论文代码学习—HiFi-GAN(2)——鉴别器discriminator代码
文章目录
- 引言
- 正文
- 鉴别器
- 多周期鉴定器
- 多尺度鉴定器
- 问题
- 总结
引言
- 这里翻译了HiFi-GAN这篇论文的具体内容,具体链接。
- 这篇文章还是学到了很多东西,从整体上说,学到了生成对抗网络的构建思路,包括生成器和鉴定器。细化到具体实现的细节,如何 实现对于特定周期的数据处理?在细化,膨胀卷积是如何实现的?这些通过文章,仅仅是了解大概的实现原理,但是对于代码的实现细节并不是很了解。如果要加深印象,还是要结合代码来具体看一下实现的细节。
- 本文主要围绕具体的代码实现细节展开,对于相关原理,只会简单引用和讲解。因为官方代码使用的是pytorch,所以是通过pytorch展开的。
- 当前这篇主要介绍鉴别器的具体实现,在HiFi-GAN中,鉴别器分是由周期鉴别器和尺度鉴别器构成,当前这篇将就两种鉴别器的原理和功能进行具体讲解。
正文
鉴别器
- 因为声音信号中的长依赖比较重要,常规的做法是通过增加鉴别器的感受野,或者增加输入数据的维度来获取这种长领域特征。在HiFi-GAN是采用了增加输入信号的范围,采用多尺度鉴定器实现MSD。另外因为声音可以通过短时傅立叶变换,拆解成不同的周期的正弦信号叠加,HiFi-GAN专门采用了多周期鉴定器见捕捉每一段信号的不同周期特征。
多周期鉴定器
- 多周期鉴定器是有专门针对不同周期信号的若干子鉴定器构成,对于多周期信号,是通过对原始的波形信号进行不同间隔进行采样,将原来的一维波形数据,变成二维信号,然后在对其进行卷积。而且每一次卷积都是专门针对某一行数据,也就是某一个间隔采样生成的数据。具体可以看如下示意图。
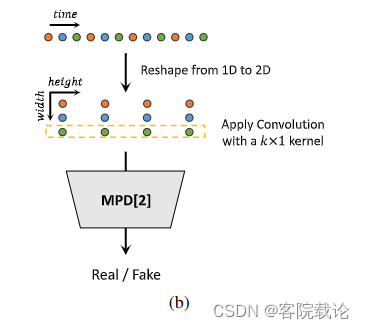
- 由于数据经过等间隔采样,每一行是某一个周期信号,然后若干行表示有若干个周期信号,然后进行宽度为1,高度为特定长度的周期T/p的二维卷积采样,具体如下。每一个颜色都是按照一定间隔进行采样之后的数据,然后整个卷积层也是按照一个周期进行生成的。
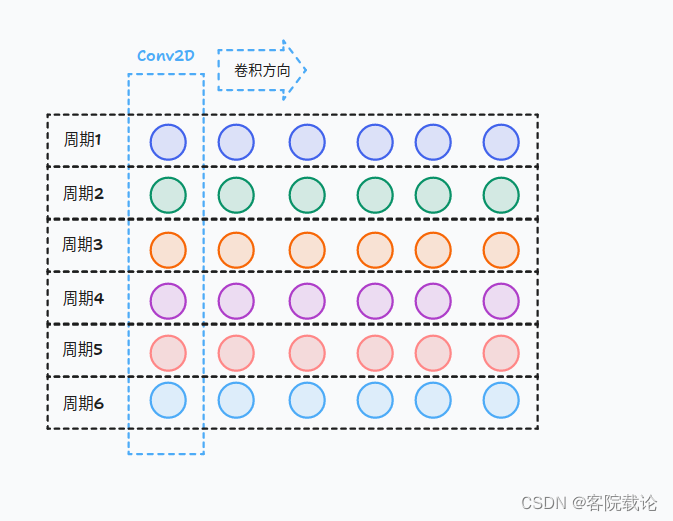
- 网络具体结构图下,鉴别输入的是真实的波形图和生成波形图,然后输出两者相似的概率值,进而衡量两者的相似程度,具体模型如下,就是若干个卷积模块的堆叠。
- 多周期鉴定器具体实现代码在,整个多周期鉴定器是由若干个子周期鉴定器构成,所以代码也是分成两个部分。
- 具体的单个周期鉴定器已经定义过了,然后就是最终的总的周期鉴定器的结构,就是多个不同周期的子鉴定器具的输出构成的列表
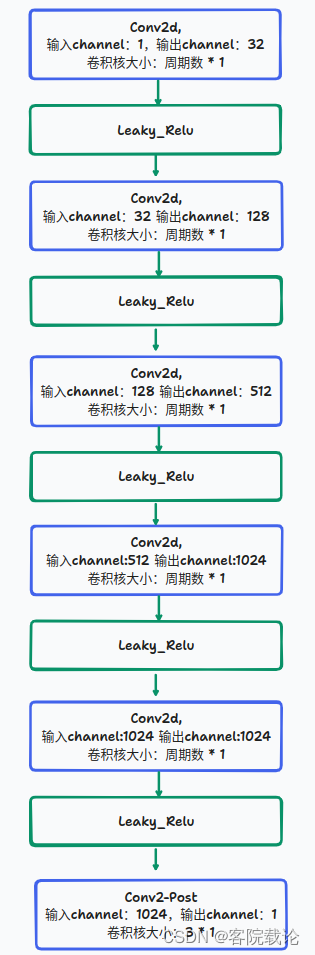
class DiscriminatorP(torch.nn.Module):def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False):# 定义鉴定器的初始化函数super(DiscriminatorP, self).__init__()self.period = period # 周期# 是否使用谱归一化norm_f = weight_norm if use_spectral_norm == False else spectral_normself.convs = nn.ModuleList([norm_f(Conv2d(1, 32, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))),norm_f(Conv2d(32, 128, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))),norm_f(Conv2d(128, 512, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))),norm_f(Conv2d(512, 1024, (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))),norm_f(Conv2d(1024, 1024, (kernel_size, 1), 1, padding=(2, 0))),])self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))def forward(self, x):fmap = []# 将原始的音频信号进行分割,分割成周期个数的小段,转换成二维的矩阵b, c, t = x.shape# b是批次大小,c是通道数,t是时间维度的长度if t % self.period != 0:# 不能进行整除的情况下,复制边缘的值进行填充n_pad = self.period - (t % self.period)x = F.pad(x, (0, n_pad), "reflect")# 更新时间维度的长度t = t + n_pad# 按照形状将数据进行填充,将时间维度分割成段数和每段的长度,从一维数据变二维数据x = x.view(b, c, t // self.period, self.period)# 将音频信号按照制定的周期进行分割,并将每个周期的信号转换为特定的维度for l in self.convs:x = l(x)x = F.leaky_relu(x, LRELU_SLOPE)fmap.append(x)x = self.conv_post(x)fmap.append(x)# 将数据恢复成一维数据x = torch.flatten(x, 1, -1)return x, fmap# 多周期鉴定器
class MultiPeriodDiscriminator(torch.nn.Module):def __init__(self):# 定义若干个周期的鉴定器super(MultiPeriodDiscriminator, self).__init__()self.discriminators = nn.ModuleList([DiscriminatorP(2),DiscriminatorP(3),DiscriminatorP(5),DiscriminatorP(7),DiscriminatorP(11),])def forward(self, y, y_hat):# 两个参数分别是真实的音频信号y和生成的音频信号y_haty_d_rs = [] # 真实音频信号的鉴定器的输出y_d_gs = [] # 生成音频信号的鉴定器的输出fmap_rs = [] # 真实音频信号的鉴定器的特征图fmap_gs = [] # 生成音频信号的鉴定器的特征图for i, d in enumerate(self.discriminators):y_d_r, fmap_r = d(y)y_d_g, fmap_g = d(y_hat)y_d_rs.append(y_d_r)fmap_rs.append(fmap_r)y_d_gs.append(y_d_g)fmap_gs.append(fmap_g)return y_d_rs, y_d_gs, fmap_rs, fmap_gs
多尺度鉴定器
- 上一节中的多周期鉴定器是将数据进行间隔采样,然后卷积处理。并没有处理连续的采样点,也就获得不了音频数据的长领域依赖。不同于生成其中使用反卷积进行的上采样,这里使用了平均池化,缩小数据的范围,然后让一个数据浓缩更多的信息 ,然后进行分别进行特征提取操作。具体见下图。
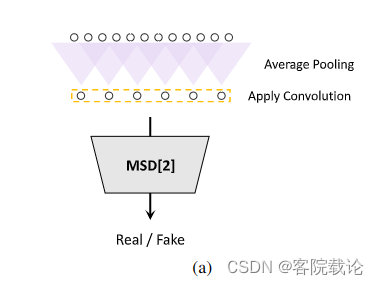
- 不同于多周期鉴定器,多尺度鉴定器中的子鉴定器是相同的,不同的是输入的信号,经过的平均池化的倍数不同,所以每一个采样点包含的信息维度就不同。具体的单个鉴定器的结构如下
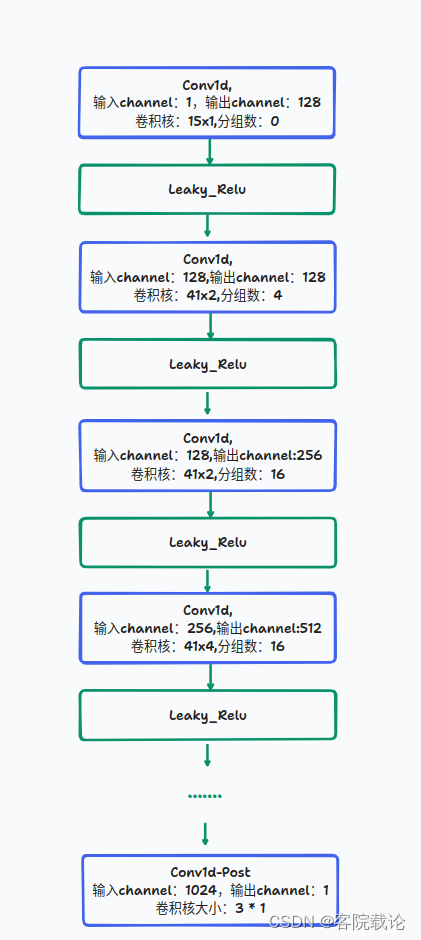
- 具体代码实现如下,首先经过平均池化层,然后再经过不同的平均特征提取层
# 多尺度鉴定器的定义
class DiscriminatorS(torch.nn.Module):def __init__(self, use_spectral_norm=False):super(DiscriminatorS, self).__init__()norm_f = weight_norm if use_spectral_norm == False else spectral_norm# 定义特征提取层self.convs = nn.ModuleList([norm_f(Conv1d(1, 128, 15, 1, padding=7)),norm_f(Conv1d(128, 128, 41, 2, groups=4, padding=20)),norm_f(Conv1d(128, 256, 41, 2, groups=16, padding=20)),norm_f(Conv1d(256, 512, 41, 4, groups=16, padding=20)),norm_f(Conv1d(512, 1024, 41, 4, groups=16, padding=20)),norm_f(Conv1d(1024, 1024, 41, 1, groups=16, padding=20)),norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),])self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))def forward(self, x):# 在前向传播的过程中,会将数据进行展平fmap = []for l in self.convs:x = l(x)x = F.leaky_relu(x, LRELU_SLOPE)fmap.append(x)x = self.conv_post(x)fmap.append(x)x = torch.flatten(x, 1, -1)return x, fmapclass MultiScaleDiscriminator(torch.nn.Module):def __init__(self):super(MultiScaleDiscriminator, self).__init__()# 定义三个特征提取模块,每一个模块前面都有一个平均池化层self.discriminators = nn.ModuleList([DiscriminatorS(use_spectral_norm=True),DiscriminatorS(),DiscriminatorS(),])# 定义两个平均池化层,尽量获取全局信息self.meanpools = nn.ModuleList([AvgPool1d(4, 2, padding=2),AvgPool1d(4, 2, padding=2)])def forward(self, y, y_hat):y_d_rs = []y_d_gs = []fmap_rs = []fmap_gs = []# 遍历每一个平均池化层,然后进行卷积,特征提取for i, d in enumerate(self.discriminators):if i != 0:y = self.meanpools[i-1](y)y_hat = self.meanpools[i-1](y_hat)y_d_r, fmap_r = d(y)y_d_g, fmap_g = d(y_hat)y_d_rs.append(y_d_r)fmap_rs.append(fmap_r)y_d_gs.append(y_d_g)fmap_gs.append(fmap_g)return y_d_rs, y_d_gs, fmap_rs, fmap_gs
问题
- 对于音频信号的采样间隔合理吗?
- 音频信号确实是由不同的频率的正弦波构成,但是这些音频的频率不同,他设置的采样间隔并没有任何根据,仅仅是因为他们是质数?这种采样周期设定,不应该根据对音频信号的分析去确定吗。
- 谱归一化和常规的归一化有什么不同?
- 权重归一化:通过对每一个神经元的权重向量进行归一化,加夸模型的收敛速度,减少训练时间。
- 谱归一化:用于约束神经网络 权重的方法,主要用于生成对抗网络。通过将权重矩阵的谱范数(即权重矩阵的最大奇异值)归一化到1来实现,借此方式GAN训练过程中的模式崩溃问题。
- 总结:两者的作用不同,权重归一化是通过修改网络权重,加速收敛和改进有化。谱归一化用于约束GAN判别函数,确保满足某些数学性质。
总结
- 在上一篇博客中,已经整理过了生成器的相关代码,生成器为了获取更加全局更加细致的信息,对数据进行了上采样,使得数据尽可能在时间维度上和原始的音频信号相同。到了鉴定器,在多周期鉴定器中,针对周期的特征提取是考虑了全局信息,从全局的角度出发。然后在多尺度鉴定器中,又使用了三个池化层,然后分别保留不同尺度下特征。
- 对于GAN模型而言,最重要的还是生成器,然后鉴定器是起到了一个引导作用。鉴定器的考虑的越周到,相应的,生成器的生成的结果也就越准确。
相关文章:
论文代码学习—HiFi-GAN(2)——鉴别器discriminator代码
文章目录 引言正文鉴别器多周期鉴定器多尺度鉴定器问题 总结 引言 这里翻译了HiFi-GAN这篇论文的具体内容,具体链接。这篇文章还是学到了很多东西,从整体上说,学到了生成对抗网络的构建思路,包括生成器和鉴定器。细化到具体实现的…...
 grep命令】)
Linux Shell 脚本编程学习之【第3章 正则表达式 (第二部分) grep命令】
第3章 正则表达式 (第二部分) 4 grep命令4.1 基本用法4.2 参考命令4.2.1 双引号4.2.2 -c 输出匹配行数4.2.3 -h 或 -l 不显示或只显示文件名4.2.4 -s 不显示错误信息4.2.5 -r 递归显示本级目录及下级目录4.2.6 -w 匹配完整词 -x 匹配完整行4.2.7 -q 退出…...
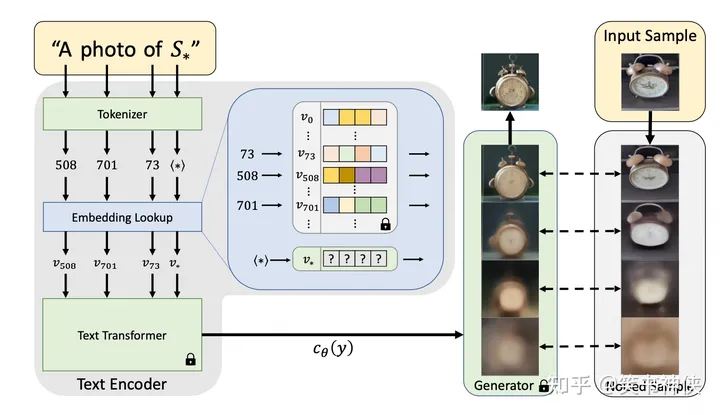
大语言模型LLM
目录 一、语言模型的发展 语言模型(Language Model,LM)目标是建模自然语言的概率分布,具体目标是构建词序列w1,w2,...,wm的概率分布,即计算给定的词序列作为一个句子出现可能的大小P(w1w2...wm)。但联合概率P的参数量…...

自学网络安全(黑客)的误区
前言 网络安全入门到底是先学编程还是先学计算机基础?这是一个争议比较大的问题,有的人会建议先学编程,而有的人会建议先学计算机基础,其实这都是要学的。而且这些对学习网络安全来说非常重要。 一、网络安全学习的误区 1.不要…...
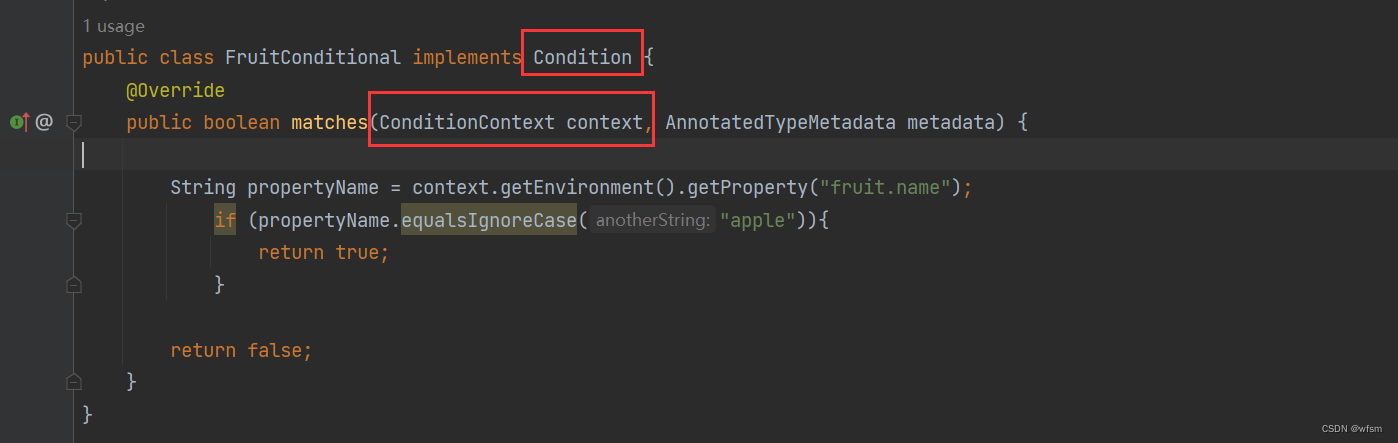
@Conditional
Conditional Conditional 是 spring framework 中提供的一个条件注解,,满足条件就注入,不满足就不注入ioc Condtional 需要和 Condition接口 一起用: 返回true注入,返回false不注入,, 里面有一…...
【Linux】网络基础之TCP协议
目录 🌈前言🌸1、基本概念🌺2、TCP协议报文结构🍨2.1、源端口号和目的端口号🍩2.2、4位首部长度🍪2.3、32位序号和确认序号(重点)🍫2.4、16位窗口大小🍬2.5、…...
模式)
Java设计模式之装饰器(Decorator)模式
装饰器(Decorator)设计模式允许动态地将新功能添加到对象中,同时又不改变其结构。 什么是装饰器模式 装饰器(Decorator)模式通过将对象进行包装,以扩展其功能,而不需要修改其原始类。装饰器模…...

element ui树组件render-content 树节点的内容区的渲染另一种方式
直接上代码吧,不用h的写法。 <el-tree :data"data" node-key"id" default-expand-all :expand-on-click-node"false" :props"defaultProps":render-content"renderContentTree" node-click"handleNodeClick"&g…...
html a标签换行显示
文章目录 用css display属性不用css,可以用<br>标签换行示例 用css display属性 可以使用CSS的display属性来实现多个a标签每行显示一个。 HTML代码: <div class"link-container"><a href"#">Link 1</a>…...

关于Redis-存Long取Integer类型转换错误的问题
背景 最近遇到了两个Redis相关的问题,趁着清明假期,梳理整理。 1.存入Long类型对象,在代码中使用Long类型接收,结果报类型转换错误。 2.String对象的反序列化问题,直接在Redis服务器上新增一个key-value,…...
)
设计模式一:简单工厂模式(Simple Factory Pattern)
简单工厂模式(Simple Factory Pattern)是一种创建型设计模式,它提供了一个通用的接口来创建各种不同类型的对象,而无需直接暴露对象的创建逻辑给客户端。 简单工厂的三个重要角色: 工厂类(Factory Class&…...
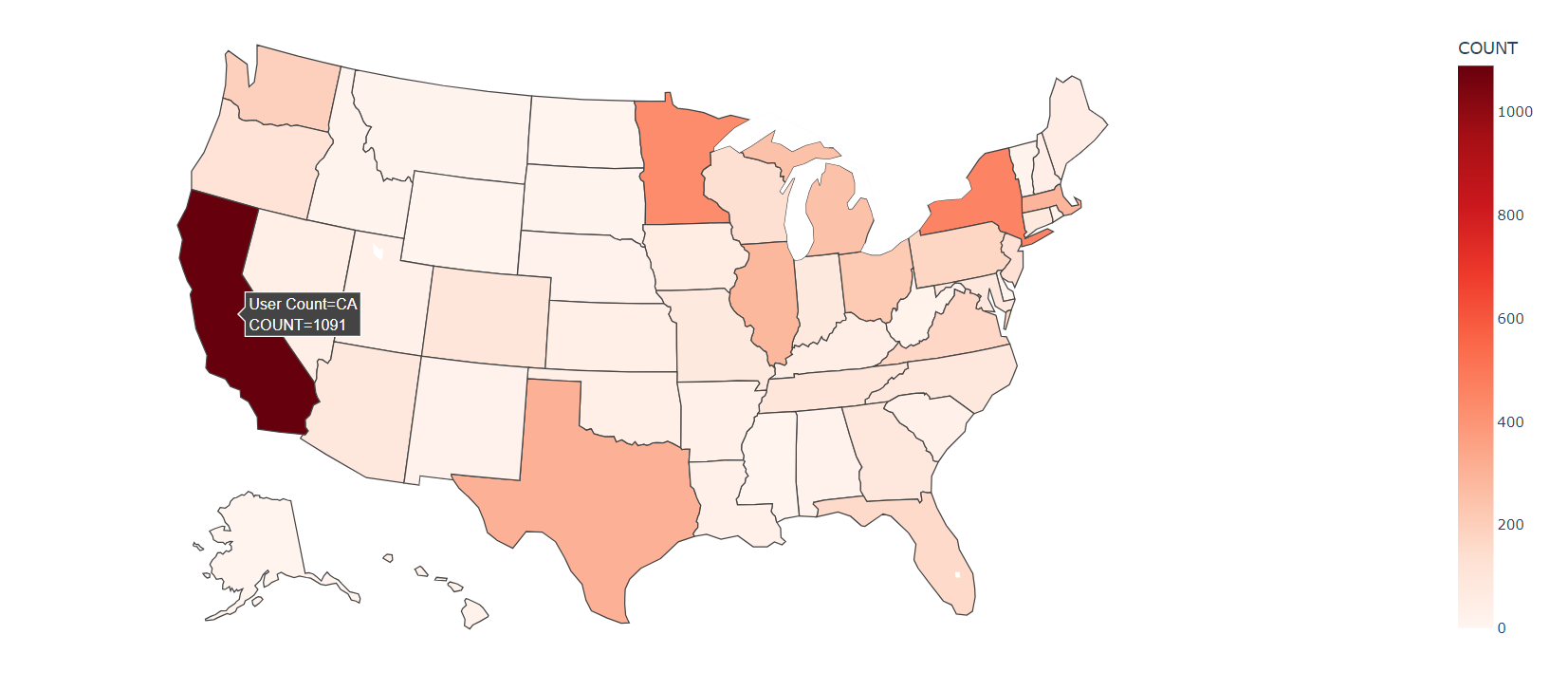
如何利用plotly和geopandas根据美国邮政编码(Zip-Code)绘制美国地图
对于我自己来说,该需求源自于分析Movielens-1m数据集的用户数据: UserID::Gender::Age::Occupation::Zip-code 1::F::1::10::48067 2::M::56::16::70072 3::M::25::15::55117 4::M::45::7::02460 5::M::25::20::55455 6::F::50::9::55117我希望根据Zip-…...

ceph集群搭建
文章目录 理论知识具体操作搭建ceph本地源yum源及ceph的安装配置NTP(解决时间同步问题)部署ceph自定义crush 理论知识 Ceph是一个分布式存储系统,并且提供了文件、对象、块存储功能。 Ceph集群中重要的守护进程有:Ceph OSD、Cep…...

前端密码加密 —— bcrypt、MD5、SHA-256、盐
🐔 前期回顾悄悄告诉你:前端如何获取本机IP,轻松一步开启网络探秘之旅_彩色之外的博客-CSDN博客前端获取 本机 IP 教程https://blog.csdn.net/m0_57904695/article/details/131855907?spm1001.2014.3001.5501 在前端密码加密方案中ÿ…...

汽车UDS诊断深度学习专栏
1.英文术语 英文术语翻译Diagnostic诊断Onboard Diagnostic 在线诊断 Offboard Diagnostic离线诊断Unified diagnostic service简称 UDS 2.缩写表 缩写解释ISO国际标准化组织UDSUnified diagnostic service,统一的诊断服务ECU电控单元DTC 诊断故障码 ISO14229UD…...

macOS 下安装brew、nvm
1、brew: /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)" brew -v 查看版本 示例: 安装jdk brew search jdk 查询可用的jdk版本 brew install openjdk11 安装制定版本jdk 更换源࿱…...

【云原生】Kubernetes工作负载-StatefulSet
StatefulSet StatefulSet 是用来管理有状态应用的工作负载 API 对象 StatefulSet 用来管理某 Pod 集合的部署和扩缩, 并为这些 Pod 提供持久存储和持久标识符 和 Deployment 类似, StatefulSet 管理基于相同容器规约的一组 Pod。但和 Deployment 不同…...

Java:方法的重载
方法重载 为什么需要方法重载 在使用方法的过程中我们可能会遇到以下如同例子的情形: public class method1 {public static void main(String[] args) {int a1 10;int b1 20;double ret1 add(a1, b1);System.out.println("ret1 " ret1);do…...

7.react useCallback与useMemo函数使用与常见问题
react useCallback与useMemo函数使用与常见问题 useCallback返回一个可记忆的函数,useMemo返回一个可记忆的值,useCallback只是useMemo的一种特殊形式。 那么这到底是什么意思呢?实际上我们在父子通信的时候,有可能传递的值是一…...
Sentinel限流中间件
目录 介绍 Sentinel 的特征 Sentinel 的组成 实战使用 简单实例 配置本地控制台 使用可视化ui配置简单流控 配置异步任务限流 使用注解定义限流资源 SpringCloud整合Sentinel 简单整合 并发线程流控 关联模式 整合openFeign使用 介绍 随着微服务的流行࿰…...
)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)在当今微服务架构盛行的时代,Go语言因其高性能和并发优势成为后端开发的热门选择。而Goframe作为一款企业级的Go应用开发框架,提供了从数据库操作到API…...

为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议
更多请点击: https://intelliparadigm.com 第一章:为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议 当团队将DeepSeek-R1或DeepSeek-VL模型用于技术方案生成时,表面看响应迅速、逻辑连贯&…...

WarcraftHelper终极指南:深度解析魔兽争霸III现代化兼容性解决方案
WarcraftHelper终极指南:深度解析魔兽争霸III现代化兼容性解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专…...

【C语言】C 语言为什么叫 C 语言呢?
【C语言】C 语言为什么叫 C 语言呢?笔记改自于王道训练营资料 其实是因为先有高级语言ALGOL 60,简称 A 语言,后来经过简化,变为 BCPL 语言,简称 B 语言,而 C 语言是在 B 语言的基础之上发展而来的ÿ…...

【DeepSeek灰度发布黄金法则】:20年SRE亲授7步零故障上线实战框架
更多请点击: https://intelliparadigm.com 第一章:DeepSeek灰度发布策略全景图 DeepSeek模型服务的灰度发布并非简单的流量切分,而是一套融合可观测性、渐进式验证与多维熔断机制的工程化闭环体系。其核心目标是在保障线上推理稳定性的同时&…...

基于树莓派打造万能遥控器:从硬件选型到Web控制界面全解析
1. 项目概述:打造一个能“学习”的万能遥控器家里遥控器越来越多,电视、空调、风扇、灯带……每个设备都配一个,找起来麻烦,用起来也乱。市面上所谓的“万能遥控器”其实并不万能,它内置的码库有限,很多小众…...

LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换!
LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换! 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 厌倦了千篇一律的英雄联盟客户端界面?想向好友展示王者段位却还在白…...

避坑指南:Unity中AABB碰撞检测失效的5种常见原因及解决方法
Unity中AABB碰撞检测失效的深度排查与解决方案在Unity开发中,AABB(轴对齐包围盒)碰撞检测是基础但容易出问题的环节。许多开发者都遇到过这样的情况:明明逻辑正确,测试时却出现物体穿透、碰撞时有时无等诡异现象。本文…...

从《吃豆人》到开放世界:聊聊Unity Navigation里Agent Radius和Cost的那些‘潜规则’
从《吃豆人》到开放世界:Unity Navigation中Agent Radius与Cost的隐藏逻辑1980年诞生的《吃豆人》用简单的迷宫路径定义了早期游戏AI的移动规则——幽灵们沿着固定路线巡逻,遇到转角时随机选择方向。这种设计在当时堪称革命性,但以今天的标准…...

音乐解锁工具:让加密音乐文件在任何设备自由播放
音乐解锁工具:让加密音乐文件在任何设备自由播放 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://gi…...