语言模型输出端共享Embedding的重新探索

©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 科学空间
研究方向 | NLP、神经网络
预训练刚兴起时,在语言模型的输出端重用 Embedding 权重是很常见的操作,比如 BERT、第一版的 T5、早期的 GPT,都使用了这个操作,这是因为当模型主干部分不大且词表很大时,Embedding 层的参数量很可观,如果输出端再新增一个独立的同样大小的权重矩阵的话,会导致显存消耗的激增。
不过随着模型参数规模的增大,Embedding 层的占比相对变小了,加之《Rethinking embedding coupling in pre-trained language models》[1] 等研究表明共享 Embedding 可能会有些负面影响,所以现在共享 Embedding 的做法已经越来越少了。
本文旨在分析在共享 Embedding 权重时可能遇到的问题,并探索如何更有效地进行初始化和参数化。尽管共享 Embedding 看起来已经“过时”,但这依然不失为一道有趣的研究题目。

共享权重
在语言模型的输出端重用 Embedding 权重的做法,英文称之为 “Tied Embeddings” 或者 “Coupled Embeddings”,其思想主要是 Embedding 矩阵跟输出端转换到 logits 的投影矩阵大小是相同的(只差个转置),并且由于这个参数矩阵比较大,所以为了避免不必要的浪费,干脆共用同一个权重,如下图所示:

▲ 共享 Embedding 权重的 Transformer 示意图
共享 Embedding 最直接的后果可能是——它会导致预训练的初始损失非常大。这是因为我们通常会使用类似 DeepNorm 的技术来降低训练难度,它们都是将模型的残差分支初始化得接近于零。换言之,模型在初始阶段近似于一个恒等函数,这使得初始模型相当于共享 Embedding 的 2-gram 模型。接下来我们将推导这样的 2-gram 模型损失大的原因,以及分析一些解决方案。

准备工作
在正式开始推导之前,我们需要准备一些基础结论。
首先,要明确的是,我们主要对初始阶段的结果进行分析,此时的权重都是从某个“均值为 0、方差为 ”的分布中独立同分布地采样出来的,这允许我们通过期望来估计某些求和结果。比如对于 ,我们有

因此可以取 。那么误差有多大呢?我们可以通过它的方差来感知。为此,我们先求它的二阶矩:
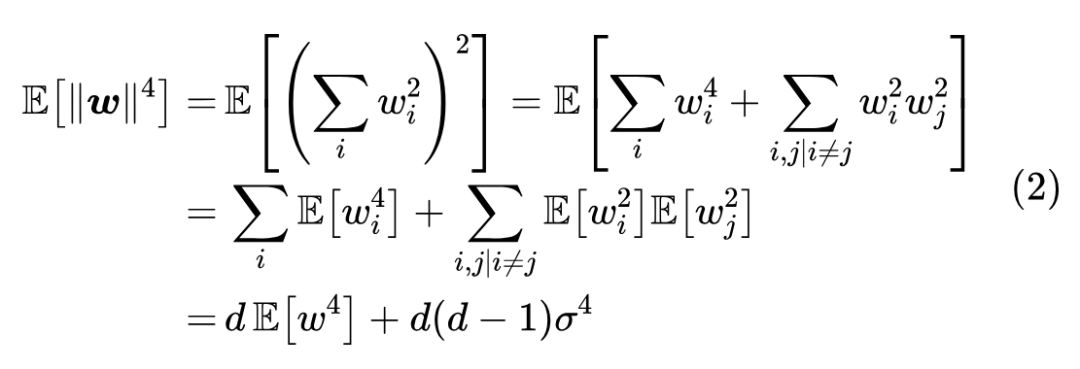
如果采样分布是正态分布,那么可以直接算出 ,所以

这个方差大小也代表着 的近似程度,也就是说原本的采样方差 越小,那么近似程度越高。特别地,常见的采样方差是 (对应 ,即单位向量),那么代入上式得到 ,意味着维度越高近似程度越高。此外,如果采样分布不是正态分布,可以另外重新计算 ,或者直接将正态分布的结果作为参考结果,反正都只是一个估算罢了。
如果 是另一个独立同分布向量,那么我们可以用同样的方法估计内积,结果是

以及
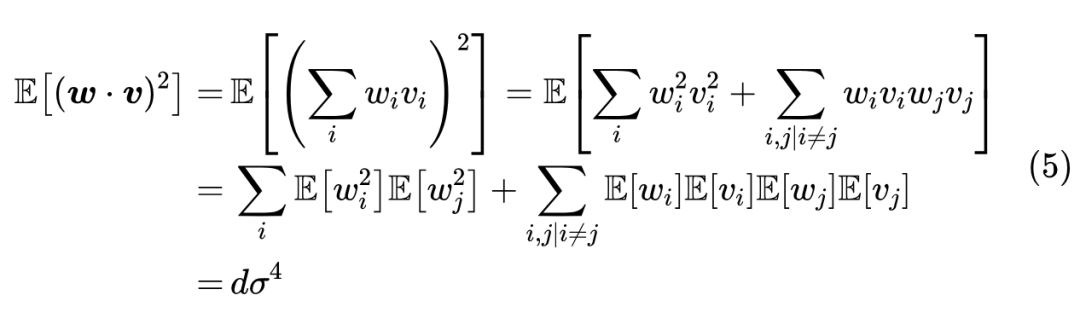
同样地,取 的话,那么方差是 ,维度越高近似程度越高。以上两个结果可以说是《n维空间下两个随机向量的夹角分布》[2]、《让人惊叹的Johnson-Lindenstrauss引理:理论篇》中的结论的统计版本。

损失分析
对语言模型来说,最终要输出一个逐 token 的 元分布,这里 是词表大小。假设我们直接输出均匀分布,也就是每个 token 的概率都是 ,那么不难计算交叉熵损失将会是 。这也就意味着,合理的初始化不应该使得初始损失明显超过 ,因为 代表了最朴素的均匀分布,明显超过 等价于说远远不如均匀分布,就好比是故意犯错,并不合理。
那么,为什么共享 Embedding 会出现这种情况呢?假设初始 Embedding 是 ,前面已经说了,初始阶段残差分支接近于零,所以输入输入 token ,模型输出就是经过 Normalization 之后的 Embedding 。常见的 Normalization 就是 Layer Norm 或者 RMS Norm,由于初始化分布是零均值的,所以 Layer Norm 跟 RMS Norm 大致等价,因此输出是
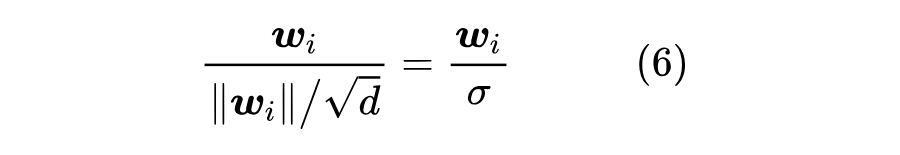
接下来重用 Embedding,内积然后 Softmax,所建立的分布实质是

对应的损失函数就是
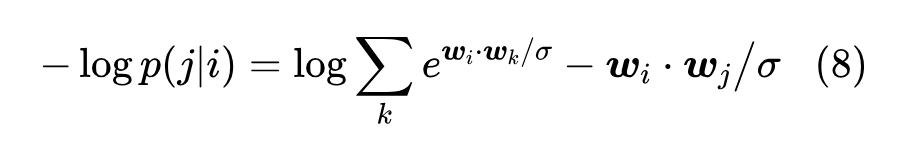
语言模型任务是为了预测下一个 token,而我们知道自然句子中叠词的比例很小,所以基本上可以认为 ,那么根据结果 (4) 就有 。所以,初始损失函数是

后面的 再次用到了式(1)和式(4)。常见的初始化方差 ,或者是一个常数,或者是 (此时 ),不管是哪一种,当 较大时,都导致 占主导,于是损失将会是 级别,这很容易就超过了均匀分布的 。

一些对策
根据上述推导结果,我们就可以针对性地设计一些对策了。比较直接的方案是调整初始化,根据式(9),我们只需要让 ,那么初始损失就是变成 级别的,也就是说初始化的标准差要改为 。
一般来说,我们会希望参数的初始化方差尽量大一些,这样梯度相对来说没那么容易下溢,而 有时候会显得过小了。为此,我们可以换一种思路:很明显,式(9)之所以会偏大,是因为出现了 ,由于两个 相同,它们内积变成了模长,从而变得很大,如果能让它们不同,那么就不会出现这一个占主导的项了。
为此,最简单的方法自然是干脆不共享 Embedding,此时是 而不是 ,用(4)而不是(1)作为近似,于是式(9)渐近于 。如果还想保留共享 Embedding,我们可以在最后的 Normalization 之后,再接一个正交初始化的投影层,这样 变成了 ,根据 Johnson-Lindenstrauss 引理,经过随机投影的向量近似于独立向量了,所以也近似于不共享的情况,这其实就是 BERT 的解决办法。特别地,这个投影层还可以一般化地加上 bias 和激活函数。
如果一丁点额外参数都不想引入,那么可以考虑在 Normalization 之后“打乱” 的各个维度,
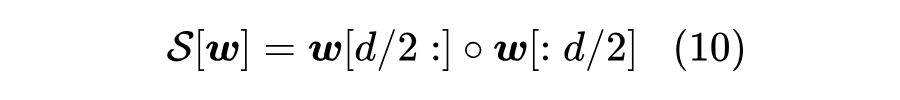
这里的 是拼接操作,那么 和 也接近正交了,内积自然也约等于0。这相当于(在初始阶段)将原来的 的 Embedding 矩阵劈开为两个 的矩阵然后构建不共享 Embedding 的 2-gram 模型。另外,我们还可以考虑其他打乱操作,比如 ShuffleNet [3] 中的先 reshape,然后 transpose 再 reshape 回来。
在笔者的实验中,直接改初始化标准差为 收敛速度是最慢的,其余方法收敛速度差不多,至于最终效果,所有方法似乎都差不多。

文章小结
本文重温了语言模型输出端共享 Embedding 权重的操作,推导了直接重用 Embedding 来投影输出可能会导致损失过大的可能性,并探讨了一些解决办法。

参考文献
[1] https://arxiv.org/abs/2010.12821
[2] https://kexue.fm/archives/7076
[3] https://arxiv.org/abs/1707.01083
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·

相关文章:
语言模型输出端共享Embedding的重新探索
©PaperWeekly 原创 作者 | 苏剑林 单位 | 科学空间 研究方向 | NLP、神经网络 预训练刚兴起时,在语言模型的输出端重用 Embedding 权重是很常见的操作,比如 BERT、第一版的 T5、早期的 GPT,都使用了这个操作,这是因为当模型…...
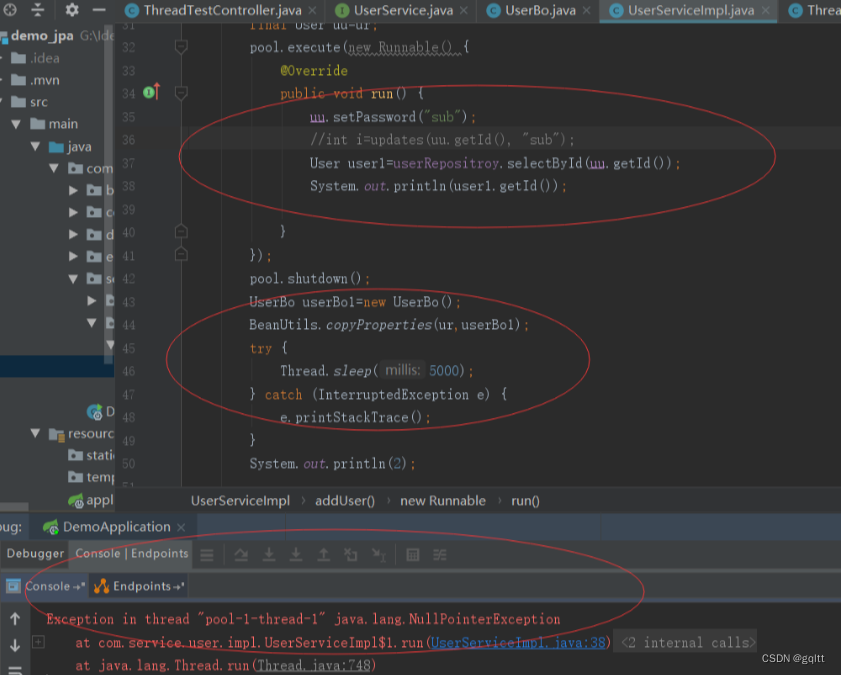
Spring中事务失效的8中场景
1. 数据库引擎不支持事务 这里以 MySQL为例,MyISAM引擎是不支持事务操作的,一般要支持事务都会使用InnoDB引擎,根据MySQL 的官方文档说明,从MySQL 5.5.5 开始的默认存储引擎是 InnoDB,之前默认的都是 MyISAMÿ…...

安卓——转场动画
先创建一个名为anim的包 往里面写入两个xml页 为淡入淡出的效果 淡入效果 <alpha xmlns:android="http://schemas.android.com/apk/res/android"android:interpolator="@android:anim/accelerate_decelerate_interpolator"android:fromAlpha...
)
多位数码管动态扫描显示变化数据(数码管右移1)
/*----------------------------------------------- 内容:多位数码管分别显示不同数字,这种扫描显示方式成为动态扫描,并不停变化赋值 ------------------------------------------------*/ #include<reg52.h> //包含头文件࿰…...
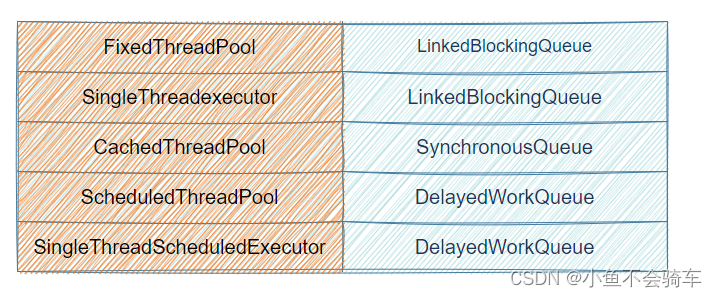
充分了解java阻塞队列机制
多线程基础 1.阻塞队列1.1 什么是 阻塞队列1.2 阻塞队列的特点 1.3 阻塞队列常用方法1.3.1 抛出异常:add、remove、element1.3.2 返回结果但是不抛出异常offer、poll、peek1.3.3 阻塞put和take1.3.4 小结 1.4 常见的阻塞队列1.4.1 ArrayListBlockingQueue1.4.2 LinkedBlockingQ…...

安装使用LangChain时的报错解决
刚刚装了LangChain但是引入各种包都报错,原因貌似为 Python3.7 不支持 LangChain,需要开启一个新的Python3.10环境,再重新安装即可正常运行。 创建新的python环境 conda create -n new_env python3.10 重新安装 pip install langchain 这是当…...
【MySQL】库的操作
🌠 作者:阿亮joy. 🎆专栏:《零基础入门MySQL》 🎇 座右铭:每个优秀的人都有一段沉默的时光,那段时光是付出了很多努力却得不到结果的日子,我们把它叫做扎根 目录 👉库…...

Java设计模式之工厂模式
什么是工厂模式 工厂模式(Factory Pattern)是 Java 中最常用的设计模式之一。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。 工厂模式提供了一种将对象的实例化过程封装在工厂类中的方式。通过使用工厂模式ÿ…...

正则表达式-速成教程
正则表达式-速成教程 今天遇到一枚程序媛在群里吐槽,并附了截图;然后无意中看到她的一个正则与她的注释描述不一致,就提醒了一下。顺带着给了个速成教程,在这里把这个速成教程贴出来,一是为了自己备份;二是…...
C语言中的数组(详解)
C语言中的数组(详解) 一、一维数组1.一维数组的创建2.数组的初始化3.一维数组的使用4.一维数组在内存中的存储二、二维数组1.二维数组的创建2.二维数组的初始化3.二维数组的使用4.二维数组在内存中的存储三、数组越界四、数组作为函数参数1.冒泡排序2.数…...

【App管理04-Bug修正 Objective-C语言】
一、咱们刚才已经把这个给大家做完了吧 1.这个Label怎么显示到上面去了, 我们现在是把它加到我们的控制器的View里面吧 我们看一下这个坐标是怎么算的,来,我们找一个坐标, 咱们的坐标,是不是用这个View的frame,减的吧 来,咱们在这里,输出一下这个Frame,看一下吧 在…...
黑客自学笔记(网络安全)
一、黑客是什么 原是指热心于计算机技术,水平高超的电脑专家,尤其是程序设计人员。但后来,黑客一词已被用于泛指那些专门利用电脑网络搞破坏或者恶作剧的家伙。 二、学习黑客技术的原因 其实,网络信息空间安全已经成为海陆空之…...

action=store_true和store_false理解及实战测试
store_true 是指带触发 action 时为真,不触发则为假, 即默认 False ,传参 则 设置为 True store_false 则与之相反 以代码为例: import sys import argparse def parse_args():parser argparse.ArgumentParser(descriptionrun …...

Android 通用带箭头提示窗
简介 自定义PopupWindow, 适用于提示类弹窗。 使用自定义Drawable设置带箭头的背景,测试控件和弹窗的尺寸,自动设置弹窗的显示位置,让箭头指向锚点控件的中间位置,且根据锚点控件在屏幕的位置,自动适配弹窗显示位置。…...

隧道安全监测解决方案
隧道安全监测 解决方案 一、监测目的 通过监控量测,实现信息化施工,不仅能及时掌握隧道实际的地质情况,掌握隧道围岩、支护衬砌结构的受力特征和变形情况,据此可以尽早发现塌方、大变形等灾害征兆,及时采取措施&…...
3 Linux基础篇-VMware和Linux的安装
3 Linux基础篇-VMware和Linux的安装 文章目录 3 Linux基础篇-VMware和Linux的安装3.1 安装VMware和CentOS3.1.1 VM安装3.1.2 Centos7.6的安装步骤 3.3 虚拟机基本操作3.4 安装VMtools3.5 设置共享文件夹 学习视频来自于B站【小白入门 通俗易懂】2021韩顺平 一周学会Linux。可能…...

什么是预处理器指令,常用的预处理器指令有哪些?什么是运算符,C 语言中的运算符有哪些?
1.什么是预处理器指令,常用的预处理器指令有哪些? 预处理器指令是一种用于在源代码编译之前进行预处理的特殊指令。它们通过在程序编译之前对源代码进行处理,可以在编译阶段之前进行一些文本替换、条件编译等操作,从而对源代码进…...
新功能 – Cloud WAN:托管 WAN 服务
我很高兴地宣布,我们推出了 Amazon Cloud WAN,这是一项新的网络服务,它可以轻松构建和运营连接您的数据中心和分支机构以及多个 Amazon 区域中的多个 VPC 的广域网(WAN)。 亚马逊云科技开发者社区为开发者们提供全球的…...
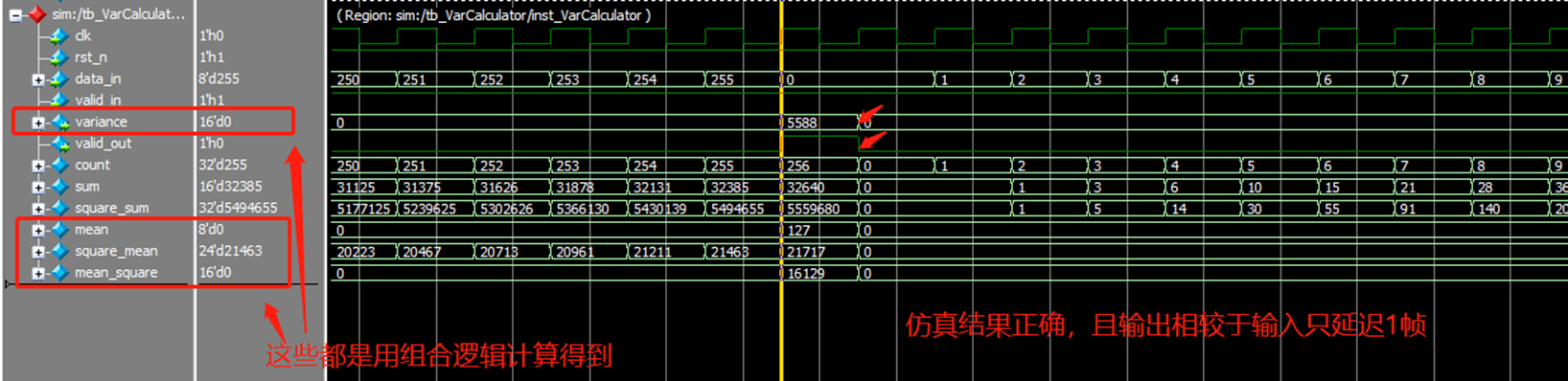
FPGA_学习_13_方差计算小模块
测距器件APD的性能与器件本身的温度、施加在APD的偏置电压息息相关。 在不同的温度下,APD的偏压对测距性能的影响非常大。 要确定一个合适的APD的偏压Vopt,首先你要知道当前温度下,APD的击穿电压Vbr,一般来讲,Vopt Vb…...
如何安装多个版本的python,python可以装两个版本吗
这篇文章主要介绍了可不可以在同一台计算机上安装多个python版本,具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获,下面让小编带着大家一起了解一下。 1、不同版本的python不能安装到同一台计算机上 可以的&#…...

机器学习周报三十九
文章目录摘要Abstract1.TurboDiffusion1.1 注意力改进1.2蒸馏模型1.3权重量化2 训练和推理2.1 训练阶段2.2 推理阶段3 Make It Count3.1数据集3.2损失函数总结摘要 本周阅读了清华大学的论文《TurboDiffusion: Accelerating Video Diffusion Models by 100–200 Times》&#…...
)
DeepSeek LeetCode 1210. 穿过迷宫的最少移动次数 public int minimumMoves(int[][] grid)
我来分析 LeetCode 1210 “穿过迷宫的最少移动次数” 的解题思路和实现。 问题分析 我们有一条长度为 2 的蛇,需要从起点 (0,0) 和 (0,1)(水平放置)移动到终点 (n-1, n-2) 和 (n-1, n-1)(仍为水平放置)。蛇可以&#x…...

网站SEO优化有哪些技巧
网站SEO优化有哪些技巧 在当前数字化时代,拥有一个高效的网站SEO优化策略至关重要。无论你是新手还是资深网站管理者,了解网站SEO优化的技巧都能帮助你在百度等搜索引擎上获得更高的排名,从而吸引更多的流量。本文将详细探讨网站SEO优化的一…...

10点滑动平均滤波器:嵌入式零依赖高效实现
1. 项目概述MovingAverageFilter 是一个轻量级、零依赖的嵌入式数字滤波器实现,专为资源受限的微控制器环境设计。其核心功能是执行固定长度(10点)的滑动平均(Moving Average)运算,并在每次新采样输入后立即…...

AI摄影师助手:OpenClaw调用Qwen3-32B自动筛选与修图
AI摄影师助手:OpenClaw调用Qwen3-32B自动筛选与修图 1. 从手动修图到AI助手的转变 作为一名摄影爱好者,我经常面临一个令人头疼的问题:每次拍摄结束后,相机里堆积如山的RAW文件需要花费大量时间筛选和后期处理。直到上个月&…...

C++ lambda 捕获机制与作用域
C lambda 捕获机制与作用域探析 在C11引入的lambda表达式为开发者提供了更灵活的匿名函数实现方式,其核心特性之一是捕获机制,允许lambda访问外部作用域的变量。理解捕获规则与作用域的关系,不仅能避免常见错误,还能提升代码的简…...

从“中式英语”到地道表达:我用Notion搭建了一个动态写作原则库
从“中式英语”到地道表达:我用Notion搭建了一个动态写作原则库 第一次参加国际学术会议时,我站在海报前手足无措——不是研究内容不够扎实,而是当外国学者用"Your findings are intriguing but the methodology section lacks clarity&…...
)
Ubuntu 20.04忘记密码?5分钟搞定root和用户密码重置(附GRUB菜单截图)
Ubuntu 20.04密码重置实战指南:从GRUB到恢复模式的完整流程 当你面对一台锁定的Ubuntu 20.04机器时,那种焦虑感我深有体会——无论是个人开发环境还是团队共享服务器,密码遗忘都可能造成工作流程的中断。不同于Windows系统的密码重置工具&am…...

光学工程师进阶指南:从入门到精通的实战路径
1. 光学工程师的职业发展路径 光学工程师的成长就像搭积木,需要从最基础的模块开始,一层层往上搭建。我刚入行时也走过不少弯路,后来才明白这个职业的发展是有明确路径的。一般来说,我们可以把成长过程分为三个阶段:初…...

Harbor集成Trivy实现镜像安全扫描:从安装到离线环境配置全指南
1. 为什么需要Harbor集成Trivy进行镜像安全扫描 在容器化部署成为主流的今天,一个NGINX镜像可能隐藏着数十个安全漏洞而不自知。去年某金融公司就曾因为使用了存在高危漏洞的Redis镜像,导致数据泄露事件。这种案例让我深刻意识到:镜像安全扫描…...