Python基础-列表(list)和元组(tuple)
Python包含6种内建的序列:列表,元组,字符串,Unicode字符串,buffer对象,xrange对象,本文讨论列表和元组。
1.列表可以修改,元组则不能修改。
2.几乎在所有的情况下,列表都可以替代元组。
一、【列表(list)】
#1.语法:列表的各个元素用","分割,写在方括号中。
#如:用列表表示数据库中一个人的信息:姓名,性别,年龄
zhangsan=['张三','男',30]
lisi=['李四','女',28]
print(zhangsan)
print(type(zhangsan))
#输出:['张三', '男', 30]
#输出:<class 'list'>
#2.列表可以包含其他列表,如:
zhangsan=['张三','男',30]
lisi=['李四','女',28]
users=[zhangsan,lisi]
print(users)
#输出:[['张三', '男', 30], ['李四', '女', 28]]
#3.所有序列类型都可以进行:索引,分片,加,乘等操作,以及包含检查元素是否存在,序列长度,最大元素,最小元素等内建函数。
#3.1 索引:索引从0开始递增;使用负数索引时,会从右边计数,右边最后一个元素位置编号是-1,不是0
hello="HelloWorld"
print(hello[0]+"-"+hello[-1])
#输出:H-d
#3.2 分片:通过分片来访问一定范围内的元素,通过冒号相隔的两个索引来实现。注意:第1个索引的元素包含在分片内,第2个索引的元素不包含在分片内
hello="SayHelloWorld"
print(hello[3:8])
#输出:Hello
#分片步长:默认步长为1,分片按照这个步长遍历序列元素,然后返回开始和结束点之间的所有元素。
print(hello[3:8:2])
#输出:Hlo
#3.2 序列相加:两种相同类型的序列才能进行连接操作。
a=[1,2,3]
b=[4,5,6]
print(a+b)
#输出:[1, 2, 3, 4, 5, 6]
#3.3 乘法:用数字x乘以一个序列,会得到将原序列元素重复x次的新序列
a=[1,2,3]
print(a*3)
#输出:[1, 2, 3, 1, 2, 3, 1, 2, 3]
#3.4 检查元素是否存在:使用in运算符
print("H" in hello)
#输出:True
zhangsan=['张三','男',30]
lisi=['李四','女',28]
users=[zhangsan,lisi]
print(['张三','男',30] in users)
#输出:True
#3.5 len(),max(),min() 函数
num=[100,34,678]
print(str(len(num))+"-"+str(max(num))+"-"+str(min(num)))
#输出:3-678-34
#4.列表方法(函数)
#4.1 list()函数:因为字符串不能像列表一样被修改,可以将字符串转换为列表
hello="HelloWorld"
hellolist=list(hello)
print(hellolist)
#输出:['H', 'e', 'l', 'l', 'o', 'W', 'o', 'r', 'l', 'd']
#反之,将列表组装成字符串,需要用到join函数
hello2="".join(['H', 'e', 'l', 'l', 'o', 'W', 'o', 'r', 'l', 'd'])
print(hello2)
#输出:HelloWorld
#4.2 del 删除元素
names=["zhangsan","lisi","wangwu"]
del names[1]
print(names)
#输出:['zhangsan', 'wangwu']
#4.3 append()方法:在列表末尾追加新元素
num=[1,2,3]
num.append(4)
print(num)
#输出:[1, 2, 3, 4]
#4.3 count()方法:统计某个元素在列表中出现的次数
chars=['A','B','A','C','A']
print(chars.count("A"))
#输出:3
#4.4 extend()方法:在列表的末尾一次性追加另一个序列中的多个值
#注意:extend()方法修改了被扩展的序列,而a+b是两个序列的连接操作,它返回的是一个新的序列
a=[1,2,3]
b=[4,5,6]
c=a+b
a.extend(b)
print(a)
print(c)
#输出:[1, 2, 3, 4, 5, 6]
#输出:[1, 2, 3, 4, 5, 6]
#4.5 index()方法:用于在列表中找出某个值第一个匹配的索引位置
chars=['A','B','A','C','A']
print(chars.index("C"))
#输出:3
#4.6 insert()方法:用于将对象插入到列表中
a=[1,2,3]
a.insert(1,"A")
print(a)
#输出:[1, 'A', 2, 3]
#4.7 pop()方法:会移除列表中的一个元素(默认是最后一个),并发返回该元素的值
#pop方法是唯一一个既能修改列表,又能返回元素值(除了None)的列表方法(类似栈,后进先出)
a=[1,2,3]
b=a.pop(1)
print(a)
print(b)
#输出:[1, 3]
#输出:2
#4.8 remove()方法:用于移除列表中某个位置的第一个匹配项
a=[1,2,3,'A','B','C']
a.remove('A')
print(a)
#输出:[1, 2, 3, 'B', 'C']
#4.9 reverse()方法:用于将列表中的元素反向存放
a=[1,2,3]
a.reverse()
print(a)
#输出:[3, 2, 1]
#4.9 sort()方法:用于在原位置对列表进行排序,改变原来的列表,而不是返回新的列表
a=[1,7,4,5,3,6,2,8]
b=['E','B','D','F','C','A']
a.sort()
b.sort()
print(a)
print(b)
#输出:[1, 2, 3, 4, 5, 6, 7, 8]
#输出:['A', 'B', 'C', 'D', 'E', 'F']
#如果只是想获取排序后的列表,而不是修改原列表,可以使用sorted()方法
a=[1,7,4,5,3,6,2,8]
b=['E','B','D','F','C','A']
print(sorted(a))
print(sorted(b))
#输出:[1, 2, 3, 4, 5, 6, 7, 8]
#输出:['A', 'B', 'C', 'D', 'E', 'F']
二、元组
#元组与列表一样,也是一种序列,唯一不同的是元组不能修改。
#1.语法:通过()扩起来,内部用","隔开。
t=(1,2,3)
print(type(t))
#输出:<class 'tuple'>
#2.tuple()函数:与list()函数基本上是一样的,以一个序列为参数,并把它转换为元组,如果参数是元组,则原样返回。
a=[1,2,3]
b=tuple(a)
print(b)
#输出:(1, 2, 3)
完整代码
#1.Python包含6种内建的序列:列表,元组,字符串,Unicode字符串,buffer对象,xrange对象,本文讨论列表和元组。
#2.列表可以修改,元组则不能修改。
#3.几乎在所有的情况下,列表都可以替代元组。#【列表】
#1.语法:列表的各个元素用","分割,写在方括号中。,如:用列表表示数据库中一个人的信息:姓名,性别,年龄
zhangsan=['张三','男',30]
lisi=['李四','女',28]
print(zhangsan)
print(type(zhangsan))
#输出:['张三', '男', 30]
#输出:<class 'list'>#2.序列可以包含其他序列,如:
zhangsan=['张三','男',30]
lisi=['李四','女',28]
users=[zhangsan,lisi]
print(users)
#输出:[['张三', '男', 30], ['李四', '女', 28]]#3.所有序列类型都可以进行:索引,分片,加,乘等操作,以及包含检查元素是否存在,序列长度,最大元素,最小元素等内建函数。
#3.1 索引:索引从0开始递增,使用负数索引时,会从右边计数,右边最后一个元素位置编号是-1,不是0
hello="HelloWorld"
print(hello[0]+"-"+hello[-1])
#输出:H-o#3.2 分片:通过分片来访问一定范围内的元素,通过冒号相隔的两个索引来实现。注意:第1个索引的元素包含在分片内,第2个索引的元素不包含在分片内
hello="SayHelloWorld"
print(hello[3:8])
#输出:Hello
#分片步长:默认步长为1,分片按照这个步长遍历序列元素,然后返回开始和结束点之间的所有元素。
hello="SayHelloWorld"
print(hello[3:8:2])
#输出:Hlo#3.2 序列相加:两种相同类型的序列才能进行连接操作。
a=[1,2,3]
b=[4,5,6]
print(a+b)
#输出:[1, 2, 3, 4, 5, 6]#3.3 乘法:用数字x乘以一个序列,会得到将原序列元素重复x次的新序列
a=[1,2,3]
print(a*3)
#输出:[1, 2, 3, 1, 2, 3, 1, 2, 3]#3.4 检查元素是否存在:使用in运算符
print("H" in hello)
#输出:True
zhangsan=['张三','男',30]
lisi=['李四','女',28]
users=[zhangsan,lisi]
print(['张三','男',30] in users)
#输出:True#3.5 len,max,min 函数
num=[100,34,678]
print(str(len(num))+"-"+str(max(num))+"-"+str(min(num)))
#输出:3-678-34#4.列表方法(函数)
#4.1 list函数:因为字符串不能像列表一样被修改,可以将字符串转换为列表
hello="HelloWorld"
hellolist=list(hello)
print(hellolist)
#输出:['H', 'e', 'l', 'l', 'o', 'W', 'o', 'r', 'l', 'd']#反之,将列表组装成字符串,需要用到join函数
hello2="".join(['H', 'e', 'l', 'l', 'o', 'W', 'o', 'r', 'l', 'd'])
print(hello2)
#输出:HelloWorld#4.2 删除元素
names=["zhangsan","lisi","wangwu"]
del names[1]
print(names)
#输出:['zhangsan', 'wangwu']#4.3 append()方法:在列表末尾追加新元素
num=[1,2,3]
num.append(4)
print(num)
#输出:[1, 2, 3, 4]#4.3 count()方法:统计某个元素在列表中出现的次数
chars=['A','B','A','C','A']
print(chars.count("A"))
#输出:3#4.4 extend()方法:在列表的末尾一次性追加另一个序列中的多个值
#注意:extend()方法修改了被扩展的序列,而a+b是两个序列的连接操作,它返回的是一个新的序列
a=[1,2,3]
b=[4,5,6]
c=a+b
a.extend(b)
print(a)
print(c)
#输出:[1, 2, 3, 4, 5, 6]
#输出:[1, 2, 3, 4, 5, 6]#4.5 index()方法:用于在列表中找出某个值第一个匹配的索引位置
chars=['A','B','A','C','A']
print(chars.index("C"))
#输出:3#4.6 insert()方法:用于将对象插入到列表中
a=[1,2,3]
a.insert(1,"A")
print(a)
#输出:[1, 'A', 2, 3]#4.7 pop()方法:会移除列表中的一个元素(默认是最后一个),并发返回该元素的值
#pop方法是唯一一个既能修改列表,又能返回元素值(除了None)的列表方法(类似栈,后进先出)
a=[1,2,3]
b=a.pop(1)
print(a)
print(b)
#输出:[1, 3]
#输出:2#4.8 remove()方法:用于移除列表中某个位置的第一个匹配项
a=[1,2,3,'A','B','C']
a.remove('A')
print(a)
#输出:[1, 2, 3, 'B', 'C']#4.9 reverse()方法:用于将列表中的元素反向存放
a=[1,2,3]
a.reverse()
print(a)
#输出:[3, 2, 1]#4.9 sort()方法:用于在原位置对列表进行排序,改变原来的列表,而不是返回新的列表
a=[1,7,4,5,3,6,2,8]
b=['E','B','D','F','C','A']
a.sort()
b.sort()
print(a)
print(b)
#输出:[1, 2, 3, 4, 5, 6, 7, 8]
#输出:['A', 'B', 'C', 'D', 'E', 'F']#如果只是想获取排序后的列表,而不是修改原列表,可以使用sorted()方法
a=[1,7,4,5,3,6,2,8]
b=['E','B','D','F','C','A']
print(sorted(a))
print(sorted(b))
#输出:[1, 2, 3, 4, 5, 6, 7, 8]
#输出:['A', 'B', 'C', 'D', 'E', 'F']#二、元组
#元组与列表一样,也是一种序列,唯一不同的是元组不能修改。
#1.语法:通过()扩起来,内部用","隔开。
t=(1,2,3)
print(type(t))
#输出:<class 'tuple'>#2.tuple()函数:与list()函数基本上是一样的,以一个序列为参数,并把它转换为元组,如果参数是元组,则原样返回。
a=[1,2,3]
b=tuple(a)
print(b)
#输出:(1, 2, 3)
相关文章:
和元组(tuple))
Python基础-列表(list)和元组(tuple)
Python包含6种内建的序列:列表,元组,字符串,Unicode字符串,buffer对象,xrange对象,本文讨论列表和元组。 1.列表可以修改,元组则不能修改。 2.几乎在所有的情况下,列表…...

Dubbo介绍及使用
🍓 简介:java系列技术分享(👉持续更新中…🔥) 🍓 初衷:一起学习、一起进步、坚持不懈 🍓 如果文章内容有误与您的想法不一致,欢迎大家在评论区指正🙏 🍓 希望这篇文章对你有所帮助,欢…...

初阶C语言-分支和循环语句(下)
“花会沿途盛开,以后的路也是。” 今天我们一起来继续学完分支语句和循环语句。 分支和循环 3.循环语句3.4 do...while()循环3.4.1 do语句的用法 3.5关于循环的一些练习3.6 goto语句 3.循环语句 3.4 do…while()循环 3.4.1 do语句的用法 do循环语句;//当循环语句…...

pytorch工具——pytorch中的autograd
目录 关于torch.tensor关于tensor的操作关于梯度gradients 关于torch.tensor 关于tensor的操作 x1torch.ones(3,3) xtorch.ones(2,2,requires_gradTrue) print(x1,\n,x)yx2 print(y) print(x.grad_fn) print(y.grad_fn)zy*y*3 outz.mean() print(z,out)注意 atorch.randn(2,…...

Linux--进程池
1.一个父进程生成五个子进程且分别建立与子进程管道 ①用for循环,结束条件为<5 ②father父进程每次都要离开for循环,生成下一个子进程和管道 2.#include <cassert>和#include <assert.h>的区别 assert.h 是 C 标准库的头文件ÿ…...

SpringCloudAlibaba微服务实战系列(四)Sentinel熔断降级、异常fallback、block细致处理
SpringCloudAlibaba Sentinel降级和熔断 接着上篇文章的内容,在Sentinel中如何进行降级和熔断呢? 熔断降级规则 降级规则 在Sentinel中降级主要有三个策略:RT、异常比例、异常数,也是针对某个资源的设置。而在1.8.0版本后RT改为…...
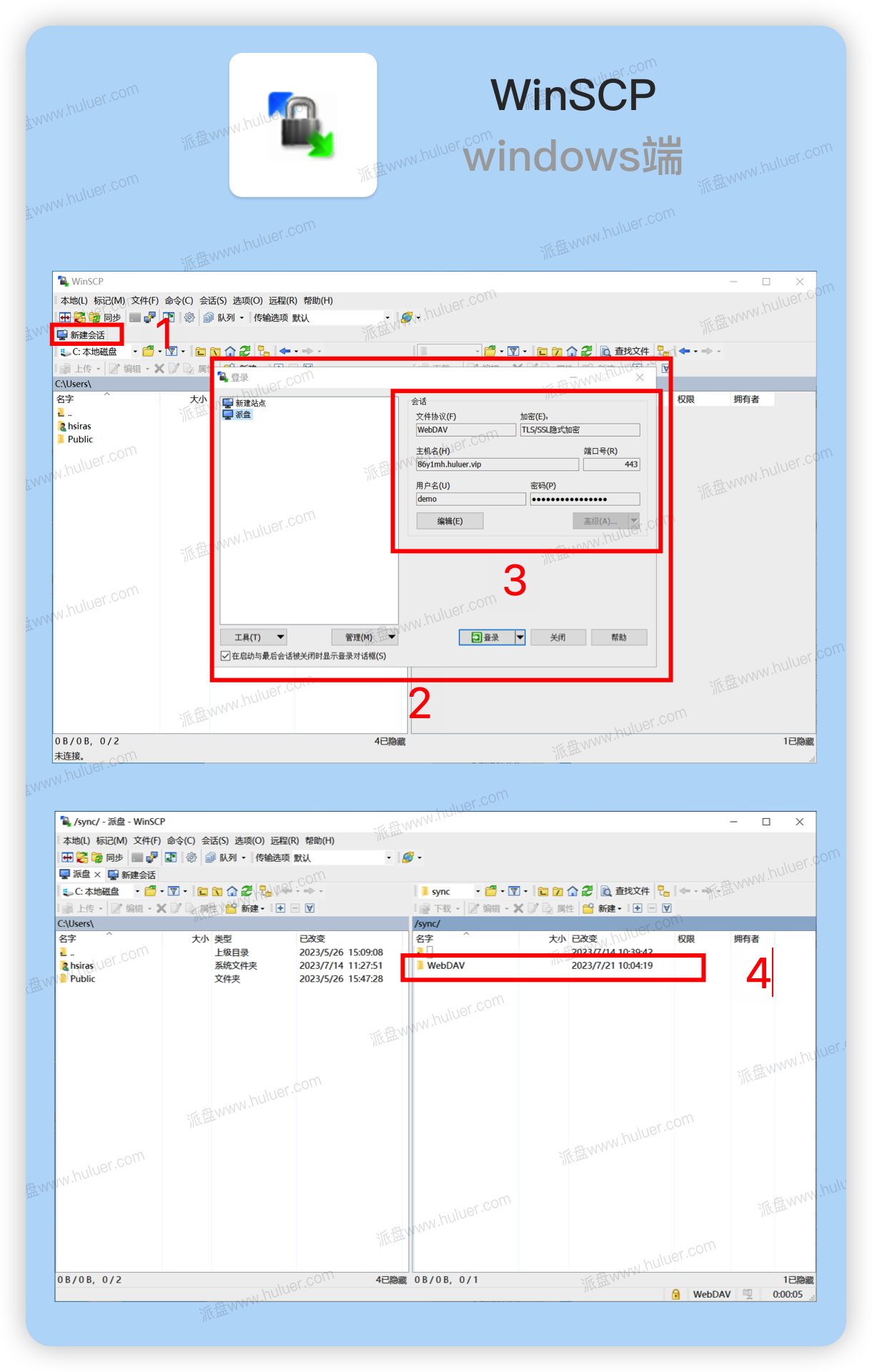
WebDAV之π-Disk派盘+ WinSCP
WinSCP是一个免费的开源文件传输应用程序,它使用文件传输协议,安全外壳文件传输协议和安全复制协议来进行纯文件或安全文件传输。该应用程序旨在与Windows一起使用,并支持常见的Windows桌面功能,例如拖放文件,跳转列表…...
Python案例分析|使用Python图像处理库Pillow处理图像文件
本案例通过使用Python图像处理库Pillow,帮助大家进一步了解Python的基本概念:模块、对象、方法和函数的使用 使用Python语言解决实际问题时,往往需要使用由第三方开发的开源Python软件库。 本案例使用图像处理库Pillow中的模块、对象来处理…...

音视频——压缩原理
H264视频压缩算法现在无疑是所有视频压缩技术中使用最广泛, 最流行的。随着 x264/openh264以及ffmpeg等开源库的推出,大多数使用者无需再对H264的细节做过多的研究,这大降低了人们使用H264的成本。 但为了用好H264,我们还是要对…...

微服务 云原生:搭建 K8S 集群
为节约时间和成本,仅供学习使用,直接在两台虚拟机上模拟 K8S 集群搭建 踩坑之旅 系统环境:CentOS-7-x86_64-Minimal-2009 镜像,为方便起见,直接在 root 账户下操作,现实情况最好不要这样做。 基础准备 关…...
C++中的数学问题---进制转换
二进制转十六进制 string binToHex(string bin){string hex"";if(bin.size()%4!0){for(int i0;i<(4-bin.size()%4);i){bin"0"bin;}}for(int i0;i<bin.size();i4){string tmpbin.substr(i,4);bitset<4>b(tmp);hexb.to_ulong()<10?char(b.t…...
开发一个RISC-V上的操作系统(三)—— 串口驱动程序(UART)
目录 文章传送门 一、什么是串口 二、本项目串口的FPGA实现 三、串口驱动程序的编写 四、上板测试 文章传送门 开发一个RISC-V上的操作系统(一)—— 环境搭建_riscv开发环境_Patarw_Li的博客-CSDN博客 开发一个RISC-V上的操作系统(二&…...

nuxt项目部署,npm run build 和npm run generate的区别
每日鸡汤:每个你想要学习的瞬间都是未来的你向自己求救 非服务端渲染的项目,比如普通的vite vue项目,我们在部署生产环境的时候,只需要两步 运行 npm run build 然后得到了一个 dist 文件夹将这个dist文件夹部署到一个静态服务器…...

数据仓库设计理论
数据仓库设计理论 一、数据仓库基本概念 1.1、数据仓库介绍 数据仓库是一个用于集成、存储和分析大量结构化和非结构化数据的中心化数据存储系统。它旨在支持企业的决策制定和业务分析活动。 1.2、基本特征 主题导向:数据仓库围绕特定的主题或业务领域进行建模…...
数据接口有哪些?(数据接口有哪几种)
数据接口是指不同应用程序或系统之间交换数据的通信界面。在现代信息化社会中,数据接口扮演着极为重要的角色,它们使得不同平台之间能够相互连接和交流,从而实现数据共享和应用集成。 数据接口的种类繁多,常见的有以下几种&#…...
华为云CodeArts产品体验的心得体会及想法
文章目录 前言CodeArts 的产品优势一站式软件开发生产线研发安全Built-In华为多年研发实践能力及规范外溢高质高效敏捷交付 功能特性说明体验感受问题描述完结 前言 华为云作为一家全球领先的云计算服务提供商,致力于为企业和个人用户提供高效、安全、可靠的云服务。…...
下载安装:SQLite+SQLiteStudio+VS
目录 1、SQLite 1.1、下载SQLite 1.2、配置SQLite的环境变量 2、SQLite Studio 2.1、下载SQLite Studio 2.2、安装SQLite Studio 3、Visual Studio 3.1、下载Visual Studio 3.2、安装Visual Studio 1、SQLite 1.1、下载SQLite SQLite官网:SQLite Downl…...

nginx路由
一般我们经常在访问网站时,通常会遇到输入某个页面的网址时,出现路由的转发,重定向等。可能访问的是一个网址,出来的时候就显示的是另外的地址。这是由于使用了nginx的缘故,保护了网址的安全性 (1…...
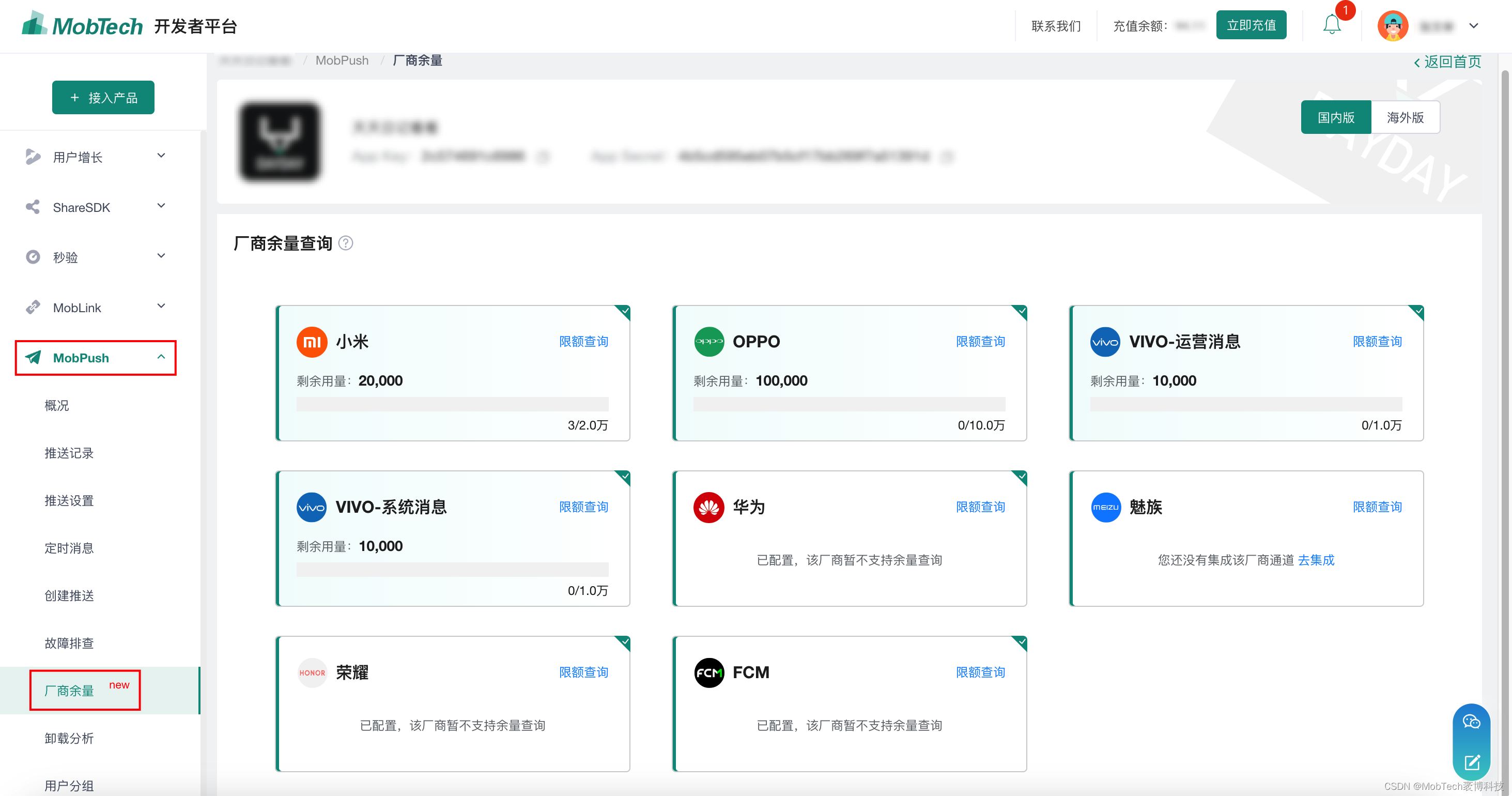
MobPush Android SDK 厂商推送限制
概述 厂商推送限制 每个厂商通道都有对应的厂商配额和 QPS 限制,当请求超过限制且已配置厂商回执时,MobPush会采取以下措施: 当开发者推送请求超过厂商配额时,MobPush将通过自有通道进行消息下发。当开发者推送请求超过厂商 QP…...
计算机网络 day7 扫描IP脚本 - 路由器 - ping某网址的过程
目录 network 和 NetworkManager关系: 实验:编写一个扫描脚本,知道本局域网里哪些ip在使用,哪些没有使用? 使用的ip对应的mac地址都要显示出来 计算机程序执行的两种不同方式: shell语言编写扫描脚本 …...

VisualVM企业级部署指南:大规模Java应用监控最佳实践
VisualVM企业级部署指南:大规模Java应用监控最佳实践 【免费下载链接】visualvm VisualVM is an All-in-One Java Troubleshooting Tool 项目地址: https://gitcode.com/gh_mirrors/vi/visualvm VisualVM是一款功能强大的全合一Java故障排除工具,…...

【NSudo】功能定位:开源权限管理工具的系统运维解决方案
【NSudo】功能定位:开源权限管理工具的系统运维解决方案 【免费下载链接】NSudo [Deprecated, work in progress alternative: https://github.com/M2Team/NanaRun] Series of System Administration Tools 项目地址: https://gitcode.com/gh_mirrors/ns/NSudo …...

dmview.ocx文件丢失找不到 打不开程序 免费下载方法分享
在使用电脑系统时经常会出现丢失找不到某些文件的情况,由于很多常用软件都是采用 Microsoft Visual Studio 编写的,所以这类软件的运行需要依赖微软Visual C运行库,比如像 QQ、迅雷、Adobe 软件等等,如果没有安装VC运行库或者安装…...

头歌平台实战:C语言文件操作中的数字提取与格式化存储
1. 头歌平台C语言文件操作实战入门 第一次接触头歌平台的C语言文件操作任务时,我完全被那些fopen、fscanf函数弄晕了。直到真正动手完成"数字提取与格式化存储"这个项目,才发现原来文件操作可以这么有趣又实用。这个项目特别适合刚学完C语言基…...

Nunchaku FLUX.1-dev 提示词工程入门:编写高质量Prompt的实用技巧与范例
Nunchaku FLUX.1-dev 提示词工程入门:编写高质量Prompt的实用技巧与范例 你是不是也遇到过这种情况:用同一个开源大模型,别人生成的图片精美绝伦,自己生成的却总差点意思,要么主体不对,要么风格跑偏&#…...

Musicdl革新性全场景音乐解决方案:5个维度揭秘开源音乐下载技术的破局之道
Musicdl革新性全场景音乐解决方案:5个维度揭秘开源音乐下载技术的破局之道 【免费下载链接】musicdl Musicdl: A lightweight music downloader written in pure python. 项目地址: https://gitcode.com/gh_mirrors/mu/musicdl 在数字音乐产业蓬勃发展的今天…...

手把手教你解决MMLab中ImportError: cannot import name ‘set_random_seed‘错误
深度解析MMLab中set_random_seed导入错误的本质与系统化解决方案 当你第一次在MMLab生态中遇到ImportError: cannot import name set_random_seed from mmdet.apis这个错误时,可能会感到困惑和沮丧。这个看似简单的导入错误背后,实际上反映了开源计算机视…...

手机号逆向查询QQ号:3步快速找回QQ号的终极免费方案
手机号逆向查询QQ号:3步快速找回QQ号的终极免费方案 【免费下载链接】phone2qq 项目地址: https://gitcode.com/gh_mirrors/ph/phone2qq 你是否曾因忘记QQ号而无法登录重要账号?手机号逆向查询QQ号工具为你提供了一种简单高效的解决方案。这个基…...

从百兆到千兆:RJ45网口背后的技术演进与协议优化全解析
从百兆到千兆:RJ45网口背后的技术演进与协议优化全解析 当你拿起一根普通的网线连接电脑时,可能不会想到这根看似简单的线缆背后隐藏着怎样的技术革命。从最初的10Mbps到如今的千兆以太网,RJ45接口承载了网络通信技术的巨大飞跃。本文将带你深…...
Qwen-Image-2512-Pixel-Art-LoRA 模型v1.0 传统艺术数字化:将油画、素描转化为像素风数字藏品
Qwen-Image-2512-Pixel-Art-LoRA 模型v1.0:当古典艺术遇见像素方块 最近在数字艺术圈里,有个话题挺有意思:怎么把那些挂在博物馆里的古典油画、素描,变成年轻人也爱玩的像素风数字藏品?听起来像是把交响乐改编成8-bit…...