echo "---------- Kafka 启动 ------------"${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)echo "---------- Kafka 停止 ------------"${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)$0 stop$0 start
;;
status)echo "---------- Kafka 状态 ------------"count=$(ps -ef | grep kafka | egrep -cv "grep|$$")if [ "$count" -eq 0 ];thenecho "kafka is not running"elseecho "kafka is running"fi
;;
*)echo "Usage: $0 {start|stop|restart|status}"
esac4.分别启动kafka
//设置开机自启
chmod +x /etc/init.d/kafka
chkconfig --add kafka//分别启动 Kafka
service kafka start
5.进行topic的管理
//创建topic
kafka-topics.sh --create --zookeeper 192.168.80.10:2181,192.168.190.40:2181,192.168.190.50:2181,192.168.190.60:2181 --replication-factor 2 --partitions 3 --topic test-------------------------------------------------------------------------------------
--zookeeper:定义 zookeeper 集群服务器地址,如果有多个 IP 地址使用逗号分割,一般使用一个 IP 即可
--replication-factor:定义分区副本数,1 代表单副本,建议为 2
--partitions:定义分区数
--topic:定义 topic 名称
-------------------------------------------------------------------------------------//查看当前服务器中的所有 topic
kafka-topics.sh --list --zookeeper 192.168.190.40:2181,192.168.190.50:2181,192.168.190.60:2181 //查看某个 topic 的详情
kafka-topics.sh --describe --zookeeper 192.168.190.40:2181,192.168.190.50:2181,192.168.190.60:2181 //发布消息
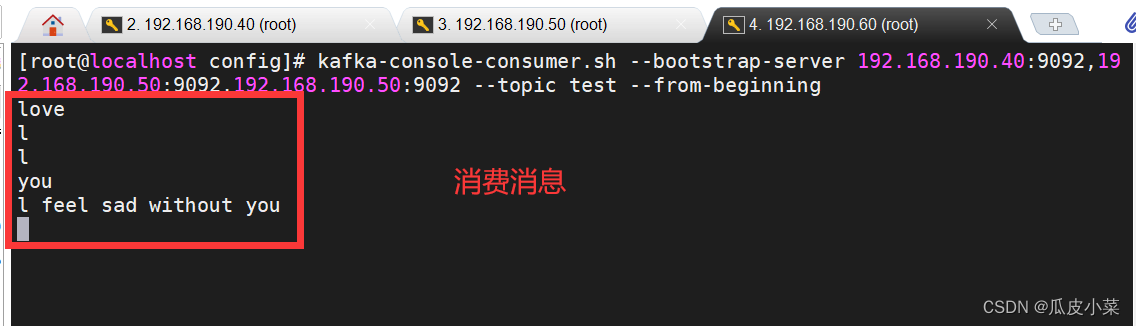
kafka-console-producer.sh --broker-list 192.168.190.40:9092,192.168.190.50:9092,192.168.190.60:9092 --topic test//消费消息
kafka-console-consumer.sh --bootstrap-server 192.168.190.40:9092,192.168.190.50:9092,192.168.190.50:9092 --topic test --from-beginning-------------------------------------------------------------------------------------
--from-beginning:会把主题中以往所有的数据都读取出来
-------------------------------------------------------------------------------------//修改分区数
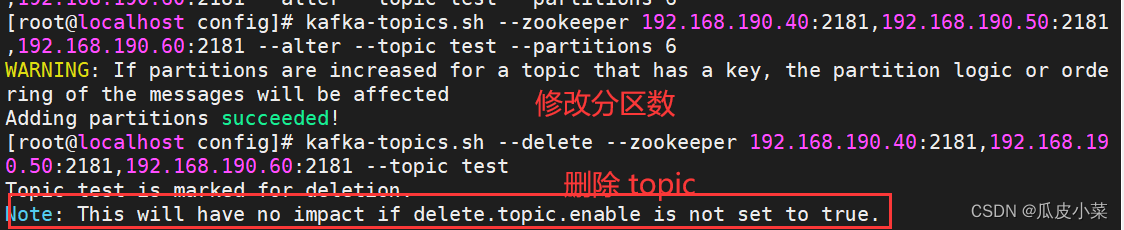
kafka-topics.sh --zookeeper 192.168.190.40:2181,192.168.190.50:2181,192.168.190.60:2181 --alter --topic test --partitions 6//删除 topic
kafka-topics.sh --delete --zookeeper 192.168.190.40:2181,192.168.190.50:2181,192.168.190.60:2181 --topic test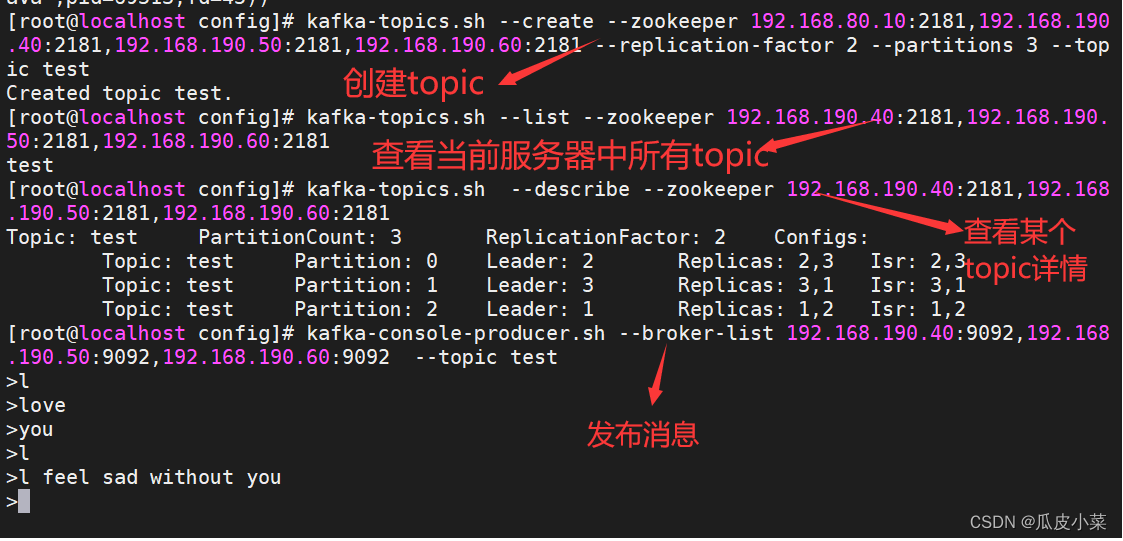
相关文章:
分布式应用之zookeeper集群+消息队列Kafka
一、zookeeper集群的相关知识 1.zookeeper的概念 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能…...
)
GStreamer学习笔记(四)
Time management 仅当管道处于PLAYING状态时,可以刷新屏幕。如果不在PLAYING状态,什么都不做,因为大多数查询都会失败。 函数与知识点 GstClockTime 说明:所需的超时时间必须以GstClockTime的形式指定。即以纳秒(ns…...
DBeaver连接华为高斯数据库 DBeaver连接Gaussdb数据库 DBeaver connect Gaussdb
DBeaver连接华为高斯数据库 DBeaver连接Gaussdb数据库 DBeaver connect Gaussdb 一、概述 华为GaussDB出来已经有一段时间,最近工作中刚到Gauss数据库。作为coder,那么如何通过可视化工具来操作Gauss呢? 本文将记录使用免费、开源的DBeaver来…...

.net core 2.1 简单部署IIS运行
netcore的项目不像netFramework那么方便部署到iis还是要费点功夫的 比如我想把这个netcore2.1的项目部署到iis并运行: 按照步骤走: 一、确认自己的netcore环境 1、需要安装下面3个环境包(如果电脑已安装请忽略) 检查是否安装cmd命令:cmd&…...

提高视觉检测系统稳定性的隐藏办法——10G高速图像采集卡
提高视觉检测系统稳定性的隐藏办法——10G高速图像采集卡 目前,随着我国各方面配套基础设施建设的完善,企业技术、资金的积累,各行各业积极探索和大胆的尝试机器视觉技术,实现工业自动化、智能化。在机器视觉系统的使用过程中&am…...

注解方式实现数据库字段加密与解密
目录 前言实现步骤定义注解加密工具类定义mybatis拦截器 总结 前言 一些敏感信息存入数据需要进行加密处理,比如电话号码,身份证号码等,从数据库取出到前端展示时需要解密,如果分别在存入取出时去做处理,会很繁锁&…...
C\C++ 使用socket判断ip是否能连通
文章作者:里海 来源网站:https://blog.csdn.net/WangPaiFeiXingYuan 简介: 使用socket判断ip是否能联通 效果: 代码: #include <iostream> #include <cstdlib> #include <cstdio> #include &…...
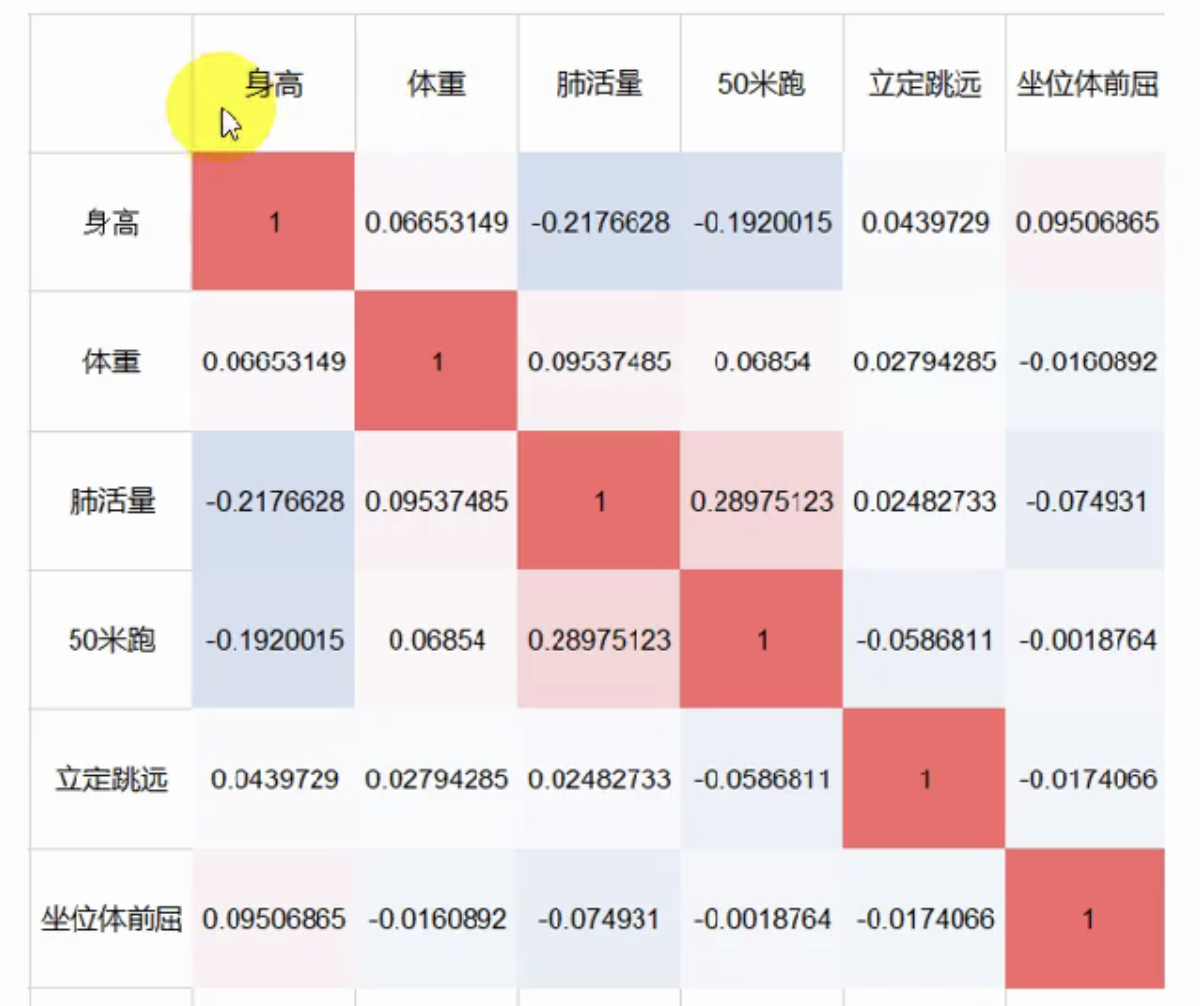
数学建模-相关系数
excel基本操作:ctrl右,ctrl左,ctrlshift下/右,ctrlshift空格 题目里有数据,给出描述性统计是比较好的习惯 excel描述性统计:数据-数据分析-描述统计 MATLAB要做散点图C62个 SPSS可以直接画出两两之间的散…...
Ubuntu下安装、配置及重装CUDA教程
安装CUDA 前往Nvidia CUDA Tools官网选择对应的架构和版本下载CUDA 以如下架构和版本为例: 查看显卡驱动 nvidia-smi如果显卡驱动已经装了,那么在CUDA安装过程中不用再勾选安装driver 下载并安装CUDA wget https://developer.download.nvidia.co…...

自学网络安全(黑客)为什么火了?
网安专业从始至终都是需要学习的,大学是无法培养出合格的网安人才的。这就是为啥每年网安专业毕业生并不少,而真正从事网安岗位的人,寥寥无几的根本原因。 如果将来打算从事网安岗位,那么不断学习是你唯一的途径。 网络安全为什…...

Android S 修改关于手机的logo
1.让图片加载生效 frameworks/base/packages/SettingsLib/LayoutPreference/res/layout/preference_about_phone.xml <LinearLayout xmlns:android"http://schemas.android.com/apk/res/android" android:id"id/entity_header" style"…...

Mysql 备份与还原
目录 一、数据备份的重要性 二、数据库备份类型 2.1 物理备份 2.2 逻辑备份 三、常见的备份方法 3.1 物理冷备 3.2 专用备份工具 mysqldump 或 mysqlhotcopy 3.3 启用二进制日志进行增量备份 3.4 第三方工具备份 四、MySQL完全备份 五、数据库完全备份分类…...

Cadence PCB 仿真Model Integrity专题
🏡《总目录》 🏡《宝典目录》 目录 1,内容概述2,内容目录 1,内容概述 本专题详细介绍Cadence的仿真建模工具 Model Integrity。 2,内容目录 Cadence PCB仿真 Model Integrity 功能详述与启动方法图文教…...

记一次阿里云被挖矿处理记录
摘要 莫名其妙的服务器就被攻击了,又被薅了羊毛,当做免费的挖矿劳动力了。 一、起因 上班(摸鱼)好好的,突然收到一条阿里云的推送短信,不看不知道,两台服务器被拉去作为苦力,挖矿去…...

Linux系统使用(超详细)
目录 Linux操作系统简介 Linux和windows区别 Linux常见命令 Linux目录结构 Linux命令提示符 常用命令 ls cd pwd touch cat echo mkdir rm cp mv vim vim的基本使用 grep netstat Linux面试题 Linux操作系统简介 Linux操作系统是和windows操作系统是并列…...

【问题总结】Docker环境下备份和恢复postgresql数据库
目录 文章目录 以从备份恢复forest_resources库为例一、备份数据库二、需要还原的数据库准备1 删除掉远程的库。2 重新创建一个空的库。可以使用sql3 找到数据库存放的路径,并将备份文件上传到对应的路径下 三、 进入docker容器内部,执行数据库恢复附录…...

《TCP IP网络编程》第六章
《TCP IP网络编程》第六章:基于 UDP 的服务端/客户端 UDP 套接字的特点: 通过寄信来说明 UDP 的工作原理,这是讲解 UDP 时使用的传统示例,它与 UDP 的特点完全相同。寄信前应先在信封上填好寄信人和收信人的地址,之后…...

如何学习java
-学习Java是一个循序渐进的过程,下面提供一些学习Java的方法,帮助您有效地掌握这门编程语言: 定义学习目标:明确您学习Java的目标和用途。是为了进入软件开发行业,还是用于特定项目或兴趣爱好?明确学习目标…...

RabbitMQ实现六类工作模式
😊 作者: 一恍过去 💖 主页: https://blog.csdn.net/zhuocailing3390 🎊 社区: Java技术栈交流 🎉 主题: RabbitMQ实现六类工作模式 ⏱️ 创作时间: 2023年07月20日…...
折腾日记)
all in one (群辉、软路由、win/linux)折腾日记
目录 生命不息,折腾不止名词解释硬件参数装机 生命不息,折腾不止 因自身能力有限,可能内容质量不高,欢迎志同道合的各路大神加入,共同折腾! 名词解释 ALL IN ONE :多功能一体机 OpenWrt【软路…...

通义千问3-Reranker-0.6B效果展示:新闻标题-正文段落时效性重排案例
通义千问3-Reranker-0.6B效果展示:新闻标题-正文段落时效性重排案例 1. 引言:重排序技术的重要性 在信息爆炸的时代,我们每天都会接触到海量的新闻资讯。但你是否遇到过这样的情况:搜索一个热点事件,结果却出现大量过…...

PredRNN++:从单元到系统,逐层拆解与实战解析
1. PredRNN核心单元拆解 PredRNN作为视频预测领域的里程碑模型,其核心创新在于Causal LSTM和GHU两大单元的设计。我们先从代码层面看看它们如何运作。 1.1 Causal LSTM的三明治结构 打开CausalLSTMCell.py文件,你会发现这个单元像三明治一样分为三层&…...

百考通:AI全流程智能化赋能期刊论文写作,让学术创作更高效
在学术研究领域,期刊论文的撰写是成果输出的关键环节,却也让众多科研工作者与学生倍感压力:选题迷茫、逻辑梳理困难、格式规范复杂、内容提炼耗时,严重拖慢了学术成果的发表节奏。百考通(https://www.baikaotongai.com…...

20世纪十大经典算法解析与应用
二十世纪十大经典算法解析1. 蒙特卡洛方法 (1946)由John von Neumann、Stan Ulam和Nick Metropolis在洛斯阿拉莫斯国家实验室提出。该方法通过随机采样解决确定性数学问题,其核心思想是:在单位正方形内随机撒点统计落在不规则图形内的点数比例该比例近似…...
)
ESP32-S3的AI新玩法:除了语音唤醒,还能用TensorFlow Lite Micro做哪些酷事?(环境音识别/振动监测实战)
ESP32-S3边缘智能实战:从环境音识别到工业振动监测的AI新范式 当一颗售价不到5美元的芯片能够听懂玻璃破碎声、预测电机故障,甚至识别婴儿啼哭时,物联网设备的"感知能力"正在被重新定义。ESP32-S3搭配TensorFlow Lite Micro&#x…...
)
基于springboot的论坛网站设计与实现.7z(源码+论文+开题报告)
[点击下载链接》》》] 随着信息技术在管理上越来越深入而广泛的应用,管理信息系统的实施在技术上已逐步成熟。本文介绍了论坛网站的开发全过程。通过分析论坛网站管理的不足,创建了一个计算机管理论坛网站的方案。文章介绍了论坛网站的系统分析部分&…...

DDD 领域驱动设计实战:从理论到代码
DDD 领域驱动设计实战:从理论到代码别叫我大神,叫我 Alex 就好。DDD 不是银弹,但它是处理复杂业务逻辑的利器。一、DDD 核心概念 1.1 分层架构 ┌─────────────────────────────────────────┐ │ …...

终极LoRaWAN服务器搭建指南:如何快速构建你的私有物联网网络
终极LoRaWAN服务器搭建指南:如何快速构建你的私有物联网网络 【免费下载链接】lorawan-server Compact server for private LoRaWAN networks 项目地址: https://gitcode.com/gh_mirrors/lo/lorawan-server 你是否想拥有一个完全可控的LoRaWAN物联网平台&…...

CANopen协议学习与实践干货分享
CANopen协议代码,学习资料,包含CANfestival官方代码框架,官方字典生成工具,可自主设定心跳,pdo,sdo等内容参数,并包含已经移植完成的且带有详细注释的一个主站程序两个从站能正常通信࿰…...

Z-Image Turbo与Vue3前端框架集成实战
Z-Image Turbo与Vue3前端框架集成实战 本文详细介绍了如何在Vue3项目中集成Z-Image Turbo图像生成API,通过WebSocket实现实时图像生成功能,并提供完整的组件封装方案。 1. 引言 前端开发者经常面临一个挑战:如何在Web应用中集成强大的AI图像…...