【NLP】视觉变压器与卷积神经网络
一、说明
本篇是 变压器因其计算效率和可扩展性而成为NLP的首选模型。在计算机视觉中,卷积神经网络(CNN)架构仍然占主导地位,但一些研究人员已经尝试将CNN与自我注意相结合。作者尝试将标准变压器直接应用于图像,发现在中型数据集上训练时,与类似ResNet的架构相比,这些模型的准确性适中。然而,当在更大的数据集上进行训练时,视觉转换器(ViT)取得了出色的结果,并在多个图像识别基准上接近或超过了最先进的技术。本文记录这种结论,等有时机去验证。
二、CNN卷积网络transformer起源
这篇博文的灵感来自谷歌研究团队的一篇题为“图像价值16X16字:大规模图像识别的变形金刚”的论文。本文建议使用直接应用于图像补丁的纯转换器来完成图像分类任务。视觉转换器 (ViT) 在多个基准测试中优于最先进的卷积网络,同时在对大量数据进行预训练后,需要更少的计算资源进行训练。
变压器因其计算效率和可扩展性而成为NLP的首选模型。在计算机视觉中,卷积神经网络(CNN)架构仍然占主导地位,但一些研究人员已经尝试将CNN与自我注意相结合。作者尝试将标准变压器直接应用于图像,发现在中型数据集上训练时,与类似ResNet的架构相比,这些模型的准确性适中。然而,当在更大的数据集上进行训练时,视觉转换器(ViT)取得了出色的结果,并在多个图像识别基准上接近或超过了最先进的技术。
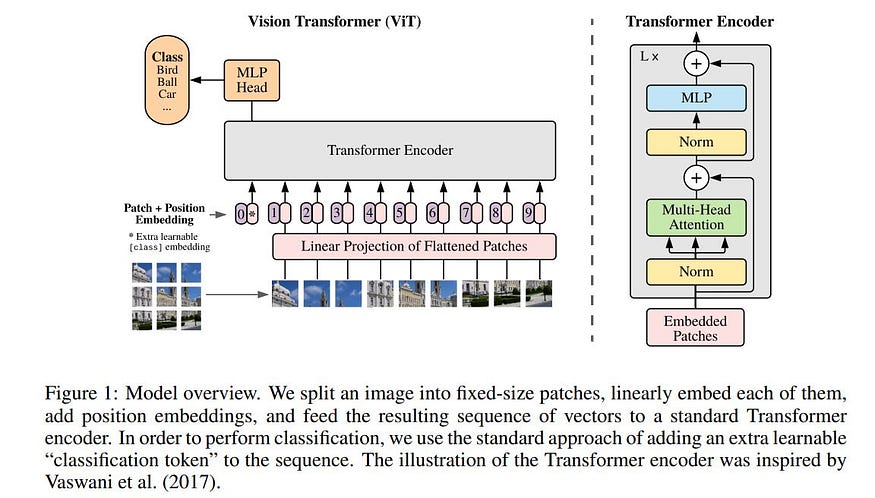
图 1(取自原始论文)描述了一个模型,该模型通过将 2D 图像转换为展平的 2D 补丁序列来处理 <>D 图像。然后将补丁映射到具有可训练线性投影的恒定潜在矢量大小。一个可学习的嵌入被附加到补丁序列之前,它在转换器编码器输出端的状态用作图像表示。然后将图像表示通过分类头进行预训练或微调。添加位置嵌入以保留位置信息,嵌入向量序列用作变压器编码器的输入,该编码器由多头自注意和 MLP 块的交替层组成。
过去,CNN长期以来一直是图像处理任务的首选。它们擅长通过卷积层捕获局部空间模式,从而实现分层特征提取。CNN擅长从大量图像数据中学习,并在图像分类,对象检测和分割等任务中取得了显着的成功。
虽然CNN在各种计算机视觉任务中拥有良好的记录,并且可以有效地处理大规模数据集,但视觉转换器在全局依赖关系和上下文理解至关重要的情况下具有优势。然而,视觉变压器通常需要大量的训练数据才能实现与CNN相当的性能。此外,CNN由于其可并行化的性质而具有计算效率,使其对于实时和资源受限的应用程序更加实用。
三、示例:CNN 与视觉转换器
在本节中,我们将使用 CNN 和视觉转换器方法,在 Kaggle 中可用的猫和狗数据集上训练视觉分类器。首先,我们将从 Kaggle 下载包含 25000 张 RGB 图像的猫和狗数据集。如果您还没有,可以阅读此处的说明,了解如何设置 Kaggle API 凭据。以下 Python 代码会将数据集下载到当前工作目录中。
from kaggle.api.kaggle_api_extended import KaggleApiapi = KaggleApi()
api.authenticate()# we write to the current directory with './'
api.dataset_download_files('karakaggle/kaggle-cat-vs-dog-dataset', path='./')下载文件后,您可以使用以下命令解压缩文件。
!unzip -qq kaggle-cat-vs-dog-dataset.zip
!rm -r kaggle-cat-vs-dog-dataset.zip使用以下命令克隆视觉转换器 GitHub 存储库。此存储库包含vision_tr目录下的视觉转换器所需的所有代码。
!git clone https://github.com/RustamyF/vision-transformer.git
!mv vision-transformer/vision_tr .下载的数据需要清理并准备训练我们的图像分类器。创建以下实用程序函数以 Pytorch 的 DataLoader 格式清理和加载数据。
import torch.nn as nn
import torch
import torch.optim as optimfrom torchvision import datasets, models, transforms
from torch.utils.data import DataLoader, Dataset
from PIL import Image
from sklearn.model_selection import train_test_splitimport osclass LoadData:def __init__(self):self.cat_path = 'kagglecatsanddogs_3367a/PetImages/Cat'self.dog_path = 'kagglecatsanddogs_3367a/PetImages/Dog'def delete_non_jpeg_files(self, directory):for filename in os.listdir(directory):if not filename.endswith('.jpg') and not filename.endswith('.jpeg'):file_path = os.path.join(directory, filename)try:if os.path.isfile(file_path) or os.path.islink(file_path):os.unlink(file_path)elif os.path.isdir(file_path):shutil.rmtree(file_path)print('deleted', file_path)except Exception as e:print('Failed to delete %s. Reason: %s' % (file_path, e))def data(self):self.delete_non_jpeg_files(self.dog_path)self.delete_non_jpeg_files(self.cat_path)dog_list = os.listdir(self.dog_path)dog_list = [(os.path.join(self.dog_path, i), 1) for i in dog_list]cat_list = os.listdir(self.cat_path)cat_list = [(os.path.join(self.cat_path, i), 0) for i in cat_list]total_list = cat_list + dog_listtrain_list, test_list = train_test_split(total_list, test_size=0.2)train_list, val_list = train_test_split(train_list, test_size=0.2)print('train list', len(train_list))print('test list', len(test_list))print('val list', len(val_list))return train_list, test_list, val_list# data Augumentation
transform = transforms.Compose([transforms.Resize((224, 224)),transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),
])class dataset(torch.utils.data.Dataset):def __init__(self, file_list, transform=None):self.file_list = file_listself.transform = transform# dataset lengthdef __len__(self):self.filelength = len(self.file_list)return self.filelength# load an one of imagesdef __getitem__(self, idx):img_path, label = self.file_list[idx]img = Image.open(img_path).convert('RGB')img_transformed = self.transform(img)return img_transformed, label四、CNN方法
此图像分类器的 CNN 模型由三层 2D 卷积组成,内核大小为 3,步幅为 2,最大池化层为 2。在卷积层之后,有两个全连接层,每个层由 10 个节点组成。下面是说明此结构的代码片段:
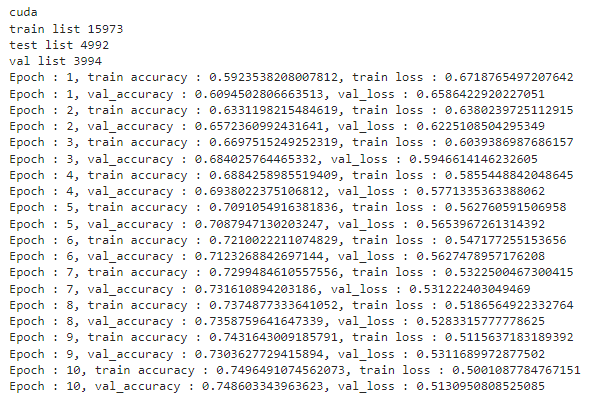
class Cnn(nn.Module):def __init__(self):super(Cnn, self).__init__()self.layer1 = nn.Sequential(nn.Conv2d(3, 16, kernel_size=3, padding=0, stride=2),nn.BatchNorm2d(16),nn.ReLU(),nn.MaxPool2d(2))self.layer2 = nn.Sequential(nn.Conv2d(16, 32, kernel_size=3, padding=0, stride=2),nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(2))self.layer3 = nn.Sequential(nn.Conv2d(32, 64, kernel_size=3, padding=0, stride=2),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(2))self.fc1 = nn.Linear(3 * 3 * 64, 10)self.dropout = nn.Dropout(0.5)self.fc2 = nn.Linear(10, 2)self.relu = nn.ReLU()def forward(self, x):out = self.layer1(x)out = self.layer2(out)out = self.layer3(out)out = out.view(out.size(0), -1)out = self.relu(self.fc1(out))out = self.fc2(out)return out训练是用特斯拉T4(g4dn-xlarge)GPU机器进行的,训练了10个训练周期。Jupyter Notebook 在项目的 GitHub 存储库中可用,其中包含训练循环的代码。以下是每个纪元的训练循环的结果。
五、视觉转换器方法
视觉变压器架构设计有可定制的尺寸,可以根据特定要求进行调整。对于这种大小的图像数据集,此体系结构仍然很大。
from vision_tr.simple_vit import ViT
model = ViT(image_size=224,patch_size=32,num_classes=2,dim=128,depth=12,heads=8,mlp_dim=1024,dropout=0.1,emb_dropout=0.1,
).to(device)视觉转换器中的每个参数都起着关键作用,如下所述:
image_size=224:此参数指定模型输入图像的所需大小(宽度和高度)。在这种情况下,图像的大小应为 224x224 像素。patch_size=32:图像被分成较小的补丁,此参数定义每个补丁的大小(宽度和高度)。在本例中,每个修补程序为 32x32 像素。num_classes=2:此参数表示分类任务中的类数。在此示例中,模型旨在将输入分为两类(猫和狗)。dim=128:它指定模型中嵌入向量的维数。嵌入捕获每个图像修补程序的表示形式。depth=12:此参数定义视觉转换器模型(编码器模型)中的深度或层数。更高的深度允许更复杂的特征提取。heads=8:此参数表示模型自注意机制中的注意力头数。mlp_dim=1024:指定模型中多层感知器 (MLP) 隐藏层的维数。MLP 负责在自我注意后转换令牌表示。dropout=0.1:此参数控制辍学率,这是一种用于防止过度拟合的正则化技术。它在训练期间将输入单位的一部分随机设置为 0。emb_dropout=0.1:它定义了专门应用于令牌嵌入的辍学率。此丢弃有助于防止在训练期间过度依赖特定令牌。
使用Tesla T4(g4dn-xlarge)GPU机器对分类任务的视觉转换器进行了20个训练周期的训练。训练进行了20个epoch(而不是CNN使用的10个epoch),因为训练损失的收敛速度很慢。以下是每个纪元的训练循环的结果。

CNN 方法在 75 个时期内达到了 10% 的准确率,而视觉转换器模型的准确率达到了 69%,训练时间要长得多。
六、结论
总之,在比较CNN和Vision Transformer模型时,在模型大小,内存要求,准确性和性能方面存在显着差异。CNN 型号传统上以其紧凑的尺寸和高效的内存利用率而闻名,使其适用于资源受限的环境。事实证明,它们在图像处理任务中非常有效,并在各种计算机视觉应用中表现出出色的精度。另一方面,视觉变压器提供了一种强大的方法来捕获图像中的全局依赖关系和上下文理解,从而提高某些任务的性能。然而,与CNN相比,视觉变压器往往具有更大的模型尺寸和更高的内存要求。虽然它们可能会达到令人印象深刻的准确性,尤其是在处理较大的数据集时,但计算需求可能会限制它们在资源有限的场景中的实用性。最终,CNN 和 Vision Transformer 模型之间的选择取决于手头任务的特定要求,考虑可用资源、数据集大小以及模型复杂性、准确性和性能之间的权衡等因素。随着计算机视觉领域的不断发展,预计这两种架构将取得进一步进展,使研究人员和从业者能够根据他们的特定需求和限制做出更明智的选择。
相关文章:
【NLP】视觉变压器与卷积神经网络
一、说明 本篇是 变压器因其计算效率和可扩展性而成为NLP的首选模型。在计算机视觉中,卷积神经网络(CNN)架构仍然占主导地位,但一些研究人员已经尝试将CNN与自我注意相结合。作者尝试将标准变压器直接应用于图像,发现在…...
【redis】通过配置文件简述redis的rdb和aof
redis的持久化方式有2种,rdb,即通过快照的方式将全量数据以二进制记录在磁盘中,aof,仅追加文件,将增量的写命令追加在aof文件中。在恢复的时候,rdb要更快,但是会丢失一部分数据。aof丢失数据极少…...

Cypress 上传 pdf 变空白页问题
在使用cypress 上传文件时,上传正常,但是,pdf一直空白的,翻边了资料也没找到原因。最后在一个不起眼的地方发现了问题所在。 错误的代码: cy.fixture(CBKS.pdf).as(uploadFile)cy.get(.el-upload-dragger).selectFile…...
【ArcGIS Pro二次开发】(52):布局导出图片(批量)
在ArcGIS Pro中设定好布局后,可以直接导出为各种类型的图片。 这是很基本的功能,但是如果你的布局很多,一张一张导图就有点费劲。 之前有网友提出希望可以批量导图,要实现起来并不难,于是就做了这个工具。 一、要实现…...

Git拉取远程分支并创建本地分支
一、查看远程分支 使用如下git命令查看所有远程分支: git branch -r 查看远程和本地所有分支: git branch -a 查看本地分支: git branch 在输出结果中,前面带* 的是当前分支。 二、拉取远程分支并创建本地分支 方法一 使用…...

OSI七层模型——物理层
OSI模型的物理层位于协议栈的底部。它是 TCP/IP 模型的网络接入层的一部分。如果没有物理层,就没有网络。本模块详细介绍了连接到物理层的三种方法。 1 物理层的用途 1.1 物理连接 不管是在家连接本地打印机还是将其连接到另一国家/地区的网站上,在进…...
和自动编码器)
【NLP】使用变压器(tranformer)和自动编码器
一、说明 自然语言处理 (NLP)中,trnsformer和编码器是至关重要的概念;本篇不是探讨原理,而是讲现实中,如何调用和使用transformer以及encoder,注意。本文中有时出现“变压器”,那是transormer的同义词,在此事先声明。 二、NLP及其重要性的简要概述 NLP是人工…...

广州华锐互动:水利数字孪生智能管理系统的特色
水利数字孪生智能管理系统是一种基于数字孪生的新型水利管理工具,它通过将现实世界中的水利设施和设备数字化,并在虚拟环境中进行模拟和分析,为水利管理者提供更加直观、精准的决策支持。该系统具有以下亮点: 首先,水利…...

php使用chatGPT生成一些东西做一个记录
好久没写了,这么长时间都去坐一些自己感兴趣的事情去了。 之前使用chatgpt-3,效果一直不咋好,这里我们来说说各个版本区别 gpt-3收费成本可以接受,生成的内容对话有点不太聪明的样子 git-3.5-turbo收费相对来说低,生成文本质量…...
轻量级Web报表工具ActiveReportsJS全新发布v4.0,支持集成更多前端框架!
ActiveReportsJS 是一款基于 JavaScript 和 HTML5 的轻量级Web报表工具,采用拖拽式设计模式,不需任何服务器和组件支持,即可在 Mac、Linux 和 Windows 操作系统中,设计多种类型的报表。ActiveReportsJS 同时提供跨平台报表设计、纯…...
听GPT 讲K8s源代码--pkg(七)
k8s项目中 pkg/kubelet/config,pkg/kubelet/configmap,pkg/kubelet/container,pkg/kubelet/cri 这几个目录处理与 kubelet 配置、ConfigMap、容器管理和容器运行时交互相关的功能。它们共同构成了 kubelet 的核心功能,使其能够在 …...
STM32MP157驱动开发——按键驱动(线程化处理)
文章目录 “线程化处理”机制:内核函数线程化处理方式的按键驱动程序(stm32mp157)编程思路button_test.cgpio_key_drv.cMakefile修改设备树文件编译测试 “线程化处理”机制: 工作队列是在内核的线程的上下文中执行的 工作队列中有多个 work࿰…...

探究HTTP代理爬虫的反爬虫策略
在当前信息爆炸的时代,海量的数据成为了企业发展和决策的关键资源。然而,越来越多的网站为了保护数据和用户隐私的安全,采取了各种反爬虫策略。作为一家专业的HTTP代理产品供应商,我们一直在研究和优化反爬虫策略,为用…...

短视频去水印小程序,一键部署你的小程序,可开流量主,实现睡后收入
插件地址 短视频去水印小程序,一键部署你的小程序,可开流量主,实现睡后收入 插件说明 本插件包含以下两部分: 短视频去水印插件,仅为一个接口,可以集成到自己的任意程序中。短视频去水印插件配套小程序…...

通讯录系统
目录 通讯录系统头文件: 通讯录系统Test: 通讯录系统函数源代码: 通讯录系统头文件: #define _CRT_SECURE_NO_WARNINGS 1 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <assert…...
14:00面试,14:06就出来了,问的问题有点变态。。。
从小厂出来,没想到在另一家公司又寄了。 到这家公司开始上班,加班是每天必不可少的,看在钱给的比较多的份上,就不太计较了。没想到5月一纸通知,所有人不准加班,加班费不仅没有了,薪资还要降40%,…...
F5 LTM 知识点和实验 3-负载均衡中的负载算法
第三章:负载均衡中的负载算法 负载算法分为静态的和动态的。静态的连接分布模式是预先设置的,流量处理中是不会变化的,动态的连接分布模式也是预先设置的,但是连接分布会根据某些因素的改变而调整。 轮询(round robi…...
多线程(JavaEE初阶系列2)
目录 前言: 1.什么是线程 2.为什么要有线程 3.进程与线程的区别与联系 4.Java的线程和操作系统线程的关系 5.多线程编程示例 6.创建线程 6.1继承Thread类 6.2实现Runnable接口 6.3继承Thread,使用匿名内部类 6.4实现Runnable接口,使…...
)
Ubuntu20.04点Ubuntu software没反应,打不开的解决方案(Ubuntu笔记)
首先检查Ubuntu Software的状态,在终端输入:systemctl status snap.ubuntu-software.ubuntu-software.service 如果状态显示为inactive,则需要启动snap.ubuntu-software.ubuntu-software.service,在终端输入:sudo sys…...

力扣1114.按序打印-----题目解析
题目描述 解析: class Foo {public int a 0;public Foo() {}public void first(Runnable printFirst) throws InterruptedException {// printFirst.run() outputs "first". Do not change or remove this line.printFirst.run();a;}public void second…...

基于Arduino的智能蓝调节拍器:DIY音乐练习伴侣
1. 项目概述:一个能“演奏”蓝调的低成本节拍器玩乐器的人,对节拍器这东西又爱又恨。它像一位严厉的监工,用单调的“嘀嗒”声强迫你跟上节奏。但你想过没有,这个监工其实可以很有趣?几年前,我在练习蓝调吉他…...
_kaic)
ssm207基于SSM的视频播放系统的设计与实现+vue(文档+源码)_kaic
第五章 系统的实现5.1 用户功能模块的实现5.1.1系统主界面用户进入本系统可查看系统信息,系统主界面展示如图5.1所示。图5.1网站主界面5.1.2视频详情界面用户可选择视频查看视频详情信息,并可进行视频播放操作,视频详情界面展示如图5.2所示。…...

Unity渲染排序三要素:SortingLayer、Order in Layer与RenderQueue协同原理
1. 为什么刚进Unity的美术和程序总在“图层遮挡”上反复拉扯?“这个UI怎么被背景挡住了?”“粒子特效一开就穿模,明明Z轴没问题!”“我调了Order in Layer到999,还是被另一个Sprite挡住——它连Sorting Layer都没改过&…...

AI IDE 革命:程序员正在被重新定义
很多开发者第一次使用 Cursor 的 CtrlK 或 Composer(高级多文件编辑模式)时,都会有一种强烈的、甚至让人有些脊背发凉的冲击感。 因为: 它已经不再是那个我们熟悉的、只能在原地等待光标落下的: “代码自动补全插件&am…...

MeloTTS实战:多语言语音合成的高效解决方案
MeloTTS实战:多语言语音合成的高效解决方案 【免费下载链接】MeloTTS High-quality multi-lingual text-to-speech library by MyShell.ai. Support English, Spanish, French, Chinese, Japanese and Korean. 项目地址: https://gitcode.com/GitHub_Trending/me/…...

深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南
深度解析网络设备权限管理工具:中兴光猫工厂模式与Telnet服务完整指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 在当今网络设备管理领域,获取设备完整控制…...
)
告别KITTI!用TartanAir数据集在Unreal Engine仿真环境里“虐”你的VSLAM算法(附保姆级下载与使用指南)
用TartanAir数据集在Unreal Engine中打造VSLAM算法的"极限考场"当你的视觉SLAM算法在KITTI数据集上跑出98%的准确率时,是否意味着它已经准备好应对真实世界的复杂场景?现实往往会给乐观的开发者当头一棒——实验室里的"优等生"在遇到…...

3个核心问题:如何突破Cursor AI的使用限制并持续获得Pro功能体验?
3个核心问题:如何突破Cursor AI的使用限制并持续获得Pro功能体验? 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: …...

量子机器学习多编码框架MEDQ:提升模型泛化能力与参数效率
1. 项目概述:为什么量子机器学习需要“多编码”?量子机器学习(QML)这几年火得不行,但真正上手做过的人都知道,它有个挺让人头疼的“怪病”:模型在某些数据集上表现神勇,换到另一个看…...

5个高效技巧:重新定义你的Chrome书签管理体验
5个高效技巧:重新定义你的Chrome书签管理体验 【免费下载链接】neat-bookmarks A neat bookmarks tree popup extension for Chrome [DISCONTINUED] 项目地址: https://gitcode.com/gh_mirrors/ne/neat-bookmarks 你是否曾花费数分钟在混乱的书签海洋中寻找那…...